
基于跨度解码的嵌套命名实体识别方法
2024-01-18 16:52念永明陈艳平秦永彬黄瑞章
计算机工程与应用 2024年1期
念永明,陈艳平,秦永彬,黄瑞章
1.贵州大学 公共大数据国家重点实验室,贵阳 550025
2.贵州大学 计算机科学与技术学院,贵阳 550025
命名实体识别(named entity recognition,NER)是自然语言处理(nature language processing,NLP)中的一项基础性工作,目标是从句子中提取如人、位置和组织等特定的命名实体。识别命名实体通常被认为是理解一个句子语义的关键的第一步,被广泛应用于支持众多下游任务,包括关系抽取[1]、机器翻译[2]、问答系统[3]等。由于句子中的命名实体可以相互重叠,从而导致了它们之间的嵌套结构。实体的嵌套现象经常出现[4],并且实体的嵌套结构通常可以表达实体之间的一些重要的语义信息,如从属关系、隶属关系、上下级关系等[5],因此嵌套命名实体的识别引起了广泛的关注。
不同于传统的平面实体的识别,嵌套实体由于句子中的一个词可以同时被多个标签所标记,所以通常不易采用输出最大化概率的标签序列的方式进行识别。很多相关工作采用跨度分类的方法来进行嵌套命名实体识别。跨度分类是识别嵌套的文本提及的一种直接而有效的方式,在识别嵌套命名实体的应用上也取了不错的成果。跨度分类的方法将句子的每个子序列视为一个潜在的实体跨度,通过穷举所有可能的跨度并使用跨度内的语义信息对每一个跨度进行验证,可以方便而有效地识别嵌套实体,同时在识别以往的方法难以识别的较长的实体上也具有优势。然而因为需要穷举所有的跨度,所以传统方法存在着计算复杂度较高和数据不平衡的问题。并且,句子中的实体普遍存在紧密的依赖关系,即一个实体是依赖于句子中的其他实体出现的。由于传统的跨度方法对每个跨度的判别是独立分开进行的,忽视了句子中重要的实体和实体之间的依赖关系。
学习和捕获实体间的依赖关系,对于辅助和增强实体识别有特别的意义。可以通过如图1 所示的一个例子来对捕获实体间依赖关系的重要性进行理解,图1所示的句子中存在两个实体,并出现了嵌套的现象,外部是一个DNA 实体,而内部是一个蛋白质实体。通常DNA 通过控制蛋白质的合成来表达遗传信息,所以在对“Interleukin-2”进行预测时,如果已知“Mouse Interleukin-2 receptor alpha gene”是DNA实体,那么将更有把握将“Interleukin-2”正确识别为蛋白质。实体间相互依赖的现象在现实中大量存在,探索一种机制来对实体间依赖进行学习和捕获,将有助于提供更加丰富的语义信息来支持识别句子中的存在相互依赖关系的实体。

图1 GENIA数据集上实体嵌套的例子Fig.1 Example of entity nesting on GENIA dataset
