
基于注意力机制的SOLOA 船舶实例分割算法
2024-01-15 14:39孙雨鑫苏丽陈禹升苑守正孟浩
智能系统学报 2023年6期
孙雨鑫,苏丽,2,陈禹升,苑守正,孟浩,2
(1. 哈尔滨工程大学 智能科学与工程学院, 黑龙江 哈尔滨 150001; 2. 哈尔滨工程大学 船舶装备智能化技术与应用教育部重点实验室, 黑龙江 哈尔滨 150001)
近年来,芯片的生产能力以及计算机技术不断提升,包括计算机视觉在内的多个人工智能领域蓬勃发展,人类已步入数字化、智能化时代。随着船舶数量、载运量不断增加,船舶交通日益稠密,人们对高性能的船舶智能监控设备的需求越来越高。船舶实例分割作为智能监控的重要基础,直接影响了监控的质量,因此寻求稳定且高效的船舶实例分割算法显得尤为重要。
然而目前多数船舶检测和分割算法大都基于合成孔径雷达(synthetic aperture radar, SAR)图像[1-3]以及红外图像[4],较少有文献研究可见光船舶图像的实例分割任务。此外,红外图像存在背景和目标的对比度较低、信噪比较低以及细节特征不全等问题。而SAR 图像含有大量伽玛分布的斑点噪声,且存在图像对比度较低、目标细微边缘不易区分[5]等问题。若将SAR 图像、红外图像应用到船舶实例分割任务,往往还需要图像降噪等预处理操作,难以直接应用。而谈到可见光图像,其在信噪比、图像对比度以及图像细节特征上均优于红外和SAR 图像,它具有丰富的颜色、纹理信息和较高的分辨率,便于检查和观测。除此之外,可见光图像易于获取,使得基于可见光图像的船舶实例分割算法拥有广泛的应用空间。同时相较于SAR 和红外图像的远景实例分割任务,可见光的实例分割可以有效应对近距离大目标,从而弥补对海上环境感知精度灵敏度较低的缺陷[6]。基于可见光图像的实例分割,在通用物体分割领域已经涌现了许多优秀的算法[7-19]并且在多分类的复杂任务中取得了卓越的性能。两阶段算法掩码分割网络[7]在通用分割领域性能优越,常被应用到诸如汽车、鸟类实例分割等其他特定领域。两阶段算法的优势是其采用先检测后分割的范式来处理图像中的目标,具有一定的鲁棒性,不易被图像中过多的背景信息所干扰。而近期许多以速度见长的单阶段实例分割算法也不断涌现,其中性能和速度名列前茅的SOLOv2算法[20]具有巨大的应用价值。然而,在使用自建的船舶实例分割数据集对SOLOv2 算法进行训练及测试时发现,对于普通海天背景下SOLOv2 算法具有可观的性能,但在船舶密集、背景复杂的场景下,由于背景干扰较多,SOLOv2 难以对船舶目标进行精确有效地分割。
本文根据上述问题,采用空间注意力机制来建模分类特征中的相互关系,并将其融合到分割特征中辅助船舶图像的分割,有效提高了复杂海上背景下的船舶实例分割性能。
1 SOLOv2 算法的原理
给定一个任意的图像输入,实例分割算法需要判断图片中是否存在实例,若存在则算法返回所有实例的分割掩码。SOLOv2 算法把实例分割问题转化为语义类别预测问题和实例掩码预测问题。主要思路是将图像划分为S×S个网格,从而以网格为样本点来预测不同实例的类别和掩码。原理如图1 所示,输入图像中的2 个船舶实例的中心落在2 个不同的网格中,则对应的2 个网格分别负责这2 个实例的掩码和类别预测,掩码和语义类别的预测分别由2 个独立的分支网络进行预测。通过采用特征金字塔网络(feature pyramid networks,FPN)[21]还可以将不同大小的实例有效地进行区分从而避免同一位置出现密集实例难以分割的情况。

图1 SOLOv2 算法的原理Fig. 1 Theory of SOLOv2 algorithm
1.1 语义分类
