
基于改进的RetinaFace 人脸检测方法
2023-11-13 16:10李云鹏席志红
应用科技 2023年5期
李云鹏,席志红
哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
人脸检测技术是人脸识别[1]的前提,只有检测到人脸并且提取出相关的信息,如人脸的位置坐标、表情、年龄、姿态等,才能应用到相应的实际需求中,提高智能化的水平。近年来,随着计算机视觉领域的发展和深度学习的提出,人脸检测取得了重要的突破,并逐步应用到人们的现实生活中。
人脸检测可以分为2 个研究方向,一个是传统的基于手动提取特征的人脸检测,Viola 等[2]提出的图片Haar 特征提取算法(线性特征、边缘特征、中心特征和对角线特征),然而传统的检测算法不仅需要人工进行手动提取特征,相对费时费力,而且特征表达能力有限,在复杂环境下,不具备良好的检测性能。随着2012 年Hinton 等[3]提出卷积神经网络,越来越多的科研人员对其进行研究与创新,人脸检测技术也随着深度学习的提出取得了进一步的发展。基于深度学习的人脸检测算法可以分为2 类:一种是先生成候选区域,再通过卷积神经网络预测目标的双阶段(two-stage)方法,如基于区域的快速卷积网络(fast region based convolutional network,Fast R-CNN)[4]、空间金字塔池化网络(spatial pyramid pooling,SPP-Net)[5],特点是精度很高,但是检测速度很慢;另一种是直接通过神经网络进行预测目标的单阶段(onestage)方法,如YOLO[6]系列(V1-V5)、RetinaFace[7]算法等,特点是速度和精度相对均衡。其中本文使用的Retina-Face 是一种基于滑动窗口,自监督与额外监督结合的多任务学习,通过回归人脸的眼睛、鼻子和嘴巴5 个关键点,对不同尺寸的人脸进行像素级的定位,对于人脸检测有比较好的结果。本文采取MobileNetV3[8]网络替代RetinaFace中的特征提取网络,大幅度降低参数和计算量;然后在骨干特征提取网络与特征金字塔之间引入高效通道注意力机制(efficient channel attention,ECA)[9]模块提高特征融合阶段特征信息的利用率,使用Soft-NMS[10]非极大值抑制代替原始的非极大值抑制(non-maximum suppression,NMS)降低在候选框重合面积太大而被误删,降低了人脸的误检率。