
面向知识图谱的会话式机器阅读理解研究综述
2024-03-03 11:21奚雪峰崔志明
计算机工程与应用 2024年3期
胡 娟,奚雪峰,2,3,崔志明,2,3
1.苏州科技大学 电子与信息工程学院,江苏 苏州 215000
2.苏州市虚拟现实智能交互及应用技术重点实验室,江苏 苏州 215000
3.苏州智慧城市研究院,江苏 苏州 215000
机器阅读理解的研究可以追溯到20世纪70年代[1],但是由于硬件设备的限制和数据集的缺失,近年来国内学者才关注到它。机器阅读理解是为了使得机器和人一样能够理解文本,输入文章段落和问题,输出答案。随着自然语言理解和建模方面的发展以及CoQA[2]和QuAC[3]大规模对话数据集的引入,使得研究朝着对话式机器阅读理解(conversational machine reading comprehension,CMC)方向发展。
对话式机器阅读理解即在机器阅读理解的基础上加上多轮对话,使得多轮对话之间有着密切的联系。这和人通过多轮对话探索某一方面的知识相符合,更加切合于实际。会话式机器阅读理解由文章段落、对话历史和对话三个部分组成,既要对文章段落进行编码,还要对对话历史进行编码。在机器中难以理解对话中的一些语言现象,比如焦点转移[3]、话题转移等。目前对于该领域的研究仍处于初级阶段,在模型的推理能力和对话的理解能力这两方面还有很大的研究空间。知识图谱推理可以利用图谱中已有的事实推断出缺失的关系和隐含的关系[4],能够有效地应对一些复杂的语言现象,基于此,将知识图谱应用于CMC领域,可以提升模型的推理能力,进一步提升答案预测的准确性。
本文从CMC开始,简要介绍了CMC刺激该领域研究的大规模会话数据集以及当前的一些模型方法,并对模型的性能和优缺点作了简要的分析。然后,介绍了知识图谱的定义、架构以及四大核心技术,并详细介绍了三大类知识图谱推理问答的模型方法。最后,对未来的研究重点进行展望。
1 会话式机器阅读理解定义及挑战
CMC的任务定义:对于给定的文章段落P,对话历史Hi={Q1,A1,Q2,A2,…,Qi-1,Ai-1}和一个问题Qi,该模型任务就是从已有的文章段落和会对话历史预测问题Qi的答案Ai。答案大致分为两种形式:文章中提取的跨距文本[3]和与文章相关的自由形式的文本[2]。
单轮机器阅读理解(machine reading comprehension,MRC)模型并不能直接应用于CMC,因为CMC 还需要模型有着捕捉多轮对话之间关系的能力。并且对人类信息寻求对话的一般观察表明,开始对话倾向于关注文章的开头部分,并随着对话的进行将注意力转移到后面的部分[3]。因此,该模型被期望捕捉到对话中的这些焦点转移,并从语义角度进行推理,而不仅仅是通过词汇或释义进行匹配。多回合对话通常是增量的和相互参照的。这些对话要么是深入,要么转移话题,要么返回话题,要么澄清话题,或者是定义一个实体[5]。因此,模型应该能够从历史中获取上下文,这些历史可能是直接的,也可能不是。如何从不同问答对之间获取信息,还是该领域的一大挑战。
2 数据集
CMC研究的快速发展源于大规模多回合会话数据集的出现:CoQA[2]和QuAC[3]。
2.1 CoQA
