
优化的传输线有限元法在电磁场中的分析及应用
2024-02-20 03:50阎秀恪钟立国任自艳张殿海
东北电力技术 2024年1期
方 锦,阎秀恪,钟立国,任自艳,张殿海
(沈阳工业大学电气工程学院,辽宁 沈阳 110870)
0 引言
在使用传统有限元法对大型电气设备进行电磁场数值分析时,为了提高计算精度,需要对结构模型进行较为精细的剖分,剖分产生的大量网格使得计算规模庞大,需要大量的计算资源和计算时间,有时甚至无法求解。为了提升有限元计算效率,学者们在网格剖分、方程组求解、并行计算等方面做了很多研究。
在有限元计算中非线性问题的求解会导致一些耗时问题。迭代法是非线性问题求解常用的方法,如直接迭代法、增量法、牛顿-拉夫逊方法等,其中牛顿-拉夫逊算法常常被使用,并不断得到改进。牛顿-拉夫逊方法在求解时需要通过修改全局Jacobi矩阵进行迭代更新。随着计算规模增大,全局Jacobi矩阵也变得十分巨大,修改全局Jacobi矩阵消耗大量的时间。
最初,传输线方法(transmission line model,TLM)被应用于研究波的传播理论,波的传播过程中入射和反射过程类似于非线性迭代过程,因此也被研究用于求解非线性问题。TLM法中电路网络节点电压方程中的导纳矩阵与FEM的系数矩阵具有相同的性质,根据对偶原理建立与有限元网络相对应的等效电路网络,因此用于求解电路网络的TLM方法,也可以用于求解有限元网络。TLM方法与有限元法相结合从而形成传输线有限元法(transmission line model-finite element method,TLM-FEM)。由于传输线的入射电压与反射电压之间存在时间延迟,混合电路网络可以解耦为线性部分和非线性部分。应用TLM方法的解耦特性,可将有限元网络转化为1个线性系统和若干个独立的非线性部分。
TLM-FEM起初应用于求解非线性的静磁场问题[1-8]。目前已经应用在电气设备电磁场和温度场的分析中[9-15],文献[16]在使用传输线有限元等效模型求解轴对称磁场问题时,在入射阶段采用并行求解器加快单步迭代计算速度。文献[17]结合传输线方法提出了一种黑盒电路模型提高了复杂问题解决能力。目前对于TLM-FEM的研究在入射阶段的线性方程组求解均使用LU分解法,未能充分利用全局矩阵对称稀疏的特点加速分解过程。同时反射阶段非线性负载两端电压的计算一般使用牛顿迭代法,迭代过程也消耗了很多时间。因此在入射阶段线性方程组的高效求解与反射阶段计算方法的研究可以提升整体求解效率。
本文推导了TLM-FEM的数学模型,将分段线性化方法引入到求解反射电压的松弛方法中,用于更新反射阶段的参数,以提高求解的效率和精度。根据单元系数矩阵计算及全局矩阵LDLT分解计算的特点,在GPU平台上实现了2个过程的并行计算。数学模型和算法均由C++语言自编程实现。将上述算法和程序应用于单相变压器的磁场计算,并与ANSYS仿真结果进行了比较和分析。
1 结合优化松弛方法的TLM-FEM建模
1.1 TLM-FEM模型
传统传输线迭代方法包含入射阶段和反射阶段。在含有非线性元件的电路中,无损传输线将线性系统和非线性元件连接在一起,根据传输线理论由于传输线特性导纳与终端导纳间存在不匹配现象,导致电信号在传输线上的传播会在两端不断反射。只有当传输线两端电压相等时,电路系统达到稳定状态能求出负载导纳两端的电压值,从而实现电路问题的求解。图1为非线性电路中第e个非线性负载的TLM方法的等效电路。
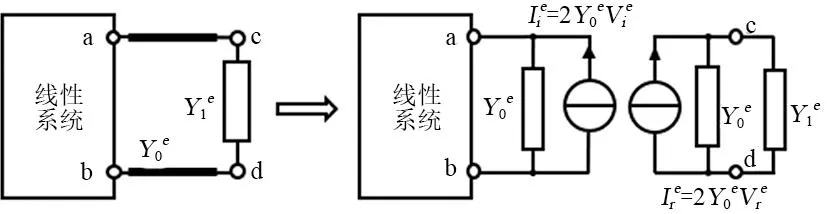
图1 非线性负载的TLM方法
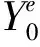
TLM法中电路网络节点电压方程的导纳矩阵与有限元方法的系数矩阵具有相同性质,以三角形单元为例,根据对偶原理,有限元单元系数矩阵对偶于电路单元导纳矩阵,节点磁位对偶于节点电压,右端激励项对偶于电路的电流源,因此可以得到如图2所示的传输线有限元的等效模型。