如图1 的分类分支主要负责预测所有网格不同实例类别的概率(包含背景类的预测),对于C个类别的数据集,如果我们将输入的图片划分为S×S(S=5)个网格,该预测网络的输出是S×S×C维度的张量,通道维度包含了不同类别实例的概率。在这种设计下每个网格都有一个语义类别的预测来表示该网格位置存在不同类别的可能性。
1.2 实例掩码预测
针对之前划分的S×S个网格,掩码分支负责预测每个网格对应S2个实例的掩码,从而产生H×W×S2维度的张量来表示全图每个网格实例的掩码预测。H和W分别表示长和宽。如图1 所示,分类分支的类别预测和分割分支的掩码预测是一一对应的,若设网格坐标为(i,j),则其对应分割分支中第k=i×S+j个通道的输出。由于实例的掩码预测和不同位置的网格是相互关联的,我们需要不同的通道激活不同位置的实例从而产生具有位置敏感性的特征。然而在一般产生预测掩码的全卷积网络(fully convolutional networks,FCN)[22]中,由于卷积网络自身存在的空间不变性,产生的特征并不满足该网络的要求。因此,SOLOv2 算法引入了坐标卷积[23]运算,在图像输入时产生2 个输入图像等大小的张量,并将其数据归一化到[-1,1]用来表示x和y坐标,最后将该张量并到图像输入的通道维,也就是说对于H×W×D维度的输入图像(H和W分别表示长和宽,D为通道数目),经过坐标卷积运算后转化为H×W×(D+2)维度输入到后面的卷积网络中。
1.3 可视化分析
为了更直观地分析SOLOv2 算法在船舶实例分割任务上存在的问题,本文采用ResNet101 作为特征提取网络的SOLOv2 算法,在构建的船舶实例分割数据集上进行36 个周期迭代的训练以获得效果最好的SOLOv2 模型,并在1 044 张图片的测试集上进行图像的可视化分析。通过可视化分析图2 发现SOLOv2 对于单一背景的图像具有良好的分割性能,而对船舶实例密集、船舶实例特征相似和背景复杂的图像的分割效果较差,出现了误分割等一系列问题。

图2 SOLOv2 船舶实例分割可视化Fig. 2 SOLOv2 for ship instance segmentation visualization graph
从SOLOv2 的实例掩码预测的网络结构可以看出,SOLOv2 算法针对不同实例的掩码是由一组对位置敏感的卷积核与融合的分割特征进行卷积运算得出的,因此实例分割算法的性能受到两方面影响:一方面卷积核需要对全图像的特征进行逐一地分类判断,在没有区域筛选限制的情况下,背景中的干扰极易影响到卷积核对实例的区分;另一方面融合的分割特征不能有效地对不同位置的实例产生不同程度的响应从而影响卷积核对不同实例的区分。
由于SOLOv2 算法主要从卷积核优化的角度出发,利用坐标卷积增加位置信息来提升算法对实例位置的敏感性,而对于分割特征还缺少一定的措施来保证其对实例的区分性。因此本文考虑对融合的分割特征进行改进,寻求一定的方法来使分割特征中的实例信息更加明显,让学习到的动态卷积核能更有效地区分不同的实例。通过建模网格间实例的相对信息,构建基于注意力机制的依靠位置分割目标(attention based segmenting objects by locations, SOLOA)算法。
2 SOLOA 船舶实例分割算法
针对于复杂海天背景下SOLOv2 算法出现的误分割问题,本文通过分析SOLOv2 的原理,构建对于复杂场景更稳定的基于注意力机制的依靠位置分割目标船舶实例分割算法。
2.1 网络结构
本文在SOLOv2 原有的网络结构上进行改进,设计了将分类特征引入分割特征的注意力(Attention)模块,充分的利用分类网络的信息,建模网格间实例的相对信息,构建SOLOA 算法。
2.1.1 分类网络
