
基于OpCode 的融合终端代码相似性检测方法研究
2023-12-25 05:48陆蔺程磊卜树坡
电测与仪表 2023年12期
陆蔺,程磊,卜树坡
( 苏州工业职业技术学院电子与通信工程系,江苏 苏州 215104)
0 引言
伴随着“数字电网”的加速建设和配电侧台区智能化逐步推进,采用Linux 嵌入式硬件平台、搭载轻量级容器及微应用App 的台区智能融合终端( 简称融合终端) 应用前景广泛[1]。融合终端的优点在于底层解耦硬件结构实现硬件平台化,中间层将环境容器化实现App 跨平台运行,应用层软件化使融合终端全部功能均由可加载的各类App 实现。由此可见,融合终端生态架构已能够支撑平台间的互操作和微应用的可移植。但是由于终端类设备可用资源受限,难以部署完善的安全防护机制,出于源代码安全等原因,开发人员将编译后形成的二进制ELF 文件及运行环境打包成可移植的镜像文件,在融合终端的中间层实现跨平台运行[2]。跨平台和通用性极大降低了准入门槛和开发难度,大量的第三方厂家采用重用技术并行开发多个相似App 产品,节约成本的同时提高了开发效率。
《台区智能融合终端微应用开发及检测规范》( 简称《规范》) 中按功能划分了30 个微应用App,包括配/用电业务、通讯协议和外部接口等定义以便于进行标准化开发。本文所述App 均特指符合《规范》的微应用,详细分类如表1 所示。

表1 融合终端App 分类Tab.1 Fusion terminal App classification
目前,国家电网计量中心要求将产品的二进制目标代码备案以防范和控制软件运行风险[3]。同时《规范》还规定不同厂家开发的相似App 必须进行互换性试验,互换后应满足功能需求及具体指标要求。由此可见,能够通过互换性试验的App 必定具备相同功能和标准化接口,这为借鉴并重用代码提供了环境依据,而丰富的公共组件库和代码重用率使不同厂家源代码之间天然呈现某种相似性。
但若公共组件库存在安全隐患并被多个程序重用,则会产生包括缺陷、恶意代码传播等负面影响,引起的连锁反应甚至会造成严重后果。心脏滴血漏洞[4]( Heart Bleed) 就是重用隐患代码导致安全问题的典型案例,其影响至今仍未消除[5]。