改进后的RetinaFace 网络,保证了检测速度的同时也兼顾了检测的精度,提高了人脸检测的平均精度。本文的具体工作如下:1)对RetinaFace 框架和原理进行介绍;2)对改进部分进行介绍;3)通过对比试验证明其可行性。
1 RetinaFace 人脸检测算法
1.1 总体概述
RetinaFace 是帝国理工、伦敦米德尔塞克斯大学、InsightFace 等团队在2020 年提出的One-Stage 的人脸检测算法,它利用自我监督和联合监督的多任务学习,在不同的人脸尺度上能够执行像素方面的人脸定位。有RetinaFace-Resnet 和RetinaFace-MobilenetV1(0.25)共2 个版本,其中基于Resnet 的有很高的精度,基于Mobilenet 的检测速度更快。RetinaFace 由主干提取网络、特征金字塔(feature pyramid networks,FPN)、单极无头(single stage headless,SSH)特征提取和检测层(Head)共4 部分组成,其中RetinaFace(骨干网络选Mobilenet 为例)网络结构如图1 所示。
1.2 特征提取层Backbone
RetinaFace 的特征提取层是MobilnetV1[11],其采用了深度可分离卷积(depthwise separable convolution),先用厚度为1 的3×3 的卷积核(depthwise)分层卷积,再用1×1 的卷积核(pointwise 卷积)调整通道数,将特征提取与特征组合分开进行,大幅度减少了运算量和参数量。其中MobilnetV1-0.25 是将MobilnetV1 的通道数压缩为原来的1/4网络,提高特征提取的速度。
1.3 FPN 特征金字塔
FPN[12]特征金字塔是利用1×1 的卷积对有效的特征层(featuremap)进行通道数的调整,然后利用Upsample 上采样和Add 进行的特征融合。将MobilnetV1-0.25 中最后3 个有效特征进行FPN 操作。把高层的特征传下来,补充低层的语义,可以获得高分辨率、强语义的特征,有利于小目标的检测。
1.4 SSH 特征提取
