
基于机器学习的隧道地质勘察岩性识别分析及应用研究
2023-10-18 04:08刘夏临刘继国陈世纪
隧道建设(中英文) 2023年9期
程 勇, 王 琛, 刘夏临, 3, 刘继国, 3, 陈世纪, 黄 胜
(1. 中交第二公路勘察设计研究院有限公司, 湖北 武汉 430056; 2. 中国交建总承包经营分公司, 北京 100088; 3. 中国交建隧道与地下空间工程技术研发中心, 湖北 武汉 430056; 4. 中山大学土木工程学院, 广东 珠海 519082)
0 引言
随着我国西部大开发发展战略的不断推进,西部各类基础设施也在不断改进[1]。然而,西部地区地质情况复杂,工程建设和安全面临着较大的挑战[2-3],例如: 在隧道建设中,新疆某些地区的地应力高、温度低、地震烈度高、海拔高和断裂带多等特征给施工带来了极大的困难[4]。因此,隧道建设前期的勘察工作尤为关键。目前,常用的勘察手段主要是垂直孔勘察。然而这一方法有一定的局限性,水平定向钻探作为新的勘察手段可在一定程度上弥补垂直孔勘察的不足[5-6],同时,水平定向钻探施工工作量少,且可以更加真实地反映隧道内的地质情况[7]。
随钻测量 (measurement while drilling,MWD)是水平定向钻钻进中应用钻孔过程监测技术获取钻机工作参数(如推进压力、转速、转矩、钻进速率等)的测量技术,在多参数自动获取方面具有巨大优势。自20世纪六七十年代以来,研究人员就开始了钻进参数与岩石可钻性指标之间的相关性研究[8-9],目前已有大量研究成果。对于长距离水平定向钻,主要依靠取芯或岩屑试验来判别围岩岩性,但这2种方法效率低、成本高。
机器学习方法是目前人工智能学习研究的热点课题,它的目标在于使机器在大量数据中学习规律,以便对新任务具有分析和解决的能力。很多研究致力于使用各种钻进参数来预测围岩相关信息。李哲等[10]使用水平钻孔进行隧道的超前地质预报,通过转矩、转速、推进压力、钻进速度4个物理量提出钻进功速比概念,并证明了钻进功速比与隧道围岩岩性、结构面有很好的响应特征。Schunnesson[11]通过监测采集到了冲击钻进过程中的钻速、转速、推进力和转矩,有效预报了岩体的围岩类别及其结构特征。Mostofi等[12]通过现场测试得到的钻头转矩、转速、进尺速率、钻头质量对地层单轴抗压强度、弹性模量、剪切模量进行预测,并采用K-Means聚类算法对地层进行划分。王琦等[13]使用自主研发的岩石钻探系统开展了不同强度完整岩石的数字钻探试验,通过钻探试验结果建立了钻进参数与岩石单轴抗压强度的定量关系模型,该模型与单轴压缩试验结果的差异率平均值小于10%,证明了该模型的科学性。