
迭代框架优化的密集场景单棵树木检测
2023-11-10 15:11江一鸣董天阳
小型微型计算机系统 2023年11期
江一鸣,董天阳
(浙江工业大学 计算机科学与技术学院,杭州 310023)
1 引 言
随着卫星遥感和无人机航拍等相关技术的发展,树木遥感影像的获取变得更为方便快捷.基于遥感图像的树木检测和识别技术在森林资源管理、病虫害调查、城市绿化规划等领域中得到了广泛应用.传统的单棵树木检测方法一般是基于像素的,如基于分水岭法来确定树冠轮廓的方法[1]、基于空间聚类的方法[2]和基于区域生长策略得到树冠边缘的方法[3],基于像素的树木检测方法受噪声影响大,且大部分情况下需要对图像进行锐化处理,在存在阴影或者其它干扰物的情况下存在较大的误差.因此,近年来数据驱动的方法被提出用于树木特征的自动学习,特别是深度学习方法受到了研究者们越来越多的关注.Li等人[4]首次将CNN引入遥感树木检测中,并在油棕榈树林的检测中取得较好的效果.Guirado等人[5]采用谷歌地图图像作为数据源,提出了一种基于CNN的树木检测方法,效果优于其它单木检测方法.基于卷积神经网络的树木检测方法对树木大小相近、场景简单的情况下检测效果较好,但在更为复杂的场景中表现不太理想.且卷积神经网络感受野大,多次下采样会不断减小特征图,使得特征更难提取,在遥感图像中目标较小,语义信息缺失的情况下会导致更多漏检错检的情况[6,7].Dong等人[8]采用级联卷积神经网络的方式对树木检测方法进行优化,提升了对难样本树木的检测能力.叶阳等人[9]在级联卷积神经网络的基础上,采用生成对抗网络对树木场景进行去阴影处理,减少了遥感图像中阴影部分对树木检测的干扰.但这些方法在背景复杂,树木密集的场景中检测结果仍存在不足.目标检测领域的发展为遥感检测领域注入了新的活力,但遥感影像的特殊性需要研究者们对目标检测算法进行有针对性的改进.
目前主流的目标检测算法分为单阶段检测和两阶段检测,两阶段检测以Faster R-CNN系列[10]为代表.两阶段检测的算法流程基本一致,首先用预设的锚框产生候选框,然后进行特征提取,最后进入分类和回归的流程.Mask R-CNN[11]采用RoI Align代替RoI Pooling进行进一步优化,解决了RoI特征和回归位置的不匹配问题.王文豪等人[12]认为该类算法感受野较大,不适合遥感图像中目标偏小的情况.单阶段检测以YOLO系列[13]和SSD系列[14]为代表,跳过了候选框的生成步骤,直接回归得到类别概率和样本坐标.YOLO系列对比两阶段检测速度更快,但精度有所下降且泛化性弱.SSD系列平衡了YOLO和RCNN系列的部分优缺点,适合多尺度训练,但对于遥感图像中的目标偏小的情况存在语义不足的问题.
所有基于深度学习的目标检测方法均会对候选对象进行密集采样,因此每个对象会产生数个不同置信度的相似框,然后网络通常采用非极大值抑制方法对产生的候选框集合进行处理,最后为每个对象生成精确的框.这种方法在规整的人工种植林之类的场景上可以得到比较好的准确度,但当树木密集且大量重叠时,很难区分两个相似候选框是属于同一个对象还是属于两个高度重叠的对象.这是对非极大值抑制(Non-Maximum Suppression,NMS)过程的极大挑战,宽抑制会造成拥挤重叠目标的漏识,而窄抑制则会导致大量候选框的重复.Guo等人[15]提出AugFPN结构代替FPN结构,采用LSTM的思路对特征提取进行优化,但在拥挤场景中,后续过程中的NMS步骤将抵消所有增益,Zhang等人[16]设计了AggLoss,使得同一个目标的候选框能够更加接近,减少对重叠目标的干扰,Bodla等人[17]提出了soft-nms,候选框的得分取决于和目标对象的重叠程度,Liu等人[18]通过一个额外的分支来估计目标的密度以自适应调整nms.Rczatofighi等人[19]提出GIOU运算替换非极大值抑制中的IOU运算,通过增大预测框的大小使得其与目标框重叠,但带来了收敛速度慢和回归不准等问题.
此外,Ge等人[20]提出了PS-RCNN,利用P-RCNN检测无遮挡的目标并通过标记抑制,然后用S-RCNN检测遮挡目标并将两者结合.这种方法取得了相当不错的效果,证明了将目标分批处理思路的有效性.
