
基于Web Service的分布式电网营销数据共享方法
2024-01-15 10:47李宇远
武汉理工大学学报(信息与管理工程版) 2023年6期
陈 竞,李宇远,杜 杰
(南方电网数字电网研究院有限公司,广东 广州 510670)
在分布式电网营销数据的管理和调度过程中,通过对电网营销数据进行特征和共享调度分析[1],实现数据共享[2]。同时,通过数据整合和信息融合,实现大规模多端口分布式电网营销数据的特征分布式重组,提高数据共享水平[3]。
文献[4]提出了智能电网环境下电力营销管理系统设计方法,结合移动互联网及数据分析技术在电力客户服务中的应用,实现电网营销过程管理和数据分析。但该方法的数据共享模糊度较大,数据融合度较低。文献[5]提出了基于AHP-Entropy的电网营销服务网点投资合理性模糊综合评价方法,通过对当期经济指标参数信息的分析,结合参数变动融合,进行大规模多端口分布式电网营销数据共享调度,采用AHP-Entropy熵函数进行分析,实现电网营销数据预测,但该方法的适应度共享水平有待提高。
针对上述问题,笔者提出基于Web Service的分布式电网营销数据共享方法。建立多个综合能源联供型微网调度模式下的大规模多端口分布式电网营销数据统计分析模型,提取电力营销数据的特征,助力于数据融合共享。构建综合能源联供型微网调度模式下的大规模多端口分布式电网营销数据的分散控制模型,通过适用性分析与模型测度分析,实现大规模多端口分布式电网营销数据的调度和信息融合。
1 电网营销数据统计分析和特征提取
1.1 电网营销数据统计分析
为了构建基于Web Service的大规模多端口分布式电网营销数据共享调度模型,先建立多个电网营销数据统计分析模型。结合模糊相关度分析方法实现对电网营销数据时间序列的特征分析[6]。分布式电网营销数据共享的总体结构如图1所示。

