
数字语音降噪系统实现研究
2023-10-17 05:04张昊宇朱泳翔
西安航空学院学报 2023年5期
宋 飞,范 焜,张昊宇,朱泳翔
(西安航空学院 电子工程学院,西安 710077)
0 引言
语音是人们进行信息交换的最直接的手段,然而在各类通信交流场景中,语音信号又很容易受到各种噪声的干扰。尤其在短波语音通信场景中,各种复杂而强大的电磁干扰往往会产生大幅度的背景噪声,会使通信语音质量明显下降。这种情况在短波通信中普遍存在,轻则可使通信双方无法识别语音,重则可对接收人员听力带来损害,因此研究效果良好且易于实现的语音降噪技术具有重要的现实意义。
语音降噪技术在生产和生活中具有广泛的应用,研究人员对其进行了深入研究。王涛[1]针对传统的频谱减法算法的噪声估计部分进行改进,使用了基于语音检测的噪声估计算法对噪声进行有效估计。并使用基于最小均方算法的自适应加权平均滤波器有效降低了语音噪声。
孙端[2]采用小波变换理论对带噪语音进行降噪处理,既可克服短时傅立叶变换窗口大小不随频率变化的缺点,又可提供随频率改变的时频窗口。孙端[2]对比了使用不同阈值小波变换的降噪效果,验证了小波降噪方法在语音信号降噪中的可行性。
聂欣欣[3]研究使用麦克风阵列结构,应用最小二乘法(RLS)进行语音降噪,并对降噪效果的影响因素进行了研究。
方健[4]将卷积神经网络噪声识别器和堆叠自动编码器相结合,利用噪声识别器的识别结果,自主选择自动编码器的模型,最终实现了噪声自适应的堆叠自动编码器语音降噪算法。
赵鼎[5]将子空间的思想与深度学习方法相结合,提出了基于子空间投影的时域语音降噪网络,在编码器和解码器之间添加了基于自注意力的投影模块,能够将嵌入向量分别投影到两个正交的子空间内,得到相互正交的语音向量和噪声向量,进而极大程度地将语音信息与噪声信息分离。
上述这些常用的降噪方法针对常见的噪音干扰具有一定效果,实验普遍是高于-5 dB的带噪语音,但对于信噪比较小,噪音幅度完全淹没语音幅度的短波电台应用场景,前述研究工作中没有提及。研究表明,基于神经网络的语音降噪方法对噪声的自动识别和提升降噪效果有一定帮助,但选择适合人耳语音的损失函数比较困难,且深度神经网络需要的计算资源较多,过于复杂的算法应用于实现环节难度较高。
