
安全帽与反光衣的轻量化检测:改进YOLOv5s的算法
2024-01-18 16:52张学立贾新春王美刚智瀚宇
计算机工程与应用 2024年1期
张学立,贾新春,王美刚,智瀚宇
山西大学 自动化与软件学院,太原 030013
分析近年来施工安全事故数据,发现近90%的事故是由于违章作业造成的,其中因未佩戴安全帽和反光衣而引发的事故尤为常见[1]。安全帽与反光衣在工业生产和交通作业中能起到预防安全事故的重要作用,被广泛地用于工地、钢铁、机械和造船等制造业,交通运输和户外作业等场景中,是工作人员的安全保障。目前,在安全管理中依然采用传统的视频监控系统和人工监督,存在不能实时检测,检测效果低,而且成本高等问题。为了解决工业生产和交通中存在的安全问题,并且实现智能化的管理,对安全帽和反光衣进行实时检测显得尤为重要。
随着近几年深度卷积神经网络和GPU计算能力的发展,目标检测被广泛应用于智慧农业、人脸识别、自动驾驶等领域[2]。如果将目标检测技术应用到安全帽和反光衣的检测中,可以有效降低安全事故的发生、人工成本,并且减少安全事故给企业和社会带来的巨大损失。现阶段目标检测算法可以分为两个主流方向,一类是基于回归策略的单步检测算法,如RetinaNet 算法[3]、YOLO系列算法[4-7]和SSD算法[8]类。此类算法的核心理论是将图像输入模型,直接返回目标的边界锚框、位置、类别信息。另一类是两步检测算法,主要有R-CNN[9-11]系列,这类算法先定位物体区域,再对区域进行分类。目前,国内外有许多学者对安全帽与反光衣进行了相关研究。Wang等人[12]提出了一种基于改进YOLOv3的安全帽和防护服检测算法,调整了锚框的尺寸增强安全帽和防护服的检测能力。Song 等人[13]将多目标跟踪算法DeepSort和YOLOv5相结合,在小目标与密集目标的环境下,提高了对安全帽的检测速度与检测准确率。Jin等人[14]在YOLOv5s 骨干网中加入DWCA 注意力机制,加强了特征学习,提高了对安全帽的检测准确率。Zhang等人[15]在YOLOv5s 中增加了一层检测头,提高了模型对小目标的识别能力。Sun 等人[16]在YOLOv5s 中加入MCA 注意力机制来降低头盔小物体的漏检率,提高检测精度。并使用通道剪枝策略对网络进行压缩。程换新等人[17]提出了一种基于改进YOLOX的安全帽反光衣检测算法,将BiFPN 模块替换原加强特征提取网络,并且使用Mosaic 方法训练,提高网络在复杂场景下的检测能力。
上述检测方法虽然一定程度上提高了对安全帽与反光衣的检测精度,但没有改变检测算法复杂、计算量大,对硬件设备要求高等问题,而且大多算法只是单一地对安全帽的检测,忽略了对反光衣的识别,应用范围小。针对目前安全帽和反光衣检测算法存在的问题,本文提出基于改进YOLOv5s的轻量化检测算法。在自制数据集上进行训练,并且效果良好。在原有YOLOv5s的网络基础上,引入Ghost_conv 代替原有的卷积模块,极大地减少了模型参数与计算量;在网络中增加了CA注意力机制模块提高了检测算法对感兴趣区域的特征提取;使用C3CBAM 模块代替部分C3 模块,在不提高模型复杂度的情况下,保持了检测精度。实验结果表明,所改进的YOLOv5s 检测算法在保证检测准确性的情况下,实现了模型的轻量化。
1 YOLOv5检测算法
YOLOv5 是YOLO 算法检测算法的第5 代版本,YOLOv5s网络结构图如图1所示。

