
基于Bert 模型的发动机故障文本分类
2023-10-24 07:36陈海松付俊涛
装备制造技术 2023年8期
孙 磊,陈海松,付俊涛,王 清
(陆军工程大学,江苏 南京 210004)
0 引言
发动机作为制造业中最关键的部件之一,被广泛应用于汽车、工程机械、农业机械、船舶等各领域,担负“心脏”作用,为其他设备提供动力。由于发动机的种类繁多,故障样式也呈现多样性,而传统依赖人工经验的诊断方法容易受到人力、技术以及地域的限制,知识共享性、重用性低,且执行成本高、劳动强度大,很难达到迅速高效的诊断与判排目的。
利用现代人工智能技术,对发动机的故障文本进行智能诊断,开展相应的分类研究,对于现代化的工程机械维修保养来说,能更为快速地定位到故障部位,减轻维护人员工作量。基于自然语言处理的深度网络模型,对发动机故障短文本分类方法进行研究,达到快速故障定位的目的,为其他类似问题的解决提供一些参考。
1 研究现状
目前,国内外学者开展了中文短文分类方面的相关研究,重点关注到其特征表达和分类方法的选取和优化。传统机器学习方法是早期文本分类的主流方法之一[1],随着文本数量增长后,目前深度学习方法效果相对较好。邓姝娟[2]采用共词分析法将航空发动机关键字分类,结合聚类分析和多维尺度分析,实现了快速检查。许驹雄[3]将发动机故障文本构成知识图谱,挖掘故障数据中的专家知识,提高了信息检索和维修效率。Kougiatsos[4]提出了基于分布式模型的燃料发动机故障监测和隔离方法,主要运用异构传感器开展数据采集,结合非线性微分代数估计和自适应阈值生成的残差实现。Tang[5]结合生成对抗网络模型,使用可变学习率来加速模型收敛,通过对发动机的失效模拟实验,表明了模型具有较高的准确性,可作为诊断的辅助工具。
而Google[6]提出的基于多头注意力的Bert 模型,则采取了全新的Transformer 的Encoder 与Decoder堆叠达到预期效果。Bert 模型具有提取信息能力强、易于使用和稳定性高等优点,能够克服描述发动机故障记录文本不规范、语句短等问题,能很好完成文本识别和分类等任务。
2 文本采集与增强
2.1 数据采集
通过对图书和网络有关文献资料中故障案例进行提取,根据发动机基本组成[7]形成包含曲柄连杆机构、配气机构、燃油供给系统、润滑系统、冷却系统、进排气系统等6 个子系统作为分类标签,共计1125 条发动机故障文本数据的原始样本集,各类别数据分布与样本示例见表1。

表1 发动机故障数据库构成
