
基于对比学习的轻量化弱监督SLAM闭环回路检测
2023-11-13 03:21王传云娄渊伟刘晓娜王静静
空间控制技术与应用 2023年5期
王传云, 娄渊伟, 刘晓娜, 王静静, 高 骞*
1. 沈阳航空航天大学, 沈阳 110136
2. 烟台市科技创新促进中心, 烟台 264003
3. 中国电子科技集团公司电子科学研究院, 北京 100041
0 引 言
航空航天技术的发展,离不开对飞行器位置以及姿态的精准掌控,目前,主要以卫星定位技术为主、多种传感器为辅的方式为航空及航天器的飞行提供实时位置信息.相比于航空飞机等大型飞行器,无人机体积小巧,能应用于多种复杂的空间探测任务,包括对复杂的城市环境、建筑内和矿井下等空间进行感知和建图.但是,由于建筑以及掩体对卫星信号的遮挡,导致无人机无法有效地获取自身的位置姿态信息来完成飞行任务,同时,无人机的尺寸也限制了其对更多高精度传感器的搭载,而视觉传感器以其小巧的体积、低廉的价格以及优秀的性能获得广泛的使用.
结合视觉传感器,利用即时定位与地图重建技术(simultaneous localization and mapping, SLAM)[1],无人载体便能够实现位置姿态实时估计以及地图重建[2-3].但是,视觉定位是一个逐步估计的过程,由于环境信息的干扰,利用视觉传感器单次估计产生的误差会逐渐累计从而导致估计的轨迹与实际轨迹产生偏差,最终影响对周围环境的建图.因此,利用SLAM闭环回路检测也称为回环检测(loop closure detection)技术,建立当前数据与所有历史数据之间的关联来优化视觉定位信息获得广泛应用.
目前,回环检测方法可以概括为2大类:一类是基于视觉里程计的几何关系,另一类是基于外观的几何关系.因为回环检测的目标在于发现“回到了之前的位置”这个事实,从而消除累计误差,但前者的做法则先假设了“回到之前位置附近”,这样才能检测回环,而由于累计误差的存在,这类假设并不适用于长时间的视觉定位,所以在应用上存在弊端.而另一种基于外观的几何关系方法仅根据2幅图像的相似性确定回环,并不存在上述的弊端,这类方法也可以称为场景识别(place recognition).因此,基于外观的回环检测方法,能够有效地在不同场景下工作,逐渐成为主流的应用方法.
对于此类任务,早期通过不同种类手工制作特征[4]来完成回环的检测,但它们的计算成本很高[5-7],如尺度不变特征变换(scale invariant feature transform, SIFT)[8-9]和加速鲁棒特征(speeded up robust feature, SURF)[10]等计算复杂,并不利于应用在资源受限的嵌入式平台上.并且对于特征本身而言,在低纹理环境中,通常很难找到足够的点特征支撑计算.
相较于以往利用专家经验设计手工特征的传统方法,利用深度学习方法可以通过大量的数据集训练,使网络具有自主提取图像特征的能力.其中,卷积神经网络(convolutional neural network,CNN)提取的视觉特征在应对视角改变、光照变换以及尺度变化等问题时更具鲁棒性[11].这种方法使系统更高效且适用性更广.因此,多种基于CNN的深度学习方法[12-13]已应用于回环检测任务,其中,视觉词袋模型(bag of visual words, BoVW)[14-17]是最常见的一种回环检测技术.大多数视觉词袋方法使用反向索引[18],用于有效检索之前获取到的图像,但是需要大量的内存来存储数据,且很多同类的方法都使用固定的离线生成词汇[16],在实时场景下的应用则受限于词袋矢量的完整度.并且,视觉词袋中的词汇尺寸越大,所需的内存就越多,不利于在一些资源受限的嵌入式平台部署,同时会对系统的执行速度产生影响[18].在此基础上,大多数基于学习的回环检测方法采用完全有监督的方式进行训练,目标是学习更好的特征表示或设计鲁棒的匹配策略.但是,此类方法在实际使用过程中,由于标签数据的获取具有一定的困难性,人为标注的过程费时且费力,导致其使用成本相对高昂,不利于相关研究的发展.