图1 分布式电网营销数据共享总体结构
根据图1构建大规模多端口分布式电网营销数据分层加权组合结构模型,得到电网营销数据分层特征信息融合系数R={r1,r2,…,rm}[7],其中m为层级。在稳定增长趋势模式的控制下,设定电网营销数据融合统计特征量为G,进而得到电网营销数据分层存储区域模块特征估计值Ts:
(1)

(2)
式中:T为融合特征参数;u为电网营销数据分层存储维数;ft(h)为t时刻下的第h个电网营销数据联合特征分布函数[8]。在上述分析的基础上,构建电网营销数据统计分析模型,从而实现分布式电网营销数据的共享调度。
1.2 多端口分布式电网营销数据特征提取
结合模糊相关度分析方法实现对多端口分布式电网营销数据时间序列的特征空间结构重组,构建电力营销异常数据的存储结构模型。电网营销数据时间序列下的特征点b在t时刻的模糊特征集合为Bt,Bt={b1t,b2t,…,bnt},其中n表示电网营销数据特征分布的稳态参数。根据空间分布式网格匹配,设定电网营销数据分块融合收敛条件和判决条件,分别如式(3)和式(4)所示。
(3)
(4)
大规模多端口分布式电网营销数据m层级的属性特征量为{l1,l2,…,lm},通过虚拟空间异构融合得到m层级的电网营销数据分层融合的特征分布集{s1,s2,…,sm}。通过语义本体融合,得到大规模多端口分布式电网营销数据的分块检测特征量U=[Ul,s]n,其中I为数据块中信息丰富度,S为数据块的结构模式。根据上述分析,实现对电网营销数据的共享调度和分块检测。
2 电网营销数据共享的优化调度
2.1 电网营销数据共享