对采集到的数据进行简要分析,其主要特点有:(1)从数据分布中可以看出,总体数据在各类别上分布总体上比较均匀,但数据量偏少,考虑到深度学习模型一般需要保持足够的数据量,才能得到较好的任务效果,因此需要提前对数据集进行样本增强;(2)数据样本描述长度普遍不长,一般不超过150 个字符,后续研究可以主要集中于短文本分类研究上;(3)数据集中存在一定的描述不完整、错误等问题,必须预先处理,否则可能影响后续模型效果。
2.2 数据增强
主要采取同义词词汇替换、回译、随机噪声注入等3 种方法。
(1)同义词替换
替换发动机故障文本中所包含的字词,但不改变其原本意思,即从故障短文本描述中随机提取一个词,并用它的同义词替代这个词,如“风扇叶片不转”中的“叶片”替换为“叶子”。
(2)回译
通过对原文进行释义,并对原文进行再翻译等两步实现数据增强的目的。采取将中文转换为英语后,再翻译到中文的方式,若无区别可更换语言。若有,则使用此新语句作为原文的数据加强样本。
(3)随机噪声注入
通过向数据中加入噪声,使所得到的数据对外界有较强的抗干扰能力,包括重新组合、随机插字[8]、随机调换、随机移除等多种方法。如样本“柴油机在运行中发出爆燃响声”通过以上四中噪声注入方式可以生成“柴油机在运行中发出爆燃响声,启动后抖动严重”“柴油机在运行中突然发出爆燃响声”“在运行中柴油机发出爆燃响声”“柴油机在运行中发出响声”四个增强样本。
经过数据预处理后,最终发动机故障文本数据量可达到11023 条。表2 中显示了数据增强后的故障文本数据量和数据增强后发动机故障数据库各类别占比。

表2 数据增强后故障文本数据量和各类别占比
3 基于Bert 模型的发动机故障文本分类模型
Bert 为预训练模型,在下游只需要经过简单微调即可适应新的任务,因此在文本处理领域应用越来越广泛。构成发动机故障短文本分类方法总体架构图如图1 所示。

图1 总体方法架构图
(1)通过网络采集与人工录入方式收集发动机基本样本集,对样本集中的发动机描述不正确、缺省、错字、漏字等进行预处理。
(2)针对样本划分为曲柄连杆机构、配气机构、燃油供给系统、润滑系统、冷却系统、进排气系统等六个子系统,并制作类别标签。
(3)进行数据增强,扩大类别数据文本库。
(4)按照8∶1∶1 划分训练集、验证集与测试集。
(5)将构建的发动机短文集作为输入,进入到预训练Bert 模型。
(6)确定评价指标,通过验证集优化模型参数。
(7)完成训练,输出微调后的发动机文本分类模型。
整个方法主要包括模型输入、模型构建、预训练与微调四个内容。
3.1 模型输入
