
一种结合卷积自编码和补丁惩罚的生成对抗网络单图像去雨方法
2024-02-26 08:00侯家振韩龙哲谭德坤
电光与控制 2024年2期
陈 铭, 赵 嘉, 侯家振, 韩龙哲, 谭德坤
(南昌工程学院信息工程学院,南昌 330000)
0 引言
雨天获取图像无法避免雨滴雨纹呈现在图像表面,并且图像中雨滴雨纹附着区域会因环境光反射而呈现场景内其他映像,无法反映该区域真实内容,造成获取图像内容被遮盖、细节模糊和图像失真等退化问题。若将此类图像直接用于后续的图像处理[1-3],将严重影响处理结果的准确性和可信度。因此,图像去雨研究极具现实意义。
图像去雨技术经过长期发展已经较为完备,根据数据输入的类型不同,一般可将其分为视频图像去雨和单图像去雨两类。视频图像去雨方法[4-5]通过图像前后帧之间的差异,根据其时空性进行去雨处理;然而单幅图像是时空静止的,无法利用时空特性对有损图像进行查补还原,使得单图像去雨较视频图像去雨难度更大。
目前单图像去雨方法主要分为基于传统的模型驱动方法和基于深度学习的方法。传统方法中,文献[6]提出了一种基于单图像的去雨框架,首先通过将去雨表述为基于形态成分分析的图像分解问题,使用双边滤波器将图像分解为低频和高频部分,然后通过执行字典学习和稀疏编码将高频部分分解为雨分量和非雨分量,再对雨分量进行去除;文献[7]使用监督学习的方法构造一个鉴别和重构字典,通过引入一个理想的正则化项,同时对所有类别的有雨图像进行低秩矩阵恢复,得到了图像相对于所构造的字典的判别低秩表示;文献[8]提出一种基于高斯混合模型(GMM)的先验方法,该方法对背景层和雨层使用简单的基于图像补丁的先验,可以适应雨纹的不同方向和深度;文献[9]提出一种新颖的低秩表现方法,使用一个从矩阵到张量结构的低秩模型,用来捕捉时空相关的雨纹;文献[10]提出了一种基于卷积编码的去雨方法,该方法通过学习一组通用的基于稀疏性和基于低秩表示的卷积滤波器,分别表示雨条纹和背景清晰图像,直接对整幅图像进行处理。但是,这些方法往往会在输出图像中留下较多的降雨伪影,并且在处理饱和降雨元素时能力不足。
由于深度学习在图像处理领域的快速发展,许多基于深度学习的方法被应用于解决单幅图像去雨。文献[11]提出了基于卷积神经网络的去雨方法,该方法将干净和对应有雨的图像数据集用于训练深度卷积神经网络,学习如何将有雨水的图像块映射到干净的图像中,隐含地捕捉自然图像中水滴的特征外观;文献[12]提出一种改进的生成对抗网络用于单幅图像去雨,该方法根据分治原则,将图像降雨任务分为定位雨水、去除雨水和细化细节3个子任务,使得生成图像在视觉呈现上更加自然;文献[13]提出了基于注意力机制的生成对抗网络,将视觉注意力注入生成网络和鉴别网络,在训练过程中视觉注意力学习雨滴区域及其周围环境,通过注入这些信息,生成网络将更加关注雨滴区域和周围的结构,判别网络将能够评估恢复区域的局部一致性。尽管这些方法取得了一定的成功,但它们在优化还原图像质量过程中过于注重雨纹特征,导致输出图像部分区域过度平滑,图像细节模糊。