因此,针对监督方法成本高昂以及嵌入式平台执行缓慢的问题,本文提出了一个基于对比学习的轻量化弱监督回环检测模型,优化原始NetVLAD[19]的模型结构,有利于在资源受限的嵌入式平台上应用,提升其在执行回环检测时的检索效率,便于无人机进行空间探测及建图.首先,采用EfficientNet[20]轻量化特征提取网络,利用其优秀的神经元结构搜索机制构建适用于回环检测的图像特征提取模块,使得原始NetVLAD能够高效地提取图像特征,有效减小网络模型在图像特征提取阶段的模型体积,提升网络模型整体的执行效率.其次,为了降低EfficientNet提取的高通道特征在经过VLAD层进行特征整合过程中有效特征丢失的风险,本文在原始压缩与激励模块(squeeze and excitation, SE)[21]的基础上进行改进,提出了一个需求压缩与激励模块(need squeeze and excitation, NSE),对输出通道进行注意力加权,在数据降维的过程中尽可能保留足够有效的特征,使网络具有更清晰的区分场景的能力,以提高回环的检测率.最后,通过实验表明,本文提出的基于对比学习的轻量化回环检测模型具有更小的模型体积、更快的执行效率,同时具有在复杂场景下相对优秀的场景识别能力,能够在一定程度上应对场景光照、视角以及季节变化等环境下导致的识别误差的问题.
1 算法模型结构
1.1 特征提取与描述符整合
常用的图像特征提取网络以卷积神经网络为主,其中,AlexNet[22]、VGG(visual geometry group)[23]、ResNet[24]已应用于多种视觉任务当中作为输入特征的提取模块.在回环检测任务中,TORII等[19]主要使用了VGG-16作为前端特征提取模块,利用VGG的多层卷积块堆叠构建深层网络,不断提取图像的高等级特征.但是,高维图像特征在回环检测过程中会对硬件存储设备提出一定的要求.因此,为了提升在执行过程中的检索效率,普遍采用词袋技术对图像特征进行降维检索,但是视觉词袋模型本身是利用词袋量化图像特征,统计的词频直方图,这样会损失较多信息.因此,TORII等[19]在传统的VLAD基础上,利用深度学习技术构建VLAD层来代替词袋模型.虽然VLAD同样考虑特征点最近的聚类中心,但是其保存了每个特征点到离它最近的聚类中心的距离,VLAD考虑到了特征点的每一维的值,对图像局部信息有更细致的刻画,且不会损失信息.VLAD的深度学习实现如图1所示.
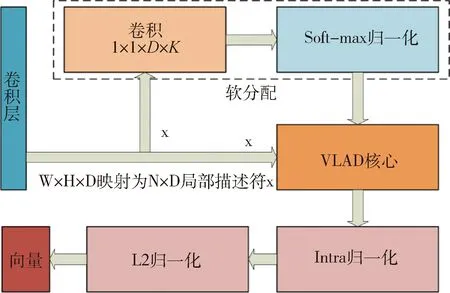
图1 局部聚合描述符矢量层结构
通过卷积层输出的特征矢量会在VLAD层中,经过软分配处理之后,在VLAD核心中与原始的输入进行整合,最后通过归一化层输出整合后的全局描述符矢量.
1.2 弱监督与三元组损失
为了使网络模型具有区分场景的能力,在网络训练的过程中,会根据数据源构建正负样本,其中,正样本表示与查询图像地理上相近的样本,负样本则表示地理上远离的样本.回环检测的核心任务是发现相似的场景,以判断是否重复经过而构成回环.因此,GPS信息是关键的标签信息,但是,获取每张图像的精准GPS数据作为标签信息是困难的,并且2个地理上相近的图像不一定描述相同的对象,因为这其中包括反方向视角以及遮挡.因此,在原始的NetVLAD中,对于给定的一个查询,GPS信息只用作潜在正样本集的源信息以及用来确定负样本集,建立不完整且噪声的弱监督,基于正负样本集,构建用于训练的三元组.

(1)
(2)
其中:α是预定义的超参数,表示来自同一类别的图像和来自不同类别的图像之间的边距,目的是使网络能够更积极地学习区分相似场景;l是一个合页损失l(x)=max(x,0).度量关系如图2所示.