图2 传输线有限元等效模型的建立过程

传输线有限元等效过程主要分为3个步骤:一是先将在有限元三角形单元的边缘分别添加负载导纳,得到等效电路拓扑网络;二是在单元边缘与负载导纳之间添加1组传输线;三是将传输线有限元等效电路解耦得到入射和反射等效电路,最终建立传输线有限元等效模型。
当等效电路中有激励产生时,首先电压信号从各个单元的非线性负载入射进线性系统。此时传输线迭代方法的入射阶段可以被描述为
YV=I+Ii
(1)
式中:Y为入射阶段的全局系数矩阵;I为电流源激励向量;Ii为入射阶段等效电流源向量。
当传输线一端的负载导纳与传输线特性导纳之间存在不匹配现象,电压信号将会从线性系统反射回各个单元的负载导纳。此时TLM方法的反射阶段在各个负载导纳上独立进行,以端口ij的反射阶段的计算为例。
(2)
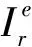
(3)
(4)
负载导纳与对应特性导纳间的不匹配,可以通过式(3)、式(4)修正。
后续迭代重复上述过程,只有当传输线两端电压差达到收敛误差则传输线迭代过程停止,同时输出式(1)中求解出的每个节点电位。
1.2 优化的松弛方法求解Vcd

图3 结合优化松弛方法的TLM迭代收敛过程


(5)
(6)

(7)

(8)
(9)
综上所述,在进行TLM-FEM迭代时,反射阶段的求解可以通过直接计算式(9)得到,计算结果用于更新式(1)中等效电流源。结合优化松弛方法的TLM-FEM求解流程的伪代码如图4所示。