房昱纬等[14]使用神经网络对楚大公路九顶山隧道超前钻探测试数据进行识别,涉及到的特征值为水平定向钻参数(钻速、转矩、推进力和转速),结果证明了采用神经网络模型进行地层识别的科学性和有效性。陈湘生等[15]指出,机器学习具有分析数据能力强、无需依靠先验的理论公式和专家知识等优势,可以通过收集盾构工程的相关参数来对围岩信息进行反演。然而,盾构施工相关数据是在工程施工阶段收集的,反演的围岩信息不能用于设计阶段,存在数据应用滞后的问题。王玉杰等[16]基于数字钻进技术建立了钻进参数与岩块单轴抗压强度之间的定量关系,可以准确且快速地测量岩块单轴抗压强度。由于围岩的岩性与其硬度等相关,因此钻进参数与硬度也存在一定的关系,所以本文采用水平定向钻钻进相关参数预测围岩岩性。
针对目前基于水平定向钻钻进参数进行岩性识别研究的不足,本文依托新疆某隧道工程勘察项目,选取232组钻探数据并进行预处理,基于KNN(k-nearest neighbor)[17-18]和随机森林算法(random forests,RF)[19]2种监督学习算法,构建适用于水平定向钻钻进数据的机器学习模型,最终形成隧道围岩判别评价方法,以期为隧道地质勘察与围岩分类评价提供一种新的思路。
1 工程概况
1.1 工程信息
某公路隧道是乌尉高速公路的重要一环,是连接乌鲁木齐和尉犁的纵向大通道,也是新疆南北贸易往来的通道。隧道全长22.69 km,最大埋深为1 112.66 m。隧道施工面临高地应力、高寒、高地震烈度、高海拔和多断裂带等问题,施工过程中发生岩爆的可能性极高,且岩爆最大的破坏力可达到中级地震的程度。因此,对隧道沿线工程地质进行准确、详细的勘察非常必要。隧道区位图如图1所示。
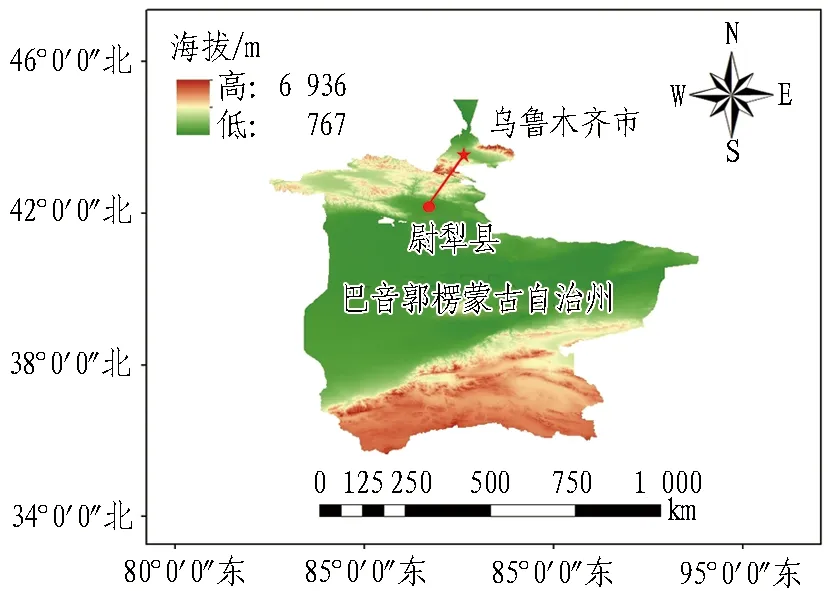
图1 隧道区位图
1.2 沿隧道轴线的岩性分布
隧道进口处至1 593 m钻孔内岩屑均为凝灰质砂岩,灰绿色,矿物成分以石英、长石、云母为主,岩性无较大的变化;1 594~1 750 m钻孔内岩屑为凝灰质砂岩与花岗闪长岩混合;1 751~2 024 m钻孔内岩屑中开始出现碳质板岩颗粒,返浆池浆液颜色由土黄色变为黑色;2 025~2 063 m钻孔内岩屑中石英与片状岩屑含量增多;2 064~2 271 m钻孔内岩屑中石英与长石含量逐渐增多。简化后的勘察成果图如图2所示,隧道岩性分布如表1所示。

表1 隧道岩性分布

(a) 俯视图
2 钻进参数的选取与校正
2.1 钻进参数的选取
