
灰岩含水层定向钻孔注浆效果智能评价方法研究
2024-02-22 11:26李文昕贾东秀陈建刚傅子群陈军涛郭洪运
煤炭工程 2024年1期
李文昕,贾东秀,陈建刚,傅子群,陈军涛,4,5,郭洪运,刘 磊
(1.山东科技大学 能源与矿业工程学院,山东 青岛 266590;2.山东能源新汶矿业集团有限责任公司 邱集煤矿,山东 德州 251105;3.山东能源新汶矿业集团有限责任公司 榆树井煤矿,内蒙古 鄂尔多斯 016299;4.煤炭资源高效开采与洁净利用国家重点实验室,北京 100013;5. 山东科技大学 矿业工程国家级实验教学示范中心,山东 青岛 266590)
矿井水害严重影响着煤炭资源的安全开采,而矿井开采属于地下工程,其隐蔽性给矿井水害防治带来了较大困难。目前,我国矿井水害的防治方法主要有留设安全煤岩柱、注浆堵水、充填开采等。注浆堵水技术是将注浆材料通过钻孔注入含水层中,将含水层改造成弱含水层,或注入导水通道隔断水源的供给,在隧道、地铁、矿山开采等地下工程的施工和运营中起到重要作用,因此,注浆效果评价方法的科学性和合理性,对于保障煤炭安全开采和工人的生命健康至关重要。
当前,含水层注浆效果评价的方法主要有物探、钻探和水文信息分析,杨志斌[1]以流体力学为理论基础,采用钻孔高压压水的试验方法,建立了煤层底板突水通道截流或突水含水层堵源的预注浆治理效果定量评价模型;司马丹琪等[2]以鲤泥湖矿区为例,构建了矿区水文地质概念模型和数学模型,最终利用模糊数学的理论,建立以各指标为评价因子的模糊综合评价模型,对注浆效果评价具有重要的指导意义;冉德立[3]结合河南永城陈四楼煤矿2517工作面注浆工程,以工作面底板注浆钻孔成果数据为基础,使用物探、Surfer软件绘图、突水系数评价、水化学等方法建立了注浆效果综合评价体系,为注浆效果检验及工作面安全回采提供了可靠依据。大多数矿井是通过对单位注浆量、渗透系数等指标单因素分析进行注浆效果评价,具有一定的不确定性,且注浆效果评价与人工智能分析结合鲜有研究。因此,基于黄河北煤田邱集煤矿灰岩含水层注浆改造工程实际,采用机器学习和人工神经网络,提出基于数据训练学习形成评价模型的注浆效果智能化评价方法,对于完善注浆效果评价方法和保障煤炭资源的安全高效开采,具有科学的指导作用和实际意义。
