
基于自适应深度集成网络的概念漂移收敛方法
2024-01-12 06:53郭虎升王嘉豪王文剑
计算机研究与发展 2024年1期
郭虎升 孙 妮 王嘉豪 王文剑
1 (山西大学计算机与信息技术学院 太原 030006)
2 (计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006)
(guohusheng@sxu.edu.cn)
随着大数据时代来临,传感器数据、在线交易数据、社交媒体数据、用户在线行为数据等源源不断地产生. 不同于传统的静态数据,这些数据具有实时性、无限性、不可再生性等特点,称之为流数据. 近年来,互联网产业与人工智能技术迅猛发展,流数据挖掘的研究价值正变得愈来愈重要.
在流数据挖掘任务中,学习器往往需要进行动态调整以适应数据的实时变化. 例如,对于推荐系统,用户的喜好可能随着时间改变,导致数据分布随着时间变化,不同时刻的数据不再满足独立同分布假设,数据分布的这种变化将导致后验概率的变化,因此先前训练得到的学习模型不再适用于新分布的数据,流数据的这种分布变化被称为概念漂移[1-3].
目前许多在线学习模型都基于集成学习技术,利用多个学习器的加权或投票来取得比单个学习器更好的性能[4-5]. 同时,根据学习模型是否主动对概念漂移进行检测,在线学习方法可分为基于漂移检测的主动在线集成方法和自适应的被动在线集成方法.基于漂移检测的主动在线集成方法大多通过模型性能指标(例如准确率)的变化来检测概念漂移,当模型性能发生大幅度波动时,说明流数据可能发生概念漂移,此时模型会用一个新的学习器来替换效果最差的旧学习器[6-10]. 然而,这种主动在线集成方法易受噪声或数据块大小的影响,造成学习器性能的大幅度波动,并且可能不能对概念漂移正确判断,导致模型性能不佳. 自适应型的被动在线集成方法[11-14]不直接检测概念漂移位点,而是根据流数据的变化情况动态地调整模型权重. 然而,这种方法难以利用历史信息去调节每个学习器权重以达到适应性和稳定性之间的平衡,并且不能很好地处理概念漂移. 此外,大多数在线学习方法都是基于线性分类器或者简单的非线性分类器(例如决策树、支持向量机、聚类等)[15-17],这些分类器表征能力较弱,且难以处理较复杂的流数据挖掘任务.
近年来,深度学习技术在图像分类[18]、目标检测[19]、机器翻译[20]等领域取得了巨大成功. 与其他方法相比,深度学习技术拥有强大的表征能力,可以应用于许多复杂任务. 传统的深度学习方法使用大规模数据集对模型进行训练,并通过验证集来选择合适的模型架构(例如网络层的数量、每层神经元数量等),使模型能够有较好的泛化性能. 然而,在流数据挖掘任务中,模型每次只能在新进入的1 个或者一小部分数据上训练和更新模型,无法利用验证集来进行模型架构选择,这就要求模型必须能够实时地动态调整以适应不断变化的数据流.
在线深度学习方法利用深度神经网络强大的表征能力去处理流数据以得到更好的效果. 尽管可以利用反向传播算法[21]对流数据直接优化损失函数,但这种方式仍存在一些问题. 首先,在流数据挖掘任务中,模型单次只能处理1 个或一小批数据,这就要求模型要有很灵活的结构,能够在动态变化的环境中进行实时调整. 然而,不同层次的深度网络模型往往有不同的收敛速度和表征能力以适用于不同场景.对于较浅层的深度网络,模型收敛速度较快,能够快速地达到较好的性能,但表征能力较差,难以处理复杂分布的问题,较适用于概念漂移刚发生时的场景,以使模型性能在漂移发生后快速回升. 对于深度网络,收敛速度往往比浅层网络要缓慢,但具有比浅层神经网络更强大的表征能力,因此更适用于数据流趋于稳定之后的场景. 此外,深度网络所面临的梯度消失等问题,也会影响其在流数据挖掘任务上的性能.
本文将梯度提升思想[22]引入含概念漂移的流数据挖掘问题中,提出了一种基于自适应深度集成网络的概念漂移收敛方法(concept drift convergence method based on adaptive deep ensemble networks,CD_ADEN).CD_ADEN 方法将若干浅层网络作为基学习器进行集成,后序基学习器在前序基学习器输出基础上不断进行纠错,以提升学习模型在含概念漂移数据流分类任务中的实时泛化性能. 此外,由于每个基学习器均为浅层网络,有较快的收敛速度,在概念漂移发生后,学习模型能够较快地从漂移造成的性能下降中恢复. 实验结果表明,对于不同的评价指标,该方法平均排名均为第一. 在Sea,RBFBlips,Tree,Covertype等数据集上,最终累积精度相对于对比方法分别提高了1.63%,0.73%,3.48%,2.2%. 本文的主要贡献包括2 个方面:
1) 通过在前序输出的基础上对损失函数进行优化来替代学习损失函数梯度的方法,提升学习模型对前序学习器输出的纠错性能.
2) 将梯度提升思想引入含概念漂移的流数据挖掘任务中,后序基学习器在前序学习器输出的基础上不断纠错,为解决含概念漂移的流数据挖掘问题提供了一个新思路.
1 相关工作
随着互联网技术的迅速发展,越来越多的机器学习任务的数据以流数据的形式呈现,概念漂移作为流数据挖掘领域中的一个重要难题,受到越来越多的关注. 针对含概念漂移的流数据挖掘任务,目前已经有较多研究. 根据是否对概念漂移的发生进行检测,大致可分为基于主动漂移检测的方法和被动漂移适应的方法[23].
