
基于强化学习的无人机电磁干扰感知与抗干扰传输方法*
2023-12-25 14:41李博扬万诺天夏晓晨张月月
电讯技术 2023年12期
李博扬,刘 洋,万诺天,许 魁,夏晓晨,张月月,张 咪
(陆军工程大学 通信工程学院,南京 210007)
0 引 言
无人机(Unmanned Aerial Vehicle,UAV)在过去的几十年里已经得到了广泛的应用[1]。无人机具有部署灵活、机动性高、隐蔽性强的特性,近年来被广泛应用于军事领域,其无人化的突出特点可以有效减少人员的战斗伤亡,在战场态势中拥有巨大的应用潜力。随着无人机成本的不断降低和设备体积的小型化,无人机也开始广泛应用于民用领域,包括通信中继、交通运输、目标快速检测等[2-3]。
低空的无人机与地外通信或基于高海拔平台的通信相比,能够更快地部署,更灵活地重新配置,并且由于存在短距离视距链路,可能具有更好的通信通道[4]。
然而,对电磁环境的依赖导致无人机具有易被干扰的致命弱点[3]。近年来,许多学者针对该问题进行了一系列研究。在电磁感知研究方面,文献[5]提出了一种通过少量感知节点获取不完整采样电磁数据(Electromagnetic Data,ED)的方案,利用复合电磁图重建方法重构完整的ED;文献[6]通过设计一种生成对抗网络(Generative Adversarial Networks,GAN)用于提取时域电磁相关信息,提出了一种域映射算法,能够有效获取频域的电磁相关信息;文献[7]针对复杂电磁环境,研究了一种适应高噪声干扰强度的数字信号调制识别模型。在抗干扰策略研究方面,文献[8]在地面存在恶意电磁干扰的情况下,通过联合优化地面传感器(Ground Sensor,GS)的传输调度、无人机水平和垂直轨迹,最大化了有限飞行周期内GS之间的最小期望速率;文献[9]从博弈论的角度出发,提出了基于博弈的无人机与干扰机之间的竞争关系,根据无人机的效用函数,选择最优功率控制策略对抗干扰;文献[10]从静态博弈和动态博弈两方面分析了无人机网络的抗干扰问题,研究了无线信道衰落特性和飞行成本对静态博弈中纳什均衡(Nash Equilibrium,NE)的影响;文献[11]对无人机和用户效用函数进行了设计,利用斯坦伯格博弈(Stackelberg Game)模型模拟抗干扰场景,联合优化无人机的功率和信道选择进行抗干扰。
强化学习算法得益于可以在未知的环境中进行快速的学习,因此被广泛应用于通信抗干扰的研究中。Q学习算法是强化学习领域的经典算法,其核心思想是通过在环境中试错,不断优化智能体的决策,以提高智能体获得的奖励值[12]。文献[13]利用无人机的通信频率、运动轨迹和空间域的自由度提出了一种多参数规划的Q学习算法,优化了接收方的通信质量。文献[14]通过核密度估计(Kernel Density Estimation,KDE)估计有效干扰信号强度的概率密度函数(Probability Density Function,PDF),提出了一种基于深度强化学习的算法来优化系统中的功率控制策略,能够在降低功耗的同时降低通信的中断概率。文献[15]针对毫米波大规模多输入多输出(Multiple-Input Multiple-Output,MIMO)系统的抗干扰问题,提出了一种基于策略爬山(Policy Hill-climbing,PHC)算法的功率控制算法,与Q学习算法相比,能够实现更高的平均信噪比和系统可达速率。文献[16]针对无人机群抗干扰传输的场景,提出了一种智能算法,能够同时实现最大化的系统可达速率和最小化的跳频开销。文献[17]通过联合控制发射机的功率和信道接入对抗不同策略下的恶意电磁干扰,但未考虑实际通信场景的信道衰落和变化。
本文针对无人机空地抗干扰通信系统提出了一种基于强化学习的抗干扰方法。在对干扰信息进行感知的基础上,将无人机的功率和信道选择策略建模为马尔科夫决策过程(Markov Decision Process,MDP),利用强化学习算法对其进行智能优化,提出了一种基于赢或快学习策略爬山算法(Win or Learn Fast Policy Hill-climbing,WoLF-PHC)的无人机抗干扰策略,通过仿真验证了所提算法的抗干扰性能优于PHC算法和Q学习算法。
1 系统模型与问题建模
1.1 系统模型
图1所示为无人机空地通信系统模型。

