
基于小样本学习的口语理解方法综述
2024-01-22 10:58郑国风徐贞顺林令德
郑州大学学报(工学版) 2024年1期
刘 纳, 郑国风, 徐贞顺, 林令德, 李 晨, 杨 杰
(1.北方民族大学 计算机科学与工程学院,宁夏 银川 750021;2.北方民族大学 图像图形智能处理国家民委重点实验室,宁夏 银川 750021)
近年来,对话式人工智能(dialogue artificial intelligence,DAI)在工业、医疗、金融和教育等领域受到广泛的关注。DAI是一种能够进行自然语言对话的人工智能技术,通过将自然语言处理(natural language processing,NLP)、语音识别(automatic speech recognition,ASR)[1]、语义理解和对话理解等技术应用到智能语音对话系统中,以实现实时有效的人机交互。根据DAI的应用场景,将其划分为面向任务的对话系统(task-oriented dialogue,TOD)和开放域对话系统(open-domain dialogue,ODD)两大类。其中,TOD主要解决针对某一具体领域的问题。例如,医疗行业部署智能对话系统完成病情分析、药品信息查询和提供诊疗方案等任务;教育领域利用智能对话系统实现教学体验提升、定制学习方案和获取学习资源等业务;金融领域则利用智能对话系统提供账户余额查询、定制理财方案等服务。ODD需要实现与人类建立情感联系,进行共情对话。与TOD相比,ODD的对话主题更为开放、覆盖范围更广、实现难度更大,是对话式人工智能亟待发展的研究方向之一。
2022年11月,OpenAI公司发布了全新的对话式通用人工智能工具即ChatGPT,受到了全球各界的广泛关注。ChatGPT产品的落地标志着大规模预训练语言模型(pre-train language model,PLM)已经具备了通用人工智能的特征。在ChatGPT产品问世之后,OpenAI公司于2023年3月发布了最新的语言模型GPT-4,其性能与ChatGPT最初使用的GPT-3.5模型相比有了巨大的提升。在口语理解方面,模型的理解能力、回答的可靠性有了显著提高。
中国类似于ChatGPT的研究也正在进行,例如百度公司推出了基于文心大模型的产品文心一言;复旦大学发布了中国第一个对话式大型语言模型MOSS;在教育领域网易公司将类ChatGPT技术进行落地研发等。目前,中国在通用人工智能领域的发展与外国相比还有很大的差距,但发展速度快,与国际领先水平的差距会随着对大规模预训练语言模型的持续研究而逐渐缩小。
目前针对口语理解任务的研究综述较多,2020年,Louvan等[2]根据神经网络结构特征对口语理解任务的方法进行归纳。2022年,Weld等[3]针对如何提高联合模型的能力、如何捕获深层次语义和如何提高模型的泛化性3大问题,对前人的工作进行总结。但以上大多数研究都采用非小样本学习的方法,对研究者来说,获取大量有标注的训练样本代价非常昂贵,并且对于新出现的意图领域,带标注的样本较少,获取十分困难。与之前的工作相比,本文主要对在小样本场景中口语理解任务的建模方式进行介绍,具有较强的针对性。
本文首先简要介绍了在非小样本场景中,口语理解任务建模的经典方法;其次,重点阐述了在小样本口语理解任务中为解决训练样本受限问题而提出的基于模型微调、基于数据增强和基于度量学习3类最新研究方法,并对不同方法的优缺点进行全面的比较与总结归纳;最后,对小样本口语理解领域存在的问题与挑战进行分析。
1 相关工作
口语理解(spoken language understanding, SLU)是对话式人工智能系统的核心任务之一。它的目标任务是提取用户输入的话语中所包含的意图,即用户的行为,并给予一定的反馈。2011年,Tur等[4]将口语理解任务划分为意图分类和槽位填充两个子任务。如表1所示,在槽位填充任务中采用的是BIO标注方案,通过意图分类识别用户的具体行为。
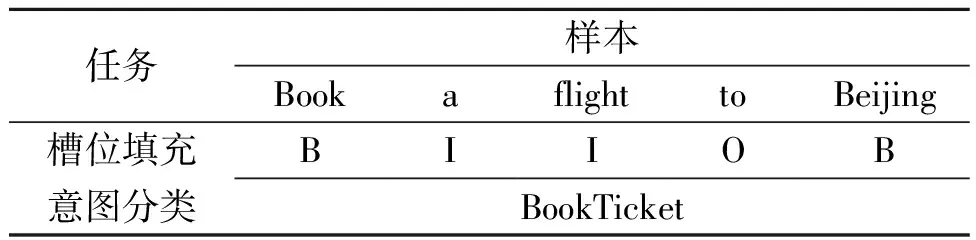
表1 口语理解任务举例Table 1 Examples of spoken language understanding tasks
根据两个子任务之间的关联程度将非小样本场景下的口语理解相关研究划分为4类:①无关联建模,意图分类与槽位填充任务分别单独建模;②隐式关联建模,意图分类与槽位填充联合建模,获取两个子任务之间的全部共享信息;③显式关联建模,意图分类与槽位填充联合建模,获取两个子任务之间有用的共享信息;④基于预训练范式建模,以上下文感知为核心,捕获更深层次的语义信息。
1.1 无关联建模
无关联的建模方式将口语理解任务划分为意图分类和槽位填充两个子任务单独建模,模块化设计让每个模型结构简单、灵活,并且可以在不修改其他模块的情况下对特定的任务进行调整。