基于主动漂移检测的方法将概念漂移检测融入模型中,通过对学习模型的性能指标进行监测来判断是否发生概念漂移. 一旦检测到模型的性能指标出现大幅度下降,就认为数据流中发生了概念漂移,并对模型做出相应调整. 典型的如:滑动窗口方法[24]通过窗口不断向前滑动,利用标准差等指标判断是否发生概念漂移,若发生了概念漂移,就将已失效的样本丢弃以适应新的数据分布;增量贝叶斯方法[25]首先通过处理历史数据得到先验概率,再结合半监督方法计算后验概率来检测概念漂移;基于滑动窗口的ACDWM 算法[4]通过设置1 个滑动窗口来保存最新的数据,当任意2 个子窗口中数据的平均值的差别大于一定阈值的时候,就认为发生了概念漂移,就会丢弃过时的数据;CD-TW 算法[26-27]构建2 个相邻的时序窗口,通过比较2 个窗口所对应数据的分布变化情况来检测概念漂移节点. 文献[4, 24-27]所述的这些方法虽然能在一定程度上处理概念漂移问题,但仍存在概念漂移误报、概念漂移检测延迟和处理概念漂移类型单一等问题.
被动漂移适应的方法并不直接对概念漂移进行检测,而是通过逐渐更新学习器以及根据每个基学习器的实时表现动态更新权重来适应概念漂移. 典型的如:SEA 算法[28]在每个数据块上都训练一个分类器,然后将其加入集成学习模型中,当集成学习模型中的基学习器的数量达到上限时,替换表现最差的基学习器;动态加权投票算法DWM[29]根据每个基学习器的实时表现来动态地调整权重,在更新权重的同时,将权重小于某一阈值的基学习器移除;CondorForest 算法[30]通过决策树模型重用机制动态调整模型中的基学习器;重用模型Learn++.NSE 算法[31]是一种基于AdaBoost 的动态加权算法,该算法根据每个基学习器与当前数据分布的一致性来对基学习器进行加权,并且在训练阶段通过一种遗忘机制来处理已过时的基学习器,在不同类型的概念漂移都取得了较好的效果. 文献[28-29, 31]所述的这些方法在对基学习器进行加权时无法有效利用基学习器的历史信息达到适应性与稳定性之间的平衡,往往不能很好地处理概念漂移.
尽管以上方法可以很好地解决概念漂移问题,但多数算法都是通过在线凸优化方法来训练的一些简单模型,对于复杂非线性任务往往难以处理. 而深度网络模型能够很好地拟合复杂的非线性函数,但往往需要对大量数据进行批量训练. 目前用于专门处理流数据的深度网络模型仍比较少,根据是否对网络架构进行动态调整可分为动态调整的在线深度网络和结构稳定的在线深度网络. 动态调整的在线深度网络不断对网络参数进行调整以适应最新的数据分布,并根据网络实时性能来决定调整速率,典型的如MOS-ELM 算法[32]、ELM 算法[33]、ADL 算法[34]、AO-LEM 算法[35]等. 结构稳定的在线深度网络并不对网络架构进行直接调整,而是通过集成学习思想将多个(层)网络结合起来,通过调整网络权重来适应流数据中的概念漂移,典型的如HBP 算法[36]、SEOA算法[37]等.
本文将梯度提升思想引入含概念漂移的流数据挖掘问题,提出了一种基于自适应深度集成网络的概念漂移收敛方法,通过集成多个浅层网络,将后序基学习器的输出加到前序输出上对损失函数进行优化,以提升学习模型的实时泛化性能. 与传统方法相比,该方法通过对前序学习器输出进行不断纠错,加速模型收敛,并为解决含概念漂移的流数据挖掘问题提供了一个新思路.
2 基于自适应深度集成网络的概念漂移收敛方法
尽管深度学习在图像分类、目标检测、机器翻译等领域取得了较大成功,但在流数据场景下,深度学习算法难以通过验证集来对模型的架构进行选择,深层网络与浅层网络分别适用于不同场景,在线深度学习算法需要根据数据流的变化实时调整自身架构以达到收敛速度与表征能力间的有效平衡.
为解决上述问题,本文将梯度提升思想的纠错机制引入含概念漂移的流数据分类中,提出了一种基于自适应深度集成网络的概念漂移收敛方法. 该方法集成多个浅层网络作为基学习器,后序基学习器在前序基学习器输出的基础上进行纠错,虽然浅层网络表征能力较弱,难以拟合复杂的非线性映射,但是通过集成多个浅层网络进行多轮纠错操作,最终的学习模型在经过多轮更新后能够得到较好的实时泛化性能. 此外,由于浅层网络收敛速度快,模型能够较快地从概念漂移造成的精度下降中恢复过来,较好地解决了其他在线深度学习方法在处理含概念漂移的流数据问题时难以兼顾模型精度与恢复速度这一问题,从而能够适用于含概念漂移的流数据挖掘任务之中. 模型的基本架构如图1 所示.
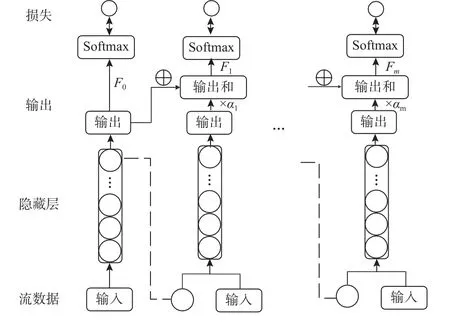
Fig.1 Framework of concept drift convergence method based on adaptive deep ensemble networks图1 基于自适应深度集成网络的概念漂移收敛方法框架图
2.1 模型架构
基于自适应深度集成网络的概念漂移收敛方法集成m个浅层网络作为基学习器,第i个基学习器的输出为fi(x,θi),i=0,1,…,m,其中 θi为第i个基学习器的对应参数,对于分类问题,这里的输出指Softmax操作之前的网络输出,每个基学习器对应一个权重 αi,因此模型的输出为
前序学习器的隐藏层输出与原始输入x合并在一起作为后序基学习器的输入. 由于后序基学习器的输入部分来自前序基学习器,因此每添加1 个基学习器可视为增加了1 层网络深度,即对输入数据进一步地处理与变换,提高了模型容量. 通过各学习器的实时性能来动态调整权重 αi,以动态控制模型容量.