结合模板特征匹配的方法,得到大规模多端口分布式电网营销数据共享调度的加权系数。建立大规模多端口分布式电网营销数据共享调度的模糊相似度特征量[9],计算密集场景中电力营销数据分布特征集的统计特征量,得到电力营销数据的共享信任度水平ITrust。
(5)
式中:kpi为综合能源联供型微网调度模式下多端口匹配节点;Qs为样本回归分布集;Trusta→b为节点a与节点b之间信任度函数,Trustb→c为节点b与节点c之间的共享度函数。根据频谱特征分解,计算综合能源联供型微网调度模式下多端口分布式电网营销数据的参数匹配特征量,得到kpi的标准正态分布。综合能源联供型微网调度模式下多端口分布式电网营销数据的解析模型为:
(6)
式中:Mpi表示综合能源联供型微网调度模式下电网营销数据共享重构特征向量a→c的个数;e表示微网调度参数,e∈[1,Mpi]。
考虑多个综合能源联供型分配,采用供应链匹配得到微网调度模式下多端口分布式电网营销数据的特征重组模型,关联映射表示为A→B,B→C。微网调度模式下多端口分布式电网营销数据的回归分析模型为:
(7)
式中:dp为对外的功率调节参数;df′为营销价值供应链参数;lp为分块样本回归分析特征量。采用目标级联分析法(analytical target cascading,ATC)[10],得到电网营销数据分层共享的互信息量:
C=I(Q)×ρ+Mp×fg
(8)
式中:I(Q)为电力营销数据的多综合能源联供参数;ρ为联合概率密度;fg为电网营销自相关信息g的分量。结合互信息特征匹配,进行综合能源联供型微网调度模式下多端口分布式电网营销数据共享。
2.2 数据共享优化
采用多次共享调度的方法得到大规模多端口分布式电网营销数据集A={a1,a2,…,ax},x为数据集A的数目,A中每个元素表示同一年度内企业业绩波动风险的κ维矢量。t时刻下综合能源联供型微网调度模式下多端口分布式电网营销数据时间序列的相似度特征变量为{atκ,1,atκ,2,…,atκ,x}。电网营销数据时间序列的相关性分布类型为jt,jt为1或-1,其中1代表正常,-1代表异常。
