
基于YOLOv5s的交通信号灯检测算法
2023-12-03 16:12周爱玲谭光兴
广西科技大学学报 2023年4期
关键词:检测
周爱玲 谭光兴


摘 要:在自动驾驶和辅助驾驶领域,准确判断交通信号灯的状态与类别对于智能汽车的行车安全十分重要。针对城市道路交通信号灯目标小、背景环境复杂多样造成的检测难度大等问题,提出一种基于YOLOv5s的交通信号灯检测算法YOLOv5s_MCO。该算法使用MobileNetv2轻量化网络代替原主干特征提取网络,利用深度可分离卷积和逆残差结构,降低模型的参数量及计算量;然后引入卷积块注意力机制(convolutional block attention module,CBAM),从通道和空间2个维度进行特征增强,增大网络的感受野,使网络更关注交通信号灯的目标特征,提高对小尺度目标的检测能力。实验结果表明:所提算法在自制的国内交通信号灯数据集上检测精度达到了81.89%,相较于原YOLOv5s算法提升了1.33%,同时改进后的模型大小仅为19.1 MB,检测速度达到了39.2 帧/s,能够满足实时高效的检测要求。
关键词:交通信号灯;MobileNetv2;卷积块注意力机制(CBAM);检测
中图分类号:TP391.41;U491.5 DOI:10.16375/j.cnki.cn45-1395/t.2023.04.010
0 引言
近年来,随着科学技术和人工智能(artificial intelligence,AI)的日益革新,基于深度学习和计算机视觉的自动驾驶和辅助驾驶技术正在逐渐取代传统的道路交通场景目标检测算法。交通信号灯是组成道路交通安全的重要元素,高效准确地识别交通信号灯的状态,可以帮助智能汽车提前获取交通路口信息,避免出现安全事故,为乘客安全提供保障。
早期的交通信号灯检测算法主要采用传统图像处理方法,通过滑动窗口手工提取交通灯的目标特征,并结合机器学习分类器完成检测与识别[1]。Omachi等[2]将RGB图像转换为RGB标准化图像,利用Hough变换从候选区域中准确定位交通灯的位置。朱永珍等[3]完成图像HSV色彩空间转换,利用色彩H阈值分割候选区域,原图再经灰度形态学操作后用Hough变换预测疑似区域,二者融合滤波后完成交通灯信息识别。这些传统图像处理算法采用大量手工设计模型提取的特征,对特定任务的依赖程度高,鲁棒性较低,泛化效果不足,难以在复杂交通环境中满足实时性要求。
近年来,随着卷积神经网络体系结构的不断发展,目标检测算法进入了百花齐放的阶段。目前,基于深度学习的目标检测算法可分成两个类别:以Faster R-CNN[4]等为代表的两阶段算法,预先生成可能存在目標的候选边界框再进行调整分类,准确率高但检测效率较低;以SSD[5]、YOLO[6]等为代表的单阶段算法,网络跳过生成候选区域的步骤一步到位完成检测,检测速度得到提升,但相较两阶段算法精度有所下降。潘卫国等[7]补充了国内交通信号灯信息,在自建数据集中使用Faster R-CNN算法,通过实验对比,选择了最优的特征提取网络,完成交通信号灯的检测与识别。王莉等[8]利用跨越式特征融合和聚类缩放获取新先验框的方法改进了YOLOv3网络,相较原网络在Bosch交通灯数据集上平均精度均值(mean average pnecision,mAP)提高了9%。Yan等[9]利用K-means聚类对YOLOv5进行改进,在BDD100K数据集中,交通信号灯的检测速度得到提高,最高可达143帧/s。现有的基于深度学习的交通信号灯算法虽然规避了传统算法中人工提取特征和对特定任务依赖程度高的问题,但却存在网络模型结构复杂、参数量过大、检测效率较低、训练代价高等问题。
针对传统图像处理方法和日常目标检测算法所存在的问题,同时考虑网络的检测精度与检测速度,以YOLOv5s目标检测算法为基础,设计了交通信号灯检测模型YOLOv5s_MCO。通过引入轻量化模型MobileNetv2,在保证检测精度的情况下,降低模型的参数以及计算量;并将卷积块注意力机制(convolutional block attention module,CBAM)模块添加至Output网络的Head检测头前,使网络更关注图像中的目标特征,增强算法的特征提取能力。实验结果表明:在自制的国内城市交通信号灯数据集上,本文所提出的交通信号灯检测算法可以较好地应用于城市道路交通场景中,并取得了良好的检测结果。