如图3 所示,分类网络依托于特征金字塔网络的多尺度输入,根据特征金字塔网络输出尺度的不同选取合适的网格大小S值,后续将图像进行双线性插值到S×S大小。后面网络包括语义分类网络和卷积核预测网络,2 个网络都采用4 个卷积层作为特征提取。同时2 个网络的权重在不同特征层级上是共享的。卷积核预测网络预测D维度的卷积核参数与S2个网格对应,对于1×1卷积来说D等于卷积输入通道数,而对于3×3卷积,D则等于输入通道数目的9 倍。语义分类网络经过特征提取后通过最后的1×1卷积来产生C个通道的类别预测输出。

图3 SOLOA 框架Fig. 3 SOLOA framework
2.1.2 注意力模块
与SOLOv2 算法不同的是,分析发现通过简单的叠加融合不同层的分割特征再进行上采样后的融合特征中具有许多干扰信息,使其在复杂的场景下无法进行有效分割。而分类网络将输入的特征插值到S×S的网格特征时也包含大量实例的信息,可以用其辅助分割产生更具有对比度、干扰较少的融合特征。另一方面,输入含有船舶的图像,分类特征中包含船舶实例的网格必然会获得较高的激活响应,这样根据分类特征的激活情况就可以获得全图中实例的分布,从而利用分类网络中的实例分布信息来辅助SOLOv2 算法的分割。
为了达到这一目的,引入了Attention 模块来建模分类特征间的关系并叠加到分割特征中,来增强分割特征中存在实例信息而减弱背景的干扰,获取全图视角的实例分布信息。具体的Attention模块结构如图4 所示,以S×S大小的分类特征(Categories Feature)为输入,通过1×1卷积产生Q、K、V等3 个向量,并通过Q和K向量相乘获得特征间相互关系矩阵进行归一化(softmax)操作运算,最后与V向量相乘获取注意力矩阵并叠加到输入的网格特征中获得最终的注意力特征。
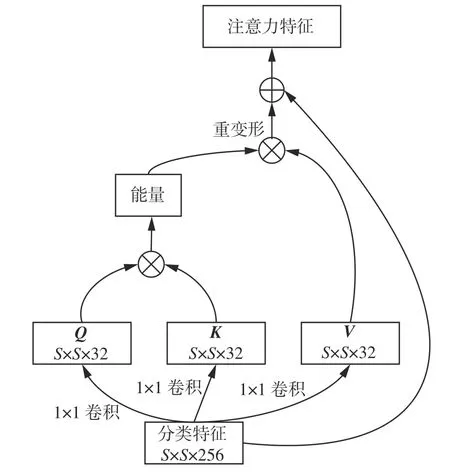
图4 Attention 模块Fig. 4 Attention module
2.1.3 分割网络
分割网络用来产生对实例敏感掩码预测。首先为了得到能包含多尺度特征的融合特征图,网络利用特征金字塔的{P2,P3,P4,P5,P6}层的特征图合并叠加本文引入的空间注意力模块的输出来产生多尺度的实例敏感特征图,然后根据不同尺度的输入重复引入3×3卷积、组归一化[24]、线性修正和2 倍双线性插值上采样,使得4 层网络都变为原图大小的1/4,然后进行叠加并通过1×1卷积网络调节通道融合特征信息,最终利用分类网络学习到的动态卷积核来产生最终的预测,细节如图3所示,实例敏感特征图的产生对于产生精确的分割掩码意义重大。
2.2 损失函数
采用常用的多任务损失函数来进行训练:
式中:分类损失Lcate采用的是Focal Loss[25],掩码预测损失Lmask的计算式为
式中:i=k/S,j=kS,Npos代表正样本的数目,p*和m*分别代表分类和掩码预测任务的真实标记值, ¶表示指示函数。
在比较不同的Focal Loss、BCE Loss 以及Dice Loss 等常用的分割预测损失函数后,选取Dice Loss 作为算法的最终损失:
D为Dice 系数,详细公式为
式中px,y和qx,y表示坐标为(x,y)的像素点在预测的掩码p和真实掩码q中的值。
2.3 推理阶段
推理阶段同SOLOv2 一致。给定一张输入图像,先将其导入特征提取和特征金字塔网络以及其后的分类和分割网络,产生每张图多达3 600 多个的掩码及类别预测,最后通过矩阵非极大值抑制算法筛选出预测效果最好的实例掩码进行输出。
3 实验与结果分析
3.1 算法平台
本次实验的硬件平台主要采用CPU 为Xeon E5-2620,内置一块NVIDIA GeForce GTX 1080Ti GPU。软件平台选择以Linux Ubuntu 16.04、Pytorch 1.5、CUDA 10.1 在商汤发布的MMDetection 1.0 框架上进行训练,保证模型训练的速度和稳定性。
3.2 数据集构建