短波电台接收端接收到的带噪语音进行语音降噪应用场景下噪声的幅度往往完全淹没语音,使用常规方法很难达到有效降低噪音干扰的效果。这要求对带噪语音进行滤波处理,改善语音质量,提高听者的舒适度和可懂度。此外,在实际应用中需要在可移动的短波电台中实现算法,因此对算法的复杂度也有一定的制约。
基于前述分析,本文探索解决短波电台接收端噪声污染问题,从接收端的带噪语音中提取尽可能纯净的语音,在有效降低单音和白噪声干扰的同时进行语音增强,提高通信质量及听者舒适度,效果要求尽可能的使语音自然度和清晰度好,可懂度高,残留“音乐噪声”少。
1 语音降噪方法设计
经比较分析,语音降噪首先采用基于梅尔倒谱系数(MFCC)的时域倒谱算法进行语音分段识别处理,后采用谱减降噪算法进行语音降噪,再进行滤波处理,整体算法流程如图1所示。
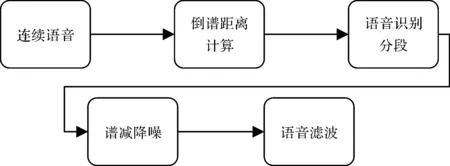
图1 整体算法流程图
1.1 基于梅尔倒谱系数的语音端点检测
梅尔倒谱系数是在语音信号处理中常用的语音特征。研究者发现人类的听觉灵敏度在可听范围内是随声波的不同频率而变化的,低频的灵敏度高于高频的。由此设计一组带通滤波器,其在低频部分较稀疏,在高频部分较稠密,输入语音信号经过此滤波器组处理后,其强度可作为该信号的基本特征。这种特征的优点是能够较好地匹配人类听觉特性,具有良好的鲁棒性,对低信噪比语音信号具有较好的识别性。
语音端点检测是语音降噪系统中的一个重要环节,主要任务是将带噪语音分成两部分:语音部分和噪音部分。这样方便后续对语音部分进行降噪,对噪音部分更新底噪,减少语音处理的数据量[6]。
端点检测的误差会直接导致语音识别的错误判别,进而对后续降噪产生不良影响。在高信噪比情况下,正确地确定语音的端点并不困难。然而,对于一些低信噪比场景下,常规的端点检测方法,如基于能量的端点检测方法等,不能有效地工作。由于基于梅尔倒谱系数的语音特征对高噪声环境具有更好的鲁棒性,本文利用其来检测语音端点,图2所示为MFCC特征向量获取流程图。
