
交互音乐中的“听觉”建构
——基于实时机器听觉的交互音乐创作探究
2023-12-13 13:46赵艺璇
中央音乐学院学报 2023年4期
赵艺璇
一、机器听觉的应用基础
机器听觉(Machine Listening)也可称作计算机听觉(Computer Audition),是一个研究机器分析和理解声音内容的算法和系统的学科。其研究范围涉及人工智能、心理声学、认知科学、音乐、声学等多个跨学科领域,很多研究成果已应用于医疗卫生、公共场所监控、交通运输业等领域。目前国内对机器听觉在音乐领域方面的研究主要集中于音乐信息检索技术(MIR)(1)“音乐信息检索”(Music Information Retrieval,MIR)是使用计算方法对数字音乐的内容进行理解和分析的技术。该技术在音乐的内容推荐、自动转录、自动分类、自动生成等程序中有广泛的应用,目前研究和应用的范围仍在不断扩大。,其研究领域不涉及艺术创作,属于音乐科学技术的研究范畴,成果已广泛应用于各大商业音乐平台,也在音乐人工智能领域发挥着极大的作用。本文侧重于机器听觉在除商业音乐之外的艺术化音乐创作方面的应用和研究,与MIR在具体使用的技术方面有一定的交叉,但其应用方式和使用目的截然不同。机器听觉对交互音乐的创作思维和映射策略有着重要的影响,这不仅限于技术本身,也关系到技术的使用方法。
(一)机器听觉的应用类型
早期电子音乐的出现打破了传统作曲中使用音符系统的创作理念,也赋予了真实乐器更多的可能性,它在创作中以声音本身为基础单元,以组织声音为核心手段,不仅在声音选择上拓宽了可使用的声音材料,也改变了音高、和声、旋律等传统音乐要素在创作中的绝对意义。交互音乐的发展离不开电子音乐的兴起和演变。对于深受电子音乐影响的交互音乐来说,其创作很大程度上也脱离了传统的音符系统。因此,对于机器听觉在交互音乐中的应用要摆脱其在传统音乐音符系统中的常规使用来讨论,需要更多地关注对声音本身的分析和理解。由于机器听觉涉及的研究范围较广,各个学科之间目前还缺乏联系。英国萨里大学的王文武教授在其著作《机器听觉:原理、算法和系统》中综合各个学科的相关内容把机器听觉的研究分为四个较宽泛的方面,分别是:1.音频场景分析、识别和建模;2.音频信号分离、提取和定位;3.音频转录、挖掘和信息检索;4.音频认知、建模和情感计算。(2)Wenwu Wang,Machine Audition:Principles,Algorithms and Systems,Pennsylvania:IGI Global,2010.从这四个方面来看,我们可以得到机器听觉大致覆盖的研究范围,但对适用于人机交互系统的应用细节仍需继续进行发掘。李伟、李硕《理解数字声音——基于普通音频的计算机听觉综述》一文中,把计算机听觉大致分为几个子问题:1.音频时频表示;2.特征提取;3.声音相似性;4.声源分离;5.听觉感知;6.多模式分析。(3)李伟、李硕:《理解数字声音——基于普通音频的计算机听觉综述》,《复旦学报》(自然科学版),2019年,第3期,第269—313页。
本文研究的交互音乐系统涉及的问题基本集中于音频时频表示和特征提取,在人机即兴交互系统中也会涉及听觉感知。交互音乐本身是一个较为宽泛的音乐类别,对机器听觉的使用也会随着音乐类型的演变和技术的发展而不断拓展。
(二)实时机器听觉的产生
实时机器听觉的应用可以追溯至现场电子音乐(Live Electronic Music,LEM)(4)Live Electronic Music也称作Live Electronics,简称LEM,是一种现场音乐形式,现场可以使用包括电子类发声装置、电子类音乐乐器、计算机或任何可以生成声音的科技设备,即兴演奏在其表演中占据重要角色。的兴起。LEM最初发展的目的是用来回应以声音为基础并为固定媒介(5)媒介可以是传播渠道、手段或工具,本文中的媒介泛指可以传播声音、图像、灯光等信号的工具。(fixed media)而作曲的音乐类型(例如具体音乐、早期电子音乐等)。LEM的定义较为宽泛,尼克·柯林斯(Nick Collins)、玛格丽特·谢德(Margaret Schedle)和斯科特·威尔逊(Scott Wilson)曾这样描述LEM:“将这种音乐(电子音乐)进行现场演示的动力一直存在”(6)Collins Nick,Margaret Schedle,Scott Wilson,Electronic Music,Cambridge:Cambridge University Press,2013,pp.180-191.。