
带有反馈调节的远程医疗专家自适化推荐
2023-10-09 01:01翟运开
系统管理学报 2023年5期
路 薇 ,高 盼 ,翟运开
(1.郑州大学 管理学院,郑州 450001;2.郑州大学第一附属医院,郑州 450052;3.互联网医疗系统与应用国家工程实验室,郑州 450052;4.河南省智能健康信息系统国际联合实验室,郑州 450001)
远程医疗是解决医疗资源不均衡问题的战略途径,因其能够借助互联网技术提供跨区域、跨机构的诊疗服务而得到了蓬勃发展[1-3]。远程医疗在使用过程中已收集、积累了大量代表患者健康状况的临床数据,明显增加了可用于面向患者决策的数字信息,使得数据驱动个性化医疗服务成为可能。但梳理业界实践发现,现有远程医疗服务并未充分利用和发挥其大数据价值。
患者最关心的是如何找到最专业的医学专家来解决他们的健康问题[4],但对患者而言,为自己挑选合适的专家极具挑战性,尤其是在没有合适匹配机制的情况下。面对信息体量的快速增长,由于患者缺乏专业的医疗背景和知识,他们在寻找合适的专家时不知所措[5],面临巨大的时间和搜索成本,使得问题不能得到及时有效的解决,甚至造成医疗资源的浪费,降低诊疗效率[6]。目前大多采用调度人员人工分配的方式为患者选择会诊专家,但随着会诊量的增加,人工分配的方式无法保证医疗服务的专业性和质量,加之医疗信息的不对称性,易引起患者不信任,进而影响医患关系和患者满意度。同时,快速变化的制度环境和日益增长的患者自主权之间的障碍使医生推荐更加复杂化。为此,探究智能化专家推荐方法,为患者推荐合适的会诊专家显得十分必要。
个性化推荐是解决信息过载[7]和知识迷向[8]问题的有效途径,能够帮助患者和调度人员过滤掉大量不相关的医疗专家,从专业层面快速准确地找到符合患者需求的远程医疗专家,降低患者搜索成本,辅助医疗决策,确保医疗服务价值的有效实现,从而为患者和远程医疗机构增益。目前,医疗保健领域的个性化推荐技术主要应用于在线健康社区,医疗资源的推荐方法主要分为两类:一类是基于投票评分机制的医生推荐[9-10],该方法本质上是赋予医生一个静态或动态的综合权威排名,并根据排名为患者推荐医生;另一类是基于相似性的医疗资源推荐[11-12],此类方法在协同过滤和内容推荐思想的基础上,借助语义网技术和社交网络技术来计算患者问题与医生标签之间的相似性,并以此为依据为患者推荐相关医生。
尽管推荐系统已被运用于医疗保健领域,但已有研究也存在以下不足:
(1) 大多患者与医生之间的交互数据较少,且出于隐私保护,患者不愿在在线平台上透露过多个人信息,数据稀疏性问题导致患者偏好难以捕捉,从而导致推荐效果不佳[13]。
(2) 仅从患者对医生的特征偏好以及医患之间的特征匹配能力出发实施推荐,忽视了患者对不同推荐方式的偏好[10]以及医生兴趣和活跃度及其随时间的变化[14],导致匹配成本增加,影响整个系统性能。
(3) 忽略反馈机制在推荐系统中的作用,未能形成推荐模型的闭环调整优化,影响推荐结果的时效性及服务质量[15]。
(4) 存在冷启动问题,新注册医生由于历史数据的不足缺乏展示机会,难以被发现[16]。
同时,以下原因使远程医疗情境下的医生推荐仍具有挑战性:①区别于传统推荐,极少患者就不同种类的医疗保健项目进行投票或评分,这给协同过滤机制带来了困难;②健康相关数据较为敏感,在远程医疗情境下,患者无法获得其他类似患者的信息,其决策行为不会受到其他患者的影响,这给采用基于社交网络的推荐系统带来了困难。
鉴于此,本文在隐私保护前提下,患者被视为独立个体,提出了一种融合专家活跃度和兴趣度以及反馈机制的专家自适化推荐方法。
1 相关研究
1.1 医疗推荐系统
推荐系统通过推荐符合个人兴趣/需求的项目来帮助用户有效处理信息过载问题,并为用户提供个性化服务。推荐技术已广泛应用于电子商务、在线搜索、新闻推送和社交媒体等众多领域[17],其在医疗领域也逐渐获得关注,相关技术和方法已应用于医生及其他医疗资源的推荐,以更好地支持医疗决策。一般而言,有4种类型的推荐系统:基于协同过滤的推荐、基于内容的推荐、基于深度学习的推荐以及混合推荐。
基于协同过滤的推荐是诞生最早且应用最为广泛的推荐算法,它基于“物以类聚、人以群分”的思想,使用评级将用户与一群志趣相投的用户联系起来,利用用户-项目行为矩阵计算用户之间或项目之间的相似性来实施推荐策略。当有足够的评级信息时,协同过滤技术表现出良好的性能。然而,矩阵稀疏性问题一直是制约其推荐效果的主要瓶颈。当前最广泛的解决方法是通过收集更多用户偏好或品味信息来自动预测用户兴趣。Ren等[18]将经常与患者疾病代码共同出现且高相关的搜索词结合,为临床医生推荐特定患者的搜索词,以便从患者大量记录中快速找出所需信息,提高诊断效率。高山等[19]提出了一种融合多种用户行为的协同过滤推荐算法,根据用户多种就医行为下的历史偏好信息进行推荐,缓解了用户在单一模式下评分数据稀少带来的冷启动问题。但此类方法需要提交大量额外的用户行为数据,且基于用户评分的相似性度量亦存在主观性过强的问题[20]。
为了弥补协同过滤方法的不足,基于内容的推荐方法被提出。它依赖于项目的内容表示来定位与目标用户喜欢的项目内容相似的项目,并为用户推荐相似内容。一些研究使用了其他类型的用户生成信息,如标签、成员关系和信任关系等以提高推荐的准确性。Ju等[21]根据患者的症状、诊断结果、地理位置以及医生的专业与所在科室向患者推荐科室和医生;患者的情境信息如性别、季节、数据特征、年龄、保险等也被融入个性化药品推荐系统中,从而支撑细粒度的诊断与处方[22]。该方法充分展示用户偏好,但容易导致“信息茧房”效应[23],使用户无法接触到其他领域优质内容,不利于创新。