Bert 输入为每个字/词的原始向量,该向量可随机初始化,也可直接选择Word2Vector 等算法预训练后的向量[9]。Bert 模型将文字转化成一维向量,并将其输入到网络结构中,为匹配句子对任务和标志句子中各字之间的位置关系。
Bert 模型还增加了分割嵌入与位置嵌入层。
分割嵌入层(segment embedding)用于刻画文本语句的全局语义信息,并与单字/词的语义信息相融合,其取值通过模型训练得到,例如两个不同句子输入就会使用分割嵌入进行区分。由于主要任务是单个发动机短文本的分类,不存在多个语句成对输入,因此,分割嵌入是一样的。
位置嵌入(position embedding)位置嵌入是针对出现在文本不同位置的字/词所携带的语义信息存在差异的情况设计,通过对不同位置的字/词分别附加一个不同的向量来提高区分度,原作者采取的计算公式为:
字向量嵌入长度主要与预训练结果保持一致即可,每个句子的pad 长度根据数据集而定,由于所采集的发动机描述数据属于短文本,不超过150 字符,pad 长度取150 即可。
最终Bert 模型将字向量、文本嵌入向量和位置嵌入向量相加之和作为模型的输入值,模型输入组成如图2 所示。
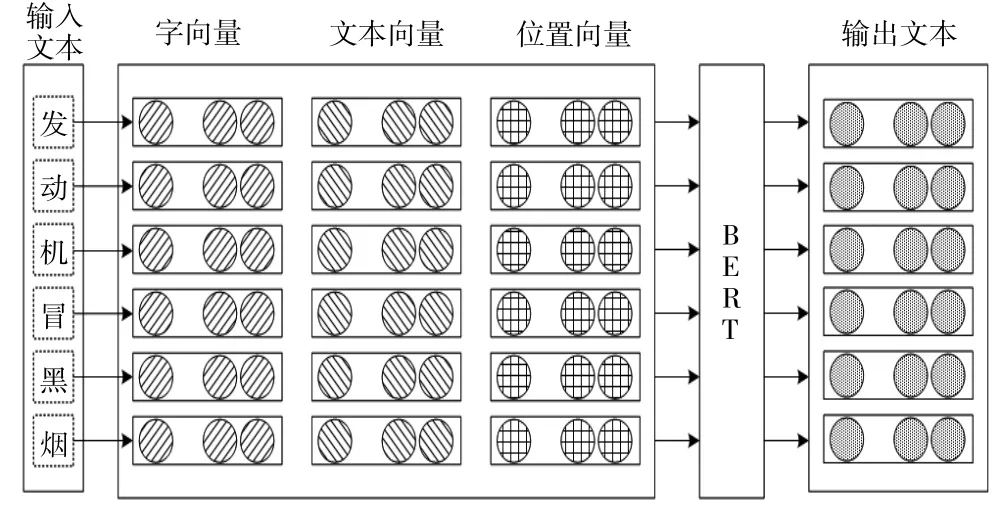
图2 模型输入组成
3.2 Bert 内部结构
在模型输入确定后,将被送入到Bert 的主体结构中,Bert 由多个Transformer 模块(图中简称TRM)堆叠而成,而每个Transformer 又由多个Encoder 与Decoder 堆栈形成,Encoder 将输入input 转换为编码信息,而Decoder 则重新将编码信息转换为解码信息,其总体结构如图2 所示,以此实现不断提取语句特征,包括表层特征、句法特征与语义层次的特征。Bert 内部还采取了双向结构、注意力机制,如图3 所示,可以较好的学习到上下文隐层关系,最终实现将语句输入Ei转换为模型输出Tj。
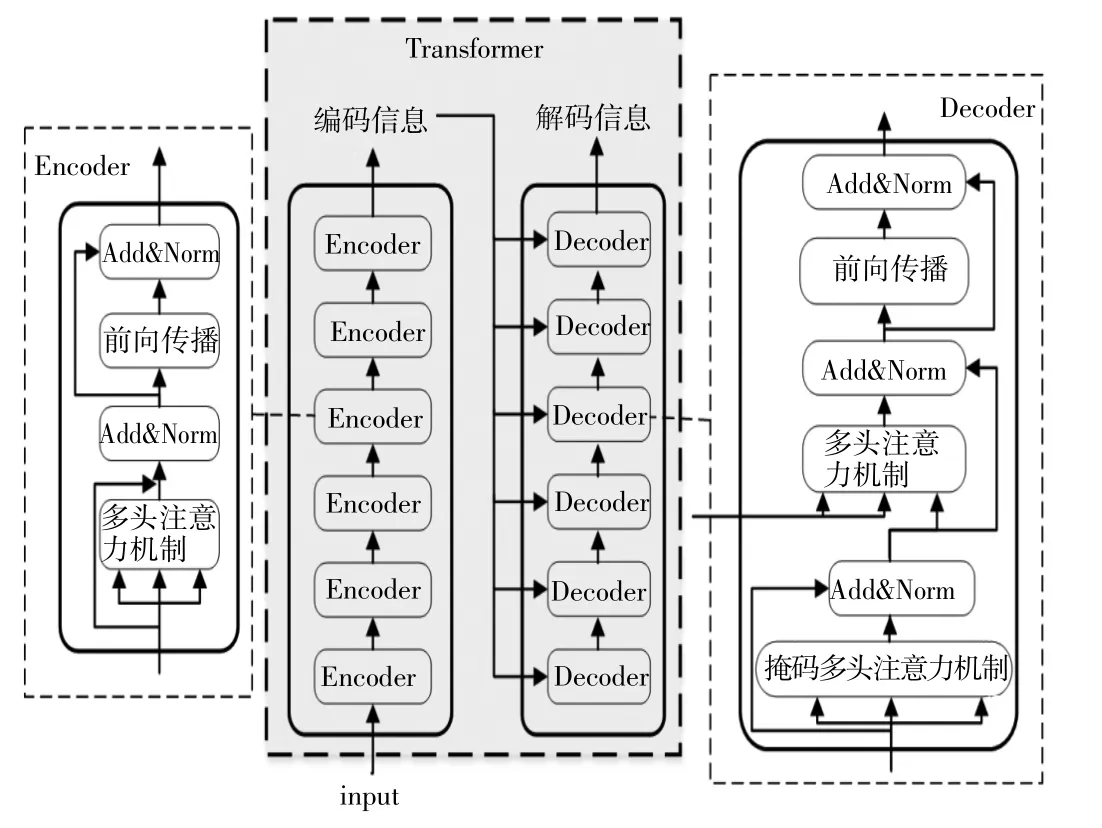
图3 Transformer 模块结构

图4 Bert 模型体系结构
3.3 预训练
Bert 模型主要进行两个预训练任务:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。
MLM(Masked Language Model):将一个或几个词语进行“隐藏”,然后通过训练进行预测,这也是分类任务的主要任务。例如,将“发动机冒黑烟”文本中的“发动机”一次隐去,然后进行网络预测,通过不断训练,最终实现该词的准确预测。