图2 三元损失度量
2 模型结构改进
2.1 轻量化特征提取
目前,卷积神经网络如VGG或AlexNet等,想要实现更好的特征提取能力,会不断加深模型的深度或者宽度,甚至结合其他模型构建混合模型,导致模型体积逐渐增大,这会在一定程度上影响模型在资源受限的平台上的执行效率.相较于上述网络模型体积的不断增大,为了进一步减少模型的乘加累积操作数(multiply accumulate operations),MobileNet-V2[25]在深度可分离卷积的基础上,结合残差连接,构建了瓶颈残差模块,在降低模型参数量的同时,解决了卷积核在实际训练过程中容易出现空卷积的问题,进一步提升模型效率.考虑到在资源受限平台上应用,为了平衡网络深度以及宽度等尺度因素对网络模型产生的影响,本文采用EfficientNet[20]的一种复合缩放方法,并结合MobileNet-V2[25]的多目标神经元结构搜索方法,优化精度和浮点运算次数(floating point operations,FLOPS).基于此,构建回环检测的特征提取网络模型的基础模块如图3所示.

图3 瓶颈残差模块
对于输入的数据,通过膨胀卷积增加输入特征图的通道数,保证在进行深度可分离卷积的时候能够提取到更多的信息,之后通过深度可分离卷积来减低参数量,并通过投影卷积来限制模型的大小,同时,利用残差连接帮助模型反向传播时的梯度在深层网络之间的传递.
2.2 NSE注意力模块
相较于原始的NetVLAD模型,针对回环检测任务,本文在整体的网络模型构建过程中,为了减轻图像特征在描述符整合过程中,由于维度变换导致有效信息丢失的影响,设计了一个NSE注意力模块对提取出来的特征进行不同通道的加权来强化更重要的特征通道,弱化不重要的特征通道,改变其对于模型计算的重要程度,针对本文回环检测任务设计的NSE注意力模块的结构如图4所示.

图4 NSE注意力模块
NSE模块由1×1卷积、平均池化以及全连接层组成,全连接层会结合ReLU以及Sigmoid激活函数一起使用.通过网络训练,利用NSE对卷积层输出特征通道加权,获得更有利于回环检测任务的图像特征.
2.3 模型总体结构
针对回环检测任务,本文将采用EfficientNet-B0作为图像特征提取网络模型,并结合VLAD层作为描述符整合模块共同构建回环检测网络模型,模型结构如图5所示.
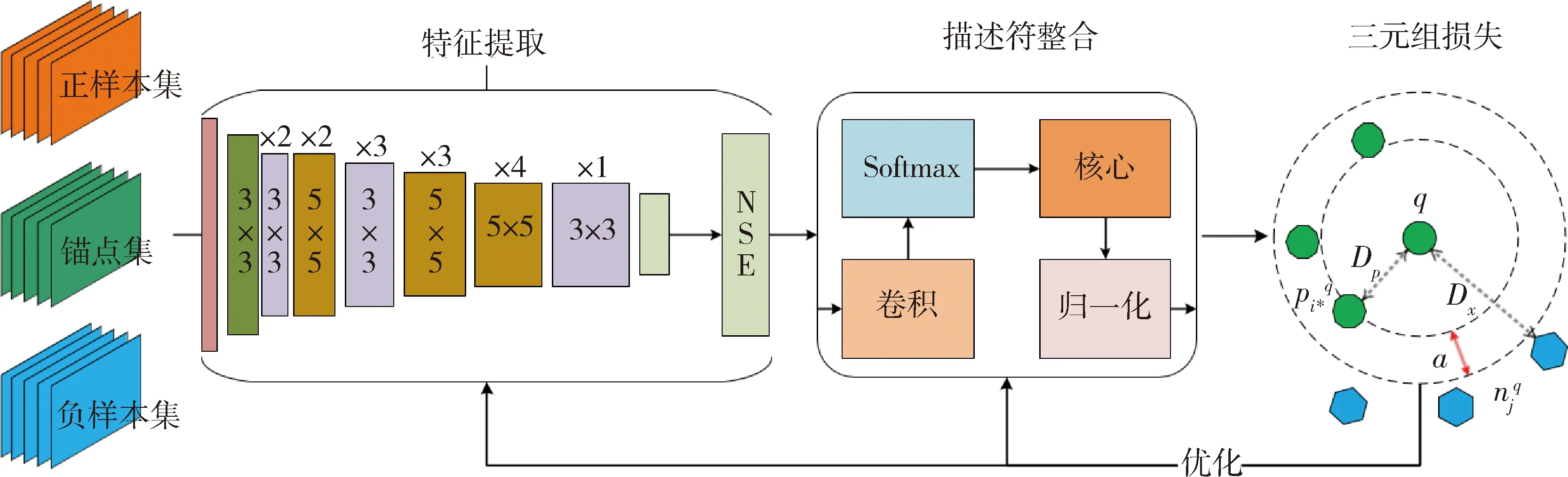
图5 轻量化回环检测网络
网络模型主要由3部分组成,包括特征提取、描述符整合以及三元组损失,在网络训练过程中,通过三元组损失网络模型不断优化模型参数,使回环检测网络逐渐具有区分正负样本的能力,能够在执行过程中提取更有效的特征,高效地整合图像全局描述符,完成回环检测.