1 YOLOv5模型
从YOLOv1发展至YOLOv5,YOLO系列作为单阶段目标检测算法的代表,集合了很多基于深度学习的目标检测网络的优点。基于实际应用考虑,本文采用YOLOv5模型(5.0版本)中深度最小、速度最快的YOLOv5s为基础进行实验,其网络模型结构如图1所示,主要分为输入端(Input)、主干网络(Backbone)、特征融合网络(Neck)、输出端(Output)4个部分。1)输入端部分包括图像数据增强、尺寸缩放等,输入图像经过输入端的统一压缩,分辨率减小为640×640后输入主干网络进行训练。2)主干网络主要包括:Focus模块的切片操作、交替使用的CBS模块和C3模块的主干网络特征提取操作、融合了局部特征和全局特征的空间金字塔池化(SPP)操作,提取出主干网络的3个不同阶段的特征输入Neck网络。3)Neck网络采用特征金字塔(FPN)和路径聚合网络(PAN)结构进行加强特征的融合提取,融合主干网络各特征层和检测网络提取的信息,增强信息传递效率,提升模型的多样性和鲁棒性。4)输出端部分具有分别检测大、中、小3种尺度目标的Head检测头:20*20、40*40、80*80,将特征融合网络中提取出的特征图经过多尺度预测,最终得出检测目标的边界框、类别和置信度信息。
2 改进的YOLOv5s模型
为更好地使模型应用在交通信号灯检测领域,本文对YOLOv5s的主干网络和输出端进行改进,引入MobileNetv2网络代替原主干特征提取网络,同时取消SPP和Focus模块,在保证检测精度的情况下,降低模型的参数以及计算量;然后利用卷积结构更改3个尺度特征的通道数,使其满足Neck网络对输入通道数的要求;最后将CBAM注意力机制添加至Output网络的Head检测头前,增强算法的特征提取能力。将改进后的算法命名为YOLOv5s_MCO,模型结构如图2所示,其中M代表MobileNetv2轻量化网络,C代表CBAM注意力机制,O代表注意力机制的添加位置。改进后的算法在自制数据集中对交通信号灯小目标的检测有着更好的表现,且体积小更适用于嵌入式设备等低算力平台。
2.1 MobilNetv2网络
作为轻量级网络的代表之一,含有深度可分离卷积的MobileNet系列网络的设计目标就是为了应用于嵌入式设备等低算力平台中。不同于常规的卷积运算,深度可分离卷积(depthwise separable convolution,DW)对一个完整的卷积运算进行了拆分重组:首先对输入特征的每个通道分别进行单通道卷积并堆叠;再利用1*1的卷积核在深度方向上进行加权融合,从而实现通道之间的信息交融。假设一张输入通道数为C1、尺寸随机的特征图,经过输出通道数为C2、卷积核大小为K*K的卷积层,计算出常规卷积的计算量P与深度可分离卷积的计算量PDW,二者的比值为
(1)
如式(1)所示,深度可分离卷积的参数量明显小于普通卷积的参数量,且随着卷积核个数的增加,差距越明显。
轻量化MobileNetv2[10]网络不仅采用了深度可分离卷积,还引入了具有线性瓶颈的逆残差结构,如图3所示。在实际网络训练中,深度可分离卷积虽然大幅度降低了网络计算复杂度,但也产生大量训练失败的卷积核,导致输出特征图维度很小,很难通过ReLU函数,造成特征信息损失。而逆残差结构首先利用点卷积(1*1卷积)扩张数据进行升维,再利用深度卷积(3*3卷积)进行特征提取,最后利用点卷积(1*1卷积)压缩数据完成降维,达到了减少参数量的目的,且在低维特征图中使用Linear函数代替原ReLU函数,解决了信息丢失的问题。
2.2 卷积块注意力机制