瓦伦蒂娜·贝尔托拉尼(Valentina Bertolani)和弗里德曼·萨利斯(Friedemann Sallis)表示:“现场电子音乐是一种表演,其中电子元素以某种互动的方式影响表演者或受表演者影响”(7)Bertolani Valentina,Sallis Friedemann,“Live Electronic Music”,in Routledge Encyclopedia of Modernism,Taylor and Francis,2016.。从这些描述中我们可以看出,关于LEM的讨论更多关注于表演层面,“现场”(live)是其核心。
LEM的起源可以追溯至电子乐器例如特雷门琴(theremin)的发明和表演。20世纪30年代约翰·凯奇(John Cage)的作品《想象的风景1号》(ImaginaryLandscapeNo. 1)尝试使用了电子产品进行现场表演。这部作品被认为是LEM作品的雏形。20世纪60年代LEM得到广泛发展,尤其是卡尔海因兹·施托克豪森(Karlheinz Stockhaus)在WDR(8)WDR (Westdeutscher Rundfunk)是1951年成立于德国科隆的西德电子音乐工作室。(Westdeutscher Rundfunk)工作室完成的《麦克风1》(MikrophonieI),《混合体》(Mixtur)和《麦克风2》(MikrophonieII),从一定意义上真正形成了LEM的音乐形态。随后很多音乐团体和实验室也开始关注LEM的发展,包括著名的伦敦自由即兴小组AMM(9)伦敦自由即兴小组AMM是一个英国自由即兴乐队,于1965年在英国伦敦成立。、罗马的现场电子音乐(Musica Elettronica Viva)(10)罗马的现场电子音乐(Musica Elettronica Viva)是一个于1966年在意大利罗马成立的现场电子音乐即兴小组。和美国的声波艺术联盟(Sonic Arts Union)(11)美国的声波艺术联盟(Sonic Arts Union)是一个活跃于1966年至1976年间的实验音乐家团体。等都开始将电子产品纳入现场表演。20世纪80年代前后,计算机的引入极大地促进了LEM的发展,其中有重要贡献的包括法国作曲家皮埃尔·布列兹(Pierre Boulez)、意大利作曲家路易吉·诺诺(Luigi Nono)和卢西亚诺·贝里奥(Luciano Berio)等人。20世纪末,声音装置、交互式表演环境、现场演奏的电子乐器、实时编码(live coding)(12)实时编码(live coding)是一种在现场即兴编写源代码以创建和使用交互式编程的表演艺术形式,通常基于数字媒介创建声音、图像、以及灯光系统、即兴舞蹈和诗歌等。等使LEM的形态呈现多元化发展,而交互音乐作为一种更注重“互动行为”的LEM类型逐渐形成了自身的新特征。
4X(13)4X是开发于20世纪80年代的数字信息处理系统,它可以对现场真实乐器进行实时处理,包括录制声音、放大声音和改变声音的频谱。系统是由朱塞佩·迪朱格诺(Giuseppe di Giugno)在IRCAM(14)IRCAM(the Institute for Research and Coordination in Acoustics/Music)即法国蓬皮杜声学/音乐研究与协调研究所,由皮埃尔·布列兹1977年创立,是致力于音乐创作和科学研究的国际大型公共研究中心之一。开发的一种数字信息处理系统,对LEM和交互音乐的发展起到至关重要的作用。皮埃尔·布列兹的《回答》(Répons)、菲利普·马努里(Philippe Manoury)的《朱庇特》(Jupiter)以及罗伯特·罗(Robert Rowe)的《镜厅》(HallofMirrors)都使用了此系统在演出现场结合真实乐器与电子音乐实时表演。在4X系统得到推广的同时,许多研究学者已经意识到一台可以实时工作的机器可以有效结合真实乐器的演奏和计算机的“演奏”。在这之后,硬件设备ISPW(15)ISPW(IRCAM Signal Processing Workstation)是IRCAM和Ariel Corporation在20世纪80年代末开发的硬件数字音频工作站。以及目前最常用的使用可视化编程语言的交互软件Max(16)Max,也称Max/MSP/Jitter,是一种用于音乐和多媒体的可视化编程语言,由Cycling’74公司开发。,其开发都受到了4X系统的影响。Max从编程层面大大简化了实现步骤,使声音的感测—映射—回应都可以在一台计算机上完成。