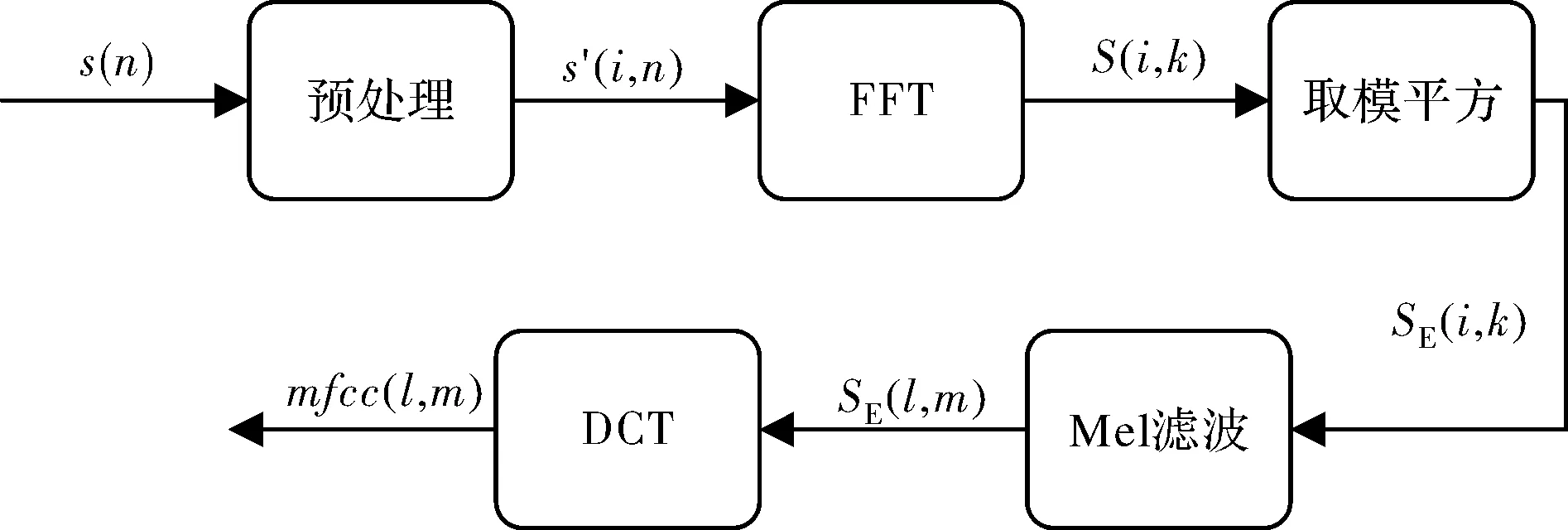
图2 MFCC特征向量获取流程图
1.1.1 语音信号预处理
语音信号预处理模块包括三个部分:预加重、分帧、加窗。
(1)预加重。预加重部分的作用是通过对高频语音的补偿,从而使语音信号的频谱更加平坦化,进而能够一定程度消除发声过程中声带和嘴唇摩擦效应。
输入信号s(n)先进行高通滤波处理,有
H(z)=1-a*(z-1)
(1)
式中:H(z)为z域滤波器函数;a为常数,介于0.9和1.0之间;z为z域自变量。
预加重后的信号s2(n),其时域表达式为
s2(n)=s(n)-a*s(n-1)
(2)
(2)分帧。语音信号具有短时平稳特性,可进行分帧处理,以降低处理难度。通常设置一帧信号有N个采样点(通常取256),持续时间约为26 ms。并在两帧之间设置一部分重叠区域,假设有M个采样点,其值一般约为N的1/3。一般语音信号的采样频率为8 kHz,可知,分帧后对应一帧的时长是32 ms。
(3)加窗。分帧后,需要用窗函数卷积每一帧信号,以降低频谱泄漏的影响。假设分帧后的语音信号为s3(n),n=0,1,…,N-1,N为帧数,使用汉明窗W(n)
W(n,a)=(1-a)-a*cos[2πN/(N-1)]
(3)
式(3)中n的取值范围为[0,N-1]。选择不同的a值可得到不同的汉明窗,一般取a=0.46。
卷积后的信号为
s′(n)=s(n)*W(n)
(4)
1.1.2 频域变换及能量求取
(1)FFT。由于语音信号和噪声信号很难从时域角度区分其信号特性,故常将其转换为频域加以区分。由此,对上一步分帧加窗处理后的信号,经过快速傅里叶变换得到其频域表达式
(5)
式中:s′(n)为语音信号输入;N为FFT变换的点数。
(2)频谱能量。对傅里叶变换后的语音信号求解其频谱能量。
1.1.3 Mel滤波
将上述谱线能量通过一组三角形滤波器组以平滑频谱,消除谐波的影响,突显语音的共振峰,与此同时还可减少数据量。
设这组含M个三角形滤波器,中心频率为f(m),M通常取20~26。随着m取值增大各f(m)的间隔也随之变宽,其频率响应定义为