水平定向钻进技术用于隧道地质勘察时,随钻测量系统一般可以测量钻头深度、钻进速度、钻进压力、泥浆流量和泥浆压力等参数。钻进时钻杆推力和转矩提供钻头破岩动力,同时带压循环泥浆为钻头旋转提供动力。根据工作原理分析可知,钻进压力、钻进速度、泥浆压力和进浆流量均与钻头破碎围岩的过程相关。这些钻进参数可以反映围岩的相关硬度、节理裂隙等信息。
将水平定向钻用于地质勘察时,因为在钻头处安装传感器可能会影响到钻进的效率,所以水平定向钻施工中收集到的参数多数为地面处测量的数据。由于钻孔设计轨迹是弯曲的,且钻杆与孔壁、钻杆与钻井液存在摩擦,钻孔底部处的压强与地面的实测钻压会有一定的差异。因此,在采用机器学习识别围岩岩性之前需要计算出钻孔底部处的压强,使用钻孔底部的压强可以更准确地反映钻孔底部的实际情况。综上分析,选用钻孔底部压强、钻进速度、泥浆压力和进浆流量作为机器学习的特征值。
2.2 钻孔底部压强矫正
水平定向钻机为GD3500-L型钻机,钻机的具体设计参数如表2所示。

表2 GD3500-L型水平定向钻机参数
当起下钻时,除旋转管柱的质量外,阻力是一种负载。在钻进过程中,旋转管柱会损失转矩,因此钻头用于破坏岩石的功率大大低于旋转平台的功率。阻力和转矩损失的原因有很多,包括压差卡钻、井眼不稳定、井眼清洁不良以及与钻柱侧力相关的摩擦相互作用。目前已有Johancsik等[20]、Sheppard等[21]、Faghih[22]提出了3种摩擦力计算模型进行钻孔底部压强的校准。
该工程水平定向钻进总距离为2 270.8 m,距离较长,且从水平定向钻勘察的纵断面图(图2(b))可知,纵断面中钻进轨迹较为笔直,因此假定钻进过程中轨迹倾角θ恒定;在俯视图(图2(a))中,钻进轨迹近似于圆弧,故将偏转的方位角β变化量视为恒定值。从水平定向钻勘察俯视图(图2(a))中可知,钻进高程随着钻进距离的增加缓慢变大,所以将钻井液从泥浆池运送到钻孔底部的沿程损失较大,且钻井液冲打在钻孔底部上也会损失一部分能量;此外,钻杆的横截面积较小,所以最终由环空压力产生的作用在钻杆横截面上的力较小。因此,本次分析中忽略钻孔底部环空压力对钻杆横截面上的作用力。综上所述,选用Sheppard模型[21]对钻孔底部的压强进行校正,压强随着钻进深度的变化率为
(1)
(2)
式(1)—(2)中:σs为测量钻进压强,Pa;s为钻进深度,m;Wb为单位长度钻杆压强,Pa/m;θ为纵断面钻进轨迹倾角,(°);k为基于钻机推力的摩擦因数;∂θ/∂s为纵断面钻进轨迹倾角变化率,(°)/m,此处为0;β为俯视图中钻进轨迹偏角,(°);σ为钻孔底部的压强,Pa。
钻杆自重
ω=Aρg。
(3)
纵断面钻进轨迹倾角
(4)
式(3)—(4)中:A为钻杆的横截面积,m2;ρ为钻杆密度,kg/m3;g为重力加速度,m/s2;H为进尺高度,m,最终为37.92 m;D为进尺距离,m,最终为2 271 m。