NSP(Next Sentence Prediction)[10]:把两个句子拼接到一起并送入模型,预测其属于同一类别的概率,可用于同义句判定或问答系统。例如将“发动机冒黑烟”“滤清器出现故障”两个短句中间加入[SEP]标记,在头尾再加上[CLS]与[SEP]后送入Bert 模型进行训练,如图5 所示,模型最终可实现句子对的预测。

图5 NSP 示意图
3.4 微调
Bert 微调就是在预训练模型的基础上使用预处理后的发动机短文本分类数据集,调整构建的Bert分类模型参数,以适应本领域文本分类任务的过程,这样不仅节省时间,而且提高模型精确性能,比较适合领域迁移,从而完成所研究的发动机常见故障文本分类任务。
4 模型实验与结果分析
4.1 实验数据集
实验采用前述预处理有增强后的11023 条数据,其中训练集、验证集、测试集数量分别为8823、1100、1100 条,标签类别编号按照曲柄连杆机构、配气机构、燃油供给系统、润滑系统、冷却系统、进排气系统顺序分别记为0、1、2、3、4、5。部分数据展示见表3。

表3 发动机故障短文本示例
4.2 模型的评价指标
分类模型的有效性,一般采取查准率(Precision)、召回率(Recall)、准确率以及F1 值(F1-score)作为评估指标[11]。
为准确描述以上三个指标,使用TP、FP、TN、FN分别代表真阳(True Positive)、假阳(False Positive)、真负(True Negative)、假负四类样本。
查准率:是指在样本分类过程中,正例被预测为正例的样本数与所有被预测为正例的样本数的比值。
召回率:是指在故障文本分类过程中,所用语料中实际上预测上都是正例的语料数目与所用语料中预测正确的数目之间的比值。
F1 值:通过将查准率与召回率进行平均数处理,得到的F1 值,作为一种衡量分类模型优劣的综合指数。
4.3 实验与结果分析
基于以上评价指标,对11023 条数据构成的样本集进行模型验证实验。
实验环境与相关参数设定为:
操作系统:ubuntu20.04
语言版本:python3.8
CPU:intel 酷睿i7
GPU:RTX 3090 24G
深度学习框架版本:pytorch1.7、keras2.6.0
迭代次数设置为100 次,损失函数选择交叉熵分类损失,当达到最大迭代次数或者连续1000 次以上损失函数没有降低后结束。
基于构建的发动机故障短文分类模型,其准确率以及Loss 值的改变情况分别显示在图6 和图7 中(每隔5 个迭代记录一次)。

图6 文本分类Loss 值曲线图
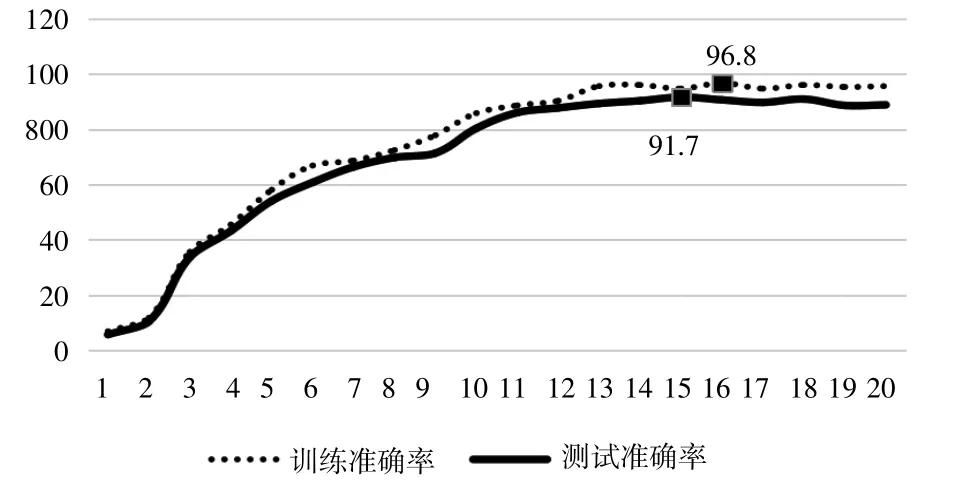