3 实验及分析
本文采用公开数据集Pittsburgh(pitts250k)[26],包含从谷歌街景(google street view)下载的25万个数据库图像和从街景生成的24万个测试查询,图像分辨率为640×480.其中,每个全景图都由一组在不同方向和2个仰角上均匀采样的图像组成.针对回环检测研究,将pitts250k数据集划分为3个子集分别进行训练、验证和测试,每个部分包含约8万个数据库图像和8千个查询.本文使用PyTorch深度学习框架和SGD[27]优化器在NVIDIA GTX1080Ti GPU上进行所有的实验.
3.1 模型训练与评估
在模型训练阶段,采用一致的迭代次数(epoch),这里将epoch设置为30,并在评估指标超过10个epoch不提升的时候停止训练.优化器的动量设置为0.9,权重衰减设置为1×10-3,用于训练所有网络.初始学习率设置为1×10-4,损失边界值设置为0.1.在相同的实验平台上,对原始的基线模型进行复现,对比基线模型结构,模型之间主要差异部分的对比如表1所示.
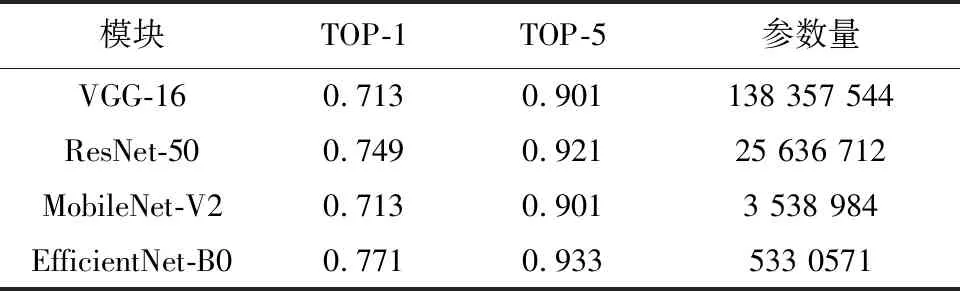
表1 模块差异对比
对于相同的视觉任务,对比不同的特征提取网络模型,通过表1中的数据可以看出,EfficientNet-B0相较于经典的VGG-16大幅度降低了模型的参数量,且在TOP-1以及TOP-5这2个评估指标上均高于经典的VGG-16网络模型的结果.同时,相对于另一种广泛采用的轻量化网络MobileNet-V2,EfficientNet-B0同样可以保持较好的召回率.本文使用回环检测研究中普遍使用的RecallRate@N(也称为Recall@N)召回率指标进行模型性能的评估,主要表示检索的参考图像(根据基本事实)不一定必须是最正确的检索图像,而只需要保证最正确的检索图像在N个最接近的检索图像中,这里RecallRate@1实际上是最大召回率PRmax时的精度,理想的召回率值为1.
基于上述评估指标,在相同的实验环境下,使用公开的pitts250k数据集,分别对原文基于AlexNet和VGG-16的模型以及本文改进的模型进行训练,训练阶段损失值变化曲线如图6所示.

图6 损失值变化曲线
在同样的30轮训练过程中,设置每10轮召回率不再提升则停止训练,原文采用AlexNet模块完整迭代30轮,模型收敛缓慢.VGG-16则在21轮结束训练,而本文模型在16轮便能结束,实验证明,本文的模型具有较高的计算效率,能够更快地达到预期效果.3个模型在不同评估指标下的评估结果如表2所示.
结合表2中的数据对比可以发现,本文提出的模型在4个不同等级的召回率指标上均表现出了不错的效果,相比于原文模型,本文提出的模型在Recall@10上有着更好的召回率表现,在Recall@1和5上较VGG16模块稍有差距.更小的召回率指标,代表着对回环检测精度要求越高,对于模型的表达能力要求也越高.由于模型在构建过程中存在通道变化导致有效信息丢失的问题,并且相较于原始模型大幅降低了模型的参数量,在一定程度上对模型的表达能力产生了影响,但是为了追求更好的轻量化应用,选择不增加模型的体积,仍然采用EfficientNet-B0作为特征提取模块,保证模型在无人机等资源受限平台上的执行效率.模型在训练过程中,由于模块本身的差异,原文模型以及本文提出的模型在训练时间以及执行时间上都存在较大的差距,对比原文最佳模型以及本文最佳模型在相同环境下的时间效率结果如表3所示.