4X系统和ISPW虽然可以通过模拟信号转数字信号的方式对现场真实乐器的演奏进行实时处理,但其感测音频的能力还停留在声音频谱表面,更细节的分析和理解能力没有得到扩展。这是由于一方面侦听系统在进行模数转换时技术不够完善,因此转换并不是无损的,有很多声音信号会因此缺失;另一方面,MIDI在后期的出现虽然简化了编程环境,但同样也会丢失很多有关音色的详细信息,因此识别音频中的详细内容需要对侦听系统进行深入研究。
随着Max、SuperCollider(17)SuperCollider是一种编程语言,由詹姆斯·麦卡特尼(James McCartney)于1996年开发,用于实时音频合成和算法作曲。等拥有开放、灵活编程环境的平台相继出现,音频工程师研究侦听级别和算法越来越便利,并且很多创作交互音乐的作曲家也对机器听觉产生了兴趣。如何在侦听系统中构建侦听的不同层次,如何基于人类感知到的音乐内容构造计算机的听觉感知,这些问题开启了对机器听觉包括实时机器听觉的广泛研究。
二、交互音乐中的实时机器听觉
“实时机器听觉”中的“实时”主要是针对交互音乐提出的,“实时”是交互音乐最重要的特点之一。交互音乐系统中的实时机器听觉是指可以在表演现场实时分析和理解音频流数据。实时机器听觉属于交互音乐系统的感测阶段,在此阶段系统需要对声音进行拾取、转换、分析和理解。实时机器听觉在这个阶段首先会经历音频时频表示,即用一种方式表示拾取的声音。可以用来表示音频的方式有很多,通常情况下会通过模拟信号转数字信号(简称A/D)的方式转换为数字信号,然后再使用快速傅立叶变换(Fast Fourier Transform,简称FFT)表示为频谱信息,具体流程如图1所示。除此之外,还有许多其他可以表示音频信息的方式。因为这不是本文研究的重点,故在此不详细举例和展开。
在这个基础上,为了使声音成为“实时控制器”实现精确的参数映射,我们需要探讨真正对交互起到决定性作用的实时机器听觉部分——音频特征提取、音频内容分析。
音频特征提取指的是从拥有多维度信息的音频数据中提取特定方面信息的过程。它可以提供多种用途,除了直接控制现场声音效果参数之外,也可以控制灯光、视频、图像等其他类型参数或提供数据进行统计和机器学习等。因此我们在探讨实时机器听觉的作用时离不开音频特征提取的作用。以下首先对音频特征进行分类,然后讨论音频特征在交互音乐系统中的具体应用。
(一)音频特征的分类
描述音频信息中的不同特征,需要各种“音频描述符”(audio descriptors)。笔者认为,可以基于对音频内容不同维度的理解对这些音频描述符进行划分。具体可分为三个维度,如图2所示。

图1.指定条件下的交互音乐系统流程图
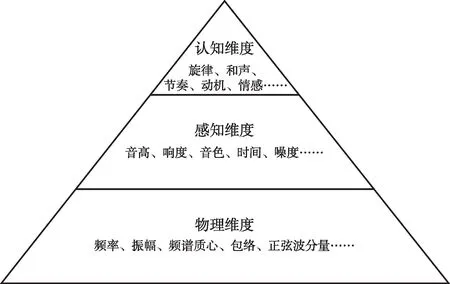
图2.音频特征的三个维度
物理维度的描述符通常由音频特征提取来获得,使用较为简单,而通过整合物理特征、执行不同算法和建模,便可以构建感知和认知维度中的描述符,其构建的结果会逐渐上升至音乐内容分析。这也显示出三个维度在复杂程度上有一定的等级划分。三个维度之间由于存在某种关联或映射关系,因此在技术原理上存在很多交叉。有些感知维度的音频描述符需要综合多个物理维度的描述符来构建,例如频谱质心、频谱通量和粗糙度等多个频谱参数可构成音色。有些不同维度的音频描述符呈对应关系,其中较为复杂的维度以音乐内容的形式进行了高级表达,例如频率和音高。我们由此得出,物理维度的音频描述符在使用时相对灵活,可控制的声音细节更多,但无法分析“音乐类”内容,而感知维度和认知维度被认为更高级、更贴近音乐内容,或者从机器角度被视为更智能、更独立。当然,它们在某些交互音乐作品中也存在不适用的特点,例如对于噪音或者无具体节奏和具体音高的声音材料来说,音频信息的特征需要物理维度的音频描述符进行描述,对音频信息进行音乐内容的分析往往难度较大。我们在交互音乐系统的设计中需要以创作理念为前提,技术为辅助,综合考虑不同维度的特点,选择适合的音频描述符。
(二)音频特征提取
在物理维度和部分感知维度可以进行音频特征提取的音频内容多达50余种,其中物理维度的音频描述符由于只关注声音的频谱信息,因此可用来描述任何有关声音信息的特征细节,除了我们熟知的频率、振幅、频谱质心、粗糙度等声音细节参数可作为音频特征被提取之外,许多专家仍在探索和扩展更多物理维度的音频描述符。
