
基于可解释性分析的深度神经网络优化方法
2024-01-12 06:53吴欢欢谢瑞麟乔塬心崔展齐
计算机研究与发展 2024年1期
吴欢欢 谢瑞麟 乔塬心 陈 翔 崔展齐
1 (北京信息科技大学计算机学院 北京 100101)
2 (南通大学信息科学技术学院 江苏南通 226019)
(wuhuanhuan@bistu.edu.cn)
近年来,深度神经网络(deep neural network,DNN)被成功应用于计算机视觉[1]、语音识别[2]、自然语言处理[3]等领域. 在自动驾驶[4]和智慧医疗[5]等场景下,DNN 甚至可以代替人类完成决策. 例如汽车制造商的自动驾驶技术[4]、监控系统常用的人脸识别技术[6]、工业制造使用的缺陷检测技术[7]等. 随着DNN 应用领域的不断扩大,人们对DNN 的质量提出了更高要求. 尤其在一些安全攸关领域,如果DNN 的质量达不到要求,或将引发灾难性后果. 据NHTSA 统计[8],在2016—2021 年,仅与特斯拉自动驾驶系统有关的8 起交通事故中就导致了10 人死亡. 因此,如何有效保障DNN 的质量已成为智能软件领域的一个重要研究课题.
与传统软件类似,DNN 也不可避免地含有缺陷.对于传统软件的质量保障问题,已有大量工作围绕缺陷检测[9]、缺陷定位[10]、增量调试[11]和自动错误修复[12]等技术展开研究,并取得了良好的效果. 但上述质量保障技术无法直接适用于DNN. 传统软件通常根据软件需求设计编写程序的内部逻辑,DNN 则是在定义好模型结构后使用数据集对模型进行训练,使其学习输入数据到预测输出的高维映射关系.DNN 的内部行为逻辑取决于其结构、训练数据及训练得出的神经元权重等[13]. 因此,需要根据DNN 的特点研究有针对性的质量保障方法.
在DNN 质量保障研究工作中,通常认为准确率低于理想值就称为DNN 存在缺陷[14]. 目前已有许多工作对DNN 缺陷检测技术进行研究[15]. 例如Pei 等人[16]根据DNN 的结构特点提出了一种白盒差分测试技术,在测试用例生成过程中将系统行为差异和高神经元覆盖率作为优化目标,取得了较高的神经元覆盖率,并在Udacity 自动驾驶汽车挑战赛数据集中发现了撞击护栏等数千个错误行为. Zhang 等人[17]提出了基于对抗式生成网络(generative adversarial network,GAN)的测试数据生成方法DeepRoad,通过生成不同天气条件下的驾驶场景来检测基于DNN 的自动驾驶系统的不一致行为.
在检测到DNN 中存在的缺陷后,更为重要的是针对所发现的缺陷优化DNN,以提升其性能. 现有的DNN 优化工作主要通过扩增训练数据和优化DNN参数2 种方式进行. 扩增训练数据是对训练数据进行扩增,使用扩增后的数据训练DNN 以提升性能. 例如Ma 等人[14]提出了一种基于状态差分分析和输入选择的自动神经网络调试技术MODE,该方法可帮助识别有缺陷的神经元,测量它们的重要性并使用GAN 指导生成具有较高真实性的训练数据,以提高模型性能. 优化DNN 参数则直接调整DNN 中的权重等参数以提升DNN 性能. 例如,Zhang 等人[18]提出了一种DNN 修复方法Apricot,其思想是使用部分原始数据集训练生成一组简化的DNN,然后利用它们提供搜索方向,以调整待修复DNN 的权重值. 上述2 种方法均达到了较好的优化效果,如Apricot 方法在所有模型上的准确率平均提升了1.08 个百分点,提升的范围是1.00~2.15 个百分点. MODE 方法的过程较为复杂且需要较高的训练成本,而Apricot 方法的修复过程需要构建训练多个DNN 来提供搜索方向,这将提高修复成本,且修复过程不具有可解释性.
针对上述问题,本文提出了一种基于可解释性分析的DNN 优化方法(optimizing DNN based on interpretability analysis,OptDIA). 首先,利用DNN 解释方法计算不同区域对DNN 预测结果的贡献值,获取不同区域对DNN 预测结果产生影响的重要程度.然后,对重要区域以不同概率使用遮挡、变异等方式进行数据变换以扩增训练数据集. 其中,重要程度越低的区域进行数据变换的概率越高. 最后,使用扩增后训练数据集再训练DNN 以进行优化. 实验结果表明,OptDIA 可以将DNN 的准确率提升0.39~2.15 个百分点,F1-score提升0.11~2.03 个百分点.
本文的主要贡献有2 个方面:
1) 提出了一种基于可解释性分析的DNN 优化方法OptDIA,使用DNN 解释方法指导扩增训练数据,并通过再训练优化DNN,以达到提升其性能的目的.
2) 为验证OptDIA 的有效性,本文实现了原型工具,对9 个DNN 模型在3 个开源数据集上进行实验,并对OptDIA 优化模型性能的能力进行验证.