从图1 可以看出,后序基学习器的任务相当于在前序基学习器输出的基础上进行纠错,假设
为第m-1 个基学习器的输出,那么第m个基学习器的学习目标即为在添加对应的输出以及权重之后的输出:
能够进一步减小损失函数,即在添加上后序基学习器的输出之后,能够对前序输出纠错,以得到较好的实时泛化性能. 在该模型中,即使单个浅层网络难以达到较好的性能,但在添加上多个基学习器的输出,经过多轮纠错操作后的实时泛化性能可能较之前有明显提升. 此外,由于浅层网络的收敛速度较快,因此所提出的模型能够较快地从概念漂移造成的性能下降中恢复,有效兼顾了模型性能与收敛速度,可有效处理含概念漂移的流数据分类.
2.2 纠错操作
为使添加后序基学习器输出后损失函数的结果有所下降,梯度提升思想借鉴最优化理论中梯度下降算法,每个基学习器相应的损失函数利用前序输出的梯度信息来进行优化,以提升模型性能.
其中L为损失函数. 为做到这一点,梯度提升算法采用梯度下降法近似逼近最优解,对于j=1,2,…,m,令
代表第j个基学习器上输出损失的梯度. 由于梯度下降只关心梯度的方向信息而不关心梯度的具体大小,因此这里可以设置一个缩放因子 β,按照式(6)训练第j个基学习器:
在训练好第j个基学习器后,利用线搜索来求得梯度下降步长对应权重 αj:
在求得步长之后,利用式(8)更新模型:
在经过m步梯度下降,即训练好m个基学习器之后,即可得到最终的模型.
然而,梯度提升思想不能直接应用于流数据挖掘中,这是由于流数据分类的高实时性要求模型能够1 次只训练1 个或一小批数据,且数据流分布动态变化,这使得后序基学习器输出的梯度信息包含较大误差,难以对损失函数在前序输出处的梯度信息进行准确学习. 为此,本文改进了梯度提升机思想,使其能够适用于含概念漂移的流数据分类.
具体地,在分类任务中,假设在时刻t基学习器f0,f1,…,fj-1的参数均已更新完毕,fj的参数按照式(9)更新,即首先利用时刻t-1 的参数计算
即先添加时刻t-1 的模型的输出结果,并令
为fj的分类输出,利用
以及
对fj的参数以及权重进行更新,将更新后的fj添加到模型中即得到
在经过m轮更新后,模型最终的输出结果即为S o ftmax(Fm(x)).
该方法通过直接对损失函数进行优化来更新各基学习器的参数,使得更新后的基学习器损失减小.相较于传统的梯度提升思想通过学习梯度信息来减小损失的方式,本文直接对损失函数优化,避免了流数据挖掘中基学习器难以准确学习梯度信息的问题.
2.3 算法总结
根据流数据到达的先后顺序将数据块赋予一个时间戳,流数据可以表示为
按照流数据的这种表示形式,可以将本文所提出的基于自适应深度集成网络的概念漂移收敛方法总结如算法1 所示.
算法1. 基于自适应深度集成网络的概念漂移收敛算法.
输入:初始化各基学习器,设每个学习器输出的logits 为fi(x,θi),i=0,1,…,m,并且将权重初始化 为αi=1/m,i=1,2,···,m;
输出:模型输出结果S o ftmax(Fm(x)).
① fort=1,2,…,T
3 实验结果与分析
为测试本文所提出的CD_ADEN 方法的性能,本文在多个真实数据集以及合成数据集上对模型的实时精度、累积精度及概念漂移发生后的恢复性等评价指标进行了测试. 所采用的深度学习框架为Tensorflow,实验所用计算机的配置为Intel®CoreTMi5-8300H 2.30 GHz CPU, 16 GB DDR4L RAM 以及 NVIDIA GeForce GTX1050 Ti 4GB GPU.
3.1 数据集及对比方法
本文所用的数据集既有真实数据集,又有模拟概念漂移的合成数据集,包含了突变型概念漂移与渐变型概念漂移,数据集[37]的具体信息见表1.

Table 1 Datasets Used in Experiment表1 实验采用的数据集
在本文中将所提出的方法CD_ADEN 与4 种在线深度学习方法HBP[36],Resnet[38],Highway[39],DNN进行了对比,实验中数据块大小为 100,隐藏节点为100,使用ReLU 激活函数,设置固定学习率为0.001.
3.2 评价指标
本文从3 个指标对模型的泛化性能及概念漂移发生后模型的收敛性能进行测试与分析.
1) 平均实时精度. 平均实时精度即实时精度在每个时间节点上的平均值,定义为
其中acct为模型在时间节点t的实时精度. 平均实时精度越高,反映模型的实时性能越好. 由于本文使用的数据集多为类别不平衡的数据集,因此本文中的实时精度acct使用的是Balanced Accuracy Score[40],acct被定义为各类别的平均值:
其中k为类别数目,cij指混淆矩阵中索引为(i,j)的元素为混淆矩阵第i列元素之和.
2) 最终累积精度. 最终累积精度即最终模型预测正确的样本数与总样本数的比值,即
其中n为每个数据块中的数据数量,nt为模型在时间节点t对应的数据块中分类正确的样本数目. 最终累积精度越高,代表模型的整体分类性能越好.
