
基于联合聚类的国家风险集成预测方法研究
2023-10-13 10:57李建平袁佳鑫尚书凡
中国石油大学学报(社会科学版) 2023年5期
李建平,袁佳鑫,尚书凡,郝 俊
(中国科学院大学 经济与管理学院,北京 100049)
一、引言
国家风险是指在国际资本流动中当事人所面临的、因特定国家层面的事件引发的目标国“不能”或“不愿”履行国际契约,从而造成当事人利益损失的风险。[1-2]由于地缘政治与国家安全冲突不断加剧,全球动荡源和风险点显著增多,各种固有和新生、一国内部和跨国联动的风险相互交织,国家风险传染速度更快,传染路径更加复杂[3-5],这无疑给国家风险预测带来了严峻的挑战[6]。作为企业跨国投资面临的重要宏观风险,国家风险的变化趋势将直接影响企业、机构和个人的投资决策。[7-8]因此,科学准确地预测国家风险的变化趋势对于保障跨国企业海外投资以及国际投资者资产安全具有重要的意义。
目前,国家风险预测模型主要分为传统的计量模型和人工智能模型两类。国家风险的诱因复杂性与多变性使得传统计量模型如ARIMA(Autoregressive Integrated Moving Average)、GARCH(Generalized Autoregressive Conditional Heteroskedasticity)、指数平滑、线性回归等,难以有效刻画国家风险的波动特性,从而导致模型精度较低。随着信息技术与人工智能的快速发展,以神经网络模型为代表的机器学习方法往往具有较强的非线性特征提取能力而被广泛关注和应用。[9-10]例如,汤铃等[11]利用分解集成方法对主要能源输出国的国家风险进行预测研究;Li等[12]利用分解重构方法对国家主权风险进行预测建模。相较于单一模型而言,集成学习将多种单体模型进行有机融合,充分挖掘不同模型的特性与优势,能够有效降低单一预测模型所带来的系统性偏差。例如,Yuan等[13]提出一种基于线性模型、机器学习模型和深度学习模型的集成预测方法,通过简单平均、最佳均值、修剪平均以及聚类均值的方式进行模型集成,结果验证了集成模型预测性能的优越性;Hao等[14]提出了一种基于多目标规划的动态集成预测模型对价格波动风险进行预测,结果表明其所提出模型显著优于单一模型和其他集成模型,进一步证明了集成学习是有效的预测工具。