图4 结合优化松弛方法的TLM-FEM程序
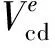
2 全局矩阵在GPUs上的形成与LDLT分解
2.1 单元系数矩阵在GPUs上的计算
在近年来,GPU由于其出色的并行计算能力被经常应用于大规模的数值计算,GPU目前采用单指令多线程执行模型,可以将计算任务分配在多个线程上同时处理,非常适合执行逻辑简单的大规模密集型计算任务。在TLM-FEM计算中,各个单元系数矩阵的计算是独立进行的,计算过程适合采用GPU单指令多线程的计算模式。以三角形单元为例,单元系数矩阵元素包括每个传输线导纳和线性部分导纳,单元系数矩阵表示为
(10)
式中:b、c的值与三角形节点坐标i、j、m有关;Δ为三角形单元的面积;线性单元的磁阻率ve是固定值,非线性单元会提前输入1个预设值。
由式(10)可知,每个单元的计算主要是利用有限元剖分信息执行乘法及加法操作,计算需要的内存少、逻辑相关弱,可设置1个或多个线程对每个单元执行计算操作。在CUDA平台上利用GPU上进行单元系数矩阵的并行计算,其过程分为3个步骤:
a. cudaMalloc申请计算所需要的内存空间,并由cudaMemcpy将参与计算的数据从主机端复制至设备端;
b. 根据剖分网格单元数量分配线程块的个数以及线程数量,调用内核函数在GPU上计算;
c. cudaMemcpy将计算结果从设备端复制回主机端,进行传输线有限元后续计算。
2.2 全局矩阵在GPUs上的LDLT分解法
在TLM迭代中,全局矩阵Y被组装以后,在后续迭代中始终保持不变。因此,使用直接法求解式(1)更加有效。通常,LU分解方法被广泛应用于求解这一类线性方程。Y只在初次迭代中被分解,其分解结果可以在后续迭代中被重复使用。
由于全局矩阵Y具有对称性,因此分解产生的矩阵U能进一步被分解为对角矩阵D和上三角矩阵LT。
Y=LU=LDLT
(11)
式(11)的矩阵形式为
(12)
在LDLT分解中,由于全局系数矩阵也具有稀疏性,因此计算范围可以由所有元素缩小到非零元素,这样可以减小计算规模和节省内存。
以矩阵Y第k列分解为例,全局矩阵的LDLT分解过程如图5所示。
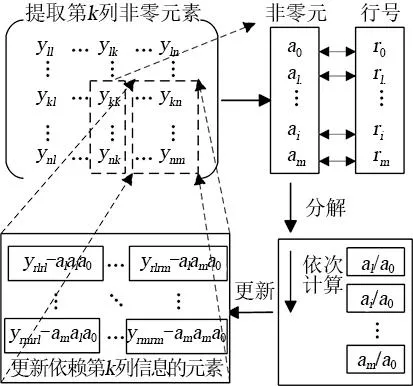
图5 全局矩阵的分解过程
图5中,将该列中所有的非零元素提取出来。提取出来的元素组成的向量A表示为
A=[a0a1…am]T
(13)
在Y中被提取出的非零元素对应位置信息由一个新的数组记录。
row=[r0r1…rm]
(14)
每次提取均在同一列进行,因此只需要记录行号,A中各元素的行号记录在row中。
其主要分为2个过程:
a. 使用向量标量除法分解当前列中所有非零元素。
ai=ai/a0
(15)
b. 更新Y中那些对第k列有依赖的元素。
(16)
A与AT的乘积所指示的Y中相同位置的元素会被更新为
