
随机森林法在母型船选型中的应用研究
2023-11-13 16:10张明霞赵桐鸣王思沂
应用科技 2023年5期
张明霞,赵桐鸣,王思沂
大连理工大学 船舶工程学院,辽宁 大连 116024
随着信息化发展,利用大数据获得有效信息并用于行业发展成为智能化时代的热点之一。船舶设计过程涉及范围广、生命周期长,船型技术经济论证非常必要。在船型技术经济论证中选取母型船多依靠设计者的经验进行,主观依赖性较强,无法充分搜寻到各方面参数及综合性能最接近设计方案的母型船;另一方面大量实船数据未得到充分利用,浪费了有效数据资源。而将知识工程应用到母型船选型中是实现船舶设计智能化的有效途径。
知识工程(knowledge engineering)是1977 年美国斯坦福大学的费根鲍姆提出的[1],以知识为对象,通过智能软件建立专家系统,将收集到的知识储存在计算机中,模拟人类推理及搜索过程进行专业问题的智能化求解,其主要环节包括知识获取、表示及推理。基于案例推理(case-based reasoning, CBR) 是Schank 等[2]于1979 年首次提出,是利用先前的案例和经验解决类似问题的方法。在船舶领域中, Turan 等[3]采用基于普通权重的最邻近算法,提出了基于CBR 的决策支持系统,并应用在干货船和客运滚装船设计中,能快速确定主尺度与船型;陈小雅[4]构建集装箱船知识库,使用基于层次分析法的最邻近算法进行相似度计算,运用基于实例和规则推理的混合推理法对集装箱船进行主尺度方案设计;黄本燊[5]基于CBR 将主观因子法与熵值法结合对母型船进行相似度评估,为母型船选型提供了新方法。
随机森林算法(random forest,RF)是由Breiman等[6]于2001 年提出的一种机器学习算法,多用于分类和预测。由于随机森林算法在分类时可以衍生获得特征属性权重,因此可以应用在案例推理中。张华年[7]提出了随机森林加权的最近邻算法,构建了混合案例推理系统,实现了应急预案智能化。在船舶领域中,Lee 等[8]使用决策树、随机森林等算法对船舶靠泊速度影响因素进行重要性分析,并使用混淆矩阵评价结果。本文将随机森林算法应用到母型船选型中,以实现选型的智能化。
1 案例检索
案例检索是从案例库中检索出与目标案例最相似案例的过程,是基于案例推理系统中的关键环节。常用的检索算法有知识引导法、神经网络法、归纳索引法和最近相邻法[9]等。