采用Web Service构架模式[11-12]构建综合能源联供型微网调度模式下的大规模多端口分布式电网营销数据的分散控制模型。
(9)
式中:O表示负荷峰值;γz表示微网调度模式下多端口分布式电网营销数据的访问节点z的最优间隔;ψtg表示t时刻下电网营销自相关信息g的分布时隙。
通过适用性分析与模型测度分析,优化调度模型:
(10)
式中:L(p)为节点p的损失函数;p为数据的分配节点。

3 仿真测试
通过仿真测试和SPSS统计分析软件,验证本文方法在实现大规模多端口分布式电网营销数据共享中的应用性能。使用高性能云计算平台支持广州电网大规模营销数据处理,设置星型网络拓扑结构,将星型拓扑中每个端口与中心节点之间的带宽限制设置为100 Mb/s,模拟分布式电网营销数据共享的网络环境。实验流程如图2所示。
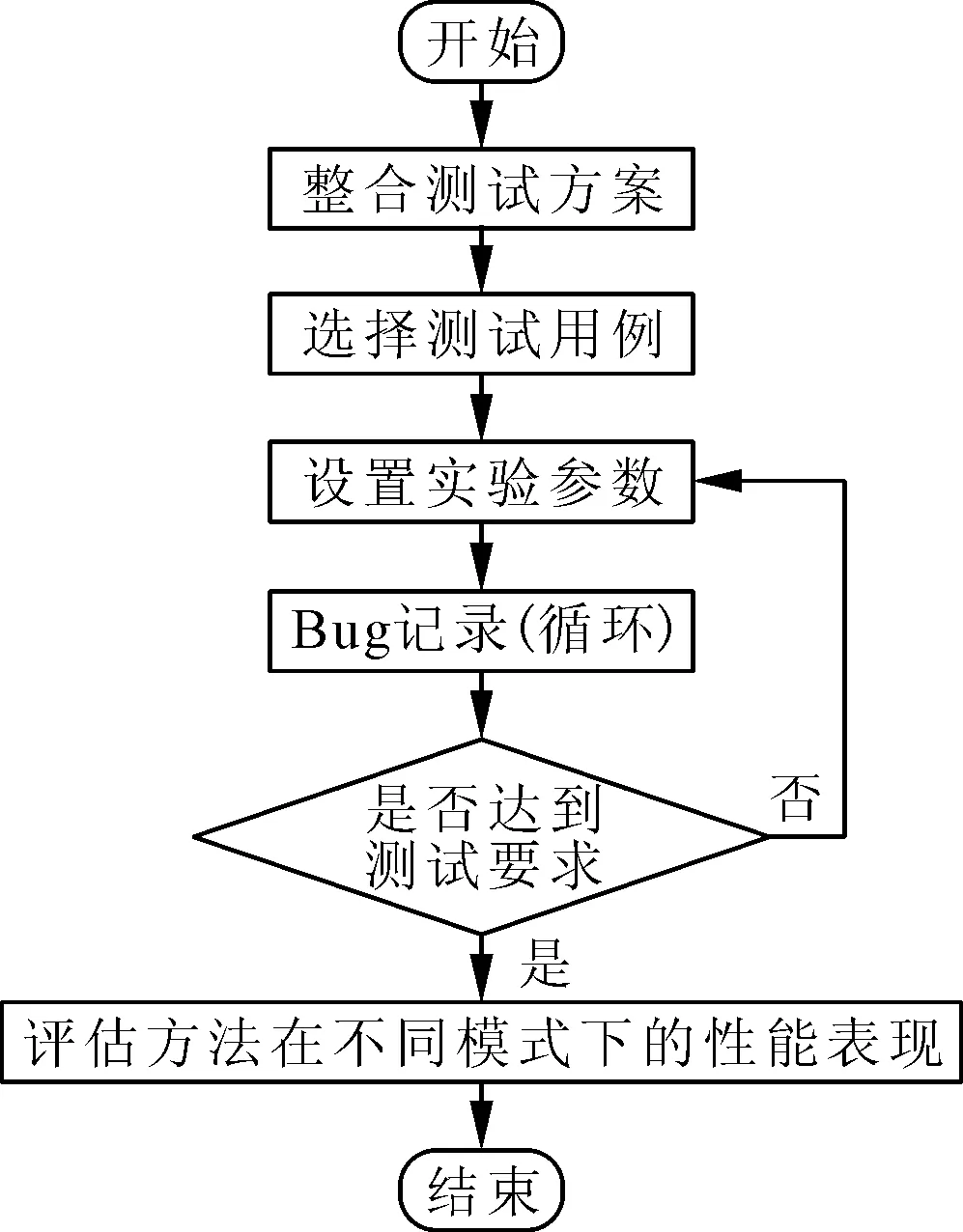
图2 实验流程图
3.1 电网营销数据描述性统计分析
电网营销数据的描述性统计分析是对数据进行整体概括和总结的过程,揭示数据的基本特征和趋势。结构参数是指电力市场规模的结构特征和组织形式。电力营销资本是指电力供应商的资本规模和财务状况。供应链是指电力供应商、交易平台和消费者之间的供应链关系和交易流程。决策链是指电力市场中的决策层级和决策流程。功耗是指电力系统或设备的功耗情况。供电能量是指电力系统提供的电力供应的总量、分时段供电能量。输出功率是指电力系统的发电机输出功率、变压器的变换功率。联合检测是指电力系统中电力质量变化情况。