
基于特征级联融合的图像篡改检测方法
2024-01-29 10:47宣高媛杨高明毕飞龙
宁夏师范学院学报 2024年1期
宣高媛,杨高明,毕飞龙
(1.安徽理工大学 人工智能学院,安徽 淮南 232001;2.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
随着数字图像的普及和应用,利用自动生成技术和图像编辑工具可以轻松且低成本地进行篡改伪造.数字图像伪造的盛行对生活产生了很多负面影响,如网络谣言、保险欺诈、假新闻,甚至学术作弊[1].在这样的背景下,研究图像篡改检测算法[2]是一个十分具有挑战性和迫切性的课题,已经得到了相当多的关注.在过去的几十年中,研究者们开展了相关研究并提出各种各样的篡改检测算法.但是这些算法受到各种限制,需要不断改进和提高.由于图像操作复杂,篡改的形式包括图像拼接、图像复制、图像修复等,因此本文提出一种基于特征级联融合的篡改检测方法,试图提高篡改检测的精度和鲁棒性.
目前主流的图像拼接伪造检测方法主要分为2类:传统检测方法和基于深度学习的检测方法.传统方法主要包括局部不变量特征匹配[3]、基于二维离散小波变换和奇异值分解、自一致性等对图像是否被篡改进行分类.这些方法通常需要足够的人工经验和领域知识,并且往往不能充分利用图像中的信息.此外,传统方法的性能在某些情况下会受到限制,对于具有高自相似性或强烈信号腐败的图像,传统算法通常检测精度较低.
在过去研究中,基于深度学习的方法在解决图像篡改检测问题方面已经超过传统方法并取得重大进展.这些方法通常使用主流深度学习框架卷积神经网络提取图像特征,并且可以利用图像中的上下文信息进行分类和检测.初期人们将卷积神经网络方法用于判断图像是否被篡改,但这种方法无法定位篡改区域,且检测到的区域只能用一些粗糙的白色方块表示.ZHANG等[4]尝试用神经网络定位篡改区域,但检测到的区域只能用一些不准确的粗糙区域表示.之后,R-CNN(Regions with Convolutional Neural Networks)及其扩展包括Fast-RCNN(Fast Regions with Convolutional Neural Networks)、Faster-RCNN(Faster Regions with Convolutional Neural Networks)和Mask-RCNN(Mask Regions with Convolutional Neural Networks)等基于区域的检测方法取得了惊人的成功.这些方法使用非重叠图像块作为输入,将感兴趣的区域边界框作为输入以对区域进行分类,再对图像篡改区域进行选择性搜索.由于这些方法采用图像块作为网络输入,丢失了上下文空间信息,容易导致错误的预测.
尽管以上基于深度学习的方法在图像篡改检测方面取得了显著的成果,但仍然存在一些问题,如忽略不同像素需要不同上下文依赖性的要求以及浅层网络特征和深层网络特征对比联系,缺乏对全局像素内在联系建模的能力.为了解决上述问题,提高图像篡改检测的准确性和鲁棒性,本文提出一种新的网络模型:FFU-Net(Feature Cascade Fusion Detection Network based on U-Net).FFU-Net模型引入特征级联融合模块,可以有效地融合来自不同尺度的特征信息,并优化多层次特征重构,提高特征信息的质量.具体采用与U-Net网络模型类似的编码器-解码器结构,通过编码器从原始图像中提取特征信息,在解码器中引入特征级联融合模块,以融合来自不同尺度的特征信息,并优化多层次特征重构,提高特征信息的质量.在CASIA和COLUMB数据集上进行实验,展示FFU-Net模型的直观检测结果.图1为随机选择的测试结果图像,可以看到该模型能够精确定位像素级的篡改.

图1 篡改位置检测结果示例图像
实验结果表明,与原始的U-Net网络及其一些变种相比,FFU-Net网络模型在各种图像篡改检测数据集上均表现更好.该模型可以有效地捕获不同尺度的特征信息,降低检测错误的可能性,并具有良好的应用前景.本文的主要贡献有,构建多层次上下文信息捕获聚合模块,通过不断地集成聚合不同尺度上下文信息,逐渐优化重构多层次特征,进而获取更高质量的特征信息.提出级联融合损失,将不同阶段的损失函数进行级联,引导模型向更加准确的预测结果学习.有效地降低模型的过拟合风险,提高模型的泛化能力,进一步提升模型性能.在CASIA2.0和COLUMBIA 2个图像篡改标准数据集上取得更高的准确率.