图1 YOLOv5s网络结构Fig.1 YOLOv5s network structure
其中根据网络深度和宽度的不同,可以分为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。YOLOv5s 网络主要由3 部分构成,Backbone(骨干网)、Neck(颈部)和Head(检测头)构成。其中Backbone由CBS(Conv+BN+SiLU)、C3 模块和快速空间金字塔池化SPPF(spatial pyramid pooling-fast)构成,主要用于提取图像特征;Neck由特征金字塔FPN(feature pyramid network)+路径聚合网络PAN(perceptual adversarial network)构成,主要进行特征融合;Head对图像进行最终的预测。
2 YOLOv5s算法优化
2.1 Ghost模块的引入
在实际的应用环境中,YOLOv5s 网络模型性能容易受到硬件内存与计算量的影响。为了适应移动与嵌入型设备,引入了GhostNet 网络结构,以降低模型复杂度。GhostNet[18]是一种轻量化的网络,与传统的卷积神经网络相比,GhostNet 在不调整输出特征图的情况下具有更少的参数和更低的计算量。GhostNet 网络主要由Ghost模块构成。
Ghost模块[19]将传统的卷积与简单的线性运算相结合,利用了特征提取与特征图冗余的关系。
在网络中Ghost 模块代替了传统了卷积过程,先对特征图进行普通卷积操作,进行通道压缩,然后进行线性变换获得更多的特征图,然后将得到的特征图进行拼接操作,得到最终的特征图[20],结果如图2所示,其中Φ表示线性变换。普通卷积浮点计算量FLOPs的公式如下:
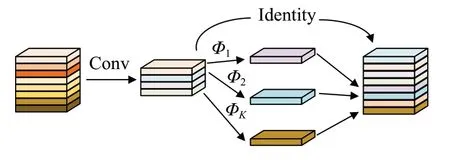
图2 Ghost模块Fig.2 Ghost module
Ghost模块的浮点计算量FLOPs公式如下:
式中,n为输出通道的数量;h′输出特征的高度;w′为输出特征的宽度;c为输入通道的数量;g为卷积核大小;s为Ghost模块中生成的特征图数量;d为线性操作卷积核的大小。
其中,s≪c,由计算可得知,普通卷积的计算量大约为Ghost 模块计算量的s倍。GhostBottleNeck(图3)中第一个Ghost 模块用于增加通道数目,第二个Ghost 模块用于减少通道数目,使其与输入通道数目相同。将C3模块与GhostBottleNeck结合,得到C3Ghost模块(图4),降低了模型的参数量与计算量。

