
基于OCR识别技术的碎片化时空信息库异常文件检测方法
2024-01-15 10:53宋吉星王宜春杨伟迪
武汉理工大学学报(信息与管理工程版) 2023年6期
杨 飞,宋吉星,王宜春,杨伟迪,赵 璟
(国能包神铁路集团 神朔铁路公司,陕西 榆林 719316)
自媒体时代的到来,丰富了人们生活的同时也割裂了每个人的时间,使得各种信息都向着碎片化发展[1]。为更好地应用这些碎片化信息,学者提出了碎片化时空信息库,用来收录各行各业的零散数据,在移动互联网环境下,实现多类型数据的交互。近年来,碎片化时空信息库的运行面临越来越多的安全隐患,在碎片化时空信息库中存在具有异常特征或与正常规律偏离的文件,包括格式异常、内容异常、结构异常、大小异常和访问异常等。为了保证信息库的安全,需要针对信息库异常文件进行精准检测。如何有效检测异常文件,成为学者关注的热门课题。
LI[2]以图形和图像的方式显示海量的网络数据和日志信息,并利用多智能体模型建立了网络数据可视化分析模型,但该方法数据处理不当,导致数据质量差,可视化方法和算法受到限制,影响检测结果。房笑宇等[3]运用滑动窗口法,将日志文件描述为日志序列,依托注意力机制,构建以生成对抗网络为核心的异常检测模型,将日志序列输入该模型判断是否存在异常,从而得出异常文件检测结果,但检测结果准确率较低。李国等[4]提出对比异常文件和良性文件的信息熵,依据信息熵差异检测异常文件,提取异常文件的特征并将其输入基于决策树算法的检测模型中,以验证异常文件检测结果,但该方法检测耗时较长。李坤明等[5]以集成决策树为基础,构建异常文件检测模型,针对训练样本进行数次迭代学习后,得到优化后的检测模型,从而得出较准确的异常文件检测结果,但该方法的鲁棒性较差。
为降低检测误差,笔者利用OCR识别技术对扫描图像进行预处理,包括图像二值化和旋转矫正等,以提高文字信息的准确性和可读性。结合连接预选框网络和端到端文本识别网络,实现对预处理图像中文字信息的自适应提取,避免了手动标注文本区域的繁琐过程。将识别出的文字信息描述为定长字节序列,通过计算熵得出文件的统计特征,从而量化文件的不确定性。对比信息库异常文件的标志特征,通过计算余弦相似度来判断文件是否属于异常文件,从而实现智能检测结果的输出。