为此,本文提出一种基于跨度解码的嵌套命名实体识别方法。首先结合字符特征、词性嵌入、词嵌入向量以及预训练语言模型输出的上下文向量对句子进行编码,获得句子丰富的语义信息以支持后续的工作。然后不同于传统的跨度分类方法对所有跨度进行穷举,通过先检测可能的实体开始边界锚定实体的位置,减少了所需要列举和验证的跨度数量。最后以解码的形式,逐一识别具有同一开始的嵌套实体,在解码过程中利用注意力机制关注于已预测的实体信息,并将预测的实体跨度信息和标签信息进行传递。通过以解码的形式层层传递实体跨度信息,可以有效学习实体跨度之间存在的依赖关系。
基于多特征编码、实体开始边界检测以及跨度解码,本文提出一个编解码结构的方法来对嵌套命名实体进行识别,并且以多目标学习的方式加强实体开始边界检测和跨度分类任务之间的交互性。本文的主要贡献如下:
(1)通过检测实体的开始边界,锚定实体位置,一定程度缓解了传统跨度分类方法存在的计算复杂度较高和数据不平衡问题。
(2)结合跨度分类和编解码结构的优势,提出了一个基于跨度解码的方法来识别嵌套实体,在解码过程中传递实体信息,能够捕获传统跨度分类方法所忽视的实体之间的依赖关系。
(3)实验证明了所提出的方法能够有效识别英文和中文的嵌套命名实体,并且优于以往基于跨度分类的方法。
1 相关工作
嵌套命名实体识别的方法可大概归结为以下3类:基于序列的方法、基于超图的方法以及基于跨度的方法。
基于序列的方法将命名实体识别视为输出句子相对应的最大概率的标签序列的任务。由于嵌套实体中的单词可以被多个标签所标记,所以传统的序列标注方法并不能直接使用,但是通过将多个标签进行组合形成新的标签便可以沿用序列标注的方法来识别嵌套实体,Strakova等人[6]就采用了这样的方案。但是这种拓展标签集的方法往往存在标签稀疏的情况。通过编解码的方式可以产生与输入序列数量不同的实体标签序列,例如Yan等人[7]提出一种通用的解码框架可以同时处理平面、嵌套和不连续实体。还有通过叠加重复使用序列标注模型,也可以对嵌套的实体进行识别,例如:Alex 等人[8]提出为每个实体类型分别用一个CRF进行识别,以及堆叠CRF层以从内到外识别嵌套的实体;Ju等人[9]通过堆叠LSTM+CRF 的平面实体识别层,设计了一种深度的神经网络模型来从内到外识别嵌套实体;Shibuya和Hovy[10]为每种实体类型训练一个CRF,先识别最优路径,然后识别其中的次优路径;Wang等人[11]提出一个金字塔状的嵌套命名实体识别模型,每一层识别特定长度的实体。
基于超图的方法是通过将句子构造成一个超图,以此来识别嵌套实体。最初由Lu和Roth[12]提出通过构造超图来抽取文本中嵌套的提及。后来Muis和Lu[13]在此基础上,通过标记词之间的间隙拓展了超图的构造方法。Katiyar 等人[14]通过使用Bi-LSTM 来对超图的边概率进行建模,进一步改进了超图的表示。再后来,Wang等人[15]提出一种分段的超图的表示,可以捕获到之前的方法无法捕获的特征。