基于深度学习的推荐主要表现为使用神经网络或基于关联规则的推荐,前者通过提取并学习数据潜在特征以达到预测效果;后者通过对不同条目的关联分析挖掘潜在规则,并将关联项目推荐给用户。为最大限度地利用发达医院的先进医疗技术和医生丰富的医学知识,Chen等[24]对疾病症状进行聚类,并引入Apriori算法对疾病诊疗规则进行关联分析,为患者和缺乏经验的医生推荐适当的诊疗方案。此类方法借助元数据挖掘隐含知识,进而产生用户意想不到的结果,但其关联规则发现需要大规模数据集且极为耗时,其规则有时难以解释,质量或难以保证,且深度学习的“黑箱子”特性导致推荐结果可解释性不足,进而降低用户信任和满意度[25]。
兼顾各类推荐方法的优缺点,有学者提出了混合推荐方法[26],用以优化推荐效果。Huang等[27]提出了一种基于协同的医学知识推荐方法,根据临床医生对过去知识项的评价行为所隐含的信任因素来衡量医生信任情况,并将其融合到协同过滤技术中,以提高推荐质量。李鹏飞等[28]对疾病的药物治疗过程进行建模,将患者历史用药数据进行主题聚类,形成药物功效组合标签,并借助XGBoost分类模型进行患者药物推荐。
1.2 医疗推荐方法
医疗推荐的核心是患者和医疗资源的内容建模,通过探知患者的信息/服务需求和医疗资源的服务能力,实现面向患者需求和兴趣的个性化推送,解决信息过载和知识迷向问题。从用户建模视角出发,医疗推荐方法可以划分为主题建模和特征建模。
主题建模是广泛应用于自然语言处理的强大智能技术,能够从无序文档或语料库中发现主题和挖掘潜在语义[29]。例如:在问答社区中,从用户发布问题和医生回答中提取词项形成用户模型,依据用户内容间的相似度得到推荐医生候选集,并通过LDA 主题模型筛选具有类似专业的其他医生以扩展候选集,最终通过相似度融合[6,12]、患者决策机理[30]、图计算[2]等方法为患者推荐合适的医生;Ali等[31]将患者病史、食物和处方药物进行本体设计,基于语义Web规则语言和模糊逻辑提取风险因素以确定患者健康状况,进而从模糊本体中检索药品和食物信息,为患者智能化推荐食品和药品;Gao等[32]利用LDA 主题模型训练用户调用记录来提取用户和服务的潜在主题,并基于相似用户形成兴趣子集,最后采用服务关联规则生成感兴趣的链式模式。
特征建模聚焦主体或服务的细节,将信任、偏好、绩效等融入推荐方法中。Yuan等[33]考虑了用户之间的信任和不信任关系,提出了一种基于深度学习的社会化医疗服务推荐模型来预测医疗服务的可靠性。Pan等[34]提出了患者偏好学习算法,向患有不同疾病的患者提供个性化的医生推荐;也有学者考虑了患者对不同推荐方式的偏好以及偏好指标之间的相互依赖性[10];患者基本信息、疾病特征及用户行为也被纳入推荐框架[35],构建场景化信息推荐模型,辅助患者获得更为精准的医疗信息。推荐系统的可解释性也逐渐被关注,成为增强患者信任的重要手段。深度学习和知识图谱[36-37]等技术被用来生成准确、可解释的医生推荐,从知识图中提取医患的交互特征来反映医生服务质量的个体特征,并将特征输入深度神经网络,基于学习得到注意力权重进而生成易于使用和可解释的推荐结果。
综上所述,主题建模和特征建模已成为医生推荐中广泛使用的方法,推荐解释也成为增强患者信任的重要手段。然而,当前研究在对医生特征建模时,大多依托在线医疗或在线问答社区情景,从医生回答文本集[38]、行为网络[39]、患者预约记录[34]、患者评价信息[40]等历史交互数据中提取医生特征,单一地聚焦医生短期内的交互信息或其衍生的评价信息而忽略了长期积累的医学背景。单一数据并不能完全揭示事物的特征,进而缺乏对决策服务的充分、全面支持[41],而多源数据能够从不同角度描述事物,实现数据之间的相互补充及印证[42],打破数据孤岛[43]。短期知识特征体现了专家近期的关注与兴趣变化,长期知识特征体现了专家持续性的特质,相对较稳定。两者结合能够更加全面地刻画专家的领域知识信息,提高推荐的准确性和科学性,尤其是对于短期交互信息不足的医生而言,长、短期知识的相互补充能够较为完整地反映医生特征及擅长领域,更好地支撑管理决策。因此,本文将专家的长、短期知识背景结合进行专家特征表征,不仅能够全面刻画专家的知识领域信息,提高推荐的准确性和科学性,也在一定程度上解决了专家推荐中的冷启动问题。
2 带有反馈调节的远程医疗专家自适化推荐模型构建
本文借助患者病历和专家长、短期知识背景进行特征建模,通过患者特征的相似性获得初始专家推荐指数和推荐专家集合,并基于专家长、短期知识特征的相似性更新新注册专家推荐指数和推荐专家集合。之后,融合专家推荐指数、活跃度和兴趣度形成专业推荐模型,并将其与效用推荐及反馈机制纳入同一框架来构建带有反馈调节的自适化推荐模型,实现专家推荐的闭环调整与自适更新。这在确保推荐结果准确性和相关性的基础上,不仅使推荐结果分布向最频繁、最活跃的专家倾斜进而提升推荐能力,也在考虑患者偏好的同时使推荐更具时效性和自适性。