目前,音频特征的具体提取技术以及使用平台有很多种。例如由米勒·帕克特(Miller Puckette)、西奥多·阿佩尔(Theodore Apel)和戴维·齐卡雷利(David D. Zicarelli)开发的fiddle~和bonk~(18)fiddle~和bonk~是可视化编程语言交互软件Max中的模块,可被用于从实时音频中提取音高、正弦波分量和起始位置。,由特里斯坦·查汗(Tristan Jehan)编写的analyzer~(19)analyzer~是可视化编程语言交互软件Max中的模块,基于FFT原理,可分析感知层面的音高、响度、亮度等音频特征参数。,由托多尔·托多洛夫(Todor Todoroff)开发的iana~(20)iana~是可视化编程语言交互软件Max中的模块,用于分析和提取声音的频率分量。等,它们都是在Max平台中被广泛使用的可进行实时音频特征提取的模块,可以提取包括音高、响度、亮度、噪度、正弦波分量、Bark尺度分解和起始位置等多种音频特征。除此之外,由米哈伊尔·马尔特(Mikhail Malt)和伊曼纽尔·乔丹(Emmanuel Jourdan)开发的资源库Zsa~,包括了一系列专门用于实时音频特征提取的音频描述符。该资源库的开发有助于在一个场景下同时组合使用多个描述符来识别指定的音频信号特征(21)Mikhail Malt,Emmanuel Jourdan,“Zsa. Descriptors:a Library for Real-Time Descriptors Analysis”,in Sound and Music Computing Conference,Berlin,Germany,2008,pp.134-137.。
(三)音频内容分析
音频特征提取普遍适用于物理维度和部分感知维度的音频描述符。认知维度由于存在复杂的音乐内容信息,涉及乐理、心理学、听觉认知等跨学科知识,不能简单地依靠音频特征提取来完成,因此认知维度的机器听觉更恰当的解释应当是音频内容分析。
音频内容分析对交互音乐系统的重要性主要体现在自由即兴(free improvisation)交互音乐系统。在自由即兴交互音乐系统中,计算机的角色更像是一个独立的“机器演奏者”。它对人类演奏者的回应基于对演奏内容的复杂认知,而不仅仅取决于对低维度音频特征的提取。即兴音乐理念是自由即兴交互音乐系统的基础,它在20世纪60年代中后期由即兴爵士乐和当代音乐发展而来,有众多的代表作曲家和演奏家,以及AMM和MEV这类的即兴团体。这些作曲家和演奏家们在即兴演奏或即兴创作的过程中也尝试使用电子产品。
在此,不得不提到乔治·路易斯(George Lewis),他是把即兴音乐理念引入交互音乐系统并作出重要贡献的音乐家。乔治·路易斯在1986至1988年之间开发的Voyager系统第一版使用了Formula(22)Formula (Forth Music Language)是一种用于控制合成器的编程语言,可以模拟人类表演的表现力。语言编程。在Voyager中,计算机可以实时分析人类即兴演奏者演奏内容的各个方面,并使用分析得到的结果引导计算机即兴创作。它的运行程序可以被认为是一组包含64个单独发声且同步运行并由MIDI控制的“机器演奏者”。当人类即兴演奏者演奏时,演奏的声音会在系统中连续转换成MIDI数据,这些数据每5—7秒被重新计算输入,然后在64个“机器演奏者”中形成新的“行为群组”(behavioural groups),这些“行为群组”会在“15个旋律算法”“150个由微分音描述的音高集合”“音量范围区间”等多个参数类别中进行选择,在选择的同时有可能还会受到上一次“行为群组”的影响。系统每一次实时生成的结果都是一个新的独特的回应,它有可能会对人类即兴演奏者进行模仿、对立、配合或者忽略。乔治·路易斯认为,Voyager是一种非层次结构的互动音乐环境,具有即兴创作的特权,在这个系统中,不同参数类别之间不一定须要进行相关计算。(23)George E. Lewis,“Too Many Notes:Computers,Complexity and Culture in ‘Voyager’”,Leonardo Music Journal,10(2),2000,pp.33-39.