本文主要以各类典型的目标为主要对象,其中包括军舰、渔船、货船、快艇、帆船等多类典型的目标。由于数据集中具体实例情况直接影响模型的训练结果,因此,收集图片时充分考虑了实例的角度、位置、距离、数目以及环境等不同因素。主要的数据来源包括3 部分:通过实船采集的海上图片、抽取通用标准数据集(VOC[26]、COCO[27])中含有船舶的图片、网络上下载的船舶图片。数据集图片总数为5 225 张,其中4 181 张作为训练集,1 044张作为测试集。数据集图片示例如图5 所示。

图5 船舶实例分割数据集Fig. 5 Ship instance segmentation dataset
3.3 模型训练
模型训练使用ImageNet[28]数据集预训练的ResNet 模型[29]进行初始化权重。初期设置了相对较大的学习率即0.01 实现模型训练的初期损失函数的快速下降,然而在实验过程中出现了损失函数收敛较慢、振荡和爆炸等问题。经过多次测试,最后选取较小的学习率即0.001 25 进行训练,并采用warmup 的形式保证训练初期的稳定性,最终采用70 000 次迭代,并为了保证模型平稳收敛在训练的第60 000 次迭代时将学习率缩小到0.000 13 左右。
模型的训练损失情况如图6 所示,在训练的初期损失下降较快,由于引入了注意力模块在10 000到20 000 次迭代时出现了一定程度的缓慢下降,但在30 000 次迭代后损失逐渐收敛,训练达到60 000次迭代时由于调整学习率,以较小的步长进行学习,整体损失基本收敛。

图6 SOLOA 模型训练损失值Fig. 6 Loss of the SOLOA model training
3.4 可视化实验
主要从改进前后的可视化分割效果和融合特征的可视化图2 个方面来说明SOLOA 算法的效果。
采用ResNet-101 为特征提取网络,超参数使用0.001 25 的学习率和0.9 的动量来训练SOLOv2 及其SOLOA,最终的分割结果对比如图7 所示。其中图7(a)为SOLOv2 算法的分割结果图,图7(b)为改进后的SOLOA 分割效果图,可见改进后实例的掩码质量得到有效的提高,同时一定程度降低了对背景的误分割。

图7 实例分割结果可视化对比Fig. 7 Visual comparison of instance segmentation results
为了更清晰地体现改进的作用机制,选取含有64 通道融合特征的模型进行训练,并和同样训练参数的SOLOv2 算法进行对比,其效果如图8所示。图8(a)为网络输入的原图,图8(b)为SOLOv2 算法融合特征图的输出,通过观察可以发现许多通道同时激活了图像中的船舶和背景,如图中标记的2 个通道,背景和目标之间的对比度较低,在后期的1×1卷积中引入额外的干扰信息,导致分割效果不好。在引入了空间注意力模块后的SOLOA 算法的特征图可视化如图8(c),可见通道抑制了背景信息的干扰,同时背景和实例的对比度更高,且大多数通道都仅仅激活了图像中的船舶信息,减少背景的干扰使得最终1×1卷积核的掩码的预测输出效果更好。

图8 特征图可视化Fig. 8 Feature map visualization
3.5 消融实验
考虑到注意力模块引入方式的多样性,本文对于相加和相乘的引入方式进行了测试。实验选择标准COCO 数据集的平均精度(average precision,AP)指标来评估算法的性能,AP 指标考虑了预测掩码和真实掩码的交并比(intersection over union,IoU)、准确率、召回率等指标,综合的反映了算法的整体性能。通过计算获得图像中每个预测掩码和真实掩码的IoU,通常评估时会选择一个合适的IoU 阈值来判断预测结果是否正确。划分好正确预测和错误预测后,对照数据集中所有标注的实例预测就可以计算平均精度。