1 异常文件检测方法
1.1 碎片化时空信息库文件图像处理
考虑到相机现场拍摄的图像可能包含一些干扰信息,在碎片化时空信息库异常文件智能检测时,需要进行图像二值化和旋转矫正处理[6]。碎片化时空信息库文件扫描图像的二值化处理,需要依托于最佳阈值法实现。将原始扫描的文件图像转换为灰度图像后,计算出图像灰度中值,充当二值化处理初始阈值,基于该值将图像所有像素划分为两部分。而后,针对灰度图像构建灰度直方图、累计直方图,对应的数学表达式为:
(1)
(2)

针对初始阈值分割后的两部分像素进行计算,分别确定灰度均值,并以此为基础更新二值化分割阈值[7]。对比更新前后的阈值,计算出二者之间的差值,当差值过高时,重复上述步骤,再次更新阈值,直到得到最佳阈值。利用最佳阈值进行二值化操作,去除扫描图像中的底纹。运用双线性插值策略,旋转矫正文件扫描图像,具体操作模式如图1所示。其中,α1、α2、α3、α4表示X轴上线性插值辅助点,β1、β2表示Y轴上线性插值辅助点。双线性插值处理时,目标点处在6个辅助点之间,按照这一操作方式不断处理,得到双线性插值结果,实现文件扫描图像的旋转矫正。
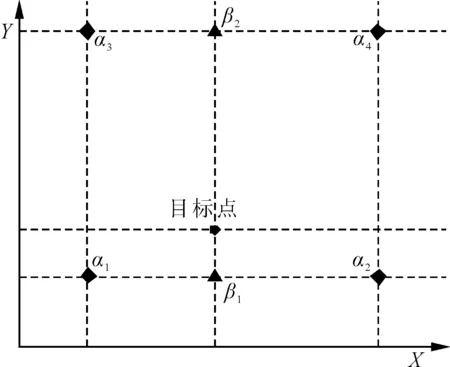
图1 双线性插值示意图
1.2 基于OCR识别的文字提取方法
在扫描仪等电子设备的辅助下,实施智能OCR识别技术,对预处理后的碎片化时空信息库文件图像进行文字提取,将图像内包含的字符描述为计算机可以识别的文字,作为后续异常文件检测的基础。基于OCR识别技术进行文字提取时,需要经历文本检测、文本识别两个环节。为提升文字提取效率,提出前一环节采用基于连接预选框网络的文本检测网络,后一环节则需要端到端文本识别网络的辅助。
由卷积层、双向短期记忆网络和全连接层组成基于连接预选框网络的文本检测网络(CTPN)[8]。在执行智能OCR识别原理时,需要通过卷积层提取碎片化时空信息库文件扫描图像的特征[9]。应用尺寸为3×3的滑动窗口进行特征向量提取,操作过程如图2所示。