1 注浆效果评价指标的选取
含水层注浆改造的实质是将特定的注浆材料填充到含水层中的岩溶裂隙、孔隙和导水通道中,通过减小含水层的渗透性而成为隔水层的过程。注浆后的评价指标,由于其产生的机理不同,对注浆效果评价的影响也不相同。因此,选择合适的注浆效果评价指标显得尤为重要。针对邱集煤矿现有数据和实际开采条件,选取了渗透系数、单位注浆量、终压、总注浆量、浆液压力、注浆位置(顶板或底板)、单位吸水率、总压力、孔口压力、水柱压力、注浆段长等十一种指标来分析定向钻孔注浆的改造效果,这些参数均属于现场注浆工程结束时即可获得的数据,保证了数据获取的便捷性,同时也提高了该评价方法的快捷程度。
1.1 吸水率和渗透系数
一些学者认为,不同的突水机理反映为形成不同的突水通道,不同的突水通道导致注浆岩土体的力学强度和渗透性能不同[4]。因此,可以把渗透性能作为注浆效果的评价指标。反映岩体渗透性能的主要指标为吸水率和渗透系数[5],吸水率主要取决于岩土体中孔隙度的大小。根据注浆泵压、吸水段长度等计算单位吸水率q,当计算结果不大于0.01 L/(min·m·m)时,才能结束钻孔注浆施工。单位吸水率的计算公式为:
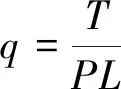
(1)
式中,q为单位吸水率,L/(min·m·m);T为压入流量,L/min;P为作用于试段内的压力(换算水头高度);L为试验段长度,m。
渗透系数是用来表示流体通过孔隙骨架的难易程度的系数,被定义为单位水力梯度作用下的流量。《水利水电工程钻孔压水试验规程》推荐:当试段位于地下水位以下,透水率在10 Lu以下,可用式(2)计算含水层的渗透系数。
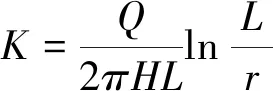
(2)
式中,K为地层渗透系数,m/d;Q为压水流量,m3/d;H为试验压力,以水头表示,m;r为钻孔半径,m。
1.2 总注浆量和单位注浆量
实践表明,在注浆改造的工程中,注浆量的多少对于注浆效果具有一定的指示作用,尤其是单位注浆量,当单位注浆量处于合理范围内时,含水层注浆效果随着单位注浆量的增大而增强。因此,可根据单位注浆量的大小反映含水层注浆改造的效果。