为了提升密集重叠树木场景单棵树木检测的准确率,本文基于目标分批处理的思想,提出了一种基于迭代框架的密集场景单棵树木检测方法,该方法针对树木密集重叠的单棵树木检测做出优化,通过两轮训练将重叠度高的对象分配到两轮训练和测试中,减少彼此候选框之间的干扰,有效地提升遥感影像的单棵树木检测精度.
2 基于迭代框架的单棵树木检测
基于迭代框架的单棵树木检测过程如图1所示.整体框架包含两条支线:上一轮迭代边框处理支线和当前检测图像数据处理支线.为尽可能地避免密集重叠的树木对非极大值抑制过程造成的干扰,本文引入迭代边框,联合两条网络支线,对图像处理支线中得到的候选框进行反向筛选,使得网络能够注意到上一轮训练和检测中因重叠度高而被删去的候选框,从而检测到原先被漏检的树木,将结果和上一轮检测的结果结合得到更精确的检测结果.迭代框架中的网络模型D1和D2可以选用不同的基于锚框运算的网络模型,可以实验测试得到最适配环境的迭代组合.本节将详细描述框架内容.
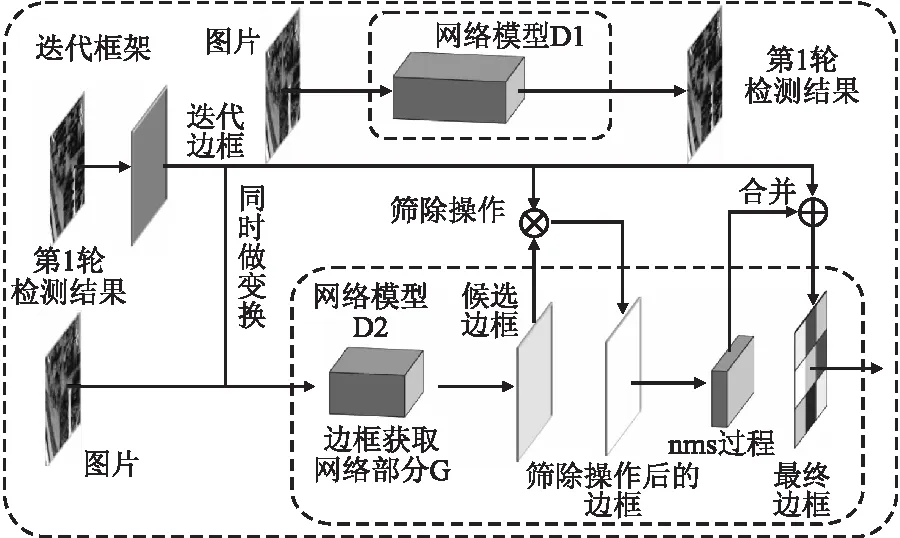
图1 迭代框架示意图Fig.1 Diagram of Iteration framework
2.1 迭代边框获取
如式(1)所示,本文首先用训练样本Is∈H×W×3对目标检测网络模型D1进行第一轮的训练,式子中,fD1表示网络D1的运算过程,θ表示网络D1的网络参数,记通过训练集进行训练后的网络的参数为θ′.然后用训练完的模型D1同时对训练样本Is和测试样本IT进行测试,得到对应的训练集边框Bs,测试集边框BT以及它们的得分Scores,ScoreT,边框和得分即本文所需要的迭代边框,其过程如式(2)所示:
BS,ScoreS=fD1(Is,θ)
(1)
BS,ScoreS,BT,ScoreT=fD1(Is,IT),θ′)
(2)

Biter=fconcat(BS,BT)
(3)
Scoreiter=fconcat(ScoreS,ScoreT)
(4)
Oiter=(Biter,Scoreiter)
(5)
2.2 边框引入
如式(6)所示,在第2轮训练中,迭代边框中的边框Biter部分会跟随训练样本IS作对应的变换(翻转,缩放),保持坐标相对应,式子中的ftrans表示图像随机变换操作过程,此过程会同时作用在迭代边框和输入图片上,保持两者变换过程同步.然后将变换后的边框和对应的置信度得分重新对应组合以进行后续的边框筛除操作.记第2轮训练的整体网络结构为D2,获取候选边框的前半部分网络为G,并将获取的候选边框记为OG,则候选边框的获取过程如式(7)所示,式子中的ν表示网络D2中获取边框部分网络的网络参数,fG表示网络G的运算过程.