SSH 特征提取层采用了3 个并行结构,利用3×3卷积的堆叠代替5×5与7×7卷积的效果,主要包括3 部分组成:左边的是3×3卷积;中间利用2 次3×3卷积代替5×5卷积;右边利用3 次3×3卷积代替7×7卷积。SSH 通过在特征图中引入上下文信息来提高小人脸的检测。
1.5 Head 层
RetinaFace 的 Head 层输出80×80、40×40、20×20共3 个不同尺寸的特征图,第1 个用于分类预测(face or not),判断先验框内部是否包含物体,利用SoftMax 进行二分类每个先验框内部包含人脸的概率;第2 个用于人脸框的回归(bbox)先验框进行调整获得预测框;第3 个用于人脸关键点回归(landmarks) 对先验框进行调整获得人脸关键点;经过Head 完成调整、判断之后,还需要进行非极大值抑制(即筛选出一定区域内属于同一种类得分最大的框)。
2 改进的Retinaface 算法
2.1 特征网络
Retinaface 的骨干网络为MobileNetV1,虽然使用了深度可分离卷积极大地降低了模型的参数提高了检测的速度,然而V1 的结构过于简单,类似于1 个直筒结构,导致这个网络的性价比不是很高。本文将骨干网络替换为MobilNetV3,提高人脸检测的性能和速度。MobilNetV3 更新了bneck结构如图2 所示。
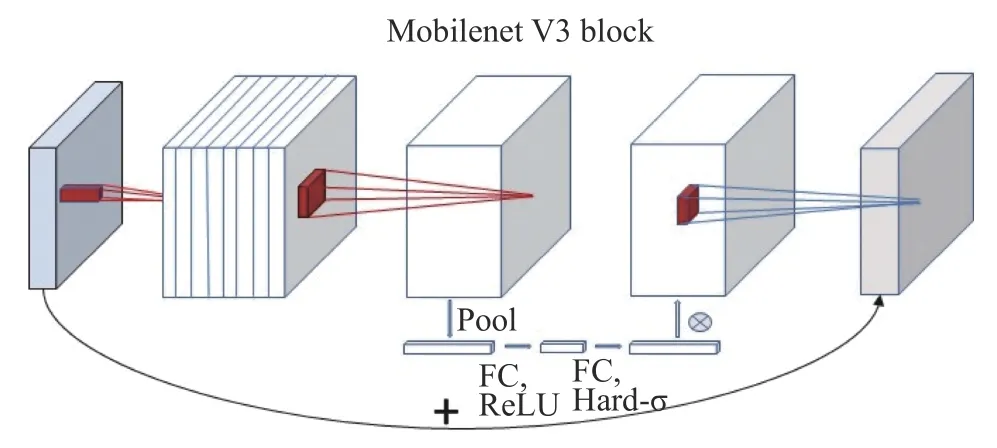
图2 bneck 结构
由于激活函数对低维度的特征会造成更多的信息丢失,而对于高维度的特征的丢失会少一些,通过一般卷积进行升维,再通过深度可分离卷积操作,再通过一般卷积进行降维,最后再进行残差相加的倒残差网络结构。此外,更新了网络结构,加入轻量化的SE[13](squeeze and excite)结构,在bottlenet 结构中加入了SE 结构,将其放在了depthwise filter 之后,在含有SE 结构中扩展层的通道数变为原来的1/4,这样不仅没有增加时间的消耗,还提高了精度。swish 非线性激活函数是谷歌团队自研的激活函数,能够有效提升网络精度,其公式为
然而swish 的计算量太大,将swish 替换为改进的h-swish,改进的h-swish 函数如下:
改进的h-swish 非线性激活函数提高了计算的速度,对量化过程更加友好。