(6)
同时需要注意这组三角形滤波器组在梅尔频率上是平均分布的,梅尔频率和一般频率的关系式如下
Mel(f)=2 595log10(1+f/700)
(7)
计算每个滤波器组输出的对数能量为
(8)
1.1.4 离散余弦转换
信号处理中,离散余弦转换(Discrete Cosine Transform, DCT)常用于有损数据压缩。语音信号经过DCT处理后能量大多集中在低频部分。
将上述对数能量SE(m)进行DCT处理后,可求出L阶的梅尔倒谱参数。不同的梅尔滤波器是交集相关的,使用DCT变换可去掉这些相关性。离散余弦转换公式如下
(9)
式中:L为MFCC系数阶数;M为三角滤波器个数。
1.1.5 差量倒频谱特征
要获得语音信号各帧之间的动态信息,就需要加上差量倒频谱特征,以显示倒频谱对时间的变化。可以用当前帧的前后几帧的信息来计算一阶差量倒频谱特征
(10)
上式得到的dt是差量特征,计算第t帧需要t-P到t+P的系数(P通常取2)。若对一阶差量的结果再使用上述公式就可得到二阶差量倒频谱特征,这样总共可得到3×12=36维的特征。取一阶和二阶差分特征,再加入每帧的对数能量作为特征,共可得到MFCC特征向量为3×13=39维。
1.2 倒谱距离双门限检测
梅尔倒谱特征作为语音信号特征具有很好的鲁棒性,在噪声强度很高的情况下,对于语音帧和非语音帧的区分,使用其他信号特征很难进行,因此采用上述计算出的梅尔倒谱特征进行语音帧的端点检测。
信号复倒谱定义为信号能量谱密度函数S(ω)的对数的傅里叶级数,其可表示式为
(11)
式中cn为实数,通常称为倒谱系数,且
(12)
对于一对谱密度函数S(ω)与S′(ω),根据Parseval定理,倒谱距离表示对数谱的均方距离
(13)
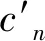
信号谱的差异可以以倒谱距离作为衡量标准。先假定开始几帧是背景噪声,可计算出其倒谱距离矢量,利用其平均值可近似估计出背景噪声的倒谱距离矢量。之后的当前帧若被认为是非语音帧,则背景噪声倒谱距离矢量可按下式进行更新
(14)

