
基于Attention 机制改进TimeGAN 的小样本时间序列预测方法
2024-01-05 12:42黄开远
华东理工大学学报(自然科学版) 2023年6期
黄开远, 罗 娜
(华东理工大学能源化工过程智能制造教育部重点实验室, 上海 200237)
近几年,利用深度学习进行时间序列预测的方法在多个领域如环境温度预测[1]、金融股票预测[2]、工业指标预测[3]等取得了广泛的成功。一般来说,其优越的性能得益于数量庞大的训练样本。然而,在实际过程中存在样本数据难以收集的问题。Um 等[4]指出在少量训练样本的情况下,预测模型可能无法捕获训练数据中的特征依赖关系,导致算法陷入局部最优。因此,缺少数据支持的模型精度难以满足预期目标。
为了弥补数据不足带来的问题,研究者提出了小样本学习(FSL)。Li 等[5]将从较少的训练样本中训练模型的学习任务称为FSL。Wang 等[6]认为FSL监督学习的核心问题是不可靠的经验风险最小化器,由于训练过程中经验风险偏离期望风险,两者的误差受样本数量与假设空间的影响,导致模型精度下降。因此,必须利用一些方法来降低经验风险与期望风险之间的误差。小样本学习分为数据增强、模型改进、算法优化3 类。Fawaz 等[7]指出数据增强方法通过提高训练数据规模有效地避免了训练过程中出现的过拟合问题。本文采用数据增强方法处理时间序列预测任务中存在的小样本问题。
小样本问题最早在图像分类、图像识别等领域被广泛研究,例如可以通过旋转、平移等几何变换[8]进行图像数据增强。Schwartz 等[9]针对类别数据不平衡的问题,通过学习样本较多类别中不同实例的迁移关系,应用在样本较少的类别中,以生成同类别的数据。Dubost 等[10]将现有的已经分析好的图像进行组合处理,对血管中蛋白质含量信号进行检测,提高了检测精度。在回归问题上,Li 等[11]通过对原始数据添加高斯噪声来进行数据增强。Zhang 等[12]提出了混合数据增强(Mixup)方法,主要是将数据以线性插值的形式进行扩充。
数据增强方法在回归与分类领域得到了充分的研究与发展,但对于时间序列数据的增强方法却少有研究。Wen 等[13]指出,在对多元时间序列进行预测分析时需要考虑多维特征在时间维度上的复杂动态变化,因此,将图像处理等领域的数据增强方法应用于时间序列数据时可能不会产生有效的合成数据。Niyogi等[14]提出了虚拟样本生成的概念,认为生成虚拟样本的过程实际上是利用随机变量拟合指定的数据分布,所生成的虚拟样本拥有与原数据相似的特征分布。生成对抗网络(GAN)[15]利用虚拟样本生成概念生成了合成数据。GAN通过联合训练生成器与判别器对原数据分布进行拟合,并逐步发展出如条件生成对抗网络(CGAN)[16]等结构。改进条件生成对抗网络(RegGAN)[17]利用采样生成新的特征数据xˆ ,而对于其标签yˆ ,则通过对CGAN 的条件进行修改,生成估计值。