另外重新设计耗时层结构如图3 所示。第1 个卷积层的卷积核的个数由32 降低为16,准确率保持不变时降低运算量。在原始的最后阶段一般是先经过4 个卷积操作,然后再进行平均池化再经过卷积输出,而在MobilNetV3 最后阶段是卷积后直接进行平均池化然后再经过2 个卷积进行输出,降低了很多层结构,在保证精度的情况下提高速度。
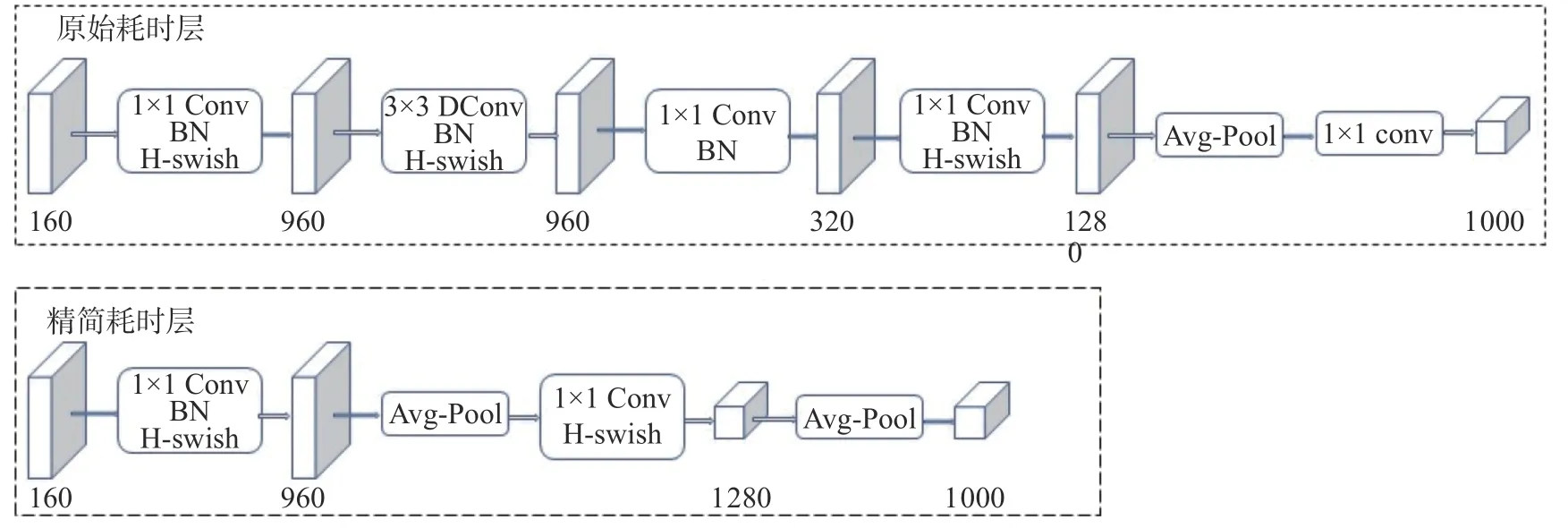
图3 耗时层结构
MobileNetV3 如表1 所示,其中bneck 是网络的基本结构,SE 表示在网络结构中是否使用注意力机制,NL 代表激活函数的类行,包括改进的HS(h-swish)以及RE(ReLU)激活函数,在此网络中输入图片的大小为2242×3,经过卷积池化后输出的向量大小为12×1 280。
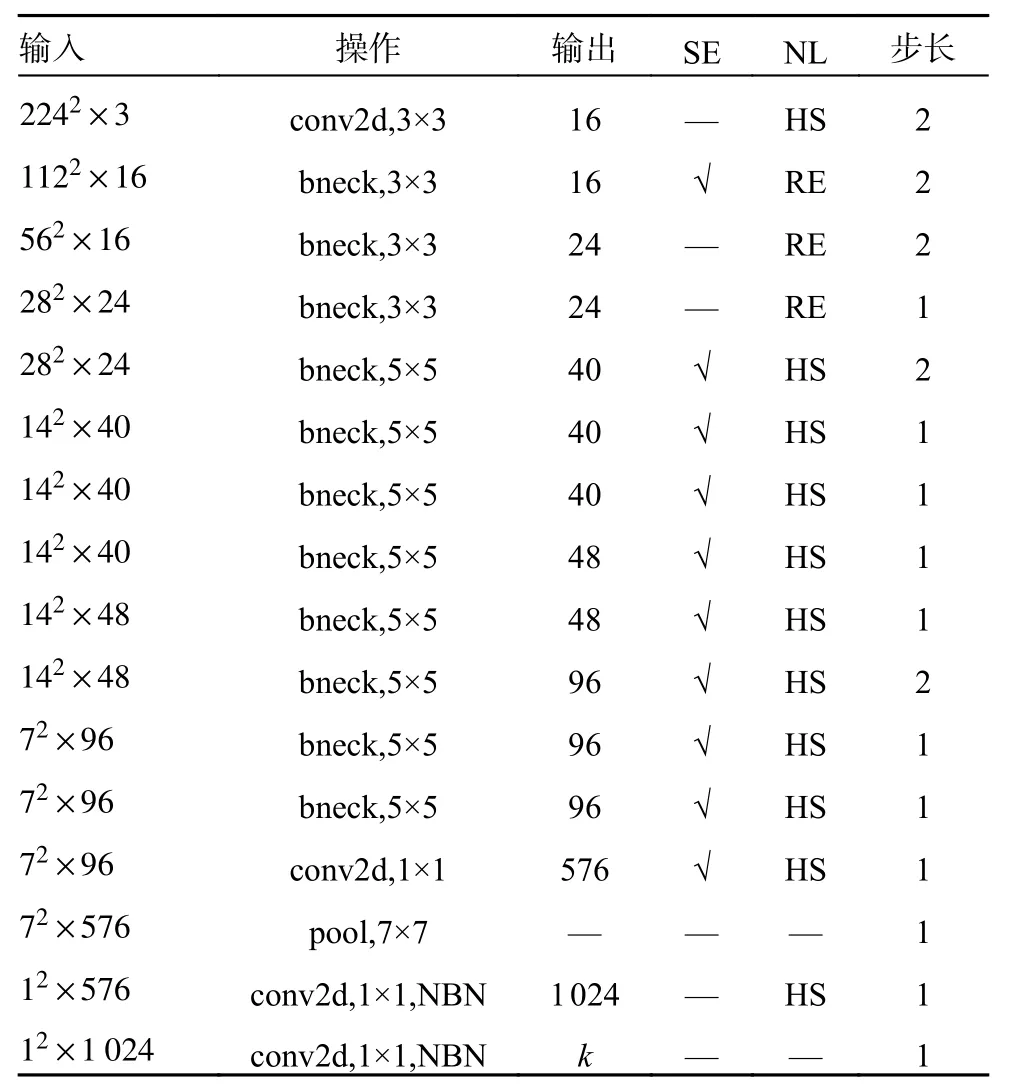
表1 MobileNetV3 网络结构
本文将Retinaface 的骨干网络MobileNetV1替换为更准确高效的MobileNetV3,提高对于人脸特征的提取。
2.2 ECA 注意力机制
为了提高对人脸特征信息的利用率,本文引入了ECA 注意力机制模块,ECA 是对于SE 机制中降维产生的负面影响进行改进。SE 模块如图4 所示。
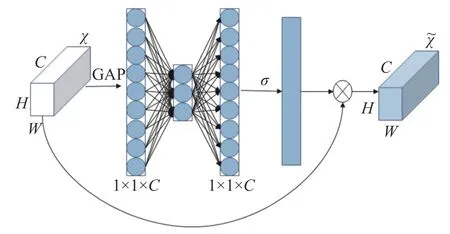
图4 SE 模块
图4 中可以看出SE 是先降维然后在升维,对于通道注意力预测有一定的负面影响,ECA 是一种不降维的局部跨信道交互策略和自适应选择一维卷积核大小的通道注意力机制,其中适当的跨信道交互可以在保持性能的同时降低模型的复杂度。在去除了原来SE 模块中的全连接层,直接在全局平均池化之后的特征上通过一个卷积核大小为K的1D 卷积进行学习,然后再经过一个sigmod函数生成通道的权值。
其中卷积核k的大小与通道数相关,其公式为
式中:C为通道数; γ、b是非线性参数, γ设置为2,b设置为1。卷积核的大小受通道数所影响,C越大K的值越大。本文对Retinaface 网络进行改进在主干网络与FPN 之间加入ECA 模块,加强对于骨干特征网络信息提取的利用率 提高对于小人脸的检测能力[14]。ECA 模块如图5 所示。
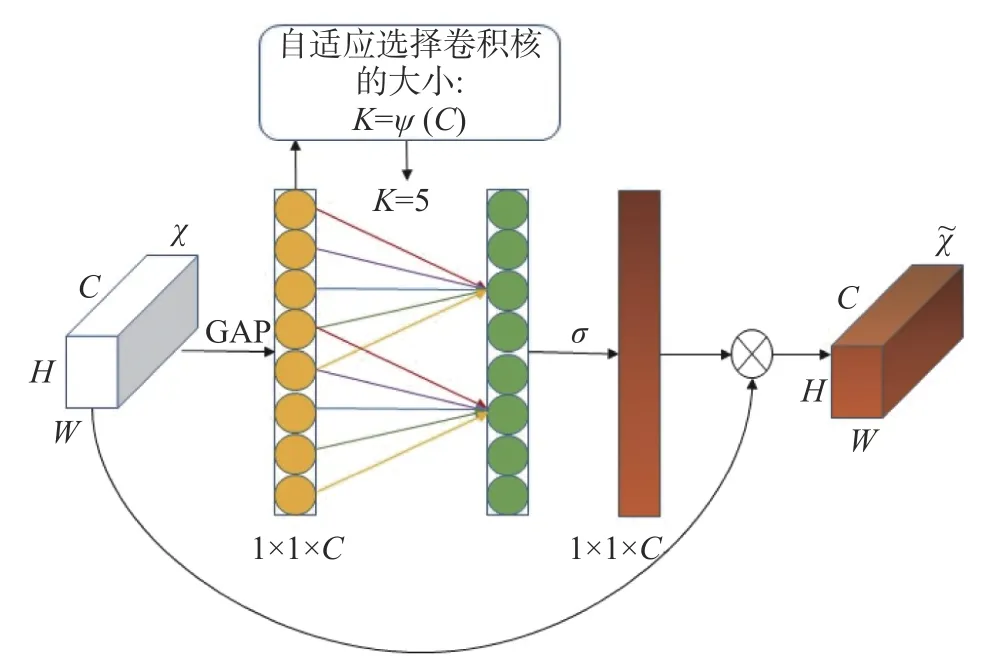
图5 ECA 模块
2.3 Soft-NMS 非极大值
