
基于对抗网络的文本情绪分析性别偏见消减方法
2024-01-24 08:52乌达巴拉张贯虹
电脑知识与技术 2023年34期
乌达巴拉 张贯虹
摘要:近年来,性别偏见引起自然语言处理领域研究者们的关注。已有研究工作证实,性别偏见不仅影响模型性能,且其传播将进一步对下游产品产生一定的危害。文章探究性别偏见对文本情绪分析的影响,提出基于对抗网络模型的性别偏见消减方法。实验结果表明,在文本数据集上,文章提出的对抗性训练方法相比其他减偏方法,使TPR-GAP下降约0.02~0.03,而性能只降低了0.8个点。
关键词:性别偏见;文本情绪分析;对抗网络
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)34-0029-03
开放科学(资源服务)标识码(OSID)
0 引言
近年来,性别偏见(Gender Bias) 在NLP领域受到了关注,它不仅影响NLP模型的性能,其传播在很大程度上会对下游产品产生一些危险的刻板印象。
性别偏见没有统一的定义,也没有用于衡量它的统一标准。但研究者们普遍认为,性别偏见是对一种性别的偏好或偏见[1],它存在于NLP 模型或系统的多个方面,比如训练数据、预训练模型和训练算法等。以下通过例子来说明不同任务中存在的性别偏见。
例句1. 机器翻译系统[2]。英语: The doctor asked the nurse to help her in the procedure. 西班牙语: El doctor le pidio a la enfermera que le ayudara con el procedimiento.
在英语源句中,护士的性别是未知的,但与her的共指表明“医生”是女性。西班牙语的目标句使用形态特征来表示性别:el doctor表示男性,而la enfermera表示女性。
例句2.词嵌入[3]。有偏见的词嵌入模型自动生成诸如“男人:女人”,“计算机程序员:家庭主妇”之类的类推。
例句3. 共指解析[4]。一个男人和他的儿子发生了一场可怕的车祸。父亲死了,男孩受了重伤。医院里,外科医生看着病人惊呼,我不能给这个男孩做手术,他是我儿子!
许多第一次听到上述描述的人很难将母亲和外科医生的角色分配给同一个实体。
例句 4. 侮辱性语言检测[5]。“你是一个好女人”(You are a good woman) 被認为存在“性别歧视”,其原因可能是由于“女人”(woman) 这个词语。
例句5. 情感倾向性分析[6]。超过75%的系统倾向于标记涉及某一种性别/种族的句子(相比其他性别/种族的句子)较高的倾向性强度值。
本文针对情感分析中存在的性别偏见问题,提出一种基于对抗网络的性别偏见消减方法。通过将情绪分析和性别预测模型以对抗的方式联合训练,增强模型泛化能力,同时抵御敏感属性(性别)对情绪分析任务的影响。
1 相关工作
目前,国内外研究者们提出了不同方法来解决性别偏见问题。例如:构建性别平衡语料的方法[7]、词嵌入去偏的方法[8]以及调整训练算法来消减偏见的方法[9]。上述研究均取得了不同程度的研究结果。但是,构建语料的方法并不完全适用于文本情绪分析,因为在情绪表达的语句中很少会直接显示性别信息。例如,“I never knew a detention was so hard to get.”(我从来不知道拘留是如此之难)。词嵌入去偏的方法存在删除过多有利于下游应用信息的问题。调整训练算法需要设计合理的模型和训练策略来平衡盲化的敏感信息(如性别)和保留的目标任务所需信息。
2 模型概述
本文借鉴对抗训练[10]的思想,对情绪识别和性别预测模型进行联合训练,通过调整对抗性损失函数达到消减性别偏见的目的。对抗性训练方法涉及同时训练两个网络模型:生成器G和判别器D。生成器G试图生成欺骗D的噪声数据,而判别器D对从G生成的真实数据和假数据进行分类。在结合G和D两个模型的学习过程中,G和D以交互方式相互促进,以实现各自的目标。
本文没有设计专门的生成器,而是采用一种基于中介的方式,将情绪识别网络的前 k 层结果视为生成器的一部分内容,它将情感特征 Xi映射到一系列表示 Ri。然后,Ri被输入到解码器网络以输出情感分值,同时它也将成为另一个解码器网络(性别预测模型)输入的一部分。因此,情绪识别模型和性别检测模型之间的关系可表示为:
[Pr(y,g|x)=p(y|x,g)⋅p(g|x+noise)y',g'p(y'|x,g)⋅p(g'|x+noise)] (1)
其中,x是句子集:x = x1, ..., xN, y = y1, ..., yN表示x的所有可能的情绪类别集合,g = g1, ..., gN, 其中,[gi∈[0,1]]表示xi的性别信息,即该条句子是由女性产生还是由男性产生。noise 表示情绪识别网络的前 k 层结果作为干扰性别预测模型的干扰数据。
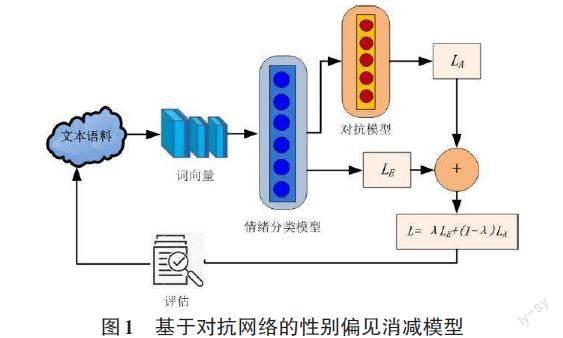
模型的流程示意图如图1所示。情绪识别模型和性别检测模型通过对抗训练实现,情绪识别模型的结果干扰性别预测模型的结果的同时保证其准确率。
2.1 基础模型
本文以CNN模型为基础框架,网络的前k层作为编码器,生成一组 N个表示Rn(Y, X), n = 1, ..., N。然后,Ri作为特征值被输入到解码器以输出情绪后验P(yi| xi)。基础模型记为E,其损失表示为LE。
2.2 对抗模型
本文针对性别预测设计了对抗模型,可以通过神经网络实现。本文设计3种不同的对抗模型:
1) 线性模型(Linear)。使用两个线性层来生成一个对抗模型。
2) LSTM 模型(LSTM)。包含 1 个嵌入层、1 个 LSTM层和两个线性层。LSTM 模型旨在通过单层双向 LSTM 将由 c1,...,cN 组成的中间卷积表示C 映射到一系列隐藏状态 h1,...,hN。H = BiLSTM(X + C) = [h1,..., hN],[H∈Rd×N],其中d是隐藏层的大小,N是给定句子的长度。
3) 基于注意力的 LSTM 模型(Attention-LSTM)。该对抗模型将注意力机制集成到 LSTM 模型中。在 LSTM 生成矩阵H后,应用均值池化将结果[h]与最后一个时刻产生的隐藏状态hN连接起来。注意力层旨在从H中学习归一化权重向量[α=α1, ...,αN]和加权隐藏表示[δ]。即[M=tanh(h⊕hN)], [α=softmax(wTM)], [δ=HαT],其中[⊕]表示连接运算符。
对抗模型记为A,其损失表示为LA。
2.3 对抗训练
基础模型E中产生的Ri作为一种噪声也同时传输到A中。在训练过程中,当A 处于最优状态时,其参数将会被冻结,同时其输入将产生被继续修改,从而达到降低A准确率的目的。但同时保证E 将找到最佳的特征,使其准确率较高。即整个系统的最终目的是让E准确地预测标签yi,同时通过Ri的干扰,使A预测gi的结果很差。
E的目的是最小化与预测训练数据(Xtest, Ytest)上的情绪类别相关的交叉熵损失LE。
[LE(X;θe)=-i=1KlogP(yi|X;θe)] (2)
A的目的是最小化与预测训练数据(Xtest, Gtest)上的性别相关的交叉熵损失LA。
[LA(X;θa)=-GlogP(gi|X;θa)] (3)
上述模型的最终参数值作为对抗网络的起点。在对抗训练中,前k个CNN层的输出C被选为特征向量,并与词嵌入连接作为A的输入。此时,对抗损失形式为:
[LA(X+C;θa)=-GlogP(gi|X+C;θa)] (4)
通过优化E对y的预测来联合训练E和A,同时随着A在预测g时受到惩罚。换言之,情绪分类器试图最小化其对特定任务预测的损失,而性别预测模型试图增加其损失。因此,对抗网络的损失函数L是 LE和 LA的加权组合。本文采用的组合形式为:
[L=λLE+(1-λ)LA] (5)
2.4 评估指标
本文采用两个指标来评估性别偏见消减结果:准确率ACC和真阳性率差异TPR-GAP。基于文献[11]对于性别偏见的影响分析,本文定义了TPR-GAP,计算公式见公式(6)。其中TPR是与“赔率相等”相关的“真阳性率”(True Positive Rate, TPR)。TPR-GAP 表示女性和男性的TPR值差异的绝对值。具体而言,通过计算每个类别的真阳性率 (TPR) 的差异,并进一步通过平均这些数量来量化这个标准。