Sheppard等[21]提出的模型中,平面内的摩擦力被简化。对于简化条件下的阻力计算,使用的摩擦因数为0.2~0.4,平均值为0.3,故本次计算取摩擦因数为0.3。进尺在0~1 000 m时采用的钻杆直径D1为0.14 m,横截面积对应表3中的A1;进尺在1 001~2 270 m时采用的钻杆直径D2为0.168 m,横截面积对应表3中的A2。钻杆壁厚均为0.009 m,长度l为9.6 m。
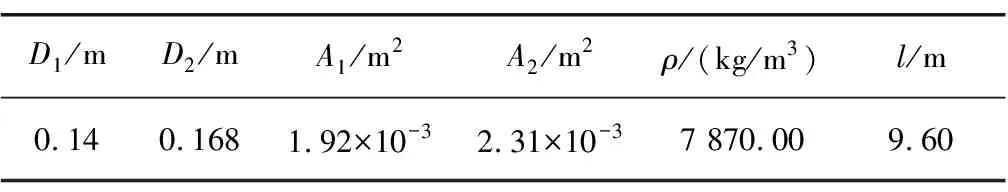
表3 钻杆参数
校正后的钻孔底部压强和钻进速度随钻进深度的变化曲线如图3所示,泥浆压力和进浆流量随钻进深度的变化曲线如图4所示。机器学习校正后的输入样本如表4所示。

表4 机器学习校正后的输入样本
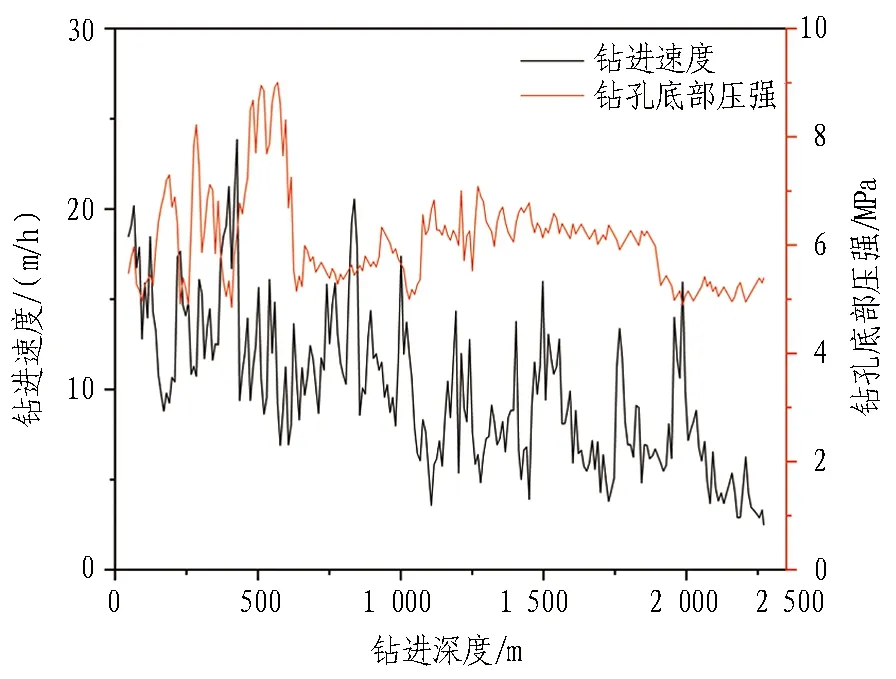
图3 钻孔底部压强和钻进速度随钻进深度的变化曲线

图4 泥浆压力和进浆流量随钻进深度的变化曲线
3 分析方法与数据处理
3.1 分析流程
机器学习大致可分为监督学习(supervised learning)、非监督学习(unsupervised learning)和半监督学习(semi-supervised learning)3类,它们最主要的区别是训练数据中是否带有标签。对于钻孔围岩分类问题,一般是已知围岩岩性而进行的训练与测试,故属于监督学习问题。对于分类问题,每个样本都具有特征值和目标值等属性值,本文中钻进速度、钻孔底部压强、泥浆压力和进浆流量为特征值,地层岩性为目标值。
常见的分类算法有ANN(artificial neural network)、朴素贝叶斯、KNN、决策树、支持向量机和随机森林[23]。本文采用常规算法和集成算法进行案例分析。KNN算法模型较为简单,对数据的分布无要求,适用于数据量较小、数据分布均衡的场景中;随机森林算法是一种集成分类算法,不需对数据进行过多处理,它由多个组合分类的决策树模型构成,每一棵决策树都有投票权来选择最优的分类结果。目前已有研究表明,在对121个UCI(University of California, Irvine)数据集分类时,随机森林算法在179种分类算法中分类性能最优秀[24]。因此,本研究采用KNN算法和随机森林算法进行岩性识别。机器学习分析流程如图5所示。
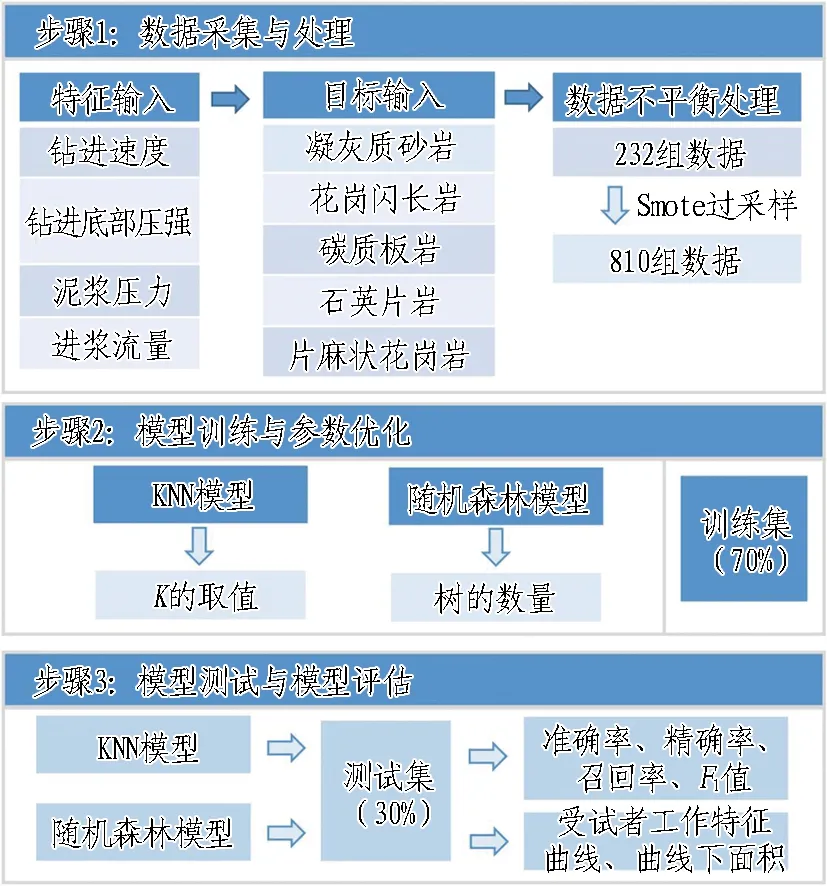
图5 机器学习分析流程图
3.2 数据预处理