在目标检测算法中,注意力机制(attention mechanism)的本质就是在特定场景下,对解决问题有帮助的信息施加更多的权重,忽略无用信息,使算法聚焦图像关键点信息。因此,本文引入卷积块注意力机制(convolutional block attention module,CBAM)[11],从而提升目标的检测精度。如图4所示,CBAM注意力机制属于混合注意力机制模块,其虽然依次从通道和空间2个维度出发对模型特征进行自适应调节,但2个模块之间既相互独立又相辅相成,如图4(a)所示。总体计算过程为
式中:[F']为过渡特征图,F为输入特征图,MC为通道注意力模块,[F″]为输出特征图,MS为空间注意力模块。
在通道注意力模块中,输入特征图采用基于宽高的全局平均池化和全局最大池化操作进行维度压缩后,经过2层共享的多层感知器(multi-layer perceptron,MLP)神经网络得到权重W0、W1,再将输出结果叠加进行加和操作以及Sigmoid激活操作后,得到通道注意力特征MC,如图4(b)所示。该模块计算方法为
式中:[σ]为Sigmoid激活函数。
在空间注意力模块中,输入特征图经过MC模块加权后,首先进行基于通道的全局平均池化和全局最大池化操作,得到2个特征图;再对结果依次进行通道拼接、7*7大小卷积核的卷积操作以及Sigmoid激活操作,生成空间注意力特征MS,如图4(c)所示。该模块计算方法为
(5)
式中:f为卷积操作。
由于轻量化模块CBAM注意力机制内部结构简单,不含大量卷积模块,且池化层和特征融合部分的运算量也较少,最重要的是不需要经过循环操作,并行化程度高,这样的结构设置就决定了该模型的复杂度较低、计算量较少、通用性较高、效果较好。基于CBAM模块的诸多优势,许多学者已通过实验证明了其在目标检测任务中的可行性,但是因为应用场景和算法模型的差异,注意力模块的具体嵌入点目前还没有定论。因此本文在改进主干网络后,将CBAM模块分别融入Neck模块和Head模块中,探究其对网络性能的影响。具体添加部位如图5所示,其中图5(a)表示将CBAM模块融入Neck网络的4个上下采样后面,图5(b)在Output网络的Head检测头前融入CBAM模块。经过实验证明,将CBAM注意力机制嵌入Output后,网络的性能表现更佳,更有利于提升模型的检测精度。
3 实验与结果分析
3.1 数据集采集
目前,在交通信号灯检测领域中开源的数据集,如BSTLD、LISA、LARA数据集等,均在国外道路采集,背景较为单一,类别较少,基本只以颜色分类,不考虑形状问题,且存在国内外的地域差异;而国内公开的交通标志数据集TT100K、CCTSDB等只标注了交通标志信息,并不适用于交通信号灯检测;因此本文采取自制数据集的方法。考虑到国内复杂城市的交通道路,首先通过网络筛选和现实拍摄2個途径进行交通信号灯数据采集,共筛选出包含目标交通灯6 050张图像;然后使用LabelImg标注软件对其进行手工标注,得出9个类别共11 782个标签,具体的9类标签类别分布如表1所示;最后以3∶1的形式划分训练集与测试集,其中训练集4 050张,测试集1 500张,图像分辨率主要为1 920×1 080和1 080×1 080。图6为自制交通信号灯数据集的部分样本。
3.2 实验环境与评价指标
3.2.1 实验环境及参数设置
本实验深度学习框架为Pytorch,其硬件和软件平台设备参数如表2所示。
模型训练采用自适应矩估计(adaptive moment estimation,ADAM)算法对网络模型的权重进行更新优化,训练阶段的超参数设置如表3所示。
3.2.2 评价指标
在深度学习目标检测中,准确率(Precision,P)和查全率(Recall,R)是一对相互制约的指标。单一指标不能说明网络模型的优劣性,所以本文将从每秒检测帧数(frame per second,FPS)、模型体积、平均精度均值3项指标出发,评判模型的性能。
式中:NTP、NFP、NFN分别代表在检测结果中交通灯被正确识别、未被正确识别以及被错误识别的数量,[AAP]代表单类别的平均精度,[AmAP]代表全类别平均精度,n代表需要被检测的交通信号灯类别数量。
3.3 实验结果
3.3.1 消融实验
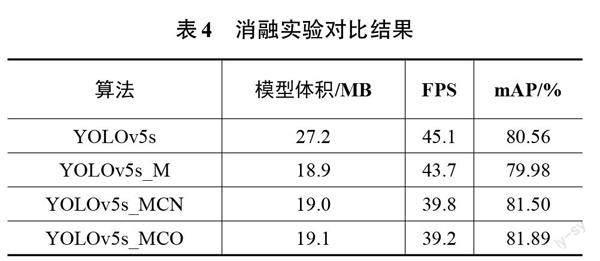