式中:PTP表示真实标记为正,预测也为正的情况;PFP表示真实标记为负,但预测为正的情况;PFN表示真实标记为正,但预测为负的情况;PTN表示真实标记为负,但预测为负的情况。具体主要包括指标PAP、PAP50、PAP75来验证所有类别实例分割预测的综合情况和PAPS、PAPM、PAPL等3 个指标来表示图像中的小目标、中目标以及大目标分割的性能。PAP50和PAP75分别表示以IoU 阈值是0.5 和0.75来评价预测样本的精度值。PAP则为综合指标,表示使用IoU 阈值(范围为0.5~0.95,步长为0.05)来评价预测样本的精度值,即PAP50到PAP95范围内的平均精度。最后的消融实验结果如表1 所示。
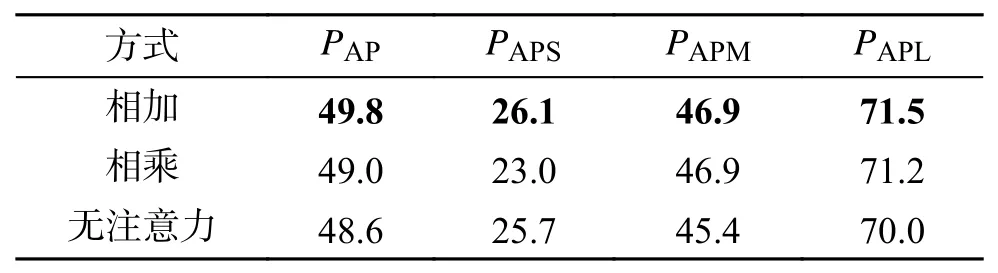
表1 注意力引入方式的对比Table 1 Comparison of the ways of using attention %
通过观察数据可以发现,相比未改进前无注意力的算法,采用相乘的形式将实例信息引入分割特征虽然对中、大目标有一定的提升效果,但会极大影响对小目标的分割效果。而采用相加的形式引入注意力特征并不会降低小目标的分割准确率同时会极大地提升中、大目标的分割效果。
3.6 主要实验结果
为了全面的评估改进后算法的性能,本文采用ResNet-50 和ResNet-101 这2 种特征提取的骨干网络,分别进行训练SOLOA 和一些其他主流的实例分割算法,包括YOLACT[8]、SOLOv2[20]和Polarmask[30]其实例分割结果如表2 所示。
相比SOLOv2,由于采用分类特征来辅助分割显著地提高了网络的表示能力,改进后的SOLOA算法在轻量级的ResNet-50 网络中有显著的提高效果,相比改进前的网络平均精度提升3.6%。而采用更复杂的ResNet-101-FPN 主干网络并采用3 倍迭代训练的模型性能最好,AP 可以达到49.8%,相比SOLOv2 算法AP 共增长了1.2%。并且改进后的SOLOA 其小、中、大目标的分割效果都有了一定的提升。同时,相比YOLACT 和Polarmask,SOLOA 算法性能也是最优的。此外,为了验证改进后SOLOv2 算法的运行速度,本小节采用单张1080Ti 显卡对模型进行速度测试和模型复杂度(参数量)比较,实验结果如表3 和表4 所示。增加了额外的融合机制并没有损失过多的速度性能,也没有增加过多的模型参数量,总体来看改进后的算法满足船舶实例分割的实时性需求。

表4 改进前后模型参数量对比Table 4 Comparison of the number of model parameters before and after improvement
4 结束语
本文针对SOLOv2 算法在船舶实例分割领域存在相似实例和背景误分割的问题,提出了一种利用分类特征中的实例分布信息进行注意力建模来融合分割特征的方法,构建了SOLOA 船舶实例分割算法。相比于SOLOv2 算法,SOLOA 算法对密集实例能有效分割,具有较好的位置敏感性和抗背景干扰能力,对不同尺度的实例尤其是中大尺度的实例均有明显的精度提升,在保证算法运行速度的前提下全面提升了分割精度,可以满足船舶实例分割的需求。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
通信学报(2019年5期)2019-06-11
北京航空航天大学学报(2018年1期)2018-04-20
通信技术(2018年3期)2018-03-21
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
电视技术(2014年19期)2014-03-11