2013年,Bhargava等[5]对口语理解任务单独建模进行了早期尝试。利用支持向量机(support vector machine, SVM)对意图分类任务建模,利用条件随机场(conditional random field, CRF)对槽位填充任务建模。同时结合上下文信息,将前一个话语中的知识合并到当前话语中,显著提高了意图分类与槽位填充任务的性能,这是口语理解任务无关联建模的开端。
随着深度学习的发展,循环神经网络(recurrent neural networks, RNN)表现出强大的语言建模能力。2015年,Mesnil等[6]采用RNN对槽位填充任务进行了深入研究,比较了RNN的几种变体,其中包括Elman-type网络和Jordan-type网络。在ATIS数据集上,两种网络结构的性能都优于CRF模型。2017年,Lin等[7]认为基于RNN的递归模型在所有的时间步中携带样本的语义信息非常困难,并且会造成灾难性遗忘的问题,因此对传统的句子编码方式进行改进,设计双向LSTM结构,使用自注意力机制替换传统的最大池化或平均池化,从而有效减少了RNN的长期记忆负担。
卷积神经网络(convolutional neural network, CNN)最初应用在图像领域中,后来研究者将CNN应用在语义融合、句子建模等NLP任务中,同样取得了非常出色的效果。2014年,Kim[8]在word2Vec基础上添加了卷积神经网络结构,使用词向量嵌入与CNN相结合的方式进行文本分类任务。CNN利用不同大小的卷积核来提取句子中的关键信息,更好地建立局部语义相关性。但其存在的缺陷是难以提取对于距离大于卷积核窗口长度的特征,同时使用最大池化仅保留提取特征向量的最大值,导致部分重要的位置编码信息丢失。针对上述CNN的缺陷,2018年,Zhao等[9]开启了使用动态路由的胶囊网络进行文本分类任务的早期探索。胶囊网络利用神经元向量替代传统神经网络的单个神经元节点,显著改善了CNN空间不敏感的问题。利用动态路由算法调整子胶囊与父胶囊之间的权重,解决了使用最大池化算法丢失位置编码信息的问题。
无关联的建模方式存在的缺陷是需要对每个任务进行单独建模,模型结构整体较为庞大。各任务的模型之间没有数据或功能共享,易产生数据碎片。在实际的应用场景中,某些意图和槽位信息会在多个领域之间共享,无关联的建模方式无法利用两个任务之间的共享知识,导致用户在与系统交互过程中达不到满意的效果。为解决上述问题,后续工作提出了联合建模的方法。
1.2 隐式关联建模
联合建模思想的提出,极大地促进了口语理解领域的研究。但在早期的工作中,大多数采用隐式联合建模的方式。仅通过共享编码器(shared encoder)捕获意图分类和槽位填充两个子任务之间的共享特征,之间没有进行任何的显式交互。
2016年,Zhang等[10]首次提出将意图分类与槽位填充任务进行联合建模,并首次将RNN结构引入到意图分类任务中。由于RNN对于捕获长期依赖关系十分困难,同时会带来梯度消失和梯度爆炸等问题,因此选择基于RNNs改进的门控循环神经网络GRU[11]作为模型的基础架构。该联合模型的缺陷在于需要等待输入序列全部输入到模型之后才能开始后续的意图分类任务,实时性差。在实际的SLU应用中,用户对系统的实时性要求通常较高。为解决上述问题,Liu等[12]提出基于LSTM的联合SLU实时模型。由于LSTM具有较强的捕获词序列中长期依赖关系的能力,因此使用LSTM作为基本的RNN单元。通过对整个序列上的RNN单元输出取平均值作为样本的表示向量,利用最后一个RNN单元输出预测的意图类别。对当前时间步以及之前时间步的隐藏状态建模槽位标签之间的依赖关系,每个时间步以单个词语作为输入,输出对应的槽位标签。Liu等[13]借鉴注意力机制在机器翻译领域的成功经验,首次提出将基于注意力机制的循环神经网络模型应用在联合意图分类和槽位填充任务中。与机器翻译不同的是,在槽位填充任务中,输入的文本与输出的标签之间具有一一对应的关系,因此采用Seq2Seq结构,如图1所示。编码层使用双向LSTM,可更好地捕获长期依赖关系。解码层使用LSTM并添加注意力机制预测槽位标签,在最后的隐藏层上通过前馈神经网络输出意图类别。
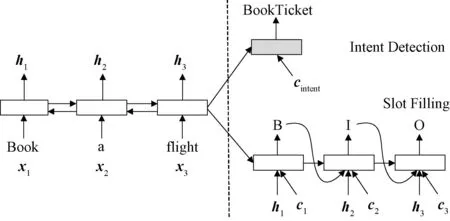
图1 Seq2Seq建模口语理解任务结构图Figure 1 Seq2Seq modeling spoken language understanding task structure diagram
上述隐式联合建模的方式在一定程度上利用了意图分类和槽位填充两个任务之间的共享信息,极大地提高了口语理解的准确性。但缺陷在于隐式联合建模缺乏噪声过滤机制,两个子任务的噪声会在联合模型中进行传播,导致模型性能受限。为解决上述问题,后续工作提出了显式关联建模的方法。
1.3 显式关联建模
为解决隐式关联建模中的噪声传播问题,一些工作利用显式联合建模的方法,通过添加类似于门控机制的方式,选择性地获取意图分类和槽位填充任务之间的共享信息。
图2 SGM-SLU结构图Figure 2 Structural diagram of the SGM-SLU
