
基于XML 数据库的制造异构数据关联规则分析与应用
2023-12-26 04:47孙赫刘蜜刘林琳丁成波
智能制造 2023年6期
孙赫,刘蜜,2,刘林琳,2,丁成波
(1.上海威克鲍尔通信科技有限公司,贵州 贵阳 550000;2.贵州航天电器股份有限公司,贵州 贵阳 550000)
1 引言
“工业4.0”[1]和中国“两化深度融合”[2]发展战略的提出,是当今世界制造业的发展趋势和需求。在新一轮以信息技术为核心的制造业变革中,我国实施了“中国制造2025”战略,并且提出了“互联网+”技术。电子信息技术的发展,促进了制造系统与信息系统的融合,“制造物联”趋势明显[3]。在制造生产过程中,产生了海量的异构数据,对工业数据的统一表达是对数据进一步处理的迫切需求,对统一格式的数据挖掘是促进产业变革,工业迅速发展的必由之路。面对产品制造与服务过程提升的需求,制造物联数据的感知、处理等难题,攻克生产过程中信息感知、处理问题,将为生产过程优化控制提供有效支持。
XML(eXtensible Markup Language,可扩展标记语言)是1998 年2 月由W3C 组织制定的一种通用语言规范,它被设计为混合语[4]。XML 的诸多优点,使它为异构的信息系统的数据交换格式提供了一个全新的思路。在XML 的发展过程中,产生诸多种XML 数据模式语言[5]。在这些模式语言中,最广泛的是文档类型定义DTD和W3C XML Schema,DTD 是Web 标 准,任何能 处理XML 文档的浏览器都能对照DTD 模式来检查文档。XML Schema 是一种模式语言,它利用XML 语言规范定义,并且支持更广泛的数据类型,可以通过特定映射机,实现更高层次的数据交换。
现阶段基于数据库的数据挖掘的相关研究主要有以下几种[6-7]:兰建鑫[8]等提出了一种基于深度递归与散列技术改进的Apriori 算法,并对改进算法进行了分析;Liu T[9]基于Apriori 和gradient 算法,采用最优解的迭代过程,达到提升全局收敛速度和计算速度的目的;Zhou Y[10]等提出一种基于Apriori 算法分析空间关联模式在点和线功能描述的算法过程,并对相关数据进行了空间概率和空间问题预测的分析。
本文针对海量制造异构数据的统一表达及分析应用的迫切需求,基于XML 对离散车间中的异构数据统一表达,采用改进的Carma-Apriori 关联规则算法对XML 数据进行关联规则分析。
2 关联规则算法
2.1 基本概念
2.2 Apriori 算法原理
算法基本描述如图1 所示。

图1 Apriori 算法基本描述
2.3 改进的Carma-Apriori 算法
Apriori 算法是通过对数据库多次扫描然后建立频繁项集,Carma[12]算法相对于传统的Ariori 算法而言的优势:①占用内存更小,②可以处理在线连续数据,③扫描一次最多两次可以构造数据集,④允许算法执行过程中按需设置支持度。本文采用改进的Carma-Apriori 算法对XML 数据进行分析实现,改进的Carma-Apriori 算法分析过程如下。
(1)产生频繁项集Lk1)从项目包含相对较多的子集开始判断Lk的真子集,即