对于集成学习而言,集成策略对预测结果具有显著影响。在早期研究中,简单平均法由于操作简单且便于计算而被广泛采用。然而,该方法对所有单体模型赋予相同的权重,无法有效发挥表现优异的模型的贡献。[15]为了充分提取单体模型的信息、发挥集成学习的优势,基于单体模型表现赋权的集成建模成为趋势,也受到越来越多的关注。基于“物以类聚”的思想,本文提出了基于聚类策略的国家风险集成预测方法。以聚类策略实现单体模型的集成,可以充分挖掘数据本身的潜在结构,在一定程度上避免了因权重分配不当而导致的误差。[13]聚类策略的运用使异常值的影响在一定程度上被消除,且每个预测模型都被分配了适当的权重,能够有效提升集成模型的预测精度和稳健性。此外,在众多聚类算法中,BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)联合AP(Affinity Propagation)聚类方法具有较高的执行效率和准确性。为此,本文构建了基于BIRCH-AP联合聚类策略的国家风险预测模型,以期有效提升预测模型的精度,实现精准的国家风险预测预警。
二、模型方法
(一)单体模型
为了避免备选单体模型同质化导致的集成预测模型失效的问题,本文选取了8种不同类型的单体模型作为备选模型。具体来说,这8种单体模型分别是:长短期记忆网络、最小绝对收缩选择算子、支持向量回归、贝叶斯岭回归、随机梯度下降、极端梯度提升、LightGBM以及极限学习机。
1.长短期记忆网络
长短期记忆网络(Long Short Term Memory,LSTM)通过遗忘门、输入门和输出门共同控制信息的流动,既能充分解决梯度消失或爆炸问题,又能在一定程度上避免欠拟合的风险。LSTM当前时刻的隐藏层输出ht和内部状态ct由上一时刻的隐藏层输出ht-1、内部状态ct-1以及当前时刻的输入xt协同决定。LSTM用三个门结构来控制信息的流动,遗忘门ft用于设置权重以选择所需保留的信息比重,输入门it用于筛选当前时刻输入的新信息,输出门ot用于从当前内部状态中提取有效信息以产生新的隐藏层,三个门的计算方法分别如式(1)—式(3)所示。
ft=σ(Wt·(ht-1,xt)+bt)
(1)
it=σ(Wi·(ht-1,xt)+bi)
(2)
ot=σ(Wo·(ht-1,xt)+bo)
(3)
式中:Wt、bt分别为遗忘门的权重矩阵和对应偏置项,Wi、bi分别为输入门的权重矩阵和对应偏置项,Wo、bo分别为输出门的权重矩阵和对应偏置项。
(4)
(5)
ht=ot⊗tanh(ct-1)
(6)