图3 GhostBottleNeck模块Fig.3 GhostBottleNeck module
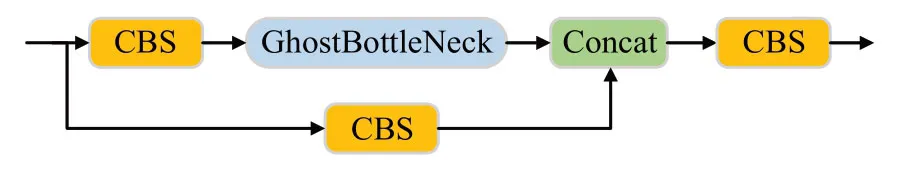
图4 C3Ghost模块Fig.4 C3Ghost module
2.2 CA注意力机制的引入
注意力机制可以忽略不重要的信息,获得特征图中重要的属性,从而提高检测性能。这种机制能够通过学习全局信息来选择性地强调信息丰富的特征并抑制无用的特征。在工业生产和交通作业,周围环境复杂多变,为了使网络更能关注到安全帽与反光衣,忽略背景信息,引入了CA注意力机制。
CA(coordinate attention)[21]是一种轻量化的注意力机制模块(图5),可以使模型更加准确地定位和识别感兴趣的区域。将通道注意力分解为两个1 维特征编码过程,分别沿2 个空间方向对特征进行聚合。这样,既可以沿空间方向捕获远程依赖关系,同时可以沿另一空间方向保留具体的位置信息,减轻由2D 全局池化引起的位置信息丢失[22]。然后将生成的特征图分别编码为一对方向感知和位置敏感的特征图,可以将其互补地应用于输入特征图,以增强关注对象的表示。不仅捕获跨通道信息,还捕获方向感知和位置敏感信息,这有助于模型更准确地定位和识别感兴趣的对象[23]。
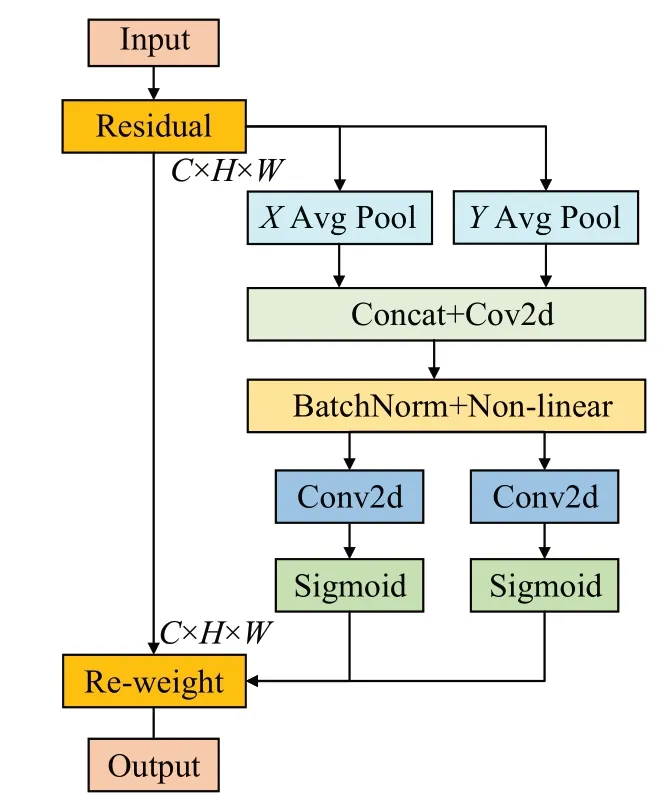
图5 CA注意力机制网络结构Fig.5 CA attention mechanism network structure
2.3 C3CBAM引入
CBAM[24](convolutional block attention module)是一个轻量级的通用模块(图6),它可以无缝集成到任何CNN架构中,计算量低,它由通道和空间的注意力机制模块构成[25]。CBAM 包含CAM(channel attention module)和SAM(spartial attention module)两个子模块,分别在通道和空间上,找到感兴趣的区域,这样既减少了参数量又降低了计算量,并且可以嵌入任意的网络结构中去。

图6 CBAM注意力机制模块Fig.6 CBAM attention mechanism module
本文将CBAM 与YOLOv5s 中的BottleNeck 模块相结合,构成了CBAMBotteNeck(图7),代替C3 中的BotteNeck,构成C3CBAM,既减少了参数量,又维持了一定的特征提取能力。

图7 CBAMBottleNeck模块Fig.7 CBAMBottleNeck model
2.4 改进后的YOLOv5s网络模型
改进后的YOLOv5s 网络模型结构如图8 所示,网络的Backone 层和Neck 层中使用Ghost 模块来代替传统卷积层,极大地降低了模型复杂度,减小了计算量。并且使用C3Ghost代替了主干网络中的C3模块。在网络模型中添加6个CA(coordinate attention)注意力机制模块,在不增加过多参数量的情况下,增强对了对感兴趣特征图区域的定位与识别,提高了识别精度。C3CBAM模块替代了Neck层的C3模块,在保持了对特征提取的同时,减少了参数量。

图8 改进后的YOLOv5s模型Fig.8 Improved YOLOv5s model
3 实验结果与分析
3.1 实验环境
实验CPU为Intel®Xeon®Gold 6230R @ 2.10 GHz,GPU 为NVIDIA Quadro RTX8000,显存为48 GB,ubuntu20.04 系统。使用Pytorch1.9.0 版本,编程语言python3.8.0,CUDA 版本为10.2。训练超参数设置为表1。共训练300 Epoch,批次大小设置为32,未添加预训练权重。