上述各改进方法在一定程度上均达到了去雨效果,但是这些方法依旧存在生成图像易产生伪影和图像细节信息丢失的缺陷。针对此类问题,本文提出一种结合卷积自编码和补丁惩罚的生成对抗网络单图像去雨方法。首先,使用卷积自编码[14]组成生成器网络,设置多个对称跳跃连接来连接低高层网络;其次,区别于传统的鉴别器在像素级上进行比较,采用马尔可夫鉴别器在图像补丁层次上惩罚模型结构;最后,定义了一种新的精细化的损失函数。实验结果表明,该方法不仅还原了图像细节信息,解决了输出图像产生伪影的问题,而且在去雨图像的视觉呈现上有了很大提升。
1 相关内容
1.1 雨图模型
本文将有雨图像建模为真实背景图像与雨滴效果图的结合,单图像去雨可以看作去除有雨图像的表面模糊雨纹,生成清晰的目标背景图像,结构雨图见图1。

图1 结构雨图Fig.1 Structural rain map
其算式为
W=X+L
(1)
式中:W表示有雨图像,是背景信息与环境反射的光线以及附着在图像表面的雨滴的复杂混合;X表示其对应的背景图像;L表示雨条纹图像。该类型模型在图像去模糊[15-16]、图像修复[17]和图像分离[18]等领域得到广泛应用。
1.2 生成对抗网络
生成对抗网络(GAN)是 GOODFELLOW等[19]在2014 年提出的一种生成式模型。GAN由生成器网络和鉴别器网络组成,GAN的主要思想类似零和博弈,通过设置两个网络的对抗学习实现能力提升。生成器网络通过噪声生成样本,经过反复训练使得生成的样本与训练样本无法区分;鉴别器网络需区分输入样本是生成器网络生成的样本还是真实训练样本。GAN在样本的训练和生成过程中,不需要任何马尔可夫链(Markov Chain)[20]。GAN的目标函数是

(2)
式中:G为生成器;D为鉴别器;x表示真实数据;z为噪声向量;Pdata表示真实数据分布;Pz(z)表示先验概率分布。
文献[21]提出了条件生成对抗网络 (Conditional Generative Adversarial Net,CGAN),通过添加额外的条件信息y提高训练的稳定性,使得生成器网络生成的数据更加高效可控。给定噪声向量z和额外条件信息y,CGAN的目标函数通过求解以下优化问题学习一个映射函数来使得生成输出数据与真实数据x无法区分,即

(3)
1.3 跳跃连接
在基于深度学习的图像处理领域,训练效果并不都会因为网络层数增加而更好,有时反而会丢失大量图像细节,并产生梯度消失、梯度爆炸和过拟合等问题。文献[22]提出了残差网络,残差网络由一系列的残差块组成。跳跃连接如图2所示。通过跳跃连接连接低层网络和高层网络,使得梯度消失、梯度爆炸和网络退化问题得到改善,跳跃连接传递的特征映射承载了大量图像内容细节,深层网络的训练也更加容易。
2 卷积自编码和补丁惩罚的生成对抗网络
本文构建了一个基于生成对抗网络的深度网络,直接学习从输入有雨图像到对应真实背景图的映射,该网络主要组成部分为生成器网络、鉴别器网络和损失函数。生成器网络是一个基于卷积自编码的对称网络,并引入了对称跳跃连接优化梯度;鉴别器网络采用马尔可夫鉴别器,在图像补丁范围内进行惩罚;定义一个全新的精细化损失函数确保生成图像的质量。下面详细阐述网络的构成。
2.1 卷积自编码生成器网络
生成器网络应当在不丢失图像细节的前提下去除图像雨纹,首先将输入的有雨图像传输到特定的区域,将其分离为背景图像和雨纹元素,分离后生成的背景图像必须回到原始域,因此需要使用对称网络结构。本文使用基于卷积自编码的生成器网络,该编码-解码网络由多层卷积层(Convolution,Conv)和转置卷积层(Transposed Convolution,T-Conv)[23]组成,卷积层作为图像特征提取器,在去除雨纹的同时编码图像的组成内容;转置卷积层具有通过解码图像抽象内容重构背景图像内容细节的能力。