若被认为是语音帧,则正常计算语音信号的倒谱距离矢量。
计算中对于式(13)表示的倒谱距离可进行近似计算,如式(15)所示
(15)
采用双门限法进行语音帧端点检测。先为倒谱距离设置较低和较高两个门限,较低门限用于检测信号的初步变化;较高门限用于最终确认信号的变化。假如信号超过了低门限,并不能确认是语音的开始,有可能是随机噪声超过了低门限。只有当信号超过了高门限,并且在之后一段时间内一直在低门限上方,才能表明语音信号开始。低于高门限时可能是扰动所引起的,未必是语音结束,只有低于低门限且持续一段时间内低于高门限,才能表明语音信号结束。语音端点检测的准确性和敏感度受这两个门限的影响很大:若设定过高,则会导致漏检率上升;若设定过低,则会使误检率上升。在实际应用中,需根据具体数据和应用场景进行的参数调整。
1.3 谱减法降噪
经典的语音降噪算法为谱减法,具有简单易实现,计算量小的优点,在实际中应用广泛。依据人类语音的短时平稳特性,以及常见加性噪声频谱,近似替代含噪语音帧中的噪声频谱,再利用带噪语音的频谱减去这个底噪频谱,从而达到降噪功能。
使用谱减法进行语音降噪处理,先根据之前阶段已找到的各语音段端点,对噪音段进行消去并更新底噪水平,对语音段消除噪声的影响。之后再进行平滑处理。人耳对语音的感知主要来源于语音幅度谱,对语音相位谱的感知并不敏感,因此在后续计算中可使用谱减前的含噪语音的相位谱近似代替谱减后的语音相位谱,进而可计算得到降噪处理后的时域语音信号。
1.4 滤波器滤除杂音
使用滤波法进一步滤除消噪后语音信号中的杂音。由于谱减法的缺点是存在对负数域的非线性处理及对噪声谱的估计存在的偏差,处理后往往会产生“音乐噪声”。为削弱这种附加的噪声,方便后续嵌入式的实现,采用车比雪夫低通滤波器对低频语音段进行滤波处理,可明显降低这种噪声的影响。此外,对于系统中存在的工频等其他频率的干扰,为便于后续嵌入式实现,采用凯泽窗高通滤波器进行滤波,只保留需要频段的语音分量,可明显消除这类噪声的影响。
2 实验分析
选用从某型短波电台接收端实际接收到的真实含噪语音作为处理信号。设置其采样率为8 kHz,采用一段典型背景下的接收带噪语音进行语音降噪和滤波处理,原始语音信号波形如图3所示。

