
基于改进神经网络算法的英语数字资源个性化推荐方法
2023-10-25 09:05强薇
中阿科技论坛(中英文) 2023年10期
强 薇
(苏州工业园区服务外包职业学院,江苏 苏州 215123)
在“信息爆炸”的时代,英语数字资源的可获得性不断增强。学习者需要选择满足自身学习的特定需求和兴趣,但学习者熟练水平提升却是一个挑战。为了解决这一问题,英语数字资源个性化推荐的概念应运而生,且有效地改变了学习者发现和使用相关资源的方式。个性化推荐方法利用先进的算法和数据分析技术来解析个体学习者的偏好、学习模式和目标。个性化推荐方法可根据用户数据(如历史互动、反馈和表现等)可以准确识别并推荐与学习者独特需求相匹配的资源。无论是算术、统计还是高级数学概念,个性化推荐方法主要目的在于强化用户的学习效果和参与度。通过个性化推荐方法,学习者可以更加高效地发现适合自己的英语数字资源。这种定制化的学习体验不仅能够满足个体学习者的需求,还能够激发他们的学习热情,使学习过程更加愉快、更加高效。
国内相关专家针对英语数字资源个性化推荐[1]方面的内容展开了大量研究。童小凯等[2]采用“知识图谱”建立不同域之间的联系,同时形成全局嵌入,最终通过全局域提高每个目标域推荐结果的准确性。黄禹等[3]将传统“用户—项目评分矩阵”转换为“用户—项目距离矩阵”,采用距离分解法获取用户、项目两者之间的距离关系,并且利用其替换原始的相似度关系,最终引入深度学习框架有效实现个性化推荐。李伟卿等[4]优先构建“用户长短偏好模型”,通过用户评分偏置和评分两者相结合的方式完成个性化推荐。以上几种个性化推荐方法在使用过程中存在英语数字资源个性化推荐结果不准确以及个性化推荐耗时长等问题。为此,文章引入改进神经网络,提出一种基于改进神经网络算法的英语数字资源个性化推荐方法。试验测试结果表明,该方法可以有效提升英语数字资源个性化推荐结果准确性,同时能够加快推荐效率。