内控参数是指电力供应商的发电能力控制能力。经营盈余是指电力市场参与者的经营收入、成本、利润等情况。经营风险是指市场波动性、政策变化、供需不平衡等波动情况。统计分析值用于衡量数据集中某个特性的总体水平或分布情况,较高的统计分析值表明样本集特性总体水平较高。大规模多端口分布式电网营销数据采样的描述性统计分析结果如表1所示。
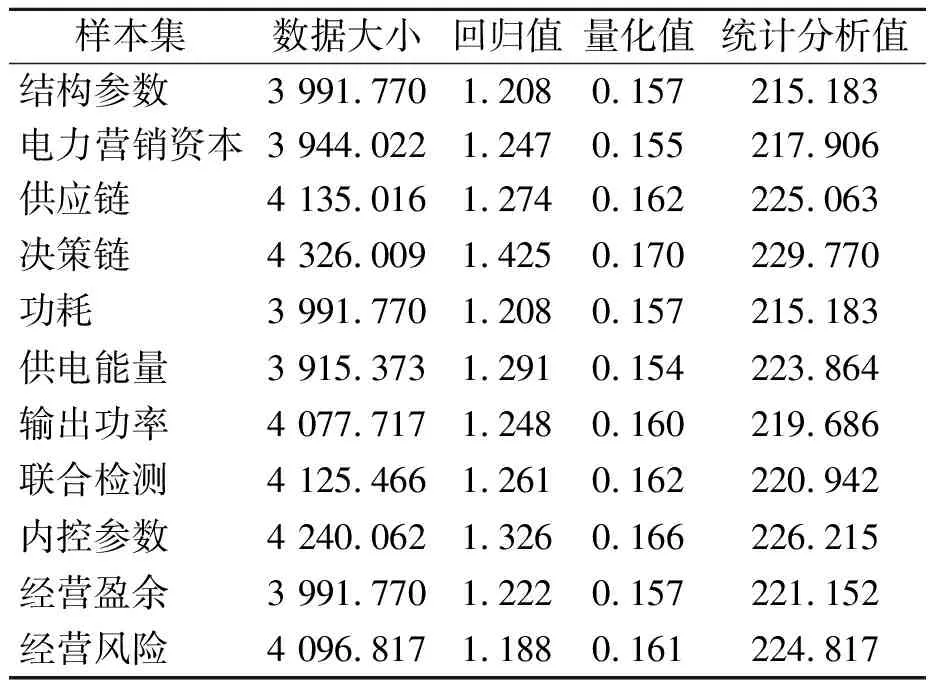
表1 电网营销数据描述性统计分析结果
由表1可知,供应链、决策链、内控参数的样本集数据统计分析值较高。供应链样本集数据统计分析值较高表明供应商交付电力设备或能源的延迟,可能会影响供应链正常运行。决策链样本集数据统计分析值较高表明决策制定和执行过程中未考虑电力需求和供应变化,导致电力分配和调度不合理。内控参数样本集数据统计分析值较高表明电力设备失效或能源短缺等,容易增加电力供应风险。
通过对样本集数据进行数据大小分析,揭示电网营销数据的趋势和变化情况,了解电力市场参与者的盈利状况及其随时间的变化趋势。对样本集进行回归值计算,揭示不同样本之间的关系,了解资本规模对经营风险的影响程度。对样本集数据进行量化值计算,揭示不同组别或不同时间点之间的差异情况,了解不同供应链模式之间的性能差异和效率差异。对样本集数据进行统计分析值计算,了解数据的分布情况和概率,有效避免极端情况,实现对大规模多端口分布式电网营销数据共享调度。
3.2 电网营销数据分布幅值分析
从电网营销数据中选择一部分样本数据进行分析。对采样数据进行清洗、去除异常值和缺失值,确保数据的准确性和完整性。使用标准差计算采样数据的分布幅值,比较训练样本和测试样本之间的计算结果。数据采样的分布幅值如图3所示。
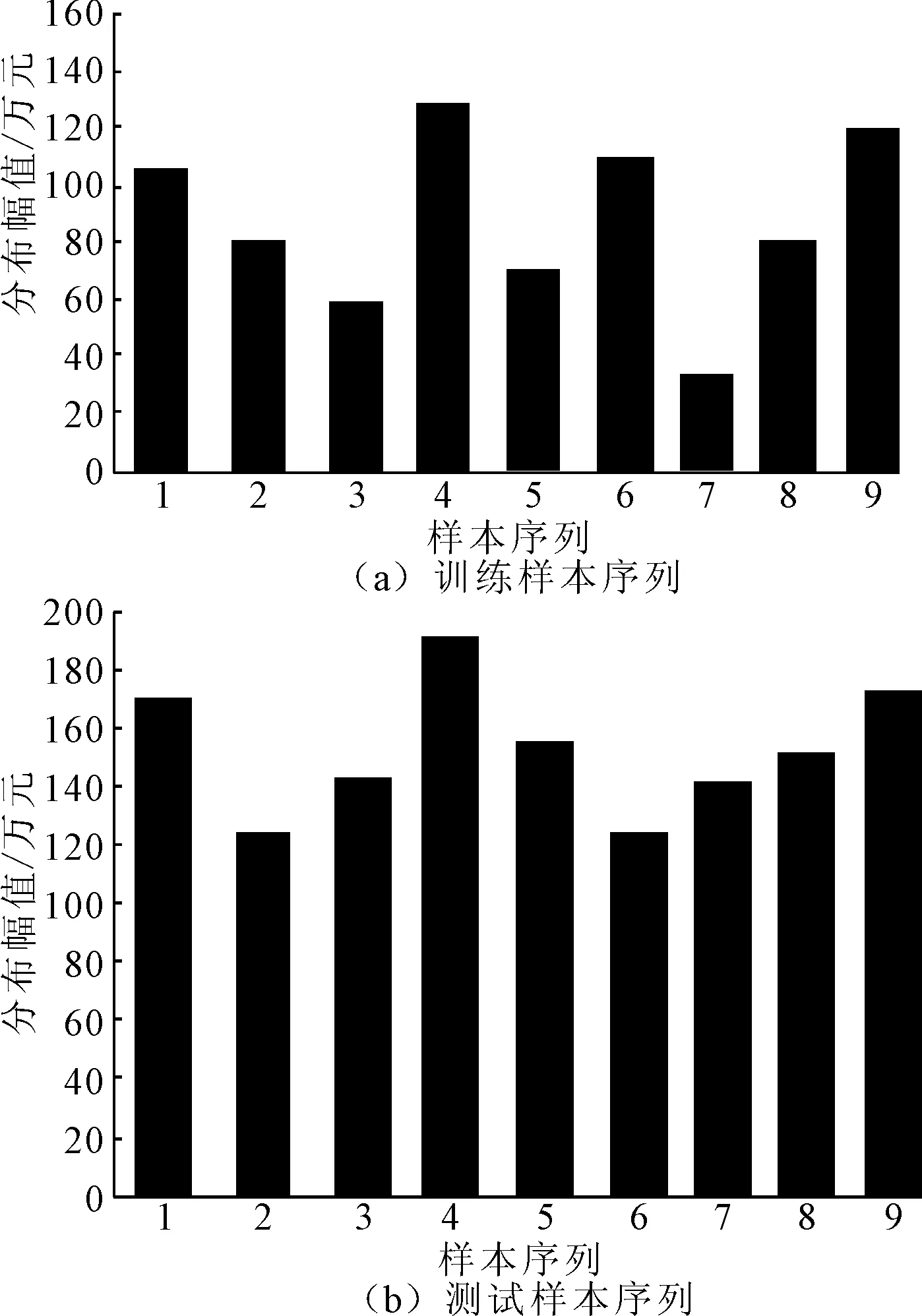