1 基于可解释性分析的DNN 优化方法
1.1 动 机
目前,缺乏可解释性已经成为制约机器学习算法研究、开发和实现的一个关键问题. 随着DNN 模型越来越多地用于自动驾驶、智慧医疗等安全攸关领域,人们对使用解释方法分析DNN 的需求越来越大. 虽然已经提出了许多DNN 解释方法,但使用解释方法分析DNN 是否达到预期效果及提升DNN 性能的研究相对较少. 由于训练数据会影响DNN 性能,若使用解释方法对DNN 预测过程进行分析,以理解其预测正确或错误的原因,可获取每条训练数据不同区域对DNN 预测结果的影响;并进行有针对性的数据变换,可增加训练数据的多样性,提升模型性能.为此,本文提出了基于可解释性分析的DNN 优化方法OptDIA.
OptDIA 的框架图如图1 所示,主要包括2 个部分. 首先使用解释方法对DNN 的训练过程和决策行为进行分析以生成梯度加权类激活图[19],梯度加权类激活图可显示原始数据中不同区域对DNN 预测结果的重要程度. 若某块区域重要程度越高,则表示该区域所对应原始数据中的特征对预测结果影响越大(将在1.2 节中详细介绍);随后是基于可解释性分析的训练数据生成阶段,该阶段按一定概率选取训练数据,根据梯度加权类激活图进行数据变换操作生成新训练数据,对DNN 再训练并记录训练过程中的性能,在达到停止条件时输出性能最佳的DNN,并将其作为优化后的DNN(将在1.3 节中详细介绍).

Fig.1 The framework of OptDIA图1 基于可解释性分析的DNN 优化方法框架
1.2 DNN 解释分析及可视化
由于DNN 具有复杂的多层非线性网络结构,难以全面理解其预测机制,因此常被当作黑盒使用,这也导致难以确认DNN 产生缺陷的原因. 对DNN 预测过程的内部工作机制进行深入分析,度量不同特征对预测结果的影响程度,才能有针对性地优化DNN.因此,OptDIA 中的一个关键步骤是对DNN 的预测过程进行解释分析,以了解训练数据不同区域影响DNN 行为的重要性差异.
目前,已有多种解释方法可用于理解DNN 的内部工作机制,例如基于反向传播的Grad[20]、基于特征反演的Guide Inversion[21]、基于类激活映射的CAM(class activation mapping)[22]和基于梯度加权类激活映射的Grad-CAM(gradient-weighted CAM)[19]等. 相比于其他DNN 解释方法,将梯度信息与特征映射相结合的Grad-CAM 无需修改网络架构或重训练模型,可避免导致DNN 准确率下降,并适用于不同任务以及多种结构的DNN 模型. 因此,OptDIA 采用Grad-CAM方法对DNN 进行解释分析和可视化.
OptDIA 首先会对训练数据进行解释分析. 具体地:在DNN 的正向传播过程中,将最后一个卷积层作为Grad-CAM 的目标层,并得到预测结果未经过Softmax 激活之前的预测值,再通过反向传播计算目标层所输出的各个特征图对于预测值的梯度,将梯度全局平均池化后得到特征图对于预测结果类别的贡献值. 目标层特征图对于预测值的贡献值计算方法如式(1)[19]:
其中,c表示类别,yc是在经过Softmax 激活之前DNN 对类别c的预测值,Ak表示目标层的第k个特征图,i,j分别为特征图Ak的单个像素值在横轴和纵轴的索引,Z为特征图Ak的长和宽的乘积.即第k个特征图对于类别c的贡献值.
接下来,将特征图对于预测类别的贡献值作为权重,对目标层的所有特征图进行加权求和,并通过函数ReLU将所有负值取0,消除一些与目标类别无关的干扰,从而获得一个粗粒度的梯度加权类激活图,以用于定位每条训练数据中具有类判别性的重要区域. 其中,类判别性指的是训练数据中对DNN预测提供重要依据的特征. 类别c的梯度加权类激活图计算方法如式(2)所示[19]:
在获取梯度加权类激活图后,可将其与原始数据叠加生成热力图,以更加直观地了解不同区域对DNN预测结果的重要性差异. 图2 为解释方法Grad-CAM生成的梯度加权类激活图,以及与原始数据叠加生成的热力图示例. 图2 中每一行的图片分别为来自CIFAR-10,CIFAR-100[23],Fashion-MNIST[24]数据集中的训练数据,标签分别为“bird”“man”“t-shirt”. 图2中第1 列为原始数据;第2 列为使用Grad-CAM 所生成的梯度加权类激活图;第3 列为将梯度加权类激活图与原始数据叠加生成的热力图,其中颜色越深的区域对DNN 分类结果影响越大. 从图2 可以看出;对于图片“bird”,对DNN 分类结果起重要作用的部分为其纺锤形的体型特征;对于图片“man”,对DNN分类结果起重要作用的部分为其身体特征;对于图片“t-shirt”,对DNN 分类结果起重要作用的部分为衣服袖口.