式中,beginTrans(n)表示n被插入Lk时所在的事务序号,count(n) 表示Lk中n在事务数据库出现的次数,maxMissed(n)表示Lk中n已添加的事务个数,σi表示支持度阀值。
2)剪枝,每读入一条剪枝一次,对小于最小支持度的maxSupport(n),将其从Lk中移除。
(2)对频繁项集Lk进行去除得到结果集 通过第一步中找出的项集Lk和最后一个支持度σi;对于支持度小于σi的项集,将其去除出U;针对祛除的项集,将其相关集也同样去除。采用Carma-Apriori 算法生成的关联规需要满足以下支持度条件:
3 XML 数据分析
3.1 XML 数据
XML 是一种基于文本的数据描述语言的通用标准,可用于定义数据的结构、属性、类型和格式的相关规范[13]。XML 为Internet 的通用语,其主要适用范围有分布式和web 发布计算、数据交换,是web 的基础。文中所分析的一种基于XML 制造信息的表述示意图,如图2 所示。

图2 基于XML 制造信息的表述示意图
XML 数据的结构属于半结构化并且是易扩展数据表示方法,针对离散制造车间中多源异构数据采集与异构数据同构化,XML 数据可以做到映射转换和结构化的统一表达,文献[14]采用Express-XML 可以完成对异构数据继承、聚合和属性的统一描述。在生产制造过程中,通过传感器网采集数据,并预处理之后采用关联规则进行数据分析与实现。
3.2 对XML 数据的算法描述
Carma-Apriori 算法对XML 数据的分析流程如图3所示。

图3 关联规则挖掘过程
1)对XML 数据库进行扫描并提取出事务T 和相关集,产生候选项集的集合,构成事务集合数据库D。
2)计算最小支持度:maxSupport(n)=(maxMissed(n)+count(n))i,扫描数据库,对候选项集的集合进行统计,并去除小于最小支持度的项集,构成集合L1。
3)通过Lk-1对自身作连接产生候选k-项集合。按照L1,L2,…Lk-1,Lk,…,Ln的次序寻找频繁项集可以避免对事务数据库中不可能发生的项集所进行的搜索和统计。连接l1和l2产生的结果项(l1[1],l1[2],…,l1[k-1],l2[k-1])。
4)频繁k-项集的任何子集合必须是频繁项集。由连接生成的集和真子集进行验证,去除不满足支持度的非频繁k-项集。
5)通过候选(k+1)-项集的集合,对其不满足最小支持度的项集去除,产生频繁(k+1)-项集的集合Lk+1。
6)通过3)~5)的循环迭代运算,直到频繁项集Lk为空集,根据最小置信度产生强关联规则。
3.3 数据分析流程
在离散制造车间中,制造数据感知环境包括有线和无线、传感器网络、现场总线网络等,用于实时制造数据的感知。数据感知主要面向异构传感设备组成的传感器群,进行多源制造信息的采集及异构传感器的管理。通过无线网、互联网、工业局域网、射频、蓝牙和红外等感知采集的信息,实现多源制造信息的实时控制。然后通过XML 数据处理最后进行关联规则的分析与实现,其流程如图4 所示。
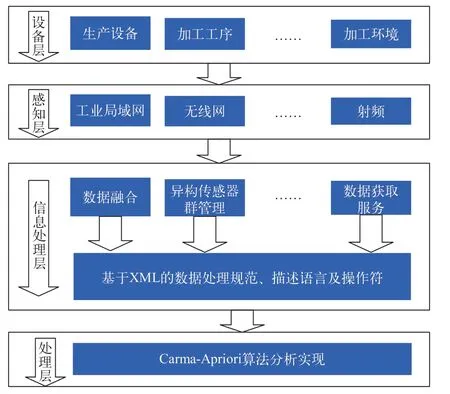
图4 数据感知处理流程