2019年,Qin等[15]认为Goo等[14]提出的仅依靠门控机制获取意图信息是有风险的,并且意图信息引导槽位填充任务具体过程的可解释性很差。因此,提出以堆栈作为数据结构的传播模型,将意图信息直接作为槽位填充任务的输入,提高了模型的可解释性。Chen等[16]提出了一种具有条件随机场和先验掩码的多头自注意力联合模型。该模型使用多头局部自注意力机制来提取共享特征,使用掩码门控机制来建立意图分类和槽位填充两项任务输出的相关性,并使用CRF约束槽位填充任务的输出,充分利用了两个任务之间的语义关系。
基于以上工作可以发现传统基于RNN的方法只能处理一定的短期依赖,无法处理长期依赖问题。后来基于LSTM和BiLSTM的模型结构在一定程度上突破了序列模型的局限性,但固有的顺序性限制了样本的并行化训练。显式联合建模的方式进一步利用了两个任务之间的共享知识,但模型无法捕获更深层次的语义信息。预训练模型的发展给口语理解任务带来了新的研究思路。
1.4 基于预训练范式建模
自然语言处理领域中的预训练研究思路最早可以追溯到word2Vec模型的提出。预训练的核心在于使用大量的训练数据,从中提取共性特征,帮助NLP下游任务简化其训练过程。早期的预训练模型专注于词向量编码,模型的特点是上下文无关,模型只知“上文”不知“下文”,缺乏双向交互能力,代表性的工作包括word2Vec、GloVe等。近几年的预训练模型以上下文感知为核心,共享知识在上下文之间进行双向流动,代表性的工作包括ELMo、BERT、GPT等。
2019年,Chen等[18]首次将预训练模型应用到口语理解任务中,使用BERT预训练模型对意图分类和槽位填充任务进行联合建模,提出了JointBERT模型。模型结构如图3所示,BERT预训练模型的下游任务之一是文本分类,因此很容易就能扩展到意图分类任务中。将[CLS]标签的输出替换成意图分类器,为后续的标签添加序列标签器,输出槽位最佳的标签匹配序列。槽位标签的预测取决于上下文单词的预测,由于结构化预测模型可以提高槽位填充的性能,在JointBERT模型的基础上添加CRF来对槽位标签之间的依赖关系进行约束建模。JointBERT模型充分利用两个子任务之间的联系,捕获两个任务之间的共享知识。
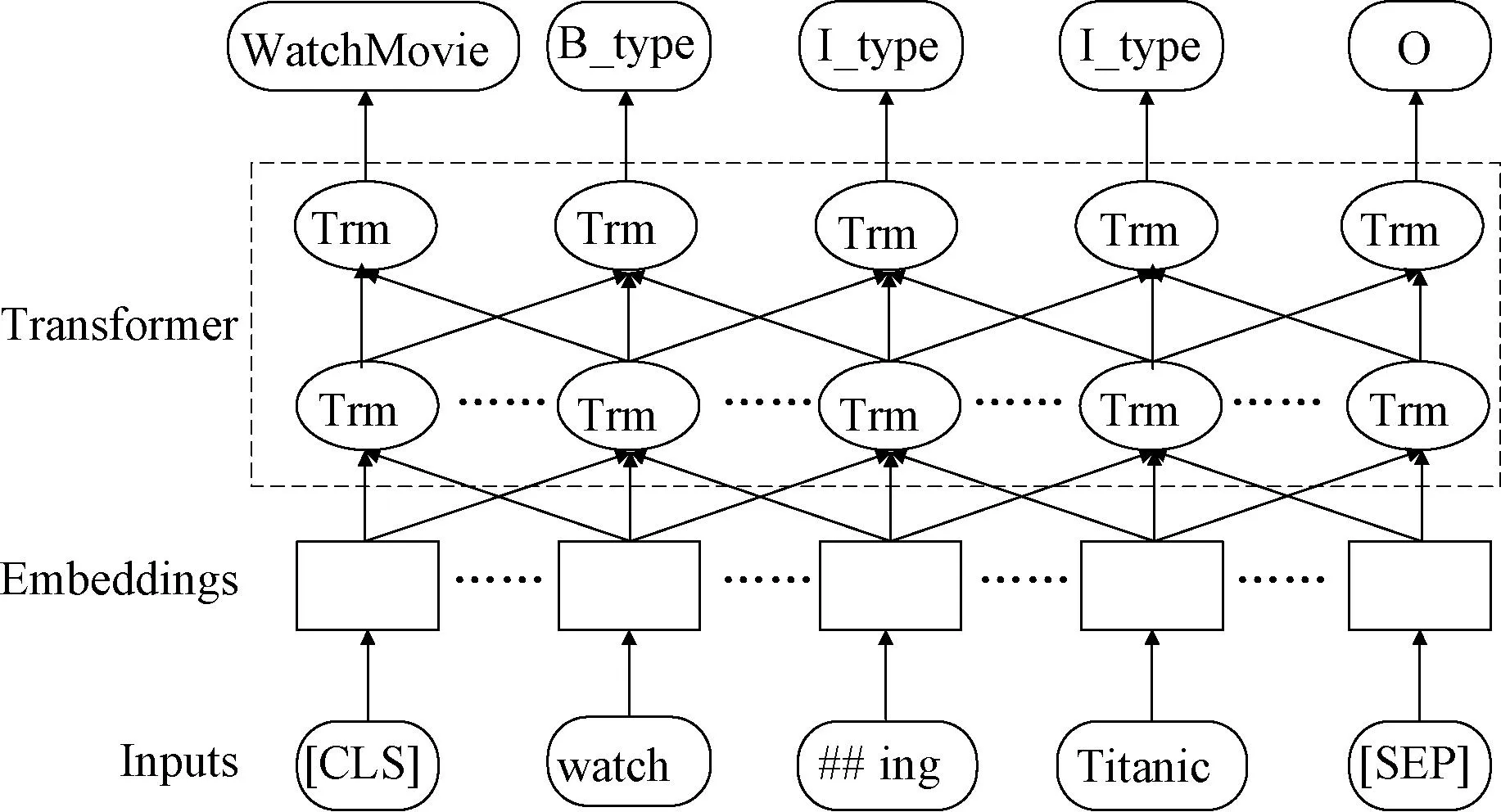
图3 JointBERT模型结构图Figure 3 JointBERT model architecture
2020年,Qin等[19]认为仅识别对话中的显式意图并不能捕获用户的全部语义,对话中的隐式意图是更为重要的语义获取来源,因此提出一种协同交互式图注意力网络(Co-GAT)来联合对话显式意图分类和隐式意图分类这两项任务。模型的核心是设计一个协同的图交互层,可以同时获取上下文信息和交互信息。这是首次将上下文信息和交互信息结合进行联合显隐式意图识别的研究。
以上基于预训练语言模型的建模方式极大地促进了口语理解领域的发展。但通过对这些预训练模型性能的评估可以发现,目前基于预训练的方法并不能从根本上解决现有模型可解释性弱、泛化能力差、推理能力不足等问题,在深层次语义获取与理解方面还远远落后于人类的认知水平。同时,如何对大规模预训练语言模型进行压缩、降低参数量是一个亟待解决的问题。
2 小样本学习
早在2006年,Li等[20]首次提出了小样本学习的概念。小样本学习致力于解决数据受限的深度学习问题,通过对少量样本甚至一个样本的训练使模型性能达到甚至超越大数据深度学习的效果。在生活中,有很多场景都属于小样本学习的范畴,例如儿童仅通过几张绘图卡片就能认识海洋生物,依靠少量的样本完成自主推理的过程。受到人类快速学习能力的启发,早期的研究人员将小样本学习方法应用在图像领域,解决训练样本数量受限的问题。2015年,Koch等[21]设计孪生神经网络解决了one-shot图像分类问题。Zhang等[22]在关系网络的基础上,通过数据增强的方法解决了小样本图像分类问题。在自然语言处理领域,小样本学习发展较为缓慢,原因是图像特征相比于文本特征更为客观,在少量样本的情况下,提取文本特征更为困难。
近年来,随着预训练模型的发展,小样本学习在自然语言处理领域也有了一些突破。2018年,Chen等[23]使用对比学习框架解决小样本文本分类中的区分表示和过拟合问题。Jian等[24]使用伪标签克服小样本学习固有的数据稀缺问题。以上方法在一定程度上缓解了由于数据过少无法支撑模型学习到足够的参数,在训练集上容易过拟合的问题。但大多数工作只专注于在已知的数据集上提高模型的学习上限,对于口语理解任务来说,注重的是模型对自然语言的理解与认知,而非学习浅层次的语义,这对模型的知识获取能力提出了更高的要求。
诸葛玉头疼欲裂,他又拿起了那把剑,运足了功力想要刺过去,可这个时候赵白又勾起唇角对他微微一笑,他仿佛听到赵白在对自己说:“诸葛玉,原来你也不过如此!从此以后这天下第一剑客就是我赵白了!”