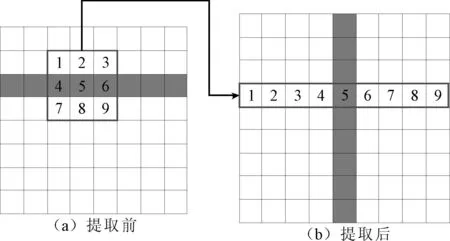
图2 特征向量提取示意图
一个滑动窗口内存在多个垂直锚点,用来描述图像中字符的垂直坐标。因此,基于锚点可以将图像文本框的垂直坐标表示为:
(3)

将提取出的特征向量输入双向短期记忆网络进行小窗口预测,初步确定文字所在区域,再通过全连接层进一步处理优化后的输出结果,定位出图像内文字所在区域。
针对检测出的文字区域,应用端到端文本识别网络(CRNN)进行具体识别,该识别网络主要包括3层结构,如图3所示。将检测标注后的图像输入深度卷积层,经由卷积计算、激活计算和池化计算提取文字特征。整合为特征序列后输入循环层,通过双向长短时记忆网络得出文本识别预测结果,再经由转录层的CTC模型,对预测结果进行验证,并将其转化为最终识别结果。
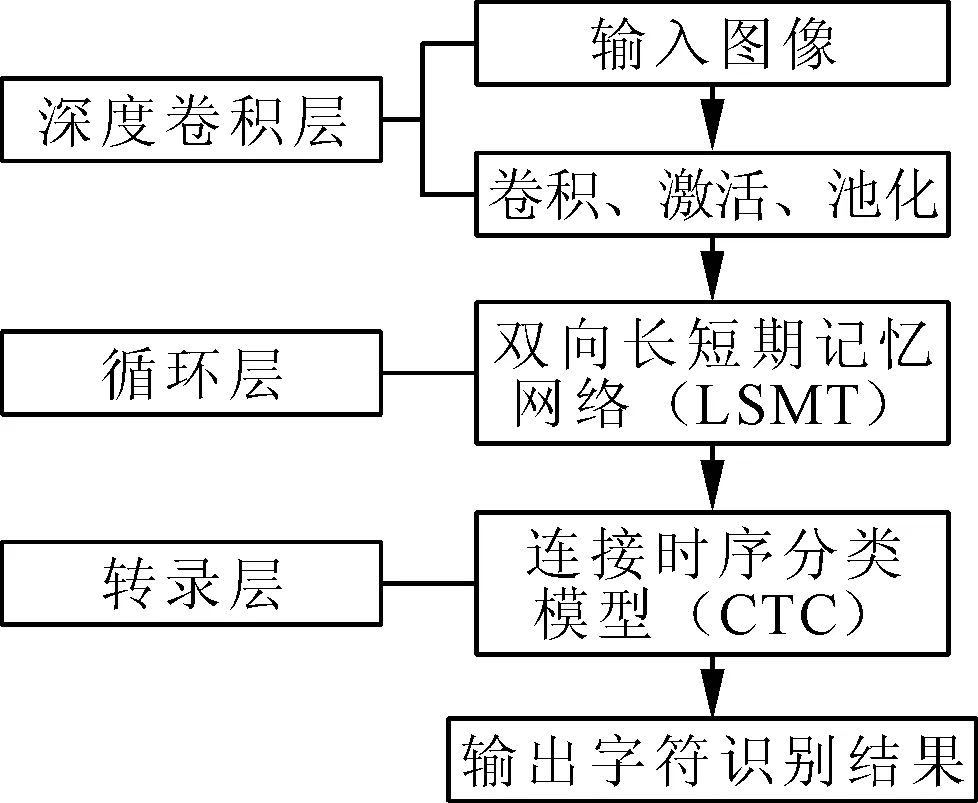
图3 CRNN网络结构示意图
1.3 提取文件类型统计特征
将文件扫描图像的字符识别结果描述为定长字节序列,再划分为大小相同的字节序列片段,每个片段可以看作一个元组[10]。实际操作过程中,通过观察某一个字节后续位置字节的不确定性,找到字节序列端点,形成文件对应的字节流。笔者采用熵计算方法描述字节的不确定性。
(4)
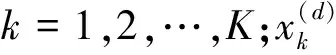
将基于OCR识别的文字提取结果汇总起来,形成包含数个字符的训练集,并应用式(4)计算出字节的后继熵。对比预先设置的判断阈值,当熵高于阈值时,可以作出一个窗口标记。对文件全部识别内容完成标记后,整个文件可以表示为包含若干标记元组的集合。针对集合内每个元组出现的次数进行统计,确定元组频率分布情况,如式(5)所示。选择几个出现频率最高的元组,总结窗口标记作为当前文件的统计特征。
γ(Gk)={TGk(g)|(g)∈Gk}
(5)