随着自由即兴交互音乐系统近些年的快速发展,通过机器听觉使用一些简单算法分析音频内容从而产生的计算机回应已不再能满足音乐家们的需求。音乐家和研究者已将机器学习大量引入系统研发,通过模仿人类的听觉认知系统来构建计算机的听觉认知系统。除Voyager之外,包括彼得·贝尔斯(Peter Beyls)、乔纳森·恩佩特(Jonathan Impett)、尼克·柯林斯、雷内·莫根森(René Mogensen)等众多音乐家都研究了此类交互音乐系统,并且尝试使用自己的模式和算法建立交互音乐系统。但每个作曲家对于计算机产生的即兴演奏或即兴创作有不同的研究层面和研究方法。例如,尼克·柯林斯提出了机器听觉和机器学习结合的系统结构“听觉学习”(LL:Listening Learning)(24)Collins Nick,“LL:Listening and Learning in an Interactive Improvisation System”,Technical report,University of Sussex,2011.;雷内·莫根森称计算机在系统中拥有“部分创造力”(partial creativity),他认为使用系统进行的表演和创作可以表现出人类创造力和计算机创造力互相影响的过程。(25)Mogensen René,“Evaluating an Improvising Computer Implementation as a ‘Partial Creativity’ in a Music Performance System”,Journal of Creative Music Systems,2(1),2017,pp.1-18.在此基础上,更多关于计算机创造力及其与人类创造力的关系等问题也开始得到不同领域研究者的关注。
音频内容分析在音频特征提取的基础上对计算机的回应提出了新的要求。由于即兴音乐在概念上完全取决于音乐家或演奏家个人的文化背景和音乐经验,它们不能够被准确定义,或者说不能够被计算机通过使用算法来得到精确的描述。因此在自由即兴交互音乐系统中,机器学习变为重要的环节。我们需要在机器的听觉系统中建立类似人类的学习机制,使之在不断和人类即兴演奏的同时学习人类演奏的音乐内容,分析理解人类演奏的音乐情感,并尝试预判人类的演奏等等。这些内容或者说这些能力需要人类音乐家和演奏家在演奏中或在建立系统时不断地去培养和试验。
音频描述符种类繁多且拥有不同维度的表达方式,虽应用于交互音乐系统中的感测阶段,但不完全取决于感测阶段。换句话说,虽然实时机器听觉需要在感测阶段对获取的音频内容进行提取和分析,但具体提取和分析的内容实际上取决于互动策略。每首交互音乐作品都有自己独特的互动策略,对于一部使用实时机器听觉来创作的交互音乐作品同样如此。
三、基于实时机器听觉的交互音乐创作模式
交互音乐作品创作中的科技手段是作曲家和艺术家创作理念的载体,它们有时是实现创作理念的重要工具,有时也可能成为创作理念的一部分。科技和创作理念两者的关系在交互音乐作品中互相影响、密不可分。基于实时机器听觉的交互音乐创作可根据音频信息的不同维度进行针对性创作,其创作模式具有一定的共性特点。下面笔者将以代表性作品的创作流程为指引,对作品创作环节、实时机器听觉的应用以及表演现场进行全面梳理,呈现一部交互音乐作品从构思概念到最终表演的完整创作链。
(一)创作流程及主要环节
交互音乐作品中媒介与电子部分的关系是实时变化的,除了对声音本身的考虑之外,还需从互动策略角度考虑人机交互的方式以及现场表演。
本文探讨的基于实时机器听觉的交互音乐创作主要使用声音数据来实现人机交互,并且由于现场需要实时的音频数据流,而不是系统已加载完成的音频数据,因此声音数据的来源被限制为真实乐器或可以自主发声的交互控制器。以真实乐器为例,其声音数据是贯穿整个创作过程的关键要素,它首先作为输入源为系统运转提供数据,其次作为控制器对回应内容进行实时控制。图3展示了基于实时机器听觉的交互音乐创作流程,描述了各个创作环节之间的关联和影响。其中图示左边是基本创作流程,它显示了真实乐器声音数据的输入方向,由于真实乐器的声音数据来自于乐谱,因此乐谱创作成为作品理念实现的第一个创作环节;交互音乐系统作为作品理念实现的平台,将基于声音数据的分析进行系统设计;表演是互动结果的呈现和展示,也代表了作品理念的最终表达。图示右边描述了交互音乐系统设计环节的具体内容,交互音乐系统是乐谱创作映射至表演现场的重要中间环节,主要在感测、映射、回应三个阶段对声音或其他数据进行处理,其他媒介也可以在其中使用或不使用感测阶段数据介入映射阶段,与真实乐器共同影响系统回应的内容。