由于加深网络层数会引起梯度消失等问题而使得训练难以进行,本文在生成网络中引入多个跳跃连接。首先,它们允许信号直接反向传播到底层,解决了梯度消失的问题,使得训练深度网络更容易,从而实现恢复性能的提高;其次,这些跳跃连接将低层特征连接到高层特征上,有利于恢复干净的图像,使得训练收敛性更好。卷积自编码生成器网络结构如图3所示,首先对输入图像进行多重卷积用于提取图像特征,然后经过多重转置卷积层用于重构图像。网络每层都采用批量归一化处理(Batch Normalization,BN)[24],使得网络中每层输入的数据相对稳定,提高了网络的训练学习效率;编码层使用Leaky_ReLU激活函数,解码层使用ReLU激活函数[25],避免梯度消失。为了保证输入图像尺寸和输出图像尺寸相同,在卷积操作中设置步长为1,卷积核提取图像特征时适当填充。在训练过程中提供有雨图像和对应的清晰无雨图像,让生成器网络直接学习从有雨图像端到无雨图像端的映射。
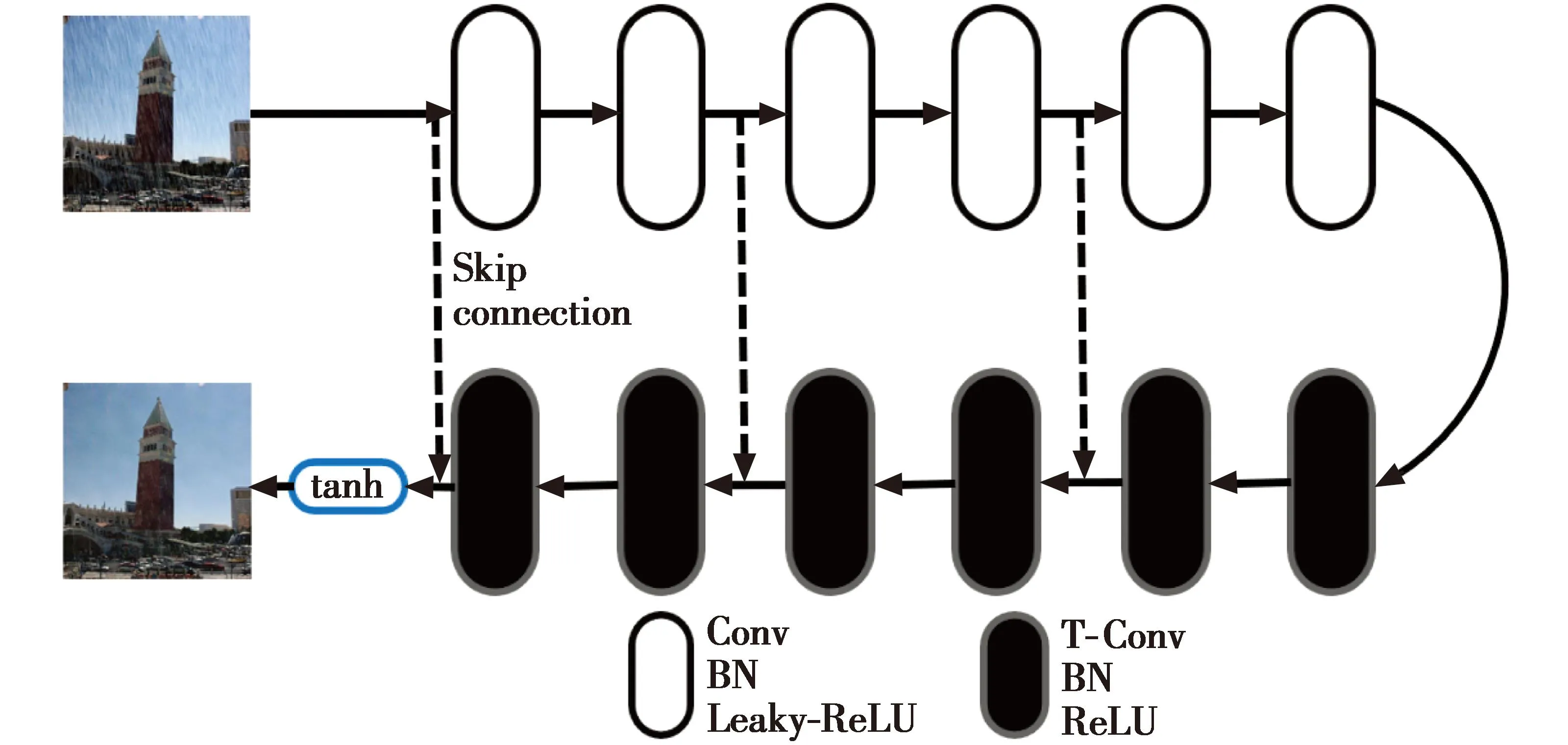
图3 卷积自编码生成器网络结构Fig.3 Convolutional auto-encoding generator network
2.2 马尔可夫鉴别器(PatchGAN)网络
鉴别器网络需判断输入图像是否由生成器网络生成,然后反向传播预测值与真实值之间的误差。鉴别器网络与生成器网络之间采取交替更新,通过不断的对抗训练,各自的能力在对抗学习中不断提升。原始GAN的鉴别器由多层感知机构成,多层感知机为含有至少一个隐藏层的由全连接层组成的神经网络,具有非常高的模型复杂度,容易造成过拟合、模型无法收敛或者在训练过程中出现梯度消失或梯度爆炸等问题,多层感知机结构如图4所示。但对于还原图像细节、抑制图像伪影生成的处理,原始GAN的鉴别器并不能完全胜任。马尔可夫鉴别器网络[26]由一系列批量归一化、Leaky_ReLU激活函数和多重卷积层组成。马尔可夫鉴别器在补丁的层次上惩罚结构,将输入映射为诸多patch,鉴别器试图区分每个大小为n×n的patch的真假,最后的卷积层没有使用激活函数,输出值被拉成一维的向量,然后送入一个全连接层进行最终的分类预测,输出一个实数值,这个实数值代表输入图像为真实图像的概率估计。马尔可夫鉴别器网络结构如图5所示,网络除最后一层外都使用Leaky_ReLU激活函数,除第一层和最后一层外都使用批量归一化处理。训练过程中消除了生成的图像伪影,并使得模型更加关注图像细节和图像不同部分的影响,因此,本文使用马尔可夫鉴别器网络。
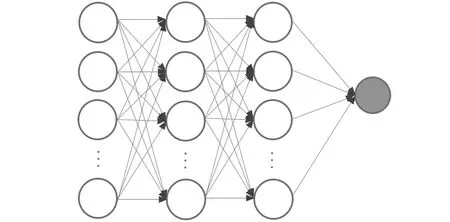
图4 多层感知机Fig.4 Multilayer perceptron

图5 马尔可夫鉴别器网络结构Fig.5 Markov discriminator network
2.3 损失函数