Otrans=(ftrans(Biter),Scoreiter)
(6)
OG=fG(ftrans(IS),ν)
(7)
迭代边框的引入位置是在获取候选边框的网络部分之后,用极大值抑制对候选边框进行处理的步骤之前.取出处理管道中的迭代边框Oiter,对候选边框进行筛除的操作,以筛除第1轮检测中已确定的树木样本目标对应的候选边框,以降低其对重叠树木目标造成的干扰.
2.3 边框筛除
边框筛除的过程首先需要设置一个合适的阈值T,计算迭代边框Oiter与每个候选框OG的交并比IOU,仅保留与每个迭代边框IOU均不超过阈值的候选框.迭代边框,边框和筛除后得到的边框如图2所示.
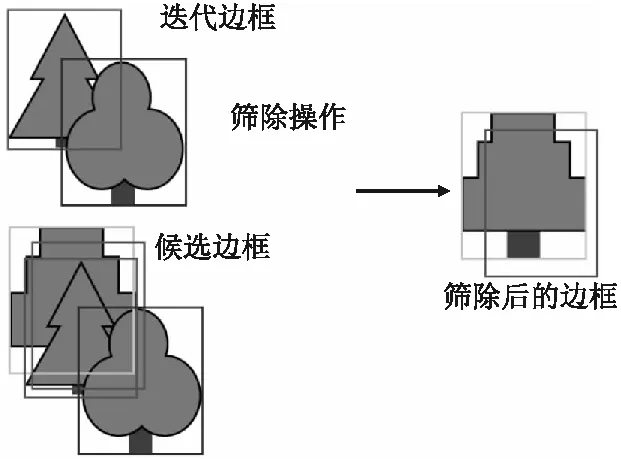
图2 边框筛除方法示意图Fig.2 Diagram of frame screening method
即属于在上一轮训练中已被检测出的目标的候选框将尽可能地被筛除,保留下来的则是因与上一轮检测目标重叠度高而在非极大值抑制环节被删去的候选框.IOU的计算方法如下,记两个需要计算交并比的边框为B1=(x1,y1,w1,h1),B2=(x2,y2,w2,h2),则交并比表示如式(8)所示:
(8)
其中areai表示两个边框交集部分的面积,其计算方式如式(9)所示:
areai=(Rmin-Lmax)·(Bmin-Umax)
(9)
其中Rmin表示边框交集的右边界,Lmax表示边框交集,Bmin代表边框交集的下边界,Umax表示边框交集的上边界,左右边界和上下边界的计算式子如式(10)~式(13)所示.
Lmax=max(x1,x2)
(10)
Rmin=min(x1+w1,x2+w2)
(11)
Umax=max(y1,y2)
(12)
Bmin=min(y1+h1,y2+h2)
(13)
记筛除后得到的边框集合为Oafter,则其计算的过程可以用式(14)表示,根据阈值T的不同取值,筛除后的边框Oafter可能存在不同的情况.式子中ffilter表示边框筛除的过程,即计算边框集OG与迭代边框集Oiter两两之间的IOU值,和设定阈值T进行比较,筛去集合OG和迭代边框集的交并比值超过设定阈值的边框.
Oafter=ffilter(OG,Oiter,T)
(14)
式子中ffilter的具体过程如算法1伪代码所示.
算法1.边框删除filter算法
Input:OG,Oiter
Parameter:T
Output:Oafter
1.LetOafter= {}
2.foro1inOG
3.foro2inOiter//和每个迭代边框进行比较
4. Letval= IOU (o1,o2) //计算边框交并比
5.ifval>T//交并比超过设定阈值则筛除
6.break
7. end if
8. end for
9.Oafter.add(o1)//筛选符合条件的边框
10.endfor
11.returnOafter
如图3所示,会出现像情况一这种仅筛除了属于第1轮检测得到的树木样本的边框以及一部分属于该样本的候选框,以及情况2这样属于第1轮检测得到树木样本目标的候选框被清除,这两种情况都是可接受的,是一种对后续非极大值抑制过程的正优化,情况3则是阈值设置不当导致原应被保留的候选框被多余过程筛除的情况.而实际筛除过程的情况并非完全像是情况图中的简单情况,而是需要网络综合考虑多组重叠情况的阈值选择,此部分在本章阈值相关的实验部分详细展开说明.
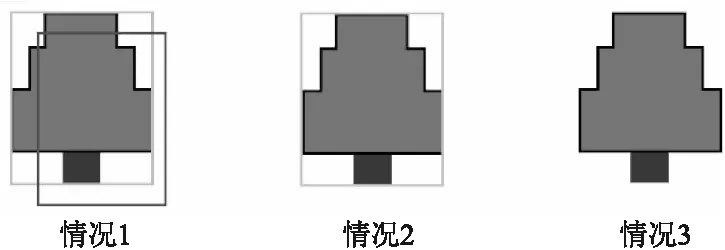
图3 不同阈值取值情况图Fig.3 Diagram of different threshold value situation
2.4 边框整合
如式(15)所示,在得到筛选后的候选框集后,对其进行非极大值抑制过程,得到分配到第2轮检测的难样本的检测边框集Ohard.