图3 原始语音信号波形
由图3可以看出,噪音幅度较大,已完全覆盖了语音的幅度。这种情况下,采用常规语音识别方法难以区分出语音和噪音。
原始语音信号经过前述的基于梅尔倒谱距离的语音端点检测处理后,依据设置的双门限划分出了各自的语音段和噪音段,结果如图4所示。

图4 基于Mel倒谱距离的双门限端点检测
图4中黑色曲线为倒谱距离轨迹,横向黑色直线为设置的较高门限T1,横向绿色虚线为设置的较低门限T2,竖向红色直线为判断的语音段起始点,竖向蓝色虚线为判断的语音段结束点。由图4可明显看出,使用本文提出的方法处理后语音段和噪音段的划分非常明显,这有利于后续的降噪处理。
采用前述的谱减法降噪算法处理后,得出降噪后的语音信号如图5所示。由图5可见,经谱减法降噪处理后,带噪语音的语音信号得到了增强,同时噪音信号得到了抑制。
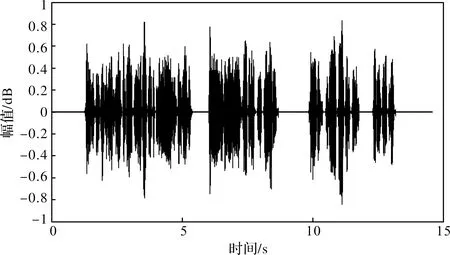
图5 谱减降噪后的波形
采用前述的滤波器进行滤波处理,前述设计的低通滤波器幅频响应如图6所示。
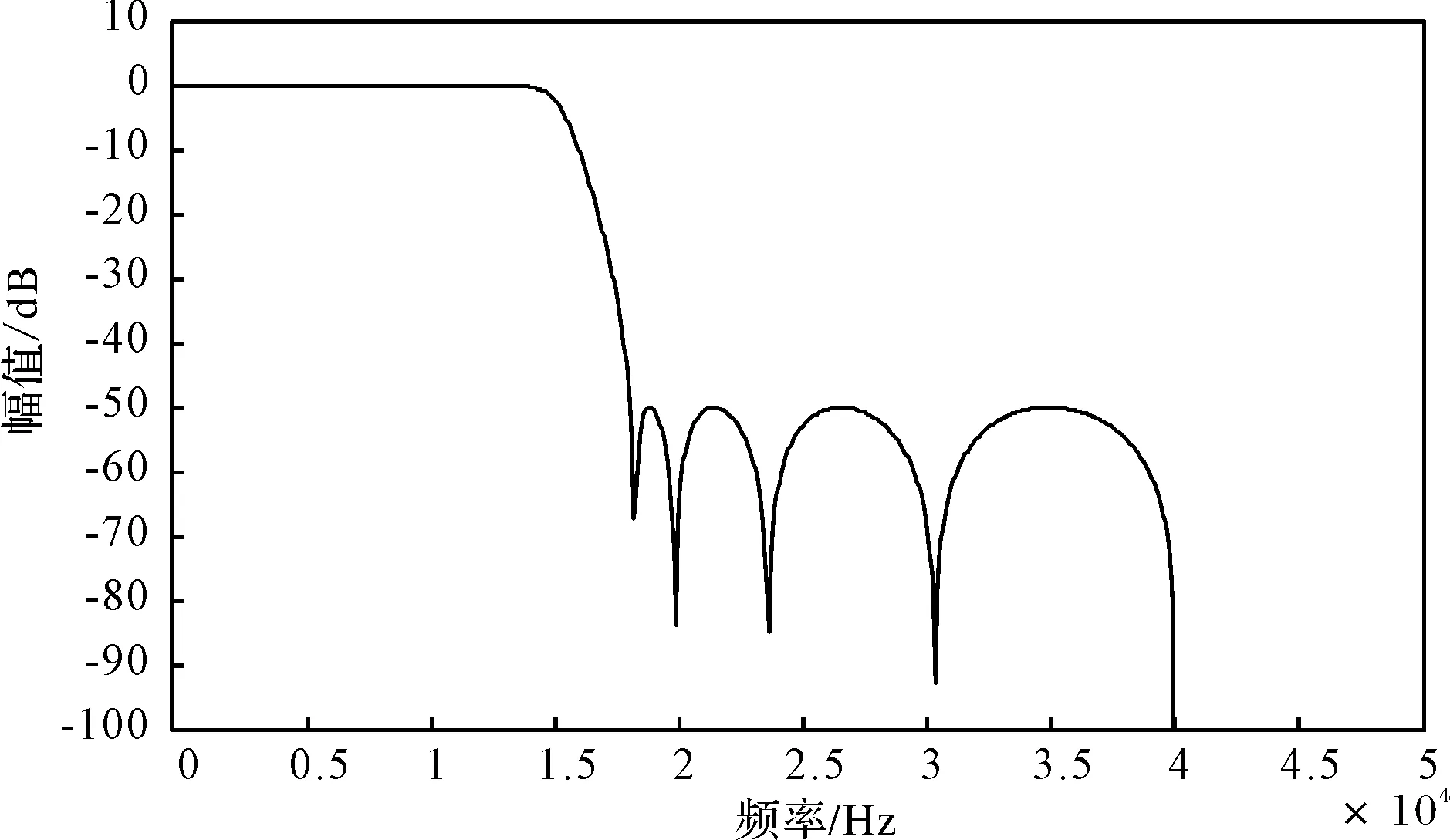
图6 低通滤波器幅频响应曲线
采用高通滤波器幅频特性曲线如图7所示。
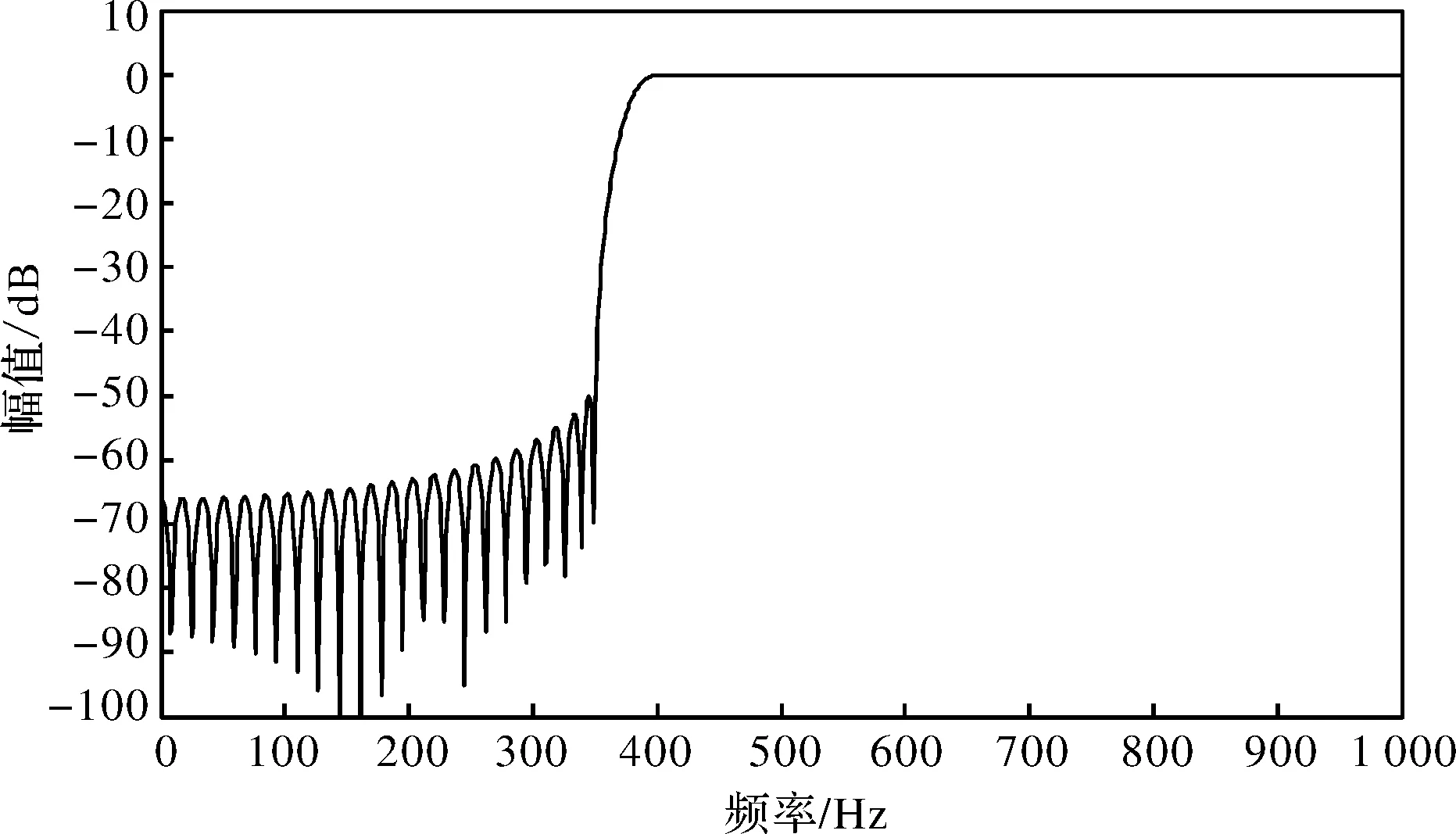
图7 高通滤波器幅频响应曲线
对带噪语音段进行滤波处理后的波形如图8所示。

图8 进行滤波处理后的波形
由图8可见,对所选择的真实带噪语音段经语音降噪系统处理后可有效进行语音段分解,语音信号得到加强,白噪声和“音乐噪声”信号得到抑制,输出语音清晰,可懂度高,噪声明显减少,能够满足语音降噪的功能要求。
为进行定性实验分析,采用上述Mel分段-谱减法对开源带噪语音数据进行降噪处理,并将所得结果与标准谱减算法进行比较。
评价指标选择语音处理中较常用的语音质量感知评价(PESQ)指标,该指标是国际电信联盟认定的客观语音质量评估指标,得分位于-0.5到4.5,越高代表语音质量越高[7]。