1 基于用户特征的偏好挖掘
在网络浏览过程中,全部用户的访问行为都是随机的,在随机一个时间序列z内,设定互动尺寸为n,在特殊情况的窗口内,对窗口内的n条数据展开均值计算。在长度为l的时间特性z处于N维空间内,可以将其中的第i个元素表示为
式(1)中,代表第i个向量。
为了更好地实现长度为l的时间特性降维处理,需要将上述时间特性划分为N个规格完全一致的帧,同时计算每个帧落入帧内的均值,并且将获取的均值计算结果按照时间轴的方式排序,得到长度为N的向量,通过初始序列的方式描述不同的向量。
将全部用户划分为多个规格相同的时间片T1,T2,T3,…,Tn,计算单一任务的平均时间tavg:
式(2)中,k代表任务总数;time(task(i))代表执行任务i的时长。
将各个类型的用户行为特征进行统计分析,分析各个时间片段Tn下各种行为特征的分布情况,同时通过落在各个Tn中的任务总数,将时间片中用户的行为状态展开划分处理。引入静态划分规则,在设定时间范围内对全部用户行为特征总数进行统计和整合,经过计算可以得到用户不同特征行为在系统整体资源所占的比例si如下:
式(3)中,taski,j代表在时间片段i中第j个任务,Call代表英语数字资源的总量。
以用户在网页的浏览时间和访问频率作为衡量标准,通过对用户在网页查询频率的分析可以得到不同类型用户的行为特征。将得到的不同类型用户行为特征模型输入到支持向量机内[5-6],将给定的英语数字资源对应的训练数据表示为{xi,yi},xi和yi分别为输入向量和英语数字资源类型标签。在支持向量机内[7-8],分类的最优超平面来自距离其最近的部分样本点。结合上述分析,得到最优分类的超平面表达式:
式(4)中,W代表权重向量,b代表标量。
在利用支持向量机[9-10]对用户偏好挖掘的过程中,同时还需要分析全部输出值对应的输入特征,再将用户平均查询频率作为标准,引入支持向量机观察不同类型用户的查询行为特征,得到用户行为特征挖掘结果f(x):
式(6)中,代表知识元,ua,i代表知识元组成的元素总数,wa,b代表混合权重因子,主要是由权重因子wa和wb组成。
在式(6)中,除了用户相似度,剩余各个参数全部可以通过实际统计得到。英语数字资源个性化推荐[13-14]是在神经网络算法的基础上实现,通过图1给出神经网络算法结构图。
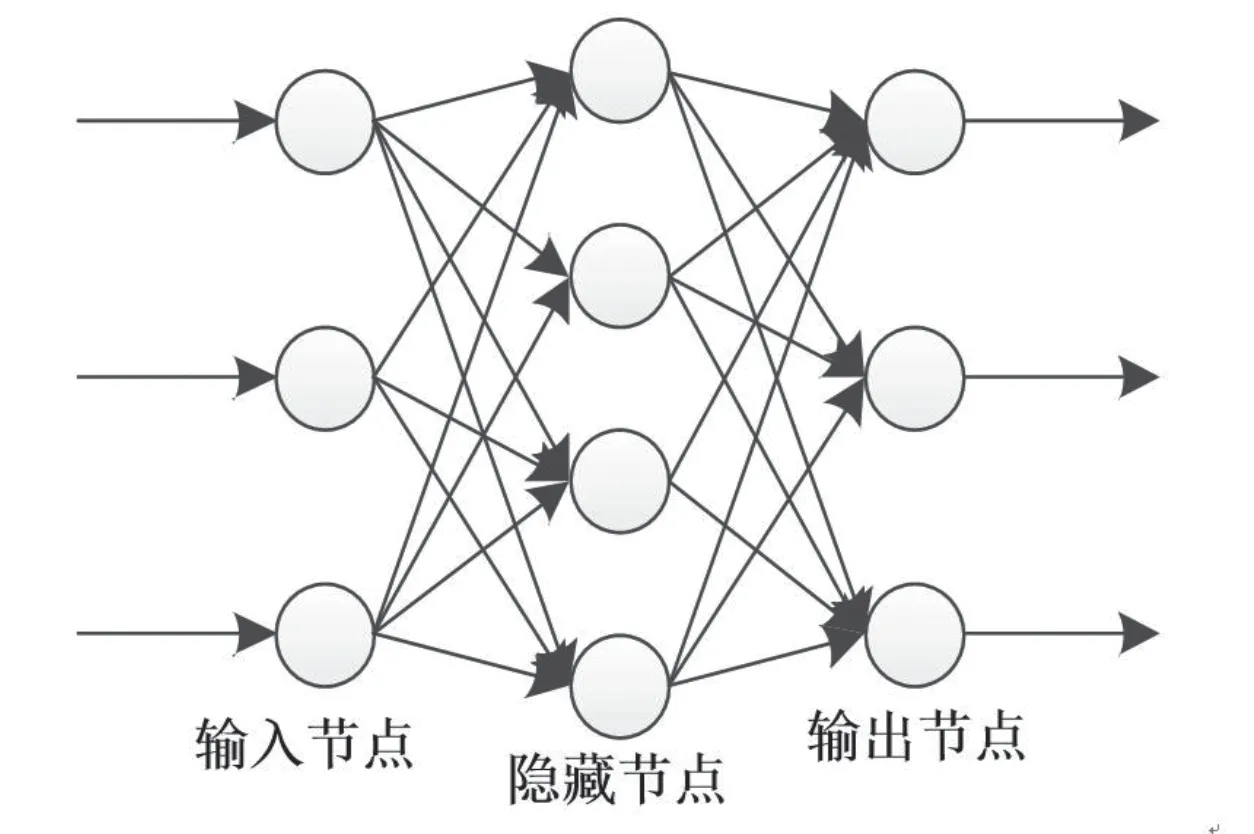
图1 神经网络算法结构图
式(5)中,K(xi)代表估计函数,β(x)代表映射函数。
2 基于改进神经网络算法的英语数字资源个性化推荐方法
以用户行为挖掘结果为依据进行英语数字资源个性化推荐。在英语数字资源个性化推荐过程中[11-12],引入Linkert量值描述英语数字资源个性化推荐结果rec(a,i),对英语数字资源个性化推荐结果产生影响的主要因素分别为用户相似度ha,w、用户评分数量s、用户评分重叠数量m、用户评分向量pa,w,进而可以将rec(a,i)表示为:
为了有效避免神经网络算法[15]在训练过程中出现震荡的情况,需要在传统神经网络算法中加入动量因子τ,引入动量因子后的权值Δθ(k)计算式如下所示:
式(7)中,r(k)代表学习速率。
通过改进神经网络算法和元数据概念构建英语数字资源本体ψ,对应的计算式为式(8):