1.3 浆液压力和注浆终压
浆液能够进入岩土体裂隙并扩散压实的主要动力是浆液压力。在定向钻进注浆防治水技术中,可以通过对浆液压力的调控来实现注浆范围的精准控制,而且浆液压力的变化也能反映注浆效果的好坏[6,7]。注浆终压是控制注浆施工结束的参数,能够决定注浆的充实率大小和质量好坏[8]。所以,注浆终压和浆液压力是控制注浆施工和评价注浆效果的重要参数。
2 注浆评价方法
2.1 检查孔法
检查孔法是一种注浆后的检验方法,是目前最可靠的一种方法[9]。注浆结束后,结合水文地质特征和注浆信息,对可能比较薄弱的注浆区域设置检查孔,再通过一系列手段进行注浆效果评价,如通过对检查孔取芯后进行压水试验测定渗透系数,但最终还是以渗透系数来反映注浆效果的好坏。
2.2 注浆信息分析法
注浆信息分析法是对注浆过程中产生的各种数据(注浆量、涌水量、浆液填充率等)进行分析,挖掘和整合隐藏信息,对注浆效果进行定性分析的方法,其优缺点见表1。

表1 部分注浆资料分析法优缺点Table 1 Advantages and disadvantages of partial grouting data analysis method
2.3 地球物理勘验法
地球物理勘探是利用岩体的物理差异来达到评价的方法,可以对注浆效果进行宏观评价,但是很多物探手段对水较为敏感,而对特殊注浆材料敏感度较低,难以反映其变化情况。
从目前常用的评价方法来看,检查孔法需对待观测区域进行打孔钻探,工程量大、所需费用较高,且受地质条件约束;注浆信息分析法计算量庞大、计算过程复杂且不能直接说明注浆好坏;地球物理勘验法受限于设备精度和地质条件,难以给出准确的结果,总的来说,上述注浆效果评价存在程序复杂、准确度不足的缺点。人工神经网络和机器学习是一个不断发展完善的过程,在此,结合上述评价方法的优缺点,本文采用人工神经网络和机器学习,对注浆效果进行科学评价分析,预期获得一种实用、简单、科学而又准确的评价方法。
3 评价模型建立
3.1 数据和可视化分析