基于跨度的方法通过生成所有可能的跨度并进行分类来识别嵌套实体。最近,Xu 等人[16]试图通过将每个子序列编码为一个固定大小的表示,然后直接对一个句子的所有子序列进行分类。Sohrab和Miwa[17]提出了一个深度穷举的方法,通过枚举所有不超过特定长度的区域并通过Bi-LSTM 来学习其表示,然后对区域进行分类,以此识别嵌套实体。之后Zheng等人[18]通过定位实体边界并联合学习边界检测和实体分类任务,改进了深度穷举的方法。Eberts 和Ulges 使用了预训练的Transformer 以跨度分类的方式联合抽取实体和实体之间的关系[19],预训练的Transformer在跨度分类方法上的应用,带来了性能的显著提升。之后,Tan 等人[20]通过实体边界检测器来获取高质量的跨度以过滤大部分的负例。
2 跨度解码模型
传统的基于跨度的方法对于每一个跨度的预测都是独立进行,对于跨度标签的预测,仅仅只利用该跨度的信息,即,其中表示第i个词到第j个词的跨度,yi,j表示其该跨度对应的标签。不同于传统的跨度分类的方法,本文所提出对跨度预测的前提不仅是当前的跨度信息,而且还需要之前的预测的实体跨度信息以及对应的预测的标签信息,即,其中分别是之前已预测出的实体跨度以及对应的实体标签信息。并且,本文通过传递实体跨度信息和跨度对应标签信息,利用注意力机制关注于与已经预测出的实体跨度信息相关的上下文信息,从而能够捕获之前方法所不能捕获的实体间的依赖关系,并获取更加丰富的语义信息以支持对实体跨度的预测。
本文所提出的模型由三个模块组成:多特征编码、跨度生成和跨度解码。模型的概况如图2 所示。多特征编码模块对输入序列进行上下文、词级、词性、字符特征的映射然后将多种特征进行融合,以获得丰富的上下文语义信息支持开始边界检测和跨度分类。跨度生成模块通过边界检测器检测实体开始,然后再从可能开始位置生成潜在的实体跨度。跨度解码模块以解码的结构,依次对不同开始位置对应的跨度进行验证,并且将预测的实体信息传递,以帮助识别后续的实体。下面将对各模块进行详细介绍。
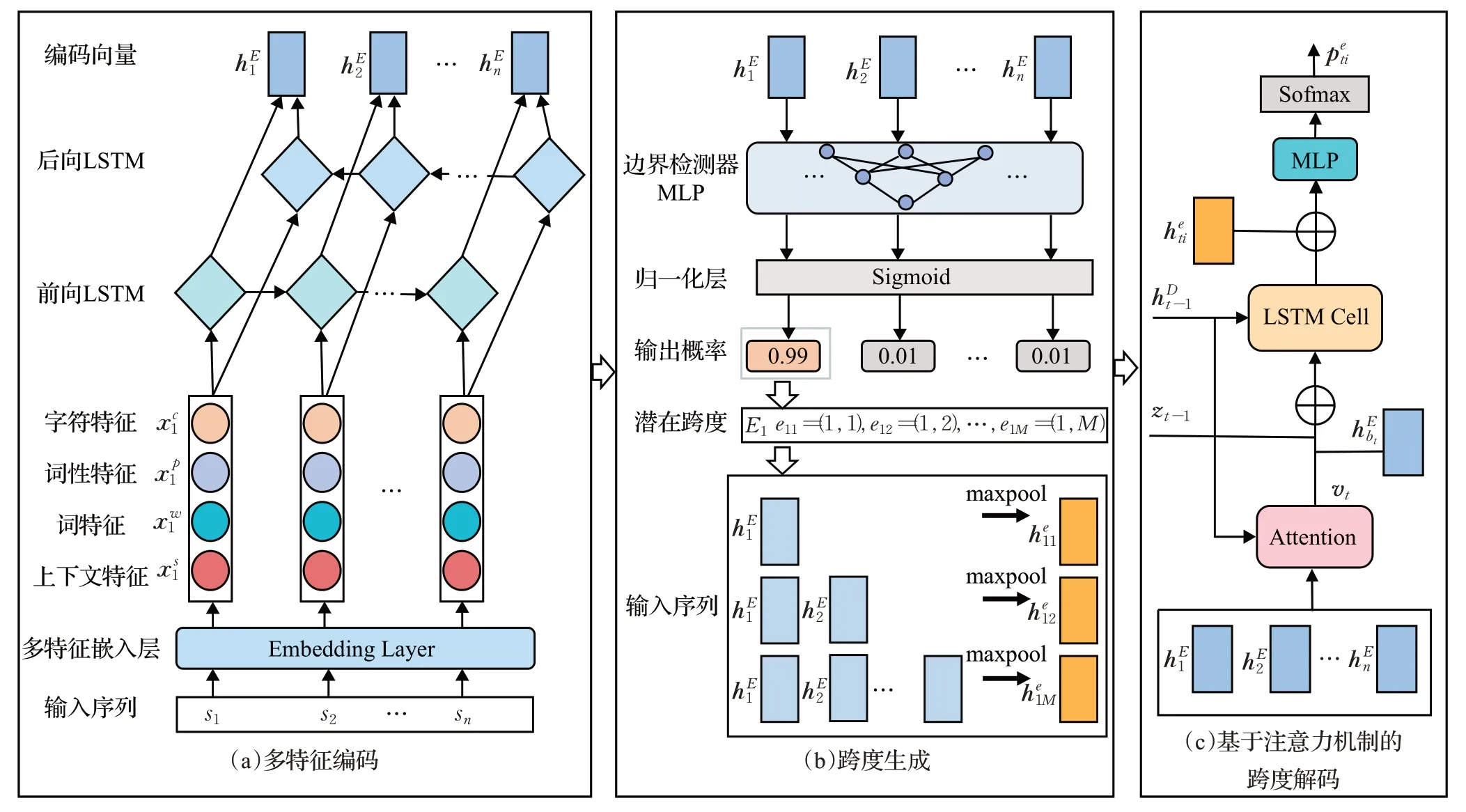
图2 模型结构图Fig.2 Model structure diagram
2.1 多特征编码
在编码阶段,结合上下文特征、词特征、词性特征以及字符特征对输入的文本序列进行编码。主要思想是将特征向量进行拼接,然后使用长短期记忆网络(long short-term memory,LSTM)来融合多特征以及进一步捕获序列的上下文信息。
对于一个输入的文本序列S={s1,s2,…,sn},si表示其中的第i个单词。通过一个嵌入层(embedding layer)获得文本序列的多个特征表示,具体过程是:通过预训练的语言模型获得S的句子级别的上下文特征表示,通过预训练的词嵌入获得词级别的特征表示,通过随机的词性嵌入映射S中词的词性得到词性特征表示。然后,对于S中的每个词使用随机的字符嵌入映射其字符表示,然后对其字符表示使用字符级别的LSTM捕获词的拼写和字符级别的上下文特征,以此获得序列S的字符特征