知识引导法是根据知识决定特征属性的重要度,结果随知识变化而变化,通常与其他检索方法结合使用;神经网络法是将目标案例的特征属性输入至构建的神经网络系统,从各案例库检索出最相似的案例,速度较快,但确定参数的合理值缺乏有效方法且容易陷入局部最优;归纳索引法是根据最能将案例与其他案例区分开来的特征属性对案例进行分类,并据此重新对案例划分结构,一般与最近相邻法结合使用[9]。
本文采用最常用的最近相邻法进行案例检索,根据特征属性的权重进行分类并检索最近邻的方案作为母型船。检索中一般认为各特征属性对结果影响程度相同或设计者进行主观赋权,这2 种方式均存在不足。本文采用更智能的随机森林算法得到特征属性权重。
2 算法原理
2.1 K 最近邻算法
K 最近邻算法(K-nearest neighbor,KNN)是一种机器学习分类算法,即如果一个样本在特征空间中的K个最相近的样本中的大多数都属于某一个类别,那么该样本同样属于这个类别[10],K的取值对分类性能有重要影响,详见3.4 节。此算法核心为待分类样本与已有样本之间距离的计算以及各特征属性的权重赋值。目标方案和样本间的距离越小,代表样本与目标方案越接近,信息内容相关程度越高。
计算样本之间距离的常用公式有曼哈顿距离(Manhattan distance)、欧几里得距离(Euclidean distance)、闵可夫斯基距离(Minkowski distance)及其对应的加权距离等。本文采用加权欧氏距离计算公式,具体为
式中:wi为第i个特征属性对应的权重,由不同赋权算法计算得出;xi为目标方案x=(x1,x2,···,xn)的特征属性;yi为已有样本y=(y1,y2,···,yn)的特征属性。
2.2 特征权重计算方法
为了验证随机森林算法的有效性,下面将普通权重法、熵权法及层次分析法–熵权法的组合权重法也分别加以介绍,以便对不同特征权重方法结果进行比较。
2.2.1 普通权重法
假设特征属性个数为n,普通KNN 算法假设各特征属性对相似度影响程度相同,各特征属性对应的权重值为1 /n,此方式忽视了特征属性的重要度差异,不符合实际情况。
2.2.2 组合权重法
付磊[11]在江海直达宽扁船型方案设计系统中,使用主客观组合赋权法确定权重。主观赋权代表了设计人员对属性的评价,常用方法有专家打分法、层次分析法等。客观权重代表着数据本身对结果带来的影响,常用方法有熵权法。这种方法比单一的赋权方法更具说服力,但仍需要人工参与,不能实现智能化自动化赋权。本文组合权重法中采用层次分析法计算主观权重,熵权法计算客观权重,二者加权求和得到组合权重。
1)层次分析法