通过对注浆参数进行分析,发现总注浆量与单位注浆量存在密切联系,在注浆段长一定时,单位注浆量越多,总注浆量也越大。因此,总注浆量与单位注浆量的相关系数为0.64,相关度较高。
地面注浆总压力为注浆孔内浆柱自重压力和注浆泵产生的压力之和,注浆孔口压力等于注浆总压力减去注浆段中间的水柱压力。因此,总压力和孔口压力的相关系数最高(R=0.88)。注浆终压是注浆结束时注浆孔口的压力,与孔口压力也具有较高的相关度(R=0.82),总压力与终压的相关系数为0.78,如图1所示。

注:1—渗透系数,m/d;2—单位注浆量,t/m;3—终压,MPa;4—总注浆量,t;5—浆液压力,MPa;6—底板或顶板(底板=0,顶板=1);7—单位吸水率,L/(min·m·m);8—总压力,MPa;9—孔口压力,MPa;10—水柱压力,MPa;11—注浆段长,m图1 数据特征相关性分析Fig.1 Data feature correlation analysis chart
通过绘制注浆后灰岩渗透系数的特征分布,发现大部分灰岩的渗透系数位于连续区间内,主要集中在0.00025 m/d附近,渗透系数在0~0.0005 m/d区域约占总数据量的85%,说明注浆后灰岩岩溶裂隙封堵较好。定向钻孔注浆工程中,注浆终压是注浆工程能否达标的重要标准,分析发现,注浆终压在满足注浆结束标准的同时均集中在8.0~14.0 MPa之间,说明注浆终压均达到了设计要求。
最大灰岩注浆量为39160 t,对应注浆段长属于正常值,说明该注浆孔附近裂隙较为发育,其他注浆量均集中在0~20000 t区间,其中,0~10000 t区间的注浆量占总数据量的90%以上。单位注浆量表现出了和总注浆量相似的分布特征。
灰岩的总注浆压力、孔口注浆压力、浆液压力、水柱压力、注浆段长和单位吸水率等参数的分布特征如图2所示,可以看出,因相对薄弱区的存在,导致个别数据相对较高,但仍在标准范围内,训练集中的数据不存在缺失、大量重复和失真等异常情况。
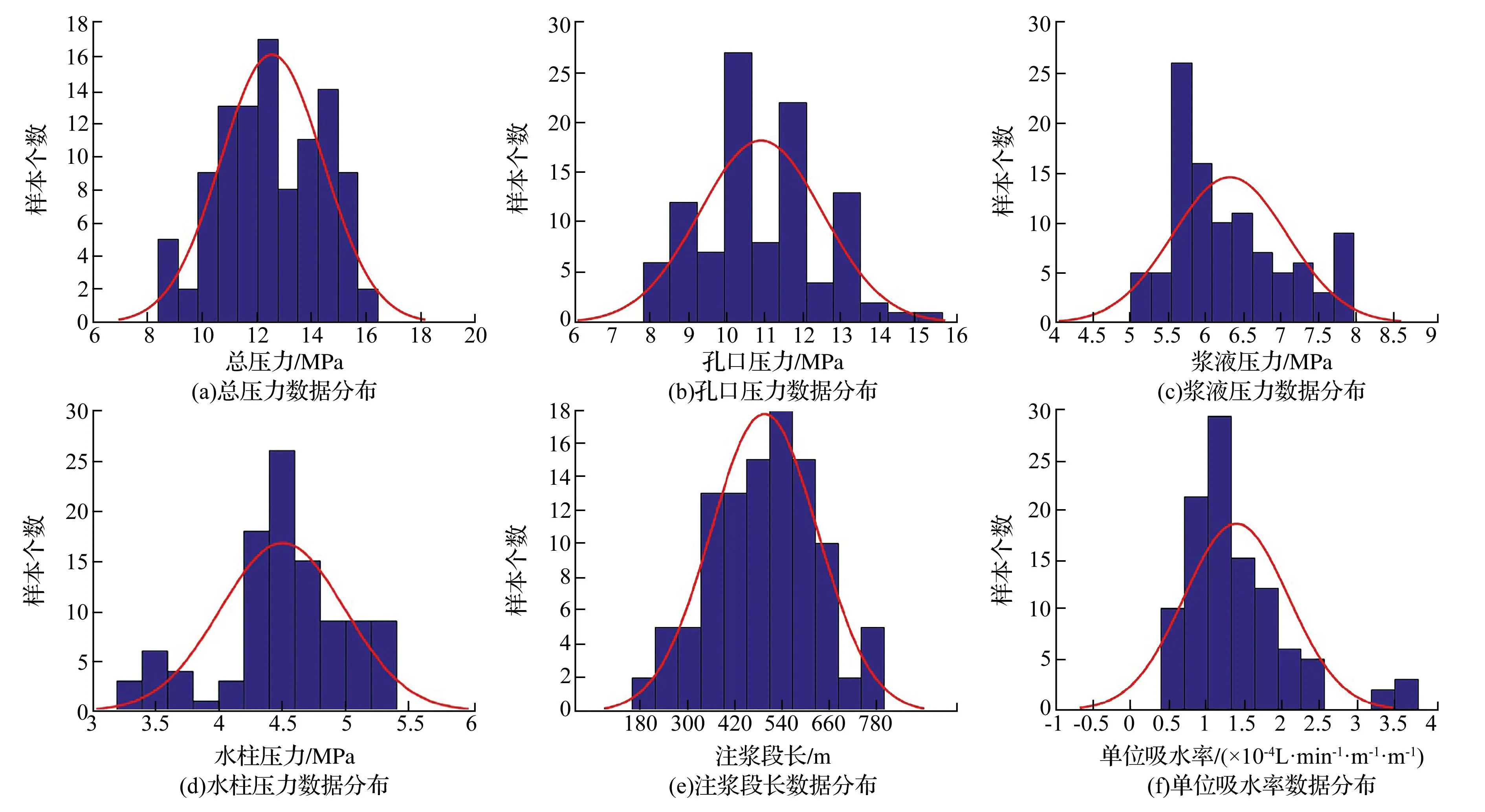
图2 注浆各参数分布Fig.2 Data distribution map