2.最小绝对收缩选择算子
最小绝对收缩选择算子(Least Absolute Shrinkage and Selection Operator,LASSO)通过构造惩罚函数压缩回归系数获得一个较为精炼的模型。相较于其他回归方法,LASSO模型更易于解释,在小部分输入变量有效而其他输入变量系数接近于零时表现出色。相关系数通过最小化L1范数惩罚项拟合公式得到,如式(7)所示。
(7)
式中:λ为调节参数。
3.支持向量回归
支持向量回归(Support Vector Regressor,SVR)具有容错性好、鲁棒性高、泛化能力强的性质。当样本线性不可分时,可将样本从原始空间映射到更高维的特征空间,使得样本在高维特征空间内线性可分。令φ(x)表示将x映射后的特征向量,对应划分超平面如式(8)所示,求解式(8)可得式(9)和式(10)。
f(x)=wTφ(x)+b
(8)
(9)
(10)
式中:k(xi,x)为核函数。
4.贝叶斯岭回归
贝叶斯岭回归(Bayesian Ridge Regression,BRR)是结合贝叶斯线性回归和岭回归两种模型优势的预测模型。贝叶斯岭回归在参数估计时引入正则项,得到参数的后验分布,对含异常值的时序预测任务表现良好。贝叶斯线性回归函数如式(11)所示,其目的是求解能使式(11)最小的参数向量分布式(12)。
(11)
(12)
式中:n为样本空间维度,m为样本容量,w为参数向量,ψ(x)为输入向量的非线性函数。
观测值分布t是以y(x,w)为均值的高斯分布,t的类条件概率密度函数为式(13),w的先验概率为式(14)。
(13)
(14)
根据贝叶斯规则,则得到式(15)和式(16)。
(15)
(16)
式中:p(w|t)为后验概率,c为常数,先验概率对应岭回归中的L2正则项。
5.随机梯度下降
随机梯度下降法(Stochastic Gradient Descent,SGD)是求解最小二乘问题的迭代方法。该方法是对梯度下降法的改进,其在每次更新参数时仅选取一个样本来计算梯度,可逐步求解损失函数最小值,从而得到模型参数。参数更新公式如式(17)所示。由于每次更新参数仅需计算一个样本梯度,因此SGD训练速度快,在样本量很大的情况下可能只需部分样本就能迭代到最优解。
θt+1=θt-η·θtJ(θ;(xi,yi))
(17)
式中:(xi,yi)为随机选取的样本。
6.极端梯度提升