3) 漂移恢复率. 一个好的在线学习算法不仅需要有较高的准确率,并且需要能够较快地从概念漂移造成的影响中恢复,因此漂移恢复率Drr指标定义为
其中step代表模型从概念漂移造成的影响中恢复所需的时间步长,avg代表恢复过程中模型的平均错误率. 漂移恢复率取值越小,表示模型在漂移发生后,越能够快速恢复到漂移之前的性能.
3.3 实验结果及分析
为验证本文所提方法的合理性,本节从实时精度、累积精度以及漂移恢复率3 个指标进行了实验分析.
3.3.1 实时精度的结果与分析
模型的超参数往往对模型的性能有着至关重要的影响,本节在不同数据集上分析基学习器数量下模型的性能表现. 表2 展示了不同基学习器数量下模型的平均实时精度情况,本文分别测试了包含4个、8 个、12 个基学习器时模型的平均实时精度. 从表2 可以看出,在多数数据集上,基学习器数量n>8时,性能差距不明显. 因此,后续与其他方法对比时本文所提出的模型均包含8 个基学习器.

Table 2 Average Real-Time Accuracy with Different Numbers of Base Learners表2 不同基学习器数量下的平均实时精度
图2 展示了不同方法的实时精度变化趋势. 从图2 中可以看出,不同方法实时精度波动趋势基本一致,但CD_ADEN 方法波动较小,因此较好地处理了流数据中包含的不同类型概念漂移.
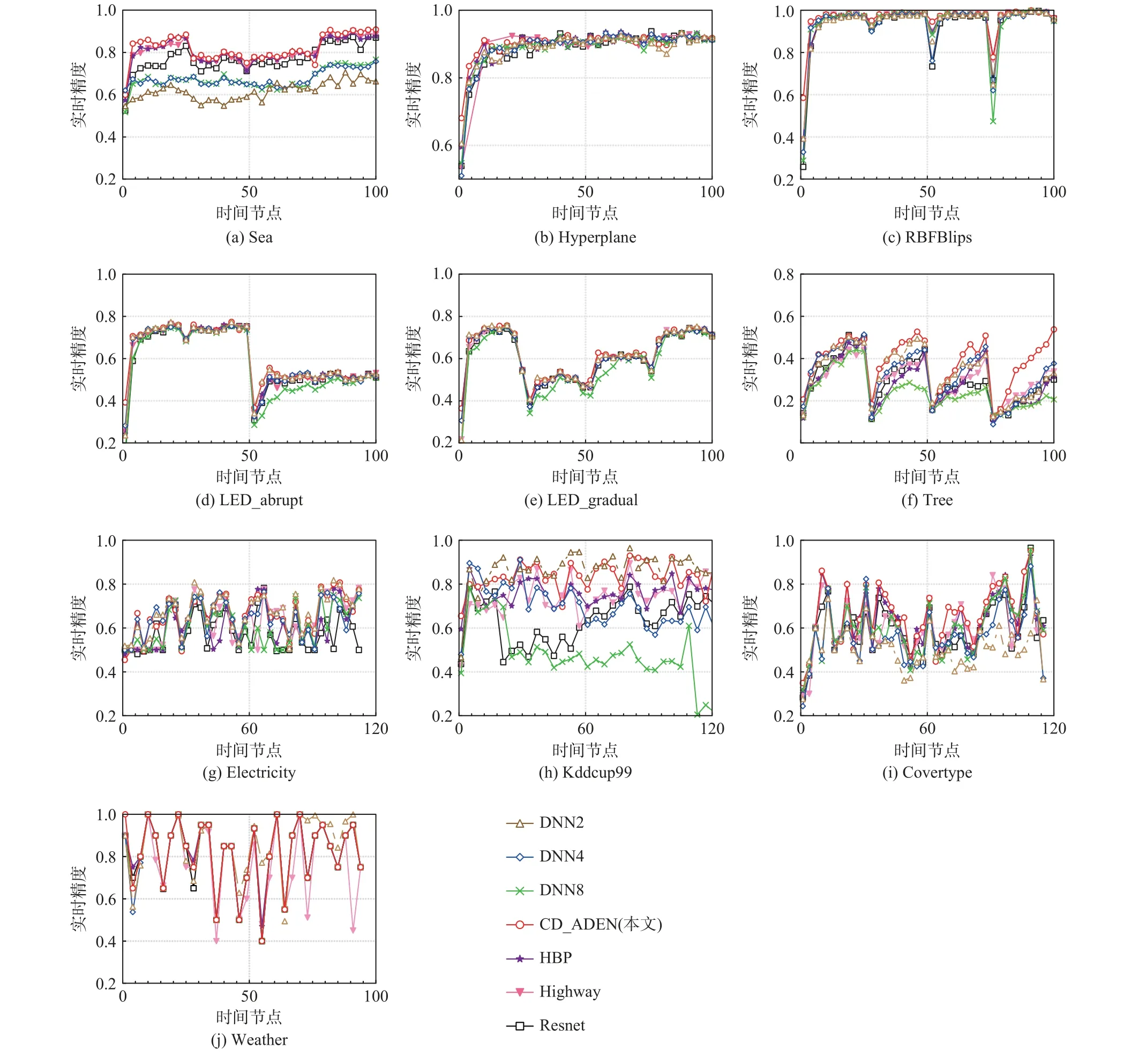
Fig.2 Comparison of real-time accuracy of different methods图2 不同方法的实时精度比较
表3 展示了不同方法的平均实时精度以及相应排序情况. 可以看出,在多数情况下CD_ADEN 方法的平均实时精度最好. 然而在LED_abrupt,Electricity,Kddcup99 和Weather 上,CD_ADEN 方法并未取得最优结果,这可能是由于数据集的分布不同,较少基学习器模型不能很好地表示数据分布,而较多基学习器则会降低收敛速度,并且导致较低的平均实时精度.