为方便数据分析,将顶底板分别设置为1和0作为数值型参数,数据归一化处理后减小了与其他参数的数量级差异。注浆效果的评价标准是参考邱集煤矿含水层注浆效果的评价报告,基于现场注浆实际需要,设定为达标区、合格区和相对薄弱区,并对其进行了特征数值化处理。
3.2 机器学习模型
机器学习是研究计算机模仿或实现人类的学习行为。该方法使用多种机器学习的算法,对目前已有数据进行算法分析,完成一个从基础数据到最终效果评价的迅速、快捷的转换。鉴于现场注浆数据量相对有限,为提高分析精度,选取XGboost、支持向量机和K近邻等模型对定向钻孔注浆效果进行评价。
3.2.1 XGboost
XGboost(全称为Extreme Gradient Boosting)是经过优化的分布式梯度提升库,具有高效、灵活且可移植的优点。在工业界大规模数据方面,XGboost的分布式版本有广泛的可移植性,能够很好地解决工业界大规模数据的问题[10]。其核心思想为:不断地添加新函数,不断地进行特征分裂来让函数成长,每次都学习一个新函数,去拟合上次预测的残差。当训练完成得到k个函数时,要预测一个样本的分数。最后只需要将每个函数对应的分数加起来,即可求得样本的预测值。
3.2.2 支持向量机
支持向量机(Support Vector Machine,SVM)是通过一个非线性映射p,把样本空间映射到一个高维或无穷维的特征空间中,使得在原来的样本空间中非线性可分的问题转化为在特征空间中的线性可分的问题[11]。目前,该技术已经被广泛用于模式识别、分类、工业工程、航天工程等多个领域,效果十分可观。
3.2.3 K近邻
K近邻分类算法(K-Nearest Neighbor,KNN)是一种基本的分类方法,即给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例。当数据量小时,K近邻算法体现出较好的性能。K近邻分类算法简单、易理解、易实现,无需估计参数,无需训练;适合对稀有事件进行分类;特别是对具有多个类别标签的多分类问题,KNN表现较好。但由于该算法对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点,导致其计算量较大。
3.3 BP神经网络
3.3.1 BP神经网络原理