TPR-GAP = |TPRf - TPRm| (6)
对于情绪识别任务,需要通过计算准确率ACC来验证学习的目标模型是否能得到令人满意的性能:准确率越高表明性能越好。对于性别偏见的影响,如果TPR-GAP越低表明性别偏见消减结果越好。
3 实验结果及讨论
3.1 实验数据及设置
实验数据:本文在ISEAR,CrowdFlower和Volkova数据集上进行相应实验。ISEAR包含7 659条语句,其中来自女性的语句4 201条;男性语句3 458条,标注了七种情绪:喜悦、恐惧、愤怒、悲伤、厌恶、羞耻和内疚。CrowdFlower是利用众包技术生成的面向推文的情感数据集,由40 000条推文构成,情绪类别包括:空虚、悲伤、热情、担忧、爱、乐趣、恨、快乐、释然、厌倦、惊讶和愤怒等。性别信息利用Facebook个人资料和社会保障局 (SSA) 提供的姓名数据集进行。Volkova的推文数据包括739 440条推文,其中417 634条句子来自女性,320 846条句子来自男性,但没有情感信息的标注。针对Volkova的推文数据,本文利用WAL(Wordnet Affective Lexicon)情感词汇库以及情感表情库(Full Emoji Database,FED)对Volkova的推文句子进行情绪标注。标注信息除了WAL中显示的六种情绪(愤怒、厌恶、恐惧、喜悦、悲伤、惊讶)之外还增加了愛和信任两个情绪标签。
实验设置:本文将数据集以80∶10∶10的比例分别拆分为训练集、验证集和测试集,同时保证测试集包含相同数量的两种性别(男性和女性)的句子。
对所有参数设置了相同的归一化参数[λ=10-4],每批数据量的大小(batch size)设置为64,AdaGrad 的学习率设置为[α=0.1],词向量大小为300。
3.2 对比实验
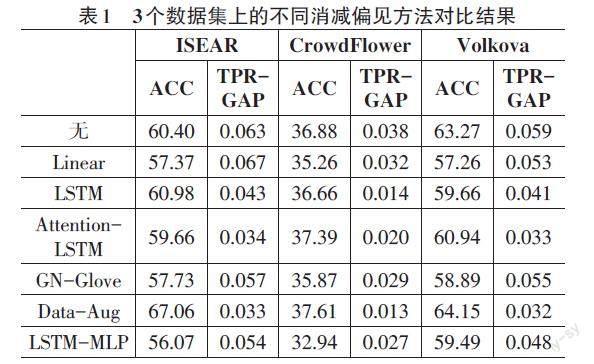
为了验证本文提出的基于对抗训练的性别偏见消减方法对文本情绪分析任务影响的有效性,本文将其与一些主流的性别偏见消减方法进行比较。对比方法包括:
1) 无消减策略(无):以在原始数据上训练的基本情绪检测模型为主模型,使用预训练的词嵌入GloVe,没有采取任何去偏或减偏策略。
2) 词嵌入去偏策略(GN-GloVe):本组实验使用文献[9]等构建去偏的词嵌入GN-GloVe替换预训练的 GloVe,以验证去偏词嵌入在文本情绪分析任务中的有效性。
3) 基于数据增强的消减方法(Data-Aug):在本组实验中,首先使用[5]描述的性别对双向字典交换所有性别词。然后,使用增强数据集和预训练的GloVe嵌入来训练模型。
4) 对抗网络架构(LSTM-MLP):构建了一个类似于文献[12]的对抗网络。该网络架构由1个用于表示的 LSTM 网络和用于分类和对抗的多层感知器组成。在本组实验中,构建了3层感知器。
对比实验结果如表1所示。
4 结论
针对性别偏见问题,本文提出基于对抗训练的方法,评估指标为准确率和真阳性率差异。实验结果表明,本文提出方法可以有效地克服文本情绪分析中存在的性别偏见。为了保证内存需求的可控性,本文限制了对抗训练阶段的迭代。在未来的工作中,将计划用一种训练标准来探索解决这个问题。同时,进一步研究更多敏感属性的影响。
参考文献:
[1] SUN T,GAUT A,TANG S,et al.Mitigating gender bias in natural language processing:literature review[EB/OL].[2022-10-20].2019:arXiv:1906.08976.https://arxiv.org/abs/1906.08976.pdf.
[2] SAVOLDI B,GAIDO M,BENTIVOGLI L,et al.Gender bias in machine translation[EB/OL].[2022-10-20].2021:arXiv:2104. 06001.https://arxiv.org/abs/2104.06001.pdf.
