
一种多线程概念约简算法
2024-02-20 11:58祁斌祁建军李俊安赵思雨折延宏
西安交通大学学报 2024年2期
祁斌,祁建军,2,李俊安,赵思雨,折延宏
(1. 西安电子科技大学计算机科学与技术学院,710071,西安; 2. 新疆政法学院信息网络安全学院,844000,新疆图木舒克; 3. 咸阳师范学院数学与统计学院,712000,陕西咸阳;4. 西安石油大学理学院,710065,西安)
德国数学家Wille于20世纪八十年代为重构格理论提出了形式概念分析(formal concept analysis,FCA)[1-2]。该理论自提出至今得到了很大的发展,已经突破了格论自身,被广泛应用到诸如数据挖掘[3-4]、软件工程[5-6]、知识工程[7-8]、推荐系统[9-10]和信息检索[11-12]等领域,成为解决知识发现问题的重要理论和工具之一。
概念约简是形式概念分析理论的一个新的研究方向,由魏玲等[13-14]于2018年提出。概念约简的目标是获取保持二元关系不变的极小概念集,这样可以在完全不损失形式背景原始信息的情况下,减少概念数量,降低使用形式概念分析解决问题的复杂性。目前,概念约简算法相对较少,魏玲等[14]在2020年提出了基于二元关系的概念约简算法。Zhao等[15]在文献[14]的基础上进一步研究,提出代表概念矩阵的定义,简明直观地展示了二元关系与概念之间的联系,并给出了基于代表概念矩阵的串行概念约简算法(serial concept reduction,SCR)。谢小贤等[16]从布尔运算的角度研究了保持二元关系不变的概念约简。马文胜等[17]针对计算部分概念约简的问题,提出同效关系,并给出通过同效关系求解概念约简的方法。李俊余等[18]提出三元概念约简,可保持三元背景中所有的三元关系不变。王霞等[19]提出一种基于概念可辨识矩阵对概念类别进行判定的方法。刘津等[20]提出了基于概念可辨识矩阵的对偶三支概念约简方法。
SCR算法将概念通过对象和属性分别聚类的方式构建代表概念矩阵,并使用代表概念矩阵计算概念约简,其时间复杂度低于文献[14]和文献[16]中概念约简算法的时间复杂度,较二者具有更快的执行速度,但SCR算法中并没有使用多线程方法,执行效率仍然不高。针对此问题,提出一种多线程概念约简算法(multi-thread concept reduction, MTCR)。