BP神经网络建立在梯度下降法的基础上,是一种单向传播,当输出结果和实际结果相差较大,BP神经网络会把误差值反向传播,将误差分配给各个神经元,经过反复学习训练,获得最小的误差和阈值并达到期望后,停止训练[12]。BP神经网络的输入输出关系实质上是一种映射关系:一个n输入m输出的BP神经网络所完成的功能是从n维欧氏空间向m维欧氏空间中一个有限区域的连续映射[13]。
3.3.2 网络的设计
为了模型需要,利用MATLAB将数据归一化,即映射至[-1,1],并将结果数值化。因为一个3层的BP神经网络已经能够完成任意的n维到m维的映射,无需添加隐层数即可完成目的。因此,选用输入层—隐含层—输出层的3层网络。
利用MATLAB中神经网络工具包Neural Net Fitting工具,将归一化后的数据作为输入层,数值化结果作为输出层,隐含层的神经元个数根据经验公式确定。
式中,h为隐含层节点数目,个;m为输入层节点数目,个;n为输出层节点数目,个;a为1~10之间的调节常数。
设计网络结构分别为15、16、17个隐含神经元。
4 结果分析与简易平台搭建
4.1 机器学习结果
基于黄河北煤田邱集煤矿现场灰岩注浆的103组数据,部分注浆数据见表2,每组数据包含前文所述的渗透系数、单位注浆量、终压、总注浆量等11种指标,数据处理后,分析表明无异常情况。

表2 部分注浆数据Table 2 Partial grouting data
现场灰岩注浆103组数据中,72组注浆数据用于模型训练,31组注浆数据用于模型测试。三种机器学习结果的混淆矩阵如图3—5所示。①在K近邻模型中,训练数据正确的个数为58组,测试数据正确个数为22组,测试正确率较低;在支持向量机模型中,模型训练的数据正确组数为62组,模型测试的正确数据为24组,测试正确率高于K近邻模型,但是,针对第三类相对薄弱区,训练数据和测试数据组数均为0,难以准确判断相对薄弱区,原因是相对薄弱区的数据组数较少;XGboost取得的效果相对较好,训练数据全部正确,测试正确数据为25组,错误6组,其中,第二类合格区错误5组,可见在针对第二类合格区的分析存在不足。
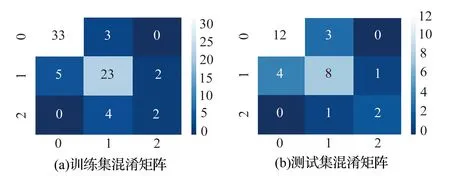