依据研究目标构建了如图1所示的远程医疗专家推荐框架,主要包含4个模块:①数据集成与预处理。将多源数据进行收集、提取、聚合及预处理操作,以提高数据质量,生成可靠语料库。②基于电子病历的患者特征建模。引入停用词表、自定义用户字典等对可靠语料进行文本分词操作,将患者病历进行文本矢量化描述,并通过挖掘患者与专家诊断背景的契合度实现患者特征到专家特征的映射。③面向长短期知识的专家特征建模。基于专家长期积累的知识背景构建专家长期知识特征模型,基于病历库构建专家短期知识特征主题模型,通过挖掘专家知识特征间的相似性,在一定程度上解决冷启动问题并实现从文档到隐主题空间的映射。④带有反馈调节的专家自适化推荐模型构建。在患者特征和专家长短期知识特征的基础上,融合专家活跃度和兴趣度形成专业推荐策略,并根据反馈机制调整不同推荐策略间的关系及动态更新专家属性,实现推荐模型的动态闭环调整优化,增强推荐模型的可解释性、自适性及时效性。

图1 带有反馈调节的远程医疗专家自适化推荐框架Fig.1 Adaptive recommendation framework for telemedicine specialists with feedback adjustment
2.1 数据集成与预处理
数据来自双渠道,即远程医疗平台中积累的业务数据和在线医疗平台中的医生简介,原始数据较为粗糙,在进行文本挖掘前需对其进行预处理:①提取、整合、存储相关数据,并对数据进行规范化、完整性检查,剔除异常数据、基于填补规则补充缺失值;②创建自定义用户字典以使医疗领域专业词汇能够被正确识别;③创建停用词列表过滤掉对本次研究无意义的词、数字和符号,进而形成可靠语料,以便后文的数据分析,提高推荐准确率。
2.2 基于电子病历的患者特征建模
本文基于电子病历进行患者特征建模,形成患者-信息特征模型,并通过患者特征间的交互计算映射获得专家初始推荐指数,进而形成推荐专家候选集。文本分词和矢量化表示利用词的上下文信息将高维语句转换成低维实数向量,并提取出描述患者特征的关键词,形成患者特征模型。具体步骤如下:
步骤1特征词标化。患者病历以专业化的术语组成了患者病症的特征描述,面对专业性强、表述方式因人而异的医学术语,本文加载同义词字典、特征词字典和停用词表进行患者病历规范化处理、中文分词、文本标注和特征词提取。这一策略可增强文本的表征力,使得专业术语能够被正确识别和划分,压缩特征空间维度,提高数据处理效率和预测准确性,增强决策鲁棒性。
步骤2文本矢量化表示。借助word2vec模型计算文本中每个关键词的向量,并对不重复的词向量取平均,进而合成句向量表示文本的最终向量[44]。如患者pi的病历di由f个特征词构成,其规范化表示为:p.feature_profile=k=1,2,…,f},其中,di表示患者pi的病历文本,wk为第k个特征词,其对应的词向量为:vk={vk1,vk2,…,vkp}。
步骤3特征词权重计算。词频(Term Frequency,TF)是指给定单词在文本中出现的频率,而逆文档频率(Inverse Document Frequency,IDF)是衡量单词重要性的指标[45]。据此定义dpi中关键词wk的tf-idf值为:
步骤4文本相似性测度。矢量化的文本可以利用余弦相似度计算文本间的相似度,即各文本与目标文本的相似度Sim(di,dj)。余弦相似度是一种最简单、有效的向量相似度计算方法,其公式为
步骤5生成推荐专家候选集。以专家诊断过的相似患者的最高相似值作为专家初始推荐指数ini_score,完成患者特征到专家特征的映射,即通过目标患者特征与专家诊断的患者特征之间的相似性映射医-患背景的相似性。相似患者的诊治专家组成初始推荐专家候选集。为推荐优质医生,需返回高相似度患者的会诊专家,但是由于远程会诊患者并不是常见疾病或特征,故设置相似度阈值会限制推荐结果。综上所述,本文设置以下两个条件:①统计所有相似专家,将其相似患者的最高相似度作为专家初始推荐指数,并按照初始推荐指数进行降序排序;②从排序结果中取Top-10纳入候选集。
2.3 面向长短期知识的专家特征建模
病历库反映了专家在一定时间段内诊疗的疾病特征,而网页上公布的专家简介表征了专家持续性积累的经验及长期关注的疾病领域,因此,专家短期知识特征以病历库为基础,专家长期知识特征从专家简介中提取。
2.3.1 基于知识视图的长期知识特征模型 基于患者病历文本相似性确定推荐专家候选集的推荐策略只能发现诊断过与目标患者相似病情的专家,对于系统中新注册或业务数据较少的专家(统称为“新注册专家”),由于业务量少、缺乏足够的数据支撑,以至于被推荐机会不高。为解决新注册专家的冷启动问题,利用知识属性快速建立专家之间的关联,即通过计算知识属性的视图相似性来表征专家长期知识之间的相似度,并据此更新新注册专家初始推荐指数,进而增加他们的被推荐机会,在一定程度上缓解冷启动问题。具体步骤如下:
步骤1特征表示。针对知识的多样性,根据其所属领域、研究专长等赋予其不同的属性,如医生和疾病之间存在多对多关系,即一个医生可能擅长多种疾病,一种疾病也可被多个医生擅长,医生专长可以用向量表示,且取值为{0,1},1表示医生擅长该疾病,0表示不擅长该疾病。因此,本文通过计算医生知识属性的视图相似性来表征医生长期知识领域之间的相似度,构建如表1所示的专家知识属性矩阵。
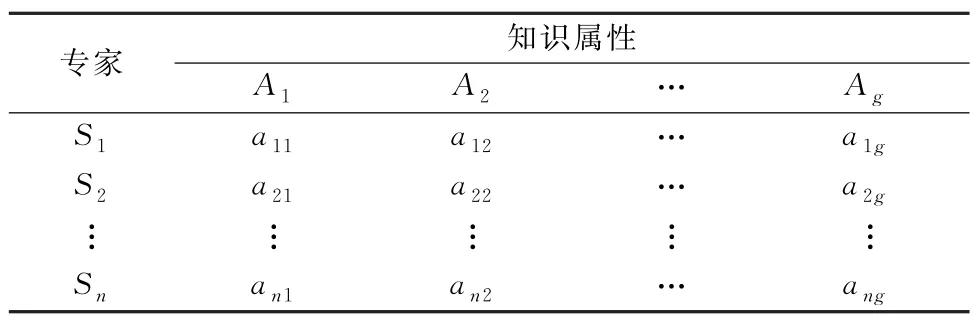
表1 专家知识-属性矩阵Tab.1 Specialists’ knowledge-attribute matrix