针对物联制造过程产生的实时数据,采用关联规则算法进行分析,在XML 中经过处理后的数据生成的数据内容包含销售商、地点、购买数量及在产品生产过程由传感器获取的生生产过程中压力、温度及时间等。基于XML 数据库,本文对实际生产的数据包括不同温度、压力、时间下,生成的事务数据如图5 所示,项目名称如图6 所示。
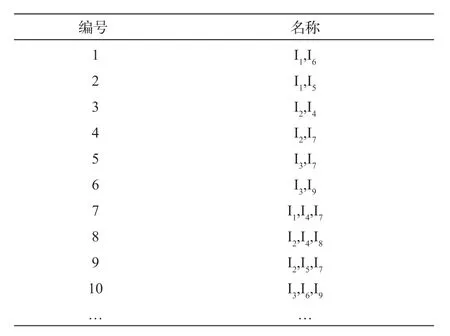
图5 事务数据
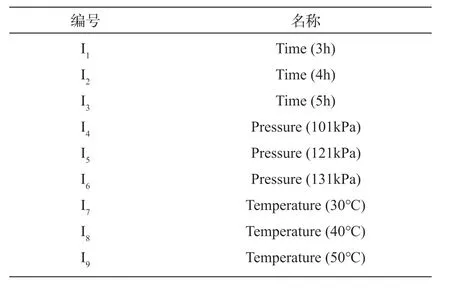
图6 项目名称
强关联规则的产生需要给定最小支持度minsup,这里设定最小支持度minsup=10%。找出支持度大于等于最小支持度的频繁项集进而找出关联规则。carma-apriori 算法挖掘过程示意图如图7 所示。

图7 算法挖掘过程示意图
4 应用实现
基于XML 整合的离散制造车间中由传感器获取的异构数据同构化处理,以某辣椒酱生产线数据感知及整个过程的匹配数据为例,其中包括温度、压力传感器及整个生产过程的时间记录,匹配数据包括供应商、产品销售数量及其出货地址等。采用NVIDIA GeForce GTX960并运用Modeler 软件进行数据挖掘的分析,Modeler[15]可以充分利用计算机系统的运算处理能力,将方法、应用于工具有机的融合一体,是解决数据挖掘的工具之一。设置支持度support=10%,置信度为confidence=40%,基于出传统Apriori 和Carma-Apriori 算法的运行结果及网格关联如图8、图9 所示。
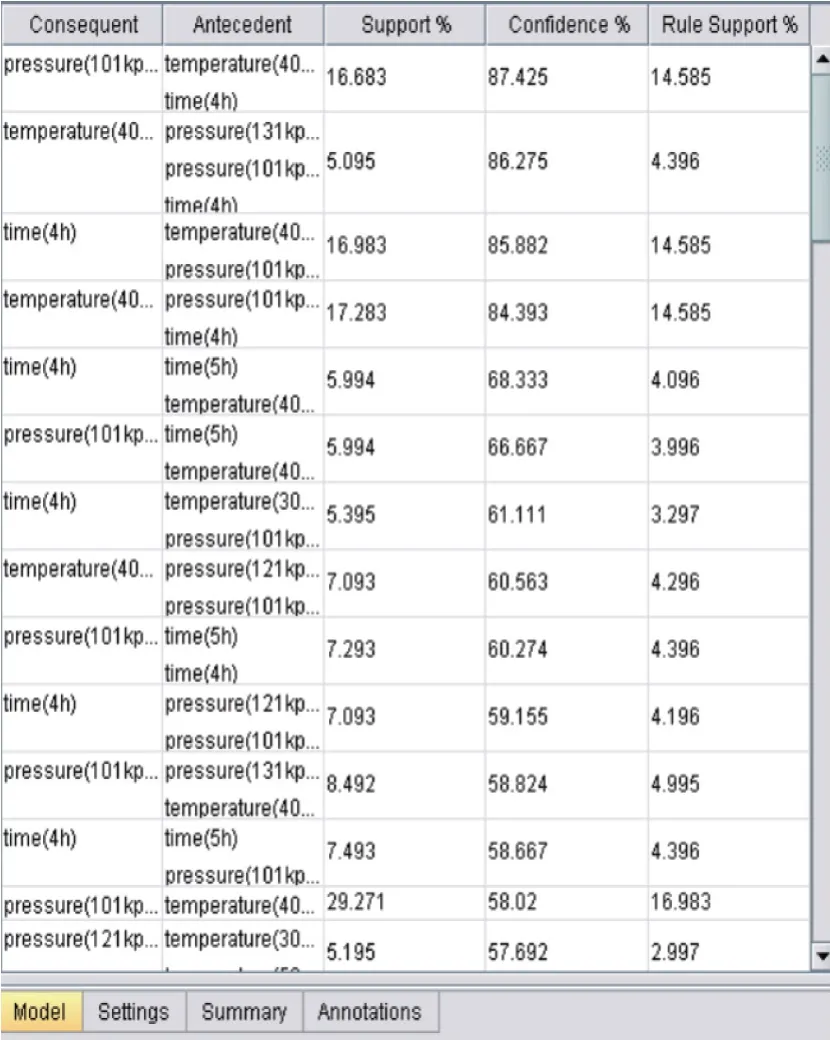
图8 Apriori 数据分析结果
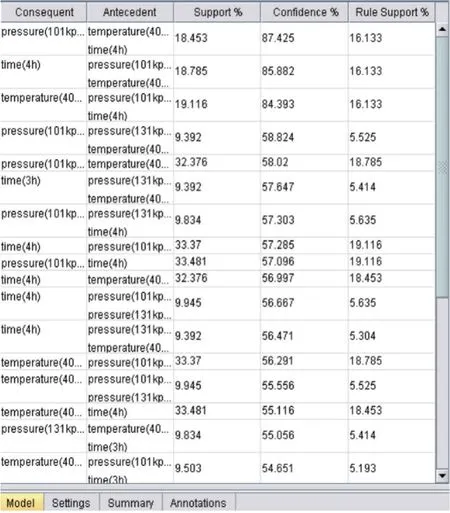
图9 Carma-Apriori 数据分析结果
针对离散制造中,基于XML 统一表达的数据分析结果可以看出,以第一组关联数据为例,温度在40℃、压力在101kPa、时间为4h 的强关联规则中传统Apriori 算法的数据支持度为16.683%,而Carma-Apriori 算法的支持度为18.453%,也就是说在生产过程中采用Apriori 算法的支持度比Carma-Apriori 算法的支持度要低,这是因为Carma-Apriori 算法的支持度support=关联规则产生的数据量/有效数据量,而传统Apriori 算法的支持度support=关联规则产生的数据量/全部数据量。以第二组数据为例,Apriori 产生的数据置信度为85.882%,Carma-Apriori 算法产生算法置信度为86.275%。
因为Carma-Apriori 算法的置信度:
而传统Apriori 算法的置信度:
式中,Consequent表示后项在数据中的pressure(101kPa),Antecedent表示前项在数据中包含的temperature(40℃)和time(4h),纵观全部数据可以得出Apriori 算法的支持度比Carma-Apriori 算法的支持度要低,而置信度上进行数据分析得出,Carma-Apriori 算法的置信度比Apriori算法的置信度要高。造成这样的原因是因为在对制造过程数据的处理的过程中有些数据是无效的,Carma-Apriori算法直接将其祛除,而传统的Apriori 算法将其保留并进行预测计算,也就是说Carma-apriori 算法的计算数据的基数为全部有效数据,而Apriori 算法的数据基数中包含一些无效数据。另外在数据分析过程存在一个参数是rule support,即规则关联度关联支持度公式如下。