将上述的Xs,Xw,Xp,Xc进行向量维度的拼接后,然后通过双向的LSTM 进行语义融合并进一步提取双向的上下文信息,得到融合多特征的句子的编码表示,形式化如下:
上述编码过程中所使用的LSTM 是一种特殊的循环神经网络(recurrent neural network,RNN),它具有能够学习较长距离依赖的优势。
一个LSTM 单元的组成包括输入门、遗忘门、更新门和细胞状态,LSTM 单元的结构如图3 所示。LSTM的计算公式如下所示:

图3 LSTM单元的结构Fig.3 Structure of LSTM cell
其中,σ是Sigmoid 函数,可以将数值归一化到为0 到1之间。it对应输入门,控制细胞状态更新值(由当前输入xt和前一个隐藏态ht-1中所得到)中的哪些信息保留在当前细胞状态中。ft对应遗忘门,控制遗忘之前细胞状态ct-1中的哪些信息。ot对应输出门,控制当前细胞状态ct的哪些信息在当前输出。
2.2 跨度生成
先识别可能的实体跨度开始,然后从可能的开始位置生成可能的实体跨度。首先对文本序列S中的每个词进行预测:
其中,MLPs为多层感知机(multilayer perceptron),输出将位置i预测为实体开始边界的预测概率。Sigmoid层将预测值进行归一化。当大于一定的阈值,即认为位置i是实体跨度的开始位置。
通过对每个位置预测,得到可能的实体开始边界集合(b1,b2,…,bm)∈B,m是预测出的开始边界的数量。对于每个可能的开始位置,生成不超过预先设置的最大实体长度M的跨度。Ei表示以bi为开始的跨度集合,其中每一个跨度用两个索引进行表示eij=(bi,bi+j)∈Ei,j=(1,2,…),分别表示其开始和结束位置。将跨度范围内的对应的单词的编码向量进行最大池化,得到跨度的向量表示:
2.3 基于注意力机制的跨度解码
在得到可能的实体跨度集合后,需要对每个跨度进行验证并预测其类型。不同于传统方法对每一个跨度分开独立进行验证,本文以解码的方式,使用解码器在已知之前预测的实体信息的前提下来对当前跨度的类型进行预测。解码器按先后顺序对同一开始的跨度集合进行验证,将预测到实体信息利用LSTM细胞单元进行传递,并利用注意力机制关注于已预测的实体信息以获得具有实体级别语义来支持当前跨度的检测。
解码器由一个用于传递实体预测信息的隐藏层维数为d的LSTM细胞单元,和一个用于跨度分类的多层感知机组成。在时间步数为t时,对从第t个跨度开始bt对应的跨度集合Et进行预测。在每个时间步内,通过已预测的跨度信息zt-1,上一步LSTM细胞单元的隐藏状态和跨度表示对跨度类型进行预测。zt-1用来表示之前预测的实体信息,计算公式如下:
例如:人教版实验4-5干燥的氯气能否漂白物质的实验,探讨次氯酸的漂白性与二氧化硫漂白性的区别,可把这些实验过程中的现象进行录像,制作成微课.使用微课视频教学,学生可以直观观察演示操作,掌握操作技能,而且实验现象清晰可见,形象生动,便于学生理解记忆,而且上课不管哪个位置的学生都能仔细观察实验过程.