式中:G为标记元组集合;γ为元组频率分布;T为目标元组出现次数;g为目标元组。
1.4 建立异常文件智能检测方案
依托于文件统计特征进行异常文件智能检测,需先确定异常文件的标志特征。以碎片化时空信息库内典型的异常文件为例,对文件中每个元组进行评估。
(6)
(7)
(8)
式中:E为元组评估值;ψ为训练样本中满足筛选条件的文档数量;ρ为筛选参数,其取值会受到指纹中元组数量的影响,指纹是指文件类型;∂为总文档数量;Φ为平滑因子;ΔR为文档与指纹中目标元组出现的频率差;R为元组出现频率;d为文档;e为指纹;ξ为元组出现频率求取过程中产生的众数数量;Mj为第j个众数。
按照上述计算方法,确定典型异常文件的元组评估值,按从大到小的顺序进行排序,选择排序靠前的几个元组作为碎片化时空信息库异常文件的标志特征。针对提取的文件类型统计特征与异常文件标志特征,计算二者之间的余弦相似度,当相似度大于预先设计的判断阈值时,即可输出检测结果,判定该文件属于异常文件。
2 实验
2.1 实验数据
由于所提智能检测方法应用了OCR识别技术,为确保该方法具有良好的实际应用效果,需要进行实验分析。本次实验所应用的数据主要来自安卓平台、Windows平台。在两个平台中,分别收集2 000个异常文件和6 000个正常文件,将这8 000个文件看作碎片化时空信息库内的文件。实验过程中,选取5 000个文件构成训练集,用来训练基于智能OCR识别的文字提取网络,调整网络参数。再将剩余的3 000个文件均分为3份,得到3个测试集。每个测试集中,异常文件的占比均为50%。应用所提方法,针对这些数据集进行智能检测,得到异常文件检测结果。
2.2 网络训练
使用一组训练数据和验证数据,其中包括100个异常文件和300个正常文件。使用训练数据来训练模型,计算文件类型统计特征和异常文件标志特征。在验证数据上进行实验和验证,通过调整不同的判断阈值,观察模型的准确率和召回率。