传统Apriori 算法的规则支持度:
Carma-Apriori 算法的规则支持度:
在数据分析中,Apriori 的规则支持度比Carma-Apriori 的均要低,所以说Carma-Aprirori 算法对数据分析的关联支持度要比Apriori 算法关联支持度高,在数据处理方面更有效,准确性与预测性比传统的Apriori 算法要更加精确。
在此关联规则中,基于XML 的面向离散制造的数据有supplier(供应商)、value(价值)、总量(quality)、时间(time)、温度(temperature)及压力(pressure)等。基于Carma-Apriori 算法建立的数据网格为所有关联规则的关联线建立,将分析数据调制144~200,存在的关联规则有temperature(50℃)关联pressure(121kPa)、pressure(131kPa)关联time(3h)及pressure(101kPa)与time(4h)、temperature(40℃)的关联,在167~200的高频区域,强关联线为pressure(101kPa)与time(4h)、temperature(40℃)的关联。在此数据分析中,关联规则为生产过程针对供应商提供的商品价格及销售总量与物理参数相匹配形成的数据关联。分析三种物理参数。得出的三条关联规则是温度在40℃、压力在101kPa、时间为4h 的强关联规则,其置信度在85%以上。也就是说在此物理常态下所生产的产品是需求最高的。基于算法对数据分析建立的网状图,可以看出各个物理参数都存在关联,但是在频数较高的区域里温度在40℃、压力在101kPa、时间为4h 三个的关联度最高,与Carma-Apriori算法的关联规则的分析结果相一致。
5 结束语
本文基于XML 数据库对物联制造过程中产生的数据采用XML 数据模型首先做了统一表达,然后通过Carma-Apriori 对关联数据进行了分析,得出结果的置信度在85%以上。但是在实际生产过程中还有能量散失、损耗等问题,也就是说针对离散制造过程的实时数据采集量还略显不足,只能在离散制造中做参考之用,研究工作上还要继续深入。现阶段已经对离散制造过程的数据包含UWB 定位数据及相关人员生产数据完成了系统界面,下一阶段将针对生产过程中的实时数据分析集成在系统界面中,以便对生产过程数据实时进行关联分析处理,达到对生产过程的实时监控与数据处理的目的。
猜你喜欢
小学教学研究(2022年5期)2022-04-28
核科学与工程(2021年4期)2022-01-12
计算机应用(2018年5期)2018-07-25
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
轴承(2015年2期)2015-07-25
卷宗(2014年5期)2014-07-15
计算机工程(2014年6期)2014-02-28
电讯技术(2011年11期)2011-04-02
