
基于空间数据挖掘的巡游巴士路径规划与推荐
2023-10-13 08:57刘洪宇
城市公共交通 2023年9期
刘洪宇 渠 华
(郑州天迈科技股份有限公司,郑州 450000)
引言
在城市生产生活中,公交出行在满足市民日常出行需求、改善交通状况和环境质量方面扮演着重要角色。当前,公众出行服务的格局正在发生深刻变革,公交企业需要通过智能化技术手段,在为乘客提供个性化、便捷化的高品质服务的同时,提高公交服务的运营效率,促进城市公共交通的高质量发展。
可以认为,需求响应式公交需要解决两个方面的问题,一是出行需求的空间覆盖,解决有没有公交的问题;二是出行需求的时间覆盖,解决即时出行的问题。本文重在解决第一类问题。公交线路的布设可以抽象为线路规划问题,以迪杰斯特拉为代表的最短路径算法、以群体智能算法为代表的启发式搜索[1-3]和以Q-learning 为代表的强化学习算法是3 类主要的路径规划算法。其中强化学习算法以其强大的环境探索能力成为众多领域的研究热点。在水上路径规划领域,王程博等[4]采用Q-learning算法,基于自定义分段奖励函数构建了船舶避障并到达目的地的仿真系统;卫玉梁等[5]基于Q-learning算法,采用函数拟合能力较强的RBF(Radial Basic Function)函数对动作价值进行逼近,从而完成智能车辆在行动过程中的避障。彭理群等[6]在公交路径规划中基于Q-learning 算法,综合考虑道路拥堵情况、站点客流人数等进行奖励函数的设计,确定了定制公交线路的规划方法。
由以上可知,Q-learning 算法在公交领域的应用,倾向于行驶过程中的避障,并不太关注行驶过程中的奖励情况,这在公交领域并不特别符合实际情况[7-8]。本文在考虑公交线路结构特征、途经道路特征和周边环境的基础上,设定Q-learning 算法的奖励规则,实现需求响应式公交线路的规划。
1 相关工作
1.1 强化学习
强化学习(Reinforcement Learning,RL)是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中,通过学习策略达成回报最大化或实现特定目标的问题。强化学习算法在一定程度上具备解决复杂问题的通用智能。其在路径规划、游戏AI 等领域有着广泛的使用场景和应用前景。
不同于一般意义上的路径导航,巡游巴士是没有终点或者目的地的。抽象到基于强化学习的路径规划场景下,即智能体活动没有明确的结束条件,智能体能够到达任意位置,这等价于智能体从任意位置出发,最终出现在起始点。结合Q-learning 算法,对其核心过程描述如下:
(1)初始化Q 表和R 矩阵。分别表示车辆从当前路段行驶到下一个路段的预期收益和即时奖励。
(2)确定寻路的终点target,该场景下为车辆的出发点。
(3)在图中随机起点source,不同于target。
(4)确定source 的邻居节点nears,如果nears不存在,回到步骤2。
(5)生成随机变量alpha,比较alpha 和预设值greedy,如果alpha <greedy,选择奖励值最大的节点作为下一个节点,否则,从nears 中随机选择一个节点,记为next。
(6)基于source →next 通行人数,确定奖励值R(s, n)。
(7)确定next 节点到邻居节点的最大Q值,记为max(Q(n, *))。
(8)根据式(1)更新source →next 的Q值:
如果next 为target,本次寻路完成,回到步骤2,进行下一次寻路;如果next 不等于target,令source=next,回到步骤3,寻找下一段路径。
(9)如果到达预设的训练次数或者Q不再变化,停止训练过程。
(10)根据以上迭代过程,确定图中各个边的权重,然后参考最短路径或者根据每个节点最大出行方向得到图中各个点到target 的最优路径。
Q 表可以初始化为零方阵,真正影响算法结果是奖励的设置,即R 矩阵。
1.2 车辆巡游
巡游巴士在行驶过程中的驾驶行为、所经道路周边环境都会对驾乘人员和运营效益产生重要影响。本方法从线路属性、所经道路等级、周边POI(兴趣点)分布等方面综合提取巡游巴士行驶特征,从而完成路径规划。其整体思路如图1 所示。
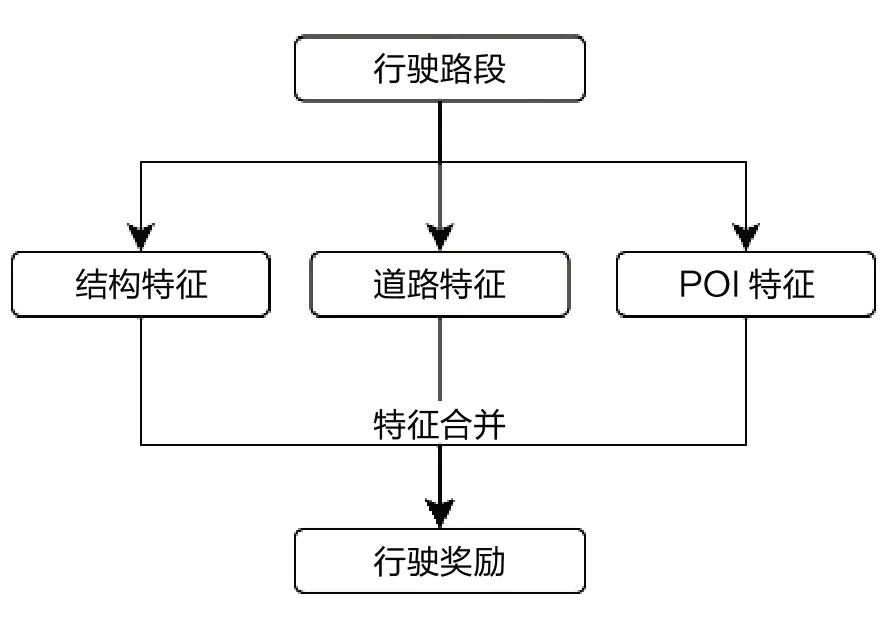
图1 行驶奖励计算示意图
1.2.1 线路结构属性
线路结构及属性是巡游巴士运营效果最直接的影响因素。比如线路长度、公交站点数量、公交站点类型(港湾式、半港湾式等)等;另外,线路的转弯次数以及对应的转弯类型(左转、右转等)都对巡游巴士的运营和体验有影响。
1.2.2 所经道路情况
一般的,公交线路所经过路段的等级(主干道、次干道等)、车道数以及公交专用道的设置情况都会对公交线路通行的难易程度产生影响。在大型、特大型城市,随着公交都市建设以及公交优先理念的影响,在道路条件具备的情况下,公交专用道设置较为完善,具体表现为,主干道和次主干道都有对应的BRT 车道或公交专用道,而其他城市公交专用道较少设置。
1.2.3 周边POI 分布
医院、学校、商圈等区域人员流量大、交通情况复杂,对巡游巴士运营同样有着较大影响,比如高峰堵车通常都发生在这些区域。所以这里提取线路周边重点类型POI 数量,从而量化POI 对巡游巴士路径选择的影响。比如,以线路为中心,分别统计线路周边30m、100m、200m 的医疗单位数量,作为衡量公交班次通行难易程度的特征。
