
机器学习辅助非靶向筛查策略用于芬太尼类物质识别鉴定的研究进展
2023-10-15 08:44曹宇奇施妍向平郭寅龙
法医学杂志 2023年4期
曹宇奇,施妍,向平,郭寅龙
1.中国科学院上海有机化学研究所 金属有机化学国家重点实验室,上海 200032;2.司法鉴定科学研究院 上海市法医学重点实验室 司法部司法鉴定重点实验室 上海市司法鉴定专业技术服务平台,上海 200063
1960 年,研究人员发现了一种新型的合成阿片类物质并取名为芬太尼[1]。芬太尼具有比吗啡强100 倍的镇痛作用,最初作为一种良好的镇痛剂应用于手术。然而近些年来,芬太尼类物质的非法滥用问题愈发突出,已经成为一个严重的社会问题[2]。芬太尼类物质具有很强的精神活性作用,操作不当极易过量,造成使用者死亡的后果[3-4]。由于监管政策的日趋严格和检测技术的逐步提升,许多传统的芬太尼类物质已经难觅踪迹。然而,不法分子通过结构修饰、官能团改变等手段不断制造出化学结构不同但具有与芬太尼类似精神活性的化合物以逃避监管[5]。因此,对于芬太尼类物质如何进行快速有效的检测和处置,已经成为目前精神活性物质监管领域的研究热点之一。
目前,对于未知样品中芬太尼类物质的检测主要遵循以下流程。首先,分析人员预先设定一些芬太尼类物质作为检测目标,使用多种手段获取这些物质的标准品在各种检测仪器中的信息。然后,通过各种检测技术如质谱、拉曼光谱、核磁共振(nuclear magnetic resonance,NMR)波谱[6]和红外光谱[7]等倾向性地搜寻样品中与检测目标相关的化合物信息。最后,将得到的谱图与检测目标的标准品谱图进行比对从而完成整个分析过程[8]。这种实验流程整体上基于靶向筛查策略,对于标准品较为依赖,同时需要对目标芬太尼类物质的化学结构有一定了解,比较适用于已知芬太尼类物质的检测分析。然而,快速迭代的新型芬太尼类物质给广泛应用的靶向筛查策略带来了巨大挑战[9]。其一,分析人员对于新型芬太尼类物质的化学结构及各类谱图信息知之甚少,且短期内难以获得合适的标准物质。其二,新型芬太尼类物质经过结构修饰,其化学性质以及在各种检测仪器中的谱图信息都发生了较大改变,已开发的靶向筛查方法难以捕捉样品中这类物质的相关信息。因此,亟须开发新型的非靶向筛查策略更加快速准确地识别未知样品中的新型芬太尼类物质。
近年来,随着计算机算力的大幅提升,机器学习领域发展迅猛[10],尤其是2012年神经网络模型AlexNet[11]以高于第二名将近10%的准确率获得ImageNet 视觉识别大赛冠军后,掀起了各类机器学习模型的研究热潮。迄今,机器学习模型的应用已不再局限于计算机视觉、模式识别、图像分割等经典问题,而是广泛渗透入各行各业的数据分析中,在新精神活性物质筛查以及代谢机制研究领域也有广泛应用[12-14]。相比传统的数据分析手段,机器学习模型最大的优势在于其具有从海量数据中自动提取特定趋势和特征的能力。研究人员在进行分析工作时无需事先根据现有经验对数据做过多的预处理工作,特征提取和模型优化过程都交给机器本身。这一优势在数据量巨大、对数据本身结构缺乏了解或是凭借经验难以归纳出较为显著的数据特征的情况下尤为有效。
与此同时,各种检测仪器的性能指标也有着巨大的进步。以质谱为例,质谱仪器(包括三重四极杆质谱[15]、飞行时间质谱[16]以及线性离子阱质谱[17]等)对于样品检测的灵敏度和谱图采集速度都有着显著的提升[18]。同时,包括超临界流体色谱、气相色谱[19]、液相色谱[20]等在内的色谱分离技术亦有突破,对于复杂样品的分析效率明显提高,单次分析时间缩短,所需样品量也大幅减少。这些技术的进步使得针对未知样品的大规模非靶向数据采集成为可能。研究人员无需事先积累大量经验针对样品设定检测目标,而是通过仪器所提供的非靶向数据采集模式,尽可能多地对样品中所包含的各种化合物信息进行采集[21]。
