
基于改进随机森林算法的机电设备异常运行状态识别方法
2024-01-03 09:09梁绍东陈彰怡
设备管理与维修 2023年22期
梁绍东,陈彰怡
(东兰县中等职业技术学校,广西河池 547000)
0 引言
机电设备运行识别的精准化,一直是机电设备需要考虑的主要因素之一。正常且高效的机电设备可以为优化产品带来更多的便利,机电设备运行状态的识别包括对有无故障以及故障类型等设备运行状态的识别。目前,识别的方式的主要流程是在前期通过信号采集得到机电设备的运行状态信息,对信息做处理,根据处理的信号进行特征的选择,最后将提取处理的机电设备的异常运行状态信息做智能识别。在这个过程中,特征的选择与提取主要是根据信号分析的结果。传统的机电设备异常运行状态的识别过程,在特征的选择和提取上,严重依赖以往的经验知识,很容易出现不熟悉识别情况,并且在剔除和分拣原始信息的过程中,很容易造成丢失有效信息[1]。
机电设备异常运行状态的识别有很多方法,例如经验模式分解法等,但普遍存在特征选择困难的问题,只能以高维信息为直接对象,在现有程序的基础上,设计运行数据上传至上机位的通信流程,通过对机电设备运行信息的特征进行提取并分析。对机电设备异常运行过程中的故障问题进行直接诊断,才能从根本上解决原始信息特征选择的问题。随机森林算法作为一种监督学习算法,主要通过对算法数据的输入进行大量的模拟计算,并通过迭代处理完成算法的优化。目前的随机森林算法主要分为分类和回归两种类型,通过对训练数据的二次处理,对数据进行回归拟合,同时,通过随机选取森林的变量,将分类的节点生成多种分类树,从而产生不同的分类结果。
1 基于改进随机森林法的机电设备异常运行状态识别方法
1.1 提取机电设备异常运行状态特征
为了实现机电设备异常运行状态的识别,对机电设备异常运行状态特征进行提取。对信息的较高的维度进行学习机器的训练,用较小的维度表示机电设备异常的运行状态,以此获取机电设备异常运行信息的特征子向量[2]。根据特征的子向量,可以得到机电设备运行信息训练子集的矩阵模型,用函数公式表示为:
其中,Am为类别机电设备运行信息的散度矩阵,Cm为类别机电设备运行信息的维特征向量,m 为类别数值,n 为机电设备运行的特征的维度。根据机电设备的训练子集的矩阵模型函数模型,可以得到机电设备运行的散度的矩阵计算式,利用高维信息进行学习机器的训练,对数据进行降维处理,将散度的比值进行处理,可以根据机电设备异常运行的训练子集均值向量数值,得到散度的矩阵模型,用公式表示为:
其中,Bm为类别机电设备运行信息的样本集矩阵,g 为运行的维特征均值向量,l 为类别的样本个数。根据散度的矩阵模型,可以得到评价特征子集辨别力的标注函数:
其中,d 为机电设备异常状态的评价特征子集类特征辨别力,根据评价特征子集辨别力,对于特征的子向量,若样本的方差很小并且相似性不大,则说明机电设备异常运行的特征子向量的辨别力强,根据标注函数的判断,将样本的类型分为较纯的子集以及相关性较小的子集,根据子集的特征,完成对机电设备异常运行状态的特征提取[3]。
1.2 基于改进随机森林法机电设备异常运行状态分类
在机电设备异常运行状态提取特征的基础上,根据随机森林算法,将提取的特征进行状态分类,提取的机电设备异常运行的状态特征信息分为多个维度,主要是信息的数量以及样本内变量的信息,生成多个分类的参数阈值,从而根据阈值生成决策树模型[4]。根据决策树的模型,使用改进的随机森林算法,从机电设备的运行数据中随机选取不同的样本数的参数,将参数进行组合,形成众多的随机决策树,在决策树的分类节点上,对数据集的信息熵进行计算,从逻辑关系的角度,根据信息熵得出机电设备异常运行状态的信息熵计算模型,用公式表示为:
其中,hi表示数据集的节点的信息熵,ei表示数据集的节点的机电设备运行的数据集的熵值,f 表示机电设备运行数据集节点之间的信息熵值。根据节点之间的信息熵的数值,得出机电设备异常运行之间联合的熵值。根据联合的熵值,以下降率为主要标准生成下降值最大数值模型,在这样随机选取样本变量的组合下,生成可以并行处理的机电设备异常运行状态信息的决策模型。通过决策模型构建机电设备运行信息识别流程(图1)。
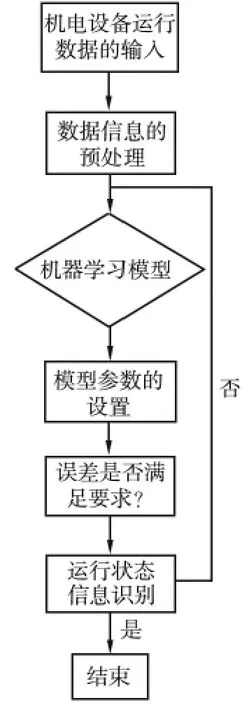
图1 机电设备状态信息识别流程
根据状态信息的识别流程,在随机算法的基础上,对初始参数较小的参数阈值,通过逐次递增选出最优的参数组合阈值,利用机电设备状态的信息训练数值进行随机数值的变量重要性的度量,包括机电设备群点的剔除,以及对训练数据的构建[5]。使用平均算法对机电设备状态运行的权重系数进行选择提取。同时,在此基础上根据采样的节点,得到不同加权系数下的提取函数模型,其函数表达为:
其中,t 为节点机电设备的平滑数值,u(k)表示为滑动加权处理参数,r 为机电设备的平滑采样点。根据得到的加权系数提取函数,得出机电设备的平滑数值参数,将平滑数值参数设置为固定采样点的参数数值,进行统一的归一化处理,得到归一化后的机电设备异常运行信息的数据信息。为了减少数据与节点之间的相互影响,对数据进行预处理,作为算法的输入数据,根据最后的输入数值,得到最后的机电设备运行信息归一公式:
其中,o 表示机电设备异常运行加权参数。通过式(6)得到平均滤波的数据处理数值,通过数据处理数值得到最终的数值,从而完成对机电设备运行数据的识别。
2 实验与分析
为了验证本文设计的机电设备异常状态识别方法的有效性,进行实验论证。在相同的训练样本条件下,采用机电设备中的一个重要断面安全裕度作为指标的历史数据进行实验分析。
2.1 实验过程