其中,ri表示当t=i时所预测出的实体信息。当t=1时,zt-1初始化为全0。
2.4 训练目标
将实体开始边界的预测值和真实标签的交叉熵作为实体开始边界检测的损失,公式如下:
然后同样使用交叉熵作为跨度分类的损失函数,公式如下:
最后将两个任务的损失相加作为整个模型损失函数:
3 实验及分析
3.1 实验设置
3.1.1 数据集
本文在具有嵌套命名实体标注的公共英文数据集ACE2005 和GENIA 上进行实验。ACE2005 英文和GENIA数据集的实体统计结果如表1所示。
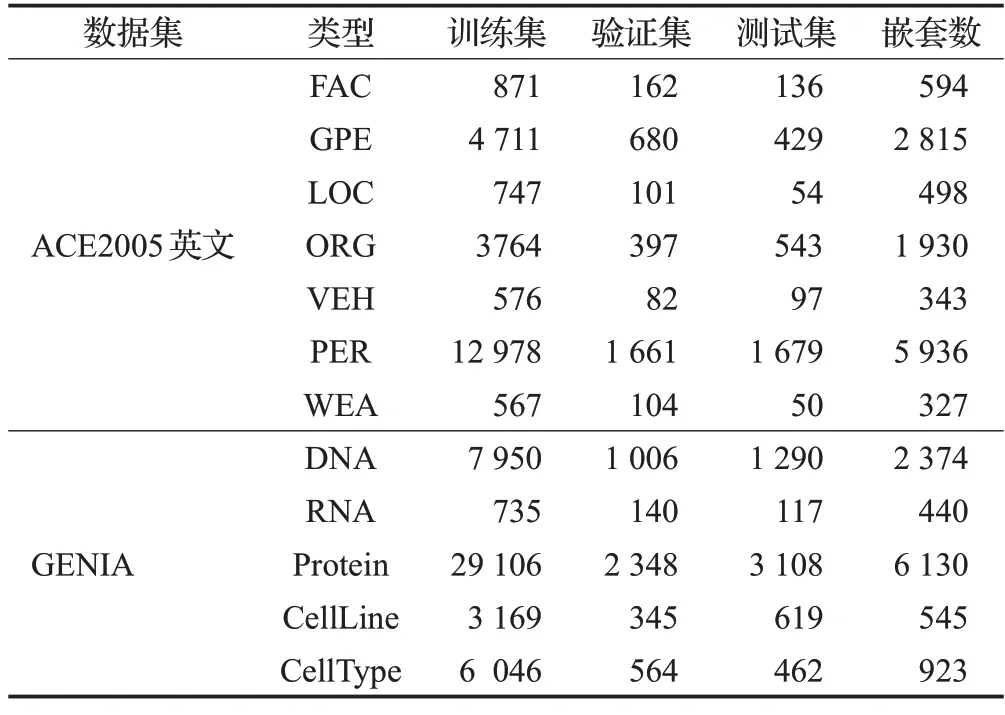
表1 对ACE2005英文和GENIA数据集的统计Table 1 Statistics on ACE2005 English and GENIA datasets
(1)ACE2005 英文数据集[21]:具有7 类实体,包括了人(PER)、地理位置(LOC)、交通工具(VEH)、政治实体(GPE)、武器(WEA)、组织(ORG)、设施(FAC)。本文跟随之前大多数人所采用的Lu 等人的数据划分方式,将数据集按80%∶10%∶10%的比例划分为训练集、验证集和测试集。
为确定在实验中所需要设定的最大实体长度M,对ACE2005英文和GENIA数据集上的不同长度的实体数量进行了统计,统计结果如图4所示。
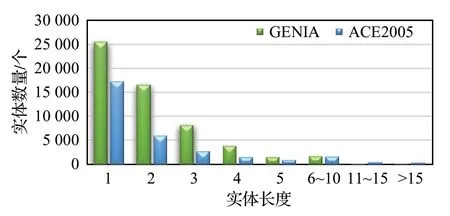
图4 不同长度的实体数量统计Fig.4 Statistics on number of entities of different lengths
统计结果显示,在ACE2005 英文和GENIA 数据集上实体长度越长其对应实体数量越少,绝大多数实体长度在实体在15以内。
为验证模型在中文数据集上的有效性,文本还选用ACE2005 中文数据集进行实验。ACE2005 中文数据集与ACE2005 英文数据集具有同样的实体类型标注,并且同样按8∶1∶1的比例对数据集进行划分。
3.1.2 实验指标
实验采用精确率P(Precision)、召回率R(Recall)和F1分数作为评价指标,计算公式如下:
其中,TP是正确识别的实体个数,FP是识别错误的实体个数,FN是未识别出的正确实体个数。
3.1.3 实验参数
本文的实验所使用的显卡型号为NVIDIA A100,编程语言为Python3.8,深度学习框架为pytorch1.8。编码部分所使用的预训练词嵌入来自于FastText[23],维数dw为300。所使用的词性嵌入和字符嵌入通过随机初始化获得,维数dp和dc均为100。ACE2005英文数据集所使用的词性标注来自于第三方工具StanfordCorenlp[24],GENIA数据集的词性标注从原始数据集获得。ACE2005英文数据集上使用的预训练语言模型为谷歌官方提供的bert-large-cased 模型[25],GENIA 上使用的预训练语言模型为biobert-large-cased模型[26],其隐藏层维数dz均为1 024。在ACE2005 中文数据集上由于不能提供字符、词性、单词等特征嵌入,编码部分仅用了基于预训练语言模型输出的上下文向量,使用的预训练语言模型为bert-base-chinese,隐藏层维数为768。