损失函数在网络训练学习过程中至关重要,它用于衡量模型预测数据与实际数据的差异化程度,不同的损失函数对网络训练学习的影响不同,各损失函数的不同组合能让网络有效训练学习不同的图像处理任务,如图像超分辨率重建[27]、图像风格转移[28]、图像翻译[29]等。L1损失函数(即MAE)常被应用于预测图像与真实图像之间像素级优化。但像素优化间各像素联系不强,无法在捕捉图像细节关联性上有很好的表现,处理后的图像清晰度不高。
GAN的训练过程极不稳定,导致生成的图像中产生伪影。为了保证输出图像的细节内容和视觉质量,本文提出一种新的精细化损失函数作为生成器损失函数,由条件对抗损失、感知损失、内容损失和总变异损失(Total Variation Loss,TV Loss)与适当的权重组成。新的生成器损失函数定义如下
LG=λCLC+λL1LL1+λVggLVgg+λTVLTV4
(4)
式中:LC表示条件对抗损失;LL1表示内容损失;LVgg表示感知损失;LTV4表示总变异损失;λC、λL1、λVgg和λTV分别是条件对抗损失、内容损失、感知损失和总变异损失设定的权值系数。下面将逐一介绍损失函数的各组成部分。
在训练过程中,生成器需使生成样本无法被鉴别器识别,则需要最小化目标;而鉴别器需尽可能识别输入样本来源于生成样本还是真实样本,则需要最大化目标。条件对抗损失的目标函数为
LC=-mean(ln(D(x,G(x,z))))
(5)
式中:x为有雨图像;z为随机噪声变量。
为了减少输出图像中的伪影并提高图像真实度,本文使用加权L1损失函数作为内容损失,L1损失函数具有鲁棒性强、梯度稳定等优势。对图像差异进行逐像素计算比较,并且对像素之差取绝对值,防止像素正负值之间相互抵消。内容损失的目标函数为
LL1=Ex,y,z(‖y-G(x,z)‖1)
(6)
式中,y为真实无雨图像。
为了最小化生成器网络生成无雨图像与真实背景图像高级特征之间的距离,本文引入特征重构感知损失,生成的无雨图像和真实背景图像通过预训练VGG-19模型进行特征提取,然后使用L1距离衡量图像之间的特征差距,计算2幅图像的输出经过Pool-4层后的L1损失。感知损失的目标函数为
LVgg=Ex,y,z(‖V(y)-V(G(x,z))‖1)。
(7)
图像重构过程中很多算法会放大噪声,容易对复原后的结果产生图像模糊失真等不利影响。本文引入总变异损失,通过降低总变异损失缩小图像中相邻像素值间的差异,使得图像相对平整光滑,总变异损失影响域的选择与损失和的计算方式直接影响成像结果和数值结果。影响域可以选择四邻域或八邻域,损失和可以选择差值平方和或差值绝对值和。总变异损失的目标函数为
(8)
式中:(i,j)表示像素点位置;xi,j表示该像素点的像素值;n的取值为1,2,3,4。本文对其不同组合做了性能对比,具体组合如下:LTV1为选择四邻域与差值平方和的总变异损失;LTV2为选择四邻域与差值绝对值和的总变异损失;LTV3为选择八邻域与差值平方和的总变异损失;LTV4为选择八邻域与差值绝对值和的总变异损失。
判别器需准确识别输入图像是生成器生成的样本图像还是真实样本图像,并给予生成器生成的样本图像较低的分数,给予真实样本图像较高的分数。为了更好地训练鉴别器网络、提高鉴别器网络的鉴别能力,在训练鉴别器时对样本的标签内容进行翻转。鉴别器将最大化以下目标函数
LD=mean(ln(D(x,y))+ln(1-D(x,G(x,z))))。
(9)
3 实验结果与分析
3.1 实验设置
