
基于局部线性重叠聚类算法的网络攻击溯源分析方法*
2024-02-16 08:47王亮,钟夫,黄健
通信技术 2024年1期
王 亮,钟 夫,黄 健
(中电科网络安全科技股份公司,四川 成都 610095)
0 引言
随着网络技术的发展和信息化程度的提高,网络规模和信息系统也日趋庞大和复杂,科技的进步提升了人们的工作效能和生活便利,但也给网络空间带来了更大的安全风险和威胁。针对高价值目标,出于商业或政治动机,网络攻击者个体或团队不再沿用过往单一的攻击模式,而是在一个较长周期内,结合多种先进的方法、工具及技术,持续和隐蔽地损害目标利益。因此,通过入侵检测系统、防火墙、Web 应用防护系统(Web Application Firewall,WAF)等传统网络安全防护体系提供的不完备的、孤岛式的检测信息来识别风险和威胁,存在信息冗余高、虚检和漏检频繁的问题[1]。为了应对日趋严峻的网络安全形势,很多企业搭建了安全运营中心(Security Operations Center,SOC)体系,集中化管理安全产品的日志、事件和告警,并且平台大都提供基于规则匹配的关联分析机制,但由于普遍缺乏安全风险上下文,且只能识别已知威胁,信息孤岛效应还是没有得以解决[2]。近来,依托大数据、人工智能技术的迭代演进,以及高级持续性威胁的研究,出现了一些面向攻击溯源的分析方法,大体思路为基于海量数据,结合网络攻击过程模型[3],根据资产、安全产品日志和网络流量的时间和空间相关性,来构建大数据[4-9]、机器学习[10-11]或者知识图谱[12-17]的检测模型,还原攻击过程和路径;但这些方法或多或少面临海量数据的计算复杂度过高,欠缺高质量的标签数据,没有先验信息和专家知识,复杂威胁过程还原能力弱,攻击路径溯源容错率低等问题,因此尚无有效的规模应用。
对此,本文提出了一种基于局部线性重叠聚类算法的网络攻击溯源分析方法。该方法首先挖掘安全产品上报日志中的攻击特征,据此对资产、海量安全事件进行社团划分;其次综合分析社团中攻击链阶段、攻击时序、攻击源和目标信息等的局部线性关系,通过重叠聚类算法进行攻击路径溯源。该方法较好地解决了上述海量安全事件处理复杂度高、攻击路径溯源容错率低等问题。
1 相关技术
1.1 溯源图谱