本文所使用的MLP为3层,隐藏层维数为输入维度的一半,使用ReLU 作为激活函数,并具有dropout 层。实验中的主要超参数设置如表2所示。
表2 中,Start Threshold 是实体开始边界检测的阈值,为了尽可能找全实体的边界设置得较小。并且,设定最大实体长度M是为降低训练和预测时的计算复杂度,在进行评估时不会过滤长度大于M的正确实体。
3.2 实验结果分析
3.2.1 英文数据集上的实验
实体开始边界的检测结果如表3 所示。实验结果表明,在ACE2005英文数据集上边界检测性能较好,F1值为94.11%。但在GENIA数据集上,检测性能不佳,其原因可能是GENIA 上的实体多数是生物医学专有名词,相当一部分实体的结构较为复杂和生僻且边界特征不明显,所以其边界检测较为困难。

表3 实体开始边界检测结果Table 3 Entity start boundary detection results 单位:%
在ACE2005英文和GENIA上的实体识别结果分别如表4 和表5 所示。实验结果表明,本文提出的方法能够有效识别命名实体。但在ACE2005英文数据集上对LOC 类型实体的识别性能较差,原因可能是LOC 实体在数据集中出现较少,缺乏相应的学习样本,模型对该类型实体的学习不够泛化。在GENIA 上,受限于边界检测性能不佳,最终的实体识别性能表现一般。

表4 在ACE2005英文上的实体识别结果Table 4 Entity recognition results on ACE2005 English 单位:%

表5 在GENIA上的实体识别结果Table 5 Entity recognition results on GENIA 单位:%
为验证本文模型的优势和有效性,与其他在英文数据集上表现先进的模型进行了对比,如表6所示。

表6 在英文数据集上与其他模型进行对比Table 6 Comparison with other methods on English datasets 单位:%
对于表6中所比较的方法,本文均列出他们所报告的最佳性能。其中,文献[6]、[7]、[9]、[11]为基于序列的方法,文献[12]、[13]为基于超图的方法,文献[17]、[18]、[20]为基于跨度的方法,具体介绍详见第1 章相关工作部分。对于本文的跨度解码方法,展示了三种不同解码结构的结果:“正向”是在句子层面上从前往后进行解码得到的结果,“反向”是从后往前进行解码的结果,而双向是同时进行前向解码和后向解码以后,将两次得到的预测概率(公式(22)所示)取平均值所得到的结果。实验结果表明,本文所提出的跨度解码方法具有明显的优势,比之前的方法在ACE2005 英文和GENIA 上分别将F1值提高了0.45和0.14个百分点。并且正向解码召回率较高,反向解码的精确率较高,而结合了正向和反向解码的双向解码取得最好的F1值。
3.2.2 中文数据集上的实验