表3 时间效率对比
从表3中可以看出,本文提出的模型在单轮训练时间上较原文的模型减少了35%,大大降低了模型训练的时间成本,且在测试执行效率上,本文提出的模型同样能够减少48%的时间,更高效地实现回环检测.回环匹配如图7所示,图7(a)为查询图像,图7(b)则为历史数据库图像.网络模型通过提取如图7(a)~(b)右下角所示的图像特征来进行描述符整合,进而通过相似度度量进行查询图像与数据库图像之间的比对.综合上述实验结果可以看出,本文提出的模型可以有效减小模型的训练时间,提升模型的执行效率.

图7 回环匹配显示
3.2 模型消融实验
为了验证本文提出的网络模型的各个模块的有效性,结合本文对特征提取以及数据变换阶段的改进,分别对本文提出的EfficientNet特征提取模块以及NSE注意力模块进行评估,构建VGG、EfficientNet和EfficientNet+NSE这3种网络模块结构,在相同测试环境下结合VLAD层构建回环检测网络模型,模型的召回率对比评估结果如表4所示.
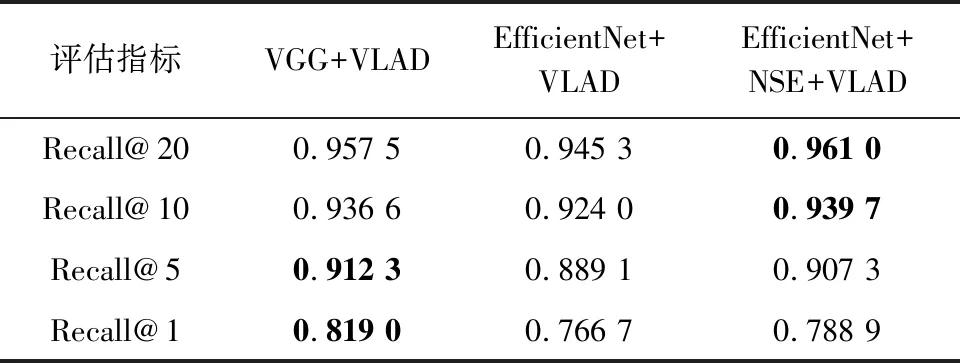
表4 算法模块有效性评估
通过表4可以看出,在原文采用的VGG+VLAD的基础上,仅利用EfficientNet+VLAD进行回环检测,在各个评估指标上均有小幅度的减弱,这其中一部分原因是图像特征在EfficientNet与VLAD之间变换时造成了有效信息的损失,而加入NSE模块,构成EfficientNet+NSE+VLAD的模型之后,可以看出模型在各项评估指标上均有较大幅度的提升,且在Recall@10和20上超过了VGG+VLAD的方法,通过图8可以更直观地看出本文各模块之间的有效性.

图8 算法模块有效性评估
4 结 论
本文提出了一种基于对比学习的轻量化弱监督SLAM闭环回路检测算法,该算法在NetVLAD的基础上进行改进,采用EfficientNet+NSE+VLAD的形式构建,在图像特征提取端利用轻量化的EfficientNet模型降低模型体积更高效地提取图像特征.为了降低图像通道变换对描述符整合的影响,利用NSE注意力模块对通道进行加权,保留更重要的图像特征通道,降低有效信息丢失的风险.在保持较高召回率的情况下,模型体积得到了大幅度缩减,显著提升了模型的执行效率.实验结果表明,对比经典的VGG+VLAD模型组合方式,本文提出的方法能够降低57%模型体积,减少35%训练时间,提升48%执行效率.本文所提出的模型更加有利于部署在无人机等资源受限的嵌入式平台,能够为视觉定位算法提供高效的回环检测结果,便于建立时隔更加久远的约束,方便通过各类优化算法对轨迹估计以及环境建图进行优化,有利于为无人机实现复杂环境空间探测建立更精准的环境地图.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·八年级物理人教版(2020年6期)2020-10-30
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
宝藏(2018年3期)2018-06-29
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
体育世界(学术版)(2015年3期)2015-07-01
噪声与振动控制(2015年4期)2015-01-01
电视技术(2014年19期)2014-03-11