本文的实验环境为Intel®Xeon®Gold 5118,64位Windows 10,所使用的编程语言为Python,编译器为Pycharm,网络基于TensorFlow的深度学习框架实现,网络搭建及所有的训练和测试都在该深度学习框架上进行。
在训练集上使用生成对抗网络进行训练,采用与标准GAN相同的训练方法,生成器和鉴别器交替更新,训练过程中使用小批量SGD算法[30]和Adam优化器[31],学习率设为0.000 2,并且将β1设为0.5。设置一个batch的大小为7,迭代训练次数为105,在训练过程中,生成器网络的卷积核数为64,移动步长设置为1,并进行适当的填充;鉴别器网络的卷积核数为48。由于卷积核的大小决定了卷积操作能够捕捉到的特征的尺度。较小的卷积核可以在更细节的层面上捕捉图像的特征,生成器中使用较小的卷积核可以更好地生成图像的细节和纹理,因此将生成器中所有的卷积层和转置卷积层的卷积核大小设置为3×3。而较大的卷积核则可以在更高级别的层面上捕捉图像的特征,鉴别器中使用较大的卷积核则可以更好地判别图像中的整体结构和形状,设置鉴别器网络中所有卷积层的卷积核大小为4×4。此外,较大的卷积核通常需要更多的计算资源和参数,因此在鉴别器中使用较大的卷积核也可以提高模型的稳定性和训练效率。
为了在特征空间中更快地降低空间维度,增加每个像素点的感受野,减少计算量和参数数量,更好地捕捉输入图像的全局信息,从而加速模型训练和提高模型的泛化能力,设置移动步长为2,并进行适当的填充。最后两层中移动步长设置为1,可更好地细化特征空间,增加特征的复杂度,从而更好地判断输入图像是否真实。
3.2 数据集
由于难以获取现实世界中的有雨图像和对应的真实无雨背景图像,训练和测试都选取的是合成雨滴数据集,同时,为了验证本文方法在现实世界有雨图像中的去雨效果,收集了部分现实图像用于直观检测。合成雨滴数据集中训练集总共由700幅图像组成,其中,500幅从UCID数据集[32]的前800幅图像中随机选取,剩余的200幅从BSD-500数据集[33]中随机选取。测试集共有100幅图像,其中,50幅图像从UCID数据集中最后的500幅图像中随机选取,另外的50幅图像从BSD-500数据集中随机选取。每幅有雨图像都是无雨图像经过Photoshop人工模拟雨纹形成[34],为了提高网络生成去雨图像的能力、模拟现实情况,每幅图像都添加了不同方向、不同密集程度和不同大小的雨纹,大大提高了训练集和测试集内图像的多样性。真实的降雨图像数据集是从网络上下载的50幅有雨图像,为了确保实验的严谨性,本文选取图像的雨纹方向、密集度和大小都不相同,由于没有对应的清晰无雨图像,此数据集的处理并不在数据结果上有所体现,仅展示处理后的图像,在视觉上进行主观评价。
3.3 评价指标
本文选取峰值信噪比(PSNR)和结构相似性(SSIM)作为实验的评价标准。
PSNR是衡量图像质量的指标,值越大,图像处理效果越好, PSNR定义式为
(10)
(11)
其中:b表示每个像素点存储所占的位数;Vmax即2b-1;EMSE是生成图像I和目标图像K的均方误差;m和n分别是图像的高和宽。
SSIM用于衡量2幅图像之间的相似度,值越大,图像失真程度越小,SSIM定义式为
MSSIM(x,y)=(l(x,y)·c(x,y)·s(x,y))
(12)