MTCR算法使用构建代表概念矩阵的思想,通过两个线程分别对对象集和属性集单独处理,计算每个对象的对象代表概念集和每个属性的属性代表概念集,并以多线程并行计算方式获取任意对象的对象代表概念集和任意属性的属性代表概念集中共有概念,从而构建出代表概念矩阵。本文是在多核环境下运行多线程程序,通过使用多线程,提高概念约简算法的执行效率。
1 概念约简基础理论
先给出形式概念分析的基础知识。
定义1[1]称(G,M,I)为一个形式背景,其中G={g1,…,gp}为对象集,每个gi(i≤p)称为一个对象;M={m1,…,mq}为属性集,每个mj(j≤q)称为一个属性;I为G和M之间的二元关系,即I⊆G×M。若(g,m)∈I,则表示对象g具有属性m,也记为gIm。
例1:表1是一个形式背景(G,M,I),其对象集G={1,2,3,4,5},属性集M={a,b,c,d,e}。表中将(g,m)∈I记为1,(g,m)∉I记为0。

表1 一个形式背景(G, M, I)
对于形式背景(G,M,I),在对象子集X⊆G和属性子集B⊆M上可以定义一对对偶算子
X*={m|m∈M,∀g∈X,gIm}
B*={g|g∈G,∀m∈B,gIm}
其中X*表示X中所有对象共同具有的属性集合,B*表示共同具有B中所有属性的对象集合。
对于任意的X⊆G,B⊆M,若X*=B且B*=X,则称(X,B)为形式概念,简称概念。其中X称为概念的外延,B称为概念的内涵。
将形式背景(G,M,I)所有形式概念的集合记为L(G,M,I)。对于任意的(X1,B1),(X2,B2)∈L(G,M,I),定义如下的偏序关系
(X1,B1)≤ (X2,B2)⟺X1⊆X2(B1⊇B2)
任意两个概念的下确界、上确界为
(X1,B1)∧(X2,B2)=(X1∩X2, (B1∪B2)**)
(X1,B1)∨(X2,B2)=((X1∪X2)**,B1∩B2)
从而L(G,M,I)形成一个完备格,被称为概念格。
例2:例1中形式背景构建的概念格如图1所示。为了使用方便,本文中所有概念的外延、内涵都以罗列其中元素的序列形式给出,并对所有概念进行编号。
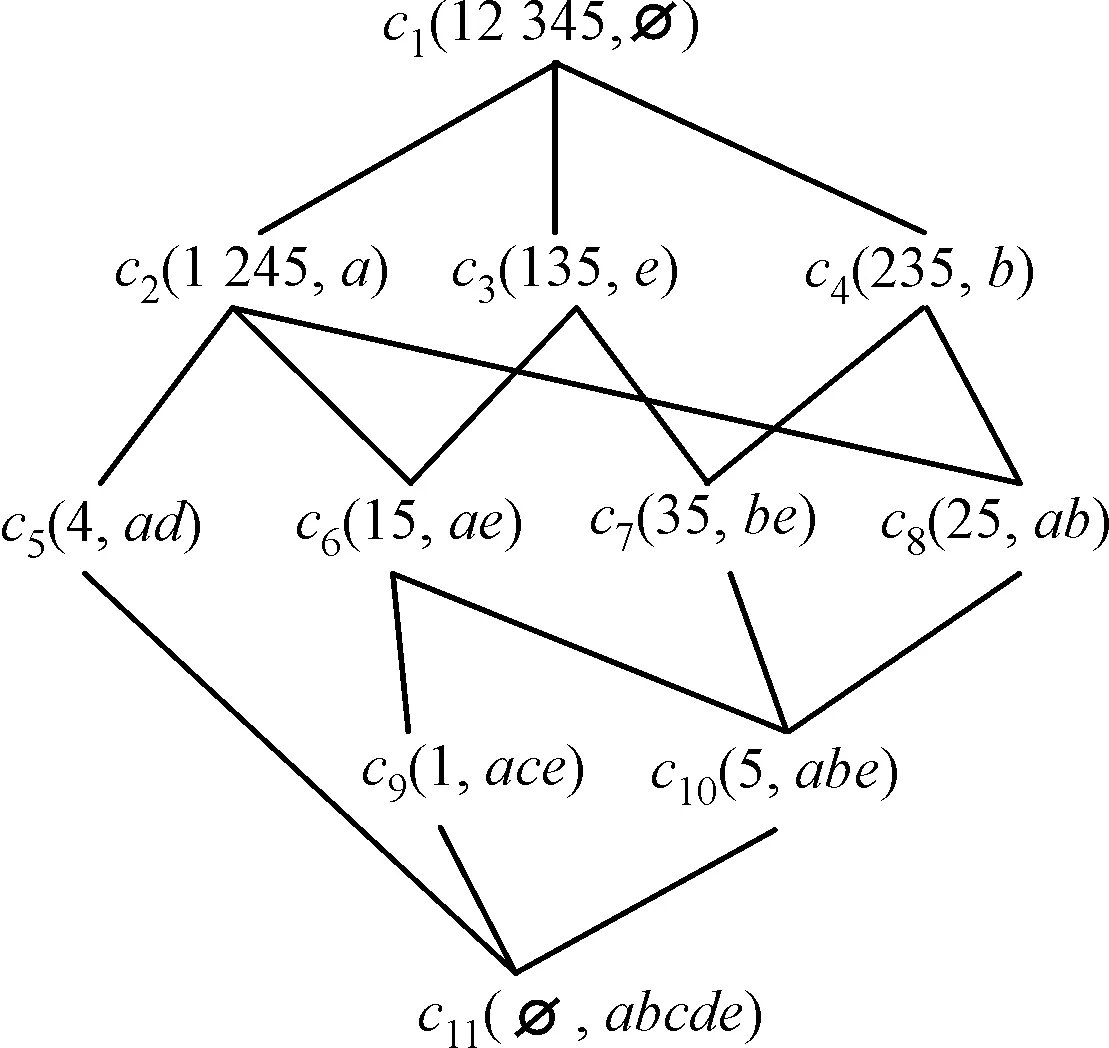
图1 L(G,M,I)Fig.1 L(G,M,I)