2.1 问题定义
在通常情况下,意图分类被看作是文本分类任务,将文本分类到指定的某个或者多个类别中。从数学定义上看,定义包含m段文本的集合T={t1,t2,…,tm}和包含n个类别标签的集合C={c1,c2,…,cn}。模型最终产生由集合T到集合C的一对一或一对多映射关系。槽位填充被看作是序列标注任务,定义输入样本X={x1,x2,…,xn},xi表示样本中的某个字词,模型输出Y={y1,y2,…,yn},yi表示槽位标签。在小样本场景中,假设支持集S包含N种意图类别,每种意图类别由K个样本组成,则将该任务称为N-wayK-shot意图分类任务。
在近些年的研究中,基于小样本学习的口语理解方法主要分为3类:①基于模型微调的方法,将在大规模数据集上训练的模型迁移到目标任务中进行微调;②基于数据增强的方法,通过增强样本空间特征,提高模型的泛化能力;③基于度量学习的方法,利用度量函数计算样本之间的相似性。
2.2 基于模型微调的小样本口语理解
2015年,Dai等[25]首次提出了对语言模型进行微调的思想,模型需要先在大规模数据集上从0开始预训练,其次在小样本目标数据集上对全连接层或顶端神经网络结构的参数进行微调。该时期的微调模型经过海量数据的预训练才能表现出良好的性能,严重限制了模型的适应性。2018年,Howard等[26]提出了一种通用微调语言模型(universal language model fine-tuning,ULMFiT)。ULMFiT模型训练主要由3个步骤组成:①在通用领域语言模型中进行预训练;②在目标任务语言模型中进行微调;③在目标任务分类器上进行微调。与其他模型的区别在于ULMFiT通过判别微调让模型的不同层学习不同的学习率。对于模型的同一层,随着迭代次数变化,使用倾斜三角学习率让参数进行自适应。判别微调与倾斜三角学习率机制让模型在小样本数据集上加快收敛速度,同时学习到更加符合目标任务的知识。
在BERT模型提出之前,传统的双向语言模型是将两个单向语言模型进行组合,而BERT模型是第一个基于微调的表示模型,在大型通用语料库中利用掩码语言模型(masked language model,MLM)和下一句预测任务(next sentence prediction,NSP)进行预训练。它使一系列NLP任务实现了当时最优的性能,表现出微调方法的巨大优势。2019年,Sun等[27]在BERT模型的基础上,研究如何通过微调BERT模型以解决长文本预处理、灾难性遗忘、低资源学习等问题。类似的工作还有2020年Mohammadi等[28]比较了微调不同层结构对BERT模型性能的影响,提出了5种不同的微调结构,如图4所示。
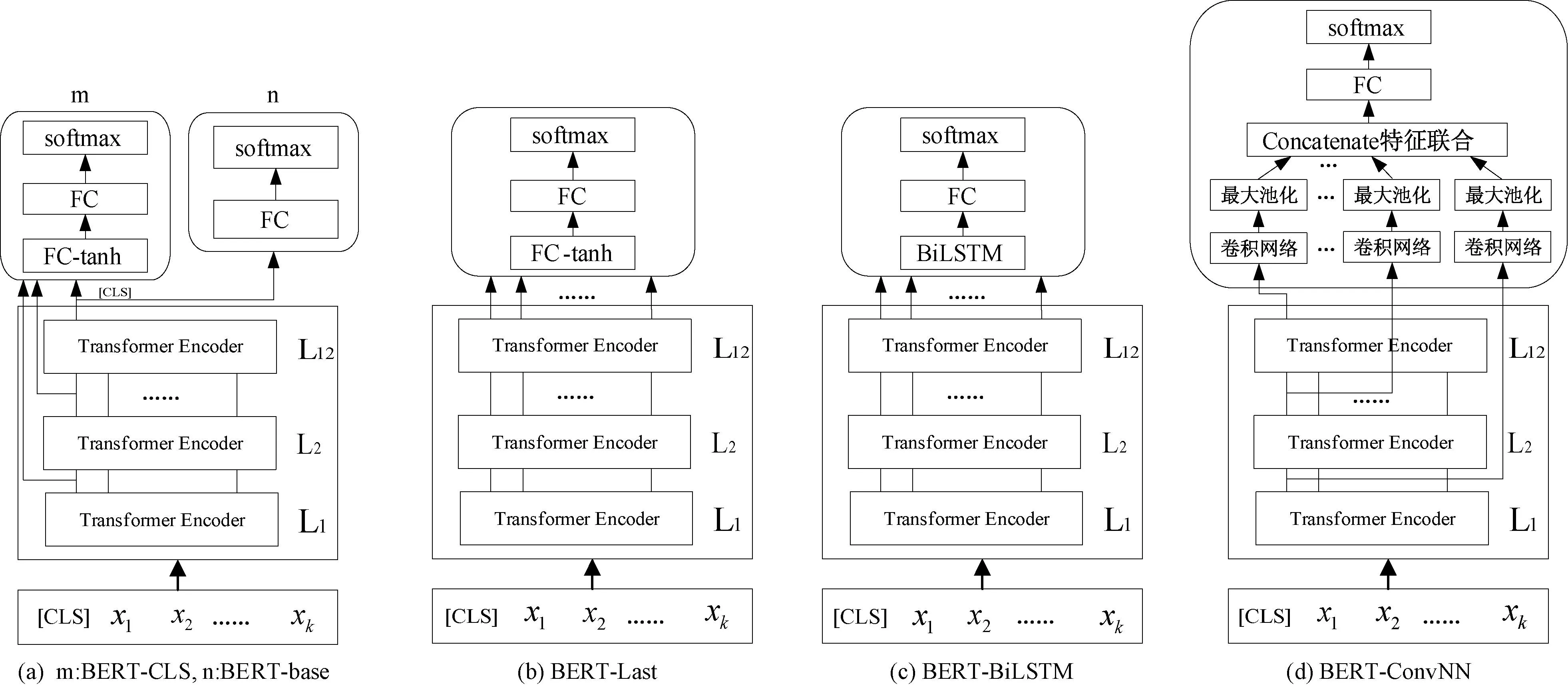
图4 5种BERT模型微调结构图Figure 4 Diagram of five fine-tuned BERT models
如表2所示,在30k-Intent(意图分类数据集,由American Online中30 000条用户检索意图文本组成)数据集上,Mohammadi等[28]经过实验证明,BERT模型通过微调添加BiLSTM与基础模型效果相似;在BERT模型之上添加全连接层作为分类器,可以得到最优的性能;卷积神经网络虽然具有较为复杂的网络结构,但该类结构不仅无法提高模型的精度,甚至会导致模型性能降低。
相比于Mohammadi等[28]的微调模型结构,2021年Zhang等[29]用少量意图分类标注样本微调BERT模型,提出了一种新的微调模型IntentBERT。该模型的优势在于目标领域的样本即使与预训练数据差异较大,也可以直接应用在目标领域上的小样本意图分类任务中,无须对目标数据进一步微调。但IntentBERT具有较强的各向异性(anisotropy),语义向量之间的余弦相似度较大,不同的语义难以分离。针对各向异性的问题,2022年Zhang等[30]利用各向同性(isotropy)技术调整语义空间,通过调整目标函数的正则化项实现对模型的微调,提出了两种正则化项:①基于对比学习的正则化;②基于相关矩阵的正则化。实验证明,两种正则化相结合的微调方式在BANKING77和HWU64数据集上能够表现出更加出色的效果。