步骤2知识视图相似度测度。根据医生擅长疾病构建其知识结构,并通过计算医生之间的知识视图相似性来预测医生的能力匹配。基于知识的属性特征,采用Jaccard系数计算知识之间的属性相似性,其计算公式为
此外,基于不同知识的贡献和重要程度的差异性,通过权重对不同知识加以区分,得到加权的Jaccard知识视图相似度:
式中,ω(a)为知识属性的权重。为充分利用属性信息,通过信息熵的大小为属性确权,权重是从数据中学习的,避免了专家确权的主观性过强,即
式中:p(a)为属性a出现的概率;n(a)为属性a出现的次数。
步骤3新注册专家初始推荐指数更新。为返回具有相似知识领域背景的专家,设置专家相似性阈值为0.7,若SimKnowledge≥0.7,则返回该专家索引值。同时,更新新注册专家的初始推荐指数,即
式中:ini_scoreh为符合阈值要求的相似专家的初始推荐指数;q为新注册专家的相似专家数量。最后,按照相似性排序更新推荐专家候选集。
2.3.2 基于LDA 的专家短期知识特征模型 仅通过寻找相似患者形成推荐专家候选集的推荐策略是片面的,系统中可能存在其他符合目标患者需求的专家。LDA 主题概率模型将专家知识特征映射至隐主题空间,在同一主题下寻找具有相似概率分布的专家,能够从语义层面有效识别出擅长诊治相似疾病的专家,大大降低寻找相似专家的规模和时间成本。因此,本文选用LDA 主题模型凝练专家诊断过的病历文本,从中识别代表疾病类别的隐藏主题,这些主题代表专家擅长的疾病特征,每个专家属于一个或多个隐藏主题,生成基于主题的专家短期知识特征描述框架,在语义层面扩展推荐专家候选集。
(1) LDA 主题模型。LDA 模型是一种用于语料库建模的非监督产生式概率方法,是主题建模[46]最常用的方法,其基本思想[47]是文档被表示为隐含主题的随机混合物,其中主题由若干个特征词以特定概率分布构成。LDA 根据文档和词汇的概率分布将高维文本-词汇矩阵分为两个低维的文档-主题矩阵和主题-词汇矩阵,从而得到文档的主题分布。一条文本的生成过程可以形式化表述为:①从Dirichlet(α)分布中抽取文档d下的多项式主题分布θd,即θd~Dirichlet(α);②从Dirichlet(β)分布中抽取主题t下的多项式词分布φt,即φt~Dirichlet(β);③对于文档d中的词wk,从以θd为参数的多项式分布中抽取主题zn,即zn~Multi(θd);从以φzn为参数的多项式分布中抽取文档d中的第k个单词,即wk~ Multi(φzn)。概率模型如图2所示。
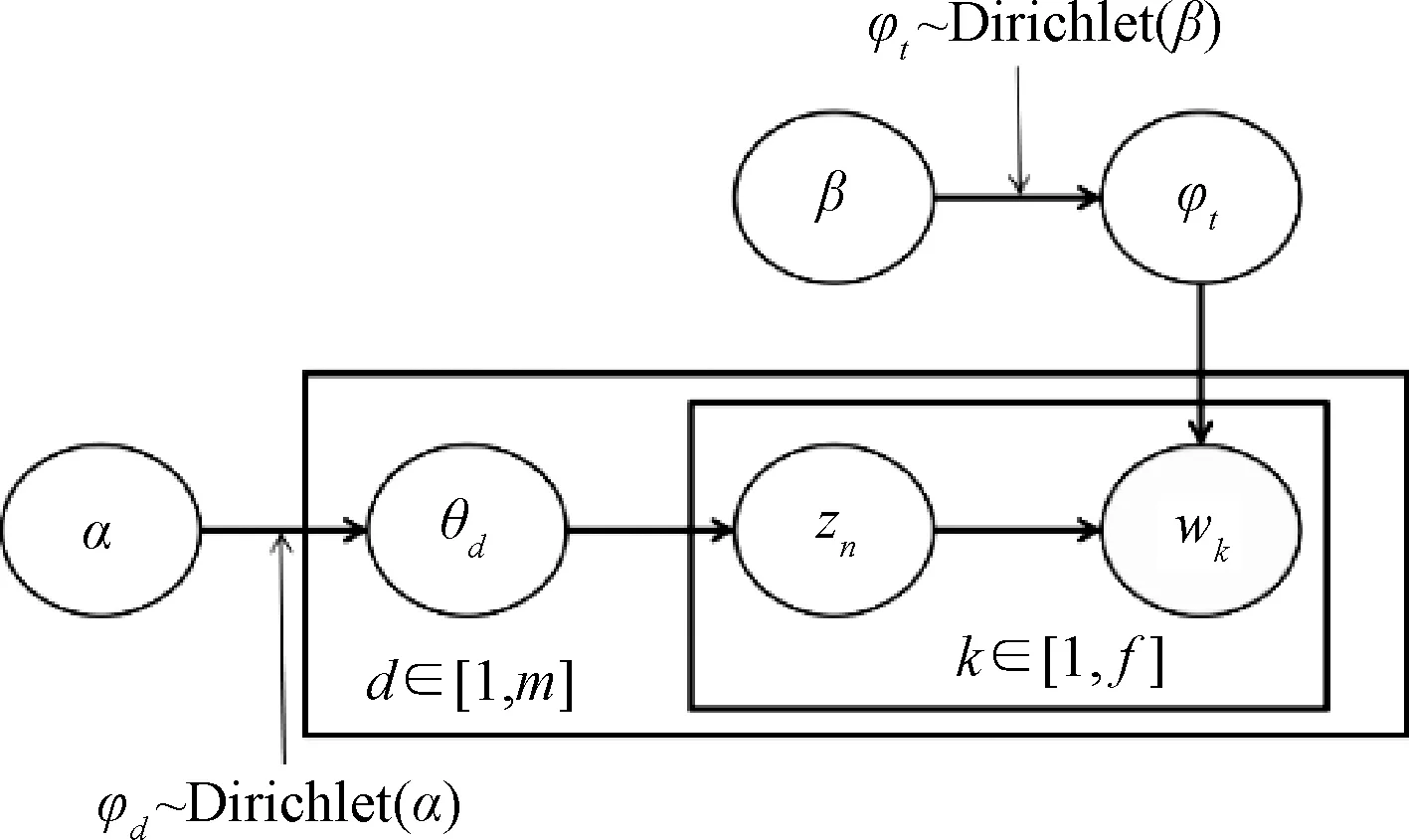
图2 LDA 概率模型Fig.2 LDA probabilistic model
LDA 的建模过程可以描述为每个资源寻找主题的混合,即文档中的每个词以特定概率选择某个主题,并从主题中以一定概率选择某个特征词来得到,该过程可形式化为
(2) 专家短期知识特征主题模型。在远程医疗情境中,一位专家可以诊疗多名患者,一名患者也可以通过多次申请享受同一位或多位专家的服务。本文侧重于由专家诊断过的患者病历文本组成的专家短期知识,专家与患者对应关系对本文影响不大,故后文不再对医患对应关系进行强调。鉴于此,本文在隐私保护基础上,在隐主题空间上构建面向短期知识特征的专家知识模型,其建模过程为:
步骤1整合专家诊断过的患者病历文本作为专家短期知识背景,进而形成LDA 训练语料库,以便于专家短期知识特征模型的训练与构建。
步骤2通过主题聚类凝练出隐藏的主题topic(t)={topic1,topic2,…,topick}及每个医生的“文档-主题”分布d.topic_profile={t1,t2,…,tk},k为经过LDA 主题聚类出的主题数。
步骤3LDA 主题聚类生成的“主题-词项”概率分布可完成对专家短期知识特征的表达:d.feature_profile={
步骤4基于“文档-主题”概率分布的相似性得到与推荐专家候选集中具有相似知识特征的专家,并以此作为面向专家短期知识特征的推荐指数short_score,这些相似专家也具有诊疗目标患者的能力。
在LDA 模型中,采用服从Dirichlet分布的主题概率向量来衡量,若使用余弦夹角来计算文本相似度就失去了主题模型的优势。KL 散度作为一种衡量两个概率分布差异性的方法,常被用来计算文档主题分布向量的相似度[48]。则两个分布P和Q的KL散度为
但由于KL散度的不对称性使其不能用作距离测量,即DKL(P‖Q)≠DKL(Q‖P),故作为KL散度的变形,具有对称性的JS散度被提出并弥补KL散度的不足。DJS∈[0,1],DJS的值越小,表示两个分布越相似,当两个分布相同时,DJS=0。则两个分布P和Q的JS散度为
两个分布越相似,DJS的值越小,因此,为了方便进行相似度计算,对JS散度值进行转换,转换方式为
式中:ε为调节因子;相似度取值范围为[0,1]。
2.4 带有反馈调节的专家自适化推荐模型构建
患者并不是被动地接受服务推荐,而可以提出自身需求和偏好,并在需求得到满足后对服务质量进行评价;将患者反馈及服务结果反馈给推荐系统能够更新专家属性值,进而优化后续推荐结果,这就由反馈机制决定。同时,被推荐者的兴趣度和活跃度会随着时间的推移发生变化,进而影响推荐效力。鉴于此,本节将专家活跃度和兴趣度及反馈机制纳入推荐框架,以实现推荐系统的可解释性及动态闭环调整,在考虑专家个体行为和患者偏好的基础上保证推荐系统的时效性与自适性。