Ohard=fnms(Oafter)
(15)
本文将得到的第2轮检测边框集Ohard和迭代边框Oiter进行合并,然后按照置信度进行排序,得到最终的边框Oafter,如式(16)所示.置信度越高,表示边框中包含的物体是树木的概率就越高,将两个集合合并后按照置信度从高到低排序,方便后续流程对检测边框的处理.
Ofinal=fsort(fconcat(Ohard,Oiter))
(16)
这样得到的新候选框集合Ofinal中同时包含了上一轮检测得到的置信度较高,包含树木的候选框,和由于密集重叠被漏检的可能包含树木的候选框,由Ofinal进入后续的网络流程.
3 实验内容
3.1 数据集获取
传统的遥感数据保密性强,获取难度高,且网上并无公开的遥感树木数据集,一些研究者使用Google Earth影像数据进行研究[8,9,21],因为数据易于获取,且数据场景种类繁多.但Google Earth图像清晰度不足,且数据标注过程中无法对标注内容进行验证,数据标注难免出现纰漏.本文的树木图像数据在杭州某地(经度120.038,纬度30.226)校园内由航拍设备拍摄,区别于大多数树木数据集中规整,场景及树木种类单一,树木间距较大的人工种植林,本数据集中包含宿舍楼间,教学楼间,操场,街道,图书馆门口等树木场景,具有较多干扰项,且树木种类繁多,相互间重叠粘连,属真实树木种植场景.
对采集的图像数据进行筛选后共593张图片,尺寸均调整为600×1000,然后采用VIA(VGG Image Annotator)标注工具对采集的图片进行人工标注.标注得到共62616个样本,将其按照3∶1的比例随机划分为训练集46621和验证集,训练集16004个样本,验证集个样本.并将数据集调整为COCO的格式.标注内容均在数据采集地进行人工实地勘察比较,确保样本情况被准确标注.
3.2 评价指标
本文采用COCO格式的AP(Average Precision)和AR(Average Recall)作为评价指标,AR是召回率R的平均值,AP则是利用积分计算P-R曲线下包围的面积,P-R曲线中P和R指准确率和召回率,计算方式如式(17)、式(18)所示.
(17)
(18)
式子中的GT(Ground Truth)指的是标定框,公式中的TP和FP含义如下所示:
TP(True Positive):IOU(Intersection of Union)大于阈值的检测框数量(同一个GT(Ground Truth)的框只算一次).
FP(False Positive):IOU小于等于阈值的检测框数量或同一个GT的多余检测框.
IOU即面积交并比,用于衡量预测框和真实框的贴合程度.
3.3 实验设置
本文将所有图片调整到800×1333的大小,然后通过水平或垂直翻转并旋转90度来增加训练样本.实验采用SGD(随机梯度下降)作为优化器,初始学习率设置为0.02,在第8和第11个epoch衰减为上一次的一半.采用pytorch进行实验,模型训练均在RTX 2080TI GPU上进行.
3.4 基线模型
首先需要挑选基线模型进行基础迭代实验,经过比较,本文采用带FPN的Cascade R-CNN[22]作为基线模型,并用ROI Align替代ROI pooling层.本文中的IOU阈值实验以及后续组合迭代实验均基于级联神经网络进行.本节主要介绍基线网络结构,阐述其和遥感树木图像检测的适配程度.
3.4.1 级联神经网络
在过程中,遥感树木图像被分成图像批在提取特征后依次被输入每个分支网络,每个分支网络最后一层均为softmax层,并采用逐步提升的IOU阈值,每个候选框在逐个网络计算后得到一个介于0和1之间的分类概率,越大的值表示候选框内目标是树木的置信度越高,值越小则表示置信度越低.同时设置一组正负样本的阈值区间,前一个分支网络对该样本分类概率在正负样本阈值区间内,对应的边框才能递进到下一个分支网络提取更深层次的树木特征.而分类概率大于正样本阈值的可以在此分支被标记为易分正样本过滤,同理分类概率小于负样本阈值的被标记为易分负样本过滤.每经过一个分支网络,边框都会变得更准确,更高的阈值可以保证下一次回归的效果更好.
级联的方式使得大量的易识别树木样本在靠前的分支网络被检测出,后续的分支网络需要的训练样本就会有所减少,极大地提高网络的运行效率.同时每个支线网络是针对不同难度的样本进行训练的,提升了网络对难分样本的检测能力.