近年来,软件安全问题频发,继承自第三方代码的漏洞一直困扰着开发人员,有效的App 代码相似性检测成为保障系统稳定运行的关键,也成为目前热点的研究课题,因此开展融合终端App 同源或相似性分析、评价源代码相似度量化指标,对于解决融合终端的安全隐患,具有非常重要的意义。
由于源代码无法获取,分析二进制ELF 文件成为研究App 相似性的理想途径[6]。二进制OpCode 操作码是从ELF 文件中提取的字符串序列,是Linux 执行静态编译时由词法、语法转化而来[7]。文献[8]指出重用代码有很大的相似性和典型特征,可通过OpCode 操作码进行特征提取。文献[9]指出反编译的二进制ELF 文件,源代码序列对应OpCode 序列相同。文献[10]指出两段OpCode 序列特征相同则可判定相似,多段OpCode 序列特征相同可判定为同源,这为二进制代码相似和同源判定提供了理论借鉴。
传统的OpCode 序列相似性判定采用N-gram 语义切分模型[11],缺点是过于庞大的特征集合会导致稀疏矩阵和维度风暴问题[12]。尽管采用多种方法如混合特征提取能够提高N-gram 的区分度,但准确性和计算性能仍有待进一步商榷[13]。
编辑距离( Edit Distance) 是通过转换步数来度量相似程度的方法[14],通过构建最优路径实现近似字符串在字符级别上的容错匹配,是本文采用的相似性衡量标准,主要应用于图相似性判断、数据清洗和语义特征提取等多种领域,其本质仍然是字符或数字序列的保序匹配与检索。二进制OpCode 操作码序列作为字符串序列的特例,同样适用字符串的相似性判定方法。
代码相似性比较是OpCode 特征向量的距离计算,文中首次引入编辑距离判定代码段相似性,提出一种面向二进制ELF 文件、以OpCode 为特征、基于代码段编辑距离和所有公共子序列图相似性相结合的融合终端相似性度量模型,为解决融合终端二进制代码快速相似性度量提供了新的思路。
1 操作码编辑距离的相似性计算
1.1 OpCode 操作码
文中的OpCode 操作码序列提取自二进制ELF 文件,其中操作码和操作数是基本元素。操作码指示代码行为,操作数体现行为目标。文献[15]指出改变编译环境只会影响操作数,而操作码不变,所以目前基本采用操作码序列作为相似性判断的依据。图1 为某用电AppA 的二进制Main 代码段。