2.4.1 融合专家活跃度和兴趣度的专业推荐 为充分考虑专家的个体行为变化,本节融合专家推荐指数与专家活跃度和兴趣度,构成基于患者病历的专业推荐方法,使推荐结果分布向最频繁、最活跃的专家倾斜,增强推荐系统的时效性。
(1) 活跃度。活跃度已成为在线医疗和在线问答社区中识别关键用户及衡量专家绩效的重要指标,其受时间、回答数量、响应速度等众多因素影响[16,49]。推移到远程医疗情境中,可以解释为专家在一段时间内会诊病历越多,间隔时间越短(以天为单位),专家在平台中越活跃,其愿意开展远程医疗服务的可能性越大。因此,在考虑相似性的基础上,还应考虑专家在平台中的活跃度,使推荐列表向活跃度高、具有较大热情的专家倾斜,提高推荐效力。借鉴文献[50]对最近活跃度的定义,本文的专家活跃度以患者最新需求发布时间及专家最近活跃时间的差值来衡量,差值越大,专家活跃度越低,即
式中:T为专家会诊时间的合集;tc为目标患者申请时间;tl为该专家上次会诊时间。为避免分母为0,本文将时间间隔扩大一个单位。为了降低专家最近活跃度的跳跃性,本文将专家最近活跃度做如下处理:
式中,ACmax为最活跃专家的活跃度。
(2) 兴趣度。兴趣反映用户对客观事物的选择态度,表现为个体认识、接近、获取客观事物的意向和态度[51]。如何衡量并理解用户的兴趣与偏好,是推荐系统成功的关键[25]。会诊数量可以看作专家对远程医疗服务的显性反馈,是专家兴趣行为的表现。随着会诊频次的增加,专家表现出对远程医疗较高的偏好和兴趣,此类专家更加信任和愿意服务于远程医疗患者,这使得可以根据专家的会诊频次来动态衡量专家对远程医疗的兴趣。同时,相关理论研究表明,兴趣会随时间的推移而发生变化,呈非线性衰减[52-53]。因此,考虑到会诊的频率和时间,将时间信息加入推荐算法,采用指数时间衰减函数对会诊专家Sj的兴趣度Ij进行动态建模,即
式中:T为当前时间段;Nj(t)为专家Sj在t阶段的会诊次数;N(t)为t阶段的总会诊次数;αj为指数衰减常数,用于控制时间衰减率,由专家会诊频次拟合曲线得到。
为消除权重系数融合时量纲的影响,进一步对兴趣度进行处理,得到专家的兴趣度,即
式中,Imax为表现出最高兴趣的专家的兴趣度。
如上所述,在推荐指数的基础上融合专家活跃度和兴趣度进行推荐,使推荐结果分布向最近、最频繁的专家倾斜,具体表达式为
式中,γ1和γ2分别为活跃度和兴趣度的权重系数,且γ1+γ2=1。具体应用中,两权重设为参数,可对线性融合方案进行灵活设置。
2.4.2 带有反馈调节的融合推荐 服务质量关乎患者就医体验和满意度,是患者就医选择决策的重要激励因素[54]。仅关注相似度的专业推荐方案可能会推荐服务质量较差的专家,影响患者就医体验和感知质量,因此,提出兼顾专家专长相似性和服务质量的融合推荐方法至关重要,既能满足患者的基本需求,也能向患者推荐服务质量高的专家,从而使患者获得优质医疗服务,增强患者满意度和依从性。这也与患者关注的医疗服务质量分类相对应,现有研究将医疗服务质量分为技术质量和功能质量两类,前者主要指与医疗技术相关的因素,而后者与服务交付过程有关[55]。在本文中,技术要素反映为基于专长相似性的专业推荐prof_score,功能要素反映为基于服务质量的效用推荐qos_score。
反馈是需求与服务匹配中闭环控制的重要环节。融合推荐将专业推荐策略、效用推荐策略和反馈机制纳入同一框架,实现推荐模型的闭环调整优化,增强其可解释性及自适性。本文的反馈机制包括患者反馈和结果反馈,患者反馈又进一步划分为主观反馈和客观反馈。主观反馈是指患者在得到推荐结果前对不同推荐方式的偏好反馈,即根据患者主观反馈调整患者对专业推荐策略和效用推荐策略之间的偏好关系,以优化推荐排序,使推荐结果关注权重更高的内容,形成可解释性推荐策略。在对推荐指数进行规范化处理后,将上述推荐指数进行线性融合,具体表示为
式中:prof_score′=prof_score/prof_scoremax;ωp和ωq分别为患者对专业推荐策略和服务质量的偏好权重,满足ωp+ωq=1。在具体应用中,可以借助简单的问题询问患者的推荐偏好来降低计算复杂度和时间,进而将患者偏好转换为对应的数字。
客观反馈是指患者在服务完成后的事后评价反馈,患者根据服务过程中的感知质量对医疗服务作出评价,即患者感知效用值,体现了患者对医疗服务和专家的满意度,是对专家客观QoS(Quality of Service)值的反馈调整。如qos1,j,qos2,j,…,qosm,j是m位患者对专家Sj的综合客观QoS评价值,患者Pi在服务完成后作出qosi,j的反馈评价,通过患者反馈进一步调整更新专家Sj的客观QoS值为
经标准化后转换为患者感知反馈效用指数为
式中,qosmax为所有专家的最高评价值。
最后,基于患者客观反馈更新专家QoS值,并在服务完成后,基于结果反馈同步更新专家的活跃度和兴趣度,形成带有反馈调节的远程医疗专家自适化推荐模型,实现推荐模型的动态闭环调整优化,在考虑患者偏好的基础上,为患者推荐相关且活跃的会诊专家。
3 实验与分析
3.1 样本选择与预处理