本节进行消融实验以验证所提模型的性能,网络输入大小与原YOLOv5s保持一致,设置为640×640,不同模型在测试集上的实验结果如表4所示。其中,YOLOv5s_M是将YOLOv5s的CSPdarknet主干网络替换为轻量化MobileNetv2网络;YOLOv5s_MCN是在YOLOv5s_M的基础上将CBAM注意力机制嵌入Neck网络中;YOLOv5s_MCO是本文所提模型,即在YOLOv5s_M的基础上将CBAM注意力机制嵌入Output网络中。
由表4可知,原YOLOv5s在测试集上的检测精度为80.56%,检测速度达到45.1 帧/s,模型体积为27.2 MB。更改主干网络后,在略微牺牲检测速度和精度的情况下,YOLOv5s_M模型体积下降了30.51%,仅为18.9 MB。为弥补更改主干网络后损失的检测精度,引入CBAM注意力机制后,检测速度有所下降,但YOLOv5s_MCN和YOLOv5s_MCO的检测精度都得到了较为明显的提升,相较于YOLOv5s_M分别提升了1.52%和1.91%,表明注意力机制的引入使得网络更关注图像中的主要目标特征,使网络学习到更多有效信息,从而提升检测精度。相比之下,将CBAM注意力机制嵌入Output后,网络的性能表现更佳,故将其作为本文的交通信号灯检测模型。综上,本文所提的改进算法YOLOv5s_MCO的检测精度达到了81.89%,相较于原YOLOv5s提升了1.33%,同时模型体积得到了大幅度的压缩,仅为原来的70.22%,更适宜部署在嵌入式设备中,并且检测速度达到了39.2 帧/s,满足实时性的要求。
3.3.2 不同算法对比
为了进一步验证所提算法的有效性,将YOLOv5s_MCO和YOLOv3、YOLOv4_tiny模型进行对比。由于对比模型的输入大小为416×416,将YOLOv5s_MCO网络输入大小改为一致后再进行训练与测试,对比实验结果如表5所示。
如表5所示,相较于传统YOLOv3算法,改进后的YOLOv5s_MCO模型体积较小,且在检测精度与速度方面拥有一定的优势。而YOLOv4_tiny是在YOLOv4的基础上简化而来,仅用2个特征层进行分类与回归预测,虽然检测速度得到了大幅度的提升,达到了95.2 帧/s,但其检测精度远不及本文的算法,需进一步优化。综上所述,本文算法YOLOv5s_MCO更满足在嵌入式设备上对交通信号灯目标检测的精度和速度方面的要求。
3.3.3 检测结果对比
在网络输入大小为640×640时,YOLOv5s与YOLOv5s_MCO的9类目标的AP值对比如图7所示。可以看出,本文所提YOLOv5s_MCO的平均精度均值达到了81.89%,相较于YOLOv5s提升了1.33%;并且除了G_R以外,其余类别目标的平均精度基本都得到了提升,特别是Y的AP值提升了10%,R_S的AP值提升了6%。
算法改进前后具体的交通信号灯检测效果对比如图8所示。可以明显看出,在图8(a)第一张图中,改进前的算法发生了误检,将G_L错误识别为G_S;在第二张图中,R_R未被成功识别,出现了漏检情况;在第三张图中,不仅存在将R错误识别为R_L的误检问题,还存在重复预测框的情况。而在图8(b)中,改进后算法不仅可以准确定位并识别交通信号灯目标,有效降低漏检率,且置信度分数也得到了提升。由检测结果可知,在复杂环境下本文算法YOLOv5s_MCO相比于YOLOv5s具有優越性。
4 结论
考虑嵌入式设备实际应用需求,本文提出了一种基于YOLOv5s的交通信号灯检测模型YOLOv5s_MCO,将主干网络替换成轻量化MobileNetv2网络,大幅度缩减算法参数量和计算量;通过添加CBAM注意力模块,使网络对交通信号灯的目标特征更加关注,提升算法对城市交通场景中交通信号灯目标检测的精度。实验结果表明:本文算法相较于YOLOv5s原网络,体积缩小了29.78%,检测精度提升了1.33%,检测速度也达到了39.2 帧/s,兼顾了实时性和准确度。在未来工作中也将继续寻找更适合在城市复杂场景中检测交通信号灯的算法。
参考文献
[1] 陈艳,李春贵,胡波.一种改进的田间导航特征点提取算法[J].广西科技大学学报,2018,29(3):71-76.