非靶向数据采集模式带来了样品分析数据量的指数级增长,结合机器学习技术方能高效挖掘其中有价值的信息。本文从新型芬太尼类物质的特点及分类,各种机器学习模型的原理及适用范围,以及机器学习技术在芬太尼类物质数据分析中的应用等方面,阐述目前机器学习辅助非靶向筛查策略用于芬太尼类物质识别鉴定的研究进展,并展望其未来发展趋势。
1 芬太尼类物质的特点及分类
芬太尼类物质的化学结构如图1 所示。以构效关系理论为基础,通过对芬太尼化学结构中的不同部分进行结构修饰,可获得不同类型的新型芬太尼类物质[5,22]。研究人员将芬太尼类似物按照结构修饰位置和类型的不同进行分类[23-24]。
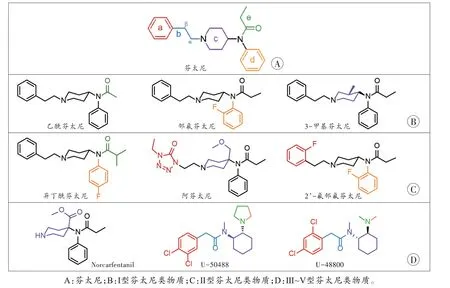
图1 部分芬太尼类物质的化学机构Fig.1 Chemical structure of some fentanyl analogs
图1A 中芬太尼的化学结构被分为5 个结构域。一般来说,新型的芬太尼类物质会对这5 个部分中的1 个或多个位置进行结构修饰。结构修饰位点越多,该物质整体化学结构与芬太尼差异越大,所得各种仪器检测数据与芬太尼相似度越低。根据结构修饰位点数量的差异,将芬太尼类物质分为Ⅰ~Ⅴ型。
1.1 Ⅰ型芬太尼类物质
Ⅰ型芬太尼类物质与芬太尼相比,整体化学结构改变不大,主要从5 个结构域(图1A 的a~e)中选取1 个部分进行结构修饰。图1B 列举了部分Ⅰ型芬太尼类物质的化学结构,整体上在结构域e 处进行官能团修改较为多见,同时结构域a、b、c、d 处也常被修改。Ⅰ型芬太尼类物质由于结构修饰幅度较小,整体药理作用和体内代谢机制与芬太尼类似,同时其在各种检测仪器中得到的数据谱图与芬太尼相似度较高。
1.2 Ⅱ型芬太尼类物质
Ⅱ型芬太尼类物质是对芬太尼的两个结构域进行结构修饰,整体来说结构变化更大。图1C 列举了3 种Ⅱ型芬太尼类物质。与Ⅰ型芬太尼类物质相比,Ⅱ型芬太尼类物质结构修饰幅度更大,但仍然保留了芬太尼整体的分子骨架。在各种仪器中收集的数据谱图与芬太尼相似度较高,具有与芬太尼相似的谱图特征。
1.3 其他芬太尼类物质
随着监管政策的逐步趋紧,针对芬太尼化学结构的修饰幅度愈发增大,从而衍生出一系列Ⅲ~Ⅴ型芬太尼类物质。如图1D 所示,这些化合物虽然以芬太尼为先导化合物,但对芬太尼中多个结构域都进行了大幅的修饰,甚至对芬太尼整体结构骨架进行了改动。许多Ⅲ~Ⅴ型芬太尼类物质的药理作用和体内代谢机制已与芬太尼迥异,且缺乏系统的药理毒理数据,过量使用所造成的健康风险大大增加。另外,这些物质在各种检测仪器中所得数据和谱图与芬太尼相似度较低,已建立的大量分析方法难以应用于此类物质的检测,其骨架结构的变化也导致难以总结出较为通用的经验规律。
2 机器学习模型的原理及适用范围
机器学习是一类算法模型的总称,这些算法模型试图借助计算机强大的算力从大量数据中发现隐含的规律并将其应用于数据分类和预测[10]。机器学习模型通过模型本身拥有的较强的线性或非线性拟合能力以及计算机算力所支撑的迭代优化过程,试图拟合出与实验数据趋势最为适合的函数,从而达到对新样本数据进行准确预测的目的。机器学习模型主要可以分为监督学习模型和无监督学习模型[25],其各自的特点和典型算法如下。
2.1 监督学习模型
监督学习模型通过对已有的训练样本进行训练得到一个最优模型。监督学习对训练数据都进行了标注(即打上已知的标签),而学习模型的训练目标是使模型的输出值尽可能与训练数据的标签达到一致。模型通过反复的训练优化并根据训练数据一步步修正模型输出,最终,模型对于新的未知样本也能给出合理的预测值。
2.1.1 线性回归算法和逻辑回归算法