表1 超参数设置Table 1 Hyperparameter setting
3.2 数据集介绍
本文使用自己从网络上收集的图片,有三种图片类型,分别为安全帽、反光衣和其他类衣服,共1 083 张。为了增加样本数量,对图像进行了随机翻转和加噪等操作,数据集图像增加到5 415张,并使用labelImg对数据集中的图像进行了标注。其中训练集和测试集的比例为8∶2(训练集4 332张、测试集1 083张)。
3.3 评价指标
本文的评价指标主要有平均精度mAP(mean average precision)、参数量、浮点计算量FLOPs和模型大小。
式中,TP(true positive)表示正样本被分类为正样本;FP(false positive)表示负样本被分类为正样本;FN(false negative)表示正样本被分类为负样本。N表示样本类别。P(precision)表示精确率,R(recall)表示召回率,AP(average precision)表示某个类比的平均精度。参数量与计算量FLOPs来衡量模型的复杂程度。
3.4 消融实验
为了验证本文所提出模型算法有效性,在自制数据集上进行了消融实验如表2 所示。在加入Ghost 模块后YOLOv5s的参数量下降了3.33×106、计算量下降了7.8 GFLOPs、模型大小降低了6.28%,但mAP 值也下降了1.7 个百分点。在YOLOv5s 中单独加入CA 模块后,在保持参数量和计算量几乎不变的情况下,mAP值提升了0.5个百分点。单独加入C3CBAM模块后,模型mAP值降低了0.9 个百分点,参数量降低了0.5×106。从表2的对比中可以看出,Ghost 模块可以大幅度降低模型的复杂程度,但同时影响了模型的平均精度。加入CA模块虽然能提高mAP 值,但同时也略微增加了模型复杂程度。C3CBAM 也降低了模型的复杂程度,同时保持了一定的mAP 值。本文将3 种模块与YOLOv5s 相结合,mAP 值达到93.6%,参数量为4.28×106,计算量为9.2 GFLOPs,模型大小为8.58 MB。与原始的YOLOv5s模型相比较,参数量下降了39%,计算量降低了41.7%,模型大小降低了37.3%,而模型的mAP值略高于原来的YOLOv5s检测算法。

表2 消融实验Table 2 Ablation experiment
3.5 对比实验
P-R 曲线代表Precision(精度率)与Recal(l召回率)之间的关系。横坐标为召回率,纵坐标为精确率。
P-R曲线与坐标轴围成的面积为此种类型的AP,所以曲线越靠近右上方,AP 越大,算法性能越好。如图9所示三条细线分别代表安全帽、反光衣和其他类衣服,蓝色实线为三种类别的平均精度mAP。可以看出,所有曲线都非常靠近右上角,围成面积占到90%以上。
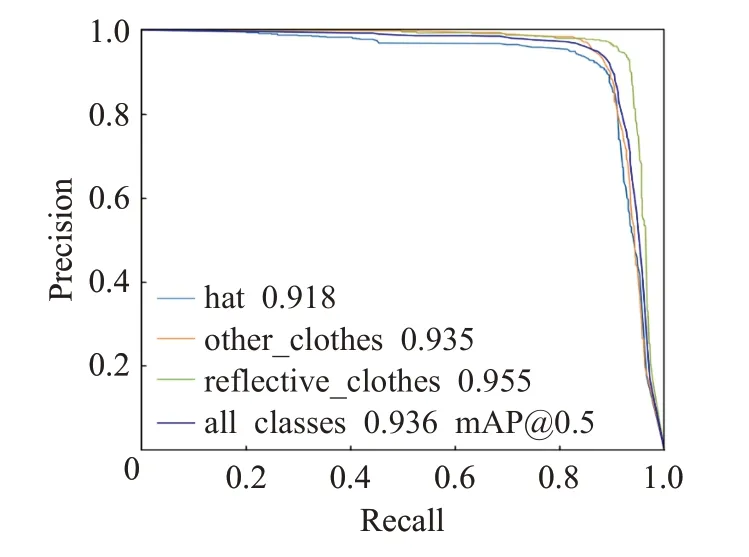
图9 P-R曲线Fig.9 Precision-Recall curve
图10为算法的mAP曲线,共迭代300轮,当训练到50 Epoch 时,算法的平均精度已经达到0.8 以上,收敛块。训练到120 Epoch,平均精度已经达到0.9,算法的平均精度高。
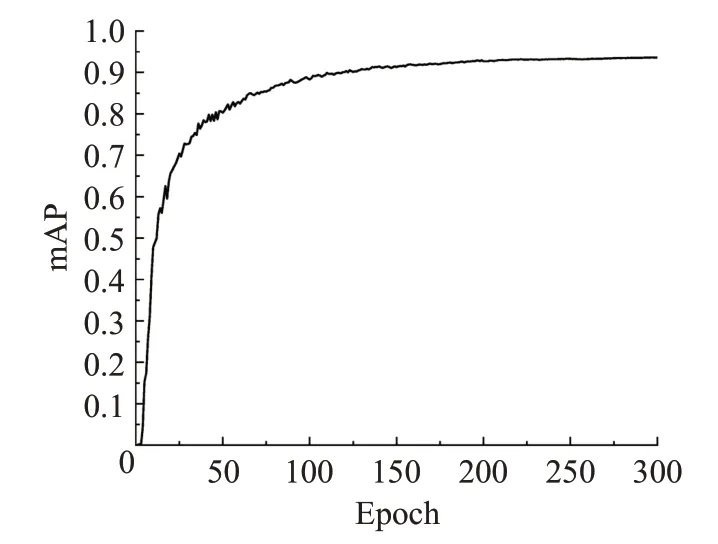
图10 改进YOLOv5s mAP曲线Fig.10 Improved YOLOv5s mAP Curve
在自制数据集上,对安全帽,反光衣和其他类衣服,使用YOLOv5s 与改进后的YOLOv5s 检测算法对目标进行识别对比,结果如图11所示。从六张图可以看出,对于安全帽的识别,改进前和改进后置信度相似,但对于反光衣和其他类衣服的检测,改进后的检测算法得到的置信度略高于改进后,展示了所改进算法的实用性。