Fig.2 Example of gradient-weighted class activation map and heat map on different datasets图2 不同数据集的梯度加权类激活图和热力图示例
1.3 基于可解释性分析的训练数据生成
DNN 性能受模型结构、超参数和训练数据等因素影响,在模型结构和超参数确定的情况下,训练数据的质量和多样性等因素也会影响DNN 性能. 因此如何提高训练数据的质量及多样性是OptDIA 的关键. 目前,几何变换[25]、颜色空间增强[26]、核滤波器[27]、随机擦除[28]、对抗训练[29]和神经风格转移[30]等数据增强方法常用于优化训练数据. 但是这些增强训练数据方法通常被研究者用来解决小样本训练问题.OptDIA 将基于解释分析结果应用数据增强方法提高训练数据质量,以优化DNN,进而提升其性能.
基于可解释性分析的训练数据生成步骤如算法1所示.
算法1.基于可解释性分析的训练数据生成.
输入:训练集trainSet,测试集testSet,原始数据索引imgId,待优化DNNM;
输出:优化后DNNM'.
① for eachiinimgId
②camMap=GradCAM(M,trainSet[i]);
③areaRank=getImportantArea(camMap);
④trainSet[i] =Augment(areaRank,trainSet[i]);
⑤ end for
⑥models = reTrain(trainSet,testSet,M);
⑦bestAcc= 0;
⑧ for eachminmodels
⑨acc=validate(testSet,m);
⑩ ifacc>bestAcc
⑪bestAcc = acc;
⑫M'=m;
⑬ end if
⑭ end for
⑮ returnM'.
算法1 中,首先将训练数据输入到DNN 进行解释分析,以生成梯度加权类激活图camMap(行①②).然后,根据camMap统计固定大小区域的热力值以获取原始数据中对预测结果影响重要性程度区域排序araRank(行③),其中,热力值指训练数据中不同区域对DNN 预测结果的重要性程度,值越大越重要. 接着,根据原始数据中的重要性程度区域排序areaRank使用数据增强方法Augment对原始数据中的一个区域进行数据变换(其中重要程度排序越低的区域被选择进行数据变换的概率越高),并将所生成的数据替换训练数据集中的原始数据(行④),其中变换数据方法可以采用随机擦除[28]等数据增强技术. 训练数据替换完成后,对DNN 进行重训练并验证每个训练轮次中DNN 的准确率(行⑧⑨). 最后,在达到预设定的重训练轮数后停止优化,并从中选择准确率最高的DNNM'作为优化后的DNN 输出(行⑩~⑮).此算法的最坏时间复杂度为O(n),其中n为数据集规模.
基于算法1,通过使用数据增强方法对梯度加权类激活图中的不同区域按重要程度和不同概率选择进行变换生成新的训练数据,以提高训练数据的质量及多样性,并使用生成的数据再次训练DNN 以提升其性能完成优化. 图3 为OptDIA 方法生成新数据示例. 其中,第1 列为对来自CIFAR-10,CIFAR-100,Fashion-MNIST 数据集中的原始数据使用Grad-CAM所生成的梯度加权类激活图,标签分别为“bird”“man”“t-shirt”. 第2 列为根据梯度加权类激活图生成的新数据,用于再训练. 梯度加权类激活图用作变换数据范围的依据以生成新数据,将对DNN 预测起重要作用的区域以较小的概率变换,而其他对DNN预测结果不重要的区域以较大的概率进行数据变换,来让DNN 学习更多重要区域的特征. 例如对于“bird”,让DNN 学习更多身体部位特征;对于“man”,让DNN学习更多人体形态特征;对于“t-shirt”,让DNN 学习更多衣服特征. OptDIA 通过解释分析对预测结果不重要的特征进行变换,来让DNN 学习更多的重要特征,从而正确分类测试数据.

Fig.3 Example of training data generated based on interpretability analysis on different datasets图3 不同数据集基于可解释性分析的训练数据生成示例
2 实验设计及评估
2.1 实验设计
我们基于所提出的OptDIA 方法,实现了DNN优化原型工具. 在原型工具中,通过解释分析对原始数据中的区域进行重要性排序,排序越高的区域被选择使用随机擦除方法[28]进行数据变换的概率越低.其中,随机擦除指的是对被选择进行数据变换的区域用随机值像素替换以生成具有不同遮挡程度的训练图像,每条数据被选择擦除的概率沿用文献[28]中的0.1. 为确定实验所用的擦除区域大小,分别将图片区域的分割方式设置为64,16,4 个大小相等的矩形区域,初步实验结果表明,不同区域大小对OptDIA的优化效果并无显著影响. 在实验中我们选择将图像等分为16 个大小相等的矩形区域,CIFAR-10 和CIFAR-100 数据集的矩形大小为8×8,Fashion-MNIST数据集的矩形大小为7×7. 原型工具的开发和运行环境为Python3.6 和Pytorch1.12.
本文通过3 个研究问题来验证OptDIA 的有效性.
问题1. OptDIA 是否能优化DNN 以提升DNN 性能.OptDIA 是一种基于可解释性分析的DNN 优化方法,为了评估OptDIA 的有效性,设计了问题1 验证OptDIA 在不同数据集训练的不同DNN 模型上提升DNN 性能的有效性.
问题2. 解释方法的引入是否提高了OptDIA 优化DNN 的有效性.