线性回归是最为基础的机器学习算法之一[26]。在线性回归模型中,将目标值预期看作各个输入变量之间的线性组合。简单来说,就是寻找一个线性函数来建立已知数据中各特征变量与标签值的映射关系,从而较好地对未知数据进行预测。逻辑回归是一种广义上的线性回归模型,算法层面与多元线性回归模型有很多相似之处[27]。最大的不同之处在于所寻找的拟合函数并不直接由输入变量的线性函数决定,而是结合logistic 函数(又称sigmoid 函数)来确定。
线性回归和逻辑回归算法在多类预测问题中均有较好的表现。如2019 年伦敦国王学院的ABBATE教授课题组[28]使用偏最小二乘(partial least square,PLS)回归分析建立了115 种芬太尼类物质与µ-阿片受体之间的定量构效关系模型,为芬太尼类物质的分类和确证提供了新的思路。
2.1.2 朴素贝叶斯分类算法
朴素贝叶斯分类算法是一种以贝叶斯定理为核心、基于概率计算的机器学习模型。在准备阶段确定特征属性并获取训练样本后,算法分别计算每个类别的概率分布并针对每个特征属性计算划分的条件概率,最后根据贝叶斯定理确定样本数据所属类别[29]。
朴素贝叶斯分类算法已经被广泛应用于新精神活性物质的分类筛查工作中,并取得了不错的效果。如2021 年悉尼科技大学的FU 教授课题组[30]建立了针对阿片类物质的非靶向筛查模型,并使用该模型对3 种类型的阿片类物质进行分类,整体分类准确率达89.5%。
2.1.3 人工神经网络算法
人工神经网络算法的发展在最近十年突飞猛进,已经成为机器学习领域研究热度最高的算法之一,并衍生出多个分支,如卷积神经网络[31]、循环神经网络以及生成式对抗神经网络[32]等。如图2 所示,神经网络模型主要包括输入层、隐藏层和输出层,每一层都由多个神经元组成,各层神经元之间通过激活函数和权重系数相连。上一层每个神经元的值通过权重矩阵和激活函数计算为下一层各神经元赋值,在神经网络模型中这一过程被称为前向传播。样本数据中每个特征属性对应模型输入层中的一个神经元。神经网络模型中可根据实际问题需求包含多个隐藏层。经过隐藏层计算,在输出层输出最终分类或回归分析结果。

图2 神经网络模型示意图Fig.2 Schematic diagram of neural network model
神经网络算法在芬太尼防控领域也有诸多应用。2021 年,DE CHOUDHURY 教授课题组[33]构建了一个神经网络模型,根据个体在网络上的发帖行为对其芬太尼滥用的可能性进行预测分析,取得了76%的较高准确性。
2.1.4 支持向量机(support vector machine,SVM)算法
SVM 是一种可靠而优雅的机器学习模型,具有强大的非线性映射能力[34]。简单来说,SVM 的训练过程就是在尝试找寻一个最优的决策边界使得距离两个类别最近的样本相隔距离最远。这一决策边界也被称为超平面,而样本中与超平面距离最近的一些点称为支持向量。虽然近年来随着人工神经网络算法的兴盛,SVM 的研究日趋减少,但SVM 有着坚实的数学基础,同时各种核函数的运用赋予其强大的非线性映射能力,在芬太尼类物质管控领域有着十分广泛的应用[35]。
2.2 无监督学习模型
对于包含标签信息的数据,可使用监督学习模型不断针对样本数据特征与数据标签之间的关系进行拟合,最终得到一个合适的映射函数用于新样本的预测。然而在一些特定情况下,研究人员希望直接通过计算来挖掘数据中隐含的内在联系。无监督学习模型的目的在于对这些未经标注的数据进行分析,挖掘数据本身蕴藏的规律结构[25]。
2.2.1 K 均值聚类算法