图3 电网营销数据采样分布幅值
由图3可知,训练样本序列包含9组数据样本,部分数据的分布幅值低于30万元,表明训练样本序列中,电网营销数据的变动范围较大,具有较大不稳定性。测试样本序列也包含9组数据样本,但其分布幅值均高于120万元。相较于训练样本序列,测试样本序列的数据变动范围较小,表明在测试过程中,电网营销数据的波动性较小。
3.3 电网营销数据聚类分布分析
以图3的测试样本序列为分布式电网营销数据对象,在供应链、决策链、内控参数条件下对电网营销数据进行聚类操作。聚类结果高于0.150的视为满足标准的聚类,聚类结果越高表明电力市场数据聚类效果越优。电网营销数据共享的聚类分布如图4所示。
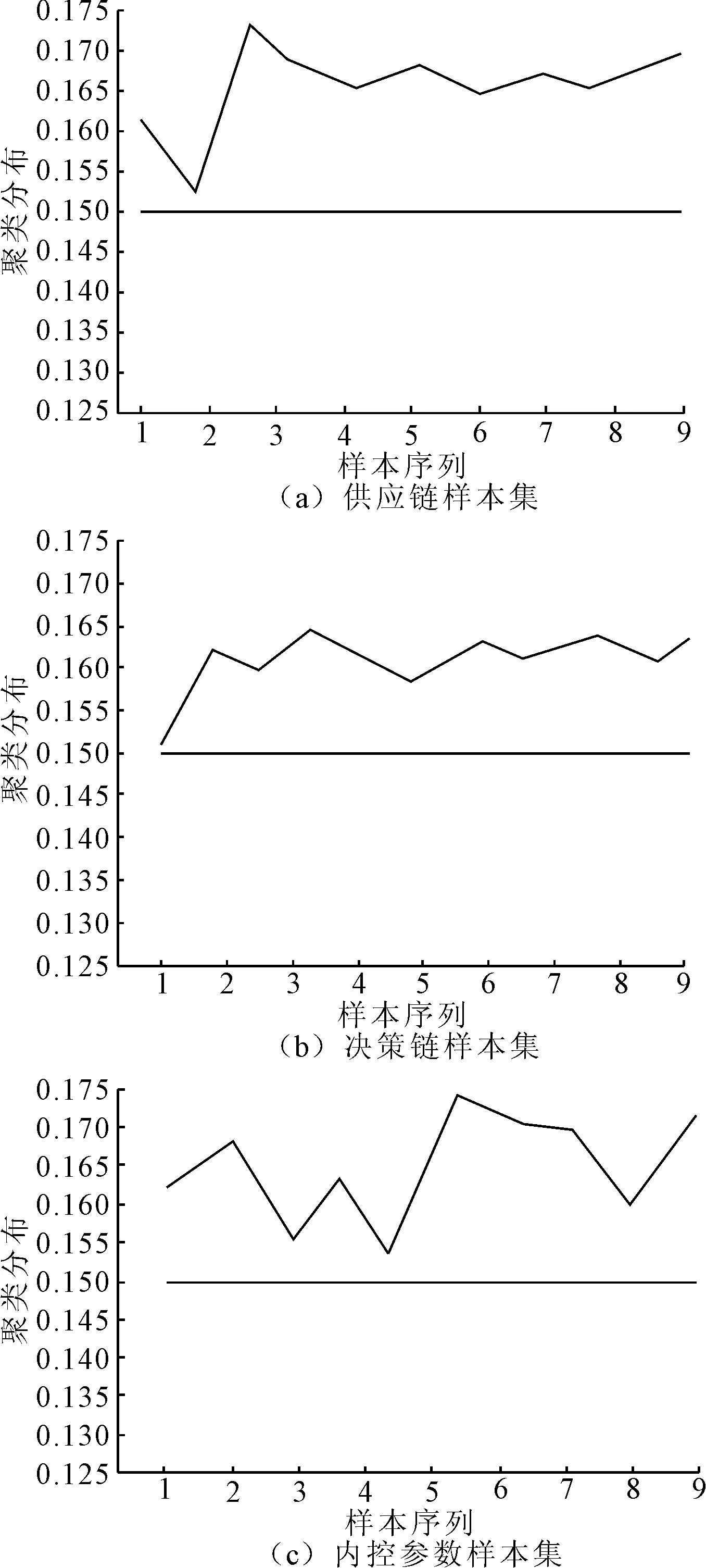
图4 电网营销数据共享的聚类分布
由图4得知,本文方法在供应链下的电网营销数据聚类结果为0.167,决策链下的电网营销数据聚类结果为0.163,内控参数下的电网营销数据聚类结果为0.168,均高于0.150。由此表明,本文方法能够有效实现对大规模多端口分布式电网营销数据的共享调度,提高数据的聚类水平。
3.4 电网营销数据共享融合度分析
共享融合度是指共享的电网数据具有互补性和完整性,共享融合度越高,越能有效提升数据内涵价值。采用本文方法、文献[4]方法和文献[5]方法分别计算大规模多端口分布式电网营销数据的共享融合度,共进行160次测试,取平均值为最终实验结果。具体计算结果如表2与图5所示。

表2 电网营销数据的共享融合度对比
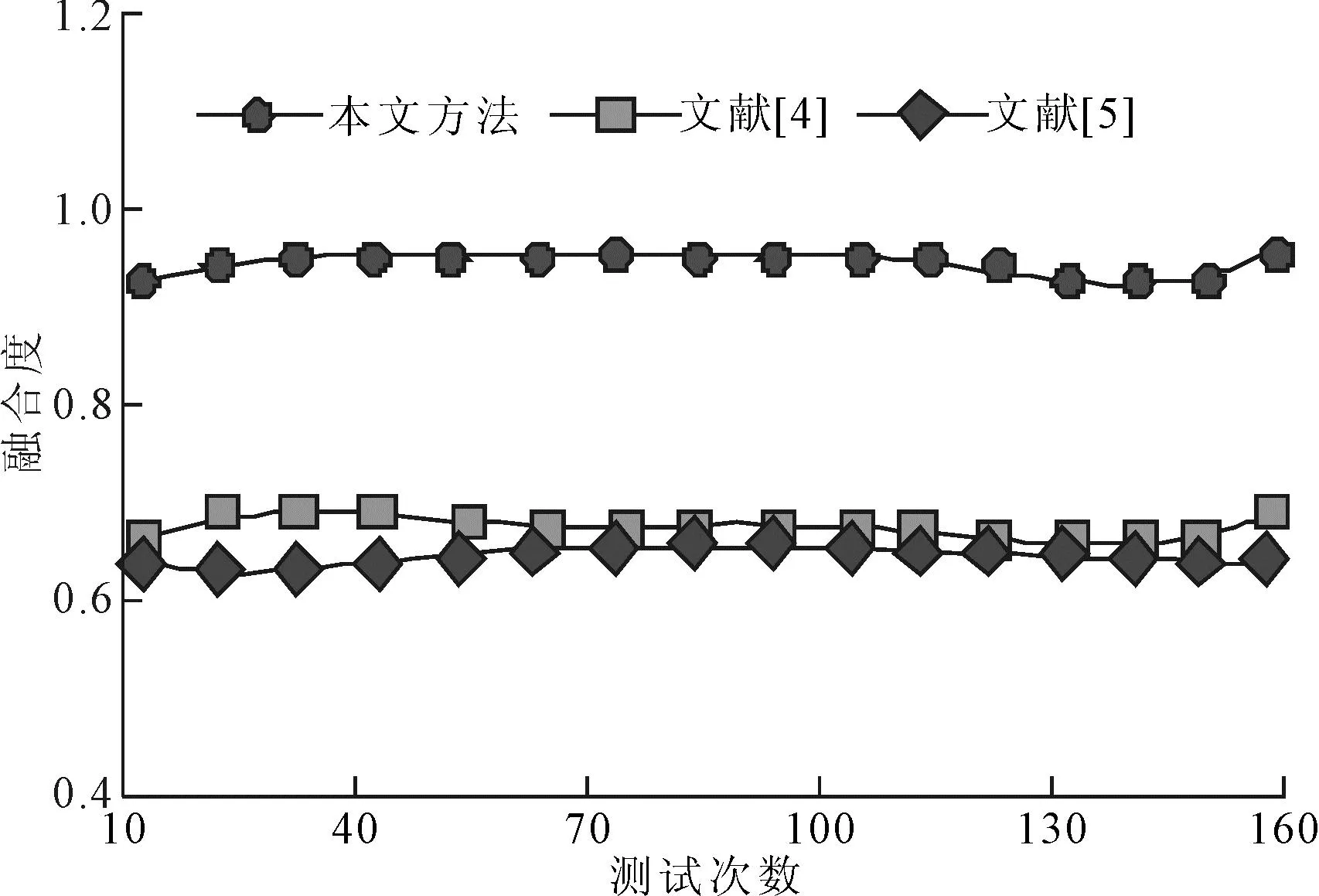
图5 不同方法的融合度对比