极端梯度提升法(eXtreme Gradient Boosting,XGBoost)是由GBDT改进而来的串行提升算法。利用不同的分类回归树训练弥补前一次训练后模型存在的不足,同时对损失函数做泰勒展开并添加正则项防止过拟合,最终将每次训练产生的结果进行加和得到最终预测值。
7.LightGBM
LightGBM是一种高效并行计算的梯度提升框架,其在GBDT的基础上使用基于Histogram的决策树优化算法,降低了时间复杂度;同时又采用带深度限制Leaf-wise的叶子生长策略,提升了训练效率。
8.极限学习机
极限学习机(Extreme Learning Machine,ELM)模型是一种包含输入层、隐藏层和输出层三层结构的单隐藏层前馈神经网络学习算法。相较于其他神经网络模型需要人为设置大量训练参数,ELM只需要设置网络的隐层节点数,是一种简单易用且有效的机器学习算法。传统的神经网络学习算法(如反向传播算法)由于人为设置了大量的训练参数,容易产生局部最优解;而ELM不需要在算法执行过程中调整网络的输入权重,具有学习速度快、泛化性能好的特点。
(二)集成预测框架
1.联合聚类算法
本文引入层次聚类算法BIRCH并嵌套AP聚类的联合方法对数据进行联合聚类分析。首先,利用基于树结构的BIRCH算法在保留数据内在聚类结构的前提下对数据进行多层压缩,并建立一棵聚类特征树;然后,使用AP聚类方法将BIRCH算法得到的各聚类特征结果作为样本点进行聚类,具体如图1所示。

图1 聚类结构
将BIRCH算法和AP聚类方法相结合,一方面,可以使用BIRCH算法避免离群值的干扰;另一方面,与传统的基于层次/密度的聚类技术相比,将BIRCH算法和AP聚类方法结合有利于快速生成较高质量的聚类结果。BIRCH算法利用分层方法实现平衡迭代规划和聚类算法。BIRCH单遍扫描数据集就可以完成聚类,执行效率和准确性较高。AP聚类是通过在样本对之间发送消息,直到收敛来创建聚类。具体而言,AP算法将数据点对之间的相似度作为输入,并同时将所有数据点视为潜在的簇中心,数据点之间交换实值信息,直到逐渐形成高质量的示例集和相应的簇;然后,使用少量有代表性的样本作为聚类中心描述数据集,而这些样本对被认为是最能代表数据集中其他数据的样本。
2.基于联合聚类算法的集成预测模型
本文所提出的集成预测框架如图2所示,具体可以划分为5个步骤。
步骤1:划分集合。为了避免数据泄露问题,我们将全部样本按照80%和20%的比例划分为训练集和测试集,其中,80%样本被视为训练集,其余20%用于测试模型的样本外表现。