NMS 与Soft-NMS[15]都是对目标检测中区域提取网络和边界回归网络候选区域的筛选过程。图像中的目标具有多个候选的边界框(bounding box),要选取置信度(confident socre)最高的候选边界框,同时尽量降低对同时存在的同一类别其他物体的影响。然而NMS 对于相邻检测框的交并比(Intersection over Union,IoU)[16]IoU直接设置为0,其中IoU 时交并比,表示2 个框的重合程度,其公式为
当IoU 越大表示2 个相邻检测框的重叠程度越高,当IoU 的值为0 时意味着2 个检测框没有重合,IoU 的值为1 时表示2 个检测框完全重合。
如果2 个同类有重叠、相互遮挡时,对于这2 个目标的检测框是重合程度很高相互靠近,即IoU 的值很高,使用NMS 算法后,会把2 个检测框中socre 较低的设置为0 强制删除。其公式为
为此Soft-NMS 在对于同类别重合时,对于相邻检测框的socre,不是像NMS 那样强制的直接设置0,是降低相邻检测框的score,虽然利用一个基于与IOU 相关的函数导致score 被降低,但相邻的检测框仍在物体检测的序列中。公式为
式中:Si为候选框得分,Nt是NMS 阈值,NMS 算法将IOU 大于阈值的窗口的得分置为0。
对于同一类别的检测,在2 个或多个待检测目标发生重合时,NMS 算法由于其强制将重合中较低的score 设置为0,很容易导致在最后的检测目标的缺失,另外当待检测目标周围有其他遮挡物遮挡时也有可能会无法检测出目标。Soft-NMS 算法不仅保留了交并比并不是最高的重叠物体的预测框,并通过相关函数给予这些预测框一个分数,使其保存在检测序列中,之后再进一步筛选,有效地解决了物体被遮挡的问题。
3 实验结果与分析
3.1 实验环境
本文实验环境为:英特尔Corei7-8 700@3.2 GHz 六核处理器,16 GB 内存;显卡为NVIDIA GeFore GTX1070;Windows 10,64 位操作系统;学习框架为pytorch 1.10.1;Cuda 11.6。
3.2 实验数据集
WiderFace 数据集是人脸检测中主流的数据集,它是由香港中文大学发布的大型人脸数据集,该数据集的图片来源于WIDER 数据集,从中挑选了32 203 张图片进行人脸标注,总共标注了393 703 个人脸数据,其中158 989 个标注人脸用于训练,39 496 个标注人脸用于验证。在每一个子集下划分了easy、medium、hard 共3 个级别的检测难度 ,评价在不同难度的情况下的检测精度。WiderFace 数据集40%、10%、50%分别作为训练集、验证集和测试集,数据集中的人脸在尺度、姿态、表情、遮挡和光照等方面又很大的变化范围。本文选择WiderFace 数据集作为实验数据集。