具有对抗性训练的连续循环神经网络(C-RNN-GAN)[18]将GAN 与循环神经网络结合起来,对时间序列小样本问题进行数据增强,但这种方法并不能保证有效地捕获数据在时间步上的依赖关系及其动态特性。Yoon 等[19]提出了一种新的GAN方法TimeGAN,通过将预测任务的监督学习方法与编码任务的非监督学习方法结合起来,有效地生成了时间序列数据。Deng 等[20]利用TimeGAN对病人是否患有高血糖或者低血糖的分类问题进行数据增强,展示了较好的分类结果。
为了解决时间序列预测建模任务中的小样本问题,本文提出了一种基于注意力机制并融合时间卷积网络与长短期记忆网络(LSTM)的数据增强网络(ATCLSTM-TimeGAN),通过融合注意力机制[21]与时间卷积结构(TCN)[22],获得更好的数据生成效果。针对TimeGAN 在编码-解码结构[23]中将输入数据编码后用解码器重构输入数据时存在时间序列信息丢失的问题,使用基于Soft-Attention 机制[24]的LSTM 网络[25]构成编码-解码网络,有效地解决了该问题。针对生成网络中生成器的输入一般为随机向量,用基于Self-Attention[26]的TCN 结构来组成生成器,充分考虑了所有变量的影响。因此,ATCLSTM-TimeGAN可以自适应地选择最相关的特征序列,取得最优的数据生成效果。真实性与有用性的实验结果表明:对比于其他数据增强方法, ATCLSTM-TimeGAN 所生成的数据更贴合于原数据分布,具有更低的预测误差。
1 问题描述
给定时间窗口尺寸为T的n维输入时间序列{x1,x2,···,xt,xT} ,其中xt=(x1t,x2t,···,xnt)∈Rn,其标签y∈R 与整个数据特征在t1∼tT时刻的分布相关。时间序列预测模型旨在学习当前目标值yT的非线性映射:
其中:F(·) 是需要学习的非线性映射函数。这通常需要大量的监督样本来进行模型训练。FSL 的目标是在给定训练集Dtrain只提供有限的监督信息的情况下获得良好的学习性能。本文采用数据增强的方法,通过对原数据分布进行估计,然后在估计分布和真实数据分布之间建立映射,生成与真实数据分布相匹配的新的合成样本,即p(x1:T)≈p(xˆ1:T) 。最终通过对数据集的扩充,获得良好的预测模型。
2 时间序列数据增强方法
2.1 TimeGAN
考虑一般的时间序列过程,通常可以将时间序列分为静态过程、动态过程以及随机噪声。时间序列生成模型除了需要捕捉数据在相关时间点的静态特征分布外,更应该关注其多维特征的动态变化。TimeGAN是在GAN 的基础上诞生的,专门用于时间序列小样本问题,有4 个组成部分,联合训练3 个损失函数,其主要目标是最小化生成数据与原始数据之间特征分布的差异:
GAN 的基本思想如下:给定一个数据集X={x1,x2,···xi···,xm}∈Rn,其 中xi为n维 特 征 的 第i个数据,定义一个生成器网络G,对于一个随机向量Z∈Rn,这个随机向量一般为Gaussian 分布或均匀分布,在经过生成器得到的生成数据G(z) ,其分布PG(z)能够逼近于原数据分布PX。为了衡量这两个分布的逼近程度,定义并训练一个判别器D,本质上D是一个先验二分类判别器。为了生成真实数据,需要最小化 l n(1-D(G(z))) ,即通过合成数据与真实数据之间分类的差距,利用反向传播对生成器进行训练,其目标函数为:
一旦判别器D收敛,可以得到PG(z)≈PX,因此GAN 可以生成近似于目标分布的数据。
TimeGAN 将GAN 的无监督对抗生成训练与回归模型中的监督训练结合起来,实现对时间序列问题的数据增强。TimeGAN 的4 个组成部分分别为编码网络E、解码网络R以及GAN 网络中的D和G。嵌入和恢复网络提供特征和隐藏空间之间的映射转换,一方面减少网络计算的维度,同时也提取其静态与动态特征,与seq2seq[27]结构类似,嵌入网络与恢复网络维护一个重构损失函数(LR):
同样,在时间序列数据下为了生成近似于目标分布的合成数据,对于D和G网络对抗训练损失函数(LU)定义为:
此外,对于时间序列而言,数据的时间维度与特征维度会对目标变量产生不同的影响,仅仅依靠GAN 中的对抗训练与编码-解码网络的非监督训练,无法准确捕捉到其时间维度上的动态特性,生成的数据只是每个时刻上数据特征的单一重构,使生成的时间序列数据失真。因此,要求生成器G在生成数据的同时, 给定 1 ∼T-1 时刻的输入数据,能够预测下一时间步T的数据,也即生成网络能够同时捕获整个时间窗口内数据在特征维度和时间维度的分布,其预测损失函数(LS)公式为:
2.2 ATCLSTM-TimeGAN
在对一个时间序列过程进行分析建模时,一般会考虑循环神经网络及其变体,如GRU[28]、LSTM[29]等。一般常用循环网络来分别组成TimeGAN 的各个部分,然而,在数据样本量较少的情况下,TimeGAN中编码-解码结构随着输入数据时间步的增加,其编码效果显著下降。Goldberg[30]提出了基于注意力机制的编码-解码网络,能够有效解决这一问题。因此,将编码网络在每一时刻输出的特征采用Soft-Attention 机制进行解码,相当于采用匹配机制来选择所有时间步上的隐藏状态部分,自适应地将权重分配到所有时间步上,对不同时间步的输入给予不同的关注权重,解决其编码-解码过程中存在的动态信息丢失问题。此外,对于生成网络G,其输入一般为随机向量矩阵Z,目的是通过不断训练使生成器能够将归一化后的值域区间分布与原数据特征分布形成对应关系,利用循环网络提取区间分布特征可能会模糊其特征分布的对应关系。与循环网络将每个时间步的信息编码到一个不断传播的隐藏状态不同,TCN 通过不断扩大的感受野,逐步将整个时间窗口的数据特征覆盖,因此考虑使用TCN 构成生成网络。同样,为了对不同时刻向量zt给予不同的关注度,自适应地给予不同权重,采用Self-Attention机制融合卷积结构,生成最贴合于原数据分布的合成数据。ATCLSTM-TimeGAN 的结构如图1 所示,图中Q、K、V分别为查询、输出、值矩阵,dk为Q与K的特征维度,ht为提取到的高维隐藏层特征。