由图5中步骤1获取特征参数和目标参数,由表1可看出不同围岩岩性样本数量差别很大。在分类问题中,各类别有均衡的样本数量是很重要的。如果各类别样本数量差别很大,在模型训练时的预测结果可能会偏向样本数量大的样本,导致模型分析不准确。因此,有必要采用重采样的方法来避免模型出现偏差。本研究中,使用Smote算法[25]对花岗闪长岩、碳质板岩、石英片岩和片麻状花岗岩4类数据进行过采样处理,处理后各类别均有162个样本,5个类别共810个样本。过采样后样本与原样本相比未出现大偏差,基本达到了平衡样本的需求。
在进行算法分析之前,通常需要对不同量纲和数量级的特征值数据进行归一化处理,按照最大值和最小值将样本值映射到 [0,1] 区间,避免样本中的极端值对分析结果产生影响。归一化的公式为
(5)
式中:x为归一化处理前的数值;xmin、xmax分别为样本中的最小值和最大值;x1为归一化后的数值。
本研究分析的围岩有5种岩性,是一个五分类问题。为了方便分析和评估模型,将问题转化为5个二分类问题,因此需要对目标值进行处理,处理流程如图6所示。以凝灰质砂岩为例,预测凝灰质砂岩时为正例,其他岩性围岩时为反例,其混淆矩阵见图7。
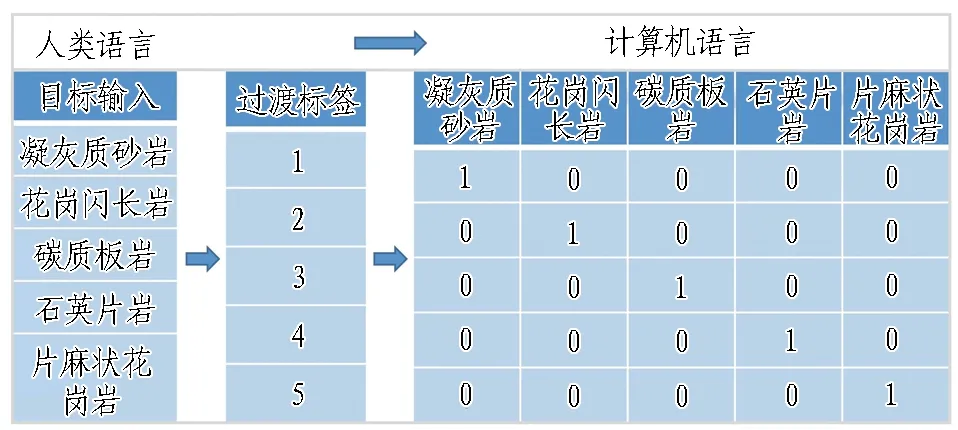
图6 分类问题转化流程图

图7 二分类混淆矩阵(以凝灰质砂岩为例)
3.3 数据集的划分
分类模型会出现欠拟合和过拟合2类问题。若机器学习模型没有从训练数据中得到充分的学习,模型的学习效率不高,就会出现欠拟合问题;若模型从训练数据中学习过度,导致训练时错误率低,而测试集的准确率比训练集低得多,就会出现过拟合问题。不同的方法估计分类模型有不同的误差,出现这些问题与训练集和测试集模型的样本选择有关。
本研究810个样本中,70%用于训练,30%用于测试模型。在KNN和随机森林2种算法中,设置取值相同的超参数对模型进行对比评估。KNN算法的超参数是K值,随机森林算法的超参数为树的数量N,超参数的取值为区间[3,50]中的整数。在这48个模型中,选取测试集准确率最高的模型进行分析和评估。
4 模型训练与评估
4.1 模型的训练和测试
按照3.3节中训练集和测试集的比例,设置不同的超参数进行训练,训练后用于验证测试集,记录测试集准确率最高时对应的超参数,结果如表5所示。

表5 最佳模型超参数表
图8和图9示出不同超参数下KNN算法和随机森林算法的准确率。当K取值为3时,KNN算法的测试集准确率最高,为90.53%。48个模型训练集和测试集准确率平均值分别为83.78%和83.28%,但不同的模型准确率差别较大,随着K值增大,测试集和训练集的准确率均在降低,这是由KNN算法的原理决定的——距离K个学习样本的欧氏距离决定该样本的属性,在有限的样本中当K值越来越大时,会出现其他样本的数值,从而导致准确率逐渐降低。所以在实际使用KNN模型时,K值不应该取得很大。