本文的临床试验数据从国家远程医疗中心获得,其依托郑州大学第一附属医院展开运营;专家简介信息从“好大夫在线”平台爬取,作为补充数据刻画专家长期知识背景。医疗机构行政部门设置不同会导致科室划分的差异,引起申请医生对申请科室的不确定性和模糊性,且内科和外科是医疗领域两大科室,门类多样且交叉、数据量大。因此,本文不考虑科室的具体分支,选取内科和外科两个部门的业务数据作为实验数据进行分析。首先,根据郑州大学第一附属医院官方网站公布的科室分布情况,将具体科室划分为内科医学部、外科医学部、综合医学部、妇产科医学部、老年医学部等12大类;然后,根据研究目的,提取内科和外科医学部两个部门下属医生的会诊数据。为充分保护患者隐私,本文尽可能压缩数据空间,提取了包含会诊时间、诊断结果、专家名称和科室4类属性的数据集,采集2021年全年数据共9 078条,其中,会诊专家252人,患者8 510人,经审查证实了会诊专家与患者的多对多关系。每月会诊量分布情况如图3所示。

图3 会诊量分布情况Fig.3 Distribution of teleconsultations
之后,对采集数据进行预处理操作。将同义疾病名称用医学领域的具体术语进行替换,例如:“呼衰”替换为“呼吸衰竭”,“HBV”替换为“乙肝”,保证数据的一致性;同时,采取2.3节提到的频次统计方法进行缺失值填充,保证数据的完整性;使用Python中的Jieba包进行中文分词,且在分词处理过程中优化搜狗输入法词库中的医学词汇大全来构建用户词典以识别专业医学词汇,如“类风湿性关节炎”“系统性红斑狼疮”的正确识别;在哈工大停用词表的基础上,根据实际情况加入对本文无用的词汇进行停用词剔除,过滤掉无实际意义且对本文分析无用的词、数字和符号等,以支持文本向量化,提升推荐效力。
3.2 实验设计及评价标准
3.2.1 实验设计 通过设计多个对比实验来评估本文所提出方法的性能,这些对比实验主要围绕两个方面展开:①实验验证。主题数量K显著影响LDA 主题模型的聚类效果,统计不同主题数量下的模型困惑度,确定最优主题个数,使LDA 模型建模性能达到最优。②对比分析。将本文所提出的融合策略与传统的基于内容的推荐策略进行性能对比分析,计算患者不同主观QoS反馈和不同推荐项目数量下推荐结果的准确率(Pre@N)、召回率(Rec@N)、相似度(Relevance)、活跃度(Activity)和兴趣度(Interest)。
3.2.2 评价标准 采用Top-N推荐系统中广泛使用的准确率、召回率作为推荐策略性能的评价指标,并通过推荐结果相关性、活跃度和兴趣度的对比分析来检验模型性能。准确率表示正确推荐项目占所有推荐项目的比率,召回率表示正确推荐项目占样本中应检索到项目的比率。两个评价指标的计算方法为:
式中:TP表示正确判别项目;FP表示错误判别项目;FN表示假阴性,即错误项目被推荐。准确率和召回率越高,模型的推荐性能越好。
相关性是指推荐专家诊断的患者与目标患者间的相似性,相似程度越高表明专家越适合为目标患者提供远程医疗服务;活跃度是指专家在远程医疗活动中的活跃程度;兴趣度是指专家对远程医疗活动所表现出的行为兴趣。这3个指标的计算方法可由章节2得到。
3.3 实验及结果分析
3.3.1 参数选择 为获取较优模型,实验需先确定模型参数。对于主题模型,主题个数的取值对建模质量和主题生成十分关键。若直接根据经验给定主题数量,可能导致LDA模型的性能不能达到最优,大大影响推荐效果,因而需采取科学的手段选择主题数量。本文采用困惑度选择主题个数,根据肘部法则选取主题数量,实验结果如图4所示。其中,横坐标表示主题个数,纵坐标表示LDA 模型的困惑度。由图4可以看出,当K=14时,LDA模型的困惑度最低。

图4 困惑度Fig.4 Perplexity degree
对于线性融合模型,主要体现在专家活跃度和兴趣度的融合以及不同推荐指数的融合。不同的权重系数通常导致不同的结果,因此,在具体实践中可将融合系数设为参数,根据应用场景进行灵活设置。此外,由于专家活跃度和兴趣度的融合不是本文重点,为公平起见,本文在实验中遵循两边相等的原则[56]进行融合,即γ1=γ2=0.5。推荐指数的融合系数则通过下文对比实验获得。
3.3.2 对比实验 本实验选取2021年12 月31日的数据集作为测试数据对算法进行测试,并通过不同情境下的对比实验来评估融合推荐模型的性能,若专家简介中包含目标患者疾病标签则视为正确推荐。
(1) 权重系数对融合推荐策略的有效性检验。推荐热度是根据患者投票、医生回复率、口碑和患者满意度等多指标按照一定规则融合计算的结果,能够综合反映医生的服务质量。因此,本文提取好大夫在线的医生综合推荐热度作为各专家的初始服务质量评价值。不同偏好权重ωq下融合推荐模型的推荐性能结果如图5所示。其中,N=10为专家推荐返回结果的个数,pre@10 为推荐准确率,Rec@10为召回率,横坐标表示ωq的不同取值,纵坐标表示百分比。

图5 不同权重偏好下的融合推荐模型性能Fig.5 Performance of the fusion recommendation model with different weight preferences
由图5可以看出,融合方法的推荐准确率和召回率在ωq≤0.4时保持较高水平。随着权重系数ωq的不断增大,推荐结果的准确率和召回率呈整体下降趋势,其中ωq增加意味着患者对服务质量更为重视,削弱了医、患现实背景对推荐结果的影响,进而影响了推荐模型整体性能。因此,在进行专家推荐时不应过分强调患者感知效应。