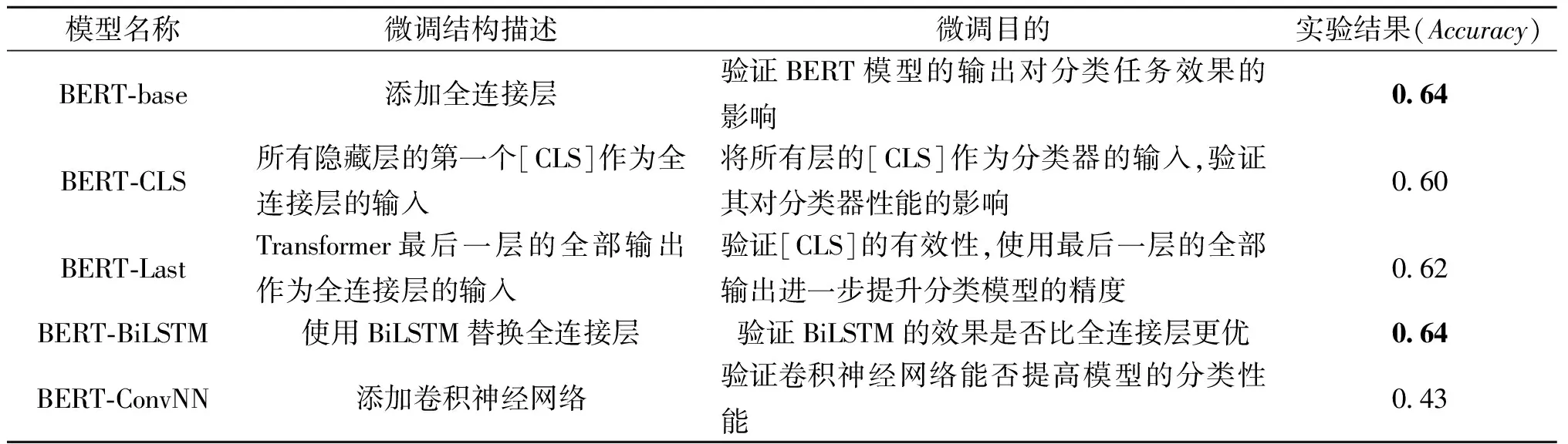
表2 5种微调模型结构对比Table 2 Comparison of five fine-tuning models
如表3所示,基于模型微调的方法思路简单,但在真实的应用场景中,预训练与微调之间的数据集和模型结构会产生显著偏差,导致微调的效果和预训练的效果会存在较大的差异性。同时,随着预训练语言模型的参数量呈现爆炸式增长,在下游任务上进行模型微调代价十分昂贵且耗时。为解决上述问题,后续工作提出了基于数据增强的方法和基于度量学习的方法。

表3 基于模型微调的小样本口语理解模型对比Table 3 Comparing few-shot spoken language understanding models with model fine-tuning
2.3 基于数据增强的小样本口语理解
数据增强是通过增加样本的数量或空间特征,从而提高模型的泛化能力,缓解数据不足的问题。现阶段,NLP领域的数据增强方法主要有:随机噪声注入、词汇替代、回译等。
2016年,Kurata等[31]首次将数据增强的思想引入到对话口语理解任务的模型中,利用编码器-解码器架构对训练样本中的数据进行重构。在数据增强的过程中,对编码器的输出隐藏层添加随机噪声来产生不同的样本,该方法的缺陷是增强产生的单个样本与其他样本之间没有建立关系。2018年,Hou等[32]针对该缺陷提出了一种新的数据驱动架构,对训练数据中相同语义框架的样本之间的关系进行建模。为了让生成的样本具有多样性,以Seq2Seq模型作为架构的核心,在样本表示中添加多样性等级队列(diversity rank),提升了生成样本的多样性并过滤相似的样本,显著提高了语言模型在标记数据稀缺领域的性能。
数据生成的方法在一定程度上避免了模型过拟合,生成的样本扩充了训练样本的数量,但缺陷在于模型会消耗额外的内存来生成噪声数据。2019年,Kim等[33]针对该缺陷提出了基于槽位添加噪声的方法,将数据转换成具有相同上下文、但不同槽位标签的短句来扩充数据。具体而言,对输入的训练数据进行噪声处理后,训练数据转变为包含噪声的嵌入向量,接着使用上下文作为神经网络的输入。模型在每一步训练中使用不同的噪声数据,由于数据增强在相同的嵌入空间中执行,因此不需要花费额外的内存空间。
2019年,Zhao等[34]提出构造原子模板(atomic templates)进行数据增强。原子模板生成细粒度更好的语义样本,每一个模板由act-slot-value三元组组成。该方法的优势在于建立起act-slot-value三者之间的关系,而不是单独地对槽位或行为建模。在输入到句子生成器之前,用自然语言处理对话行为,以便生成器能够理解,提高了句子生成器的领域自适应能力。原子模板是在句子级上进行创建,减轻了人为创建模板的工作量。
为了提高口语理解模型的可变性和准确性,2021年,Peng等[35]提出基于预训练语言模型的数据增强方法,将在预训练阶段学习到的语法和语义融合到特定领域样本生成的过程中,该数据增强框架对生成的样本语义可控性更强。Qin等[36]基于预训练模型提出一种新的数据增强框架CoSDA-ML,用于生成多语种code-switching数据微调mBERT模型。该模型的主要思想是通过融合上下文信息来将源语言和多个目标语言的表示进行对齐。为了验证所提出的动态增强机制的有效性,与静态增强方法进行比较。模型的优势在于动态采样允许模型将更多的单词表示在多种语言中进行更紧密的对齐,同时对语言的依赖性较低,与mBERT模型相比,在各项NLP任务上的性能都有显著提高。