图3 K近邻模型训练集和测试集混淆矩阵Fig.3 Nearest neighbor model training set and test set confusion matrix
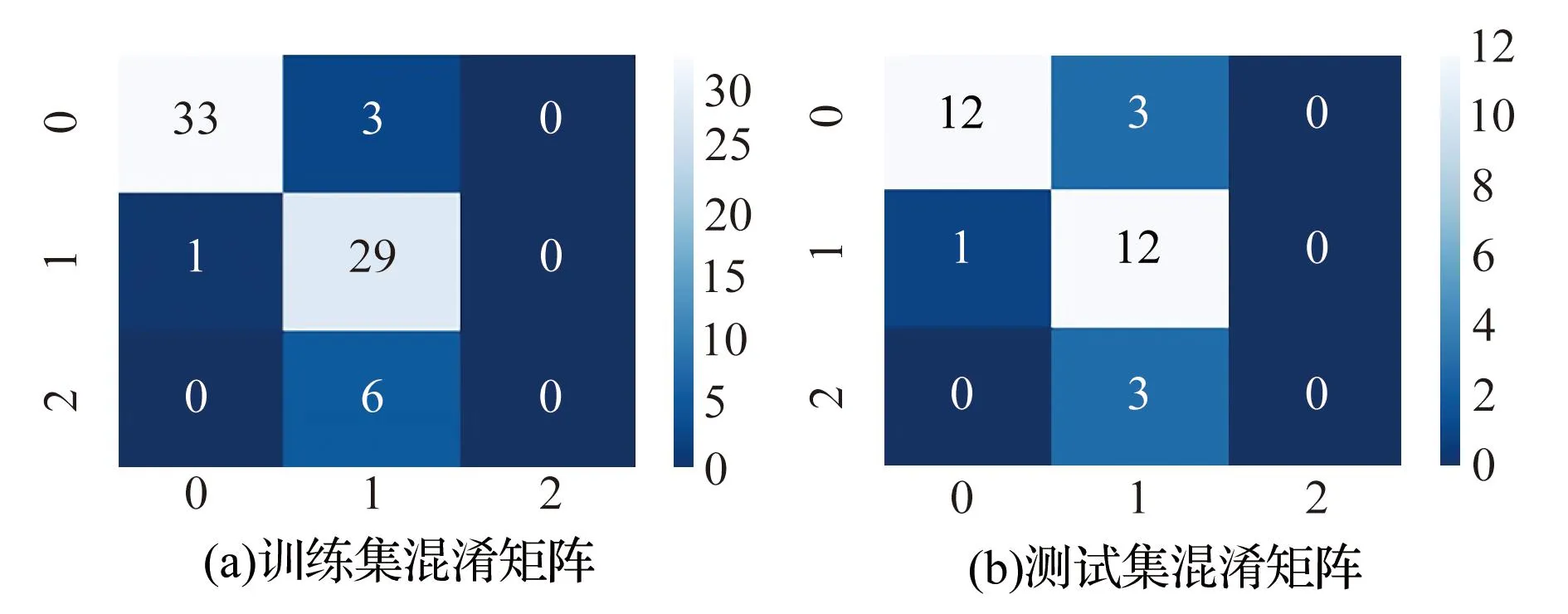
图4 支持向量机模型训练集和测试集混淆矩阵Fig.4 Support vector machine model training set and test set confusion matrix
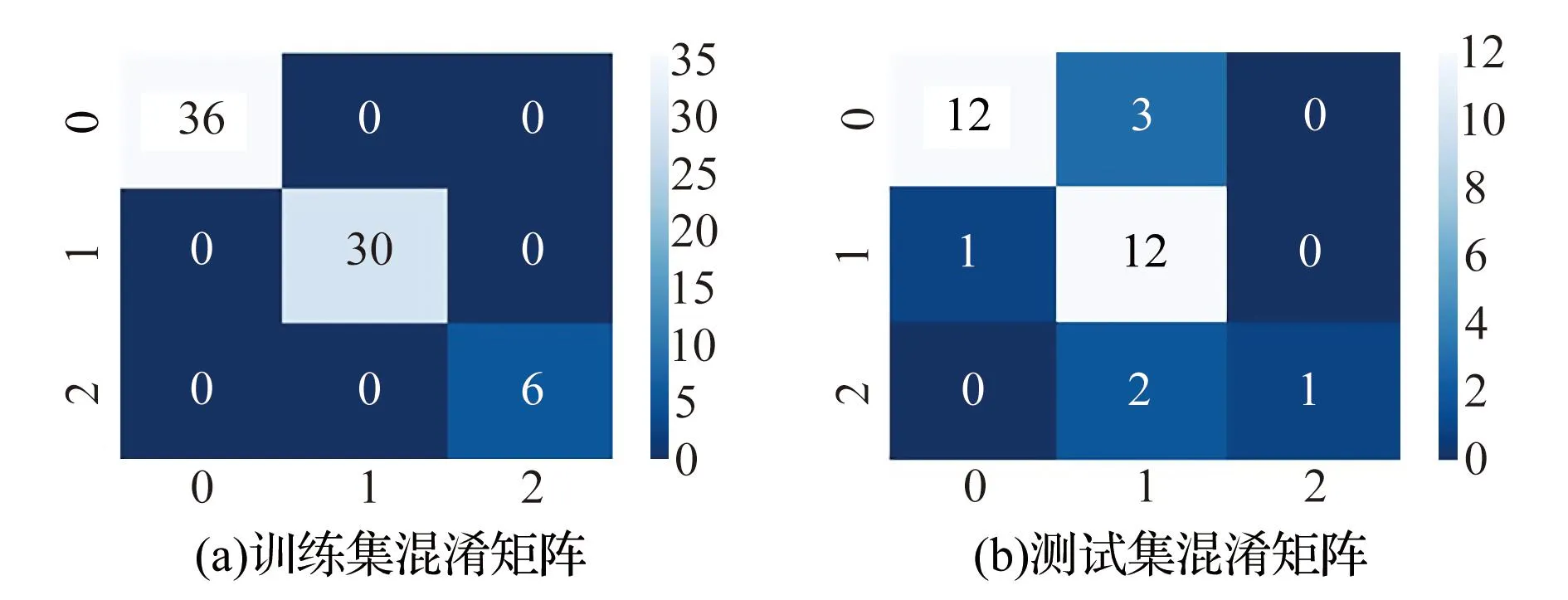
图5 XGB模型训练集和测试集混淆矩阵Fig.5 XGB model training set and test set confusion matrix
综上,利用现有数据进行训练得出:XGboost算法的准确度最高(0.8064);支持向量机算法准确度(0.7742);K近邻效果最差(0.7154)。从运行时间可知:K近邻花费之间最少;XGboost由于运行过程中不断添加函数,花费时间也相应增加。但是,三种机器学习的算法精确度均不能达到0.9,主要原因可能如下:①各指标间存在很大的数量级差距,难以通过归一化完全消除;②数据量和指标组数较少,导致其精度较差;③相比合格和达标的数据,相对薄弱区训练数据较少,影响了其精度。
4.2 BP神经网络结果分析
15个隐含神经元的拟合程度达不到0.9,16、17个隐含神经元的拟合程度分别为0.94、0.93,二者大致相等,但17个隐含神经元的线性化程度更高。因此,设置17个隐含神经元。
神经网络训练的均方根误差在第4代时为0.12673,均方误差约为0.075,如图6所示。在训练第4代之前,随着训练次数的增加,训练误差与测试误差同时下降;当超过第4代后,训练误差仍在下降,但测试误差开始上升,说明此时训练过度。
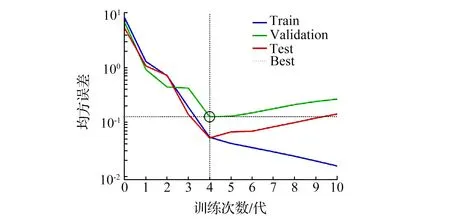
图6 最佳验证性能Fig. 6 Best verification performance graph