K 均值聚类算法于1967 年被提出,其算法思想非常直观:对于样本数据集,计算各样本间距离。根据距离大小,将数据集分割为k个组别,使得每组内的数据点紧密连接(距离最小),而组间距离尽可能的大。K 均值聚类算法应用广泛,在芬太尼类物质数据分析领域也有很好的表现。如2020年,美国国家标准与技术研究院质谱数据中心的WALLACE 教授课题组[23]建立了44 种Ⅰ型芬太尼类物质的电子电离(electron ionization,EI)质谱图相似度数据库,并使用K 均值聚类算法对这些芬太尼类物质按照谱图相似度进行聚类分析。
2.2.2 主成分分析(principal component analysis,PCA)算法
PCA 算法是最为常用的一种数据降维方法,其整体算法思路在于寻找一种线性映射将高维数据在低维空间形成映射关系。PCA 的目的在于寻找一种合适的线性函数,将高维数据投影在低维空间中,并使得数据在所投影的维度中尽可能多地保持高维数据所带有的信息[36]。
PCA 算法的基本流程见图3。数据准备工作与其他算法类似,接着对各样本的所有数据进行中心化操作,计算协方差矩阵C。然后,对于N个特征计算其对应于协方差矩阵C的特征值λ和特征向量u。按照从大到小的原则将特征值λ进行排序,根据设定的新特征数目k(一般为2 或3)选取前k个特征值和特征向量。最终将各个样本的原始特征值投影到所选择的新k个特征中并进行相关可视化分析,就完成了整个PCA 过程。PCA 算法在芬太尼类物质各仪器检测数据分类工作中的应用广泛。如2020 年,MCKEOWN等[37]运用高场(300 MHz)和低场(43 MHz)傅里叶变换NMR 波谱结合PCA 以及正交偏最小二乘-判别分析(partial least square-discriminant analysis,PLS-DA)算法,成功地对使用3 种合成方法得到的芬太尼前体N-苯乙基-4-哌啶酮和4-苯胺基-N-苯乙基哌啶样品进行了分类。

图3 PCA 基本流程示意图Fig.3 Schematic diagram of the basic procedure of PCA
2.2.3 层次聚类算法
层次聚类也是一种应用十分广泛的聚类算法。不同于K 均值聚类,层次聚类不需要选择初始点或预先设定k值。在K 均值聚类中,k值和类别数目这两个参数的设定对于聚类结果会产生巨大影响,需要进行多次优化。层次聚类则对数据点进行一层一层聚类,可以在聚类过程中控制最终的类别数目。层次聚类的核心算法思想在于不断计算各类簇之间的距离(距离计算有多种方法),每一轮聚类将距离最大的两个类簇进行拆分或是将距离最小的两个类簇进行合并。
层次聚类较为灵活,分类结果直观,已广泛应用于芬太尼类物质的谱图分类研究中。如2020 年,英国曼彻斯特城市大学的GILBERT 等[38]使用PCA 结合层次聚类算法对芬太尼类物质的EI 谱图建立自动化分类模型,对于未知芬太尼类物质也有着非常高的预测准确性。
3 机器学习技术在芬太尼类物质识别鉴定中的应用
各种仪器分析技术飞速发展,研究人员仅需少量样品便可获取包含样品化合物信息的海量谱图数据。对这些数据进行合理分析就能帮助研究人员建立更为高效准确的芬太尼类物质识别鉴定技术。此外,机器学习技术的发展日新月异,已成为大规模数据分析的重要支柱。将机器学习技术应用于芬太尼类物质的仪器数据分析工作,将对芬太尼类物质的非靶向筛查、大规模识别鉴定、代谢机制研究以及使用风险评估等领域产生重大影响。
3.1 机器学习结合质谱技术分析芬太尼类物质
质谱分析因其分析速度快、检测灵敏度高以及化合物兼容性广,已经成为芬太尼类物质检测的首选分析方法[18,39-41]。质谱与各种色谱分离技术联用建立了GC-MS[19]和LC-MS[20]等方法,进一步拓宽了质谱分析的应用范围,可以对复杂的实际样本进行自动化的快速分析。GC-MS 一般使用EI对化合物进行离子化[42]。EI 质谱图稳定性高,在不同仪器中重现性高,目前已有专门针对新型精神活性物质的SWGDRUG 质谱数据库。当然,GC-MS 也有其自身的局限性,对于热不稳定或是难挥发性的化合物分析效果不佳。针对这些化合物,使用LC-MS 结合碰撞诱导解离(collision induced dissociation,CID)技术进行串联质谱分析即可得到化合物的特征碎片信息,辅助化合物结构确证工作。