将训练样本的数据进行统计,实验采用全体机电设备的数据作为模型的输入数据,为了保证实验的适用性,使用随机取样来选择实验的主要样本,并将主要样本分为6 个编码类别,在6个编码类别分别设置对应的样本比例(表1)。
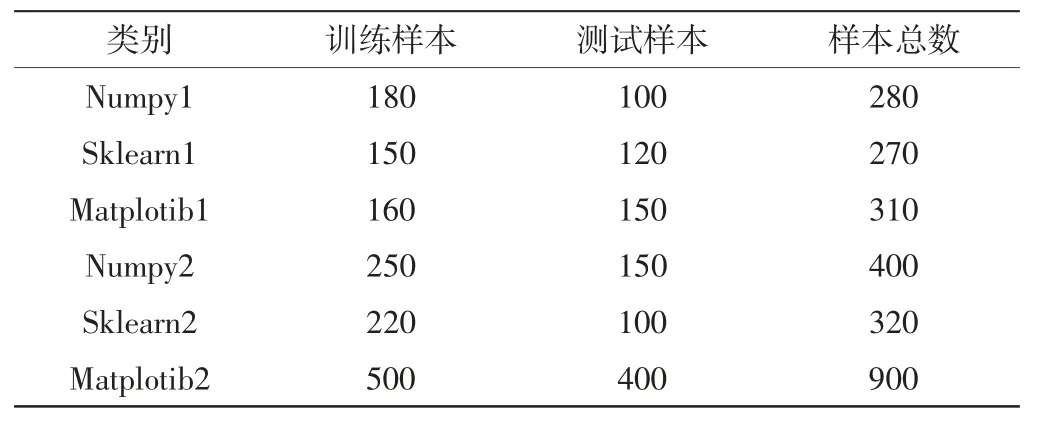
表1 机电设备运行的样本比例
选取合适的初始参数,根据初始参数的不同,将样本数据分为不同的分类结果,采用初始参数值的最小的值为初始值,并筛选出训练误差最小的数值来组合参数。为保证本文提出的基于随机森林算法的机电设备异常运行识别方法的有效性,从训练样本的数据集中随机挑选机电设备运行的数据信息进行深度的特征提取,不同卷积层下的输入与输出特征如图2 所示。

图2 卷积层机电设备的输入特征
从输入特征图中可以清晰地看清机电设备卷积层的轮廓,区分性的局部信息明显,抽象的程度较高,满足实验的基本要求。使用随机森林的分类器,对单独的连接层的输出特征进行测试,在测试中实验的随机个数为200。对200 个参数进行特征组合,得到特征提取的结果如图3 所示。
图3 数据特征提取结果
根据提取的数据特征,使用森林算法识别技术以及其他两种方法进行机电设备异常运行精准度的识别。
2.2 实验结果与分析
采用相同的训练样本,引入不同的识别方法,在6 个编码类别下进行精度测试实验,用UA 表示输入端的节点的精度,PA表示输出端节点的精度,则不同方法下的机电设备运行的异常运行识别精度对比如表2 所示。
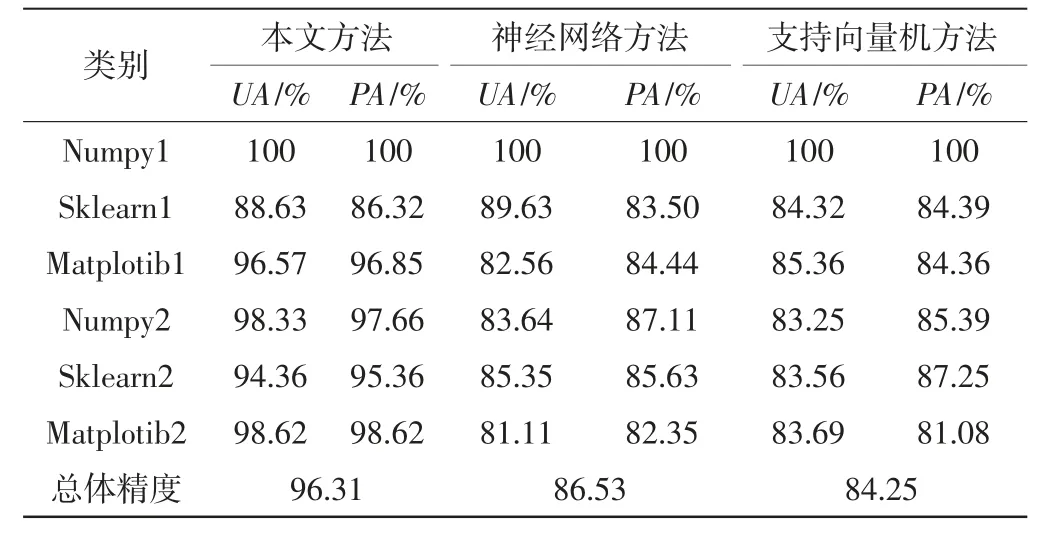
表2 不同方法的异常样本识别精度
通过三种方法异常运行识别精度的比较,可以看出,随机森林算法的识别精度明显高于其他方法,不论是在输入区域的精准识别还是在输出的精准识别方面,其精准度都高于其他两种方法。随机森林算法下的识别方法对运行数据做了精准分类并进行了异常数据特征的提取,能够实现机电设备异常运行状态的精准识别。
3 结束语
本文以机电设备的运行状态识别作为研究内容,在改进随机森林算法的基础上,分析了自动化的机电设备的典型工作流程。使用随机森林算法完善数据的识别功能,通过集中存储机电设备的正常运行状态信息,并对异常可疑状态进行简单分析,实现设备故障自动化识别以及软件的故障引导识别,从而实现了机电设备的高精度运行识别。
猜你喜欢
小学生学习指导(低年级)(2023年4期)2023-05-09
中学生数理化·高一版(2021年11期)2021-09-05
建材发展导向(2021年13期)2021-07-28
建材发展导向(2021年11期)2021-07-28
中学生数理化·高一版(2021年2期)2021-03-19
经济技术协作信息(2018年8期)2019-01-14
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
焊接(2016年2期)2016-02-27