误差直方图如图7所示,总体上属于正常型误差,但存在少量大数据偏差,说明在正常范围内存在较大数据。借助黄河北煤田邱集煤矿注浆的分析模型,建立注浆数据的测试网络,效果如图8所示,可以看出,第一类达标区与第二类合格区效果较好,数据相对集中,第三类相对薄弱区由于训练数据过少,存在一定的偏差,总体来说准确度达到0.9,证明该方法可行。
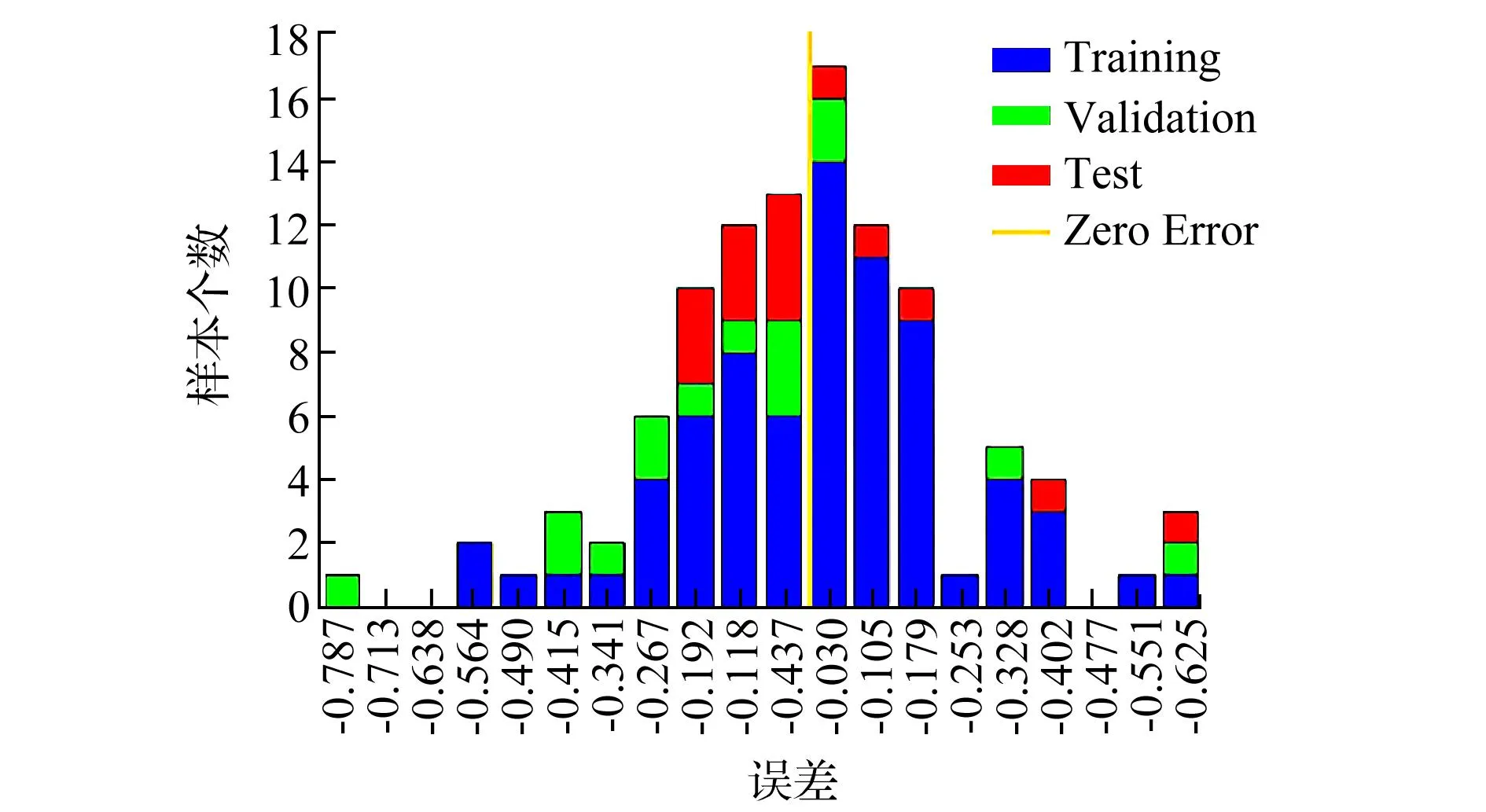
图7 误差直方图Fig.7 Error histogram
4.3 简易系统搭建
比较XGboost、支持向量机、K近邻三种机器学习与BP人工神经网络,发现BP人工神经网络精度最高,使用现场数据测试取得了较好的效果。根据通过MATLAB训练的BP人工神经网络模型,在此基础上,通过pycharmIDE制作了演示系统,其工作方式为:下载excel模板,根据模板要求填写渗透系数、单位注浆量、终压、总注浆量、浆液压力、注浆位置(顶板或底板)、单位吸水率、总压力、孔口压力、水柱压力、注浆段长等数据;将文件上传该演示系统,系统能够自动评价注浆区域的效果。
5 结 论
1)通过三种机器学习模型与BP人工神经网络模型的拟合分析,发现BP人工神经网络模型的拟合效果较好(0.93811)。
2)提出了采用BP人工神经网络模型的灰岩含水层定向注浆效果智能评价方法。采用现场数据与拟合结果对比,可知BP人工神经网络模型分析的准确度达0.9,验证了该方法的可行性。
3)随着应用次数以及时间的积累,注浆数据的样本会不断增加,样本因素造成的结果误差会不断减小,效果评价结果的准确性会进一步提高。
猜你喜欢
中国煤炭(2023年12期)2024-01-04
地质与资源(2021年1期)2021-05-22
建材发展导向(2019年11期)2019-08-24
江西建材(2018年4期)2018-04-10
浙江工业大学学报(2017年5期)2018-01-22
水利规划与设计(2017年8期)2017-12-20
水科学与工程技术(2016年2期)2016-07-10
中国煤炭(2016年1期)2016-05-17
河北地质(2016年1期)2016-03-20
江西煤炭科技(2015年2期)2015-11-07