3.3 评价指标
为了展现对于人脸检测的效果,本文设置了每秒传输帧数(frames per second,FPS)和精度值(average precision,AP)2 个评价指标。相关公式为
式中:Pre为精度(precision),R为召回率(recall),NTP(true positive)代表的是预测框中预测为真实际也为真,NFP(false positive) 代表的是预测框预测为假实际为真,NFN(false negative) 代表的是预测框预测为假实际为假。以Pre作为纵坐标、R作为横坐标把每一次的结果计算出来,并按照关系绘制出曲线,AP就是经过插值的precision-recall 曲线与x轴包络的面积。对于FPS,一般来说当大于25 f/s 时可以具备实时性,对于AP 而言其值越大表示检测效果越好。
3.4 实验设置
本文选择pytorch 深度学习框架训练,采用SGD optimiser 作为模型的优化器,训练150 个轮次(epoch);批次大小(batch size)设置为8;初始学习率设置为0.01,经过150 个epoch 后达到0.001;动量(momentum)为0.9;权重衰减(decay)设置为5×10-4,Soft-NMS阈值设置为0.5,训练集验证集的输入图片均为640×640×3。
3.5 仿真特征图与消融实验
RetinaFace 人脸检测由骨干网络、FPN 特征金字塔、SSH 特征提取、head 共4 部分组成,其中骨干网络、FPN 以及SSH 是提取人脸信息。以图6为原始人脸图片,经过各个阶段后的特征图可视化结果。

图6 人脸图片
图7 为人脸图片在经过没有改进的RetinaFace后的特征图可视化结果。

图7 可视化图
图7 中,上面3 张图是经过骨干网络后3 个通道的可视化结果,网络层越深提取的抽象;中间3 张图是经过FPN 特征金字塔后的可视化结果,其中最左侧的提取的有效信息很少;下面3 张图是经过SSH 特征提取后可视化效果图,由于FPN 提取的有效信息少,造成SSH 不能够很好地利用人脸信息,如图7 左侧结果图所示。