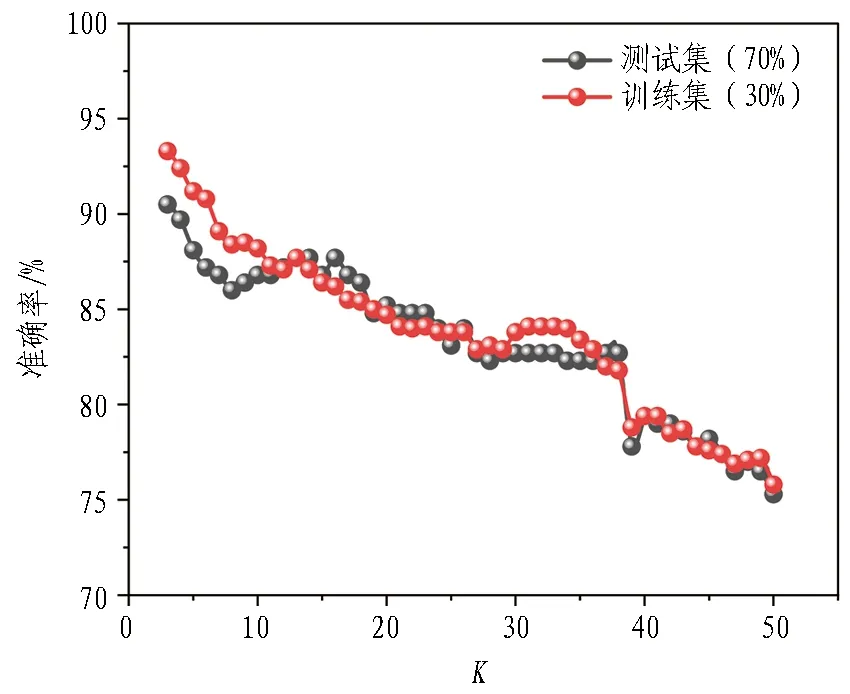
图8 不同超参数下KNN算法的准确率
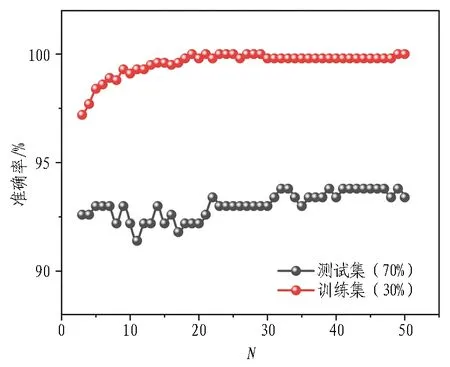
图9 不同超参数下随机森林算法的准确率
在48个不同超参数取值中,随机森林算法的训练集和测试集平均准确率分别为99.59%和93.04%。当N为32时,测试集准确率最高,为93.83%。从图8和图9中可知,相较于KNN算法,随机森林算法的准确率较为稳定。
对于每个算法的48个模型,比较训练集和测试集是为了检查模型是否过拟合或欠拟合。KNN算法测试集与训练集的结果相差不大,而随机森林算法测试集与训练集的结果平均相差7.00%左右,2个算法模型都没有出现欠拟合和过拟合的情况。
4.2 模型评估
除了准确率(Ac)之外,还引入了精确率(Pr)、召回率(Re)和F1值对模型进一步评估。4个评价指标中,准确率用于衡量模型正确预测样本的能力;精确率和召回率分别用于衡量模型所有预测为正的样本中实际为正样本的概率和实际为正的样本中被预测为正样本的概率;F1值是一个综合性的指标,同时考虑了精度和召回率。精确率、召回率和F1值越接近1,模型的性能就越好。4个评价指标的计算见式(6)—(9),其中,TP、FP、FN和TN的含义见图7。
(6)
(7)
(8)
(9)
选取表5最佳超参数对应的2个模型进行评估。图10和图11分别示出KNN算法最佳模型和随机森林算法最佳模型的4个评价指标。图中1、2、3、4、5分别代表凝灰质砂岩、花岗闪长岩、碳质板岩、石英片岩和片麻状花岗岩。从算法的角度分析可知,随机森林算法的4个评价指标均高于KNN算法。对凝灰质砂岩(1)和花岗闪长岩(2)的识别中,随机森林算法4个评价指标数值为95.00%左右,而KNN算法的4个评价指标数值为90.00%~95.00%;对碳质板岩(3)、石英片岩(4)和片麻状花岗岩(5)的识别中,2种算法的4个评价指标均值相差不大,但是随机森林算法的偏差更小、更稳定。从不同围岩岩性的角度出发,石英片岩(4)的4个评价指标值都很大,机器学习的效果最好。总体上看,2种算法的评价指标都比较理想,但随机森林算法要优于KNN算法。

图10 KNN算法最佳模型评价指标数值
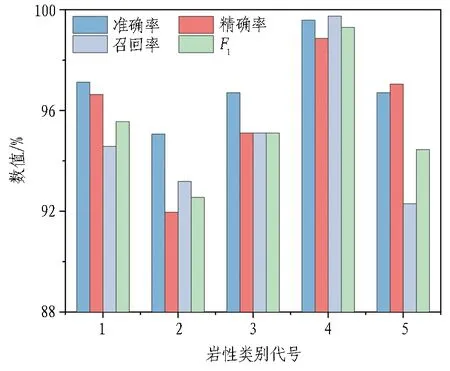
图11 随机森林算法最佳模型评价指标数值