首先对各特征属性进行分析判断,两两比较各属性来判断指标之间的相对重要度bij,构建权重判断矩阵B=(bij)n×n;计算判断矩阵的最大特征值λmax及其对应的特征向量 ξ;计算一致性指标Ic=(λmax-n)/(n-1),根据随机一致性指标IR的数值计算一致性比率Rc=Ic/IR,当Rc<0.1 时,通过一致性检验,将 ξ作为特征属性的主观权重wsub。表1为1~10 阶对应的平均随机一致性指标数值表。
2)熵权法
计算第j项指标下第i个样本值占该指标的比重其中i= 1,2,···,m且j=1,2,···,n;再计算第j项指标的熵值A=1/ln(m)>0;计算信息熵冗余度dj=1-ej,计算各项指标的权重作为特征属性的客观权重wobj=
3)组合权重法
对主客观权重计算的权重结果进行加法组合加权,从而确定组合权重为
2.2.3 随机森林算法
随机森林算法(random forest,RF)是一种机器学习算法,准确率高、训练速度快、抗干扰能力强。利用随机森林进行特征重要性度量来确定特征属性的权重是随机森林算法的一个分支,本文使用基尼(Gini)指数计算基尼不纯度从而对特征进行重要度排序,若通过某特征划分后平均基尼指数减少的程度越大,即通过该特征划分集合变纯的程度越大,则可以认为该特征的分类能力越强,重要性越大[12]。Gini 指数代表样本集合D中某随机样本被分错的概率,计算公式为
式中:F为决策树有F个类别,pf为集合D中随机选中的样本属于类别f的概率。
样本集合D根据特征A是否取某一可能值a被划分为D1和D2两部分,则在特征A的条件下,集合D的基尼指数为[13]
式中:|D|为集合D中的样本数,|D1|为集合D1的样本数,|D2|为集合D2的样本数。
平均不纯度减少的计算公式为
式中E为随机森林中决策树的个数,Ginin(D)为第n棵决策树Gini(D)划分前集合D的基尼指数,Gini(D,A) 为第n棵决策树Gini(D)通过特征A划分后集合D的基尼指数[13]。
2.3 模型算法评估
使用不同的权重算法均能得到特征属性权重,代回KNN 算法中检索最近案例,但如何判断各权重计算方法的优劣,需要对算法模型的性能及检索后的结果进行比较评估。
2.3.1 多分类问题的评价指标
最近邻算法及随机森林算法本质是分类算法,可采用分类算法性能的评价指标来评价。假设有n个类别,将模型预测值与实际值进行对比后的结果有4 类,以类别2 为例:实际与预测均为类别2(真正类);实际为类别2 预测不为类别2(假负类);实际不为类别2 但预测为类别2(假正类);实际与预测均不为类别2(真负类)[14],见表2。
根据以上情况多分类的性能评价指标如下[14]:
1)准确率(accuracy,A):
表示分类模型中所有预测正确的样本数量(包括真正类及真负类)占总样本数量的比重,代表整体的预测准确程度。
2)宏观精确率(macro precision,Pmacro)
表示所有被预测为正的样本(包括真正类及假正类)数量中实际为正的样本数量的比例,分别计算出每一类的精确率值,再取算数平均值。
3)宏观召回率(macro recall,Rmacro)
表示实际为正(真正类及假负类)的样本数量被判断为正样本(真正类)的比例,分别计算出每一类的召回率值,再取算数平均值。
4)宏观f1分数(macrof1_score,f1_scoremacro)
由于精确率及召回率互相矛盾,因此定义f1分数为二者的加权调和平均,从而进行整体评价。将式(1)式(2)计算得到的值代入下式则可以宏观f1分数指标值。
2.3.2 十折交叉验证
调用机器学习算法模型需要输入参数,参数不同时训练结果不同,需进行交叉验证[14]评估算法模型的准确度,以选取最优参数值。采用十折交叉验证,将数据集平均分为10 份,选取其中1 份作为测试数据,其余9 份作为训练数据,依次循环可得到数据集的平均准确率、平均宏观f1分数两个评价参数,二者值越高,代表不同赋权方法及参数下的最近邻算法分类性能更优。
3 实例分析
3.1 数据收集及样本库建立
以油轮为例,收集到617 例实船数据(来自国际船舶网、中国船级社及论文),将其分类为VLCC、苏伊士型、阿芙拉型、巴拿马型、中型、灵便型和通用油轮,并用1~7 编号分别表示,按表3中的特征属性将对应数据储存在SQL Server2014数据库中。
3.2 数据预处理
在KNN 算法计算样本距离时,各特征属性的单位不同、数量级不同,如果一个特征值域范围非常大,那么距离计算主要取决于此特征,所以只考虑空间中坐标之间的距离可能会出现量级相差大的现象,因此本文采用Min-Max 标准化对数据进行预处理[15]。
式中x为某特征属性的值,min(x)、 max(x)分别为不同方案中该特征属性的最小值及最大值。
3.3 特征值权重计算
选取表4 中船长、垂线间长、型宽、型深、吃水、总吨、载重、航速、主机持续功率作为特征值,使用以下方法计算对应权重。

表4 标度值含义
3.3.1 普通权重
特征属性对应的普通权重为
3.3.2 组合权重
1)层次分析法主观权重
层次分析法采用1~9 标度方法,比较各特征属性两两之间的重要度,并建立判断矩阵。
式中每个标度值bij代表指标i比j的重要程度。