解释方法的引入是OptDIA 区别于其他DNN 优化方法的重要步骤,为了评估解释方法的引入对DNN 优化能力的影响,设计了问题2 验证OptDIA 在DNN 优化过程中,使用解释方法选择数据变换区域和使用随机方法选择数据变换区域对优化效果的影响.
问题3.OptDIA 能否在已使用数据增强方法进行训练的模型上继续提升DNN 性能.
目前,数据增强方法已经能有效地在训练过程中对训练数据进行扩增,以提高模型的泛化能力并达到较高的性能. 问题3 验证OptDIA 是否能进一步提升应用了数据增强方法进行训练的DNN 性能.
2.2 实验环境
2.2.1 数据集
为回答2.1 节的3 个问题,实验将OptDIA 在使用CIFAR-10,CIFAR-100,Fashion-MNIST 数据集训练的DNN 上进行验证和分析. 所使用的数据集被广泛应用于提升DNN 性能的工作中[14,18,28]. 其中,CIFAR-10 数据集由10 类共60 000 张尺寸为32×32 的3 通道彩色图像组成,其中包含50 000 张训练图像和10 000张测试图像. CIFAR-100 具有和CIFAR-10 相同的数据格式和规模,2 个数据集的区别在于类别数不同,CIFAR-10 具有10 种分类类别,而CIFAR-100 具有100 种分类类别. Fashion-MNIST 由10 类共70 000 张尺寸为28×28 的单通道灰度图像组成,其中包含60 000张训练图像和10 000 张测试图像. 数据集的详细信息如表1 所示. 数据集已经被划分好训练集及测试集,实验使用其中的训练集训练,测试集用来测试及评估优化效果.

Table 1 The Statistics of Datasets表1 数据集信息
2.2.2 实验对象
我们使用CIFAR-10,CIFAR-100,Fashion-MNIST数据集训练了3 种模型:分别使用18 层、34 层和50层结构的ResNet[31]. 优化器学习率从0.01 开始每训练20 轮下降3 倍,在第50 轮停止训练. 将这些完成训练的DNN 作为待优化模型. 为减少随机性的影响,所有实验均重复运行3 次后取平均值.
2.2.3 评价标准
在实验中使用准确率Accuracy和F1-score来评价优化效果,以反映DNN 的拟合能力和预测未知样本的能力.
对于二分类问题,其中正样本被正确预测称为TP,负样本被错误预测称为FP,负样本被正确预测称为TN,正样本被错误预测称为FN. 式(3)为准确率Accuracy的计算方式,即所有样本中正确预测为正样本占所有样本的比例;式(4)为精确率Precision的定义,即预测的正样本中实际是正样本的个数占被预测为正样本的比例;式(5)为召回率Recall的定义,即所有样本中被预测为正样本占所有正样本的比例;式(6)为F1-score的定义,同时考虑精确率和召回率.实验中使用的CIFAR-10,CIFAR-100,Fashion-MNIST数据分别有10,100,10 个类别. 对于多分类问题,可将每个数据集中的类两两组合,分别计算每个类和其他类之间的Accuracy和F1-score,再计算平均值即可.
2.3 实验结果及分析
2.3.1 针对问题1 的结果分析与讨论
为了评估OptDIA 的有效性,在实验中使用固定大小的滑动窗口扫描原始数据,对每个矩形区域统计其在加权梯度类激活图中的贡献值,并根据贡献值排序,贡献值越低的区域进行数据变换的概率越高. 实验将分别在3 个数据集上预训练50 轮的9 个DNN 模型作为待优化模型,再使用OptDIA 重训练50 轮进行优化,并将预训练300 轮的DNN 模型的准确率与优化后DNN 模型的准确率进行对比.
实验结果如表2 所示,其中Org50和Org300分别表示优化前预训练50 轮和300 轮DNN 的准确率,OptDIA 表示优化后DNN 的准确率. 实验结果表明,OptDIA 可提升使用3 个数据集训练的9 个DNN 的准确率以进行优化. 其中,对于使用CIFAR-10 训练的ResNet-50 模型,OptDIA 将准确率提升了1.23 个百分点;对于使用CIFAR-100 训练的ResNet-50 模型,OptDIA将准确率提升了2.15 个百分点;对于使用Fashion-MNIST训练的ResNet-50 模型,OptDIA 将准确率提升了1.32个百分点. 实验结果表明,在3 个数据集上训练的9个模型中,有7 个使用OptDIA 优化50 轮后所提升的准确率比直接预训练300 轮模型的准确率高. 其中,对于使用CIFAR-10 训练的ResNet-50 模型,优化50轮后的准确率要比预训练300 轮模型准确率高1.02个百分点;对于使用CIFAR-100 训练的ResNet-50 模型,优化50 轮后的准确率要比预训练300 轮模型准确率高1.79 个百分点;对于使用Fashion-MNIST 训练的ResNet-18 模型,优化50 轮后的准确率要比预训练300 轮模型准确率高0.39 个百分点. 其中,对于初始准确率较低的模型,准确率提升空间比较大,OptDIA提升准确率的幅度也相对较大. 如使用CIFAR-100 训练的ResNet-50 模型,初始准确率55.66%,OptDIA 将其准确率提升了2.15 个百分点;对于初始准确率较高的模型,其准确率提升空间较小,OptDIA 提升准确率的幅度也相对较小. 如使用Fashion-MNIST 训练的ResNet-34 模型,初始准确率已达92.98%,OptDIA 仅将其准确率提升了0.53 个百分点.