溯源图谱是根据设备上报告警生成的具有有向图结构的数据,可以用于描述系统行为。所有系统级别的实体被当作溯源图中的节点,而实体之间的操作被当作溯源图的边。根据目前设备上报的内容分析,将唯一IP 作为实体,IP 与IP 之间的交互事件类型作为边,因此定义如下:
定义1:“溯源图谱”是一个带有标签的有向无循环图,G=(V,E,L,M,K,Z)。其中,V是图中的顶点,表示攻击过程事件中的网络实体集合;E是图中边的集合,描述网络实体之间的关系;L是网络实体数据类型标签集合;M是网络实体和标签的映射集合;K表示V事件的集合;Z表示E事件的集合。
定义2:“网络实体”是网络中存在的IP 地址。
定义3:“网络实体关系”表示网络实体之间的相互作用和联系。
具体的溯源图谱如图1 所示。
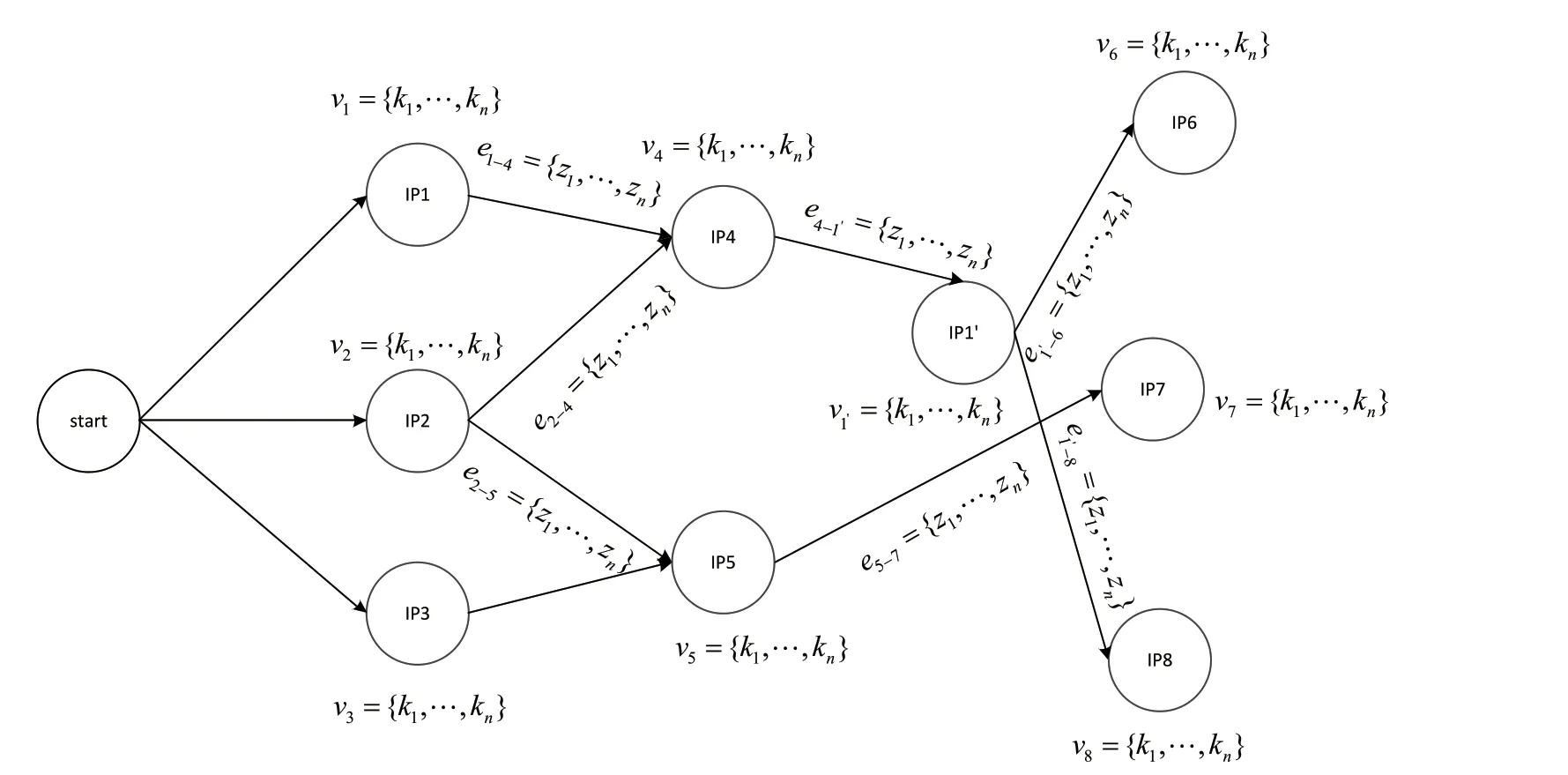
图1 溯源图谱
如图1所示,顶点V、边E、实体类型标签集合L、实体与标签的集合M、顶点事件集合K、边事件集合表示如下:
1.2 攻击溯源
攻击溯源是在溯源图G中以v为开始节点,使得G中存在li条路径,当该li的概率超过某个阈值时,则为G的可疑网络攻击链路,其数学定义为:
式中:top_prob为计算攻击链路的概率函数,thread表示阈值。,如图2所示。
图2 中,加粗实线表示最有可能的攻击链路,虚线表示的可行性较低一些,细实线表示不太可能的攻击链路。其中,z表示边事件集合,k表示节点事件集合,如果该事件参与了链路中相关攻击过程,则对其进行标注。
2 基于重叠聚类技术的攻击溯源分析
攻击场景由事件组成,在形成的社团中,事件数量较多,且事件与事件相互形成的攻击特性的事件组合也非常多,无法通过枚举的方式进行一一判断符合攻击场景的事件组合,因此本文选用Cyber Kill Chain 网络攻击模型进行建模,在离散的攻击事件之间建立连接并构建符合认知的攻击场景,从而辅助执行攻击行为检测、评估和防御等各个流程[18]。Cyber Kill Chain 模型将网络攻击链总结为7 个步骤,即侦察目标、投递植入、漏洞利用、安装驻留、命令控制、行动收割、清除痕迹。在利用该模型进行攻击路径溯源的过程中,由于某一个攻击步骤是下一个攻击产生的前提,满足攻击路径溯源的组合事件较多,且存在某一个步骤属于其他攻击路径溯源中的攻击步骤,因此攻击路径溯源存在重叠性,为此定义其数学模型如下:
给定数据集X={x1,x2,…,xn}∈ℝn×m,使得f(X)=O,其中O={(x1,x2,…,xn),(xo,xp,…,xi),L,(xf,xm,…,xj)}表示数据集X被分配到不同的攻击场景集合中。
本文设计的攻击溯源分析流程包括数据源采集、构建溯源图、划分攻击社团和通过重叠聚类进行攻击溯源4 个步骤,如图3 所示。
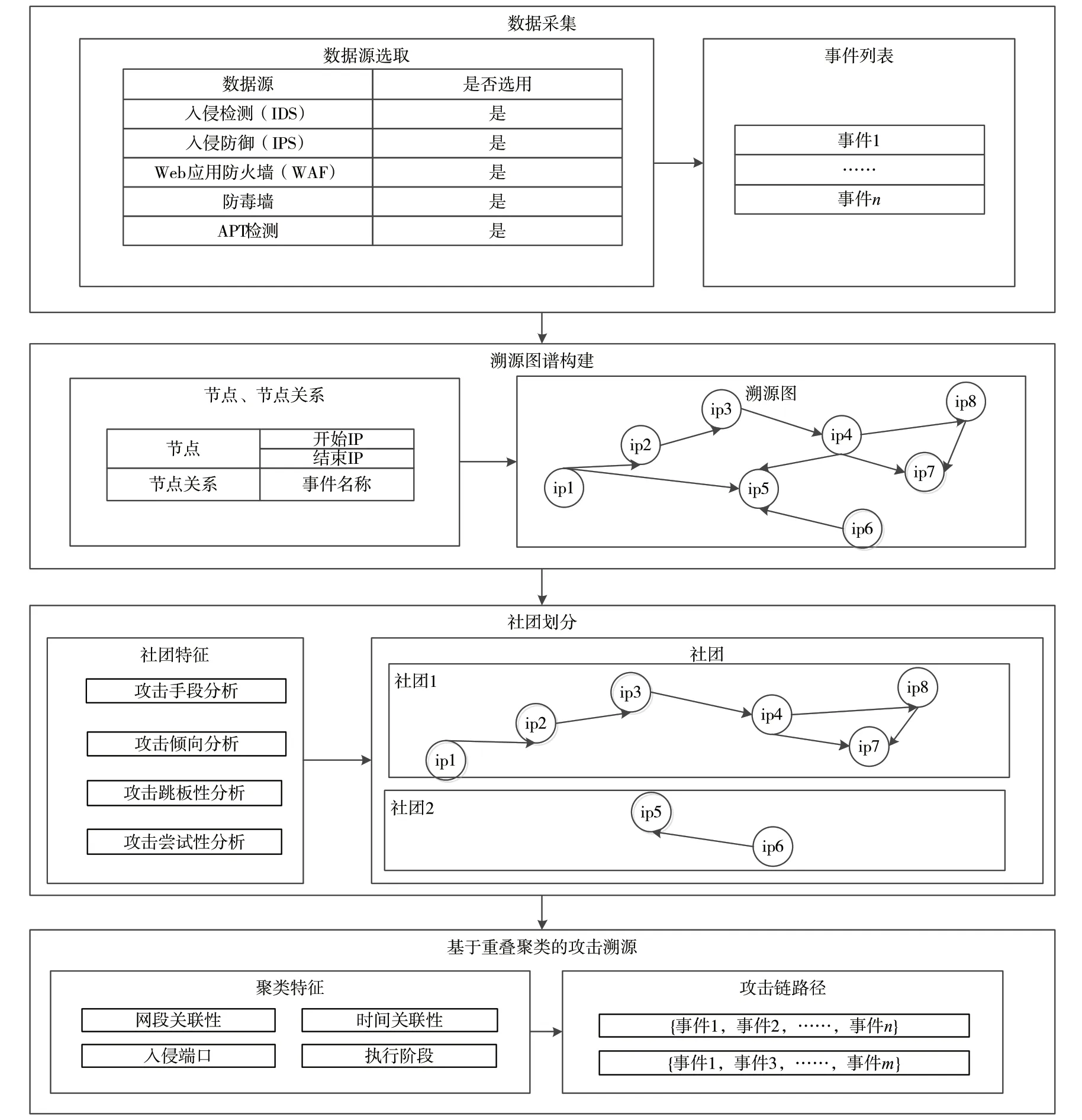
图3 攻击溯源的分析流程
在图3 中,数据采集主要来自安全设备上报的日志,作为构建溯源图的数据输入。考虑到数据量规模带来的计算复杂度,利用网络攻击的社团性进行社团划分,从而减轻其溯源的计算量,最后应用于重叠聚类算法对社团进行攻击溯源分析,得到可疑度高的攻击溯源相关事件。
2.1 数据源采集
常见的数据源有流量检测日志、安全设备日志、访问记录、服务运行日志、用户认证记录、pcap 日志包、威胁情报、服务运行状态等。根据目前所具有的采集能力,采集的数据主要来自入侵检测(Intrusion Detection System,IDS)、入侵防御(Intrusion Prevention System,IPS)、Web 应用防火墙(Web Application Firewall,WAF)、防毒墙、高级持续性威胁(Advanced Persistent Threat,APT)检测设备,并按照相关事件模型定义进行抽取,其攻击阶段属性符合Kill Chain 模型,按照时间顺序进行事件存储。
2.2 构建溯源图
第1 个阶段主要是构建溯源图结构,从图谱的结构出发对网络攻击进行分析,因此根据定义1、2、3 构建溯源图,其中,原始数据分为两类:一类是节点事件,形成节点,该事件只有HostIP 值,没有源IP 和目的IP 的值;另一类是节点与节点产生边的事件,该事件具有源IP 和目的IP 的值。
将第1 类事件产出的所有事件形成一个节点,并将该节点包含的所有事件用数组的属性保存;第2 类事件对应形成节点与节点的边关系,并与第1类事件具有相同的IP 进行事件融合,若源IP 或者目的IP 与第1 类事件IP 相同,则不生成新的节点,否则添加新的节点。
2.3 基于攻击特性的溯源图社团划分