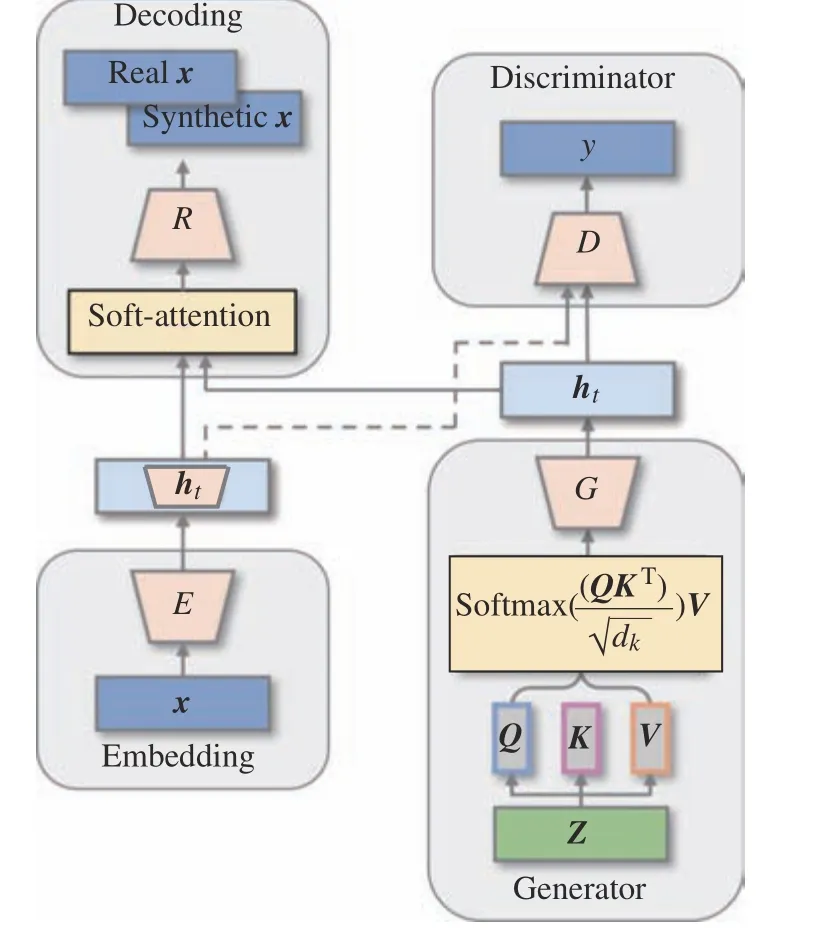
图1 ATCLSTM-TimeGAN 结构Fig.1 Structure of ATCLSTM-TimeGAN

图2 Soft-Attention 的结构Fig.2 Structure of Soft-Attention
通过在编码-解码网络中引入Soft-Attention 机制,对不同时间步状态给予不同的注意力权值,获得更好的编码-解码效果。在生成网络中利用TCN 卷积结构,通过不断扩张的感受野对整个时间步的输入数据进行覆盖,同时加入Self-Attention 机制充分考虑了所有变量的综合影响,获得较好的数据生成效果。
其中:ett′∈R ,即为当前时刻下对所有输入给予不同注意力的权值,可以通过式(9)求得;式(9)中v、W为模型参数,它们与编码器和解码器中的各个权重与偏移项以及嵌入层参数等都是需要同时学习的模型参数。
2.2.2 Self-Attention 在生成器中,对于一个n维的输入随机序列Z=(z0,z1,···zt···,zT) ,其中zt∈Rn,因为序列一般为均匀分布或高斯分布的随机值,生成器捕获归一化的值域区间取值分布与真实数据分布之间的对应关系,极小化其分布的差值,所以才能生成与真实数据分布相似的合成数据。然而,一方面,随机序列本无时间维度的关系,使用循环网络来合成数据可能会模糊其特征对应关系;另一方面,卷积网络对无时间序列关系数据的特征提取能力优于循环神经网络,因此在生成器中使用TCN 网络来生成数据。TCN 网络结构如图3 所示(图中d表示膨胀系数)。同样,在输入到TCN 卷积结构之前,自适应分配权重给不同时间步的输入,采用Self-Attention机制提取输入数据间的依赖关系,以达到数据生成的最佳效果。
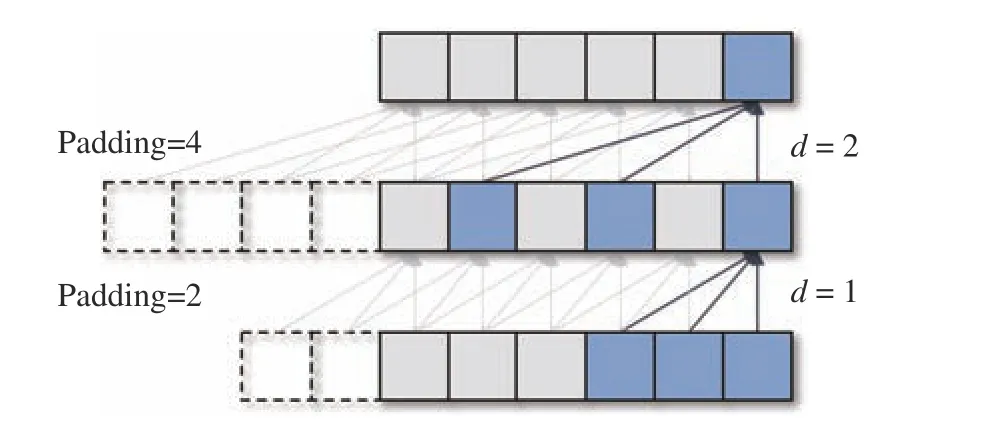
图3 TCN 网络结构Fig.3 Structure of TCN

图4 Self-Attention 的结构Fig.4 Structure of Self-Attention
3 实验与分析
为了验证本文所提出的数据增强方法用于小样本情况下时间序列预测问题的有效性,本文首先在两个典型时间序列数据集上进行数据生成与可视化的基准实验,这两个数据集样本数量庞大,利用较多样本的分布可视化更直观地展现生成数据与原始数据分布间的差异,以检查生成样本的真实性。然后,在两个典型工业过程数据集中进行数据增强后的时间序列预测,验证所生成数据的有用性。
(1) 可视化。将合成的数据与原始数据进行t分布-随机近邻嵌入(t-SNE)和主成分分析(PCA)降维可视化处理。与PCA 分析类似,t-SNE 也是一种降维技术,它将不同数据之间的相似程度转化为概率分布,使特征相似的过程数据映射在低维空间具有相似的分布,以此评价合成数据的真实性。