1 理论基础
1.1 深度学习的像素二分类检测算法
当前的主流研究方法之一是将篡改区域定位视为像素级的二分类问题,采用图像分割的算法定位篡改区域.在一些图像分割任务上的一些方法被广泛关注,并在图像检测任务上得到应用.U-Net是一种深度学习网络结构.该网络结构在神经元结构分割任务上取得了重大成功,具有突破性的框架,并能够实现特征在层间的传播,它可以用很少的训练图像实现高精度分割.该结构通过收缩路径(连续层)捕获上下文信息,对输出特征进行上采样,然后与通过对称扩展路径传播的高分辨率特征结合,减少了细节信息的丢失并实现了精确定位.U-Net的U型对称的编码器解码器结构在图像篡改定位中相当有效,但U-Net也存在一些局限:只能针对图像语义和结构相对简单固定,且在深度网络结构中会出现梯度退化导致网络训练准确性下降的问题.在网络中加入环形残差,构建前向反馈和反向计算残差信息以达到消减梯度退化.LIU等[5]提出一种基于区域损失的 U 型网络,用于检测小尺寸图像篡改区域.该方法通过增强异常区域的特征并采用区域损失增强技术,解决了样本不平衡问题,并提高了对篡改区域的判别能力.AKRAM等[6]提出一种结合判别鲁棒局部二进制模式(DRLBP)和支持向量机的新型图像拼接检测方法,以应对日益增长的图像拼接伪造技术的挑战.WEI等[7]提出合成对抗网络和混合密集U-Net,通过扩大数据集并利用空间特征提高检测精度和鲁棒性.SUN等[8]提出一种边缘增强变压器,用于精确定位图像拼接篡改区域,通过集成边缘线索和特征增强模块,以提高篡改检测的准确性和降低误报.DING等[9]提出一种基于双通道U-Net的图像篡改定位方法,对编码器和解码器进行2次特征融合,可以更准确地对篡改和非篡改区域进行分类,但是只能检测拼接类型的图像篡改操作.即检测的图像操作类型过于单一.以上方法的网络结构相对复杂,训练和推理需要大量的计算资源,尤其是模型规模较大时,需要更大的计算资源.
1.2 弥合视觉表现和语义理解的差距
由于篡改图像通常会为了保留大部分高级语义信息而破坏图像的低级视觉表现,因此一个主要的挑战是弥合低级视觉表现和高级语义理解之间的差距.传统的图像处理技术主要借助固有痕迹,需要特定的篡改类型和简单的图像结构才能取得较高的准确性,即缺乏关联图像深层特征属性的,深度学习可以更好地学习图像特征以及兼顾低级视觉表现和高级语义理解的需求.
一种常见的解决低级视觉表现和高级语义理解之间差距的方法是构建特征金字塔以获取多尺度特征.深度图像先验DIP(Deep Image Prior)是一种基于特征金字塔的方法,它通过在训练期间随机初始化输入图像,最小化像素差异,以实现篡改检测.此外,一些研究人员已将神经网络与特征金字塔结合使用,以获得更好的性能.另一种方法是使用注意力机制帮助网络更好地关注重要区域,从而提高网络性能.一种基于注意力机制的方法使用空间注意力模块增强网络对细节的感知.SAM(Spatial Attention Module)基于像素之间的相对位置计算它们之间的相关性,从而增强网络感知细节的能力.还有其他方法被提出以解决低级视觉表现和高级语义理解之间的差距.例如,一些方法使用多尺度卷积核处理不同大小的对象,从而提高网络性能;一些方法使用高波滤波器捕获图像中的纹理信息,从而实现更准确的篡改检测;还有一些方法使用GAN(Generative Adversarial Network)合成篡改图像扩展训练数据集,提高网络的泛化能力.
现有的方法在一定程度上提高了网络性能和准确性,但仍有许多问题需要解决.未来的研究方向包括进一步提高网络性能,开发更有效的特征表示,探索解决低级视觉表现和高级语义理解之间差距的新方法.此外,需要更多的研究,以解决在使用深度学习方法时面临的数据不平衡、对抗攻击和隐私保护等问题.因此,深度学习方法在图像篡改检测领域中具有广泛的应用前景,需要进一步研究以推动其发展.
2 基于U型网络的特征级联融合检测模型
本文提出一种新的FFU-Net网络模型.该模型将U-Net模型和特征级联融合模块相结合,可以有效地融合来自不同尺度的特征信息,优化多层次特征重构,提高特征信息的质量.针对所提取到的不同尺度的上下特征信息,优化重构多层次特征,捕获高质量的特征信息,降低检测错误的可能性.