步骤2:建立聚类特征树。根据设定的滑动窗口,对给定样本选择合适的数据,使窗口的最后一个数据点为当前待预测点,对于窗口中的数据使用BIRCH进行压缩并建立聚类特征树。
步骤3:选定评估聚类簇。使用AP算法将各聚类特征结果进行聚类,根据最终聚类结果,选取与当前待预测点数据结构相同的簇作为单体模型评估的数据基础。
步骤4:预测表现评价。基于平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)指标,计算各单体模型在预测所选定簇中的各个观察点上的预测表现。
步骤5:集成预测。对比各单体模型在所选定簇中的各个观察点上的表现,选择表现最好的模型作为对当前待预测点集成预测的输出。
三、实证研究
(一)数据描述
考虑到数据的可获取性,本文选取了欧佩克成员国中石油产量较大的4个国家,即沙特阿拉伯(Saudi Arabia)、科威特(Kuwait)、伊朗(Iran)、利比亚(Libya)的ICRG(International Country Risk Guide)数据,以验证所提出模型的样本外预测表现。样本数据时间跨度为:2001年5月—2022年3月,共251个观测点。这4个国家风险评分描述性统计结果如表1所示。此外,我们选择“官僚主义”“内战”“消费者信心”“腐败”“跨境冲突”“政府稳定性”等40个评价指标作为外部变量,具体如表2所示。为了直观展示实验对象,本研究绘制了国家风险评分序列图,如图3所示。由图3可以看出,在样本时段内,国家风险评分具有明显的波动,各国风险波动规律也不尽相同。其中,利比亚ICRG在2014—2016年间有明显下跌,可能是因为在该时段其恐怖袭击多发、政治局势动荡,这也表明ICRG国家风险评分数据的可靠性。
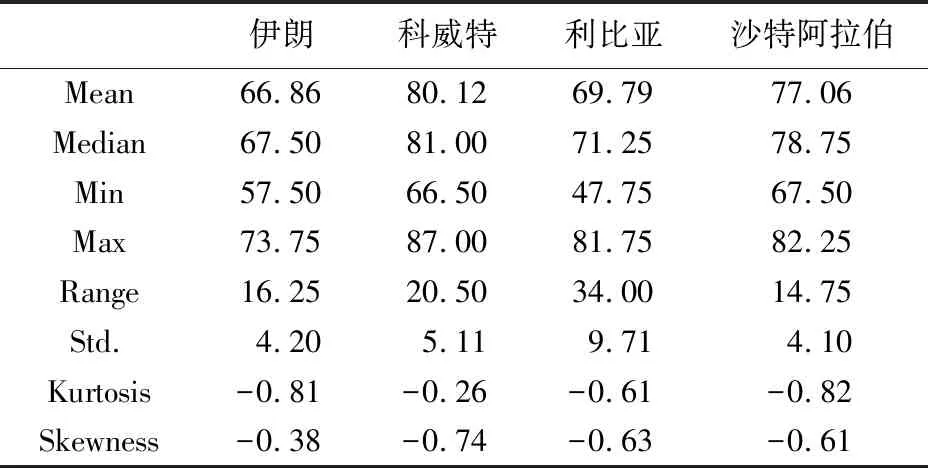
表1 国家风险评分统计结果
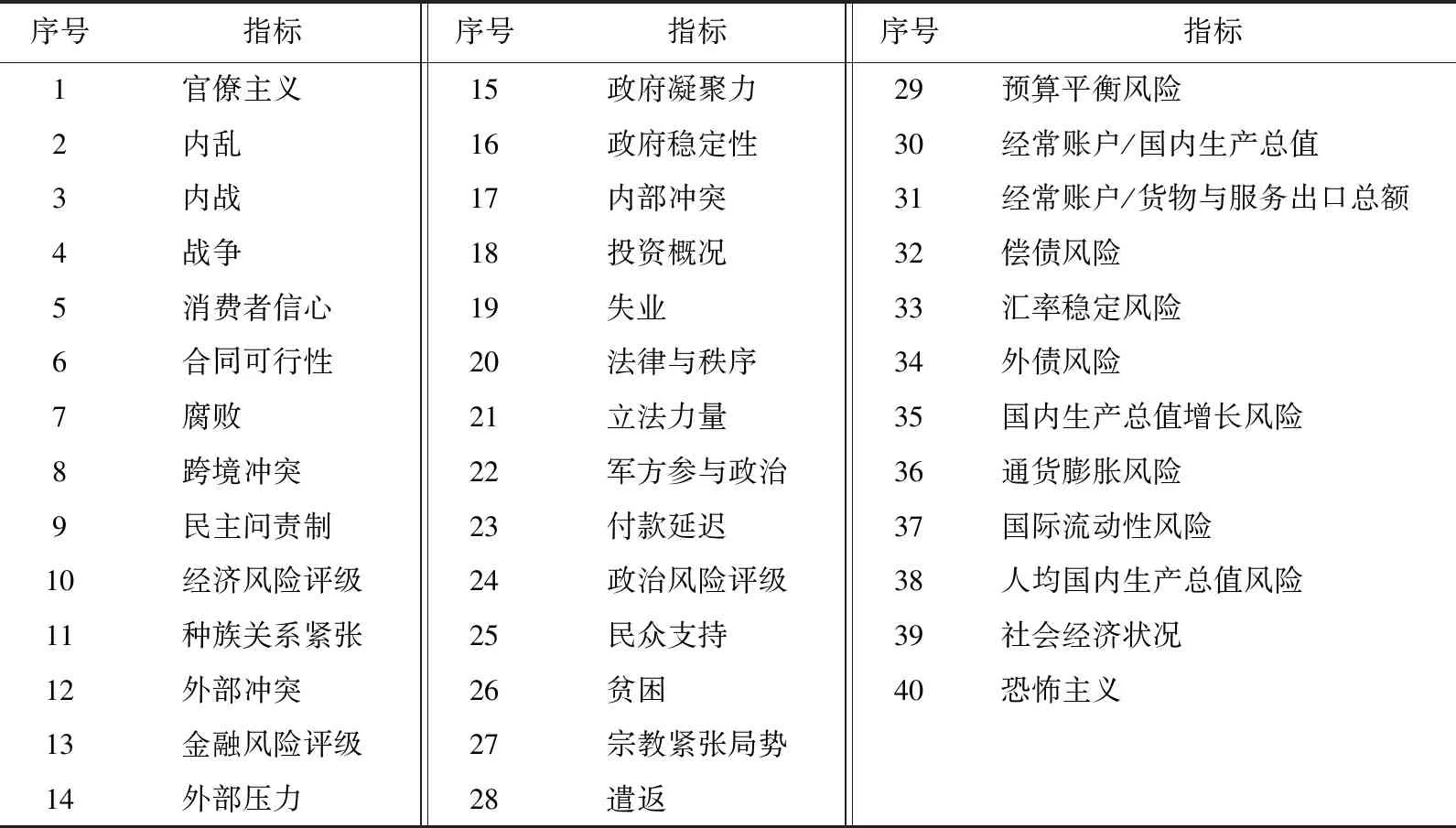
表2 国家风险相关的影响因素清单
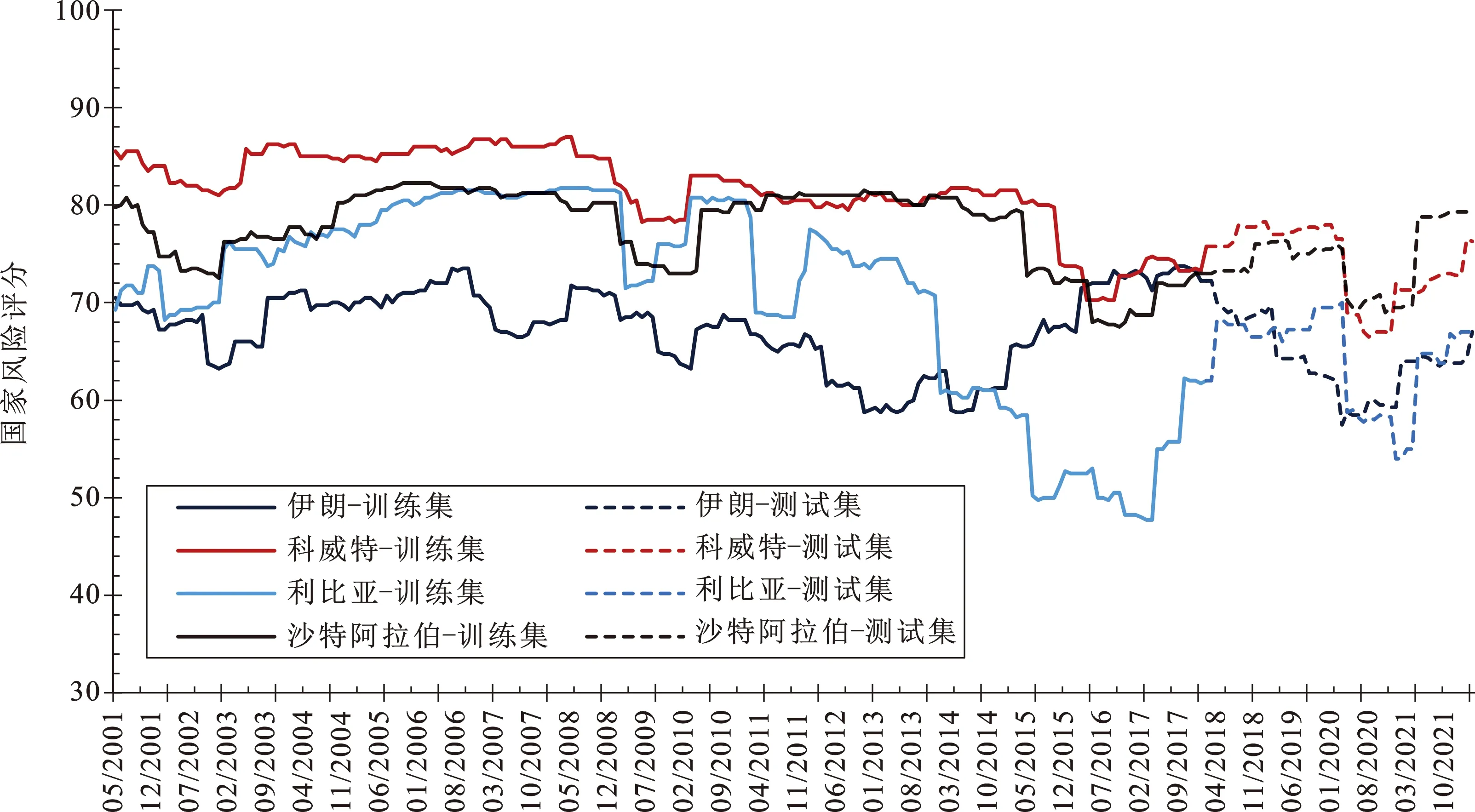
图3 国家风险评分序列
根据ICRG的均值与中位数可知,科威特的国家风险评分最高,然后依次是沙特阿拉伯、利比亚和伊朗。根据标准差和极差结果,利比亚国家风险评分的波动性显著高于其他三国。此外,根据偏度测算结果可知,各国国家风险评分均呈现左偏分布,表明序列中可能存在极小值;峰度测算结果则表明各国国家风险评分数据分布有“宽平台短尾巴”的特征。