(2) 推荐结果个数对推荐模型的有效性检验。专家推荐根据患者病历文本的相似性来实施专家推荐,这是典型的基于协同过滤的推荐方法。因此,为检验融合推荐模型的性能,本文采用基于协同过滤的推荐方法作为基准方法。本实验分别对基准方法和本文所提出的融合推荐方法进行建模,通过分析不同推荐结果个数下两种推荐方法的准确率、召回率、相关性、活跃度和兴趣度来评估模型性能。经过上节实验验证,当ωq=0.4时达到最佳实验效果,故在模型对比分析过程中设定ωp=0.6,ωq=0.4。模型在准确率和召回率上的对比实验结果如图6 所示。其中,横坐标表示专家推荐返回结果的个数,即Top-N中N的取值,主纵坐标表示准确率,次纵坐标表示召回率。
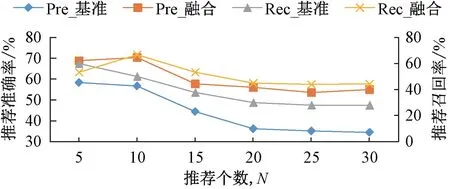
图6 推荐结果的准确率和召回率对比Fig.6 Comparison of Precision and Recall of recommended results
根据准确率的定义,一般情况下,对于同一算法,N取值越大,其推荐结果的准确率越低[24],即准确率随着N值的增加呈下降趋势。由图6 显示,pre_融合>pre_基准,表明融合方法在会诊专家推荐中表现出较高的准确性,能够准确地为患者推荐合适的会诊专家,提高了推荐结果的准确率。同样地,融合推荐方法在召回率上也表现出较高的性能。综上可知,本文所提出的融合方法提高了专家推荐结果的准确率和召回率。
图7所示为基准模型和融合模型在推荐结果的相关性、活跃度和兴趣度上的对比。其中,横坐标表示推荐返回结果的个数,纵坐标反映推荐结果的相关性、活跃度和兴趣度。由图7显示,融合推荐方法的推荐结果在专家的相关性、活跃度和兴趣度上均优于基准模型,表明融合推荐模型能够在保证推荐准确性的基础上,为患者推荐相关且活跃的专家,进一步证实了本文所提出方法的有效性。

图7 推荐结果的相关性、活跃度和兴趣度对比Fig.7 Comparison of Relevance,Activity,and Interest of recommended results
3.3.3 实验结果分析 从数据集中随机选择一患者P0(“上消化道出血,心力衰竭,高血压***”)作为目标患者进行推荐,以验证本文所提出方法的可行性。
首先,对目标患者病历及数据集中所有患者病历进行矢量化表示,并计算目标患者与其他患者病历文本的相似性,结果如表2所示。据此,根据相似性排名取TOP-10纳入推荐集合生成初始推荐专家候选集S={S13,S208,S23,S189,S249,S203,S178,S39,S74,S188}。

表2 目标患者相似性Tab.2 Similarity of the target patient
其次,新注册专家历史记录不足导致其缺乏被推荐机会,本文引入专家长期积累知识,即专家简介作为补充来充分刻画专家知识特征,通过计算新注册专家与候选专家长期知识视图的相似性,更新专家推荐指数并扩展初始推荐专家候选集,以解决新注册专家的冷启动问题。假设将会诊量低于10例的专家定义为新注册专家,根据相似性阈值Simknowledge≥0.7 筛选到5 位相似专家,分别为:S40、S87、S209、S102 和S250。相应地,更新其初始推荐指数为:
进而形成新的推荐专家候选集:S′={S13,S208,S40,S87,S209,S23,S189,S249,S203,S178,S39,S102,S250,S74,S188}。
然后,LDA 主题模型使用数据集中医生诊断过的所有病历进行训练。设置topic=14,迭代次数=500,每个主题下展示前10 个高频词。根据文档-主题分布划分各专家的历史诊断记录,根据分布相似性寻找系统中可能存在的其他符合目标患者需求的专家。部分结果如表3所示。

表3 专家间主题相似性(部分)Tab.3 Similarity of topic distribution among specialists (partial)
最后,将专家活跃度和兴趣度纳入推荐系数,依据会诊频次拟合专家兴趣衰减系数,并根据会诊时间和频次计算专家活跃度和兴趣度,同时考虑患者感知效用,进而构建远程医疗专家推荐模型,通过计算得到最终推荐结果为:{S23,S13,S241,S2,S68,S39,S100,S141,S178,S95},其中融合系数为:ωp=0.6,ωq=0.4。
本文所提出方法成功为目标患者推荐了10位远程医疗专家。经审查,这10 位专家在治疗消化道、胃肠、心血管等领域具有丰富的临床经验,符合目标患者治疗需求。同时,推荐结果实现了专长相似性、专家兴趣度和活跃度及患者效用反馈的有机融合,共同作用于推荐结果的可接受性:例如:专家S23在相似性和积极性上略低于S13,但其推荐热度为4,使其在患者良好反馈的助力下得到优先推荐;同时,S13和S2虽然被优先推荐,但其推荐热度低于S68和S141,其在较高的相似性和积极性的推动下被优先展示。再者,目标患者原会诊专家S39也在最终推荐列表中。此外,对比发现,最终推荐结果与前两阶段推荐专家候选集均存在一定差异,也验证了专长相似性、专家兴趣度和活跃度及患者感知效用共同作用于推荐结果的可接受性。以S102为例,新注册专家未出现在推荐列表中,可能因其患者反馈较差,生成较低推荐指数,进而导致其在推荐列表中位次降低,而在其他策略中,如ωp=0.9,ωq=0.1,S102得到了推荐。这说明,新注册医生在缺乏会诊历史记录情况下已经得到了推荐,本文所提出方法在一定程度上解决了冷启动问题,增加了新注册专家的被推荐机会。上述证据验证了本文所提出方法的可行性和有效性,能为目标患者推荐满足需求且具有较高积极性的远程医疗专家,进而提升推荐效力。