在得到用户偏好以及英语数字资源本体后,为了提升英语数字资源个性化推荐结果的可靠性,需要对以上二者进行双重聚类处理,也就是利用双重聚类算法对用户偏好以及英语数字资源进行聚类处理,详细的聚类结果如式(9)和式(10)所示。
式(9)中,L代表用户偏好集合;式(10)中,P代表英语数字资源集合。
对聚类结果展开匹配,最终实现英语数字资源个性化推荐I:
式(11)中,GL和GP分别代表用户类和英语数字资源的聚类中心。
3 试验
为了验证所提出的基于改进神经网络算法的英语数字资源个性化推荐方法(以下简称所提方法)的有效性,试验选取来自Kaggle数据网,计算不同英语数字资源个性化推荐方法(文献[2]方法、文献[3]方法、文献[4]方法)的准确率,并在相同的试验环境下,对不同推荐方法的查准率以及运行时间等评价指标展开测试分析。
3.1 数据来源和试验环境
试验在Kaggle数据网选取10种不同类型的英语数字资源作为试验数据,在Windows 10环境下通过Python(3.5)对试验数据展开分析。
3.2 试验分析
(1)英语数字资源个性化推荐准确率
在用户兴趣特征词数量持续增加情况下,不同英语数字资源个性化推荐方法的准确率变化情况,如图2所示。
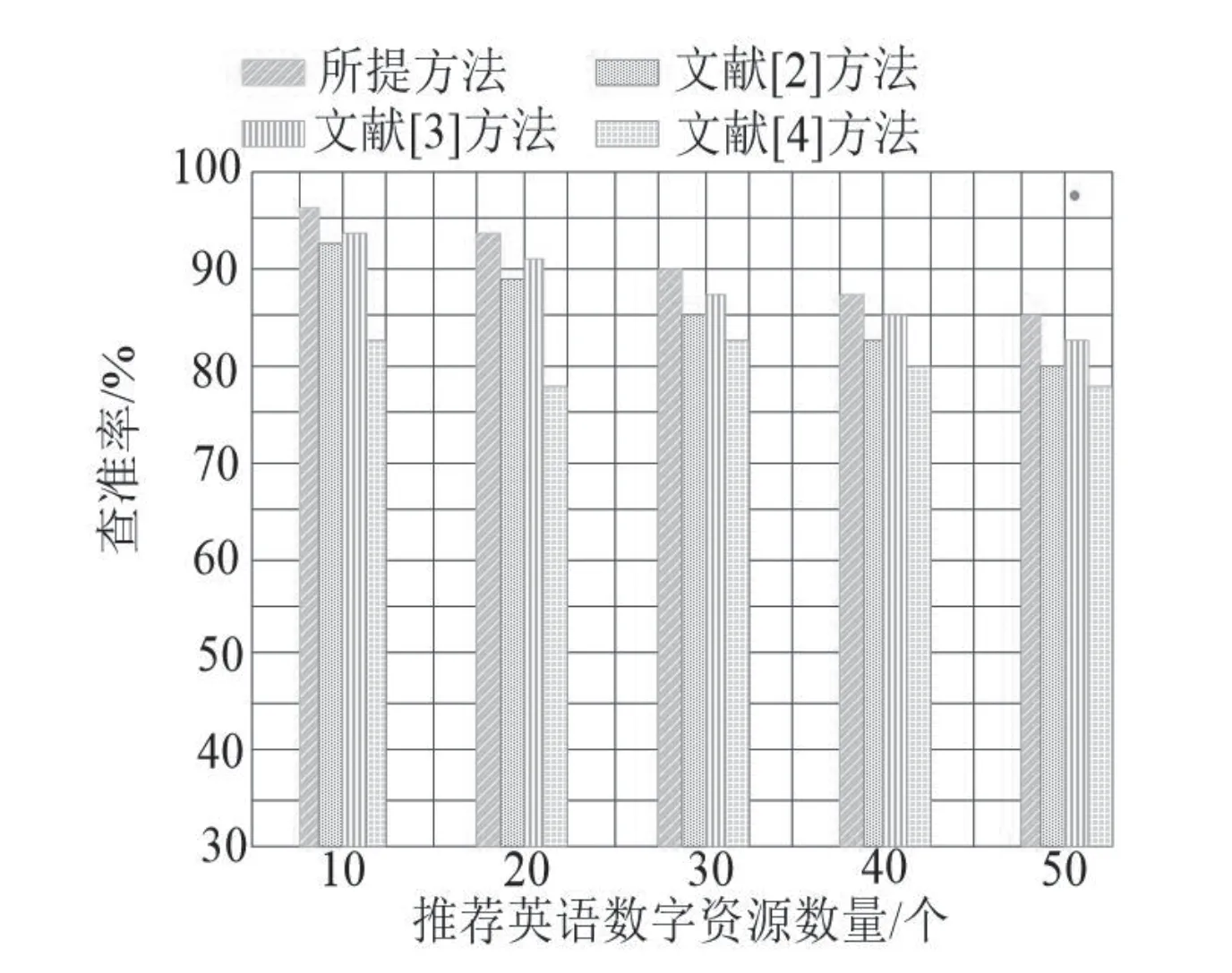
图2 不同英语数字资源个性化推荐方法的准确率比较
分析图2可知,随着用户兴趣特征词数量的持续增加,不同推荐方法的准确率也逐渐增加。当用户兴趣特征词数量达到55时,不同推荐方法的准确率也达到最高。但是所提方法的准确率明显更高,证明其更加适用于英语数字资源个性化推荐。
(2)查准率
在设定推荐英语数字资源数量的情况下,不同英语数字资源个性化推荐方法的查准率变化情况,如图3所示。
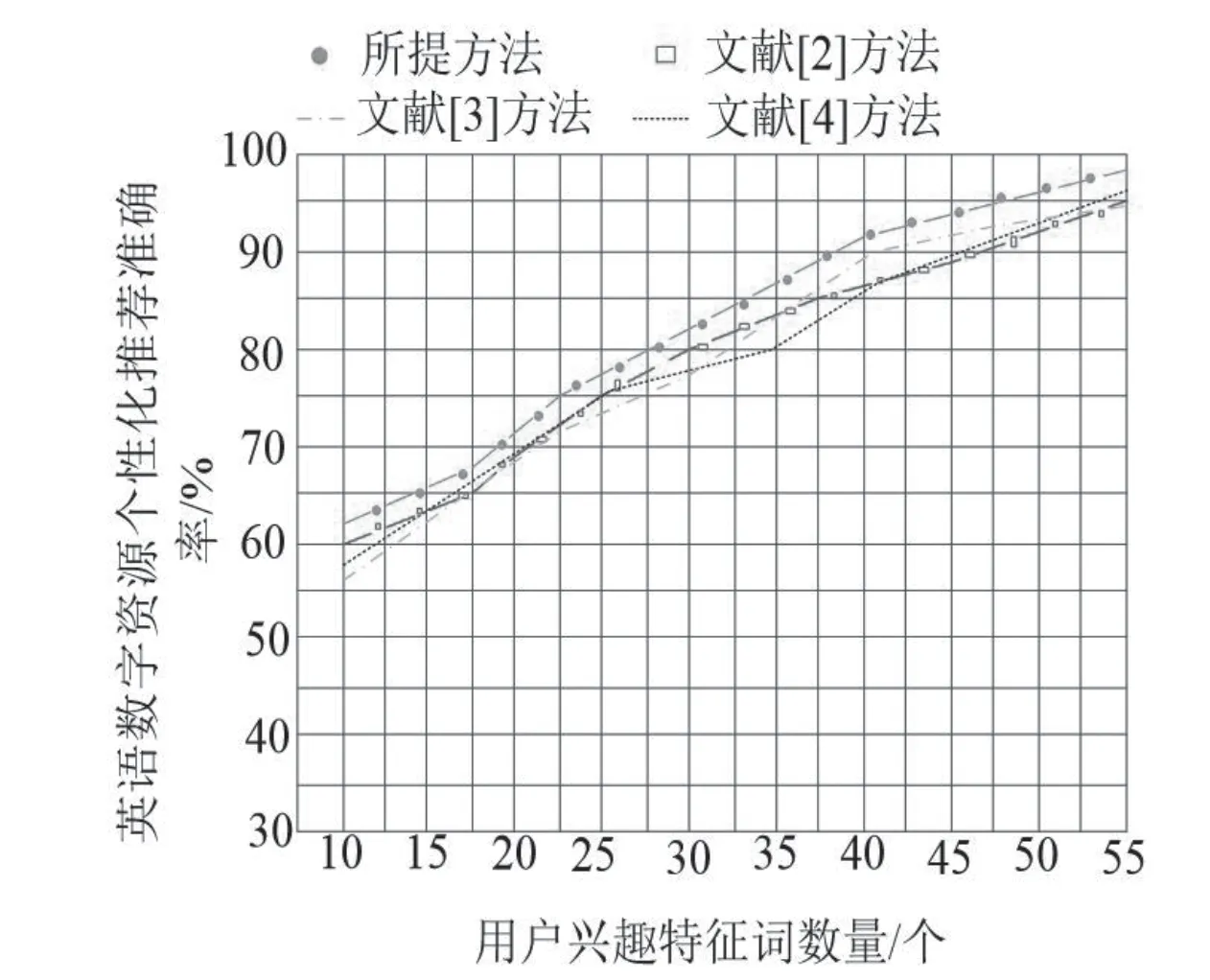