美国约翰斯·霍普金斯大学应用物理实验室的KOSHUTE 等[43]于2022年在Forensic Chemistry上发表了其最新研究成果。研究人员构建了一个有监督机器学习模型以完成通过EI 谱图检测芬太尼类物质的任务。研究人员收集了3 718 个精神活性物质的EI谱图,其中包括195 个芬太尼类物质和3 523 个非芬太尼类物质。接下来,研究人员确定了输入机器学习模型的数据特征。不同于简单地将每个m/z作为一个特征,该课题组对每张EI 谱图都进行了处理,确定了12 个与质谱峰相关的特征和12 个表征谱图整体相似度的特征。质谱峰相关特征包含基峰、平均峰强度和出现最频繁的相邻质谱峰之间的质量差值等,而相似度相关特征主要计算谱图与几种代表性的芬太尼类物质谱图的相似性。模型训练过程遵循了10 倍交叉验证策略,即将所有输入的谱图平均分为10 组,选9 组作为训练数据,1 组作为测试数据(不参与训练过程)。将训练所得的模型应用于测试数据来评估模型性能。该研究共考察了3 种机器学习模型:逻辑回归模型、神经网络模型和随机森林模型。逻辑回归模型采用广义线性回归和二分类模式,而神经网络模型选用了有两个隐藏层的浅神经网络,随机森林模型类似于决策树算法。完成这3 种机器学习模型的训练后,研究人员将所建立的3 种模型和传统的数据库比对算法模型一起进行性能评估。最终,随机森林算法的分类准确性最高。
2020 年,美国国家标准与技术研究院质谱数据中心的WALLACE 教授课题组[23]在Forensic Chemistry上发表了其运用机器学习模型计算谱图相似度对芬太尼类物质进行分类的研究成果。与KOSHUTE 等的研究不同的是,该研究搭建了一种无监督学习模型。对于一系列Ⅰ型或Ⅱ型芬太尼类物质的EI 谱图,该模型能够根据谱图之间的相似度直接对这些谱图进行聚类分析并将聚类结果可视化。该研究表明使用无监督学习聚类分析对于未知分子自动化结构归属具有可行性。接着,研究人员选用了一种新颖的无监督学习算法,即多维尺度变换(multidimensional scaling,MDS)[44]。该算法与PCA 类似,是一种强有力的数据降维方法,能够对各数据样本间的相似度进行空间可视化。其算法思想受到SVM 模型和K 均值聚类算法的启发,整体算法原理在于通过计算成对样本间的相似度,将高维数据映射到一个低维空间中,并尽可能地在数据映射到低维空间后,保持各数据样本之间的相似度与高维空间一致。MDS 算法被用于将各芬太尼类物质的高维EI 谱图映射到二维空间中,得到一张二维相似度聚类分析图。MDS 模型分析能够将芬太尼类物质EI 谱图分为3 个组别,结构修饰位点相似的芬太尼类物质其谱图相似度也越高,在聚类分析图中被划分为同一组别,验证了该无监督学习模型对EI 谱图进行自动化结构预测分类的可行性。最后,研究人员提出了一个根据可疑芬太尼类物质EI谱图推测其化学结构的自动化预测平台。所得可疑芬太尼类物质EI 谱图首先经过一个芬太尼分类器。该分类器包含两个组件:一是通过计算与已知结构芬太尼类物质谱图的相似度来确定与可疑芬太尼类物质最为相近的芬太尼类物质的化学结构,通过阈值设定判断其为Ⅰ型或是Ⅱ型芬太尼类物质;二是使用构建的MDS 聚类模型判断该可疑芬太尼类物质可能的结构修饰位点。最终综合这两项结果给出该可疑芬太尼类物质的化学结构预测。