CoQA数据集(https://stanfordnlp.github.io/coqa/)是来自7个不同领域收集的段落,分别为来自CNN的新闻文章[6]、MCTest[7]的儿童故事、RACE[8]的中学英语考试、Project Gutenberg 网站上的文学文章、Writing Prompts dataset 网页的Reddit 社区文章、AI2 Science Questions网站上的科学文章,以及维基百科。在这7 个领域中,两个用于域外评估,仅用于评估,而不是培训,而其他5个用于域内评估,包括培训和评估。问题几乎都是可回答的问题,但需要充分的共同引用和实用推理[9]。此数据集答案生成方式有66.8%是跨距抽取生成的,有33.2%是自由生成的。使用单词重叠的宏观平均F1 值作为评价指标,在域内和域外分别计算。
2.2 QuAC
QuAC 数据集(https://quac.ai/)来自维基百科文章段落,涉及不同类型的人,如文化和野生动物。该数据集使用非对称设置,学生只被允许看到章节的标题和主要文章的第一段,而教师则被额外提供了对章节文本的全部访问权限。因此,学生试图根据从对话中获得的有限信息来寻找关于隐藏问题的信息,而老师则通过提供该部分的简短摘录来回答。问题是描述性的、高度上下文化的、开放性的,因为数据集的不对称特性阻止了释义。它们需要充分的共同参照和实用推理。除了对话是逐渐深入的,它比CoQA更频繁地切换到新主题。它的答案是提取的,可以是yes/no 或no answer。除了提取广度,回答还包括被称为对话行为的附加信号,如继续包含后续、可能后续,或不后续以及肯定包含是、否,或两者都不,这提供了额外的有用的对话流信息,用于训练,正如Qu等人[10]和Ju等人[11]所使用的。QuAC答案更长,这可以归因于它的非对称性质,从而激励搜索者提出开放式问题来衡量隐藏的文本。此数据集除了整个集合的宏观平均F1得分外,QuAC还评估人类等效得分(human equivalence score,HEQ),通过找到系统的F1 匹配或超过人类F1 的实例百分比,来判断系统相对于平均人类的性能。HEQ-Q和HEQ-D是分别作为问题和对话的HEQ分数。
3 会话式机器阅读理解模型分析
3.1 CMC模型框架
Gao 等人[12]将典型神经MRC 模型中定义阅读理解的步骤,首先,将问题和文章段落编码一组嵌入中;然后在神经空间进行推理以识别答案向量;最后输出自然语言。Huang 等人[13]通过添加会话历史建模在CMC 中调整了这些步骤。Qu等人[10]提出了一种ConvQA模型,该模型具有历史选择和建模的独立模块。在这些工作的基础上,合成了一个CMC 模型的通用框架。典型的CMC模型包含文章段落P,当前的问题Qi和会话历史Hi,以及需要生成一个输出答案Ai。CMC框架如图1所示。根据它们对整个CMC 流程的贡献,该框架有四个主要组件。
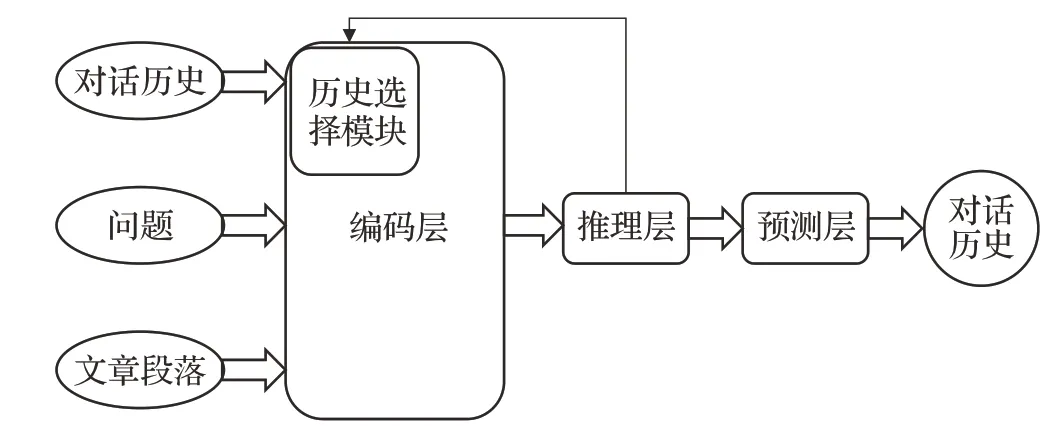
图1 CMC模型的通用框架Fig.1 Common framework of CMC model
现有的模型都是先基于词向量和BERT[14]实现文章段落、对话历史和问题的编码,形成具有语义信息的低维向量。然后,将其转换为推理模块的输入嵌入。在高层次上,涉及到与上下文无关的单词嵌入的转换和组合,称为词汇嵌入。如GloVe[15],序列内上下文嵌入,如ELMo、BERT[14]或RNN(recurrent neural network),问题感知嵌入以及额外的特征嵌入,如POS 标签[16]、历史嵌入[10]或对话计数。对话历史通常与该模块集成到所有上下文输入嵌入中,这个过程称为历史建模,是CMC编码器最重要的方面。推理层需要融合各方面的信息,以生成支持查询和支持历史的上下文化输出嵌入,这个过程可能涉及单步推理或多步推理。该模块的输入通常包含每个历史回合的两个或多个序列集,或跨所有回合聚合,然后在每个层中融合,并经常相互交织[13]。模型输出可以是文本跨度、对话行为之类的信号[3]或自由形式的答案[2]。