评价模型的另一个重要指标是受试者工作特征(receiver operating characteristic,ROC)曲线。ROC曲线是一种分类模型效果评价方法,通过其曲线下面积(area under curve, AUC)、敏感度、特异性和最佳分界点等关键参数,可确定岩性识别模型的阈值。ROC曲线主要根据图7中的混淆矩阵绘制。在ROC曲线中,曲线下面积(AUC)越大、越接近于1,模型的性能越好;越接近于0.5,模型的性能越差。
KNN算法和随机森林算法的ROC曲线以及AUC值分别如图12和图13所示。真阳率表示正确的预测为正的数量与原本为正的数量之比;假阳率表示错误的预测为正的数量与原本为负的数量之比。无论是从算法角度还是从不同岩性的角度,KNN算法和随机森林算法AUC值都趋近于1,表明模型分类性能良好,模型的鲁棒性较强、泛化能力较好。同时,随机森林算法在不同超参数下测试集的准确率较高且较稳定。

图12 KNN算法ROC曲线及AUC值
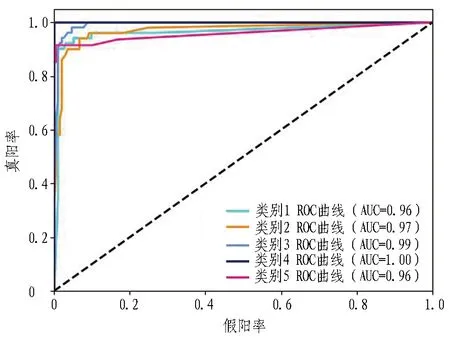
图13 随机森林算法ROC曲线及AUC值
由于随机森林算法的准确率、精确率、召回率和F1值总体比KNN算法更高、更稳定。因此,在本案例选取的常规算法和集成算法中,随机森林算法的效果较好。
4.3 过采样算法评估
进行岩性识别之前,使用Smote算法对不平衡的样本数据进行扩充,每一个类别数据量都增添到162组,得到了一个平衡的数据集。
按照3.3节中训练集和测试集的比例,设置不同的超参数对未采用Smote的数据集进行训练。未使用Smote算法进行数据过采样的围岩岩性识别准确率如图14所示。在48个不同超参数模型中,KNN算法的训练集和测试集的平均准确率分别为79.67%和77.74%,与经过Smote过采样后的模型准确率相差不大。当K取4时,测试集准确率最高,为81.43%。
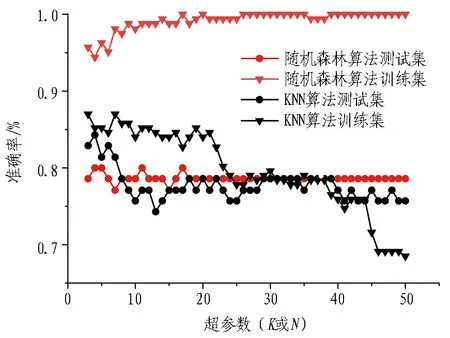
图14 未使用Smote算法进行数据过采样的围岩岩性识别准确率
48个模型中,随机森林算法训练集准确率很高,接近于100.00%,而测试集准确率接近80.00%。训练集和测试集准确率相差很大,训练的随机森林模型存在过拟合现象。48个模型中,采用Smote过采样后随机森林测试集的平均准确率为93.04%,比未过采样的模型准确率高,且没有出现过拟合现象。当N取4时,测试集准确率最高,为80.00%。
未使用Smote算法的最佳测试模型的预测结果如表6所示。虽然2种算法总体的测试结果较高,但由于样本数量非常不均衡,样本数量少的岩性类别得不到充分的训练和验证。
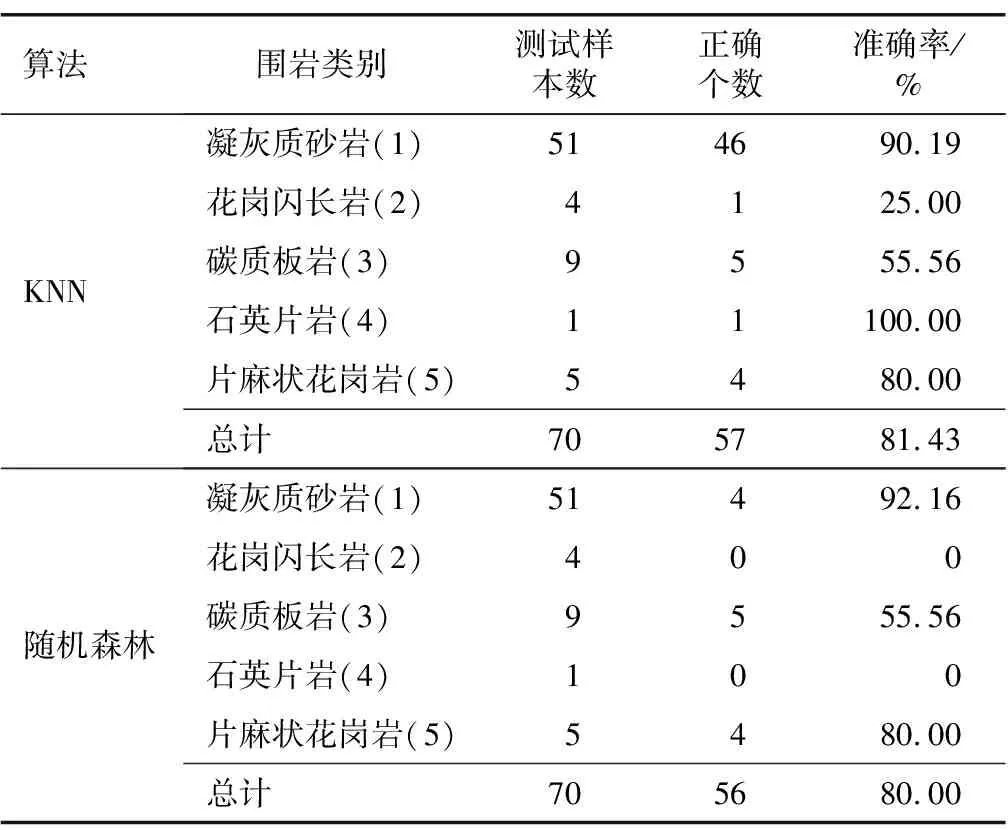
表6 未使用Smote算法的最佳测试模型的预测结果