改进后的RetinaFace 在更换骨干网络以及在FPN 之间加入了ECA 注意力机制。改善后的部分如图8 所示。

图8 改进后的可视化图
图8 上面2 张图分别为更换骨干网络MobileNetV3、ECA 注意力机制的可视化结果,下面2 张图分别是FPN 金字塔以及SSH 的可视化结果,相比之下加入ECA 注意力机制后,FPN 特征金字塔以及SSH 特征提取能够提取出关键的人脸特征,有效地改善了对于提取人脸信息的效果。
为了验证改进算法对于RetinaFace 的优化效果,在widerface 数据集上,对比原始算法设置了1 组消融实验,消融实验包括3 个改进方面的对比:第1 个是替换骨干网络简记为V3;第2 个是加入ECA 注意力机制;第3 个是使用Soft-NMS非极大值抑制。逐步增加改进方式,通过对比其检测的结果,验证算法改进后的效果。如表2 所示,其中√表示在RetinaFace 人脸检测网络中用此种方法,Easy、Medium、Hard 分别是在数据集3 种模式下的检测精度,检测速率为每秒的传帧数。
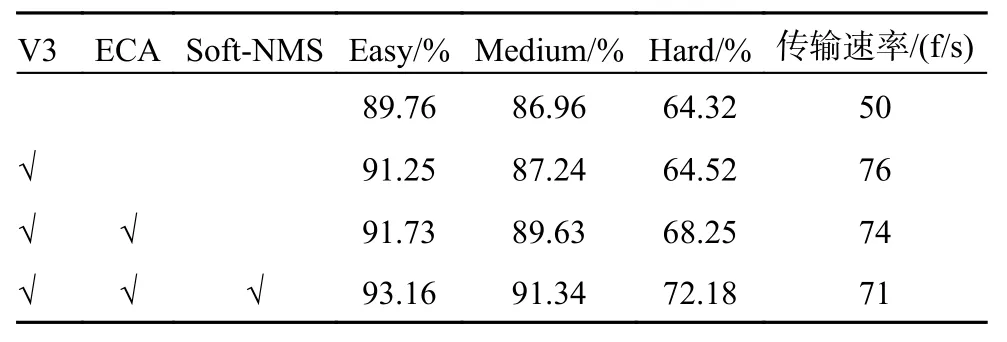
表2 消融实验对比
表2 中可以看出,在更换网络后,FPS 的值有很大提升,加入ECA 注意力机制和Soft-NMS 后检测精度有所提升,由于加入新的模块计算量增加,造成话检测的速度FPS 的数值有所下降,但满足实时性的要求。
3.6 实验结果与分析
考虑到本文提出的改进网络是用于人脸实时检测的,在减少参数和计算量的同时要保留较高的检测精度, 故选择Fast R-CNN 、 MTCNN、RetinaFace-Resnet50、RetinaFace-MobileNetV1 作为对比,所有算法均在Wider Face 数据集上进行的测试。可以看出本文提出的算法与其他算法相比有明显的优势。测试对比结果见表3。
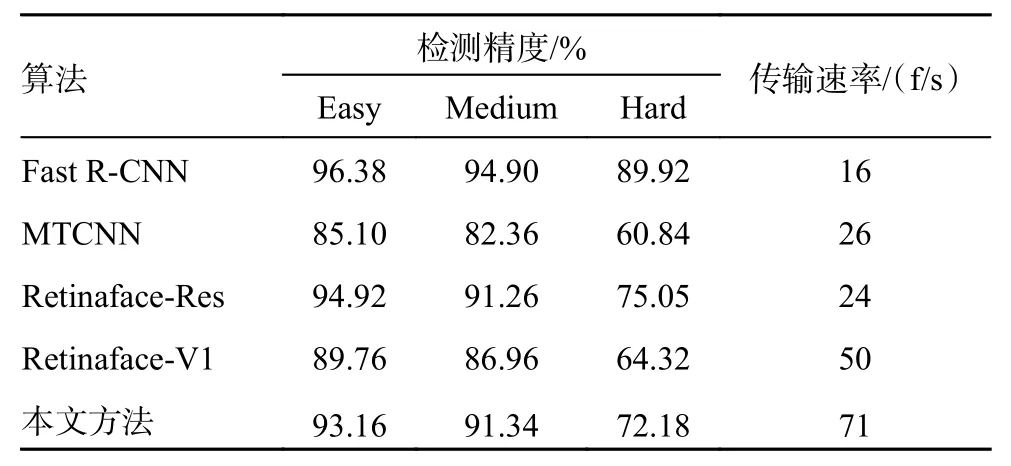
表3 测试对比结果
由表3 可知,Fast R-CNN 在3 个样本下的检测精度都很高,但是由于它为two-stage 大型网络计算量比较大,所以它的检测速率非常的低,RetinaFace 作为one-stage 网络平衡精度和检测的速度,本文改进的网络与RetinaFace-MobileNetV1相比无论是精度还是检测速度都很大的提高,RetinaFace-Resnet50 虽然在检测精度上略微高于本文检测网络,但是在检测速度上本算法有绝对的优势。