Table 2 Accuracy Comparison of Different DNNs Before and After Optimization by OptDIA表2 不同DNN 使用OptDIA 优化前后的准确率比较 %
从表2 可以看出,对于3 种DNN 模型,使用OptDIA均可提升其准确率,甚至相比较预训练300 轮的DNN 模型,预训练50 轮后使用OptDIA 优化的DNN模型准确率更高. 对实验结果进行分析发现,这是因为OptDIA 使用解释方法对DNN 的预测过程进行分析,获取每条训练数据中不同区域特征对DNN 结果预测的重要程度,并对越不重要的区域以越大的概率进行变换生成新数据,增加训练数据的多样性,从而提升DNN 模型的性能.
对问题1 的回答:对于使用不同数据集和结构训练的DNN,OptDIA 均可有效提升其准确率,提升幅度为0.39~2.15 个百分点,所有模型的准确率平均提升了1.04 个百分点,即使与训练300 轮的DNN 模型相比,使用OptDIA 优化的模型准确率也更高.
2.3.2 针对问题2 的结果分析与讨论
为分析OptDIA 中解释方法对DNN 模型优化效果的影响,实验在不同结构的DNN 和数据集上分别使用OptDIA-和OptDIA 优化方法,并对所提升的性能进行比较. 其中,OptDIA-指没有使用Grad-CAM 对数据进行解释分析,而是直接对训练数据进行随机擦除操作以扩增训练数据. 实验在预训练50 轮的待优化DNN 基础上,分别用OptDIA-和OptDIA 再训练50 轮,并对比所提升性能的差异.
表3 给出了OptDIA-和OptDIA 使用3 个数据集训练的9 个DNN 模型上提升性能的情况. 如表3 所示,除ResNet-50 模型在CIFAR-100 数据集上使用OptDIA-的优化效果优于OptDIA 外,其他模型使用OptDIA 的优化效果均优于比OptDIA-,准确率提升了0.39~2.15 个百分点,F1-score提升了0.11~2.03 个百分点. 其中,对于使用CIFAR-10 训练的ResNet-18,OptDIA 可以提升0.53 个百分点的准确率和0.41 个百分点的F1-score,而OptDIA-只能提升0.20 个百分点的准确率和0.17 个百分点的F1-score,OptDIA所提升的准确率和F1-score分别为OptDIA-的2.65倍和2.41 倍;对于使用CIFAR-10 训练的ResNet-34,OptDIA 可以提升0.80 个百分点的准确率和0.87 个百分点的F1-score,而OptDIA-只能提升0.15 个百分点的准确率和0.78 个百分点的F1-score,OptDIA 所提升的准确率和F1-score分别为OptDIA-的5.33 倍和1.12 倍.
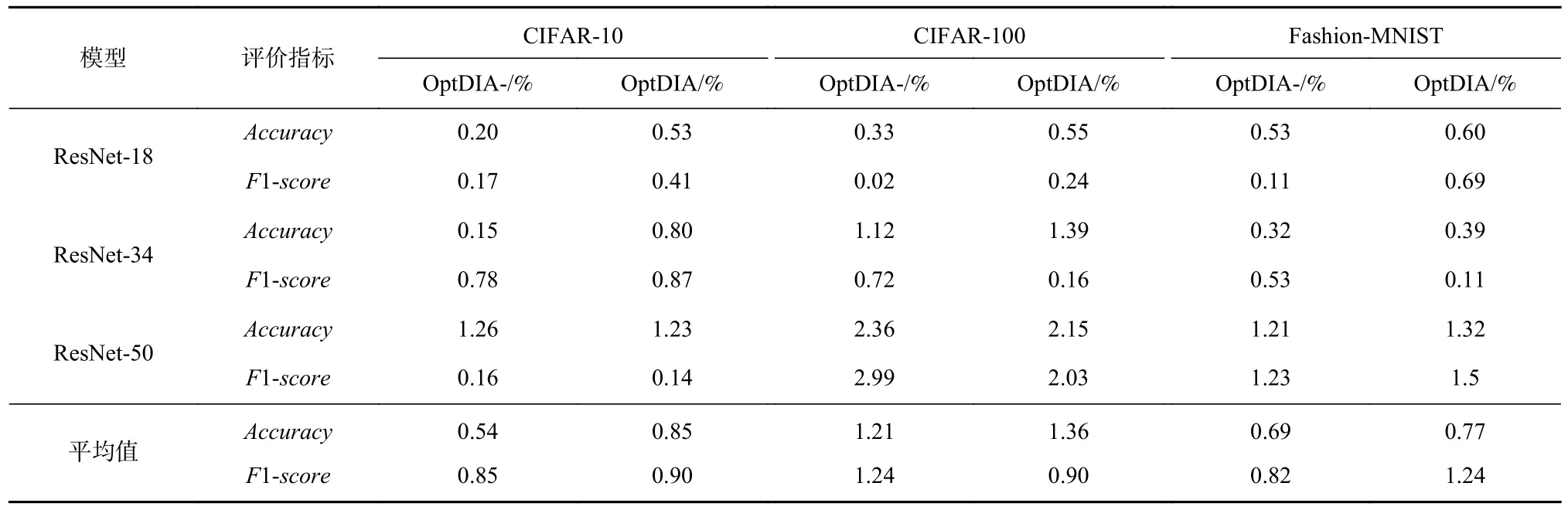
Table 3 Performance Improvements of Optimizing Different DNNs by OptDIA- and OptDIA 表3 不同DNN 使用OptDIA-和OptDIA 优化性能提升比较
就所有模型的平均优化效果而言,对使用CIFAR-10 数据集训练的DNN,OptDIA 和OptDIA-平均提升的准确率为0.85 个百分点和0.54 个百分点,提升的F1-score为0.90 个百分点和0.85 个百分点,OptDIA平均提升的准确率和F1-score分别是OptDIA-的1.57倍和1.06 倍;对使用CIFAR-100 数据集训练的DNN,OptDIA 和OptDIA-平均提升的准确率分别为1.36 个百分点和1.21 个百分点,提升的F1-score分别为0.90个百分点和1.24 个百分点,OptDIA 平均提升的准确率是OptDIA-的1.12 倍,平均提升的F1-score与OptDIA-相近;对使用Fashion-MNIST 数据集训练的DNN,OptDIA 和OptDIA-平均提升的准确率为0.77 个百分点和0.69 个百分点,提升的F1-score为1.24 个百分点和0.82 个百分点,OptDIA 平均提升的准确率和F1-score分别是OptDIA-的1.12 倍和1.47 倍.