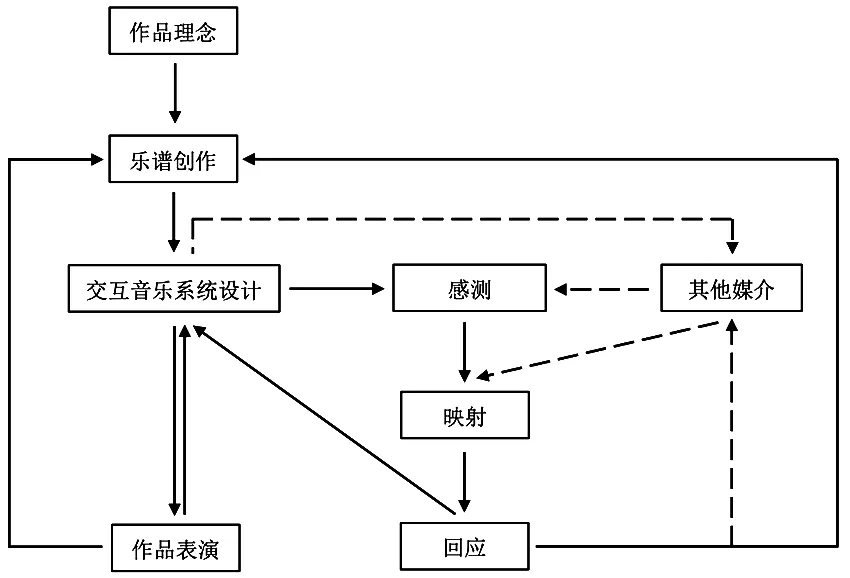
图3.创作流程及主要环节图示
“乐谱创作—交互音乐系统设计—作品表演”是创作过程中的具体实施步骤。与传统作曲不同,由于交互音乐系统设计环节的增加,仅仅依靠对乐谱的认识并不能评估人类演奏家演奏的最后效果。因此在乐谱的实际创作过程中,需要通过提前构想互动策略来对最终的声音呈现进行预估,在交互音乐系统设计的过程中,也需要提前对现场表演进行预估。通过不断地对最终效果进行预判,可以避免后期出现的效果不融合、不匹配等问题。虽然在创作过程中可以提前对下一环节的结果进行预估,但是真正呈现的效果往往会由于系统计算的原因而与想象的结果之间出现误差。因此,我们需要在多次排练中进行互动策略的试验,无论是针对机器回应内容的误差还是表演者现场表演效果的误差,都需要对交互音乐系统或乐谱进行调整。
总之,基于实时机器听觉的交互音乐创作是由一系列互相影响的创作环节构成,不同创作环节之间关系紧密,需要共同配合才能完成作品的最终呈现。
(二)实时机器听觉的应用
与一般的交互音乐作品不同的是,基于实时机器听觉的交互音乐作品应着重体现其在分析声音数据方面的特点和优势。我们在前文中已经介绍了实时机器听觉的应用原理以及它所包含的不同维度的音频描述符。在实际创作过程中,把握实时机器听觉应用的目的以及如何依托作品理念进行应用是需要重点关注的问题。
实时机器听觉需要通过对声音数据的分析才能得到应用,声音数据是贯穿互动策略最核心的要素,但系统中的声音数据不能仅仅作为一个输入信号来整体考虑。我们在实时机器听觉的应用过程中需要充分考虑以及体现声音数据中不同特征数据的使用价值。具体的应用取决于乐谱创作或无固定乐谱的现场表演,乐谱创作或表演是声音数据的来源。乐谱中的音乐表达和表演者的音乐表演姿态都对机器回应有直接影响,因此在实时机器听觉的应用过程中需着重考量乐谱内容及其表演,并对其映射方式及结果提前作出规划。只有对乐谱或表演中可利用的有效特征进行提取和分析,才能更合理地设计人机互动中的创意和细节。
实时机器听觉中不同维度的音频描述符有各自不同的应用价值,且不同维度音频描述符之间没有明确、具体的划分界限。根据罗伯特·罗在其著作《交互音乐系统》(26)Robert Rowe,Interactive Music Systems,Cambridge:MIT Press,1993.中对交互音乐系统分类的方式,我们可以大致判定较低级别音频描述符的使用属于乐器模式,其作用主要是为了拓宽乐器的演奏性能,而高级别的音频描述符由于更接近人类听觉系统,在应用上偏向于演奏者模式,其作用是为人类演奏家提供近乎平等的“演奏伙伴”。然而,在实际创作过程中,罗伯特·罗的分类方式只能帮助创作者对系统进行大致规划,具体分类的依据可能会限制和困扰创作者对实时机器听觉的定位以及音频描述符的选择。因此,在实时机器听觉具体应用的过程中,要注重创作理念而不是具体系统类型,针对最后想要呈现的效果而不是一味地提升音频描述符的使用级别。以尼克·柯林斯作品《替代品》(Substituet)(27)《替代品》是由尼克·柯林斯于2006年创作的为羽管键琴和巴洛克竖笛而作的交互音乐。为例,作品原理是由从一件乐器中提取的声音数据来控制从另一个乐器中提取的声音数据,其灵感来源于巴洛克时期的复调作品(28)Nick Collins,Towards Autonomous Agents for live Computer Music:Realtime Machine Listening and Interactive Music Systems [D],Centre for Music and Science,Faculty of Music,University of Cambridge,2006,p.195.。尼克·柯林斯在固定乐谱方面做了很多巧妙的设计,尤其是当其中一位演奏家单独演奏时,演奏家与开启的合成音色库会营造出真实乐器和虚拟乐器互相模仿的“假象”。
实时机器听觉的应用是帮助作品完成人机互动的首要步骤。对输入声音的认知是其应用的基础。不同类型的音乐或声音有各自不同的特点,我们需要对音乐内容进行不同层面的分析,对最适合体现作品理念的,在映射阶段最有效控制声音效果的特征数据进行提取和分析,只有合理恰当地应用实时机器听觉才能体现其应用价值和意义。