图3 不同推荐英语数字资源数量下不同推荐方法的查准率对比
分析图3可知,在推荐英语数字资源数量不断增加的情况下,不同推荐方法对应的查准率呈现下降趋势。但是经过对比发现,所提方法的查准率优于另外三种推荐方法。
(3)运行时间
在不同推荐英语数字资源数量情况下,不同推荐方法的运行时间变化情况,如表1所示。
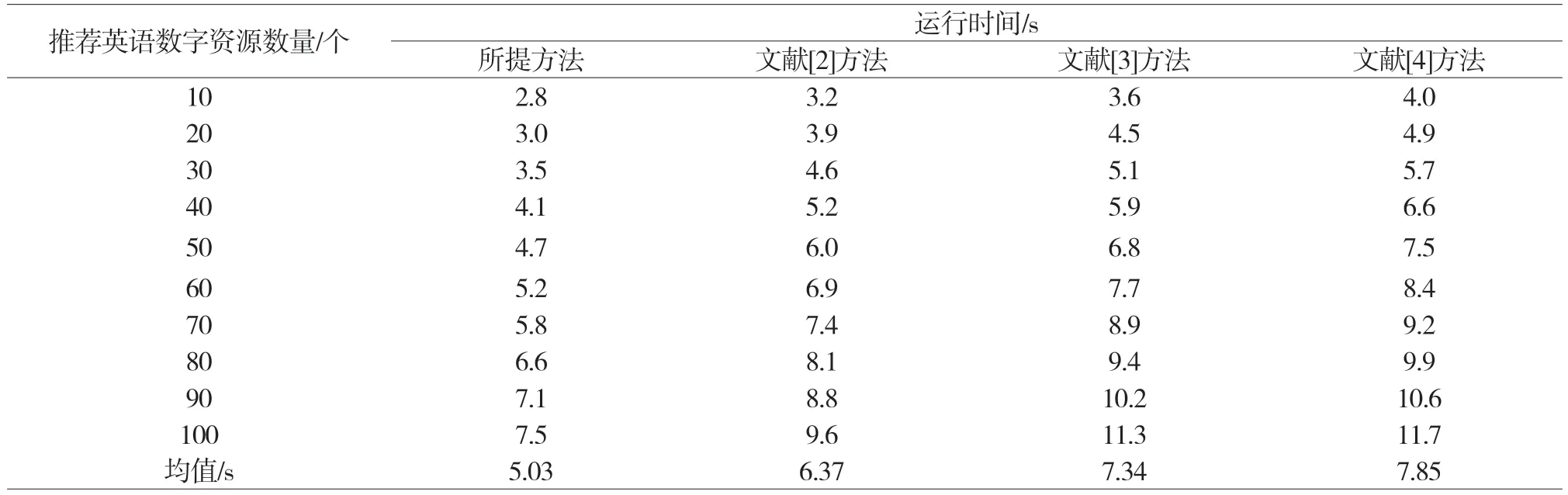
表1 不同推荐英语数字资源数量下不同推荐方法的运行时间对比
通过分析表1可知,所提方法的运行时间明显低于另外三种推荐方法,说明所提方法在现实中具有更高的应用价值,可以有效提升英语数字资源个性化推荐效率。
4 结语
针对传统英语数字资源个性化推荐方法存在的推荐结果不准确以及运行时间较长等问题,文章提出一种基于改进神经网络算法的英语数字资源个性化推荐方法。通过和已有的个性化推荐方法相比较,可证明所提方法在英语数字资源个性化推荐过程中更加高效,同时所获取的结果也更加精准、查准率也更高,所提方法的研究成果为英语数字资源个性化推荐的后续发展提供了全新的思路。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
文苑(2020年4期)2020-05-30
新闻传播(2018年12期)2018-09-19
现代电子技术(2018年16期)2018-08-21
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
汽车与新动力(2016年6期)2017-01-04
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