概念格虽然可以清晰地展示形式背景中概念之间的层次关系,但是在知识还原方面,概念格中的概念信息存在冗余,而通过概念约简仅用部分概念就可以完全还原形式背景的全部信息。下面给出概念约简的相关定义。
定义2[14]设(G,M,I)是一个形式背景,L(G,M,I)是概念格,F⊆L(G,M,I)。如果I=∪(X,B)∈F(X×B),则称F为保持二元关系I不变的概念协调集;若对任意的(Xi,Bi)∈F,F′=F{(Xi,Bi)},有I≠∪(X,B)∈F′(X×B),则称F为保持二元关系I不变的概念约简。
注由文献[15]可知,概念格中顶元与底元均不存在于概念约简中。因此,这两种概念在之后的讨论中不予考虑。
定义3[15]设(G,M,I)为形式背景,gi∈G,mj∈M。如果存在(X,B)∈L(G,M,I),满足gi∈X且mj∈B,那么称(X,B)为(gi,mj)的一个代表概念。记REP((gi,mj))={(X,B)∈L(G,M,I)|(gi,mj)∈X×B},称REP((gi,mj))为(gi,mj)的代表概念集;记Λ=(REP((gi,mj)),gi∈G,mj∈M)|G|×|M|为代表概念集REP((gi,mj))构成的矩阵,称Λ为(G,M,I)的代表概念矩阵。
定义4设(G,M,I)为形式背景,gi∈G,mj∈M。如果存在(X,B)∈L(G,M,I),满足gi∈X,那么称(X,B)为对象gi的对象代表概念,记REP(gi)={(X,B)∈L(G,M,I)|gi∈X},称REP(gi)为对象gi的对象代表概念集;若存在(X,B)∈L(G,M,I),满足mj∈B,那么称(X,B)为属性mj的属性代表概念,记REP(mj)={(X,B)∈L(G,M,I)|mj∈B},称REP(mj)为属性mj的属性代表概念集。
根据对象gi的对象代表概念集和属性mj的属性代表概念集的定义,可以得到如下性质。
性质1设(G,M,I)为形式背景,gi∈G,mj∈M,则有REP((gi,mj))=REP(gi)∩REP(mj)。
例3:L(G,M,I)中每一个对象的对象代表概念集和每一个属性的属性代表概念集分别如表2和表3所示。

表2 例1中的REP(gi)

表3 例1中的REP(mj)
例1中代表概念矩阵Λ如下所示。