(13)
(14)
(15)

3.4 不同损失函数结果分析
在本文改进的生成对抗网络去雨方法中提出了一种新的精细化损失函数,为了验证不同损失函数及其组合在生成去雨图像过程中的具体作用,分别对本文设置的损失函数进行拆分实验。训练测试过程中,除损失函数不同外,网络其余参数设定完全一致,同样使用PSNR和SSIM对生成的去雨图像进行数值评价。迭代相同次数后,同条件下选取原测试集中10组图像后的实验结果如表1所示。

表1 不同损失函数实验结果Table 1 Experimental results of different loss functions
由表1可知:添加内容损失后,PSNR提升至25.29 dB;添加感知损失后,SSIM提升至0.915 5;添加内容损失和感知损失后,PSNR提升至27.80 dB;添加不同组合的总变异损失后PSNR和SSIM数值也都有一定提升;而本文设置的精细化损失函数在PSNR和SSIM数值上有明显提升,相较于原始的条件对抗损失,PSNR提升了5.49 dB,SSIM提升了0.040 4。总变异损失影响域选择八邻域,损失和计算方式选择差值绝对值和的结果相对更好。
图6是不同损失函数训练处理后生成的图像对比。
从条件对抗损失LC的去雨图像可以看出,仅添加条件对抗损失使得处理后的图像细节严重丢失,图像中仍有较多雨纹,且会引入伪影;从添加内容损失LL1的去雨图像可以看出,图像产生的伪影更少并且在色彩呈现上有一定程度提升;从添加感知损失LVgg的去雨图像可以看出,一定程度上降低了重构图像与目标图像的差异性;从添加内容损失LL1和感知损失LVgg的去雨图像可以看出,图像整体还原度较高,但细节部分成像模糊,并残留雨纹;从添加总变异损失LTV1,LTV2和LTV3的去雨图像可以看出,图像整体变得相对平整光滑,清晰度有所提高。从使用本文提出的精细化损失函数的去雨效果图看,总变异损失影响域选择八邻域,损失和计算方式选择差值绝对值和的结果更好,生成图像不仅清晰平整,在视觉质量上也有较大提升,并且在去雨过程中没有产生伪影,完整地保留了图像细节内容,证明了精细化损失函数组成的合理性和高效性。
3.5 合成雨滴数据集的分析
为了验证本文提出的去雨方法比其他方法更具优越性,通过对数据集进行训练和测试,将本文提出的方法与SPM[6],PRM[9],DSC[7],CNN[11],GMM[8],CCR[10],ID-CGAN[34]的实验结果在该数据集上通过PSNR和SSIM进行对比。不同去雨方法的实验结果如表2所示,列举了不同方法在该数据集上的测试结果。
由表2可知,传统基于模型驱动方法的PSNR大都在20 dB以下,SSIM全部在0.8以下。基于深度学习的PSNR大都在20 dB以上,SSIM大都在0.8以上。本文方法与ID-CGAN[34]相比,PSNR提升0.2 dB,SSIM提升0.035,从结果看,本文方法相较于其他方法在PSNR和SSIM数值表现上都更好,有较大的提升。
图7是本文方法在合成雨滴数据集上的去雨效果,从图中可以看出,有雨图像经过处理后去雨效果十分显著,在生成的图像上基本未出现残留雨纹,也没有产生任何伪影,并且生成图像在视觉质量上有明显提高,图像色彩区域分明,图像清晰度高、平整光滑。