在232个样本中,凝灰质砂岩数量162个,其余类别围岩样本数量过少。训练集和测试集也存在着样本不平衡的问题,样本数量少的类别得不到很好的机器学习训练。在70个测试样本中,5个围岩类别的数量分别为51、4、9、1、5,后4个围岩类别的岩性识别准确率变化幅度大,个别案例难以代表整体,模型结果说服力不强。所以,在样本不平衡的情况下采用Smote算法进行过采样是必要的,进行过采样后的模型数据量大且均匀、鲁棒性好、泛化能力强,没有出现过拟合或者欠拟合等问题。
5 结论与讨论
5.1 结论
1)分别对KNN算法和随机森林算法的48个不同超参数模型进行比较,2种算法测试集平均准确率分别为83.28%和93.04%,随机森林算法比KNN算法准确率高且更稳定。
2)将岩性识别的五分类问题转化为5个二分类问题进行分析,采用每一类别岩性的准确率、精确率、召回率、F1值、ROC曲线和AUC值对模型进行评估。随机森林算法的4个评价指标总体上优于KNN算法。总体的评价结果表明,随机森林算法的围岩岩性识别效果更好。
3)原始数据量少且各类别的数据差异大,机器学习算法模型的结果不符合大数据分析要求,说服力不强;而采用Smote算法处理后的数据集很平衡,训练模型的鲁棒性好、泛化能力强,没有出现过拟合或者欠拟合等问题,在样本不平衡时建议使用此方法对数据进行处理。
5.2 讨论
1)本文使用理论分析方法对钻孔底部压强进行求解,但理论分析和实际有偏差。目前已有钻进技术可以直接测量钻孔底部压强,但是在本案例中未使用此技术,在今后的研究中应考虑采用此技术进行测量,以更真实地反映钻孔底部压强。
2)本文研究中案例样本数量有限,且涉及的围岩岩性类别仅有5种,由于自然界的围岩类别较多,故本方法尚不能应用于实际勘察中。今后的研究应该注重对于不同类别岩性的数据收集,形成一个庞大的数据库,为机器学习提供强有力的支撑。
3)本文研究只选取了有代表性的常规分类算法和集成分类算法对岩性识别进行初步的探讨和分析,在数据库丰富的基础上仍需要对各种算法进行细致调参、相互比较和筛选。此外,机器学习算法注重教学模型分析而淡化工程中出现的物理问题,如何解释机器学习方法的可行性和说服力是目前需要解决的问题。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
云南化工(2020年11期)2021-01-14
中华建设(2019年12期)2019-12-31
中国交通信息化(2018年5期)2018-08-21
江西建材(2018年4期)2018-04-10
录井工程(2017年1期)2017-07-31
江西煤炭科技(2015年1期)2015-11-07
中国铁道科学(2015年5期)2015-06-21