矩阵共有5行5列。第i行第j列的代表概念集表示外延包含第i个对象gi,同时内涵包含第j个属性mj的所有代表概念。代表概念由对象gi的对象代表概念集REP(gi)和属性mj的属性代表概念集REP(mj)做交运算获得。例如代表概念矩阵第1行第1列的概念集合由对象1的对象代表概念集{c2,c3,c6,c9}和属性a的属性代表概念集{c2,c5,c6,c8,c9,c10}做交运算获得,即满足外延包含对象1同时内涵包含属性a的所有概念为{c2,c6,c9}。空集∅表示不存在相应的代表概念。
为了得到概念约简,可以将代表概念矩阵中的代表概念集罗列,并在每个代表概念集中任取一个概念进行组合,得到概念协调集,其中极小的集合就是概念约简。具体方法由命题1给出。
命题1[15]设(G,M,I)为形式背景,L(G,M,I)是其概念格,对任意的(gi,mj)∈I,记代表概念函数f(Λ)=ΛREP((gi,mj))∈Λ(∨(X,B)∈REP((gi,mj))(X,B)),则f(Λ)所对应的极小析取范式中的所有合取式为该形式背景所对应的概念约简全体。
在代表概念矩阵中可以很明显发现,代表概念集之间可能存在包含关系。这种包含关系使代表概念矩阵中存在大量重复信息,造成信息冗余。为了降低概念约简的计算复杂度,提升概念约简执行效率,可以通过删除包含元素,保留被包含元素的方式,将代表概念矩阵简化。简化后的代表概念矩阵称为最小代表概念矩阵。上面的代表概念矩阵简化结果如下
Λmin=
由例3中最小代表概念矩阵Λmin,可以得到4个概念约简结果为{c5,c7,c8,c9}、{c2,c4,c5,c7,c9}、{c2,c3,c4,c5,c9}和{c3,c4,c5,c8,c9}。
2 MTCR概念约简算法
2.1 SCR概念约简算法
图2为使用SCR算法计算概念约简的流程图,主要包含4个步骤。
(1)计算概念:将输入的形式背景通过概念格构建算法计算生成所有形式概念。
(2)计算代表概念矩阵:计算所有对象的对象代表概念集和所有属性的属性代表概念集,并通过任意对象的对象代表概念集和任意属性的属性代表概念集中的共有概念构建代表概念矩阵。
(3)计算最小代表概念矩阵:判断代表概念矩阵中代表概念集之间的包含关系。若两个不同的代表概念集之间存在包含关系,则删除包含的代表概念集,保留被包含的代表概念集。若代表概念矩阵中任意两个代表概念集之间均不存在包含关系,则该矩阵为最小代表概念矩阵。