2 算法示例
2.1 数据概况
研究区数据由实际道路抽象得来,其示意图如图2 所示。
道路数据共有路段531 条,道路交叉点317 个。东西走向约11km,南北宽在7km 左右。另有研究区内的POI 数据1 万余条,包括超市、学校、企业单位等各种类型。
对强化学习而言,Q 表是最终结果的体现,而奖励规则的设计是强化学习成功与否的关键。在车辆出行过程中,行驶方向、道路属性、周边环境是考虑的核心因素。
行驶方向:常见的动作包括直行、右转、左转和调头四种类型,在无目的地的车辆巡行过程中,认为直行和右转有更多的选择倾向,而左转和调头因为不利于公交车操作,成为规避行驶方向的可能性更大。
道路属性:常见的城市道路有快速路、主干道、次干道和普通道路,快速路因其无红绿灯设置,通行能力和通行体验都是最好的,一般情况下,可以使用快速路、主干道、次干道、普通道路的顺序为道路的通行体验排序。
POI:兴趣点的类型和多少是构成局部区域交通吸引量的重要因素。学校、商场、工业园区是常见的高吸引性POI 类型。值得一提的是,工业园区的交通吸引量有明显的时间相关性,而商场、公园等时间相关性要弱得多,体现为前者交通吸引量随时间变化较大而后者相对较小。POI 的类型复杂,量化较为困难,这里采用POI 的数量进行衡量。
2.2 实验设计
2.2.1 奖励设置
结合上述描述,从三个角度分别设置奖励函数,研究奖励方案对最终路径的影响。
从表1 可以看出,3 种奖励方案在结构特征上的设置完全相同,在道路特征方面,方案1 与后两者有差异,具体表现为快速道路的奖励值不同,这是为了区别两种不同的行车目的,如以送客优先和以载客优先为目的的行车,因快速道路通行能力强、行车体验佳,方案1 给予最大的奖励取值,而由于快速道路鲜有乘客出现,在后两个方案中给予最小的奖励。在POI特征方面,为了更好地量化该维度特征,对POI 数量进行了处理,其中N表示智能体从当前位置所能到达的所有路段周围的POI 数量总和,n表示当前路段周围的POI 数量。值得一提的是,方案3 对POI 数量奖励进行了放大,目的是确认通过调整奖励,来引导出行路线或者加快算法收敛。

表1 奖励矩阵设置方案
2.2.2 Q 表更新
Q 表的更新是以Q-learning 为代表的值迭代强化学习算法的重要过程。根据强化学习的算法流程,核心的更新公式如下:
式中: 表示从路段s到路段t的综合奖励,Reward表示即时奖励,即行驶过程中,道路属性、转向和POI 所得到的奖励,α和β分别表示学习率和奖励折扣,实际计算中,两者都取值为0.8。