3.4.2 特征金字塔
考虑到树木数据集中树木目标尺寸不一,本文采用特征金字塔[23]来提取图片信息,首先自底向上提取树木的语义信息,然后依次采用最近邻插值法进行上采样,各层用1×1卷积降低通道数后和图右侧的同级特征图进行元素级相加(element add),这样就能很好地将浅层定位细节与上采样的高层语义结合,最后用的卷积做融合.
自顶向下的过程采用上采样将小特征图一步步放大使得和上一步的特征图匹配,上采样过程使用最近邻插值法,能够在上采样的过程中最大程度地保留特征图的语义信息,有利于后续的分类操作,同时将上采样特征和自底向上过程中高分辨率,有助于定位的特征图进行融合,得到既有良好空间信息又具有丰富语义信息的特征图.
3.5 IOU阈值实验
非极大值抑制的过程步骤如下所示:
1)首先设定树木目标候选框的置信度阈值,将低于置信度的候选框的置信度值置0.
2)对所有候选框按照置信度进行降序排列,方便后续过程按照置信度从高到底进行边框处理.
3)选择最高置信度的候选框加入集合,计算选择的候选框和剩下的同类候选框的交并比,将和其计算交并比在设定阈值以上的候选框的置信度值置0.
4)重复步骤2)、3),直到有置信度的候选框集为空.便完成了非极大值抑制的过程.
在非极大值抑制的过程中,重叠度高的树木样本会相互干扰,使得应该被保留的候选框因和已被选中的置信度高的候选框交并比过高而被筛除.因此分两轮训练,尽可能地在第2轮训练中排除第一轮选中的目标候选框对非极大值抑制过程的干扰,可以有效地解决这个问题.
如图4所示,在迭代框架的边框筛除过程中,过高的IOU阈值会使得属于第1轮检测出目标的候选框不能被完全筛除,过低的IOU阈值会使得理应保留的目标候选框被筛除.而在实际情况中,阈值的设置需要兼顾多组重叠情况,可能一个阈值在一组重叠中属于最优情况,而在另一组重叠中会导致目标候选框被误删,这些情况使得阈值的确定更为困难,因此需要实验确定一个合适的阈值,使得第1轮检测中得到的目标尽可能的被筛除且不影响剩余的内容.综上,本文首先对边框筛除的过程进行阈值实验.本文共设置了6组阈值进行实验,分别为0.7,0.75,0.8,0.85,0.9,0.95,为方便进行比较,实验的第1轮和第2轮训练均采用级联R-CNN,实验结果如表1和表2所示.

表1 IOU阈值实验准确率表Table 1 IOU threshold experiments accuracy table

表2 IOU阈值实验召回率表Table 2 IOU threshold experiments recall table
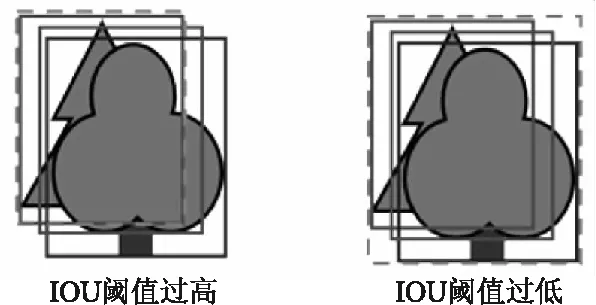
图4 IOU阈值设置图Fig.4 IOU threshold setting diagram
将指标APS,SPM,APL,ARS,ARM,ARL绘制折线图如图5所示,从折线图中可以发现,随着选定IOU阈值的上升,多数指标是逐渐上升的,而APL和ARL两条折线在IOU值为0.8时达到顶点。当IOU阈值达到0.8以上时,剩余指标的折线坡度并不显著,而和较大目标相关的两项指标则有所下降,说明过高的阈值更倾向于只筛除了第1轮检测目标对应的边框,而第1轮检测得到的目标的多余候选框被部分保留了下来,从而依旧会影响第2轮目标检测中的非极大值抑制的过程.综合考虑以上的情况,本文选择0.8作为选定的阈值进行后续的实验.

图5 IOU阈值实验折线图Fig.5 Threshold experiment line chart
3.6 自迭代实验
本文对几种常用的2阶段网络进行了自迭代实验,自迭代指的是第1轮和第2轮的实验均采用同一种主体网络.