(4)计算概念约简结果:计算最小代表概念矩阵中所有非空代表概念集极小析取范式中的所有合取式获得概念约简。
在上述4个步骤中,因为第1步和第4步的算法已相对成熟[21-25],所以在概念约简中使用现有算法,SCR算法只提出第2步和第3步的算法。第2步是SCR算法的核心步骤,也是占用时间最长的步骤,因此MTCR概念约简算法对第2步实现多线程并行计算方式改进,其余步骤与SCR算法保持一致。

图2 概念约简计算过程流程图Fig.2 The flow chart of concept reduct calculation
2.2 MTCR概念约简算法
计算代表概念矩阵分为两步,先计算对象代表概念集REP(gi)和属性代表概念集REP(mj),再计算REP(gi)和REP(mj)中的共有概念。
MTCR算法在计算代表概念矩阵时,先以对象和属性为出发点,通过不同线程并行计算每一个对象gi的对象代表概念集REP(gi)和每一个属性mj的属性代表概念集REP(mj)。实现过程如算法1所示。
算法1:计算对象代表概念集和属性代表概念集。输入概念集合concepts,输出为对象代表概念集objs[i]和属性代表概念集attrs[j]。
1 Process1:
2 fori= 0 to |G|
3 for (X,B) in concepts
4 ifgi∈X
5 Add (X,B) to objs[i];
6 end if
7 end for
8 end for
9 Process2:
10 forj=0 to |M|
11 for (X,B) in concepts
12 ifmj∈B
13 Add (X,B) to attrs[j];
14 end if
15 end for
16end for
算法1创建了线程1、线程2,两个线程并行执行。算法第1行到第8行,创建线程1并计算每一个对象的对象代表概念集。遍历L(G,M,I)中的概念,将外延中包含对象gi的所有概念的标志以位运算的方式存于objs[i]中。
算法第9行到第16行,创建线程2并计算每一个属性的属性代表概念集。遍历L(G,M,I)中的概念,将内涵中包含属性mj的所有概念的标志以位运算的方式存于attrs[j]中。