(2) 预测。为了模拟实际生产过程中数据量不足的问题,使用少量样本进行数据增强与预测。少量样本的数量为原始数据刚好能够得到较好预测效果最小数据量的一半,这样的样本数量在不进行数据增强时得到的预测网络的预测效果达不到预期目标。使用数据增强方法对训练数据进行扩充后,通过预测误差评价合成数据的有用性。
3.1 数据集
空气质量(Air Quality)数据集收集了某个被污染地区的空气质量,包括一氧化碳、苯等污染物指标的含量。通过特征工程去除缺失值较多的特征序列,并对缺失值较少的特征序列进行平均值填充,保留12 个相关特征序列,其中以苯含量作为目标序列值。经过测试,在使用200 个以上原始数据进行预测训练时,能获得可接受的预测效果,均方误差(RMSE)为0.015 左右,因此选择使用100 个原始数据进行增强。
用电能耗(Appliances Energy)数据集收集了环境数据与用电量之间的关系。通过特征工程,保留25 个相关特征序列,以用电量为预测量。该数据集的特征维度较高,数据中用电量变化较大,存在较多突变点。通过不断测试,在使用1000 个样本进行预测训练时,能获得可接受的预测效果,RMSE 为0.06左右,因此选择使用500 个原始数据进行增强。
工业蒸汽(Industrial Steam)数据集通过对锅炉传感器进行分钟级别的连续采样,根据锅炉的工况,预测产生的蒸汽量。对特征与目标之间进行相关性分析,保留12 个相关特征序列作为输入。经过不断测试,在使用100 个以上原始数据进行预测训练时,能获得可接受的预测效果,RMSE 为0.064 左右,因此选择50 个原始数据进行增强,生成50 个合成数据,共100 个数据作为训练集,然后进行预测训练。
青霉素(IndPenSim)数据集是工业级青霉素发酵过程模拟器IndPenSim 所生成的数据,具有较强的非线性和不确定性。通过相关性分析与在线可测性分析,保留9 个相关特征序列,对青霉素生产终点的质量进行预测。经过测试,在使用250 个以上原始数据进行预测训练时能获得可接受的预测效果,RMSE为0.067 左右,因此选择150 个原始数据进行增强,生成150 个合成数据,共300 个数据作为训练集,然后进行预测训练。
3.2 评估指标与参数设置
在上述数据集中将ATCLSTM-TimeGAN 与一些数据增强方法进行性能比较,包括Mixup、C-RNNGAN、TimeGAN(含使用LSTM 与GRU 的TimeGAN),以及本文所提出并逐步改进的基于时间卷积神经网络的TC-TimeGAN、基于注意力机制的Attention-LSTM-TimeGAN。为了评估不同模型所合成数据的真实性与有用性,首先通过可视化合成数据与真实数据的分布评估其真实性。然后,通过比较合成数据用于样本数量较少情况下的预测性能评估其有用性。