(二)参数设置
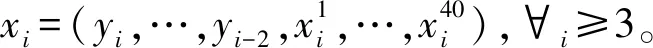

表3 备选模型与参数选择
(三)评价指标
为了更为全面地比较所提出的集成预测模型相较于其他基准模型的表现,本文从水平预测精度和方向预测精度两个方面对预测表现进行评价。为此,本文引入2个评价标准:均方根误差(Root Mean Square Error,RMSE)和方向性精度(Directional Accuracy,DA)。其中,RMSE是水平预测精度指标,DA是方向预测精度指标。具体公式为
(18)
(19)
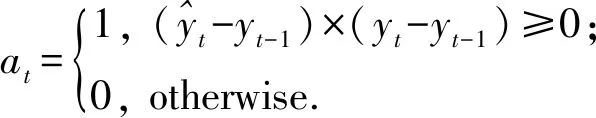
(四)结果分析
为验证所提模型的预测性能,本文选择8个单体模型以及不进行聚类的集成模型作为对比模型,分别计算预测模型在不同提前期下的评价指标结果。以伊朗为例,研究选择具有代表性的4个提前期:1、6、12和24,分别代表一个月、半年、一年以及两年,并计算水平预测精度指标RMSE和方向性预测精度指标DA,结果如表4所示。
由表4可知,所提模型在不同提前期下均具有良好的预测表现,尤其是在长期预测中。其中,在提前期为24时,所提模型的RMSE比次优模型(BRR)降低5.72%,而其DA值则比次优模型(LightGBM)提升16.13%,这表明所提模型具有优异的预测表现。此外,伊朗国家风险预测结果还符合以下规律:(1)从不同指标来看,所提模型在方向精度方面具有显著的良好表现;(2)对比不同模型,所提模型相较于不聚类模型有明显的预测优势;(3)从不同提前期来看,所提模型在较长期时仍能保持较好的预测性能。为直观呈现模型预测效果,本研究绘制了提前期为1时不同预测模型在4个国家的评价指标,如图4所示。综合表4和图4可以发现:所提模型在DA指标上表现出更为显著的优势,这可能是因为集成模型在一定程度上避免了单体模型的预测惯性。将差异化的单体模型通过聚类策略进行集成,有利于降低预测的系统性风险。每次对当前预测点进行不同单体模型的评估与预测,能够避免对历史数据的过度依赖,因此集成策略的使用能有效提升方向性预测精度。
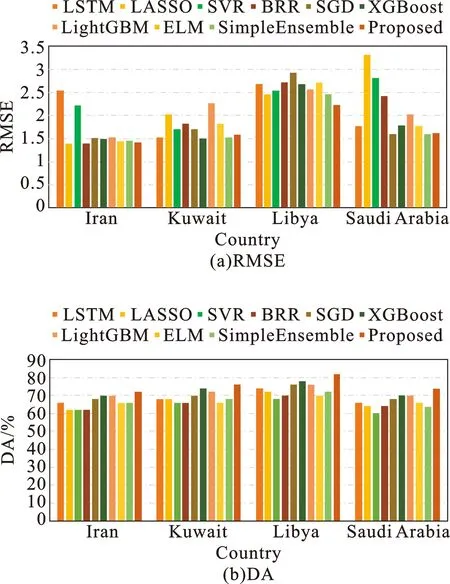
图4 提前期为1时不同模型的预测评价指标结果