由表2与图5可知,本文方法进行大规模多端口分布式电网营销数据的共享融合度水平较高,平均数据融合度均高于0.9。而文献[4]方法和文献[5]方法的共享融合度水平较低,平均融合度介于0.6~0.7之间。这是因为本文方法采用Web Service构架模式,统一不同端口的接口规范,降低数据集成的复杂性,提高电网数据的互操作性,进而提高电网营销数据的共享融合度。
4 结论
(1)基于Web Service提出了分布式电网营销数据共享方法。通过构建电网营销数据统计分析模型和电力营销异常数据的存储结构模型分析和提取了电网营销数据统计特征。采用Web Service构架模式计算电力营销数据的共享信任度水平,结合适用性分析与模型测度分析实现大规模多端口分布式电网营销数据共享调度。
(2)电网营销数据聚类分布效果较好,在供应链、决策链、内控参数环节中均具有较高的相似性和一致性,能够从中各环节中提取特征信息,以此优化电力分配和调度,进而降低电网运营风险。
(3)电网营销数据共享融合效果较优,经过160次迭代测试后所提方法的共享融合度均高于0.9。由此证明,所提方法共享电网数据互补性和完整性较高,能够进一步提升数据内涵价值,为电网营销决策提供全面、准确的信息支持。
猜你喜欢
科学家(2021年24期)2021-04-25
智富时代(2019年7期)2019-08-16
智富时代(2019年7期)2019-08-16
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
财讯(2018年28期)2018-05-14
网络安全和信息化(2017年6期)2017-11-23
现代财经-天津财经大学学报(2016年1期)2016-12-01
通信电源技术(2016年6期)2016-04-20
电脑迷(2015年6期)2015-05-30