数据增强网络中可调节的参数主要包括:网络层数n,隐藏层单元数m。预测网络中的参数主要包括:预测网络LSTM 的n与m。实验中统一将时间步长T设置为8,在4 个数据集的实验中,数据增强网络的n统一设置为2,m根据数据特征维度不同分别设置为12、16、12、10,迭代次数(epoch)统一设置为5000;预测网络的n同样统一设置为2,m根据数据特征维度不同分别设置为12、16、12、4,epoch 统一设置为1000。本文在3 个不同的评价标准上进行预测结果对比,分别是RMSE、平均绝对误差(MAE)、平均绝对误差百分比(MAPE),并对多次试验结果取平均值。
3.3 生成与可视化
为了评估合成数据的真实性,本文在Air Quality数据集与Appliances Energy 数据集上利用小样本下原数据训练的数据增强网络生成5000 个合成数据然后与原5000 个样本进行可视化对比,结果分别如图5、图6 所示。C-RNN-GAN 在训练过程中只是将随机向量简单编码后与原数据一起进行对抗训练,其生成数据的可视化结果较差,并且很可能生成了超出原数据分布的合成数据。GRU-TimeGAN 在用Appliances Energy 预测数据集中所生成的数据对原数据具有较好的覆盖,但在Air Quality数据集中表现并不理想,其原因是该数据集不够稳定,对模型捕捉特征分布的性能要求较高,而TimeGAN 在这方面的能力较弱。基于Attention 机制的TimeGAN 由于在生成模型中仍然使用LSTM网络,其生成数据可视化结果仍然具有改进空间,并且可能存在过拟合的情况。而ATCLSTM-TimeGAN通过引入TCN 卷积结构获得更好的特征提取能力,其生成数据可视化结果均优于其他基线模型。不同方法所合成的数据用于预测训练的结果如表1、图7 和图8 所示,可以得知, ATCLSTM-TimeGAN所生成的数据用于预测时,在各项评估指标中均占据优势。
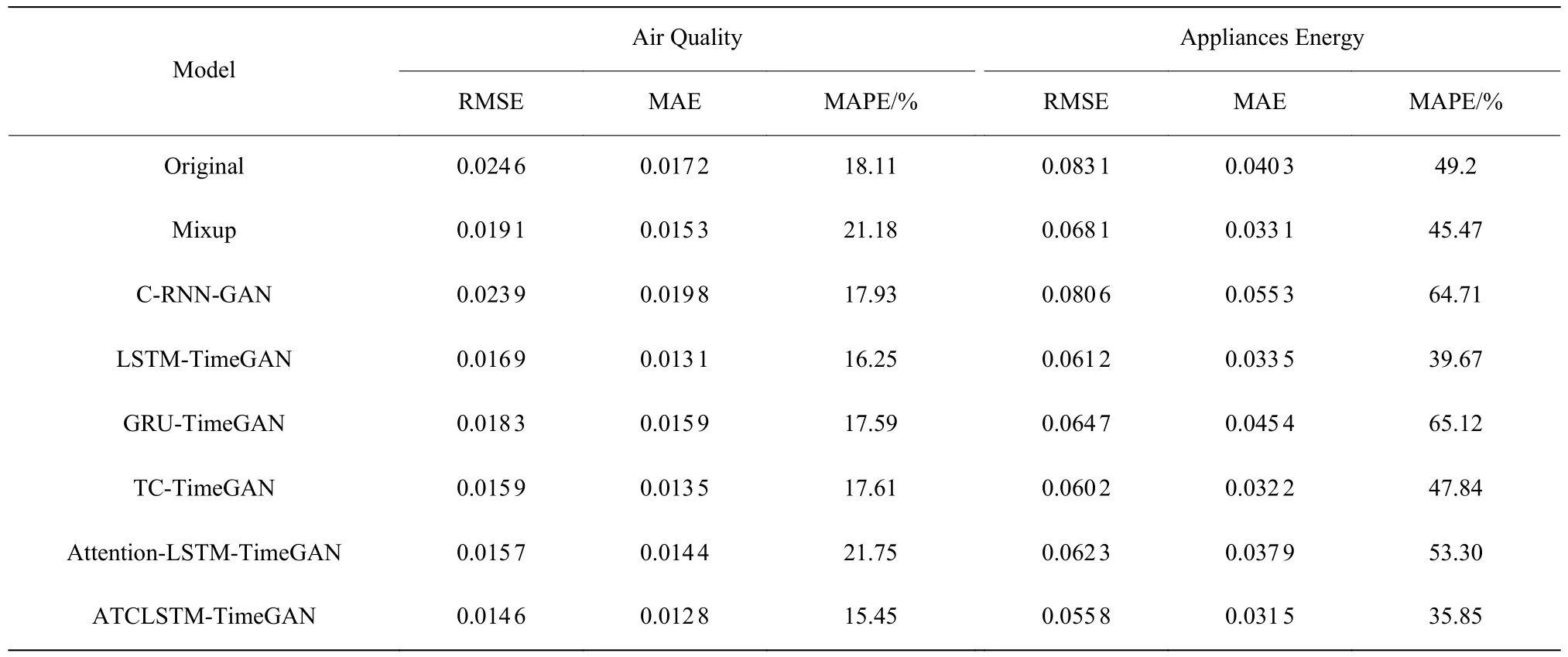
表1 Air Quality 数据集与Appliances Energy 数据集预测性能对比Table 1 Prediction performance comparison between Air Quality dataset and Appliances Energy dataset
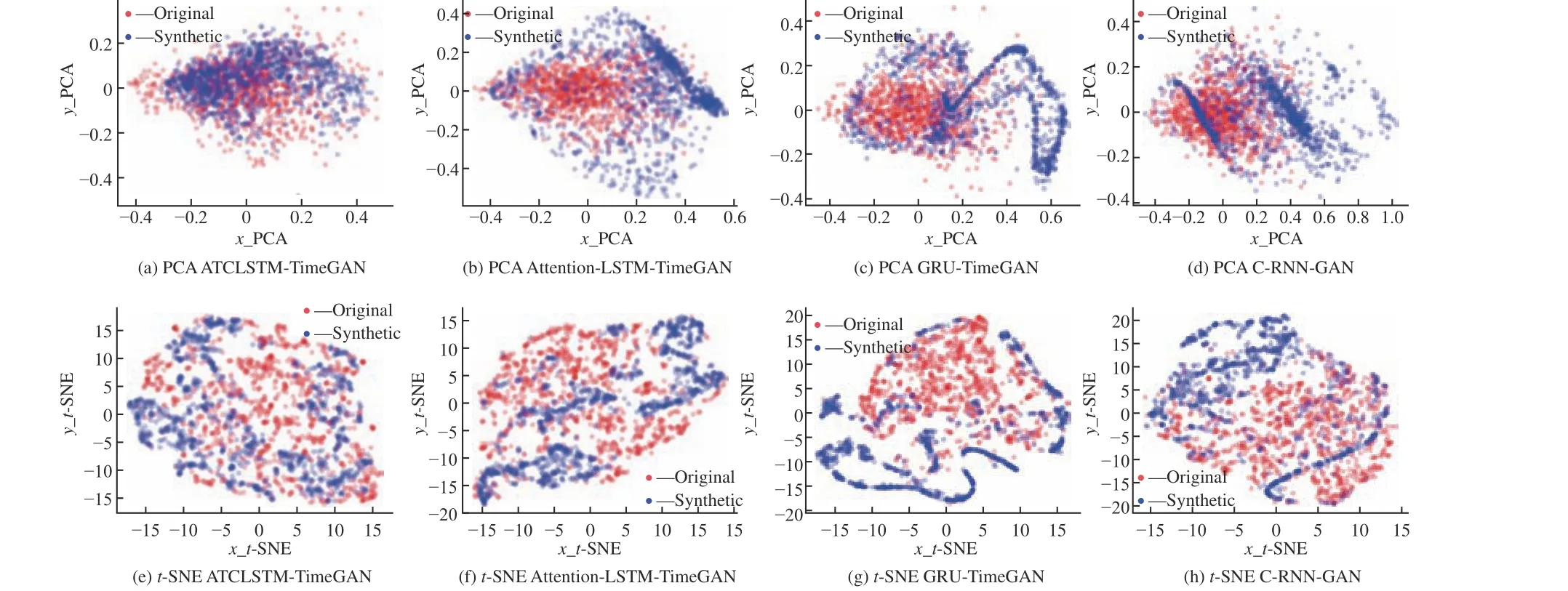
图5 Air Quality 数据集t-SNE 与PCA 可视化对比图Fig.5 Comparison of t-SNE and PCA visualization of the Air Quality dataset

图6 Appliances Energy 数据集t-SNE 与PCA 可视化对比图Fig.6 Comparison of t-SNE and PCA visualization of the Appliances Energy dataset