[3] BOLUKBASI T,CHANG K W,ZOU J,et al.Man is to computer programmer as woman is to homemaker?debiasing word embeddings[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems.December 5 - 10,2016,Barcelona,Spain.ACM,2016:4356-4364.
[4] RUDINGER R,NARADOWSKY J,LEONARD B,et al.Gender bias in coreference resolution[EB/OL].[2022-10-20].2018:arXiv:1804.09301.https://arxiv.org/abs/1804.09301.pdf.
[5] PARK J H,SHIN J,FUNG P.Reducing gender bias in abusive language detection[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing.Brussels,Belgium.Stroudsburg,PA,USA:Association for Computational Linguistics,2018.
[6] KIRITCHENKO S,MOHAMMAD S M.Examining gender and race bias in two hundred sentiment analysis systems[EB/OL].[2022-10-20].2018:arXiv:1805.04508.https://arxiv.org/abs/1805.04508.pdf.
[7] LU K J,MARDZIEL P,WU F J,et al.Gender bias in neural natural language processing[EB/OL].[2022-10-20].2018:arXiv:1807.11714.https://arxiv.org/abs/1807.11714.pdf.
[8] BARTL M,NISSIM M,GATT A.Unmasking contextual stereotypes:measuring and mitigating BERT’s gender bias[EB/OL].[2022-10-20].2020:arXiv:2010.14534.https://arxiv.org/abs/2010.14534.pdf.
[9] ZHAO J Y,ZHOU Y C,LI Z Y,et al.Learning gender-neutral word embeddings[EB/OL].[2022-10-20].2018:arXiv:1809. 01496.https://arxiv.org/abs/1809.01496.pdf.
[10] GOODFELLOW I J,POUGET-ABADIE J,MIRZA M,et al.Generative adversarial networks[EB/OL].[2022-10-20].2014:arXiv:1406.2661.https://arxiv.org/abs/1406.2661.pdf.
[11] ROMANOV A, DE-ARTEAGA M, WALLACH H,et al. What’s in a name? reducing bias in bios without access to protected attributes. In NAACL-HLT,2019:4187-4195.
[12] ELAZAR Y,GOLDBERG Y.Adversarial removal of demographic attributes from text data[EB/OL].[2022-10-20].2018:arXiv:1808.06640.https://arxiv.org/abs/1808.06640.pdf.
【通聯编辑:唐一东】