2022年,Sahu等[37]提出使用预训练语言模型生成意图样本,对任务进行数据增强。该方法的缺陷在于未考虑到生成样本的质量,模型可能会在低质量的生成样本上过拟合,同时生成的样本需要进行人工标记,成本较大。为解决上述问题,2023年,Lin等[38]引入Pointwise V-information(PVI)作为衡量过滤意图分类数据的指标,提出了基于PVI的上下文数据增强方法(in-context data augmentation,ICDA),该方法首先在小部分训练数据上微调模型,接着在与已知意图相对应的样本上生成新的样本。经过实验证明,在BANKING数据集上,基于PVI的方法相比于未添加PVI过滤时意图分类准确率提高了4.45%。
对现有基于数据增强的方法进行分析和总结如表4所示。数据增强的方法通过增加样本的数量或空间特征,一定程度上提高了模型的泛化能力,但这些方法也会存在一些缺陷。例如:生成样本的质量会对模型产生影响,并且增强过程中可能会丢失一些关键信息。为了克服上述缺陷,一些工作转变研究思路,提出了度量学习的方法。

表4 基于数据增强的小样本口语理解模型对比Table 4 Comparing few-shot spoken language understanding models with data augmentation
2.4 基于度量学习的小样本口语理解
目前,基于度量学习的方法已经成为解决小样本口语理解任务的主流方法,如图5所示,其主要思想是利用度量函数计算两个样本之间的距离,从而得到它们之间的相似度。
2.4.1 原型网络
2017年,Snell等[39]为解决小样本分类问题提出原型网络(prototypical networks,PN)如图6所示。该模型的整体思想是首先通过学习一个度量空间,在该空间中用每一类样本的平均值作为该类别的样本中心,对于查询集新样本x,计算x与每一类样本中心的欧氏距离,选择距离最小的类作为查询集新样本x的最终分类。与其他的小样本学习方法相比,该模型的分类器具有较强的泛化性,同时使用样本中心表示类别,提高了模型的鲁棒性。
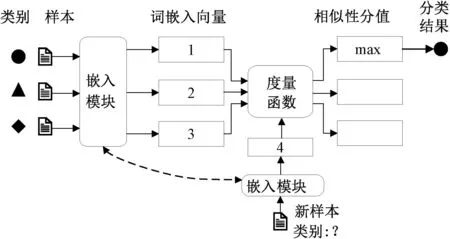
图5 基于度量学习的口语理解示意图Figure 5 Schematic of SLU with metric learning
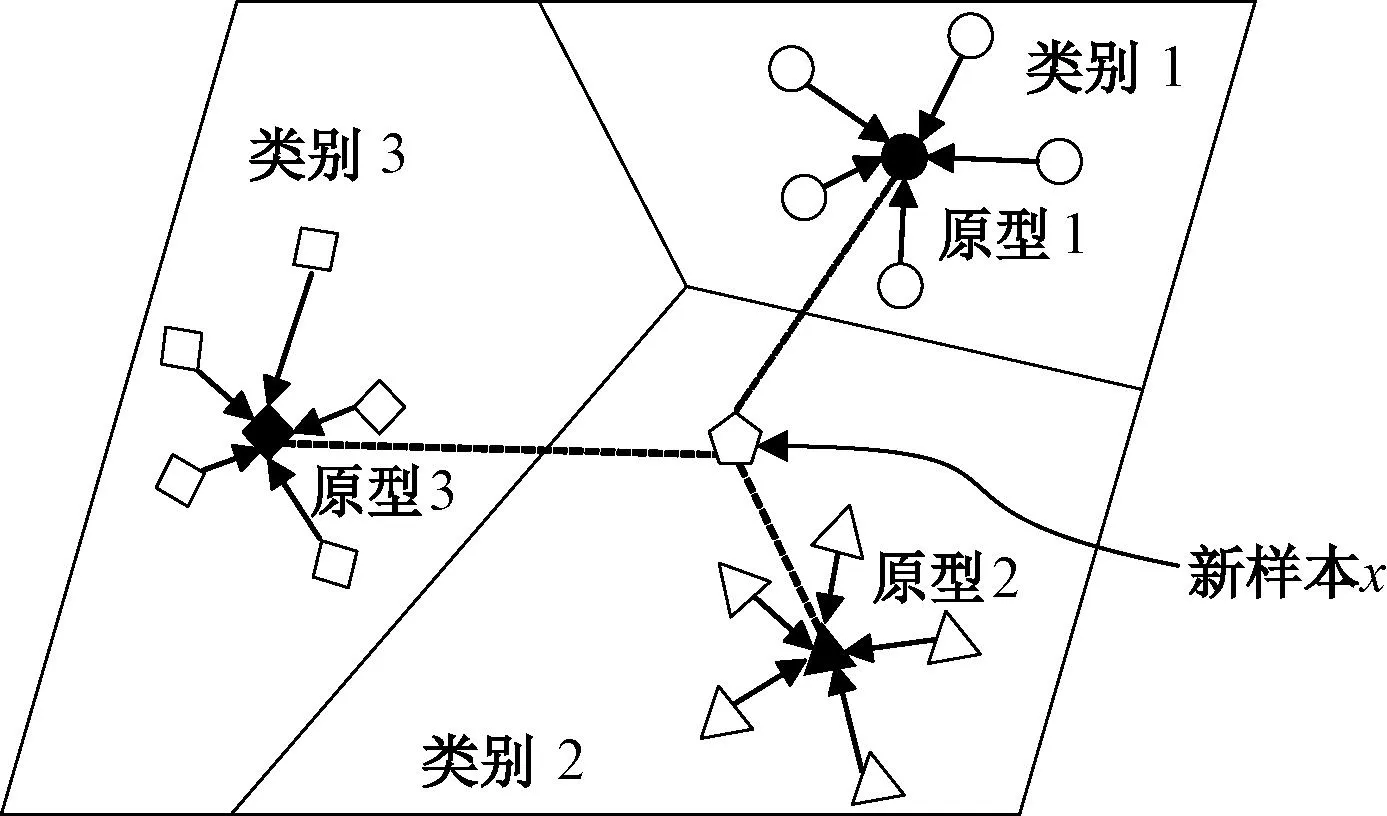
图6 原型网络示意图Figure 6 Schematic of the prototypical network
2020年,Hou等[40]在原型网络基础上,设计出基于相似性度量的小样本学习模型SepProto,以及利用Goo等[14]提出的门控机制设计出JointProto模型,实现意图分类和槽位填充的联合学习。利用对话意图分类领域新的研究基准FewJoint在两个基于原型网络的模型上进行实验,结果表明:JointProto模型在意图分类和槽位填充两个任务上都优于SepProto,前者意图分类的准确率高于后者7.25%,证明了来自联合学习任务的额外信息能够提高模型的性能,与普通的小样本学习方法相比,联合学习在语言理解上更具有优势。2021年,Xu等[41]提出语义传输原型网络(semantic transportation prototypical network, STPN),是首个专注于单词级判别信息的小样本意图分类模型。Xu等[41]认为在度量空间中,不相关的词会导致同一类词的全局特征表示相距较远。2021年,Dopierre等[42]在原型网络的基础上进行扩展,提出了一种应用在意图分类任务中的短文本分类元学习算法PROTAUGMENT。Dopierre等[42]认为元学习模型在小样本训练过程中很容易导致过拟合,通过在原型网络框架中引入一种无监督离散释义损失去解决该问题。