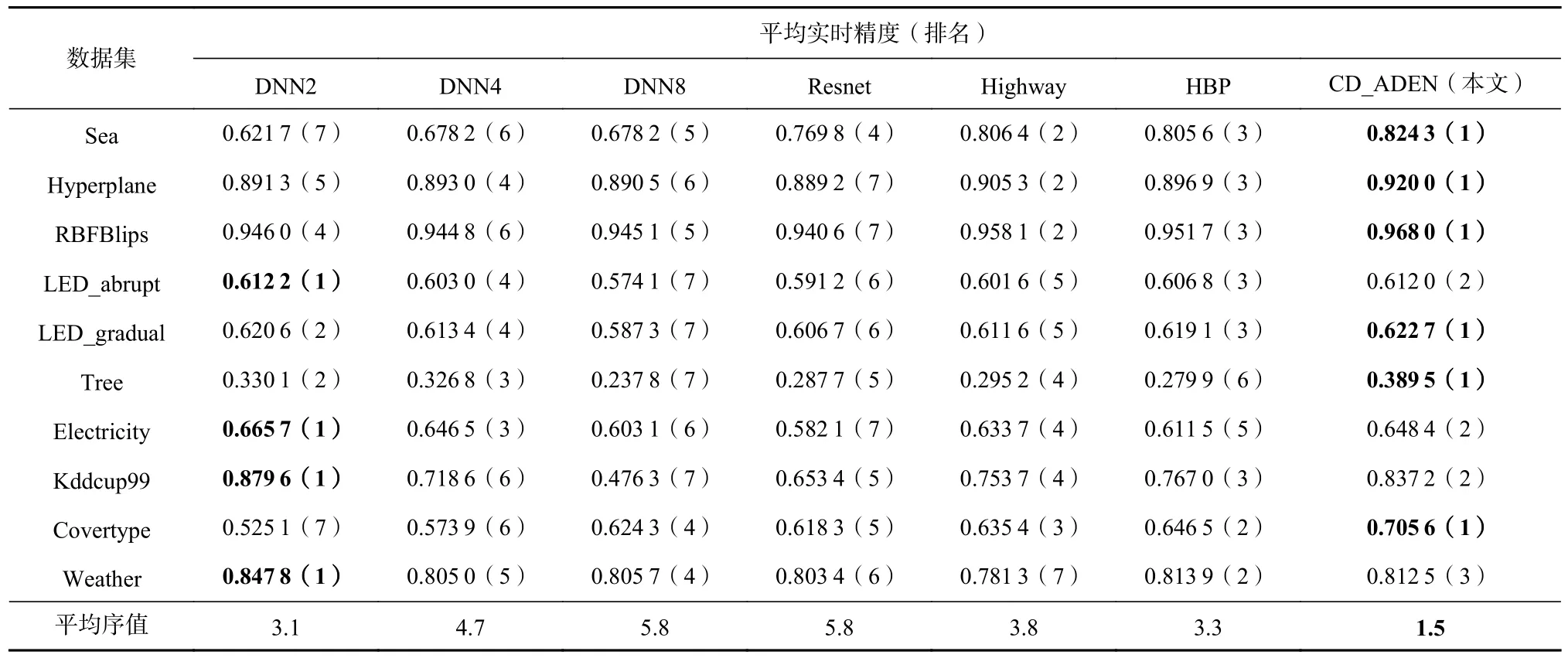
Table 3 Average Real-Time Accuracy Comparison of Different Methods表3 不同方法的平均实时精度比较
本文通过非参数测试方法Friedman 检验[41]进行统计测试. 对于给定的k个算法和n个数据集,是第j个算法在第i个数据集上的排名,第j个算法的平均序值零假设H0为如果所有的方法性能相同,那么它们的平均序值是相等的. 在零假设下,当k和n足够大时,FF服从自由度为k- 1 和(k- 1)(n- 1)的F分布:
其中
若零假设H0被拒绝,计算出的统计量大于FF的临界值,表明学习方法在性能上有显著差异,对上述方法的平均实时精度进行测试,得到统计值FF=9.75.由于其在显著水平 α=0.05 处的临界值为2.272,因此拒绝了算法之间性能不可区分的零假设.
此外,所有方法的临界差(CD)都是通过Bonferroni-Dunn 检验计算的,用来显示CD_ADEN 方法和对比方法之间的相对性能,如果2 个算法的平均序值之差超过了临界差CD,则2 个分类器的性能有显著差异:
其中qα是显著级 α的临界值. 可得在 α=0.05 时CD=2.195. 统计分析的结果如图3 所示. 其中,平均序值在一个临近值域内的方法用黑线连接. 结果表明,CD_ADEN 方法的平均实时精度显著优于DNN8,Resnet,DNN4.
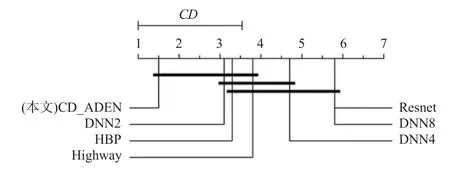
Fig.3 Bonferroni-Dunn test result for average real-time accuracy图3 平均实时精度的Bonferroni-Dunn 检验结果
3.3.2 累积精度的结果与分析
表4 展示了不同基学习器数量n下模型的最终累积精度情况. 在大多数据集上,基学习器数量越大,模型的最终累积精度表现越好.