2.1 特征级联融合模块
本文采用U型结构的网络模型作为基础模型进行图像篡改检测,为了更加高效、准确地识别篡改区域与未篡改区域的差异,搭建特征级联模块,由上一层网络卷积中获取的关键特征作为参考,指导下一层的网络学习,不断集成聚合不同尺度上下文信息逐渐优化重构多层次特征,进而获取更高质量的特征信息以判断检测结果.特征级联融合模块结构如图2所示.

图2 特征级联融合模块
具体来说,给定输入RGB图像,在卷积计算获得的特征集T={d1,d2,…,dn;u1,u2,…,un;f1,f2,…,fn}对于空间上较粗糙的瓶颈层块的特征fi和特征级联融合模块的输出,以因子fi对空间分辨率进行上采样.以下1×1卷积运算用于对齐2个输入要素之间的通道尺寸.然后通过加法和级联操作,将上采样的网络层ui、下采样的网络层di和连接的瓶颈层块的特征fi融合为
fi+1=Conv(fc(ui)+fu(fi))‖fc(ui)‖fc(di),b∈[1,B-1],
(1)
式中,+和‖分别表示加法和级联运算.fu(·)是上采样和1×1卷积模块的函数.fc(·)是1×1卷积模块的函数,用于对齐2个特征之间的通道数.Conv是一个1×1卷积块,它融合拼接操作后的特征,并维持特征通道数不变,如图2所示.重复该融合处理,直到生成最新的特征图fn.
特征级联模块的优势在于能够提高特征的多样性和鲁棒性,同时降低模型的参数量和计算量.具体来说,该模块能够将低层次的视觉特征和高层次的语义特征结合起来,提高模型对图像中不同尺度和复杂度的特征的表示能力.
2.2 网络结构
本文的基础网络结构主体是U型网络结构,由下采样的压缩路径和上采样的扩展路径组成.在采样的网络层中加入特征融合模块,在上采样网络恢复空间信息的过程中反馈到相应层级的特征提取层进行级联融合.将篡改图像RGB输入U-Net网络的编码器部分,经过多个卷积层和池化层提取篡改图像的特征.在这个过程中,卷积层的卷积核会检测输入图像的局部特征,如边缘、纹理等.篡改图像和原始图像的差异特征会通过瓶颈层传递到解码器部分,其中瓶颈层通常由一些卷积层和激活函数组成,在解码器部分,通过上采样和反卷积等操作将低维特征重新映射到高维特征空间中,得到与原始图像尺寸相同的分割结果.对上一层瓶颈层和特征大小相同的编码器中的特征、解码器中的特征通过特征级联融合模块形成下一层的输出,最终得到一个与原始图像尺寸相同的分割结果.
总体模型框架分为2部分:第一部分以U型网络分割伪造区域和提取全局特征为基底,主要用于分割伪造区域和提取全局特征,有助于提高网络的准确性和鲁棒性,从而更好地检测图像中的篡改和伪造.第二部分为多层次特征级联融合模块,旨在实现多层次特征中互补信息的交流学习.该模块允许多个不同层次的特征参与学习,从而提高了检测结果的准确性和鲁棒性.在这个模块中,不同层次的特征将被级联融合,以实现更全面和准确的特征表示.基本网络结构如图3所示.

图3 FFU-Net的网络体系结构
不同层次特征包含不同信息分布,浅层含空间结构信息但分辨率高,深层含语义信息但分辨率低,全局上下文信息可突出目标区域并减少背景干扰,融合不同特征信息可提高显著性检测精准度.由于深层的语义特征信息在自上向下的传递过程中逐步淡化,使显著性目标在层层卷积上采样后丢失高级别语义信息的指导,导致模型检测性能下降.因此,FFU-Net在每个网络块融合浅层特征信息,瓶颈层和深层特征信息都加入特征级联融合模块,可以弥补深层语义信息的淡化,提升浅层网络检测能力,有效减少图像内容的干扰,并在每层卷积实现对篡改区域的精准定位.通过特征级联融合模块,可以捕获到较为细节的空间和语义信息,联合深层网络的多层次特征,可以达到更加准确的区域检测.
2.3 损失函数
在网络训练中,本文训练损失函数的第一个组成部分是最后一层预测掩模un与真实掩模truemask之间的二元交叉熵损失,
LBCE(un,truemask).