由于原始数据在一段时间中产生的量特别巨大,且从攻击的宏观性角度来看,其具有社团性的特点,因此在这个阶段的主要目标是通过社团的划分减少攻击溯源的计算量,以及在分割的过程中减少攻击事件的错误划分。对此,根据定义节点间的攻击性的权重向量对社团进行划分,且社团划分为无监督划分,根据权重向量对社团的增益性进行划分。
针对溯源图谱中的攻击特性,经过相关安全专家讨论,设计如表1 所示的节点间事件数量的变化性、节点间的交互性、节点间的事件类别多样性、节点所处溯源网络结构的最大深度4 个指标,作为溯源图中边的攻击特性衡量的向量,并利用信息熵对这4 个指标进行线性加权,得到边的权重。

表1 溯源图谱攻击特征
根据表1,进行如下定义。
定义4:单位时间内节点间数量变化np1=max(在一段时间内,上一时刻与下一时刻产生的斜率),表示一种攻击的可能性。
定义6:事件类别np3=max(在一段时间内,上一时刻与下一时刻产生的斜率),表示攻击手段的变化性。
节点边的权重为以上定义的4 个特征的信息熵,并利用相关社团划分算法对溯源图进行社团划分,其中信息熵计算公式如下:
2.4 重叠聚类
研究发现,仅利用X={x1,x2,…,xn}的Kill Chain模型的攻击阶段属性来构建离散攻击事件的攻击场景有局限性,如分布式拒绝服务(Distributed Denial of Service,DDOS)攻击在事件的表现上具有时间性的特点,为此参考文献[19]中事件攻击相似性的处理,使用时间关联性、网段关联特性、入侵端口、执行的阶段性这4个特征作为攻击路径溯源的依据,具体特征如表2 所示。

表2 事件特征
根据表2 的事件特征,本文定义特征计算方式如下文所述,其中ai和aj分别代表两组数据且j>i。
(1)时间引起的事件关联性:时间反映了攻击事件之间的前后关系,随着时间的推移,两个攻击事件之间的关联性逐渐减弱。其相似性度量可定义为:
(2)网段关联特性:一般而言,攻击方的IP地址大都从同一网段中发起,因此同一攻击方在IDS 告警日志的源IP 或目的IP 上具有相似性。其相似性度量可定义为:
式中:M=max{H(ai,sIP,aj,sIP),H(ai,sIP,aj,dIP)},H(ai,dIP,aj,sIP),H(ai,dIP,aj,dIP),其中H函数是两个IP 地址的二进制表示从左到右位相同的数目,sIP指源IP 地址,dIP指目的IP 地址。