图7 合成雨滴图像去雨效果Fig.7 Rain removal effect of synthetic rain images
3.6 真实降雨图像的分析
为了验证本文去雨方法的现实性和可行性,体现图像去雨实验的丰富性,本文使用经过合成雨滴数据集训练后的网络对现实中的降雨图像进行测试,同时,为了兼顾实验的普适性,选取的图像同样具备不同的雨纹大小、方向和密集程度等特性。真实降雨图像去雨效果如图8所示,从图中可以看出,处理后的图像雨纹基本消失,没有产生伪影,图像的细节部分没有出现失真,对于雨纹较密集的现实雨图,处理后的图像清晰平整,并提高了图像呈现的视觉效果。因此,本文方法对真实降雨图像的去雨同样具备很好的效果。

图8 真实降雨图像去雨效果Fig.8 Rain removal effect of real rain images
3.7 复杂天气下图像去雨的分析
现实生活中,复杂天气时常出现,例如雨雾交融、雨雪交融等。这类场景产生的图像不仅包含雨纹,而且夹杂着水雾或雪纹,处理这种降雨图像非常困难。实验将本文方法应用于上述图像去雨,雨雪图像和雨雾图像的去雨效果如图9所示。


图9 复杂天气下图像去雨效果Fig.9 Rain removal effect of complex weather images
从图9可以看出:图9(a)中包含大量密集雨纹和雪纹,部分图像内容被遮盖;图9(b)仅消除了部分雨纹雪纹,图像边缘信息丢失,图像雨雪密集部分的消除效果较差;图9(c)中包含水雾和密集雨纹,并伴有雨滴白点;图9(d)视觉效果模糊,仍存在大量密集雨纹,并且图像中雨滴白点的消除效果不明显。实验表明,本文方法对复杂天气下图像去雨处理的作用较小。
4 总结
本文提出一种结合卷积自编码和补丁惩罚的生成对抗网络单图像去雨方法。该方法采用生成对抗网络的基本体系,生成器网络是基于卷积自编码的编码-解码结构,由对称的卷积层和转置卷积层构成,并使用跳跃连接形成残差块,确保添加深层网络时的训练收敛性能;引入马尔可夫鉴别器网络,有效提高输出图像细节质量,去除生成图像中的伪影。两者相互对抗训练,各自的能力在对抗学习中稳步提升,使得生成图像色彩饱满清晰平整,与目标图像高频信息更加接近;设计了一种新的精细化损失函数,增强生成对抗网络训练的稳定性,提高整个网络的学习能力,使得去雨算法更加高效。实验结果证明了此方法对有雨图像进行去雨操作的可行性和高效性,在基本还原目标图像内容信息的基础上,提升了生成图像的视觉质量。
本文方法依旧存在不足之处,如当雨条纹极其密集、对目标图像产生大部分遮挡时,无法进行有效的去除;如在几种天气同时发生时的图像处理也未考虑,像雨雾、雨雪、雷雨等;如夜晚能见度较低时,有雨图像的雨纹去除则更为艰难。如何改进算法或者更改模型将是进一步研究的方向。
猜你喜欢
通信学报(2022年10期)2023-01-09
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
国防科技大学学报(2019年4期)2019-07-29
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
系统工程与电子技术(2016年5期)2016-11-02
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