两标度值的中间值为两标度重要度的中间值。考虑主观因素影响,构建3 个判断矩阵计算3 个主观权重,特征属性的重要度排序一致为:载重>船长、垂线间长、型宽、型深、吃水>航速、主机持续功率>总吨,给各矩阵属性的标度值赋予3 组不同的值,见表5,对应的判断矩阵如B1、B2、B3。
利用Python 编程求得判断矩阵对应的最大特征值λmax及其对应的特征向量 ξ。
一致性检验指标:
满足一致性检验,所以主观权重
2)熵权法客观权重
根据2.2.2 中2),可以得到以下计算结果:
由信息熵确定各指标的客观权重为
3)3 个判断矩阵对应的主客观组合权重分别为
3.3.3 随机森林权重
1)随机森林模型参数确定
调用Python 中Scikit-learn 库的Randomforest Classifier 模块,不需人工参与赋权过程,仅需要设定决策树数量及随机状态2 个重要的参数。运用2.3.2 的十折交叉验证研究这2 个参数随机森林模型准确度的影响,选择准确度最大时对应的参数值来进行调用。
①决策树数量(n_estimators,ne):当决策树数量较小时,随机森林的分类回归误差大,性能也较差;当决策树数量过大时,模型构建时间长,森林的规模达到一定程度会导致森林的可解释性降低[16]。本文分析不同决策树数量对随机森林算法模型准确度的影响,见图1。
当ne= 43 时,随机森林模型的平均准确率及平均f1分数均最高。
②随机状态数值(random_state, SR):用来设置不同的随机状态,一般取0~100 内整数。在每次运行需要保证随机状态数值一致,以此保证构建模型、拆分结果相同,使结果可以重现。本文研究了随机状态数值对随机森林模型准确度的影响,见表6。
可以看出,随机状态数值对准确度影响不大。综上,使用 RandomForestClassifier (n_estimators =43,random_state = 0)命令来构建随机森林模型。
2)随机森林权重
根据模型获得各特征的对应权重见下式。
为直观展现权重大小,绘制出各权重算法不同特征的重要度柱形图,见图2。
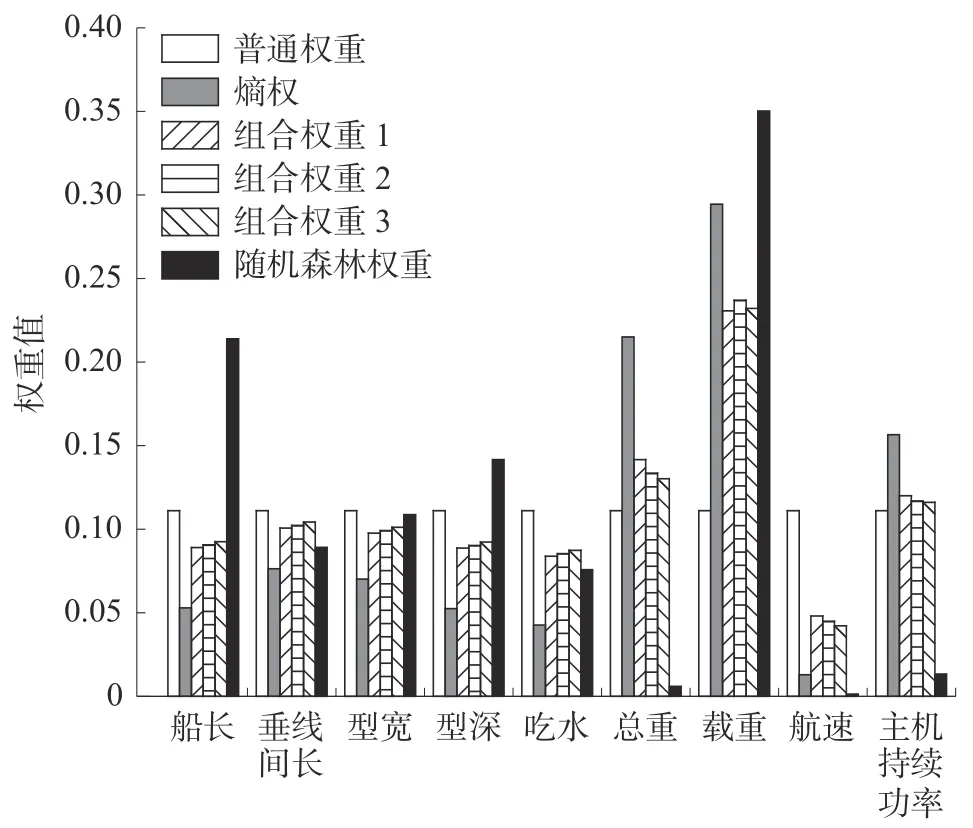
图2 特征重要度
3.4 分类模型准确度比较
以上4 种方法均能确定特征属性权重,但如何保证结果的准确性,需要对算法结果进行评估来评判模型的优劣。本文的K 近邻算法模型的准确度取决于K值的选取(一般取1~20 的奇数)及权重的赋值方法,采用平均准确率和平均宏观f1分数2 个指标对其进行交叉验证,获得最近邻算法模型的平均准确率和平均宏观f1分数与K值的关系,如图3。