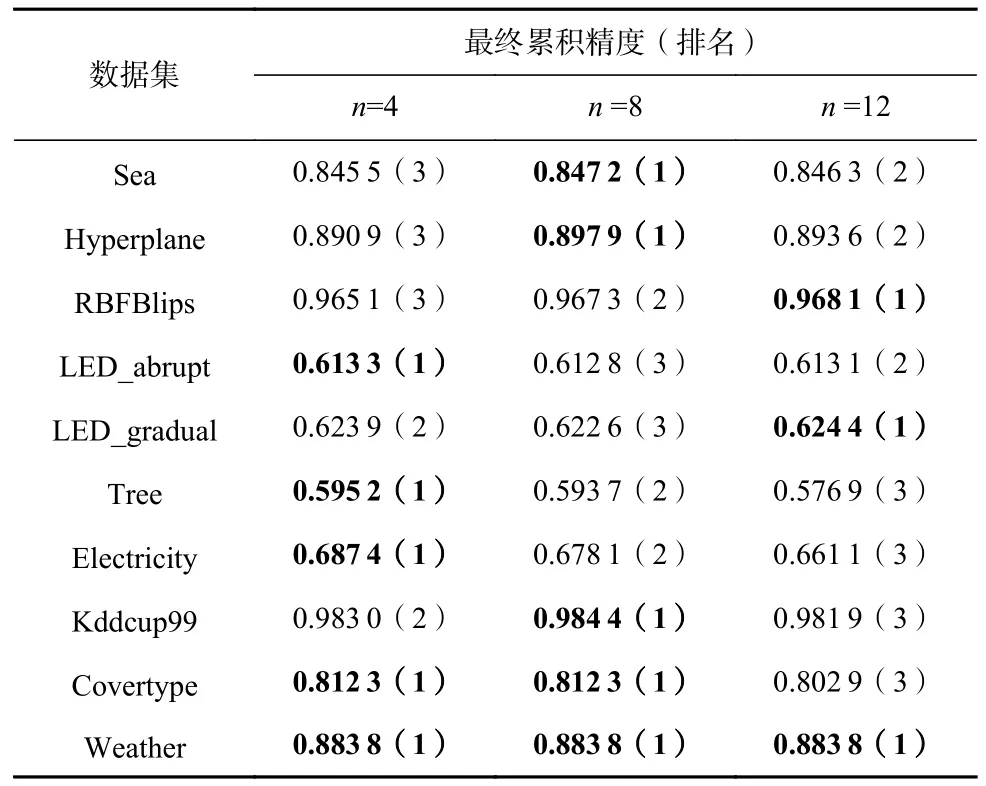
Table 4 Final Cumulative Accuracy with Different Numbers of Base Learners表4 不同基学习器数量下的最终累积精度
图4 展示了不同方法的累积精度比较. 可以看出所有方法的累积精度趋势相同,漂移发生后,CD_ADEN 的累积精度下降低于其他方法,这是由于后序基学习器在前序输出基础上不断纠错,提升了模型的泛化性能.
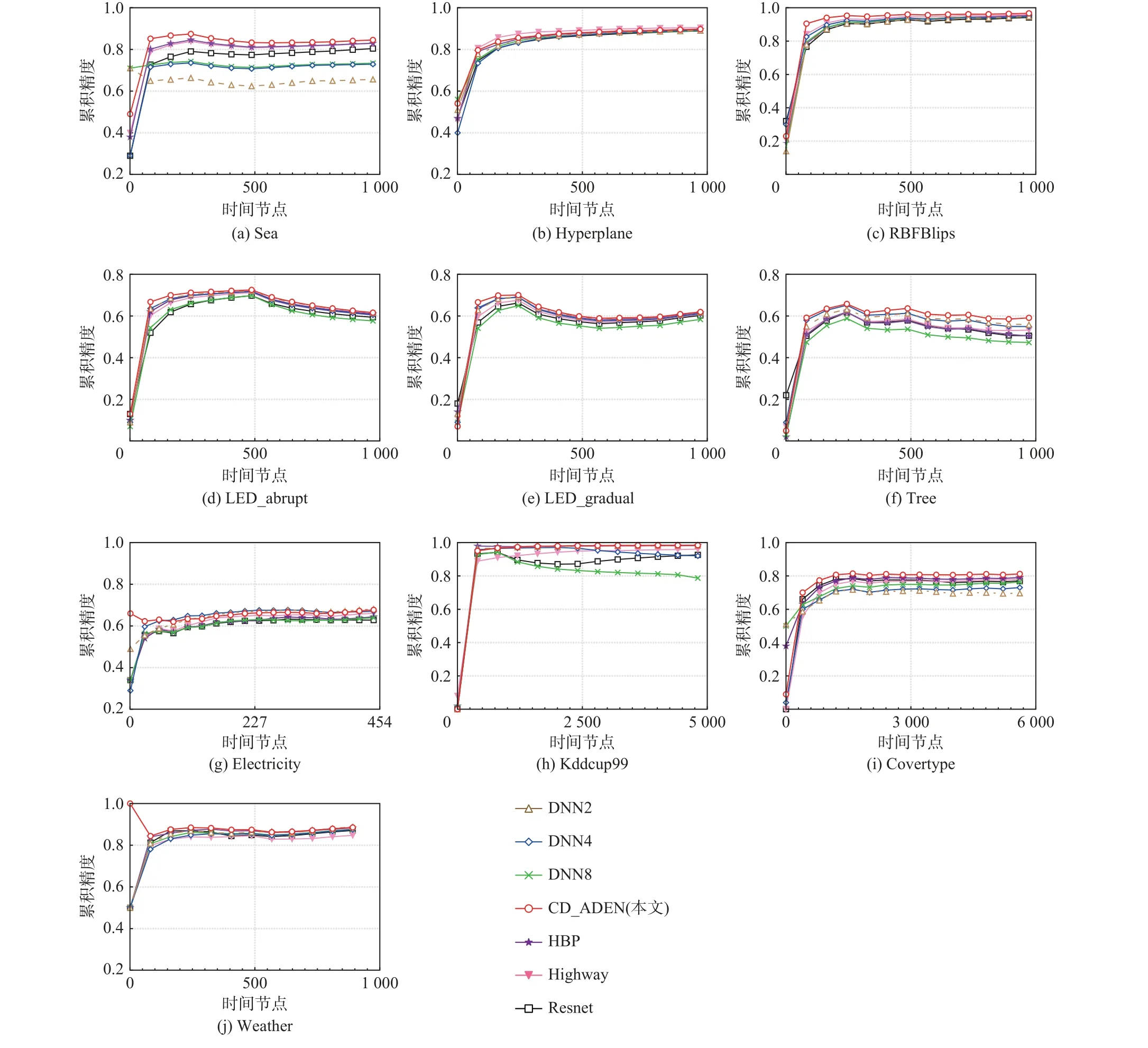
Fig.4 Comparison of cumulative accuracy on different methods图4 不同方法的累积精度比较
表5 展示了不同方法的最终累积精度结果以及相应的排序. 通过平均序值的比较可以看出,CD_ADEN的性能最好,HBP 和DNN2 次之,DNN8 表现最差.CD_ADEN 在除了Hyperplane 的合成数据集上都取得最高的最终累积精度,在真实数据集Electricity,Weather 上表现稍差于DNN2 方法. CD_ADEN 通过将梯度提升算法的纠错机制引入流数据挖掘任务中处理概念漂移,使模型具有较好的泛化性能. 然而,CD_ADEN 并不是均能保持最优精度,这可能是由于基学习器数量未选择至合适数目,较少或较多的基学习器数量均会导致在部分数据集上取得较低的最终累积精度.