综合应用多种机器学习算法可以进一步提高分类准确性或完成更加复杂的筛查任务。2020 年,GILBERT 等[38]首先使用PCA 对54 种芬太尼类物质的EI 谱图数据进行降维分析,随后使用层次聚类模型将这些物质分为9 类。所建立的PCA 结合层次聚类模型具有较强的泛化能力,将其应用到67 种芬太尼类物质(未包含在模型训练过程)的分类中,取得了很高的分类准确度。研究人员首先对54 张EI 谱图进行初步的数据整理,包括截取m/z41~352 的质谱信号并将所有信号的m/z取整。去除在所有谱图中强度变化幅度较低的信号,最终保留了176 个m/z作为模型输入特征,并使用R 语言中相应的算法包进行PCA分析。对降维结果进行层次聚类分析。最后,67 种不同结构的芬太尼类物质被用于模型的性能评估。研究人员选用了两种分类标准。第一种,计算每个类簇的中心点坐标,测试化合物被分入距离其坐标最近的中心点所在类别中;第二种,考察距离测试化合物坐标最近的数据点,并将其分入该数据点所在类簇。最终,第一种中心点法整体分类准确率为83.6%,第二种最邻近点法整体分类准确率为91.0%。该研究对于芬太尼类物质EI 谱图的自动化分类、谱图特点以及特征离子的挖掘有重要意义。
机器学习技术不仅能够辅助新型未知芬太尼类物质质谱数据的自动化分类和相似度计算等任务,还能帮助禁毒工作者探索不法分子生产各种芬太尼类物质的各种途径,更加精准地对制毒贩毒行为进行打击。目前已报道了许多芬太尼类物质的合成方法[45-47],不同的地下工厂都有自己的合成工艺,每种合成方法都不可避免地在最后的成品芬太尼中引入一些杂质,研究人员将这些杂质的种类和含量信息称为化学分布特征[48]。通过分析成品中化学分布特征的差异,能帮助研究人员掌握芬太尼样品的合成方式,结合其他信息,最终能够更加精准地掌握毒品的来源和特定地下工厂的分布。通过多种质谱手段如GC-MS、LC-MS等可以灵敏地捕捉芬太尼样品中各杂质的信号,然而在未知杂质种类的情况下对海量质谱数据进行非靶向分析,任务繁重,进展缓慢。近几年,机器学习技术的引入为这一领域的研究带来了新思路[48-49]。
2016 年,美国劳伦斯利弗莫尔国家实验室法庭科学中心的WILLIAMS 教授课题组[48]在Analytical Chemistry发表的研究中,全面评估了6 种已报道的芬太尼合成方式的化学分布特征的区别。研究人员使用GC-MS、LC-MS 以及电感耦合等离子体-质谱(inductively coupled plasma-mass spectrometry,ICP-MS)尽可能全面地捕捉6 种合成方式的化学分布特征信息,结合PLS-DA对海量质谱数据进行处理,确证了160种有机和无机杂质信息并从中找出87 种具有路线特异性的化学分布特征信息。PLS-DA 本质上是一种多元线性回归模型,融合了PCA 的思想。通过PLS-DA模型的使用,研究人员建立了一个能从芬太尼样品中提取化学分布特征信息并对其合成方式进行预测的分析平台。
国内的研究人员运用质谱高通量和高灵敏度的特点,设计出一系列非靶向芬太尼类物质的鉴别分析方法。如2020 年司法鉴定科学研究院施妍研究员团队[24]在Journal of the American Society for Mass Spectrometry上发表的研究成果,分别运用EI 和电喷雾离子源(electrospray ionization,ESI)结合高分辨串联质谱技术分析了25 个新型芬太尼类物质的碎裂途径。既往已开发的GC-MS 和LC-MS 分析芬太尼类物质的方法,只能针对已知芬太尼进行检测分析,且需要标准品对照,对于新型未知结构芬太尼类物质难以分析。通过串联质谱技术的使用,可以发现芬太尼类物质所共有的碎裂模式和特征,从而为芬太尼类物质的非靶向筛查提供基础。通过分析,研究人员在ESI和EI 串联质谱碎裂实验中均观察到哌啶环降解和苯乙基与哌啶环解离两种碎裂模式。值得注意的是,在ESI 串联质谱碎裂实验中还观测到酰胺基团裂解产物。该研究能够对相似结构新型芬太尼类物质的检测定量提供指导。