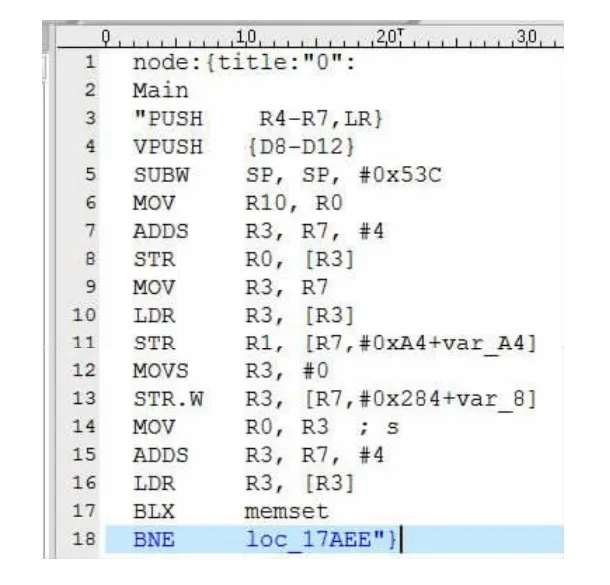
图1 反汇编代码段Fig.1 Disassembly code snippet
图1中第1-2 行指令中title:"0"表示AppA 的首代码段节点名称是Main,其编号为node0,本文所有ELF 文件的首代码段均为Main。第9 行指令中"MOV"为操作码,则从图中可得到代码段的操作码序列为:OMain={PUSH,VPUSH,SUBW,MOV,ADDS,STR,MOV,LDR,STR,MOVS,STR.W,MOV,ADDS,LDR,BLX,BNE}。
1.2 操作码序列的编辑距离相似度
设操作码序列O1={O11,…,O1r},O2={O21,…,O2s} 的编辑距离定义为: 将O1转换为O2所需的最少操作步骤[16],其中r、s分别为O1、O2的长度。操作步骤包括操作码的删除、插入和替换。操作码序列的编辑距离通过动态规划法计算匹配距离矩阵[17]:
其中,wins(O1i) 为插入操作权重,wdel(O2j) 为删除操作权重,wsub(O1i,O2j) 为替换操作权重,当O1i=O2j时wsub(O1i,O2j)=0 。例如将给定的操作码序列O1={PUSH,VPUSH,SUBW,MOV,ADDS}转换为O2={SUBW,VPUSH,MOV}需编辑3 步:
1) 将PUSH 替换为SUBW: { SUBW,VPUSH,SUBW,MOV,ADDS};
2) 删除SUBW:{SUBW,VPUSH,MOV,ADDS};
3) 删除ADDS:{SUBW,VPUSH,MOV}。
编辑距离匹配矩阵的具体计算过程见文献[18],此处不再详述。图2 为O1和O2的编辑距离匹配矩阵。
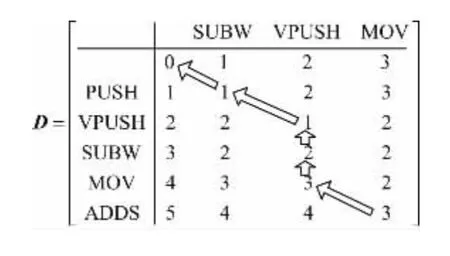
图2 编辑距离计算矩阵Fig.2 Editing distance calculation matrix
根据动态规划的思想,删除、插入和替换在计算矩阵中分别体现为路径的垂直、水平和对角移动。从图中可见,自矩阵D(4,6) 单元格回溯至D(1,1) 单元格能绘制出一条最短的操作步骤路径,此路径即为O1转换为O2的具体操作步骤: 替换SUBW、删除SUBW、删除ADDS。矩阵的D(4,6) =3 即为操作码序列O1转换为O2的编辑距离。操作码序列的编辑距离相似度定义为:操作码序列O1,O2间的编辑距离与较长序列长度的比值[19],公式如下:
从式(3) 可知转换步骤越少,操作码序列O1,O2相似程度越高,否则相似程度越低。
需要说明的是,ARM64 指令集中能够进行排列组合的指令数量只有200 多个,相似性度量过程就是统一操作码序列中差异部分的过程,即只考虑序列中操作码的删除、插入和替换顺序,因此相对于其他方法,编辑距离更适合二进制操作码序列比对,这也是本文引入编辑距离的主要原因。其次从耗费时间角度,在程序执行过程中若两个操作码一致,则只执行公式(1)的赋值操作而不执行式( 2) ,显然式( 1) 的执行速度相对较快,因此若序列相似度越高,编辑距离的执行步骤越少,执行速度就越快。从式( 1) 、式( 2) 可知编辑距离时间复杂度较低,为O(| r | ×| s |) ,适合进行长序列对比。最后编辑距离只需动态规划迭代实现,无需矩阵参与计算,不会因稀疏矩阵导致维度风暴而产生额外的消耗。综上所述,采用编辑距离度量操作码序列的相似性具有速度快、长序列等优点。
1.3 基于拓扑序列所有公共子序列的相似度
逻辑相似度计算是二进制代码相似性度量不可或缺部分,文献[20]指出反编译的二进制文件代码与源代码的逻辑调用关系大致相同。假设两个App 代码有相似的执行顺序,可认为这两个App 的逻辑调用关系也具有相似性。
目前,二进制文件调用关系主要以代码段为基础的有向流程图的逻辑关系[21]。文中采用所有公共子序列法( All Common Subsequences,ACS) 将流程图跳转逻辑相似性问题转化为有向图的相似性度量。
设ACS(x,y) 为待求的所有公共子序列数量,有如下公式:
Vx ={V1,…Vm},Vy ={V1,…Vn} 是将有向图进行深度优先搜索后转化的多重拓扑序列,其中Vi∈(Vx,Vy) 是操作码序列的集合,即代码段。ACS(x,y)值越大,多重拓扑序列相似度越高,否则相似度越低[22]。两个有向图所有公共子序列的相似度为:
现举例简要说明拓扑序列所有公共子序列的图相似度判定方法。如图3 所示有两个程序调用逻辑有向图为(G1,G2) ,各节点分别为代码段且节点编号均不相同。从图中可见有部分子图相同,说明两个有向图的调用逻辑具有相似性。