3.6.1 Cascade R-CNN自迭代实验
首先对级联R-CNN进行自迭代实验,实验结果见表3和表4所示,可以看出效果提升较为明显,和分别提升了2.4%和2.7%,其中较大目标的检测上提升较明显,提升了7.8%,而小目标的检测上提升并不多,则仅提升了0.5%.

表3 CascadeRCNN自迭代实验准确率表Table 3 CascadeRCNN self iteration experiments accuracy table

表4 CascadeRCNN自迭代实验召回率表Table 4 CascadeRCNN self iteration experiments recall table
3.6.2 DCN-Net自迭代实验
DCN-Net(Deformable Convolution Network)为引入了学习空间几何形变能力的可变形卷积网络[24].相比于常用的3×3卷积核采样方式,可变形卷积在基础的卷积采样基础上加上了随机的偏移向量,这种方式使得感受野可变,可以在位置点附近随意采样,不再局限于规则格点.
本文对DCN-Net进行级联操作,在级联的DCN网络上的自迭代实验结果如表5和表6所示,APL和ARL提升了2.2%和2.4%,APS和ARS则仅提升了0.1%和1.1%.可以看到实验结果和Cascade R-CNN自迭代实验的结果较为相似,同样在大目标的检测上有较为明显的提升,而在小目标的检测上的提升则较低.

表5 DCN-Net自迭代实验准确率表Table 5 DCN-Net self iteration experiments accuracy table

表6 DCN-Net自迭代实验召回率表Table 6 DCN-Net self iteration experiments recall table
3.6.3 ResNeXt和ResNeSt自迭代实验
ResNeXt[25]和ResNeSt[26]是ResNet的两种优化的变种,其核心均是分组卷积,ResNeSt则是在ResNeXt的基础上借鉴了SK-Net,在分组卷积的基础上添加注意力机制进行优化.分组卷积将输入的特征图分成组,每个卷积核也对应分成组,在对应的组内进行卷积运算,共生成卷积核组数个特征图.
设g为分组的组别数,则输入每组的特征图尺寸为W×H×C/g,每个卷积核的尺寸为k×k×C/g,输出的特征图尺寸为W′×H′×g,参数量和运算量的计算如式(19)和式(20)所示,可以看到同样的参数量和运算量可以获得g个特征图.
(19)
(20)
ResNeSt和ResNeXt采用分组卷积,采用少量的参数和运算量就能生成大量特征图,而大量特征图就意味着更多的信息,能更好地完成树木检测任务.
本文分别对ResNeSt和ResNeXt网络进行级联,在级联ResNeSt和级联ResNeXt上的自迭代实验结果如表7和表8所示,可以看到在APL指标上两者都获得了高于3%的提升,而小目标相关的指标则没有较大的提升.

表7 自迭代实验准确率表Table 7 Self iteration experiments accuracy table

表8 自迭代实验召回率表Table 8 Self iteration experiments recall table
3.7 组合迭代实验
本文尝试了不同网络的组合,即第1轮训练和第2轮迭代训练的网络采用不同的网络,测试组合的效果.
3.7.1 ResNeSt和DCN-Net组合迭代实验
实验尝试了第1轮使用级联的ResNeSt进行训练,第2轮则换用级联的DCN-Net进行训练和测试,实验结果如表9和表10所示.可以看到ResNeSt和DCN-Net组合迭代的情况下,相比于DCN-Net和ResNeSt两个本体网络APL指标上均有所提升,但相比于ResNeSt部分指标甚至有所下降;和DCN-Net自迭代的实验结果相比,各项指标均有所提升,AP和AR分别提升了2.4%和1.5%,但和ResNeSt自迭代实验相比,AP和AR则分别下降了1.5%和0.7%,其余各项指标也均有下降.