将自动编码器在Seq2Seq任务上进行预训练的去噪过程转化为释义生成任务,不同的解码方法大多使用基于Beam Search算法进行扩展,使用Diverse Beam Search(DBS)算法替代Beam Search算法,进一步提高了释义的多样性。2022年,Yang等[43]认为由于训练数据有限,难以覆盖用户的多样性表达,导致如今的小样本学习方法在小样本口语理解任务中效果较差。受到Word2Vec模型中单词类比关系的启发,提出了一种多样性特征增强的原型网络(diversity features enhanced prototypical network, DFEPN)模型,通过对已知意图样本的多样性特征进行充分挖掘,并将其迁移到新的意图样本中,从而达到增强新的意图样本多样性特征的效果。
2.4.2 归纳网络
基于度量学习的神经网络架构往往致力于将新的查询集样本与支持集中的样本进行比较,2019年,Geng等[44]认为同一类别的不同表述有很多种,这种比较会忽视从样本表示到类别表示的建模。因此在Yang等[43]的启发下,将小样本学习方法和胶囊网络进行融合,提出了一种新颖的归纳网络(induction networks,IN)。使用胶囊和动态路由从基于样本的广义类级表示中捕获信息,动态路由方法使模型在小样本文本分类任务中具有更好的泛化能力。模型采用了Encoder-Induction-Relation三级框架,架构如图7所示。其中Encoder 模块使用基于自注意力机制的BiLSTM编码输入的词向量矩阵,得到每个样本的句子级别语义表示;支持集中每个样本被编码为样本向量后,Induction模块将其视为胶囊的输入,经过Dynamic Routing变换后,输出胶囊归纳出支持集样本的类别特征;Relation模块用于度量查询集和类别之间的语义关系,进而完成分类。
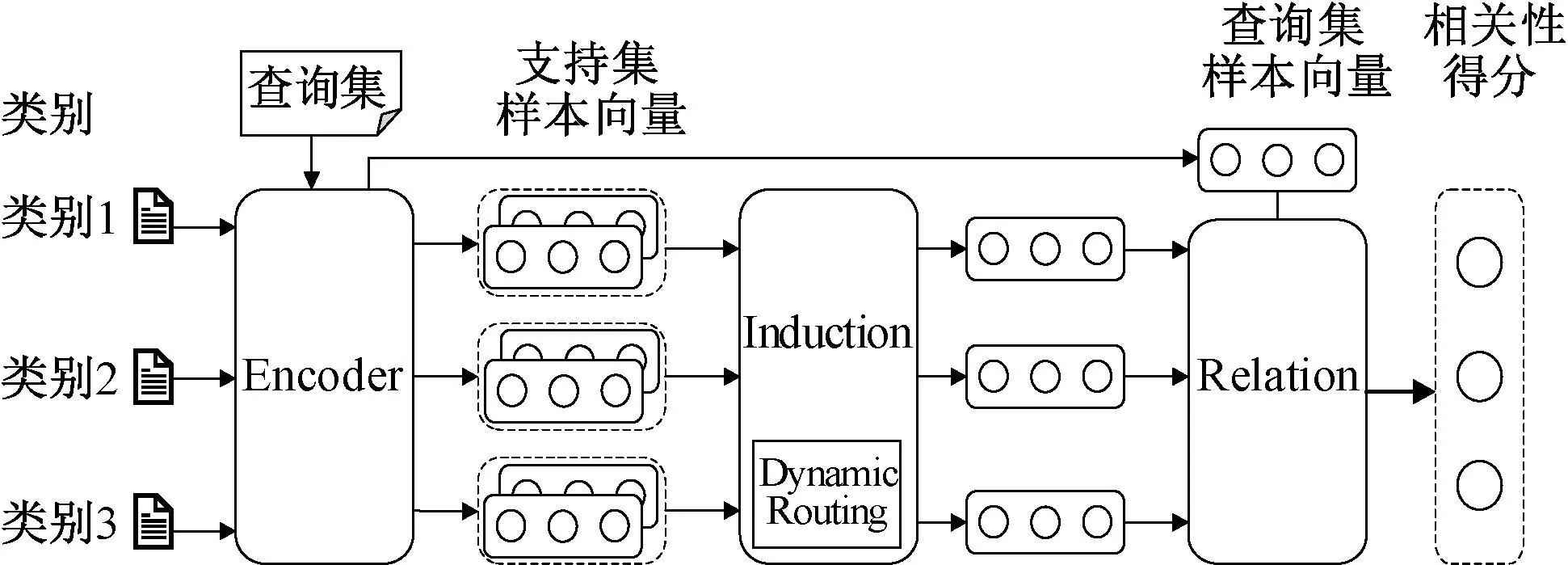
图7 归纳网络架构图Figure 7 Induction networks architecture diagram
2020年,Geng等[45]在IN的基础上进行改进,提出动态记忆归纳网络(dynamic memory induction networks, DMIN),与文献[44]区别在于编码模块采用BERT-base,并增加了预训练监督学习阶段。经过动态记忆模块后,样本向量得到更好的分离,动态记忆模块能够有效利用监督学习的经验来编码低级别样本特征和高级别样本特征之间的语义关系,从而实现小样本文本分类。
在小样本学习方法中,相似性度量模型除了原型网络、归纳网络,还有孪生网络、匹配网络[46]和关系网络[47]等,但针对后三者的研究主要集中在图像领域。如表5所示,在小样本口语理解任务中,将基于相似性度量的方法与深度学习方法相结合,是该领域今后的研究重点。

表5 基于度量学习的小样本口语理解模型对比Table 5 Comparing few-shot spoken language understanding models with metric learning
3 挑战与前沿
随着对话式人工智能的持续发展,新的口语理解任务不断出现。在实际的应用场景中,用户表达的语义具有多样性,目前的预训练语言模型并不能真正解决深度学习模型鲁棒性差、可解释性弱、推理能力缺失等问题。
3.1 零样本口语理解
零样本口语理解的任务是使模型能够在没有接受样本训练的情况下,对用户输入的内容进行识别和理解。目前针对零样本口语理解任务可以从以下3个方面进行研究:①借助外部资源,将现有意图中的先验知识转移到新意图中,从而实现对新意图的推断预测。但该方法需要对每一种新意图添加额外的辅助信息,代价十分昂贵;②基于相似性学习的方法度量新意图标签和已知意图样本之间的相似性,但在不同的语境中,语义会发生动态变化,从而产生语义漂移问题;③利用槽位填充任务指导意图分类,两个任务联合建模有助于提高意图分类的准确率。但两个任务产生的噪声会在模型中传播,如何有效控制噪声、对有用知识进行增强,是未来的主要研究方向之一。