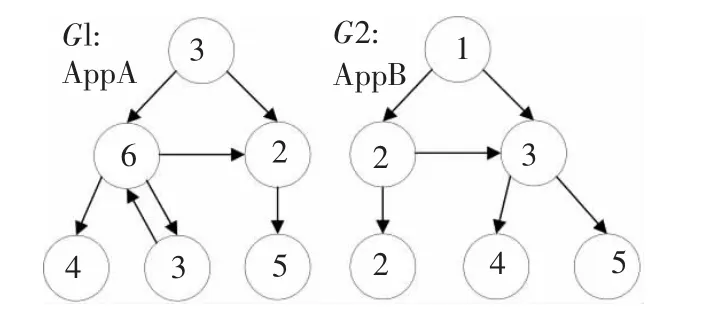
图3 有向图转化序列Fig.3 Directed graph transformation sequence
从顶点开始对(G1,G2) 进行深度优先搜索形成的拓扑序列为:
按照公式(4) 建立所有公共子序列数量矩阵如图4 所示。
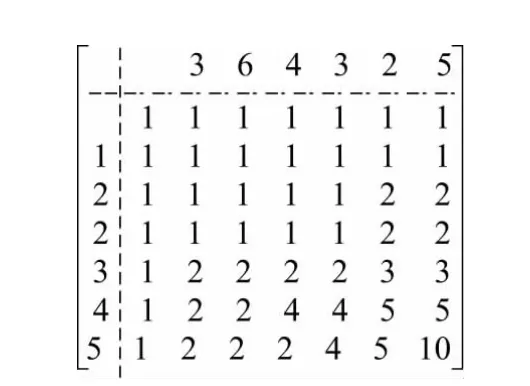
图4 ACS 计算矩阵Fig.4 ACS calculation matrix
矩阵计算结果可得:ACS(VG1,VG2)= D(8,8)=10 ,所有公共子序列为: {,3,4,2,5,25,34,35,45,345}。根据公式(5) 得:
1.4 二进制ELF 文件同源性判定
二进制代码相似性度量需要等同考虑代码段和调用逻辑的作用,得到二进制ELF 文件最终的相似度估算结果[19,23]:
2 台区智能融合终端代码反编译
2.1 融合终端App 分类
《规范》中将融合终端App 按照功能分为基础App和业务App。基础App 对通信接口、通信协议、数据模型、数据中心接口服务等基础资源统一管理,为业务App 提供技术支撑。业务App 分为采集通信类和应用分析类。采集通信类App 实现与上行主站通信交互及下行设备数据采集;应用分析类App 实现配电、用电业务场景的需求应用。表1 为App 分类及其主要功能,其中序号1-7 为基础App,序号8-30 为业务App。从表1 可以看出,融合终端App 种类较多,范围涵盖中压、低压大部分功能。
2.2 二进制ELF 镜像文件反编译
Linux 软件包分为源码包和二进制ELF 镜像包,后者是直接运行的机器代码。因镜像包不能直接读取,需将其反编译为汇编指令序列。文中反编译某用电AppA 的二进制ELF 镜像包,得结构框图及部分代码结果如图5 所示。
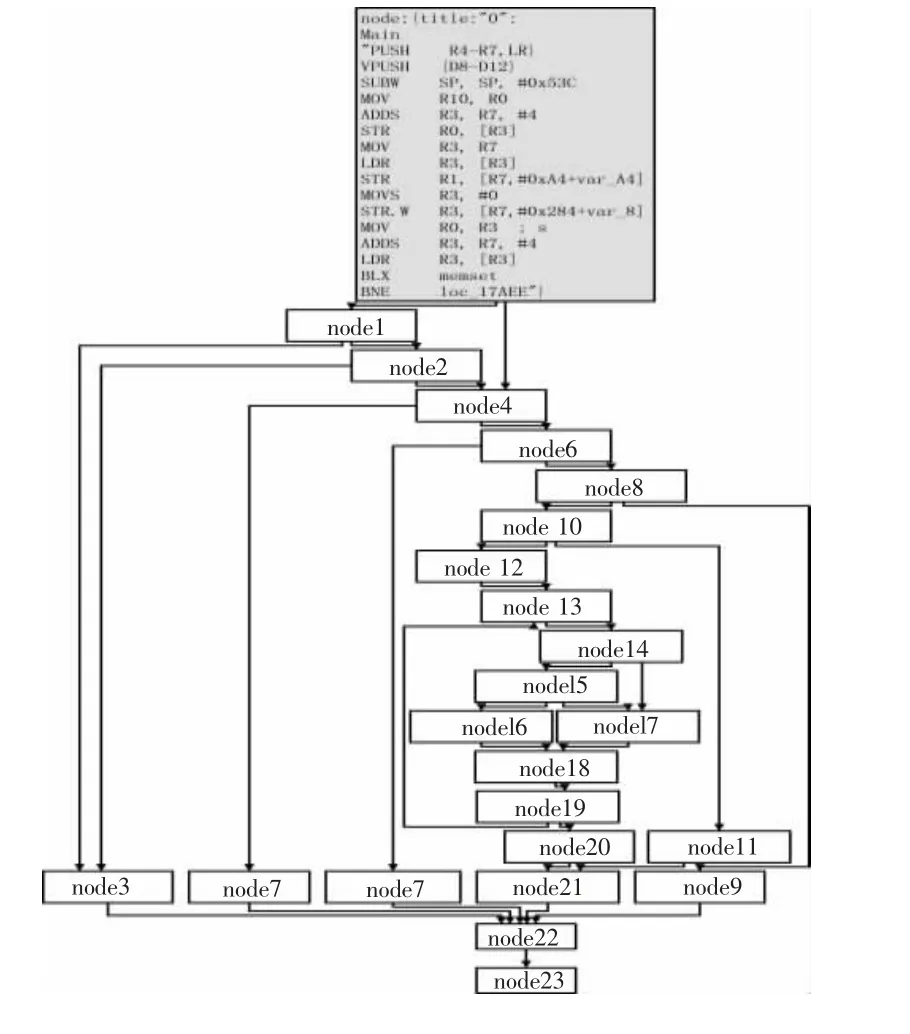
图5 调用过程图Fig.5 Calling process diagram
从图5 中可见,反汇编后共有24 个代码段节点,最顶端编号为node0 的节点是主程序节点Main,其指令如图1 所示。去除node0 节点中指令序列的操作数,得OpCode 操作码序列为1.1 节中的OMain_A。