[2] OMACHI M,OMACHI S.Traffic light detection with color and edge information[C]//IEEE International Conference on Computer Science and Information Technology,2009:284-287.
[3] 朱永珍,孟庆虎,普杰信.基于HSV色彩空间与形状特征的交通灯自动识别[J].电视技术,2015,39(5):150-154.
[4] 朱宗洪,李春贵,李炜,等.改进Faster R-CNN模型的汽车喷油器阀座瑕疵检测算法[J].广西科技大学学报,2020,31(1):1-10.
[5] TIAN Y,GELERNTER J,WANG X,et al.Lane marking detection via deep convolutional neural network[J].Neurocomputing,2018,280:46-55.
[6] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:unified,real-time object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2016:779-788.
[7] 潘卫国,陈英昊,刘博,等.基于Faster-RCNN的交通信号灯检测与识别[J].传感器与微系统,2019,38(9):147-149,160.
[8] 王莉,崔帅华,苏波,等.小尺度交通信号灯的检测与识别[J].传感器与微系统,2022,41(2):149-152,160.
[9] YAN S J,LIU X B,QIAN W,et al.An end-to-end traffic light detection algorithm based on deep learning[C]//2021 International Conference on Security,Pattern Analysis,and Cybernetics(SPAC),2021:370-373.
[10] SANDLER M,HOWARD A,ZHU M L,et al.MobileNetV2:inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2018:4510-4520.
[11] WOO S,PARK J,LEE J Y,et al.CBAM:convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV),2018:3-19.
Traffic signal detection algorithm based on YOLOv5s
ZHOU Ailing, TAN Guangxing*
(School of Automation, Guangxi University of Science and Technology, Liuzhou 545616, China)
Abstract: In the field of autonomous driving and assisted driving, it is important to accurately determine the status and category of traffic signals for the driving safety of smart cars. To address the problems of detection difficulty caused by small targets of urban road traffic signals and complex and diverse background environments, a traffic signal detection algorithm YOLOv5s_MCO based on YOLOv5s is proposed. The algorithm uses MobileNetv2 lightweight network instead of the original backbone feature extraction network, and uses depth separable convolution and inverse residual structure to reduce the parameters and computation of the model. Then the convolutional block attention module is introduced to perform feature enhancement from both channel and space dimensions to increase the perceptual field of the network, so that the network can focus more on the target features of traffic signals and improve the detection ability of small-scale targets. The experimental results show that the detection accuracy reaches 81.89% on the homemade domestic traffic signal dataset, which is 1.33% better than the original YOLOv5s algorithm, while the size of the improved model is only 19.1 MB and the detection speed reaches 39.2 frames per second, which can meet the requirements of real-time and efficient detection.
Key words: traffic signal; MobileNetv2; convolutional block attention mechanism(CBAM); detection
(责任编辑:黎 娅)
收稿日期:2022-12-03
基金項目:国家自然科学基金项目(61563005)资助
第一作者:周爱玲,在读硕士研究生
*通信作者:谭光兴,博士,教授,研究方向:智能控制技术,E-mail:gxtan@163.com
猜你喜欢
中国设备工程(2022年12期)2022-07-11
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化·七年级数学人教版(2020年12期)2021-01-18
中学生数理化·七年级数学人教版(2020年12期)2021-01-18
中学生数理化·七年级数学人教版(2019年9期)2019-11-25
中学生数理化·七年级数学人教版(2019年9期)2019-11-25
中学生数理化·七年级数学人教版(2019年12期)2019-05-21
中学生数理化·七年级数学人教版(2019年12期)2019-05-21