3.2 中文口语理解
目前,针对中文的口语理解研究远不如对英文的口语理解研究,其中一方面的原因是带有标注的中文意图训练数据较少,对中文文本进行标注代价十分昂贵;另一方面是中文具有比英文更为复杂的结构,表达的语义更加丰富。
2021年,Sun等[48]提出ERNIE 3.0模型在各种NLP任务中表现出比已有的中文预训练语言模型更加出色的效果。ERNIE 3.0模型的参数量更少,在小样本环境中可以快速进行模型微调和训练,同时在情感分析、口语理解等任务上表现出强大的性能。但在中文意图识别任务中,ERNIE模型的潜力还有进一步挖掘的空间,是未来该领域的工作者进一步研究的方向之一。
3.3 开放域口语理解
现阶段的对话系统大多停留在封闭的知识领域内,在真实的应用场景中,更多的是需要解决开放领域的问题。2022年,Zhang等[49]构建了两个用于开放域意图分类的数据集CLINC-Single-Domain-OOS与BANKING77-OOS。作者在BERT模型上进行验证后发现,经过预训练的Transformer模型在两个数据集上的鲁棒性很差,开放域场景下的小样本口语理解还需要进行细粒度更好的研究。
目前针对开放域意图识别可以细分为两个子任务:①将开放域意图与已知域内意图分离;②捕获开放域意图的细粒度类别。模型需要在确保“已知意图”准确识别的前提下,捕获没有先验知识的“未知意图”。未来的研究需要寻找合适的决策边界,平衡对“已知意图”和“未知意图”的识别能力。
3.4 跨语言口语理解
目前大多数针对口语意图识别的研究以英文为主。但对于不流行或者资源较少的语言来说,在口语理解任务中,同样需要找到一种合适的解决方案。现阶段针对跨语言口语理解的研究主要有两种方式。一种是选择基准英语数据集,将其翻译成目标语言。2020年,Bhathiya等[50]先在英语样本中学习先验知识,接着在西班牙语和泰语样本上验证模型的适应性。该方法存在的缺陷是机器翻译时会出现数据扭曲问题,样本质量显著降低而无法训练语言模型。另一种是利用迁移学习的方法。2021年,Sharma等[51]提出多语言教师-学生网络(multi-lingual teacher-student network,MTSN),将从mBERT模型中学习到的先验知识迁移到目标语言任务中。该方法减少了对目标语言样本量的需求,但会受到不同语种表达方式的差异而显著影响模型的性能。
4 结束语
在口语理解领域中,基于大数据的预训练语言模型已经在传统的口语理解数据集上取得了接近饱和的效果。相比研究经典数据集,在现实的应用场景中,更多面对的是训练样本受限的问题。近年来,随着小样本学习方法在图像领域的深入研究,越来越多的NLP领域研究者开始关注该方法在口语理解任务中的应用。本文重点阐述了小样本场景下的模型微调、数据增强和度量学习3类方法,对不同模型的可解释性、推理能力以及泛化能力等性能进行对比。未来的研究重点是用户在不同场景下语义多样性的表达,以进一步提高模型在深层次语义上的理解能力。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
法律方法(2021年3期)2021-03-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
文苑(2018年22期)2018-11-19
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
学生天地(2017年10期)2017-05-17
小天使·三年级语数英综合(2016年6期)2016-05-14
延河(下半月)(2014年3期)2014-02-28