(2)
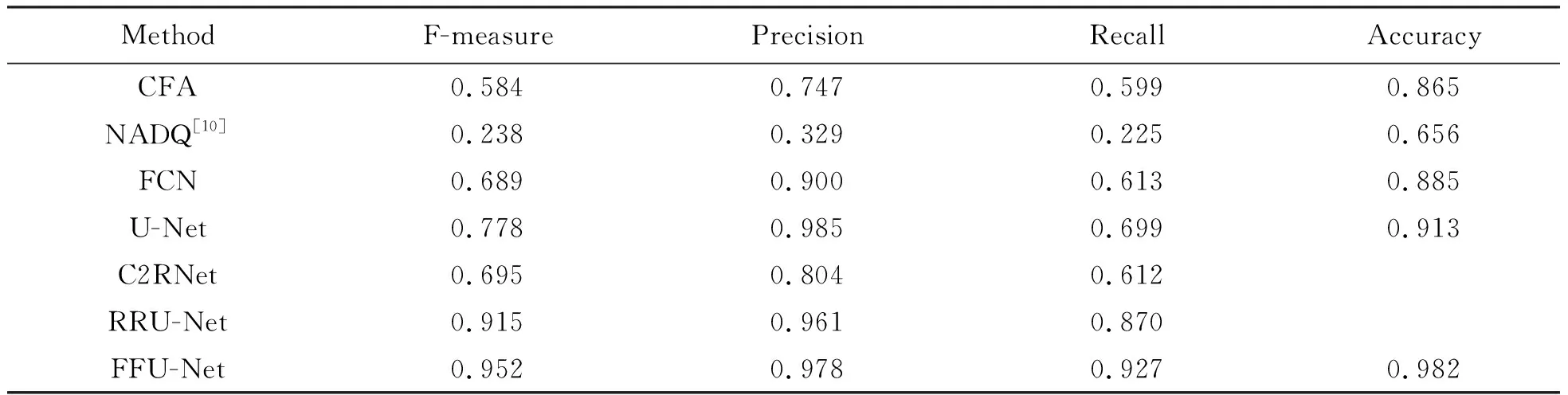
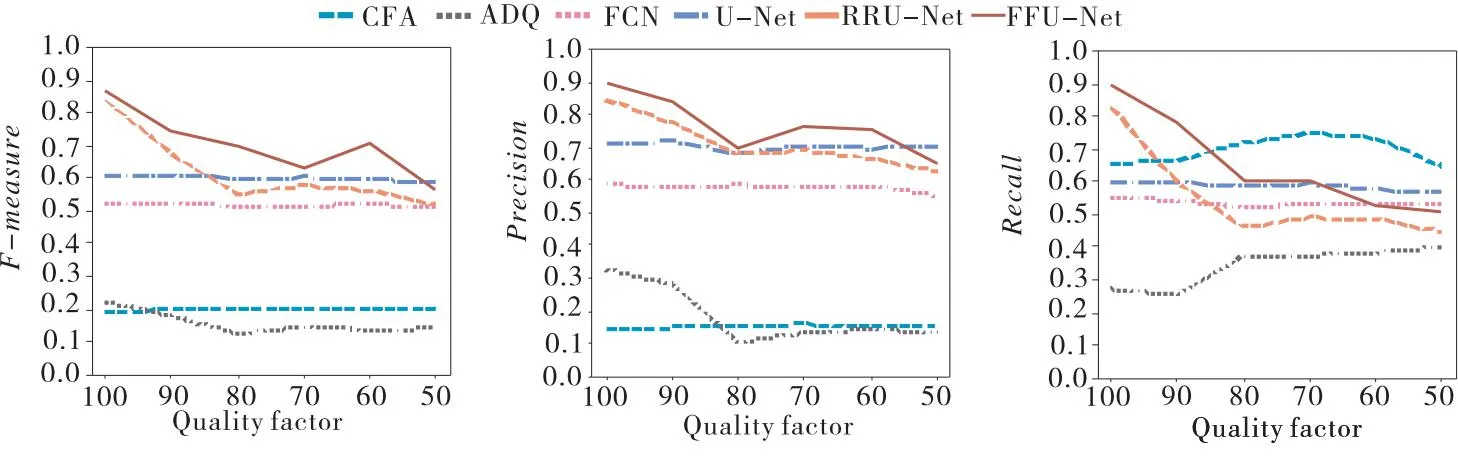
第二个组成部分同样是对所有其他fn LBCE(fn,truemask). (3) 第三个组成部分选用损失函数Lfea,函数是用来平滑正则化的,它通过将输入样本的所有特征与最后一个特征之间的误差作为惩罚项,保持模型的稳定性和准确性.训练的特征损失函数Lfea的计算公式为 (4) 总损失函数如公式(5)所示,平衡了准确的掩模预测和网络不同层学习特征一致性之间的重要性. (5) 式中,超参α、β和γ控制了这些组成部分在整个损失函数中的相对重要性. 在实验中,本文使用了CASIA V2.0和COLUMB 2个公共标准数据集,对FFU-Net进行了多个实验以评估其性能和鲁棒性. CASIA数据集有2个版本:1.0版本是一个较小的集合,仅有1725张经过拼接的篡改图像且图像格式等相对固定;2.0版本是各种操作具有的大集合,有12323张彩色篡改图像示例,主要包含拼接和复制移动.COLUMB图像数据库由2部分组成.一部分是灰度图像数据集COLUMB图像拼接检测评价数据集.该数据集由933个真实图像块和912个拼接灰度图像块组成.在CASIA上,伪造区域是物体,小而精细.在COLUMB上,拼接伪造区域是一些简单的、大的和无意义的区域.这2个数据集均为未压缩数据,也是现在图像篡改领域应用最多的公共数据集. 本文从CASIA数据集中随机选择715组图像作为训练集,并选择35组图像作为验证集.这些图像都包含原始图像和篡改图像.同样,从COLUMB未压缩数据集中选择125组篡改的图像,其中10组作为验证集数据、44组作为测试数据.为了防止由于数据样本较少而导致过拟合,对训练数据进行扩展,通过随机高斯噪声、IPEG压缩和随机反转进行数据增强,使数据集的容量增加了4倍.标准数据集划分情况如表1所示. 表1 基于CASIA和COLUMB划分的训练、验证和测试集 在CASIA和COLUMB数据集中,实验将训练集和验证集的图像大小调整为384×256.为了比较和分析图像拼接伪造检测方法的鲁棒性,本实验对伪造数据集进行JPEG压缩和噪声破坏,以模拟各种攻击场景.在接下来的实验中,为了公平,所有实验图像均为JPEG格式. 在实验中,用Python和PyTorch实现所提检测方法,使用Adam优化器进行训练,并将学习率设置为0.001.在NVIDIA GeForce GTX 3080 Ti GPU上运行本实验. 使用以下4个指标评估算法在像素级别上的性能:精确度(Precision)、召回率(Recall)、F度量(F-measure)和正确率(Accuracy).这些评价指标能够全面地衡量算法的性能,帮助深入了解算法的优缺点,并为后续的算法优化提供重要的参考依据.其中,精确度衡量的是算法检测到的篡改像素中真实篡改像素所占的比例, (6) 式中,TP表示算法检测到的正确篡改像素数量,FP表示算法检测到的错误篡改像素数量. 