在指定出发路段的基础上,进行算法的训练。以Q 表与之前步骤的差异(以Q值的相关系数衡量)作为算法终止的条件(如R2>0.95)。分别记录不同奖励方案在不同步骤下的Q 表值,最后基于Q 表,确定奖励最大的出行路径。
2.2.3 结果与讨论
Q-learning 算法训练过程是一个值迭代的计算过程,一般的,其迭代终止条件是Q 表不再发生变化,这对一个较大的系统而言,可能大大降低其训练速度。为了寻找合适的迭代次数,通过多轮迭代实验,分别生成各自不同训练步数下的Q 值,通过Q 表值的相关系数来衡量Q 表的变化情况。图3 记录了以50 轮为步长,当前Q值与之前Q的相关系数平方的变化。
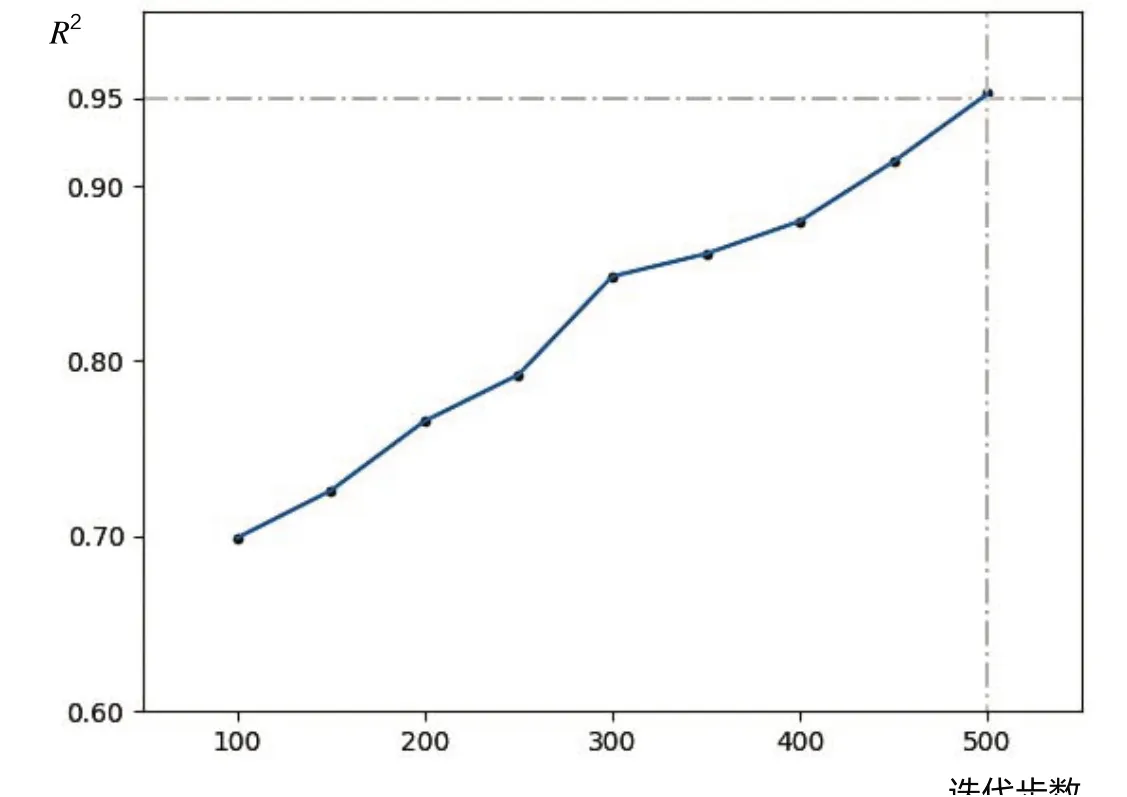
图3 迭代步数与Q 值变化
从图3 可以看出,随着迭代次数的增加,当前Q值与之前Q值的相关系数越来越大,也就是说,Q 表的变化是逐渐变小的,在实验场景下,当前Q值与50 轮之前Q值相关系数的平方在500 步之后,满足退出条件。
奖励方案的不同会影响路径规划结果,图4 展示了三种奖励方案下的路径规划效果。值得提出的是,为了避免路径规划时频繁调头的现象,这里在基于最大奖励获取路径时,禁止回到已经经过的路段。
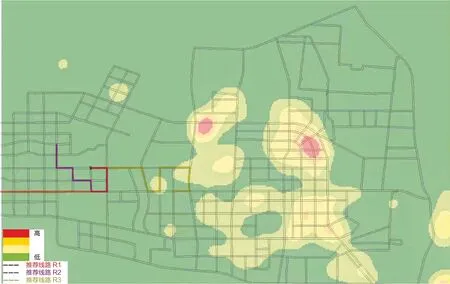
图4 三种不同奖励方案下的路径规划结果示意图
由图4 可知,方案1(紫色路径)在路径生成过程中,右转的现象非常明显,这与奖励方案设置时右转权重最大呈现正相关关系;对于方案2(红色路径),可以看出在常规路段,依然存在右转的趋势,不同于方案1 的是,在主干道上能够保持直线前进;对于方案3(黄色路径),可以看出路径是向着POI 集中区域延伸的。综上可知,奖励方案会影响强化学习路径的规划结果,可以通过调整奖励方案,为多种出行目的打造对应的路径规划方案。
3 总结
本文基于GIS 数据分析和挖掘确定巡游巴士的路径规划奖励方案,采用Q-learning 算法,对比了不同奖励方案的路径规划结果。实验结果表明,可以通过设置不同的奖励机制,来影响算法的路径规划效果。
猜你喜欢
家居廊(2022年12期)2023-01-05
儿童时代·快乐苗苗(2022年11期)2022-12-12
工会博览(2022年5期)2022-06-30
环球时报(2022-04-18)2022-04-18
中国慈善家(2021年5期)2021-11-19
中国交通信息化(2021年2期)2021-07-22
文苑(2019年20期)2019-11-16
建材发展导向(2019年11期)2019-08-24
宝藏(2018年1期)2018-01-31