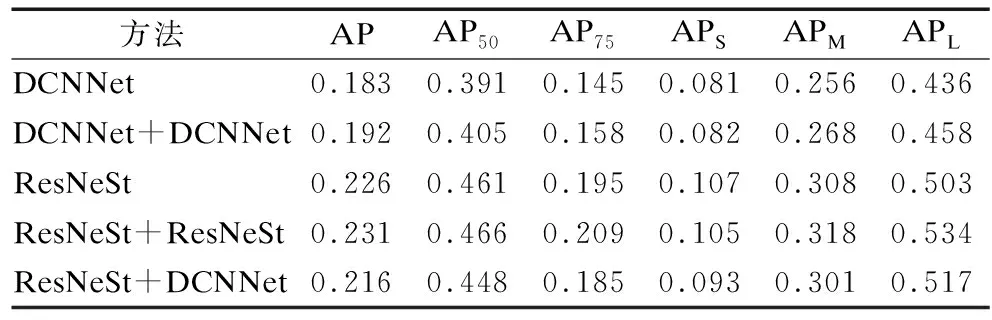
表9 组合迭代实验1准确率表Table 9 Combinatorial iteration experiment 1 accuracy table

表10 组合迭代实验1召回率表Table 10 Combinatorial iteration experiment 1 recall table
3.7.2 ResNeSt和ResNeXt组合迭代实验
ResNeSt和ResNeXt的组合迭代实验采用级联的ResNeSt作为第1轮训练的主体网络,用级联的ResNeXt进行第2轮的训练和测试,实验结果如表11和表12所示,ResNeSt和ResNeXt组合迭代的情况下,相比于ResNeXt自迭代在小目标的检测上有所提升,APS和ARS分别提升了0.2%和0.6%,相比于ResNeSt自迭代在小目标的检测上提升更为明显,APS和ARS分别提升了0.9%和0.9%.而在其它指标上没有明显的差距.可以看到由于ResNeSt和ResNeXt同样是采用了分组卷积的结构,且检测能力较为接近,这种组合迭代的方法相比自迭代方法并没有检测能力的下降,相反则一定程度上补足了小目标检测能力的缺陷.
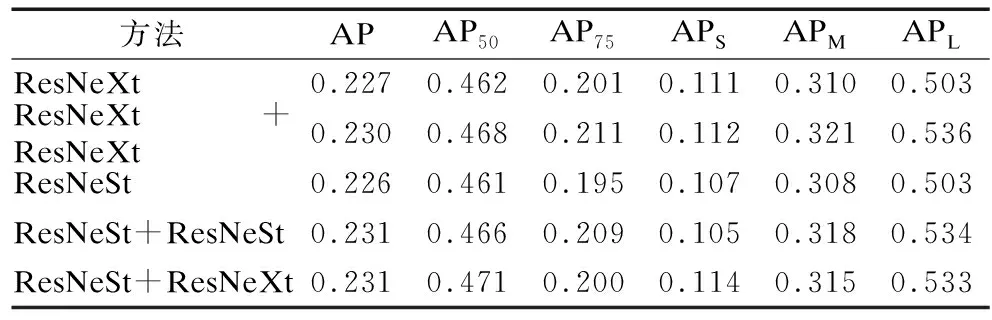
表11 组合迭代实验2准确率表Table 11 Combinatorial iteration experiment 2 accuracy table
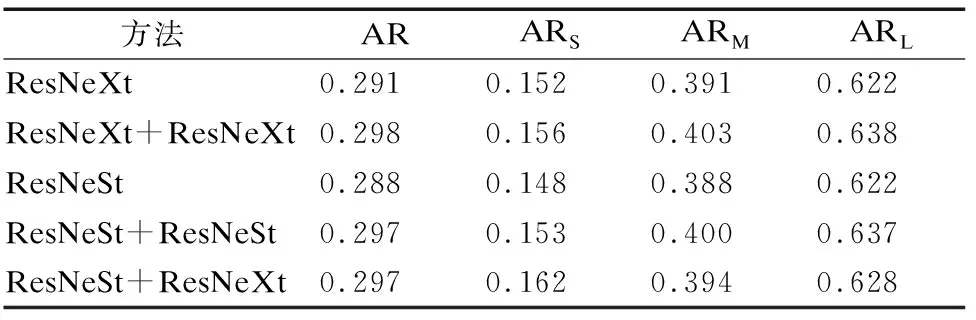
表12 组合迭代实验2召回率表Table 12 Combinatorial iteration experiment 2 recall table
可见差距过大的网络组合时,指标会介于两者的网络自迭代效果之间,远不如指标较高的网络自迭代.性能相对接近的网络组合时,效果相对于两个原网络均有所提升,和网络自迭代的效果相比,在某些指标上拥有优势.
3.8 与现有其他检测方法的比较
为评价基于迭代框架的单木检测方法的性能,本节在密集树木数据集上选用了一些先进方法进行了实验比较,实验结果如表13和表14所示.本文在实验区域进行可视化,其结果图局部的对比如图6所示,从图中可以看出本文方法在密集重叠的树木样本和小目标树木样本上均有不错的检测结果,而其他先进检测方法则存在小目标的误识漏失情况,且一定程度上会受到密集树木情况的干扰.