召回率衡量的是算法能够正确检测到的真实篡改像素数量占总体真实篡改像素数量的比例,可表示为 (7) 式中,FN表示未检测到的真实篡改像素数量.在分类器性能评估中,Precision和Recall指标可能会出现矛盾,这时需要综合考虑它们,F-measure是最常用的综合考虑Precision和Recall的指标,F-measure可以被视为Precision和Recall的加权调和平均.具体的计算公式如下: (8) 当Precision和Recall同时很高,F-measure也会很高.准确率一般用来评估检测模型的全局准确程度,计算公式为 (9) 在实验中,精确度、召回率和F-measure都是在测试集上进行平均计算的.除了像素级别的评价指标,还需要考虑算法对于未篡改图像和篡改图像的区分能力.也就是说,未篡改图像不应该被检测为篡改图像,反之亦然.为了验证模型的检测效果,本文在图像层次上采用准确率以评估算法的性能. 本文主要从2个角度进行对比实验:直观检测结果和定量指标评价. 3.3.1 检测结果 为了评估所提方法的有效性,进行一些基线实验,并比较了FFU-Net模型与这些基线方法的表现.将所提方法与FCN[10]、DeepLab V3、U-Net和RRU-Net模型的直观效果做对比.其中,FCN是一种像素级分类方法,自动学习图像篡改特征用于图像拼接篡改检测;DeepLab V3是针对图像语义分割任务的有效检测方法;U-Net作为全卷积网络结构的模型之一,与FCN相比,最重要的改进是增加了跳跃式结构,减少了信息的丢失,在像素级分类检测上有明显效果;RRU-Net则在U-Net的基础上改进了梯度下降的问题,增加残差结构,让检测更加有效.图4展示了本文所提模型和这些检测方法的直观检测效果,可以看出基础U-Net方法只对原图的显著性目标有较高的识别性,而不只是篡改部分;RRU-Net在检测篡改区域上误检率降低了很多,但是不够精细;本文的网络结构相比前面几种方法,更加准确,非常接近真实标签. 图4 FFU-Net与其他篡改检测方法的比较可视化结果 实验用上述的4个评价指标对本文模型实验检测结果进行了更加客观的评价,结果见表2和表3. 表2 CASIA数据集评估结果 表3 COLUMB数据集评估结果 表2和表3分别显示出对CASIA和COLUMB数据的评估结果.从表对像素级分类的评估结果可以看出,NADQ方法4个评价指标的结果相对较低,CFA算法对COLUMB数据中的简单篡改有一定的检测效果,在4个评价指标上取得了高于NADQ的分数.综合来看,基于深度学习的图像篡改检测优于传统检测算法.C2RNet提出从粗到细的拼接检测方法,采用聚类算法对检测结果进行处理,但检测精度较差.RRU-Net在传统U-Net网络的基础上增加了残差学习和反馈过程,大大提高了模型的检测效果.