图9 给出了RetinaFace-ResNet、 RetinaFace-MobileNetV1 以及本文改进算法的检测效果,表4给出了图9 中原始图像经过改进Retinaface 后的部分人脸预测框的分数列表,Retinaface 在检测上存在部分漏检,能够检测出部分人脸,但是对于遮挡,hard 数据集上还是有改善的空间。
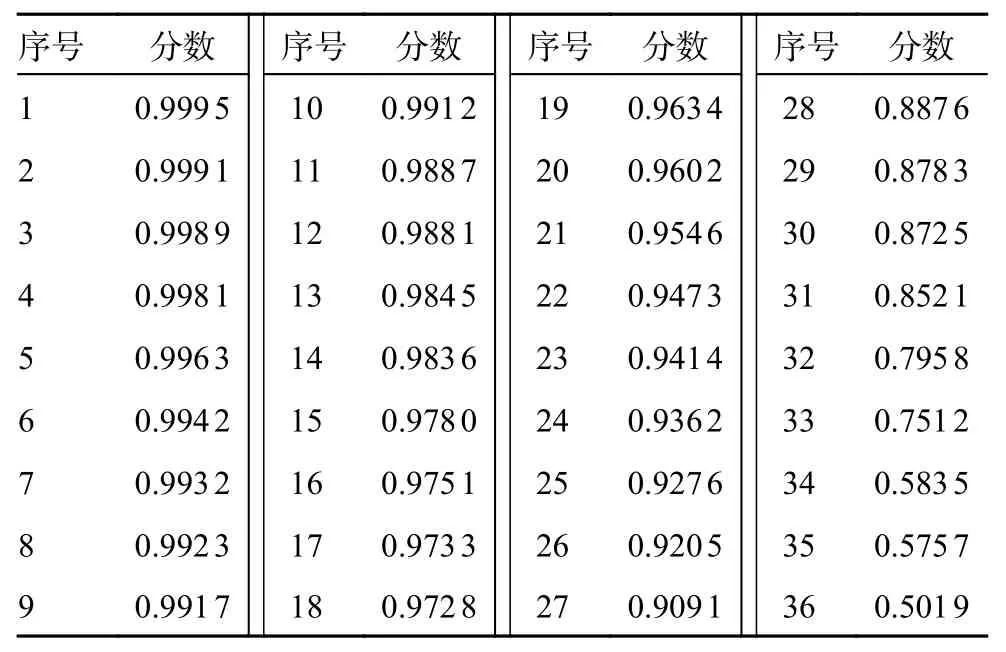
表4 预测框分数列表

图9 检测效果
4 结论
本文改进了Retinaface 人脸检测网络,使用MobileNetV3 网络代替原版的Retinaface 的骨干网络,相比较而言 MobileNetV3 减少了卷积参数的运算,大幅度减少了网络的计算量提高检测的速度,此外,在骨干网络与特征层之间加入ECA 模块,提高对于人脸特征信息的利用率,提高检测精度,将Soft-NMS 代替NMS,改善了在人脸遮挡重合时的NMS 直接将相邻检测框直接设置为0,造成在检测结果中某些目标的缺失。经过实验证明,本文提出的改进型的RetinaFace 算法在提高AP 的同时,提高了FPS,能够很好地完成实时情况下的人脸检测任务。
此外,在研究时发现在人脸密集、遮挡严重的hard 样本下检测精度还有较大的提升空间。之后,本文将考虑进一步优化Retinaface 算法的网络结构,考虑主干特征网络优化,替换其他注意力机制模块,提高人脸信息的利用率,增强对于hard 样本的检测能力。在保证网络的实时检测速率前提下,提高hard 样本的AP。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
当代水产(2019年11期)2019-12-23
电子制作(2018年19期)2018-11-14
动漫星空(2018年9期)2018-10-26
知识经济·中国直销(2017年5期)2017-06-15
自动化学报(2017年11期)2017-04-04
发明与创新(2015年33期)2015-02-27
噪声与振动控制(2015年4期)2015-01-01
奇闻怪事(2014年5期)2014-05-13
中国学校体育(2014年11期)2014-05-10