表13 比较实验准确率表Table 13 Comparative experiment accuracy table
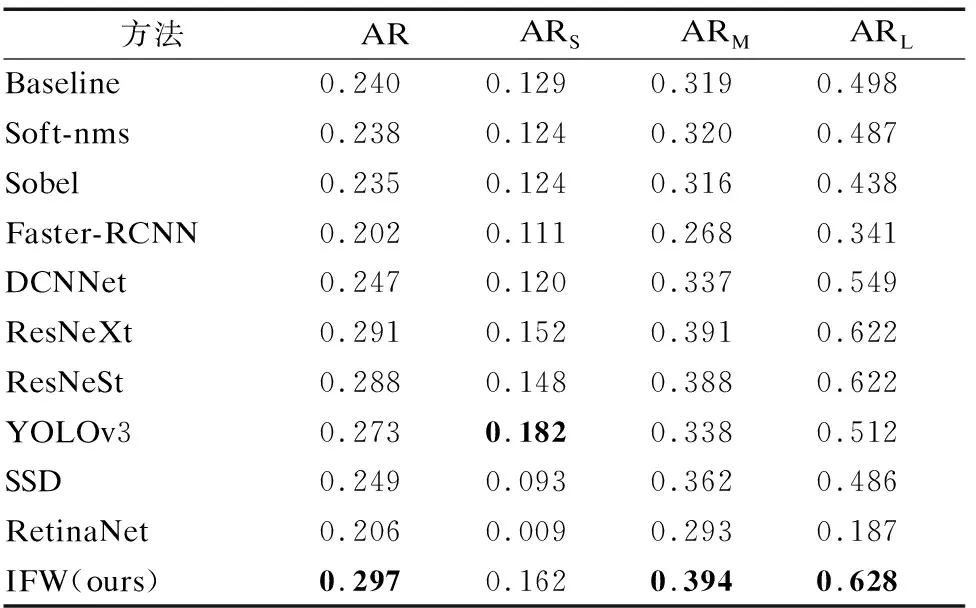
表14 比较实验召回率表Table 14 Comparative experiment recall table

图6 检测方法对比Fig.6 Comparison diagram of detection methods
考虑到单棵树木检测中树冠边缘的重要性,本文尝试对遥感图像中的线条信息进行强化,采用Sobel算子计算图像灰度的近似梯度,作为额外辅助信息对树木检测进行优化,从实验结果可以看出,强化边缘的做法在密集复杂的遥感树木图像中并不能起到很好的效果.可能是因为在枝叶粘连的情况下,强化的边缘信息会对检测造成干扰.Soft-nms方法是根据重叠程度用权重函数对有重叠检测框的置信度进行衰减的方法,在多数目标检测任务中具有比较好的应用效果,因此本文也选用这种方法对基线模型进行优化尝试,但在密集粘连的树木情况下,大量的重叠衰减使得这种方法成为了一种负面优化.
从表中可以看出,YOLOv3[27]得益于本身的多尺度优化,在小目标的检测上具有相对较好的效果,ARs指标在一众算法中最高,而RetinaNet[28]所采用的Focal Loss在平衡正负样本的同时将训练重心放到了稀疏样本上,在密集且粘连的目标情况下表现并不佳.本章提出的迭代方法和baseline相比AP和AR分别提升了5.6%和5.7%,AP上比YOLOv3高3%,比Faster-RCNN高10.6%,优化效果显著.
4 结 论
本文提出了一种迭代方法,通过将属于密集重叠树木目标分配到两轮训练检测中,减少了重叠粘连树木目标之间的干扰,有效地提升了在密集树木数据集上的检测性能,该方法可以采用不同的现有先进网络进行迭代训练,检测精度较原网络均有明显的提升.本文提出的方法不需要对网络结构有较大的改动,可以简单地替换两轮训练中的主干网络结构,尝试更多的组合迭代效果,根据不同的树木环境情况,更好地对检测过程进行优化.
对于迭代方法,本文首先探究了候选框筛除过程中交并比阈值对训练检测结果的影响,通过消融实验确定了在本文的树木数据集上最为合适的阈值以进行后续的实验.同时在树木数据集上和其他先进的检测方法进行了比较,证明了本文方法的优越性.此外,本文尝试了ResNeSt、DCN-Net等不同网络的组合,发现性能较为接近的网络有更好的相性,在某些指标上具有一定的优势.
在实验中可以发现,迭代训练方法因为筛除候选框的过程带来了额外的计算成本.因此,未来将对候选框筛除的过程进行优化,在不影响网络性能的前提下,节约计算成本.
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
核科学与工程(2021年4期)2022-01-12
计算机工程与科学(2021年4期)2021-05-11
计算机应用(2018年5期)2018-07-25
火力与指挥控制(2018年3期)2018-04-19
摄影之友(影像视觉)(2018年1期)2018-03-22
摄影之友(影像视觉)(2017年11期)2017-11-27
中国照明(2016年6期)2016-06-15
轴承(2015年2期)2015-07-25