通过对象代表概念集REP(gi)和属性代表概念集REP(mj)可以计算出(gi,mj)的代表概念集。在计算过程中,每计算一个代表概念集,都会查询相应的对象代表概念集和属性代表概念集,但不同代表概念集的计算过程互不影响。因此为了提高计算效率,可以使用多线程方式并行计算不同代表概念集。将形式背景中的对象依次放入p个队列,并为每个队列分配线程,通过多线程方式并行计算出任意对象的对象代表概念集和任意属性的属性代表概念集的交集,最终得到代表概念矩阵。实现过程如算法2所示。
算法2:计算代表概念矩阵。输入对象代表概念集objs[i]和属性代表概念集attrs[j],输出代表概念矩阵represented[i][j]。
1 for obj in context
2 count ++;
3 Store(obj, queue[count%p]);
4 end for
5 forq=0 top-1
6 new process;
7 for obj in queue[q]
8i←obj;
9 forj=0 to |M|
10 if objs[i]∩attrs[j] ≠ Ø
11 represented[i][j]= objs[i]∩attrs[j];
12 end if
13 end for
14 end for
15end for
算法第1行到第4行,将形式背景中的对象依次存入p个队列。
算法第5行到第15行,为每个队列分配线程,分别计算队列中所含对象的对象代表概念集和与每一个属性的属性代表概念集中的共有概念。由性质1可知,结果即为外延具有特定对象且内涵具有特定属性的概念集合,并将其存于代表概念矩阵represented中。
算法2以形式背景中对象为分配数据依次放入p个队列,计算任意对象的对象代表概念集与任意属性的属性代表概念集中的共有概念构建代表概念矩阵。若将算法2中的对象与属性互换,以属性作为分配数据放入p个队列,同样可以得到代表概念矩阵,并且与算法2计算得到的代表概念矩阵一致。为了使多线程负载均衡,当形式背景中对象数大于等于属性数时,MTCR算法使用以对象为分配数据的方式进行计算;当形式背景中的对象数小于属性数时,MTCR算法以属性为分配数据的方式进行计算。
通过多线程并行计算对象代表概念集和属性代表概念集的方法计算代表概念矩阵,极大地提高了执行效率。
3 实验结果与分析