(三)表演现场
表演决定了作品理念的最终呈现效果,一个优秀的表演现场需要呈现易于理解的互动方式。透过表演现场的宏观表现,我们不难发现许多经过系统处理后的声音信号或其他信号在表演现场可能会出现不融合、互相干扰或表达不清晰等问题。接下来,笔者将从表演现场的角度探讨作品整体的呈现效果,涉及不同媒介对数据的处理以及表演形式的构想,指出表演现场中可能出现的问题,并提出一些常规的建议和看法。
关于表演现场的声音效果,我们在创作环节中已经探讨过,互动策略需要在彩排时多次试验和调整才能尽可能地避免计算数据在声音效果上产生的误差,其他媒介同时介入映射阶段也是如此。多个媒介的映射需要互相配合,无论使用哪种方式映射,都要始终清晰地展现媒介与其回应效果之间的映射路径,避免多个媒介在同时映射时导致的回应声音效果互相干扰和混淆的现象。关于表演现场的表演形式,多媒介表演是一种融合性表演。为了尽可能使表演流畅,且体现不同媒介的参与程度,创作者需要对人类演奏家的表演进行一些思考。比如一位人类演奏家在演奏真实乐器的过程中能否同时操作其他交互控制器?是否有必要为其他媒介的表演增加其他人类演奏家?另外,如果有除声音外的灯光、视频、图像等其他媒介参与回应时,则需考虑舞台效果是否混乱。我们始终需要牢记,任何媒介的表演都不是单独呈现的,表演是一个整体,需要存在一定的互动规律才能使创作的核心理念更牢固。
以笔者的作品《卡戎》(Charon)(29)《卡戎》是笔者于2020年为古筝、小提琴和现场电子音乐而作的交互音乐作品。为例,该作品的创作结合了中国乐器(古筝)、西方乐器(小提琴)、电子采样和电子效果多种不同类型的音色,其交互音乐系统设计致力于创造不同音色之间的交互作用,利用不同音色之间的互动推动作品的发展。在具体交互方案部分,小提琴部分通过实时机器听觉提取其声音的起音、音高、速度、包络等特征数据,然后分别在作品的5个阶段使用不同的交互方案实时控制6个电子采样的运动变化。古筝部分除了通过实时机器听觉提取其声音的响度、起音等特征数据实时控制古筝的混响和延时效果之外,同时还使用Myo臂环(30)Myo臂环是一款由加拿大Thalmic Labs推出的可穿戴设备,它可以通过读取穿戴者小臂的表面肌电信号识别穿戴者的手势运动。收集演奏家左臂的运动数据,这些运动数据首先通过OSC(31)OSC (Open Sound Control)是一种基于以太网使各种设备(计算机等)之间互相传输信息的通讯协议。传输至Max平台,然后在平台上进行数据处理和机器学习,最后将训练和处理好的5个动作指令映射出6种声音效果。古筝演奏家在表演时一方面利用演奏声音控制古筝电子效果的变化,另一方面通过Myo臂环识别到的左臂动作控制其他电子效果的变化,两种不同信息类型的映射结果同时进行,共同构成机器的回应内容。
除了互动策略设计对表演现场的影响之外,由于感测声音数据对作品交互音乐系统的运转非常重要。如果交互控制器的信号为数字音频信号,则不受现场表演的声场环境和拾音方式的影响,但如果交互控制器例如真实乐器的发声为模拟信号,则对表演现场有较高的要求。首先,拾取声音的麦克风一般使用心形或超心形指向的麦克风,此类麦克风指向性强,可以隔绝多余的环境噪音和周围其他乐器的声音;其次,在多个发声媒介同时表演的情况下,要注意媒介之间的物理距离,避免收集声音数据时互相干扰;最后,表演现场的声场环境需要提前试验,因为麦克风对声音数据的收集非常灵敏,任何声场环境中潜在的噪音都可能会对拾音产生影响,所以在彩排时需要提前对表演环境中的环境噪音设立阙值,既要保证声音数据有一定的灵敏度,同时也要保证声音数据的稳定性。
基于实时机器听觉的交互音乐创作模式具有一般性的特点,但也在具体实践中存在一定的特殊性。通过对创作过程中一些典型情况的思考,笔者指出了创作的主要内容和需要规避的常见问题,在明确创作重点的基础上,试图整合创作的核心思路和基本方向。
四、几点讨论
随着交互音乐的不断发展,人机交互的方式呈现出多元化的发展趋势,基于实时机器听觉的交互音乐创作随着科技的进步未来仍有较大的发展空间,但也面临不可忽视的挑战。
(一)实时机器听觉影响下交互音乐创作的开放性和局限性