开源含噪语音数据选择的是中文语音库THCHS-30,其由清华大学语音与语言技术中心制作。其干净语音由单麦克风录制,并且可选择附加强度可控的三种典型噪声:餐厅噪声、汽车噪声或白噪声。设置采样精度为16 bit、采样率为16 kHz。
本文选择该语音库中具体代表性的语音段并附加白噪声,控制信噪比分别为-5、0、5、10和15 dB,通过下采样达到8 kHz采样率,分别采用标准谱减法和Mel分段-谱减法两种方法进行降噪处理,结果如表1所示。
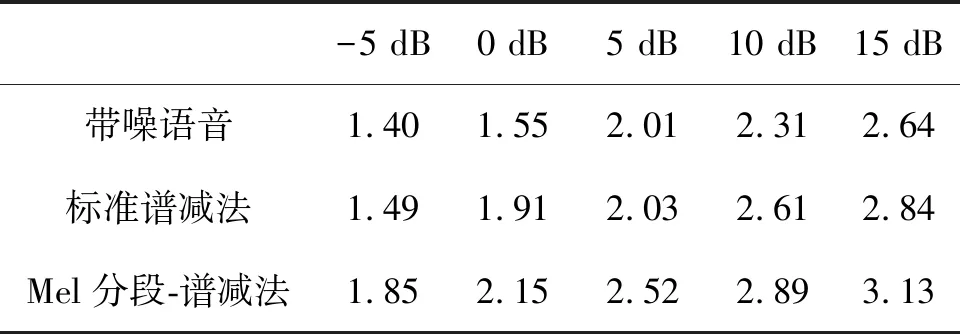
表1 不同信噪比下不同算法的PESQ结果
由表1可知,带噪语音的信噪比从-5 dB到15 dB变化时,经Mel分段-谱减方法进行降噪处理的PESQ得分相较于标准谱减法降噪分别提高了0.36、0.24、0.49、0.28和0.29,相较于未处理语音更是提高了0.45、0.60、0.51、0.58和0.49。由此可看出,本文所提出的基于Mel分段-谱减降噪算法在降噪性能上优于标准谱减算法。
3 结论
针对短波语音通信场景,基于梅尔倒谱距离的语音端点检测与谱减法降噪和有效的滤波器滤波相结合研究了数字语音降噪系统设计方案,并通过实验方法对带噪语音进行降噪处理,并与常用的标准谱减法进行对比。结果表明,本文提出的Mel分段-谱减法能够高效的实现对强噪声短波电台接收语音的有效降噪功能,输出语音清晰,可懂度高,同时又具有算法简单等优点。
猜你喜欢
数学物理学报(2022年2期)2022-04-26
哈尔滨工业大学学报(2022年5期)2022-04-19
汽车实用技术(2022年4期)2022-03-07
中国西部(2021年4期)2021-11-04
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
中学生数理化·教与学(2019年8期)2019-09-18
红领巾·探索(2019年2期)2019-04-19
语言与文化论坛(2019年3期)2019-04-13
畅谈(2018年17期)2018-10-28
数学物理学报(2017年1期)2017-06-05