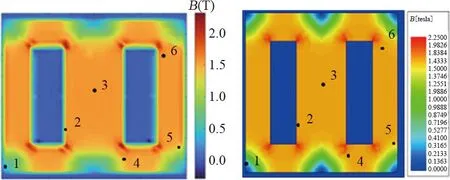
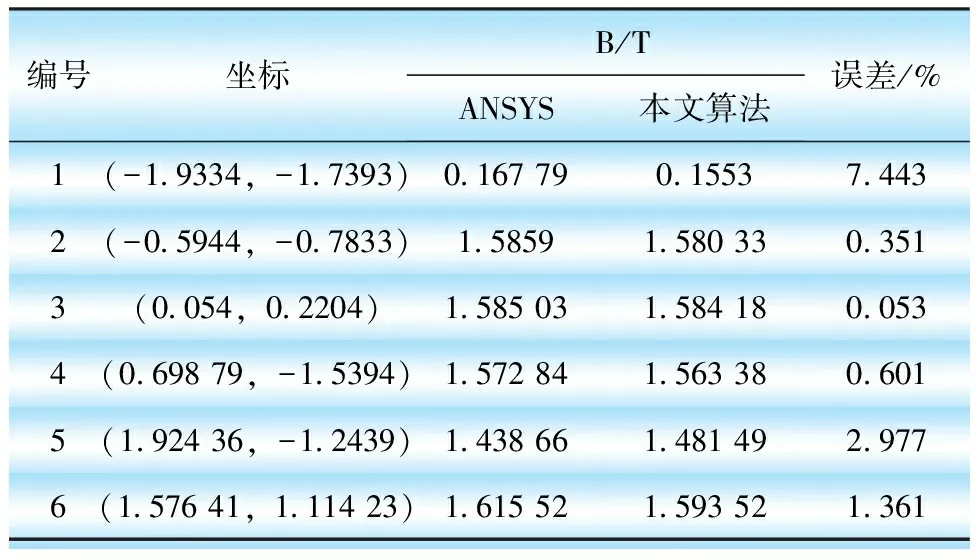
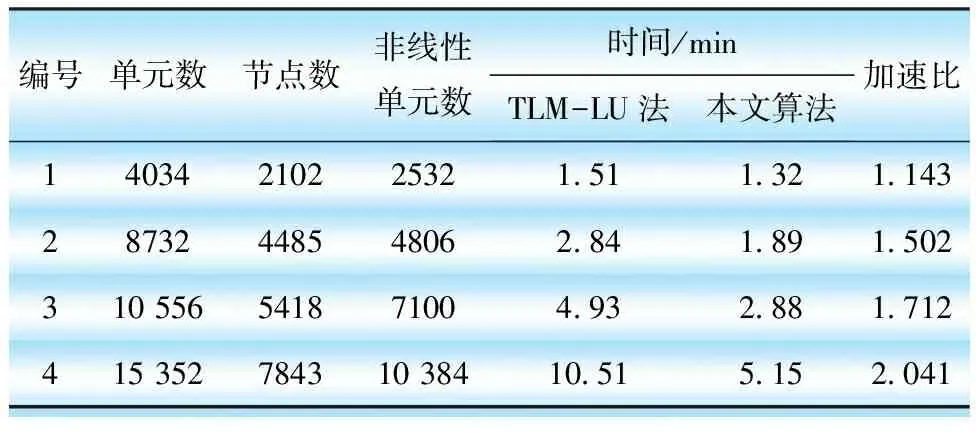
yrirj=yrirj-aiaja0(i,j (17) 由上述过程可知,全局矩阵中每1列元素的分解操作和更新操作是2个并行度较高的流程,适合在GPUs上并行执行,2个流程间采用串行方式。单元分析及全局矩阵LDLT分解的并行过程见图6。 图6 全局矩阵的LDLT并行分解过程 为了验证优化后的TLM-FEM在电磁场计算中的求解精度和效率,本文将算法和程序应用于1台型号为DSP-241000 kVA/500 kV的单相变压器磁场计算,并将计算结果与采用商用软件ANSYS计算得到的结果进行对比分析。变压器的结构模型和网格剖分见图7。变压器一次侧施加空载电流,二次侧开路,计算得到的磁场分布见图8。 图7 变压器几何模型和网格剖分 图8 变压器磁通密度分布 在求解域内随机选择6个位置,提取ANSYS和本文算法的计算结果如表1所示。 表1 ANSYS与本文算法结果对比 如表1所示,本文算法误差是在可以接受范围,位置1处的误差大于5%,分析原因是由于该处的值本身较小,其余各点的值均在3%以内,证明本文算法正确。 为考察本文开发的并行计算对计算时间的影响,对结合LU分解的TLM(TLM-LU)方法和本文算法在不同单元、节点数目下进行求解,计算时间见表2。本文算法程序在带有NVIDIA 940MX GPU和Inter i7-6700HQ CPU的计算机上执行。 表2 TLM-LU和本文算法计算时间的对比 由表2可知,本文算法相较于TLM-LU方法计算时间减少,随着网格数量增多、计算规模增大,加速效果更为明显。 本文提出优化松弛法用于计算TLM-FEM反射阶段的参数,以提高求解的效率和精度,同时将单元系数矩阵计算及全局矩阵LDLT分解计算在GPU平台上并行实现。针对于单相变压器电磁场问题的求解,该方法可以达到与商业软件一致的求解精度。本文算法能通过缩短全局矩阵分解时间和反射过程计算时间从而提升整体求解效率,模型数量规模越大,加速效果越明显。
3 算法验证与应用

4 结语
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
南京大学学报(数学半年刊)(2020年1期)2020-03-19
赤峰学院学报·自然科学版(2018年9期)2018-10-18
金桥(2018年4期)2018-09-26
西部广播电视(2015年5期)2016-01-16
池州学院学报(2015年3期)2016-01-05
地震地质(2015年3期)2015-12-25
中国卫生(2014年5期)2014-11-10
电波科学学报(2011年4期)2011-05-29