图7 文本分类准确度曲线图
图6、7 中的横坐标表示迭代次数,纵坐标表示loss 值与准确率。从图6 中可以看到,Loss 值曲线的总体变化趋势是逐渐下降的,而在次数达到14(即70个迭代次数)后,Loss 值已经接近于相对稳定状态,这时的Loss 值在0.1 和0.3 之间,模型的精度也在不断地提高,测试精度从刚开始的20%提高到了91.7%,这表明,所构建的模型能在较快的迭代后适应新的测试集,保持在较为可信的区间,验证了Bert 模型的发动机故障短文本分类在数据集应用的有效性。
为进一步研究不同类别的分类效果,将类别的查准率、召回率以及F1 值评价指标分别列出,得到表4,为清晰观察比较各类别之间的关系,将三者绘制为折线图,如图8 所示。

图8 各类别下查准率、召回率以及F1 值对比
由图8、表4 可发现,所有类别的指标均大约0.8,占据数据量最多的配气机构和燃油供给系统具有相对较好的结果,也说明了数据量增大能一定程度上提高模型精度。而润滑系统和进排气系统的实验结果不够理想,分类准确率不高,可能有两方面的原因:(1)总体数据量还是相对较少的;(2)在数据增强的过程中,样本替换、消除相似度过高,导致增强效果一般。因此,可以针对效果不佳的类别进行数据集优化以得到更精确的分类结果。
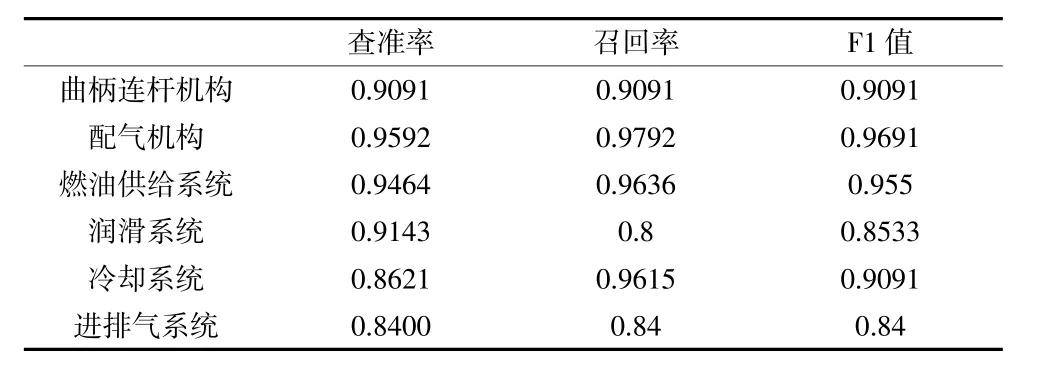
表4 各类别下查准率、召回率以及F1 值对比数据
5 结语
针对装备发动机的故障文本,基于与训练Bert模型对其开展了分类研究。首先对发动机常见故障的文字资料进行了数据预处理,包括错误故障去除、重复故障去除、故障分类,针对数据不足的现实,采用词汇替换、回译、随机噪声注入等技术对故障文本进行增强。其次基于Bert 模型,采取微调方法,构建了装备发动机故障文本分类模型,设计了总体算法流程。通过实验表明,模型对数据集的准确率、召回率与F1均表现较好,具备了较好的应用价值。未来将进一步考虑故障现象的多重原因分析,即复合故障诊断,进而提升模型实用性。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
民用飞机设计与研究(2019年2期)2019-08-05
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
汽车与新动力(2015年1期)2015-02-27
阅读与作文(英语高中版)(2013年12期)2013-12-11
阅读与作文(英语高中版)(2013年11期)2013-11-13