图7 Air Quality 数据集预测曲线图Fig.7 Air Quality dataset prediction plots
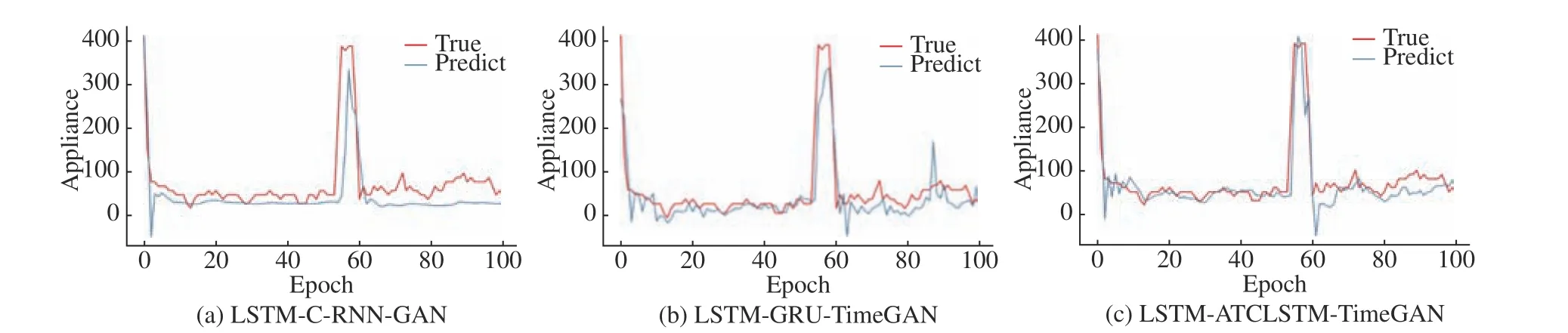
图8 Appliances Energy 数据集预测曲线图Fig.8 Appliances Energy dataset prediction plots
3.4 预 测
为了验证本文所提出的数据增强方法能够解决实际生产过程中存在的小样本问题,在Industrial Steam 数据集和IndPenSim 数据集上模拟数据量不足的情况下,利用数据增强方法进行预测训练,以评估模型生成数据的有用性,可视化对比如图9、图10 所示。不同方法用于预测时的结果如表2 与图11、图12 所示。分析两次实验的预测结果可知,使用CRNN-GAN 增强后的预测效果最差。Mixup 方法对原数据采用线性插值来生成虚拟数据,实验过程中发现该方法所得到的可视化分布图几乎是完全覆盖与跟踪的,其原因是该方法只对现有数据的插值进行组合,而忽略了变量之间的复杂关联,数据的有用性得不到保障。基于循环网络的TimeGAN 通过在训练过程中强调数据的时间序列依赖特性进行联合训练,生成相对真实的时间序列数据,在合成数据的真实性与有用性上取得了较好的结果,但由于其编码结构与特征提取能力的缺陷,对特征分布不稳定性较高的数据集的预测结果较差。ATCLSTMTimeGAN 模型生成的数据用于训练预测网络所得到的3 个评价结果均优于其他基线模型,其预测曲线在突变点与峰值处具有更好的预测效果,并且能够达到在数据充足情况下的预测效果。
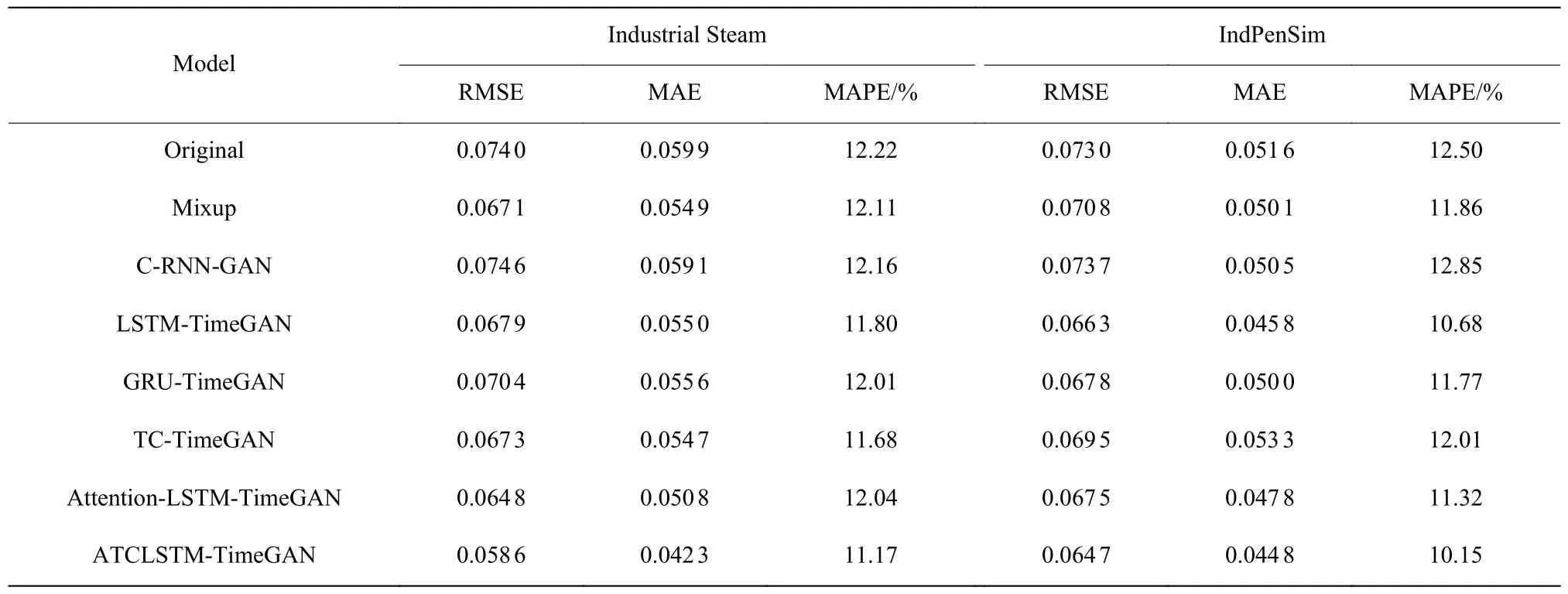
表2 Industrial Steam 数据集与IndPenSim 数据集预测性能对比Table 2 Prediction performance comparison between Industrial Steam dataset and IndPenSim dataset

图9 Industrial Steam 数据集生成数据与原数据t-SNE 与PCA 可视化对比图Fig.9 Comparison of t-SNE and PCA visualization of the Industrial Steam dataset

图10 IndPenSim 数据集生成数据与原数据t-SNE 与PCA 可视化对比图Fig.10 Comparison of t-SNE and PCA visualization of the IndPenSim dataset
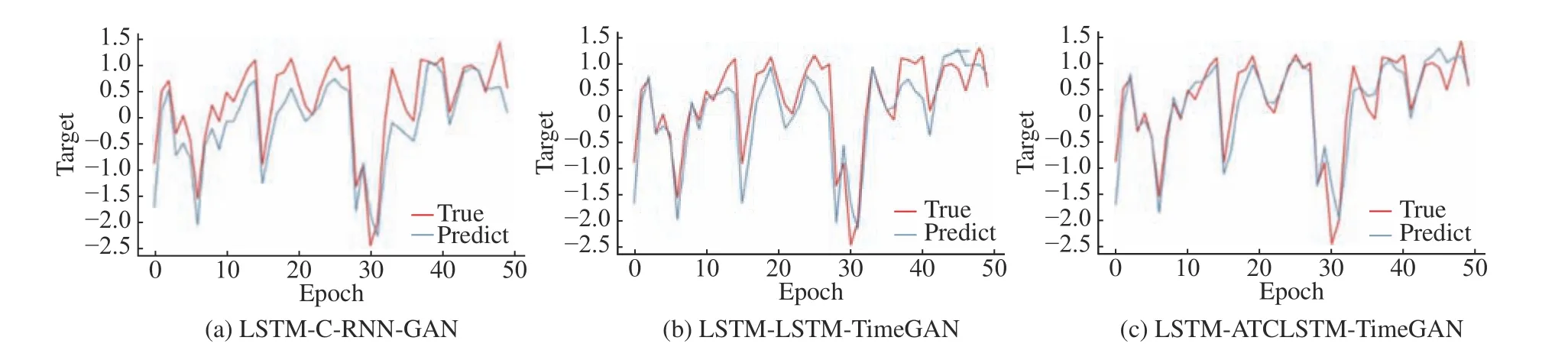
图11 Industrial Steam 数据集的预测曲线Fig.11 Prediction plots of the Industrial Steam dataset