从表3 可以看出,使用解释方法指导变换数据再训练DNN 所提升的性能高于未使用解释方法指导变换数据再训练DNN 所提升的性能. 对实验结果进行分析发现,这是因为解释方法可更好地帮助理解DNN 模型的预测过程. 使用解释方法将DNN 训练过程透明化,以掌握训练数据中部分区域特征的重要程度,并将此作为变换数据以增加其多样性的依据.而未使用解释方法指导数据变换则有较强随机性,难以使DNN 模型学习多样化的特征.
OptDIA 使用解释方法分析DNN 的预测行为,并根据分析结果对原始数据进行数据变换以生成新数据. 解释方法的引入将消耗更高的时间成本,过高的额外时间成本将影响OptDIA 在现实场景中的实用性. 为研究OptDIA 在有效提高DNN 准确率的前提下额外消耗的时间成本,在计算表3 中的实验数据时,我们还统计了对不同结构的DNN 和数据集分别使用OptDIA-和OptDIA 生成新数据所消耗的时间成本,如表4 所示.

Table 4 Time Costs Comparison of Different DNNs by Using OptDIA- and OptDIA to Generate Training Data表4 不同DNN 使用OptDIA-和OptDIA 生成训练数据的时间消耗比较
如表4 所示,使用解释方法Grad-CAM 选择擦除区域的OptDIA,与直接对训练数据进行随机擦除的OptDIA-相比,解释方法的引入平均额外消耗了1 min 34 s,即平均每生成一张新训练数据额外消耗约0.016 s(以擦除概率为0.1,每个数据集生成约6 000 条新数据计算). OptDIA 只对被选择进行数据变换的数据进行解释分析,算法的时间复杂度为O(n),且分析和数据变换区域的选择均可由GPU 执行,具有较高的执行效率. 与DNN 动辄数小时的训练耗时相比,OptDIA 额外消耗的时间成本并不会明显降低其实用性.
对问题2 的回答:与随机选择数据变换区域的方法相比,OptDIA 能更有效优化DNN 以提升其性能,且消耗额外时间较少.
2.3.3 针对问题3 的结果分析与讨论
为验证OptDIA 是否能在应用现有数据增强方法进行训练的DNN 上进行优化,首先将Zhong 等人[28]提出的数据增强方法,即随机擦除(random erasing,RE),应用于DNN 训练,然后再对使用RE 训练的DNN 尝试使用OptDIA 进行优化. 实验使用RE 方法在3 个数据集上分别训练了300 轮的9 个DNN 模型,并在其基础上再使用OptDIA 继续训练50 轮.
实验结果如表5 所示,其中RE 表示不同结构的DNN 使用随机擦除方法进行数据增强训练所得到DNN 的准确率,OptDIA 表示在使用RE 方法训练的基础上再使用OptDIA 继续训练所得到DNN 的准确率. 实验结果表明,与直接训练相比,RE 训练的模型准确率提升了0.51~3.24 个百分点,OptDIA 则进一步提升使用RE 训练的6 个模型的准确率和7 个模型的F1-score. 其中,对使用CIFAR-10 数据集训练的模型,OptDIA 将RE 训练的ResNet-50 模型的准确率和F1-score分别进一步提升了0.32 个百分点和0.97 个百分点,对使用CIFAR-100 数据集训练的模型,OptDIA将RE 训练模型的ResNet-50 模型的准确率和F1-score进一步提升了2.72 个百分点和2.35 个百分点,对使用Fashion-MNIST 数据集训练的模型,其准确率和F1-score已较高,OptDIA 将RE 训练的ResNet-50 模型的准确率和F1-score分别进一步提升了0.25 个百分点和0.15 个百分点.