实验在Apple M1 Pro 10核、主频为3.20 GHz、内存为16 GB的便携式计算机上进行,分别对例1中形式背景和4种UCI数据集进行处理,分析SCR算法与MTCR算法在性能上的区别,表明MTCR算法可以准确得到概念约简结果,并且在运行速度上快于SCR算法。在对比实验2中使用随机数据集,分别考虑属性数量、对象数量和密度大小对MTCR算法性能的影响。
实验中计算概念步骤和计算概念约简结果步骤分别使用Andrews[24]提出的InClose3算法和智慧来等[25]提出的极小覆盖法。为了直观对比MTCR算法相对于SCR算法在执行速度上的提升,我们仅比较计算代表概念矩阵和计算最小代表概念矩阵消耗的总时间,并计算提升效率。
例1中使用MTCR算法的实验结果如表4所示,其中t为计算概念约简所需时间。表4中概念约简结果与例3中计算得到的概念约简结果相同,表明MTCR算法的准确性。
对比实验1使用的UCI数据集是UCI Machine Learning Repository网站中提供的Balance-Scale、Car、Iris和Wine这4个数据集,对比SCR算法和MTCR算法在执行时间上的差异,对比结果如表5所示,MTCR运行时间为使用两个线程时所消耗的时间。SCR算法分别与1、2、4和8个线程的MTCR算法对比结果如图3所示。
通过对4个UCI数据集进行实验,由图3可以明确观察到使用MTCR概念约简算法在计算概念约简时,使用单线程情况下,与SCR算法计算时间几乎相同;使用2、4和8线程时,MTCR算法使用时间均少于SCR算法。当线程数不超过8时,线程数每增加1倍,计算速度可以提高约30%。
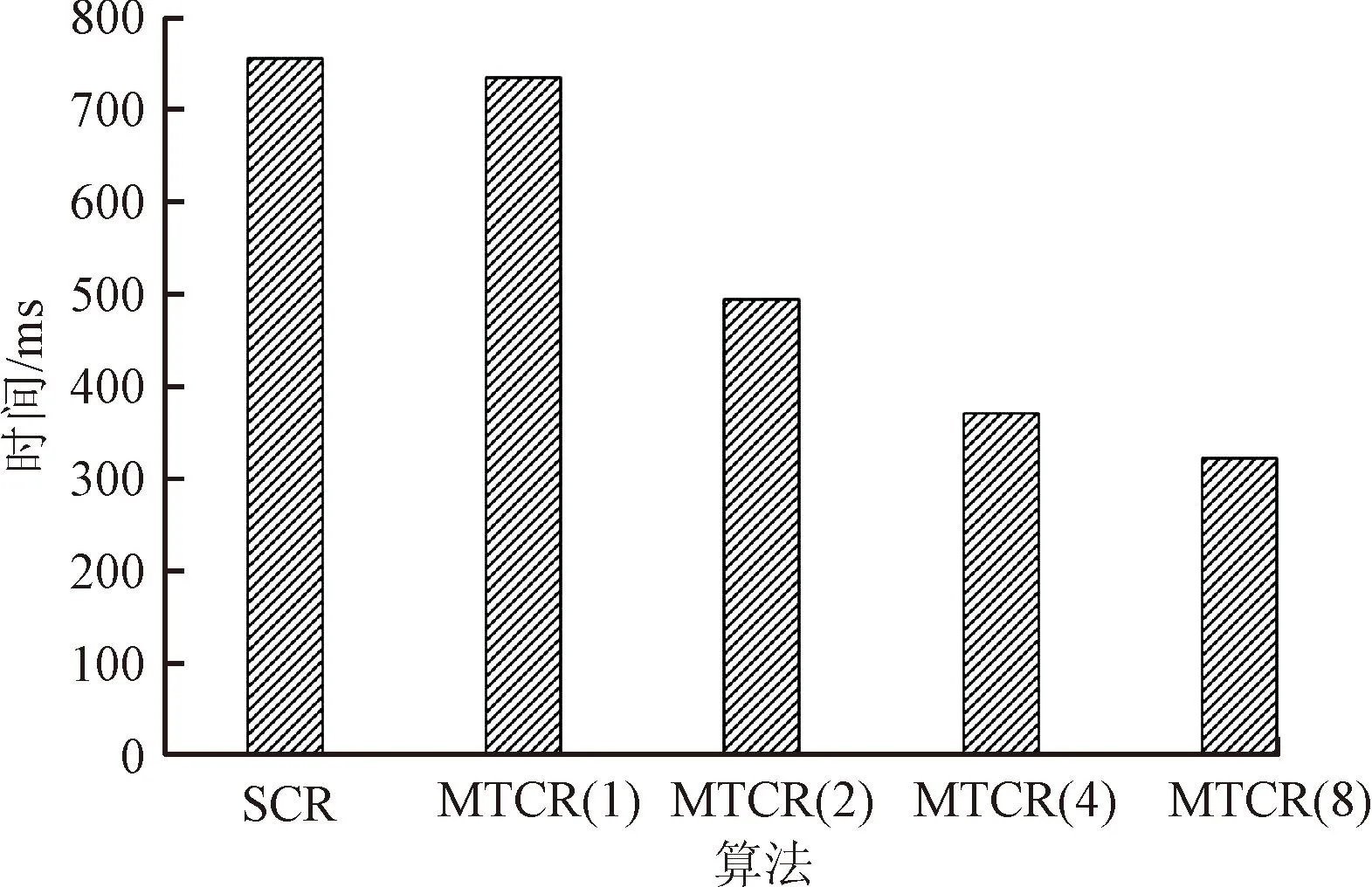
(a)Balance-Scale

(b)Car

(c)Iris
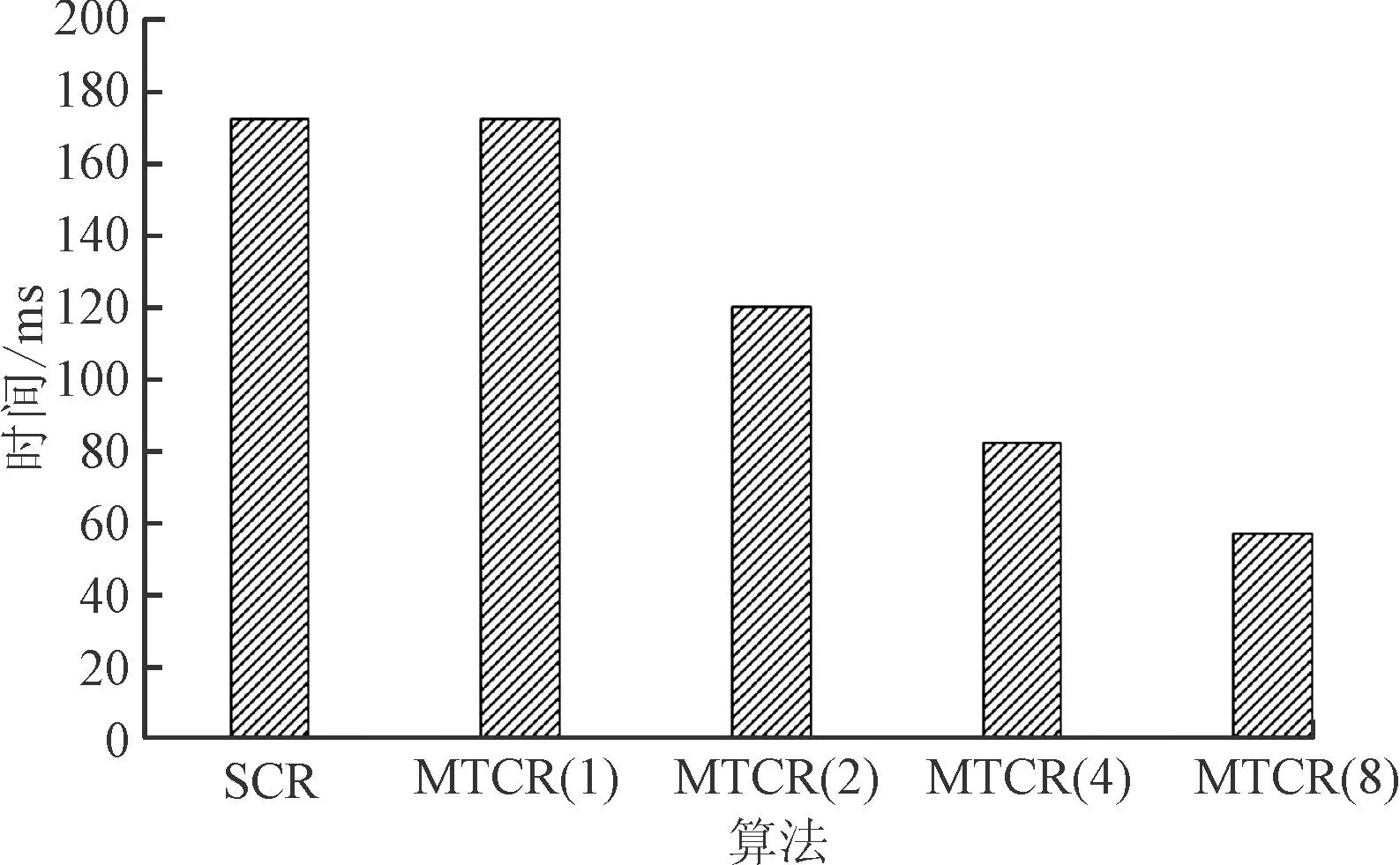
(d)Wine

表4 例1实验运行过程表

表5 4个UCI数据集实验结果
对比实验2,为了进一步验证MTCR算法的高效性,对随机数据进行实验,固定形式背景中其他变量,分别改变属性数量,对象数量和密度大小,分析对不同数量线程性能的影响,实验结果如图4所示。
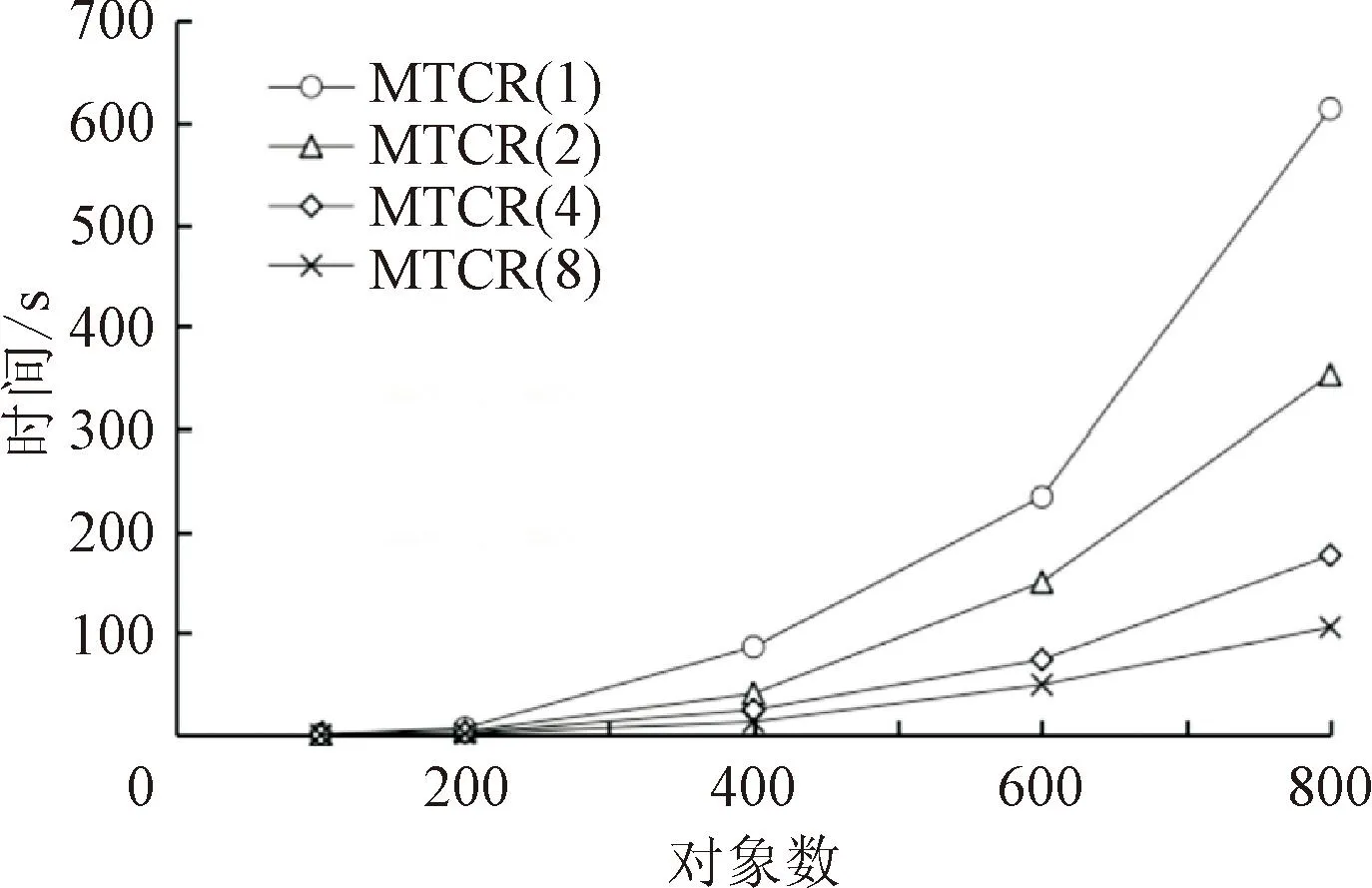
(a)对象数(|M|=30,d=30%)

(b)属性数(|G|=300,d=30%)

(c)密度(|G|=100,|M|=20)