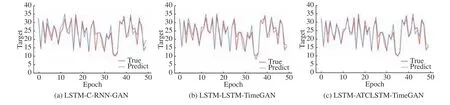
图12 IndPenSim 数据集的预测曲线Fig.12 Prediction plots of the IndPenSim dataset
3.5 分 析
本文引入Attention 机制得到Attention-LSTMTimeGAN,自适应地将权重分配于时间序列特征维度上,提取时间序列依赖关系,增强网络的编码-解码能力。针对TimeGAN在特征提取能力上的缺陷,引入TCN 的卷积结构,将归一化后值域区间内的取值分布与真实数据的分布形成对应关系,得到TCTimeGAN,增强其特征提取能力。这两个改进的模型在合成数据分布可视化效果与预测效果方面均优于原TimeGAN,说明模型的改进有一定的效果。ATCLSTM-TimeGAN 融合这两个改进点,继承其优点,在合成数据可视化与预测任务中均优于其他基线模型。
表1、表2 示出的original 代表小样本情况下不使用数据增强方法的预测效果,结果表明很难得到满意的预测准确度。从4 个实验的预测效果图中可知,ATCLSTM-TimeGAN 所合成的数据在突变点与峰值处具有较好的增强效果,说明所合成的数据对原数据具有较好的覆盖。在实验过程中设置各种网络参数的数量相近,避免因参数的数量相差过大影响实验效果。相较于不使用数据增强方法,将ATCLSTM-TimeGAN 所合成的数据加入到预测训练中,使预测精度在Air Quality、Appliances Engergy、Industrial Steam、Indpensim 这4 个数据集上分别提升了41%、33%、20%、12%。
4 结 论
本文针对时间序列预测任务中存在数据量不足而无法准确建模的时间序列预测小样本问题,改进原TimeGAN 结构而提出了ATCLSTM-TimeGAN。两个大规模数据集的PCA 与t-SNE 的可视化结果表明,ATCLSTM-TimeGAN 所合成的数据对原数据具有更好的跟踪与覆盖,真实性更高,优于其他数据增强网络。最后在两个典型工业过程中验证合成数据的有用性,即通过数据增强的方法来解决实际生产过程中数据样本量不足的问题。实验结果表明ATCLSTM-TimeGAN 所生成的数据用于预测训练时,在突变点与峰值处能够产生较好的拟合,具有更低的误差,能够显著提高小样本情况下预测模型的精度。
猜你喜欢
黄河之声(2022年10期)2022-09-27
世界科学技术-中医药现代化(2022年3期)2022-08-22
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
云南化工(2021年8期)2021-12-21
中学生数理化·高一版(2021年2期)2021-03-19
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