3.2 CMC模型分析
在数据集CoQA 和QuAC 发布后,诞生了大量有代表性的模型。Reddy等人[2]使用DrQA+PGNet的组合模型作为数据集CoQA的基线模型。其中DrQA[17]模型根据问题的内容从文章段落中寻找答案线索,该模型在多个数据集上表现出了强大的性能[18-19]。因为DrQA在训练时要求将文本跨度作为答案,所以作者选择与原始答案有最高词汇重叠的跨度作为答案。如果答案在故事中出现多次,就会用这个原理找到正确的答案。如果任何答案词没有出现在故事中,就返回到一个额外的未知标记作为答案。作者在每个问题前面加上过去的问题和答案,用来说明对话的历史,与对话模型相类似。考虑到数据集中有很大一部分答案是“是”或“否”,还增加了一个增强阅读理解模型进行比较。在文章末尾添加两个额外的令牌:是和否,如果黄金答案是或否,则需要模型预测对应的令牌作为黄金跨度;否则它将执行与前一个模型相同的操作。PGNet[20]模型则根据线索来生成预测答案。Choi 等人将改进后的BiDAF++和BiDAF++w/n-ctx 模型作为数据集QuAC 的基线模型,其中BiDAF++模型将自注意力机制和情景化嵌入应用BiDAF[21]模型上。
会话机器理解需要理解对话历史,为了使传统的单轮模型能够全面地对历史进行编码,引进了Flow 机制。与将问题和答案作为输入连接起来的方法相比,Flow 在集成对话历史的潜在语义方面更加有效果。FlowQA 模型[13]在最近提出的两项对话挑战上表现优异。Flow的有效性也表现在其他任务中。但随着会话的进行,会话机器理解需要对对话流程有深入的理解,而之前的工作提出了FlowQA 来隐式建模推理中的上下文表示,以更好地理解。Yeh等人[22]提出FlowDelta模型,通过对话推理对信息增益进行显式建模,使模型能够聚焦于信息量更大的线索。该模型在对话式数据集QuAC上取得了最先进的性能,表明了所提机制的有效性,并展示了其对不同QA 模型和任务的泛化能力。Chen等人[23]认为现有的方法不能有效地捕获会话历史,很难解决涉及共引用或省略的问题。此外,针对在推理时将文章简单地视为一个词序列,而忽略词之间丰富的语义关系的问题,提出了GraphFlow模型。该模型提出了一种简单而有效的图结构学习技术,在每个对话回合动态构建一个感知问题和对话历史的上下文图。GraphFlow 模型在捕获对话中的会话流很有效,并在CoQA和QuAC测试中显示出与现有的最先进方法相比具有竞争力的性能[23]。大多数模型简单地结合之前的问题进行对话理解,只使用循环神经网络进行推理。为了从不同的角度深刻而有效地理解上下文,Zhang[24]提出了一种新的神经网络模型——多视角卷积立方(multi-perspective convolutional cube,MC2)。他们把每次对话都看作一个立方体,将一维卷积和二维卷积与RNN 相结合。为了解决模型预演下一轮对话的问题,还将部分因果卷积扩展到2D。在CoQA数据集上的实验表明,此模型取得了最先进的结果。