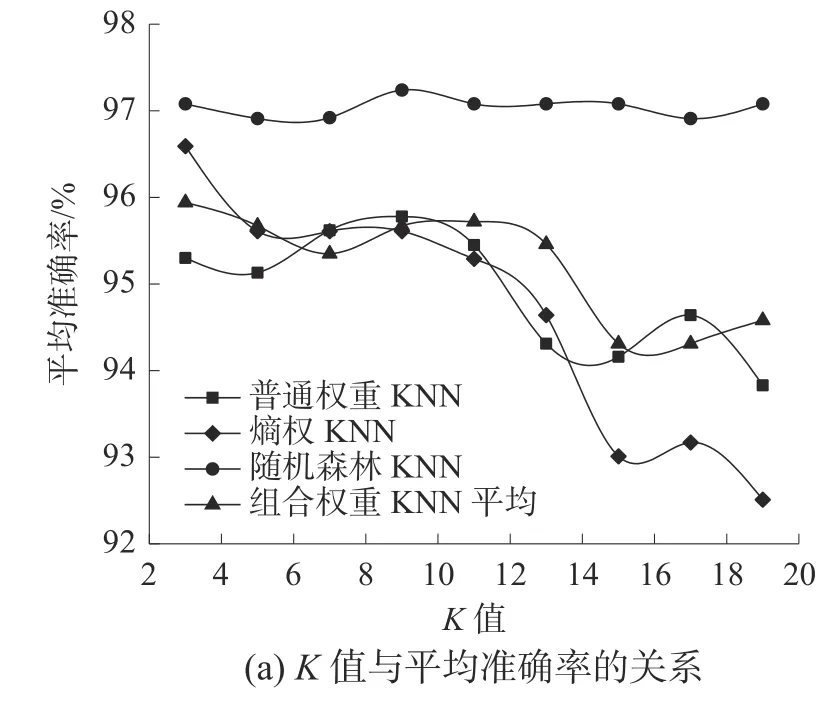
图3 K 取值对各KNN 算法准确度的影响
可以看出,不同加权的KNN 算法平均准确率和平均宏观f1分数为最大值时对应的K值不同:普通权重及随机森林,K=9;熵权法及组合权重,K=3。随机森林加权KNN 算法的平均准确率及平均宏观f1分数均比其他3 种高。将各算法的最大平均准确率及平均宏观f1分数进行比较,见表7。
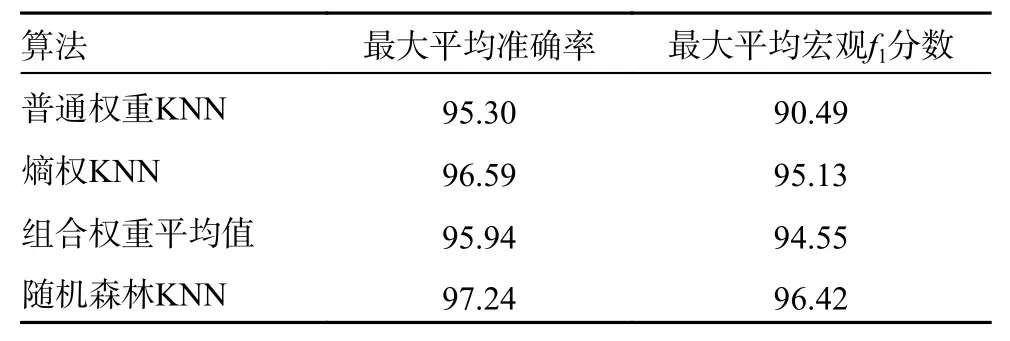
表7 不同K 值对应各算法的最大平均准确率及平均宏观%
随机森林加权KNN 算法最大平均准确率指标高出1%~2%,最大平均宏观f1分数高出1%~6%,因此使用随机森林加权KNN 算法进行案例检索可行有效。
3.5 最邻近方案检索
以巴拿马型油轮为例,分别选择各算法最大平均准确率及平均宏观f1分数最大时对应的K值构建最近邻模型进行检索,目标方案及各算法检索母型船特征值见表8。
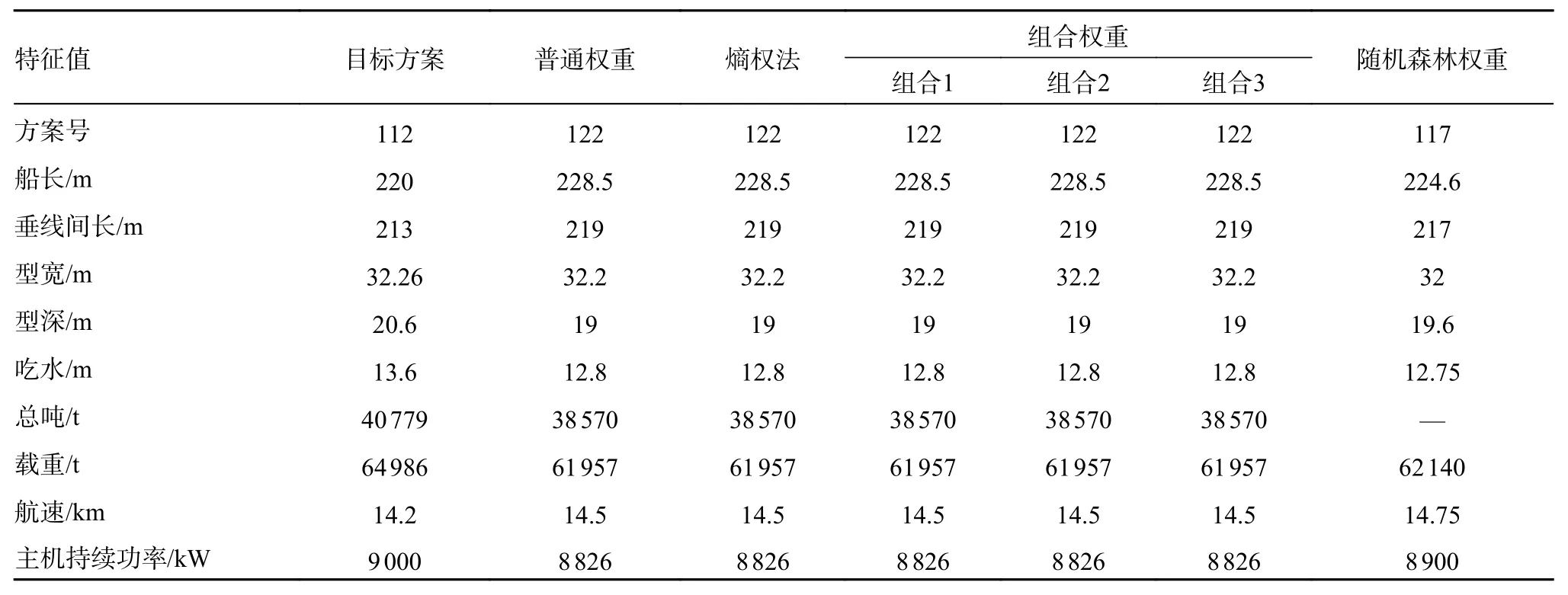
表8 目标船型特征值
以上4 种方法中,基于随机森林权重的最近邻算法检索出的方案的特征参数值与目标方案更为相似,进一步证明随机森林加权KNN 算法在案例检索的表现优异。
4 结 论
通过研究,实现了基于数据库船型资料的智能化检索,具体结论如下:
1)传统案例检索通常由设计人员选取特征属性并对其进行主观赋值,而随机森林算法基于数据根据重要度排序确定特征属性权重,减少主观影响。
2)随机森林加权的最近邻算法模型在分类算法有良好的表现,相比较于使用普通权重、熵权及组合权重加权KNN 算法的最大平均准确率高出1%~2%,最大平均宏观f1分数高出1%~6%,准确度更高,分类性能更优。
3)基于随机森林权重的最近邻算法检索出的方案的特征参数值与目标方案更相似,证明了随机森林加权KNN 算法在案例检索中的有效性。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
当代陕西(2020年17期)2020-10-28
意林图解作文(小学版)(2019年6期)2019-07-16
中国交通信息化(2018年5期)2018-08-21
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
专利代理(2016年1期)2016-05-17
河南科技(2014年15期)2014-02-27