(3)入侵端口:假使攻击方使用不同的工具进行服务器入侵访问并成功得手,那么这两条数据的HTTP 请求方法、服务器端口号、客户端端口号、客户端环境、HTTP 响应码应该具有相同之处。目前原始信息中只有相关端口,因此其相似性度量定义为:
(4)执行的阶段性:从杀伤链的特点来看,前一条事件的攻击方法造成的结果可能是展开下一条事件中的攻击方法的前提条件。其相似性度量可定义为:
目前大部分对攻击路径溯源的方法都是非重叠性的处理,使得攻击路径溯源的容错率较低。虽然有利用重叠算法进行直接聚类的,但是在构造攻击溯源路径特征进行距离计算时,存在对属性特征变化不敏感的情况。为此本文提出基于局部线性重叠的聚类算法对攻击路径溯源进行聚类,具体计算过程如下文所述。
(1)局部线性处理。xi与xj在欧式空间中的关系如图4 所示。为了使得特征距离计算具有敏感性,利用该相互关系进行表示。同时,为了满足xi在高维空间中的稀疏性,利用局部线性进行处理,并且为了关注xi形成的所有可能的攻击路径,利用近邻点进行表示。
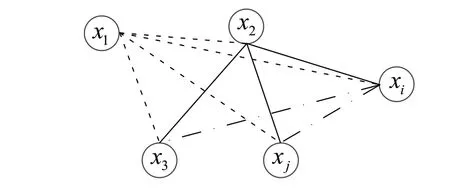
图4 局部近邻点
因此,xi由其k个近邻点表示:
式中:lj为噪声点,fjk为相似性。
(2)K 近邻点的确定。K 近邻点的确定大部分是利用K 最近邻(k-Nearest Neighbor,KNN)算法找出其k个近邻点。在攻击溯源路径中,特别是路径的最后一步,其与之相邻的点往往小于k个点,因此k近邻点是不固定的,故而通过对xi利用kmeans 进行聚类,确定近邻点个数。
(3)fjk的权重求解。为了使得fjk尽可能与X矩阵相似,构造的数学模型如下:
式中:||·||F为范数,λ是为了引入噪声添加的系数。
(4)重叠聚类。本文参考基于图熵聚类的重叠社区发现算法[20]中利用信息熵的思路,进行重叠聚类算法设计,步骤如下:
①将数据集中的xi作为候选节点,从候选节点中选取部分节点存入种子集合中;
②随机选取种子集合中的一个节点,并加入其所有邻居节点组合成一个类;
③计算聚类中邻居节点的熵值,如果熵值降低则移除;
④计算其聚类外的边界点的熵值,如果熵值降低则添加;
⑤输出具有最小熵值的聚类并从种子集中删除该种子;
⑥重复以上步骤直到种子集中没有种子剩余。
3 应用列举
本文提出的算法已作为安全运行监管系统的核心能力应用于威胁监测模块,在某企业的实际使用中,针对不同厂商上报的威胁日志,安全运行监管系统会对网络攻击类和恶意代码类威胁事件按照标准数据模型进行转换,并按事件模型定义对齐进行信息补全,再进行数据抽取、构图、分析,最后利用相关的数据构造溯源图,如图5 所示。