在实验和验证过程中,得到了以下结果:当判断阈值为0.8时,模型的准确率为90%,召回率为85%;当判断阈值为0.7时,模型的准确率下降至85%,但召回率提高至90%;当判断阈值为0.9时,模型的准确率提高至95%,但召回率下降至80%。根据以上结果,权衡准确率与召回率的关系来确定最终的判断阈值。由于研究重点为异常文件的准确识别,所以选择较高的判断阈值,即设置为0.9。
为保证文字识别结果更加准确,在网络训练过程中,定义所有文件扫描图像尺寸为3×225×225,并保证所有图像的像素值取值范围为[0,1]。网络训练过程中,设置网络训练次数和批次大小分别为150和50,该条件下网络训练的损失值、准确率变化曲线如图4所示。由图4可知,在训练次数增加后,文字识别的准确率不断提升,而训练损失值则在不断降低。从训练次数为70次开始,准确率无限贴近为1,确定此时网络处于最优状态。
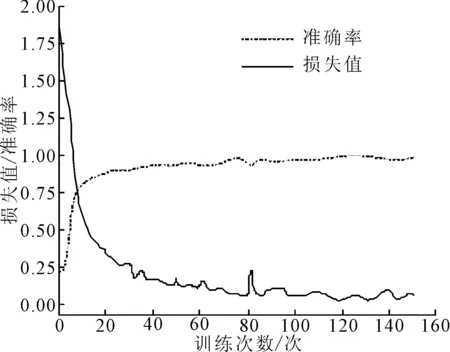
图4 训练集损失值、准确率变化曲线
应用训练后的网络处理测试集,并得到损失值、准确率变化曲线,如图5所示。由图5可知,当完成150次训练后,文字提取网络的识别准确率达到了98.8%,表明基于连接预选框网络的文本检测网络、端到端文本识别网络,实施智能OCR识别技术后,可以得到准确的文字识别结果。
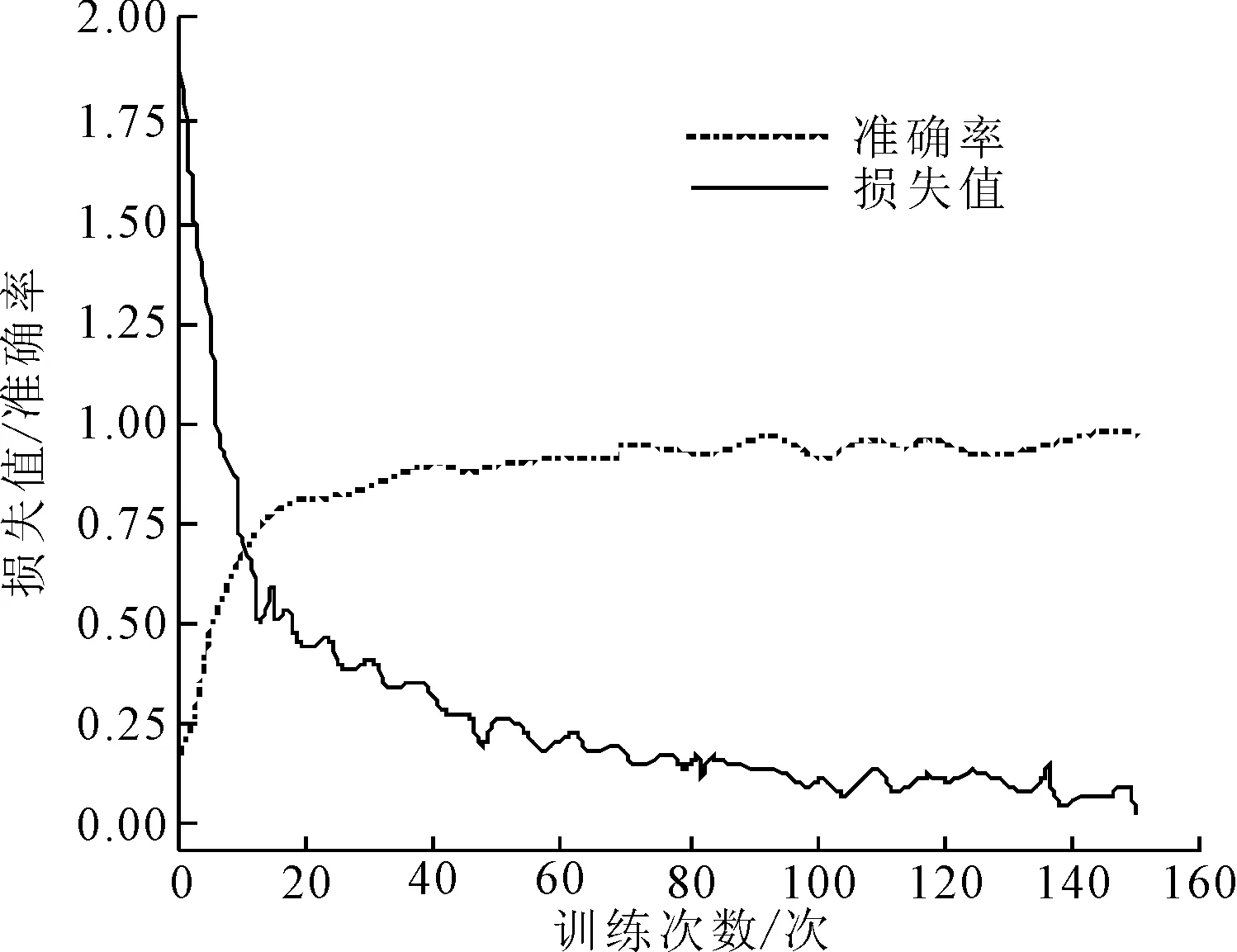
图5 测试集损失值、准确率变化曲线
以测试集的任意文件为例,对其扫描图像进行文字识别,结果如图6所示。由图6可知,所提方法可以将文件内包含的文字字符完整识别出来,并基于此进行后续异常文件智能检测。

图6 文件字符识别结果
2.3 异常文件检测结果
在完成文字识别后,对3个测试集分别进行异常文件检测,检测结果如表1所示。由表1可知,所提方法在完成异常文件检测的同时,还可以确定异常文件类型。且最终得出的异常文件数量,与预期相同,表明所设计智能检测方法的可行性。
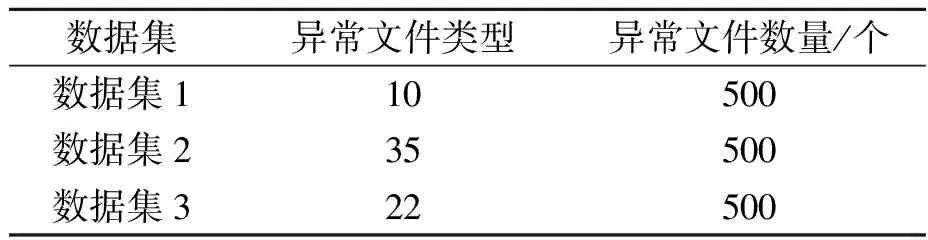
表1 异常文件检测结果
2.4 方法性能对比分析
定义评价指标为精确率和召回率的加权调和平均值(F-Score),以此来描述异常文件智能检测方法的性能,具体计算公式为:
(9)
式中:P为异常文件智能检测精确率;R为异常文件智能检测召回率。
将所提方法和基于复合特征的检测方法、基于注意力机制的检测方法进行对比,分别进行异常文件智能检测,3种方法检测结果的F-Score对比结果如图7所示。由图7可知,两种传统的智能检测方法的平均F-Score分别为0.60和0.46,基于OCR识别技术的检测方法的F-Score始终保持在0.9以上,平均F-Score达到了0.97,比其他两种方法提升了38.14%、52.58%。
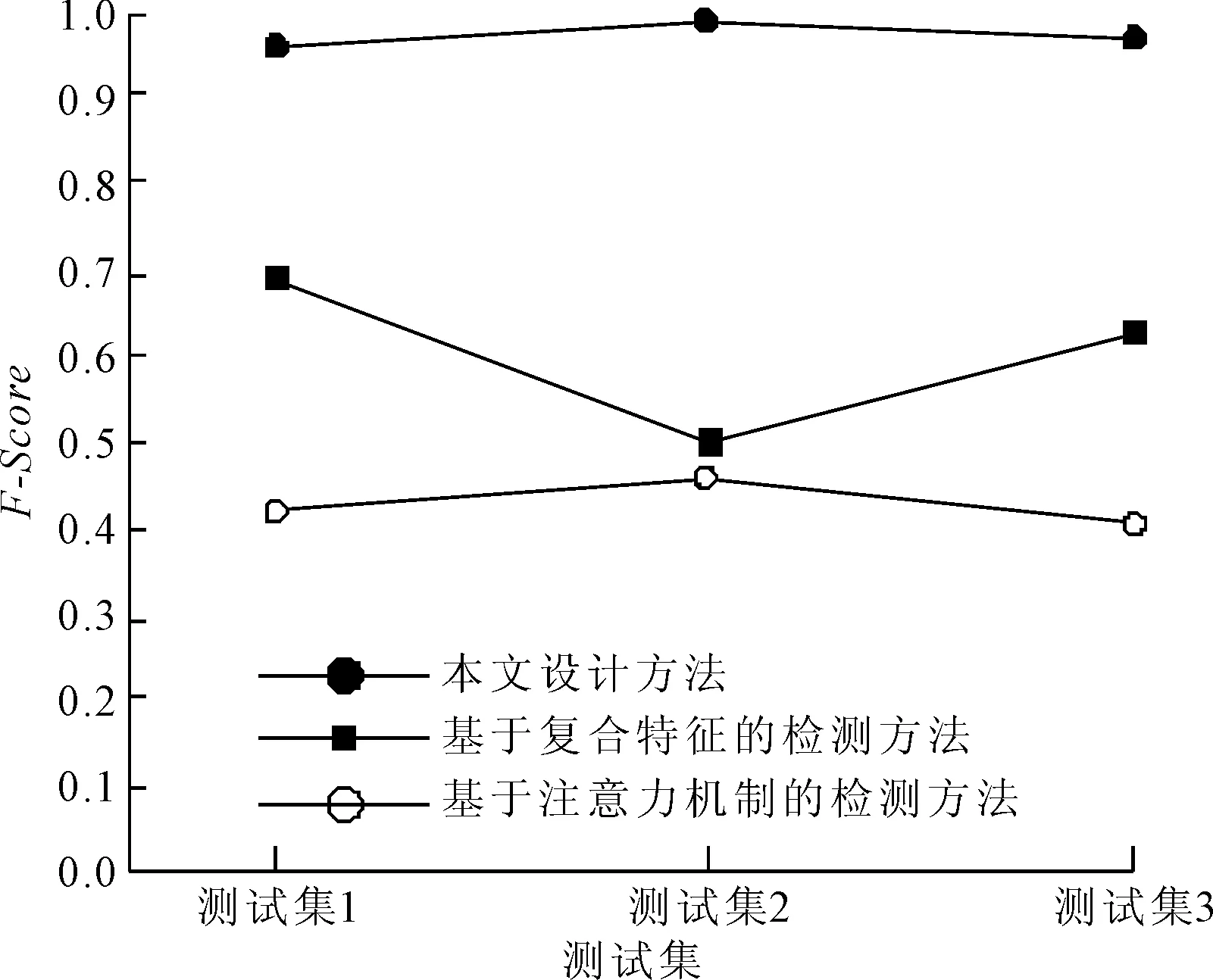
图7 不同智能检测方法的F-Score对比
3 结论
(1)针对信息库异常文件智能检测进行研究,提出应用OCR识别技术的新型检测技术,并在深度学习网络的辅助下进行异常文件检测。研究发现:①结合图像预处理技术和深度学习网络,能够准确提取扫描图像中的文字信息,并进行针对性的检测。②通过连接预选框网络和文本识别网络的结合,实现了对异常文件类型的智能检测,有效减少了人工判断的主观性和不稳定性,提高检测的准确性和效率。
(2)检测方法在异常文件检测方面表现良好,平均F-Score达到了0.97,说明该方法在智能检测异常文件时具有较高的准确性和效率,可以有效降低人工判断的工作量。该方法的可靠性和实用性得到了充分验证,可以作为一个实用价值较高的智能检测方案应用于碎片化时空信息库的异常文件检测。
猜你喜欢
承德医学院学报(2023年1期)2023-02-08
电脑报(2021年14期)2021-06-28
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
计算机与生活(2019年5期)2019-07-18
新生代(2018年16期)2018-11-13
中国交通信息化(2018年5期)2018-08-21
吉林大学学报(理学版)(2018年2期)2018-03-29
电信科学(2013年10期)2013-08-10