另有AppB 主程序节点Main 的操作码序列OMain_B= { MOVW,MOVW,POP,MOV,PUSH,PUSH,LDRW,STRW,LDR,LDR,BLX,BLX},按式(1) 、式(2)可得编辑距离矩阵的计算结果,如图6 所示。
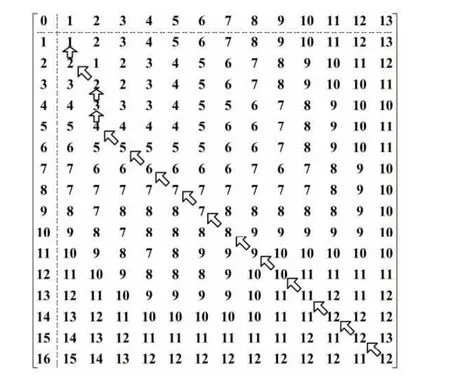
图6 Main 编辑距离计算矩阵Fig.6 Main editing distance calculation matrix
从图6 中可得D(13,16) =12 为操作码的编辑距离。根据式(3) ,OMain_A和OMain_B的编辑距离相似度为:1-12/16 =25%。同理,选择AppA-AppE 中较长的代码段,采用同样方法得编辑距离相似度结果见表2。从表2 知来自AppE 中的(O5-1,O5-2) 相似度最高达到44.6%。反编译共享函数库并与(O5-1,O5-2) 对比发现,这两个代码段重用了多个共享函数是导致相似比例过高的主要原因,类似情况还包括(O2-1,O2-2) 。
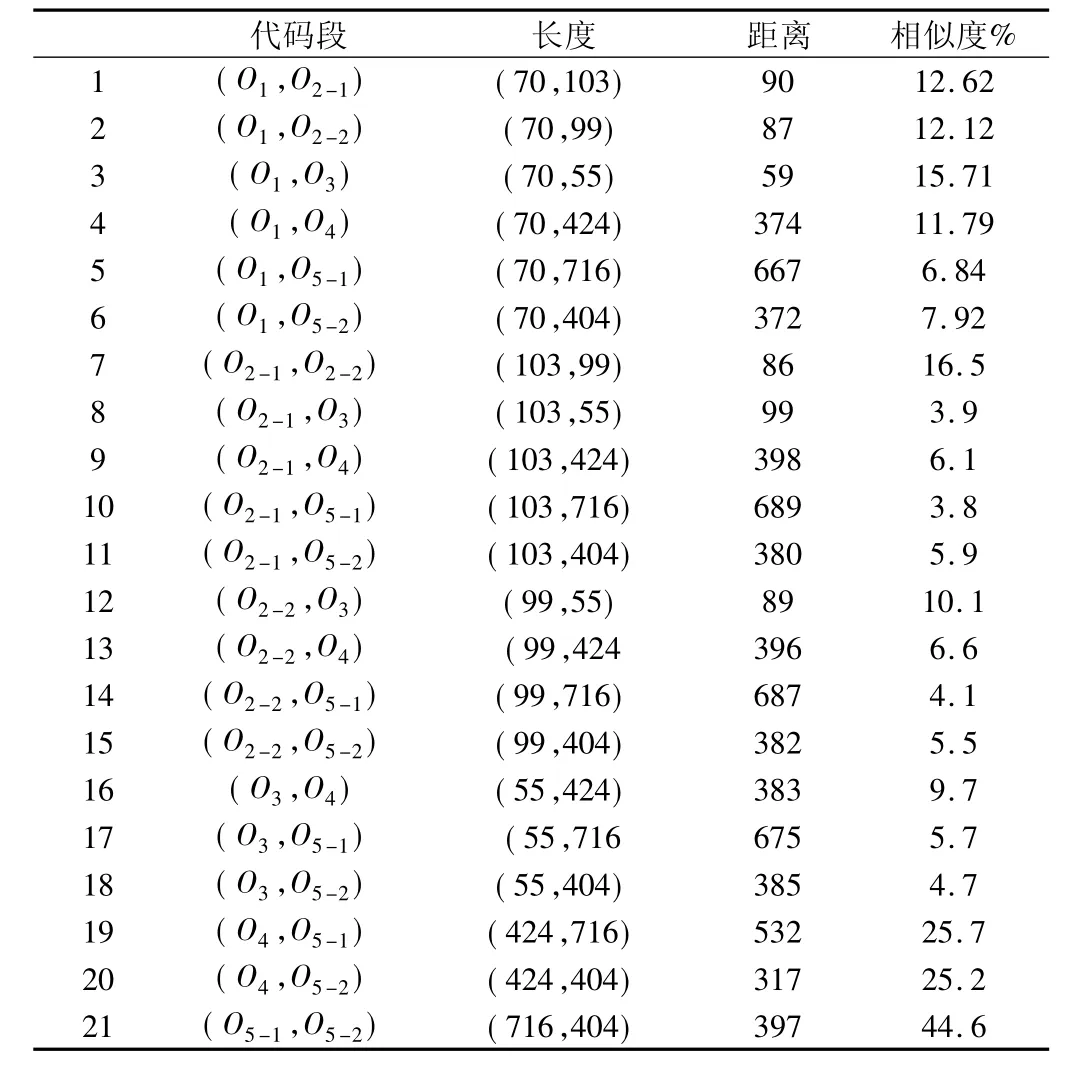
表2 编辑距离及相似度计算结果( 长度、距离×100)Tab.2 Editing distance and similarity calculation results ( length,distance×10)
另外,编辑距离的相似度会出现极小数值情况,当两个代码段长度相差较大时会导致相似度变小,长度相差越大相似度越小。根据式(3) 的计算结果表明,有时相似度数量级相差范围在103以上,因此尽量不进行类似的比较,或者可以忽略长代码段和短代码段的比较结果。另外编程语言的基本语句结构如if、switch、while、for 语句,尽管参数有所不同,但转换成二进制代码后逻辑结构是一致的,因此不同源的二进制代码段也有一定的相似度。由于篇幅有限,表2 只给出部分编辑距离的计算结果。
2.3 执行序列相似度
按1.3 节中所述,将AppA 的调用过程图( 图5) 变形为有向图,如图7 所示。
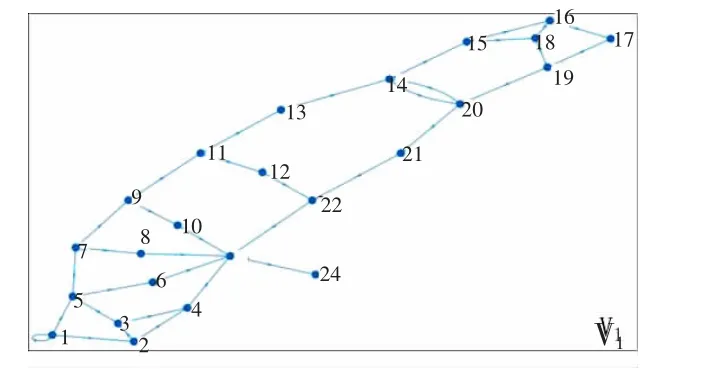