此外,为了进一步验证所提模型在预测方面的优势,本文对伊朗、科威特、利比亚和沙特阿拉伯4个国家在不同提前期下进行实验并计算RMSE指标,其结果如图5所示。由图5可以看出,不同提前期下模型预测精度有所波动。整体而言,随着提前期的增加,所提模型的预测优势也愈加明显。同时,所提模型在较长提前期下(2年)表现较好,这说明所提模型能够较好地捕捉国家风险的数据特征与内在规律,其表现不会因数据变化而产生较为严重的劣化,这进一步验证所提模型的有效性。综合图4和图5可以看出,所提模型相较于不聚类模型具有更好的表现,表明聚类集成策略的有效性。通过聚类方法将单体模型进行集成,能够达到“取长补短”的效果,既充分利用了各单体模型的优势,也能规避因各单体模型本身特性所造成的误差,最终达到最优的预测效果。
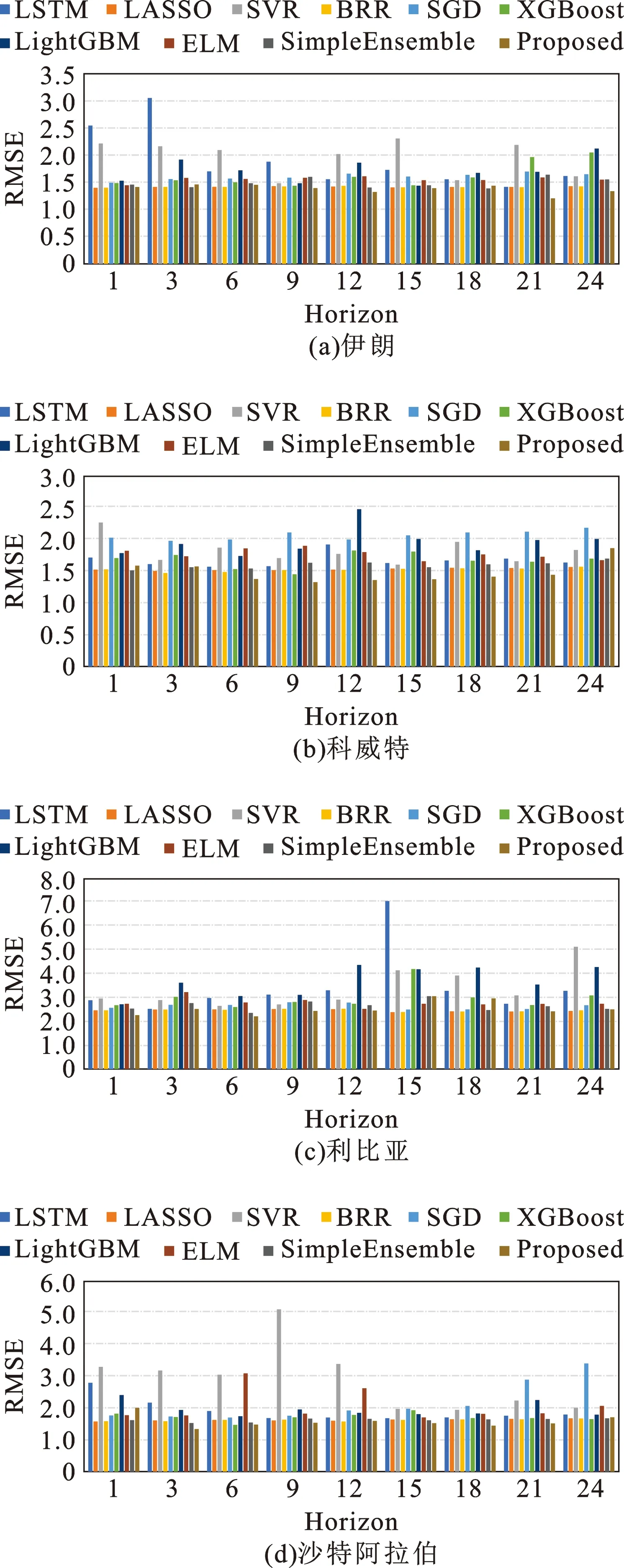
图5 不同提前期下4个国家的预测评价指标结果(以RMSE为例)
四、结语
准确预测国家风险能够有效降低一国在对外贸易中期望收益受损的可能性。然而,国家风险构成复杂、诱因多样,且相关因素往往具有突发性,使得精准预测国家风险面临严峻挑战。为此,本文提出了一种基于BIRCH嵌套AP算法的联合聚类集成预测模型,并基于所提模型及其对比模型在不同国家和不同提前期下进行实验,计算了多个评价指标值以比较模型的预测性能。实证结果表明:所提模型在不同提前期下较对比模型体现出优异的预测表现,尤其在方向性精度上,总体表现出较显著且稳定的优势;所提模型在不同国家中也表现出较高的预测精度,进一步体现了所提模型预测的稳定性;此外,基于聚类策略的集成模型在较长提前期内表现均较好,表明该模型能够较好地捕捉预测时序的数据特征,其表现不会随着数据的变化而产生较为严重的劣化,这进一步证明了所提模型的有效性。
猜你喜欢
电子制作(2018年11期)2018-08-04
中国军转民(2017年7期)2017-12-19
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
测绘科学与工程(2016年5期)2016-04-17
大连工业大学学报(2015年4期)2015-12-11
电子设计工程(2015年6期)2015-02-27
电子设计工程(2015年3期)2015-02-27
中国卫生(2014年10期)2014-11-12
中国神经精神疾病杂志(2014年1期)2014-03-01