3.2 机器学习结合光谱技术分析芬太尼类物质
拉曼光谱是近年来广泛应用于化学物质鉴定的光谱技术之一。由于拉曼散射过程与分子结构独特的振动模式有关,因此,拉曼光谱可以提供有关分子键和结构的相关信息,并且能够识别复杂物质中的化学成分。此外,拉曼光谱具有分析速度快、灵敏度高、成本低、操作简单等优点。因此,该技术被广泛应用于分子结构鉴定、精神麻醉药品检测等领域[50-51]。在使用拉曼光谱分析复杂的混合物样品时,获得的光谱数据集极其庞大,往往需要使用各类数据处理方法进行数据的采集、提取、分析等,故机器学习以及人工智能等策略与拉曼光谱技术相结合逐渐被应用于各领域内分析物的鉴定。
近年来,表面增强拉曼散射(surface-enhanced Raman scattering,SERS)技术迅速发展。该技术与机器学习算法结合,在药品鉴定、毒物分析领域得到了广泛应用[52-53]。目前,通过使用SERS 技术结合PCA、SVM 手段,研究人员能够较好地对羟考酮、海洛因、四氢大麻酚和可卡因等毒品进行区分,并在一定程度上展现出定量分析的潜力[54]。在检测比较复杂的体液样品时,将PCA 与SERS 相结合能够高效分析唾液中的四氢大麻酚[55],将PLS-DA 与SERS 联合使用能够检出唾液中微量的海洛因和甲基苯丙胺,并区分两者[56]。
在芬太尼类物质的检测方面,WANG 等[57]使用PCA 结合SERS 检测尿液样本中的芬太尼类物质,结果表明,可以从高浓度的吗啡和芬太尼混合样品中检测出质量浓度低至50 ng/mL 的芬太尼。该方法共分析了5 种芬太尼(芬太尼、卡芬太尼、4-氟丁酰芬太尼、去甲芬太尼和瑞芬太尼),检测灵敏度范围为50~2 000 ng/mL。HADDAD 等[58]使用SERS 进行海洛因混合物中芬太尼的定量分析。该研究还将与每种物质相关的诊断峰的强度比拟合到Langmuir 等温线校准模型中,在样品中芬太尼含量<6%时仍能保持良好的线性,表明该方法适用于犯罪现场调查中定量检材中的痕量芬太尼。GOZDZIALSKI 等[59]报道了将便携式拉曼光谱仪与PLS-DA 联用对混合物粉末中的芬太尼进行定量分析,结果表明该分析方法有望应用于实时检测分析并定量非法药物。MIRSAFAVI 等[60]将SERS与微流控技术相结合,检测芬太尼及其两种化学前体——去丙酰芬太尼和N-苯乙基-4-哌啶酮。除了利用高灵敏度的SERS 外,该研究还结合分层PLS-DA分析算法区分具有相似特征的光谱图。分层PLS-DA方法的分类具有严格的分类阈值,显示出其在分析结构相近化合物时的良好性能。
除了拉曼光谱,近红外光谱(near infrared spectrum,NIR)也是一种无需处理样品即可进行分析的技术。目前,商用拉曼手持光谱仪已被执法人员广泛使用。虽然手持光谱仪体积较小,便于携带,但仍有其局限性。主要问题之一是荧光化合物会干扰和模糊拉曼信号,如果样品中存在特定的荧光杂质,会导致光谱仪灵敏度降低、检测限升高[61]。此外,商用拉曼光谱仪拥有其光谱数据库,但在实际检测过程中,往往会遇到被分析物未包含在数据库中的情况。相比之下,NIR 分析仪不受荧光影响,并且比拉曼设备便宜、体积更小,适合在犯罪现场进行实时分析[62]。目前已有多项研究表明机器学习结合NIR 分析仪具有较好的应用前景,如LIU 等[63]使用SIMCA(soft independent modeling of class analogy,一种有监督机器学习算法)对甲基苯丙胺、氯胺酮、海洛因或可卡因类的光谱进行分类,然后使用PLS-DA 回归模型进行量化;HESPANHOL 等[64]基于多种机器学习算法建立了针对阿片类物质NIR 数据的快速定性和定量分析模型。未来,相信红外光谱结合机器学习将在芬太尼类物质分析领域发挥更重要的作用。