为验证本文模型对中文嵌套命名实体识别的有效性,在ACE2005 中文数据集上进行了实验并与其他用于中文嵌套命名实体识别的模型进行对比,结果如表7所示。其中“ShallowBA”模型是使用了边界信息的跨度分类模型,它采用CRF识别实体的开始和结束边界并将边界组合为候选实体,然后使用最大熵分类器对实体候选进行分类[27]。“Cascading-out”模型对每个实体类型使用独立的BERT-Bi-LSTM-CRF模型来进行识别,如果遇到相同类型的嵌套实体,则只识别最外层的。“Layeringout”模型用两个独立BERT-Bi-LSTM-CRF 模型分别识别最内层和最外层的实体。“NNBA”模型是采用了先进的神经网络模型BERT,bi-LSTM 等对“ShallowBA”进行改进的版本[4]。实验结果表明,本文所提出的模型(双向)在对中文嵌套命名实体识别方面也具有显著优势,比以往的方法在F1分数上提升了4.32个百分点。
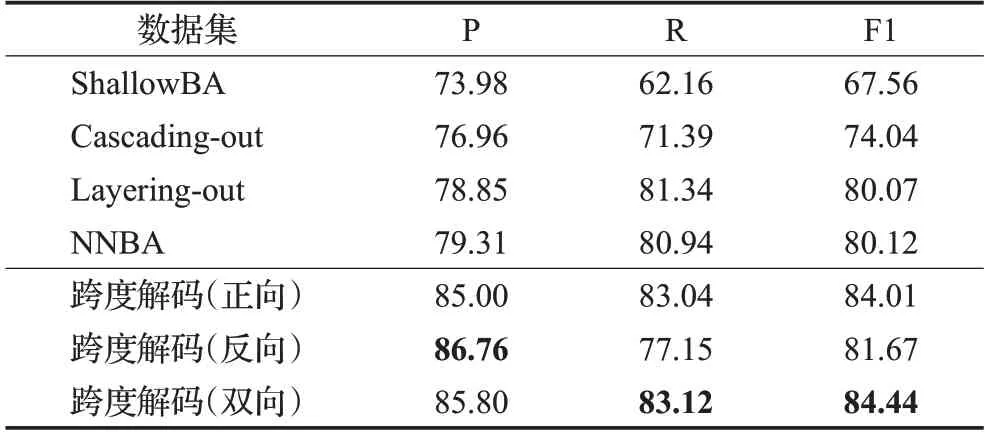
表7 在ACE2005中文数据集上与其他模型进行对比Table 7 Comparison with other methods on ACE2005 Chinese 单位:%
3.3 消融实验
为验证本文所使用的基于注意力机制的解码器的有效性,在ACE2005英文上进行了消融实验,实验结果如表8所示。默认是本文所提出模型(正向结构),在移除注意力机制后F1 分数下降了0.21 个百分点,在完全移除解码器后F1 分数下降了0.36 个百分点,这证明了基于注意力机制的解码器的有效性。
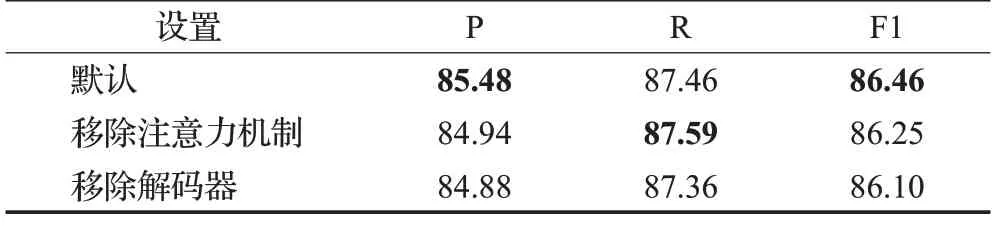
表8 在ACE2005英文上的消融实验结果Table 8 Results of ablation experiments on ACE2005 English 单位:%
解码器将已预测实体的跨度语义信息用于计算上下文注意力分数,并且作为关键的语义信息通过LSTM单元的进行传递,这样有效利用和传递了实体的跨度语义信息,使得预测的精确率明显提升。但实验结果也表明,传递和利用实体跨度语义的机制仍有较大的改进空间,探究更有效地传递和利用跨度语义的机制,可以更好地学习实体间依赖,促进命名实体识别性能的提升。
4 结语
本文提出了一种基于跨度解码的嵌套命名实体识别方法,首先将句子的不同的特征信息进行编码,然后识别开始边界,最后以解码的形式逐一识别同一开始的嵌套实体,并在解码过程中传递实体信息并利用注意力机制关注与已预测实体相关的上下文信息,这有效缓解了传统跨度分类方法对实体间依赖存在忽视的问题。实验结果表明,该方法比传统的基于跨度的方法在识别性能上有明显的优势。
在未来的工作中,将尝试捕获更加全面的实体间的依赖信息,比如现阶段还未考虑到的同一开始的不同实体之间的依赖关系。并且,未来将探究更加充分有效地利用和传递跨度语义的机制,以更好地学习实体间的依赖关系。
猜你喜欢
建材发展导向(2022年14期)2022-08-19
系统工程学报(2021年4期)2021-12-21
西部交通科技(2021年9期)2021-01-11
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
上海建材(2018年4期)2018-11-13
数学物理学报(2017年5期)2017-11-23
计算机工程(2014年6期)2014-02-28
河南科技(2014年24期)2014-02-27
河南科技(2014年23期)2014-02-27