为进一步检验融合推荐模型性能,本文分别采用基准模型和融合模型为目标患者推荐专家,产生两组推荐结果。之后,根据推荐结果制作问卷进行实地调查以评估推荐结果与目标患者的适切度。问卷内容包括目标患者病历描述及两组推荐结果的合理性评估,并采用Likert 5级量表进行评分,1~5分别表示非常不合理~非常合理。将调查问卷发放给国家远程医疗中心4位长期从事远程医疗调度工作的医疗人员,其结合实际并根据自身工作经验对两种推荐结果进行适切度评分。评分结果如图8所示。
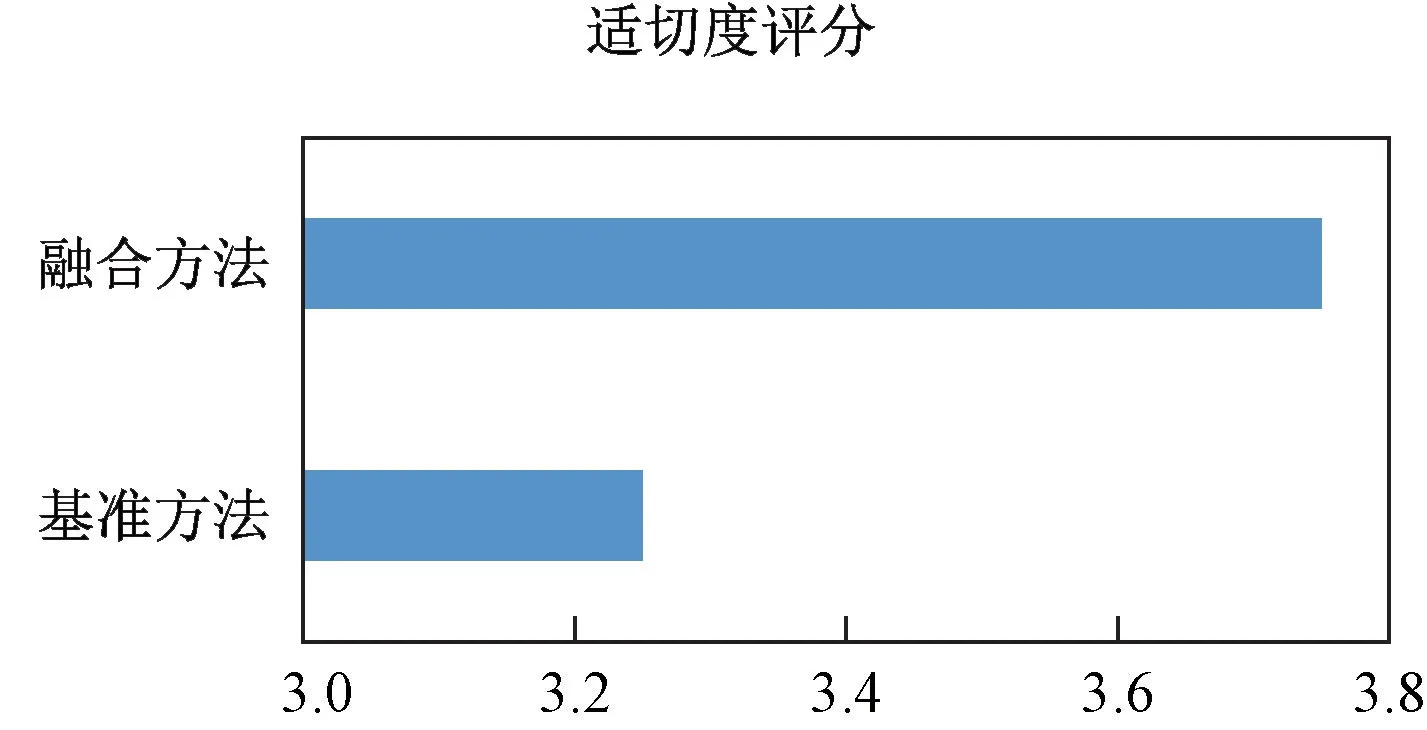
图8 两种推荐方法的适切度评价Fig.8 The rationality evaluation of the two recommendation methods
由图8可见,在适切度评价上融合推荐方法优于基准方法,足以证明融合推荐方法的推荐医生列表比基准方法的推荐列表更合理,更能满足患者的疾病及其就诊需求。
多组实验验证了本文所提出推荐方法的有效性。①能够为患者推荐相关且在远程医疗服务过程中具有较高积极性的专家,满足患者个性化需求,提供智能化的个性化服务;②通过对专家会诊时间和频次的挖掘,分析专家的兴趣度和活跃度,识别其对远程医疗的态度,以对优质医疗资源进行合理化配置;③可以缓解专家推荐中的冷启动问题,提高新注册专家的被推荐机会,使有能力、具有较高积极性的新注册专家不囿于匮乏的历史记录,实现了患者需求和专家服务能力的有效适配。总之,本文所提出方法能够在考虑患者个性化需求的基础上确保推荐结果的准确性和相关性,同时也保证推荐的专家对远程医疗具有较高的活跃度和兴趣度,进而提高远程医疗效率和服务质量,促进远程医疗的可持续发展。
4 结语
本文在隐私保护的前提下,提出了一种带有反馈调节的远程医疗专家自适化推荐方法,借助个性化推荐技术为患者筛选合适的专家,降低患者搜索成本,确保医疗服务价值的有效实现。本文分别面向患者电子病历和专家长短期知识进行患者和专家的特征建模,并通过特征交互计算得到专家推荐指数,其中通过专家长短期知识的相互补充和印证相对全面地刻画专家特征,并根据专家长期知识的相似性建立专家之间的知识关联来更新新注册专家初始推荐指数,缓解冷启动问题。同时,将专家推荐指数与专家活跃度、兴趣度及患者效用反馈纳入同一推荐框架,实现推荐框架的反馈调节和自适更新,在考虑专家行为变化的基础上,使推荐结果分布向最近、最频繁的专家倾斜,并在考虑患者偏好的同时强调结果反馈,使推荐更具可解释性和时效性,进而提升推荐能力。本文借助远程医疗真实案例数据进行实验分析,实验结果验证了所提出方法的有效性及其在数据稀疏性和隐私保护前提下的可操作性,对远程医疗个性化推荐和医患匹配理论及实践具有以下管理学启示和意义:
(1) 多源数据的相互补充能够较为全面地刻画背景信息,在解决推荐系统中冷启动问题的同时支持管理决策。面向专家长、短期知识背景的特征建模,即在短期知识(历史诊断数据)的基础上辅以专家长期知识(个人简介),实现了专家长、短期知识的相互补充和印证,能够更为全面地刻画专家知识领域,尤其是对于缺乏历史诊断数据的新注册专家,通过对专家间长期积累经验的相似性挖掘,增加了新注册专家的被推荐机会,在一定程度上缓解冷启动问题。
(2) 推荐结果质量除受需求影响,也与被推荐者个体行为因素有关。专家活跃度及对远程医疗的兴趣会随时间发生变化,通过动态衡量专家在远程医疗服务中的活跃度及兴趣度,使推荐结果分布向最频繁、最活跃的专家倾斜,增强推荐模型的时效性,进而提高匹配成功率和推荐能力,提升服务效率和质量。
(3) 反馈机制实现推荐模型的闭环调整优化,提升推荐模型的自适性与可接受性。基于患者主观反馈调节不同推荐方式的关系,基于患者客观反馈动态调整感知效用,并通过结果反馈动态调整专家行为属性,在满足患者偏好的基础上提高了推荐模型的可解释性、时效性与自适性。同时,本文所提出方法减少了大量额外信息的提交,压缩数据空间,解决了数据稀疏性和隐私保护问题。
(4) 该方法能够为远程医疗实践提供参考,完善远程医疗平台建设,进而促进远程医疗的可持续发展。该方法同样适用于在线健康问答平台及评审专家推荐系统,考虑专家的兴趣领域及其随时间的变化,能够为专家推荐相关的问题或符合兴趣领域的评审稿件,提升推荐的合理性,保证工作效率和效果。
本文研究存在一定的局限。本文重点关注专家服务能力与患者服务需求之间的匹配而忽略了等待成本,今后研究需结合专家排班调度展开进一步的研究。未来研究还可审查专家能力与患者选择之间的因果关系,考虑属性之间的相关性,以构建更精准的专家推荐模型。
猜你喜欢
军事文摘(2022年20期)2023-01-10
数学物理学报(2022年5期)2022-10-09
计算机应用(2022年2期)2022-03-01
英语文摘(2021年11期)2021-12-31
河北画报(2020年8期)2020-10-27
学生天地(2018年19期)2018-09-07
浙江大学学报(工学版)(2016年2期)2016-06-05
宠物世界·猫迷(2016年3期)2016-04-23
少儿科学周刊·少年版(2015年3期)2015-07-07
俄罗斯问题研究(2013年1期)2013-03-11