图1 系统模型
当无人机向地面用户发送信号时,在地面用户附近存在一个恶意干扰机,企图对地面用户的信道接入进行电磁干扰,阻断无人机与用户的合法通信。假设无人机-地面用户和干扰机-地面用户均为视距链路,地面用户接收到的信号为
(1)
式中:pt表示无人机的发射功率;pj表示干扰机的干扰发射功率,其发射功率均受最大发射功率的限制,pi≤pimax,i=t,j;st表示无人机的发射信号;sj表示干扰机的电磁干扰信号,假设E{si}=0,E{|si|2}=1,i=t,j;n表示地面用户所处位置的加性高斯白噪声,服从均值为0、方差为σ2的高斯分布。
所有信道均假定为准静态平坦衰落模型,地面用户接收到的信干噪比为[13]
(2)
式中:x为干扰因子,当地面用户被干扰时x=1;未被干扰时x=0,即
(3)
式中:ct表示无人机与地面用户之间的通信信道;cj表示干扰机的干扰信道。
1.2 问题建模
本文的优化指标为地面用户的可达速率,当干扰机对地面用户的信道接入进行恶意电磁干扰时,可以通过动态调整无人机的发射功率及信道选择规避干扰,以最大限度地提高地面用户的可达速率。优化问题表示为
max lb(1+RSIN)
(4)
s.t.C1:pt≤ptmax,
C2:ci∈{C},i=t,j。
式中:ptmax为无人机的最大发射功率,发射功率pt小于等于ptmax;{C}为无人机与干扰机的可用信道集,当ct=cj时,地面用户受到干扰机的恶意电磁干扰,信干噪比下降。由于干扰机的干扰策略是动态未知的,因此可以采用强化学习算法,通过在动态环境中的试错探索,优化该空地通信系统的抗干扰方法,达到提升地面用户可达速率的目的。
2 MDP建模
强化学习的核心思想是通过智能体在环境中不断交互得到的奖励值,进行自身决策优化,以达到奖励最大化的目的。其基本要素有状态、动作、策略、奖励函数、价值函数、环境模型[12],学习过程可以描述为如图2所示的马尔科夫决策过程。针对信道跟随干扰,可采取强化学习的方式,将无人机的功率和信道选择策略建模为马尔科夫决策过程[18]。

图2 强化学习基本模型
在这一场景下,无人机空地通信系统作为环境,无人机作为智能体对干扰进行感知和学习。状态、动作、策略和奖励函数的设置分别如下[17]:

(5)

(6)
策略:π(·)表示从当前系统状态映射到某个可选动作的概率分布,即π(sn,an):sn→an。
奖励:智能体通过环境反馈的奖励值优化下一步的动作,因此奖励函数的设计与系统性能的期望目标相关联。在本文中,优化目标为最大限度地提高地面用户的可达速率,但同时也应考虑尽可能地降低无人机的功耗,包括发射功率代价以及信道切换代价。因此,奖励函数定义为
(7)
式中:JP表示无人机的发射功率代价系数;Jc表示无人机的信道切换代价系数;zn表示当前时隙的信道切换状态,定义为[17]

3 算法实现
3.1 电磁干扰感知算法
电磁干扰感知是指通过对电磁信号的监测和分析,及时发现和定位电磁干扰信号的时域、频域特征的技术,是对抗恶意的电磁干扰的前提手段[19]。
常用的电磁干扰感知方法有功率谱估计法[20]、小波频谱感知[21]、学习算法类频谱感知[22]等,其中,小波感知算法不需要检测信号的先验信息,属于半盲检测,由于小波变换具有多分辨率特性,因此能够对频带的高频部分进行更为细致的频谱分析[23];学习算法类频谱感知在干扰信息动态未知的抗干扰传输场景中更具有优势,可以分析识别获得干扰机的攻击信道。
本文基于长短期记忆(Long Short-Term Memory,LSTM)神经网络算法[24]实现电磁干扰感知来获取对方的信道信息。干扰机采用信道跟随干扰的策略,以某一恒定功率值对地面用户进行干扰,即干扰机当前时刻的干扰信道始终与其感知到的上一时刻的通信信道保持一致。如图3所示,绿色部分代表无人机与地面用户合法通信信道,橙色部分代表干扰机攻击的信道。

图3 通信合法信道与被干扰信道信息
无人机通过电磁干扰感知获得上一时刻的干扰信息后,依据链路反馈的通信质量对抗干扰决策进行优化,通过强化学习算法对决策过程进行训练,以提升用户的可达速率,降低干信比。
3.2 基于WoLF-PHC的抗干扰算法实现
Q学习算法是强化学习中的典型算法,其中智能体的目标是最大化当前时刻的长期累积折现奖励,即
(9)
式中:γ∈(0,1]为折现因子,用于权衡潜在的未来奖励对于当下的影响。Q学习是将状态和动作张成一个二维Q表来存储Q值,Q值函数Q(sn,an)表示在状态sn下执行动作an的价值,可以表示为
(10)
智能体根据Q值来选取能够获得最大奖励的动作。传统的Q学习的Q值函数按照下式更新[12]:
(11)
式中:α∈(0,1]表示学习率。为了避免学习结果陷入局部最优,Q学习算法采用贪婪策略来平衡挖掘和探索之间的关系[25]。在贪婪策略中,智能体以概率ε选择该状态下Q值最大的动作,以概率1-ε随机选择动作。智能体的动作选择概率表示为
(12)
Q学习需要准确地估计每个状态-动作对应的Q值,每一步对Q表中的Q值进行更新,学习智能体在每一步做出动作,与环境进行交互,从而不断优化决策动作的能力,达到提升奖励值的目的。
WoLF-PHC算法是在Q学习的核心思想基础上进行的拓展[26],该算法结合了WoLF(Win or Learn Fast)和PHC(Policy Hill-climbing)算法,采用平均策略来近似均衡策略,通过可变的学习率增强了智能体的探索能力和效率。
在智能体执行一次动作到达下一状态且更新Q值后,平均策略的更新方式如下:
(13)
式中:C(s)表示状态sn被访问过的次数。当智能体的表现比期望值好的时候,降低学习速度;反之,加快学习速度,寻找更优策略:
(14)
(15)
基于WoLF-PHC的抗干扰算法步骤如下:
2 开始迭代:n=1,2,…,N
3 获取初始状态s0;
4 在当前状态sn下根据策略π(s,a)选择动作an,获得奖励rn并转移到下一状态sn+1;
7 根据式(14)、(15)更新策略;
8 更新状态。
4 仿真与分析
本节对无人机空地通信系统基于强化学习的抗干扰进行仿真实验,对比在不同学习算法训练下的抗干扰性能指标。仿真参数如表1所示。