图4(a)为固定形式背景的属性数量为30,密度为30%,对象数量的变化范围为100~800;图4(b)为固定形式背景的对象数量为300,密度为30%,属性数量的变化范围为25~45;图4 (c)为固定形式背景对象数为100,属性数为20,密度大小的变化范围为20%~100%。
在形式概念分析中,对象与属性呈对偶关系,对象数与属性数对MTCR算法的性能具有相同的影响。由图4中(a)、(b)可知,固定其他变量,仅改变对象数(属性数)时,MTCR算法计算时间随对象数(属性数)增加而增加,当对象数和属性数都较大时,形式背景中的概念数量呈指数倍增长,MTCR算法计算时间也呈指数倍增长。由图4(c)可知,固定对象数和属性数不变,形式背景密度处于80%左右时,概念数量相对较多,MTCR算法计算时间较长,密度趋于0%和100%时,概念数量相对较少,MTCR算法计算时间较短。
通过对UCI数据集和随机数据集的实验分析可知,MTCR算法使用的线程数量增长对算法效率的提升趋于稳定,当线程数不超过8时,随着线程数量每增加1倍,MTCR算法计算效率均可提速30%以上。但是,随着概念数量的增长,MTCR算法在使用固定数量的多线程情况下,计算所需时间随概念数量的增长呈指数倍增长。在处理较大规模的数据集时,应增加线程数量,以提高计算效率。
4 结束语
本文基于通过构建代表概念矩阵计算概念约简的方法,对SCR算法中计算过程复杂,执行效率低的部分提出并行化处理方案。通过对例1中的形式背景、UCI数据集和随机数据集的实验表明,MTCR算法能准确、快速地计算出概念约简的结果,极大提高概念约简算法的执行效率。当线程数不超过8时,随着线程数量每增加1倍,MTCR算法计算效率均可以提升30%以上。
猜你喜欢
汽车工程师(2021年12期)2022-01-17
当代陕西(2020年14期)2021-01-08
成都信息工程大学学报(2019年2期)2019-08-28
自动化学报(2018年2期)2018-04-12
成都信息工程大学学报(2017年1期)2017-07-21
环球市场(2017年36期)2017-03-09
贵州师范学院学报(2016年4期)2016-12-01
河南科技(2014年7期)2014-02-27
计算机工程与科学(2013年2期)2013-06-07
吉林建筑大学学报(2012年3期)2012-08-15