图5 溯源图构建流
根据2.3 节的溯源图边权重的定义计算方式进行社团划分,选用Lovain 算法进行社团划分,结果如图6 所示。
针对2.4 节所筛选出的事件特征,使得特征之间具有相似性和阶段性,将相似的进行聚合,从而得到候选攻击链事件。由于没有任何先验信息和专家知识,聚类算法以相似性度量为基础能够有效识别和挖掘无标签数据中的潜在聚簇信息,本文利用重叠聚类进行相关聚类,结果如图7 所示,其中具有攻击特性的攻击事件链集合1 的事件如表3所示。
通过以上分析可以看出,此模型算法具有如下优点:
(1)处理告警信息中的误报问题。主要体现在重叠聚类对事件特征进行稀疏的过程中,将与攻击特性不相关的事件进行去除。
(2)处理告警信息中漏报的问题。主要体现在重叠聚类方法对具有攻击特性的事件链进行聚合的过程中,将具有阶段性、时间关联性、端口和网段的同源性数据拉近。kill chain 模型的攻击链的7个阶段分别为:侦察目标—投递植入—漏洞利用—命令控制—安装驻留—行动收割—清除痕迹。因此,此过程中可能存在“命令控制”的漏报事件,需要相关安全人员进行排查。
4 结语
本文利用安全设备上报的日志数据在溯源图谱的定义上构建相关图谱,在降低攻击路径溯源的计算复杂度和计算量的基础上,提取溯源图谱具有攻击特性的边权重,并利用Lovain 算法进行社团划分,将溯源图谱拆分为具有攻击特性的溯源子图社团。最后利用本文提出的基于重叠聚类技术进行攻击溯源分析。实验结果表明,该算法设计能够有效对攻击进行溯源,并有效地改善溯源中误报和漏报的缺点。
猜你喜欢
阅读(中年级)(2022年9期)2022-10-08
华人时刊(2021年13期)2021-11-27
少先队活动(2020年12期)2021-01-14
心声歌刊(2020年4期)2020-09-07
军事文摘(2017年16期)2018-01-19
小学生(看图说画)(2017年6期)2017-11-06
中成药(2017年3期)2017-05-17
中学生(2016年13期)2016-12-01
领导科学论坛(2016年9期)2016-06-05
电子设计工程(2014年19期)2014-02-27