表1 仿真参数
如图4所示,以地面用户为坐标轴原点建立直角坐标系,地面用户所处位置为(0,0);无人机在以(100 m,100 m)为圆心、10 m为半径的圆内悬停,并且会发生10 m内的小幅度的位移抖动;干扰机位于(150 m,0)位置处。

图4 系统模型位置示意
无线信道中的路径损耗表示为
LP=LP0-10βlg(d/d0) 。
(16)
式中:LP0=30 dB;参考距离d0为1 m;β为信道中的路径损耗指数,无人机-地面用户链路与干扰机-地面用户链路的路径损耗指数均为2.2。
针对电磁干扰,进行了干扰强度感知的仿真,利用干信比表示干扰信号的强度,定义为瞬时干扰信号强度与用户接收到的有用信号强度之比。图5所示为随机策略、Q学习、PHC算法和WoLF-PHC算法的干扰感知结果,可见随着学习进程的加深干信比随之降低,WoLF-PHC算法最终收敛到的干信比值低于其他算法。

图5 不同算法下的瞬时干信比
图6所示,WoLF-PHC算法能够挖掘出智能体更大的潜力,最终能够收敛到更高的奖励值。智能体使用WoLF-PHC算法经过一段时间的学习后瞬时奖励由12.3提升到16.2,提升了31%。
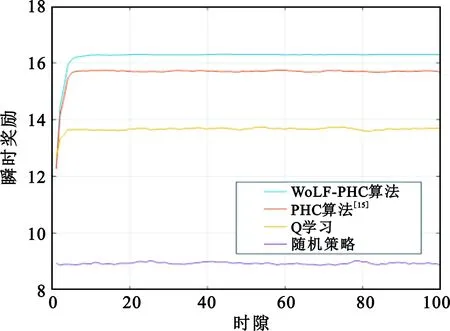
图6 不同算法下的瞬时奖励
图7给出了不同算法下地面用户的中断概率,当地面用户的瞬时信干噪比小于5 dB时,判断无人机与地面用户间的通信发生中断。仿真结果显示,随机策略下中断概率维持在0.22不发生变化;使用Q学习算法,地面用户的中断概率由0.12降低到0.08;使用PHC算法,中断概率从0.125降低到0.025;使用WoLF-PHC算法,中断概率从0.10降低到接近于0。

图7 不同算法下的中断概率
图8所示为智能体使用不同算法学习后地面用户可达速率的变化,地面用户可达速率为本文优化的目标量。仿真结果显示,WoLF-PHC算法能够达到较好的可达率提升效果,在初始值基础上提升了14%;PHC算法提升了约11%;Q学习算法提升了约2%。

图8 不同算法下的用户可达速率
5 结束语
本文针对无人机空地通信系统中的抗干扰问题,在对干扰进行电磁频谱感知的基础上利用强化学习算法对无人机进行训练学习,使其具有智能抗干扰传输的能力。通过联合控制无人机发射功率和信道选择对抗干扰机的恶意干扰,有效提升了用户可达速率,降低了干信比。通过仿真实验对比了4种不同算法的抗干扰性能,结果验证了所提的WoLF-PHC算法的抗干扰传输性能优于PHC算法、Q学习算法以及随机抗干扰策略。
在下一步的研究中,将对强化学习的算法进行优化,以降低算法复杂度,缩短学习收敛的时间。
猜你喜欢
航天电子对抗(2019年4期)2019-12-04
无线互联科技(2017年24期)2018-01-22
中国管理信息化(2017年18期)2018-01-04
北京航空航天大学学报(2017年9期)2017-12-18
物联网技术(2017年2期)2017-03-15
军事运筹与系统工程(2016年4期)2016-07-10
现代兵器(2016年6期)2016-06-25
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
电子设计工程(2015年8期)2015-02-27