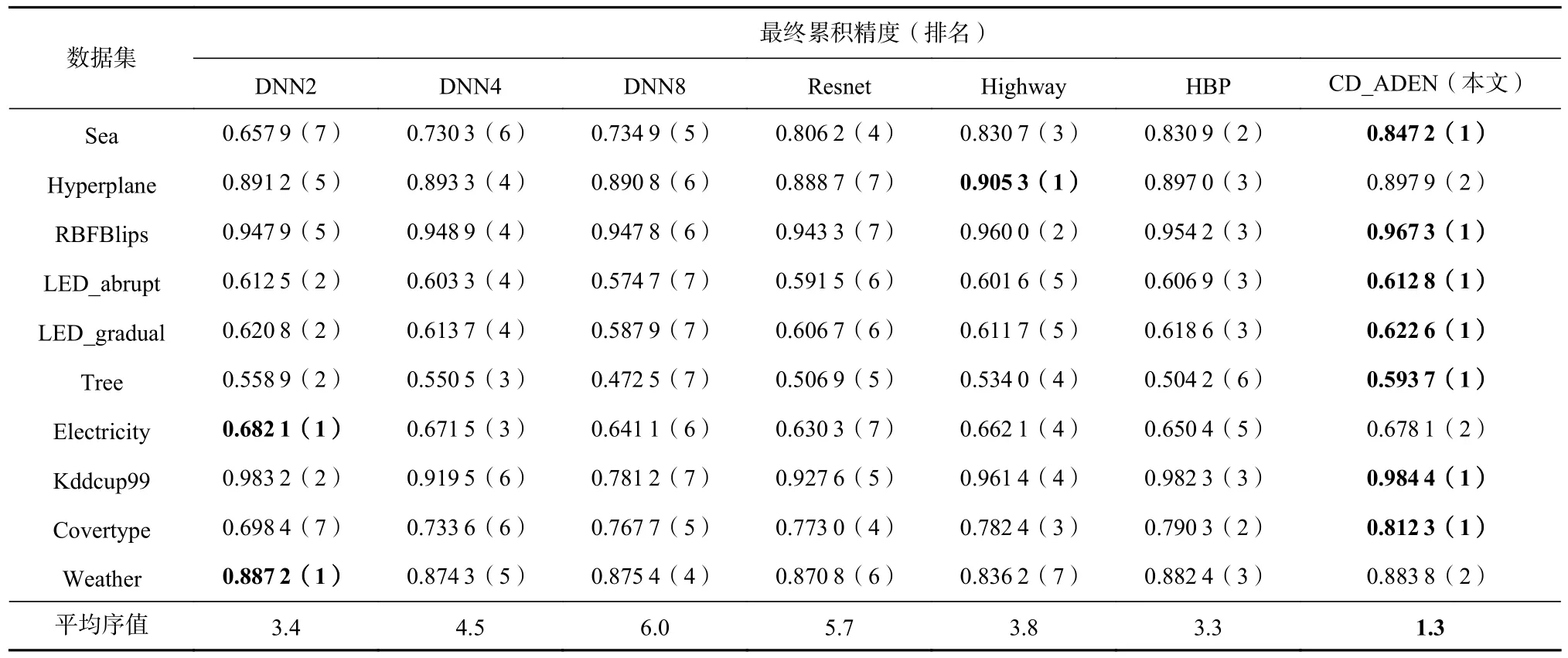
Table 5 Final Cumulative Accuracy Comparison of Different Methods表5 不同方法的最终累积精度比较
进一步分析计算出检验值FF=10.874 4,在显著水平 α=0.05 处的临界值为2.109,因此拒绝了方法之间性能不可区分的零假设. Bonferroni-Dunn 检验结果如图5 所示,结果表明CD_ADEN 方法的最终累积精度显著优于DNN4,DNN8,Resnet.
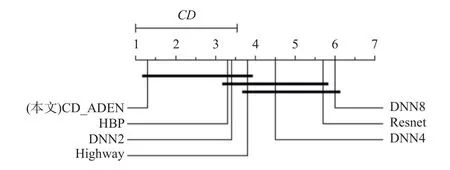
Fig.5 Bonferroni-Dunn test result for final cumulative accuracy图5 最终累积精度的Bonferroni-Dunn 检验结果
3.3.3 漂移恢复率的结果与分析
在线学习模型不仅要考虑其准确率,同时也应该考虑概念漂移发生之后模型的恢复性能. 本文在突变型概念漂移数据集上对模型的恢复性能进行了测试. 当模型的实时精度恢复到概念漂移发生之前的 δ倍时即判断为恢复,根据数据集的不同, δ相应被设置成不同的值.