机器听觉是在人类听觉机制的启发下产生的,虽然在系统构造等基本原理上试图无限接近人类,但是由于存在与人类完全不同的听觉理念与逻辑结构,从而赋予了交互音乐创作开放性的特点。机器听觉中各类音频描述符可以单独、灵活地使用,创作者在一部作品中可以使用其中一种或几种声音特征进行创作,也可以将多种特征整合为高级特征进行使用和创作,并且机器听觉只能拥有相对统一、固定的听觉模式,不像人类一样可以自由进行建构。换句话说,机器听觉的模式可以模拟人类,也可以完全不同于人类。因此,在创作过程中我们可以根据自身的创作需求选择合适的音频描述符进行创作,或通过建构独立个性的人工神经网络模型为创作者提供专属的“演奏伙伴”。
虽然音频描述符的多样性和灵活性为创作者提供了较为宽广的创作空间,但同时也会给创作带来一定的局限性。由于音频描述符的种类繁多,内部结构复杂,拥有复杂创意或需要建构复杂人工神经网络模型的作品对创作者的编程能力有很高的要求,可能会在技术层面限制和困扰创作者创作理念的实施。另外,特殊的即兴演奏系统需要使用一定数量的音乐数据进行机器学习,这在音乐版权方面可能存在争议。因此,虽然机器听觉的应用使机器拥有了类似人类的听觉系统,但实际上不一定会使交互音乐创作更便利,相反有时可能会使创作更复杂。
(二)交互音乐创作中实时机器听觉的创造力和潜力
在基于实时机器听觉的交互音乐创作中,实时机器听觉为互动策略提供了新的互动形式,而由实时机器听觉激发的机器创造力和潜力则为创作提供了创作思路和创作灵感。如何看待实时机器听觉引发的创造力和潜力是一个具有争议性的问题,机器听觉在模拟人类听觉系统结构的过程中需要寻找人类潜在的诱发基因,才能解决机器听觉的真正“思维”结构。但大多数证据表明人类认知系统的复杂性是不能被完美模拟的,优化机器思维结构是一个持久并且可能不会被解决的问题,因此机器可能永远无法拥有人类所定义的“创造力”和“潜力”。但从另一个角度来看,最佳的音乐创造性输出应该是一个音乐审美的问题。对于艺术化的音乐创作,机器的创造力和潜力不需要完全等同于人类,且机器听觉的不完美也许会造就新的音乐审美。也就是说,机器在某方面可能存在未知的“创造力”和“潜力”,而这些“创造力”和“潜力”与人类提出的定义和解释可能不同。关于实时机器听觉激发的机器创造力和潜力,作曲家和艺术家更需要关注的是如何给予计算机系统文化属性和个体属性,以及计算机的记忆应该以何种方式进行“衰退”(32)此处“衰退”是让计算机模仿人类的记忆力“衰退”。众所周知,人类的记忆力会随时间而衰退,但计算机不会做出此行为,此处用“衰退”一词是想强调:如果使计算机的记忆模仿人类进行“衰退”(比如,通过计算函数定时删掉某些之前储存的数据),这种方式会如何影响交互结果。。这些衰退是否会形成新的音乐审美价值,也是一个需要讨论的问题。
总之,利用机器听觉开发和发掘的机器创造力和潜力对交互音乐创作有不同程度的影响,除了在回应内容上激发创作者的创作之外,还可以引发创作者对交互音乐创作模式、人机思维模式等其他方面更多的思考。
(三)基于实时机器听觉的交互音乐创作的发展前景
人类与计算机系统的互动是一种变革性的创新,这一方式必然与人类和人类的互动有所区别。本文以声音特征数据作为研究基础,以人类在互动中的音乐体验为研究参考,对基于实时机器听觉的交互音乐创作展开讨论。探索人类与计算机系统互动的本质不仅对交互音乐创作中的人机互动策略有指导意义,也对交互音乐创作中的人机互动理念有推动作用。
基于实时机器听觉的交互音乐创作研究是一项复杂的跨学科研究,无论是对实时机器听觉技术的研究、对基于实时机器听觉的互动策略的研究,还是对实时机器听觉引发的机器创造力的研究等,都仍需要进行更多理论和实践方面的探索。促进创作理念和互动策略不断创新是基于实时机器听觉的交互音乐创作的发展目标。未来依托音乐人工智能技术的发展,实时机器听觉的研究会更加注重人机听觉系统之间的相关性、差异性以及显著性,而针对此类型交互音乐创作的研究也将在技术的推动下发现更多的发展路径。
猜你喜欢
中国音乐(2022年3期)2022-06-10
测绘学报(2022年12期)2022-02-13
计算机应用与软件(2020年6期)2020-06-16
戏曲研究(2019年1期)2019-08-27
数字通信世界(2018年1期)2018-04-18
乐府新声(2017年1期)2017-05-17
测绘科学与工程(2017年5期)2017-05-07
北方音乐(2017年4期)2017-05-04
未来英才(2016年22期)2016-12-28
人间(2016年27期)2016-11-11