可以看出本文方法在查准率、查全率和F测度都优于其他方法,综合评估在数据集CASIA上相较于最新的方法F-measure提高了3%,在数据集COLUMB上提高了4%. 3.3.2 鲁棒性检测 为了评估本文所提方法在图像篡改检测鲁棒性方面的表现,本实验从CASIA和COLUMB数据集中随机选取了20%的图像,并对这些图像进行了不同程度的篡改处理,包括JPEG压缩和高斯模糊,并与2种常见的图像篡改检测模型做对比实验.实验对比结果见图5、图6、图7和图8,横轴分别为噪声强度和JPEG压缩质量. 图5 CASIA数据集添加高斯噪声的实验结果 图6 COLUMB数据集添加高斯噪声的实验结果 图7 CASIA数据集中JPEG压缩攻击的实验结果 图8 COLUMB数据集中JPEG压缩攻击的实验结果 从实验结果可以看出,随着高斯噪声的增加,所有评价指标都出现不同程度的下降。如图5和图6所示,当方差为0.002时,CFA和ADQ这2种传统方法的F-measure 值和精度值几乎达到了最低点.随着高斯噪声的方差从0.002 逐渐增加到0.01,其余基于深度学习的检测方法的评价指标也逐渐下降.可以看出,噪声攻击对深度学习方法有很大的影响,但不存在像传统方法那样的检测失败.如图7和图8所示,在JPEG压缩攻击时也有同样的表现.从检测指标可以看出,随着高斯核尺寸的增大和JPEG压缩质量因子的降低,FFU-Net进一步降低了高斯噪声的影响,从而获得与其他方法相比最好的结果,所提出的模型的检测指标受到的影响最小,其Fmeasure值始终保持在较高的水平.在CASIA和COLUMB数据集上的平均F-measure值最高,表明本文提出的FFU-Net 具有较好的鲁棒性. 本文提出一种新的基于U型网络的检测模型FFU-Net.该模型将U-Net网络模型和特征级联融合模块相结合,可以有效地融合不同尺度的特征信息,优化多层次特征重构,提高特征信息的质量.通过构建多层次特征级联融合模块,实现不同层次特征之间的互补信息交流学习,提高显著性检测的精准度,在不同类型的图像篡改任务中均取得了较好的表现.综合来看,该方法是一种有效的图像篡改检测方法,具有较强的实用性和应用前景.同时,测试结果表明FFU-Net模型具有较好的抗噪声和抗压缩能力.3 实验结果和比较分析
3.1 数据集

3.2 实验设置和评价指标
3.3 对比实验与分析





4 结论
猜你喜欢
艺术家(2023年8期)2023-11-02
小哥白尼(军事科学)(2022年2期)2022-05-25
疯狂英语·新策略(2019年10期)2019-12-13
红领巾·萌芽(2019年8期)2019-08-27
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
电子制作(2016年15期)2017-01-15
系统工程与电子技术(2016年2期)2016-04-16
CHIP新电脑(2016年3期)2016-03-10
电测与仪表(2014年1期)2014-04-04