3.3 机器学习结合NMR 技术分析芬太尼类物质
NMR 是司法鉴定和禁毒领域除质谱与光谱外常用的分析技术之一。超导核磁共振波谱仪的仪器成本和冷冻剂维护支出较高,且仪器体积大,因此NMR在司法鉴定领域的普及程度没有质谱与光谱高[65]。近年来,台式NMR 设备不断发展,且成本更低,占地面积更小,不需要使用冷冻剂,并且几乎无需维护[66]。更重要的是,NMR 凭借其自身的独特优势——能够在没有任何信息参考的情况下高效地推测出检材中毒品的化学结构及成分信息,开始广泛应用于新型毒品以及未知毒物的检测。如在芬太尼类物质的检测方面,有文献[67]曾报道运用低场(65 MHz)核磁共振波谱仪获得的核磁共振氢谱(1H-nuclear magnetic resonance,1H-NMR)谱图可以轻松区分65 种芬太尼及其类似物,包括各种类型的位置异构体,为建立独立于场强的1H-NMR 谱图库提供了新的研究思路。此外,有研究[6]应用核磁共振氟谱(19F NMR)对含氟芬太尼类似物进行定性及定量分析(检出限为74~400 µg/mL,定量限为290~1 340 µg/mL),该方法可以改善含氟芬太尼类似物信号在1H-NMR 检测混合物时受到限制的问题,并能够很好地区分含氟芬太尼的位置异构体。
目前,运用机器学习结合NMR 技术分析芬太尼类物质方面的研究报道较少。2020 年,MCKEOWN等[37]运用高场(300 MHz)和低场(43 MHz)傅里叶变换NMR 波谱结合PCA 以及正交PLS-DA 用于3 种方法合成的芬太尼前体N-苯乙基-4-哌啶酮和4-苯胺基-N-苯乙基哌啶共42 个样品的分类研究。与高场相比,低场NMR 数据集每个bin 中的数据点较少且可区分的光谱特征较少,但通过合理建立多变量分析模型,研究人员在低场1H-NMR 光谱中尽可能挖掘出足够的样品信息,最终所有测试样本均获得了较为满意的分类结果。运用机器学习与NMR 技术相结合可以区分由特定方法合成的芬太尼及其前体,为法医学鉴定提供了新的研究策略。
4 总结与展望
在芬太尼类物质非靶向筛查识别领域,机器学习技术已经显示出巨大的潜力。传统的精神活性物质识别鉴定方法大多依赖标准物质,只能对已知的芬太尼类物质进行靶向分析。面对层出不穷的新型芬太尼类物质,这一策略面临巨大挑战。机器学习技术通过强大的数据分析能力结合计算机算力支持,能够快速挖掘大量芬太尼类物质谱图数据中所蕴藏的共性规律,从而对未知化合物谱图与芬太尼类物质的相似度进行计算以评估其风险系数。各种监督学习模型能够高效、自动地从各种类型的芬太尼类物质谱图中提取特征并通过迭代优化建立高性能的分类和回归模型,为新型芬太尼类物质的早期筛查提供数据支持。同时,无监督学习模型能够对海量的芬太尼类物质实验数据进行聚类分析,帮助研究人员了解数据结构,加速研究工作的推进。相信随着各类仪器分析技术和机器学习技术的不断发展,各种针对芬太尼类物质的大规模非靶向筛查方法将蓬勃发展,新型芬太尼类物质的监管空窗期也将不断缩短。
猜你喜欢
中国典型病例大全(2022年11期)2022-05-13
食品安全导刊(2021年20期)2021-08-30
广东医科大学学报(2020年4期)2020-08-24
当代化工研究(2016年5期)2016-03-20
分析测试学报(2015年4期)2016-01-13
中国继续医学教育(2015年1期)2016-01-06
天津医科大学学报(2015年3期)2015-06-05
特产研究(2014年4期)2014-04-10
中国烟草学报(2012年6期)2012-04-09