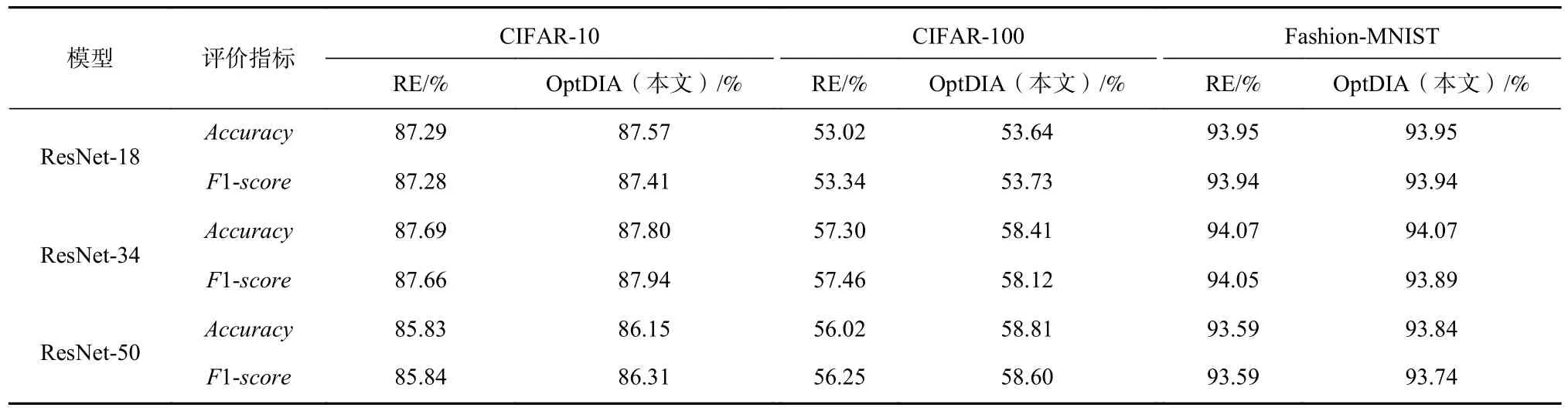
Table 5 Performance Comparison of Different DNNs Trained by Using RE and Before and After Optimization by OptDIA表5 不同DNN 使用RE 和OptDIA 优化前后性能比较
从表5 可以看出,对于经使用数据增强方法预训练的DNN 模型,OptDIA 仍可进一步提升其准确率,即达到优化DNN 的效果. 对实验结果进行分析发现,因为利用DNN 的解释方法指导进行数据变换能有效增加训练样本的多样性,使DNN 学到更多的特征.
对问题3 的回答:OptDIA 可进一步提升使用数据增强方法训练的DNN 模型的准确率和F1-score,提升幅度分别为0.11~2.72 个百分点和0.13~2.35 个百分点.
2.4 有效性分析
2.4.1 内部有效性
本文方法的内部有效性分析主要在于确实影响实验正确性的因素. 首先,实验中使用的DNN 解释方法为Grad-CAM 的开源项目pytorch-grad-cam[32],该开源项目也被其他相关工作使用[33];其次,我们参考开源项目Random-Erasing 的源代码[34]实现了实验所用的数据增强方法;最后,实验构建和训练DNN 模型的代码来自Torchvision[35]的开源实现,此外,还对代码进行了多次内部交叉检查,以尽量确保实现的正确性.
2.4.2 外部有效性
基于可解释性分析的深度神经网络优化方法的外部有效性主要在于实验中所用的DNN 模型和数据集是否具有代表性以及OptDIA 是否具有可扩展性. 首先,本文实验所使用的ResNet 模型以及CIFAR-10,CIFAR-100,Fashion-MNIST 数据集在优化DNN 的工作中被广泛使用[14,18,28],具有一定代表性,但不能确保OptDIA 在其他待优化DNN 和数据集上的有效性.其次,在实验中只使用了擦除方法对数据进行扩增,不能确保OptDIA 能在裁剪等其他数据扩增方法上的有效性. 此外,虽然任何准确率的提升都是对模型有意义的优化[14],但由于DNN 模型具有内在不确定性,因此无法保证准确率的提升幅度.
2.4.3 构造有效性
本文方法的构造有效性影响主要在于优化DNN的评价指标. 实验中使用测试集的准确率和F1-score来评价实验效果,这2 项指标常被用于评价DNN 性能[14]. 此外,为避免实验结果的随机性,我们使用相同参数进行多次实验求得平均值作为实验结果.
3 相关工作
传统软件缺陷修复方法通过基于启发式搜索[9]、人工模板[36]、语义约束[37]和统计分析[38]等技术自动生成针对特定缺陷的程序补丁,并将补丁自动添加到软件以修复缺陷,或将补丁作为提示信息来帮助开发者继续优化软件[12]. 与传统软件不同,OptDIA 主要关注基于DNN 的智能软件,其内部具体权重参数通过训练获取且结构较为复杂,这使其输出结果缺乏传统软件的解释性,因此传统方法难以直接应用于优化DNN. 目前对DNN 进行优化的研究主要从训练集和模型参数2 个切入点进行,本节将对这2 类方法分别进行介绍.