图11 检测对比Fig.11 Detection and comparison
为了更进一步展示所提出算法的优异性,将本文所改进的检测算法与YOLO系列的轻量级模型YOLOv3-Tiny、YOLOv4-Tiny 和YOLOv7-tiny 相比较,同时也和经典YOLO 检测算法YOLOv3、YOLOv4 和YOLOv7 相比较,结果如表3 所示。YOLOv4-Tiny 的mAP 值仅为65.99%,模型大小为22.49 MB 与改进后的YOLOv5s 模型有较大差距。YOLOv3-Tiny 的mAP 值为86%,远远低于YOLOv5s的平均检测精度。YOLOv7-tiny的mAP值为92.0%,参数量为6.01×106,性能表现良好,但并未超越改进后YOLOv5 的效果。改进后的YOLOv5s 的mAP达到93.6%,而且模型的复杂程度也小于其他轻量级模型。而YOLOv3 检测算法的mAP 值虽然达到93.7%与改进后的算法相接近,但其模型参数量达到61.5×106,计算量为154.6 GFLOPs,相较于轻量级算法过大。YOLOv4的模型复杂度也相对较高,而且在自制数据集的上检测精度也过低,仅为61.2%。YOLOv7 的mAP 值略高于改进后的YOLOv5s,但其模型复杂,不符合轻量化。YOLOv7-tiny、YOLOv3-tiny 与YOLOv4-tiny模型的每帧推理时间分别为2.0 ms、2.9 ms与3.1 ms,检测速度较快。改进后的YOLOv5 的每帧推理时间5.3 ms与原始YOLOv5s 相近,但比YOLOv3、YOLOv4、YOLOv7检测算法更快。综合比较后,可以看出改进后模型的性能明显优于其他网络模型。

表3 对比实验Table 3 Contrast experiment
4 结论
本文针对安全帽与反光衣提出了一种改进的轻量化YOLOv5s检测算法。使用Ghost模块替换了YOLOv5s中的卷积,极大程度地减少了模型的参数量和浮点计算量。同时加入了CA注意力机制,并且用C3CBAM模块替换了网络中原来的C3模块,维持了算法原本mAP值。通过消融实验对比,展示了改进各模块的优点。最后与其他轻量级算法相比较,改进后检测算法的各项指标表现优异,符合模型轻量化要求,更适合在移动设备和嵌入式中使用。
猜你喜欢
机电安全(2022年4期)2022-08-27
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
课外生活·趣知识(2019年4期)2019-09-10
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
华东理工大学学报(自然科学版)(2014年3期)2014-02-27