图7 AppA 调用过程有向图Fig.7 Directed graph of AppA calling procedure
有向图中每个节点代表一个代码段,每条路径的节点1 均为主程序节点Main,并进行深度优先搜索后形成拓扑序列V1。采用同样方法将AppB-AppE 的调用过程转化成有向图,如图8 所示:
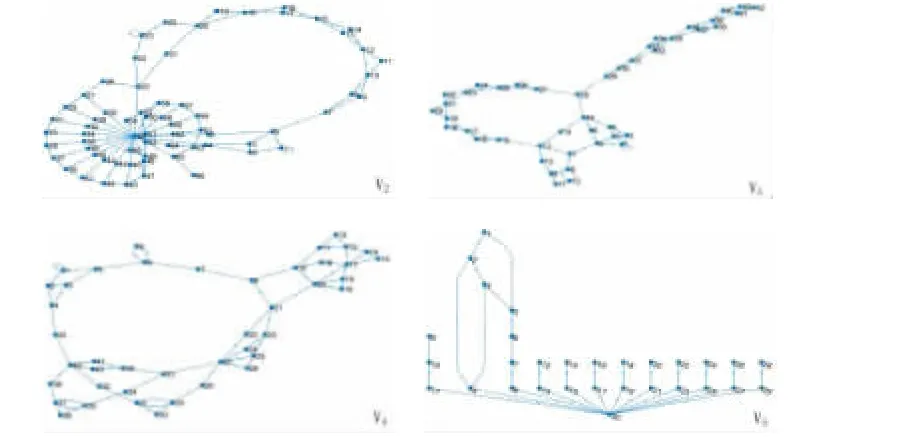
图8 AppB-AppE 调用过程有向图Fig.8 Directed graph of AppB-AppE calling procedure
从图8 中可见,有向图呈现不规则变化,无法从中判断调用逻辑是否相似。
将有向图进行深度优先搜索得全部多重拓扑序列路径V1-V5,结果见表3。
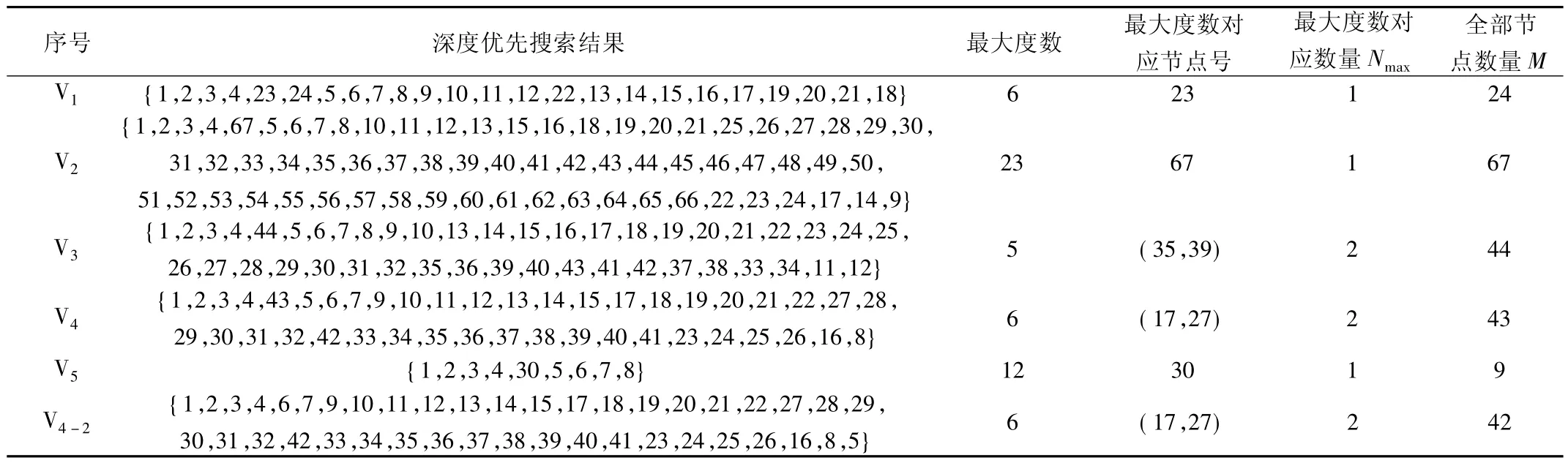
表3 多重拓扑路径表Tab.3 Multiple topology path table
根据图7 和图8 还可得出有向图V1-V5中节点最大度数、最大度数对应节点数量及编号。根据式(4) 计算多重拓扑序列,计算过程在1.3 节已有详述,文中直接给出ACS 的结果及序列相似度,见表4。

表4 文件相似度计算结果Tab.4 File similarity calculation results
2.4 二进制ELF 文件同源性判定
根据公式( 9) 计算AppA-AppB 二进制文件相似度,从表4 中取SimACS(V1,V2) 、从表2 中取Simedit(O1,O2-1) 及Simedit(O1,O2-2) 、从表3 取Nmax及M得:
同理计算得各个App 之间的相似度结果如表4 中第7 列所示。从表4 中可见,参与测试的App 功能基本相似但相似度结果均不相同,范围在( 9. 9393%,40.6097%) 之间。文献[24]指出二进制同源App 的相似度下限为50%,可知AppA-AppE 均未超过同源判定阈值。相同软件代码的不同版本被认定是同源数据集,版本越靠近相似度越高。由于融合终端产品的特殊性,暂时不能进行全部融合终端相邻版本的相似性度量。为验证本文方法有效性,将AppD 的二进制ELF 文件做适当修改后作为试验版本,其有向图如图9 所示:
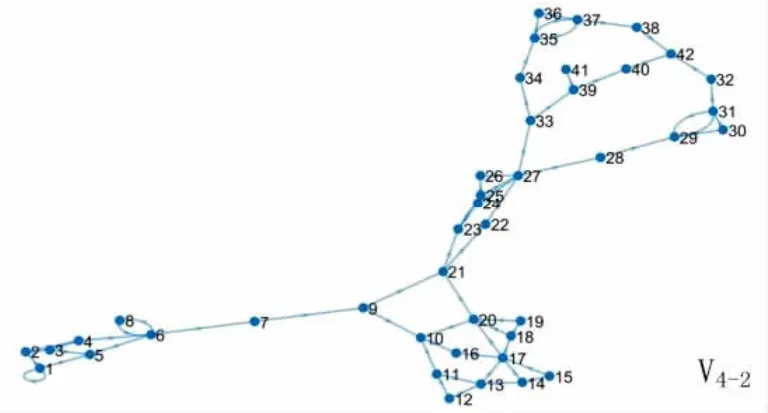
图9 试验版本调用过程有向图Fig.9 Directed graph of trial version calling process
从表3、表4 中提取数据计算AppD-AppDtest的相似度为:
文献[25]指出不同源代码段相似度上限为30%,综上所述的计算结果符合要求。
3 结束语
近年来,软件隐患代码原因导致的App 微应用遭受攻击的数量逐年升高。融合终端产品的快速发展、组件库和代码库数量不断攀升、同源代码规模持续增加,安全缺陷检测研究面临严峻挑战。如何判定App是否同源,作为解决安全问题的共性关键技术变得尤为重要。对二进制代码进行快速相似性度量逐渐成为终端安全防护的重点研究方向。目前融合终端厂家较少,还处在硬件实现和运维工具设计阶段,没有进行批量上线运行,能够进行对比的程序样本较少,因此不适合采用深度学习、神经网络等大批量样本训练的方法进行相似性分析。
针对常规OpCode 检测方法特征维度过高、检测效率低等问题,提出了一种新的基于OpCode 代码段编辑距离和所有公共子序列的图相似性相结合的智能融合终端二进制ELF 文件相似性判定方法。首次将编辑距离引入二进制指令集的相似度比较,从OpCode 序列和代码段调用顺序两个模式进行组合,提出调整后相似度模型的量化公式。与N-gram 法相比规避了维度灾难并且时间复杂度较低,解决了代码段层面的OpCode序列比较难题,为解决融合终端二进制代码相似性度量提供了一种新的途径。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
中等数学(2021年8期)2021-11-22
云南民族大学学报(自然科学版)(2021年3期)2021-06-24
河北画报(2020年8期)2020-10-27
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
四川师范大学学报(自然科学版)(2018年4期)2018-07-04
廊坊师范学院学报(自然科学版)(2017年3期)2017-10-11
浙江大学学报(工学版)(2016年2期)2016-06-05
山西大同大学学报(自然科学版)(2014年2期)2014-01-23