一类方法是通过扩增训练集优化DNN 以提升其性能. Ma 等人[14]提出了DNN 调试方法MODE,该方法首先通过分析神经网络状态生成差分热图(differential heat map),并结合DNN 模型找出对于分类影响较大的神经元,分别对在训练过程中存在欠拟合或过拟合的DNN 进行调试,然后指导GAN 生成具有较高真实性的训练数据,从而提升模型的性能以优化DNN. Gao 等人[39]提出了一种基于模糊测试的数据扩充方法,该方法结合模糊测试和遗传算法扩增数据,将优化问题转化为搜索问题,以提高模型的健壮性,从而达到优化DNN 的目的. Liu 等人[40]提出了一个面向数据的变异框架Styx,该框架首先通过对原始数据进行轻微变异生成新的训练集,并将其用于重新训练DNN,以提高模型健壮性,从而达到优化的目的. 文献[14, 39-40]所述的方法可在一定程度上优化DNN,然而依然存在扩充数据集的过程缺乏针对性,需要引入新的DNN,增加数据多样性的能力有限且过程难以理解等问题.
另一类方法是通过修改模型参数优化DNN 以提升其性能. Zhang 等人[18]提出了一种权重调整方法Apricot,该方法通过在原始训练集的许多不同子集上进行训练得到简化深度学习模型(reduced deep learning model,rDLM),使用其权重来辅助修改原始模型中的权重,从而提升模型的准确率以优化DNN.随后他们又提出一种超启发式方法Plum[41],该方法通过应用不同的修复策略生成一组候选DNN 模型,然后根据候选修复策略的整体优化效果对修复策略进行评估和排序,并使用最佳优化策略生成优化后的DNN. 基于变异的DNN 优化方法GenMuNN[42]量化神经元权重对DNN 预测结果的影响,并根据量化结果对各层神经元权重进行排序,然后使用遗传算法对权重进行变异以生成变异体,直到出现准确率较高的DNN,即可达到优化的目的. Zhang 等人[43]提出了一种DNN 训练监控与自动修复方法AUTOTRAINER,该方法可检测梯度消失、梯度爆炸、损失振荡和收敛缓慢等常见训练问题,并自动采用如替换激活函数等内置修复方案提高DNN 性能,以达到优化DNN的目的. Sun 等人[44]提出了基于因果关系的神经网络修复方法CARE,该方法通过最小限度地调整给定DNN 的权重参数,通过执行基于因果关系的缺陷定位以识别并优化“有罪(guilty)”神经元,通过构建一个满足目标属性(如公平性、无后门等)的神经网络来提高其性能. 然而,直接对DNN 参数进行优化也会有一定风险,例如在调整权重时,直接调整参数难以控制修改幅度,甚至可能会影响模型准确地拟合训练数据.
文献[18, 41-44]所述的工作主要通过扩增数据集或修改模型参数的方式优化DNN,由于缺乏解释性导致其修复过程大多难以理解. 本文所提出的基于可解释性分析的深度神经网络优化方法OptDIA使用DNN 解释方法获取训练数据中对预测结果影响较大的区域,并通过对其进行数据变换生成新的数据再训练DNN,以提升DNN 性能,从而达到优化DNN 的目的. 相较之前的工作,OptDIA 引入了DNN解释方法,提高了数据扩增的针对性,使优化DNN的过程更容易被理解.
4 总结和未来工作
为优化DNN 以提升其性能,本文提出了一种基于可解释性分析的DNN 优化方法OptDIA. 使用解释方法获取原始数据中对DNN 决策具有较高重要性的区域,并将其作为变换数据生成新数据的依据,再重新训练DNN 以提升其性能,从而达到优化DNN的目的. 在使用3 个数据集训练的9 个DNN 模型上进行的实验结果表明,OptDIA 可以有效提升DNN 性能以进行优化,并可进一步优化使用现有数据增强方法训练的DNN. 在下一步工作中,我们计划在更大规模数据集上引入更多数据增强方法验证OptDIA的优化效果,并计划尝试将本文方法引入语音、文本处理等领域,如利用解释方法获取词语对情感分析结果的重要性程度,将其作为变换数据的依据,使用变换后的数据重新训练模型,以提高其性能.
作者贡献声明:吴欢欢负责相关工作调研、论文撰写及修订等工作;谢瑞麟完成实验并修改论文;乔塬心协助完成实验;陈翔提出指导意见并修改论文;崔展齐指导论文选题、确定论文整体框架设计并修改论文.
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
法律方法(2021年4期)2021-03-16
家庭影院技术(2019年8期)2019-08-27
中国交通信息化(2018年5期)2018-08-21
文教资料(2018年30期)2018-01-15
传播力研究(2017年5期)2017-03-28
中国宪法年刊(2016年0期)2016-05-20
燕山大学学报(2015年4期)2015-12-25