表6 展示了不同基学习器数量n下模型的漂移恢复性能. 由表6 可以看出,不同于多层DNN,当模型的基学习器越多,就对应着更复杂、容量更大的模型,模型的恢复速度反而更快. 这可能是因为越多的基学习器对应越多的纠错次数,可以使模型更快地从概念漂移导致的高错误率中恢复. 这也一定程度上印证了本文提出的纠错机制是适用于含概念漂移的流数据挖掘问题的解决之中的.

Table 6 Drift Recovery Rate Under Different Numbers of Base Learners表6 不同基学习器数量下的漂移恢复率
表7 展示了CD_ADEN 与其他方法的对比. 可以看出,CD_ADEN 有较好的恢复速度,平均排名为各种方法中最高,能够较好地应用于含概念漂移的流数据挖掘任务.
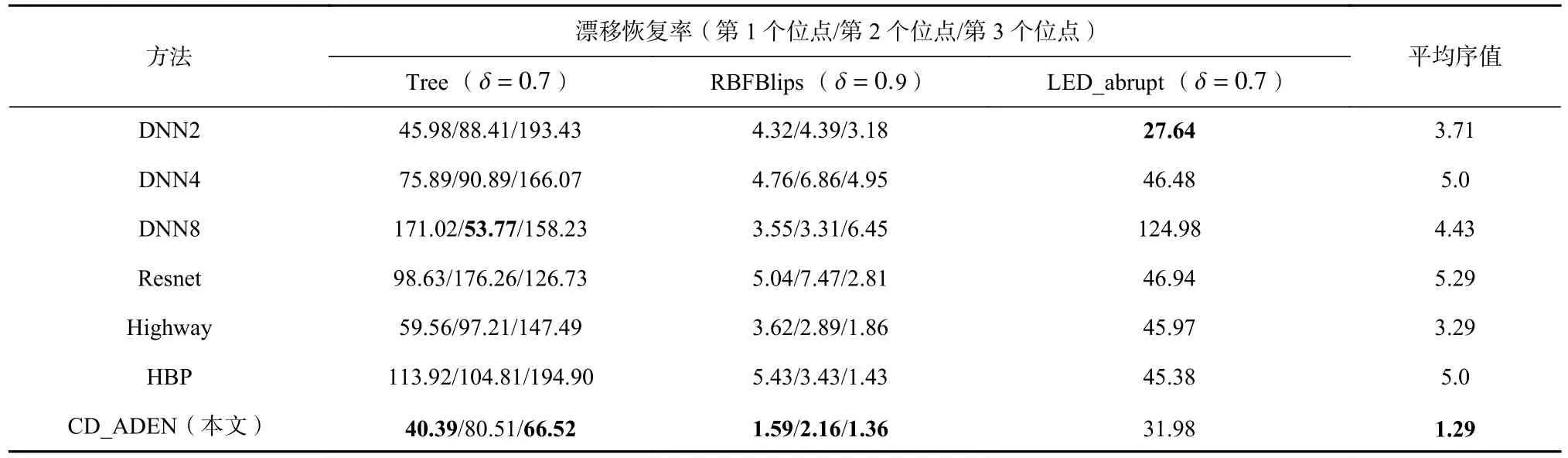
Table 7 Drift Recovery Rate of Different Methods表7 不同方法的漂移恢复率
进一步分析上述结果,比较CD_ADEN 和对比方法在漂移恢复方面的性能. 计算出FF=6.501 6,在显著水平 α=0.05 处的临界值为2.109,因此拒绝了方法之间性能不可区分的零假设. Bonferroni-Dunn 检验结果如图6 所示,结果表明,CD_ADEN 方法的漂移恢复性能显著优于DNN4,DNN8,Resnet.
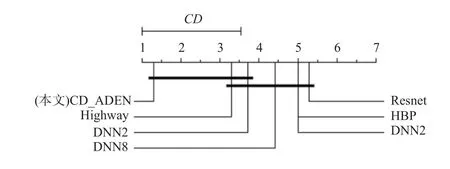
Fig.6 Bonferroni-Dunn test result for drift recovery rate图6 漂移恢复率的Bonferroni-Dunn 检验结果
4 总结与展望
本文针对流数据挖掘中概念漂移问题带来的挑战,将梯度提升的纠错思想引入概念漂移问题的解决之中,提出了基于自适应深度集成网络的概念漂移收敛方法CD_ADEN. CD_ADEN 方法通过集成多个浅层网络构成集成学习模型,后序基学习器在前序输出的基础上对其进行纠错以提升模型的实时泛化性能,在一定程度上缓解了传统在线深度网络难以兼顾模型精度与恢复性能的问题,从而更好地应用于含概念漂移的流数据挖掘任务当中.
作者贡献声明:郭虎升提出思路,设计方法,负责初稿写作及论文修改;孙妮负责论文撰写、数据测试及论文修改;王嘉豪负责代码实现、数据测试及论文撰写;王文剑负责写作指导、论文修改审定.
猜你喜欢
数学物理学报(2021年6期)2021-12-21
大众投资指南(2021年35期)2021-02-16
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
电子制作(2018年11期)2018-08-04
电力与能源(2017年6期)2017-05-14
测绘科学与工程(2016年5期)2016-04-17
信息通信技术(2015年6期)2015-12-26
电子设计工程(2015年3期)2015-02-27
河南科技(2014年14期)2014-02-27