Qu 等人[25]在原有模型框架的基础上,将会话历史通过BERT 上下文嵌入传入模型,基于此提出HAE(history answer embedding)以及PosHAE(positional history answer embedding)[10]嵌入方法。HAE 可以将对话历史无缝集成到建立在BERT 上的会话问题回答模型中,即ConvQA是对话搜索的一个简化但具体的设置,然后提供一个解决ConvQA 的通用框架。PosHAE提出了一个涉及三个方面的ConvQA解决方案。首先,它提出了一种使用BERT[14]对带有位置信息的对话历史进行自然编码的位置历史答案嵌入方法。其次,设计了一个历史关注机制(history attention mechanism,HAM),对对话历史进行“软选择”。这种方法根据历史转折对回答当前问题的帮助程度,对历史转折进行不同的权重处理。最后,除了处理对话历史之外,此方法利用多任务学习,使用统一的模型体系结构进行回答预测对话行为预测。
与传统的单轮机器阅读理解任务不同,对话性问题回答包括文章理解、共参考解析和上下文理解。于是,Zhu等人[16]提出了一种基于注意力的上下文的深度神经网络(SDNet),将上下文融合到传统的MRC 模型中。模型利用相互注意和自我注意来理解会话上下文,并从文章中提取相关信息。由于BERT 对输入序列的数量和长度有限制,用BERT对多回合问答建模还没有建立起来。Ohsugi等人[26]就提出了一种简单而有效的方法,即使用BERT来编码一个独立的段落,在多回合上下文中,每个问题和每个答案都是有条件的。然后,该方法用BERT 编码的段落表示预测一个答案。但是模型对于对话历史的顺序问题没有很好的解决方式。
文章段落与会话历史长度超出512字符,超过BERT限制输入序列的长度。于是,Gong等人[27]针对此问题,提出BERT-RCM(BERT recurrent chunking mechanisms)模型。该模型通过强化学习以更灵活的方式学习分组,还采用循环机制,使信息在各个部门之间流动。这样可以获得更可能包含完整答案的片段,同时围绕基本真相答案提供足够的上下文,以更好地预测。之后,Zhao 等人[28]提出了一种读-过-读方法RoR,它将读取字段从块扩展到文档。具体来说,RoR 包括一个块阅读器和一个文档阅读器。前者首先预测每个数据块的一组区域答案,然后将其压缩成原始文档的高度浓缩版本,保证只编码一次。后者从这份浓缩的文件中进一步预测了全部答案。最后,利用投票策略对区域和全局答案进行聚合和重新排序,以实现最终预测。值得注意的是,RoR在提交时在QuAC数据集排行榜上排名第一。
对话式问题回答需要了解对话历史,这是一项具有挑战性的任务。Ju等人[11]提出了一个新的系统RoBERTa+aT+KD,包括理论标注多任务、对抗训练、知识蒸馏和语言后处理策略。这个单一模型在CoQA 测试集上达到了91.4%,在没有数据增强的情况下,得到的F1 值高于人类。
表1展示了上述所分析的模型在CoQA数据集上所表现的性能,可以看出目前已经有模型超过了人类水平。同时可以看出,与流机制相结合的模型中,Graph-Flow的推理能力要优于FlowQA,BERT-FlowDelta推理能力与之相当。最新提出的新系统RoBERTa+aT+KD,它的推理性能明显是优于人类的推理能力的。

表1 模型在CoQA数据集上的F1值Table 1 F1 values of model on CoQA dataset 单位:%
表2展示了上述所分析的模型在QuAC数据集上的推理性能,可以看出当前大多数模型与人类水平相比仍有很大的进步空间。由于数据集非对称的特性,需要对原有信息进行额外的加工和提取才能准确预测答案,需加强模型的推理能力。
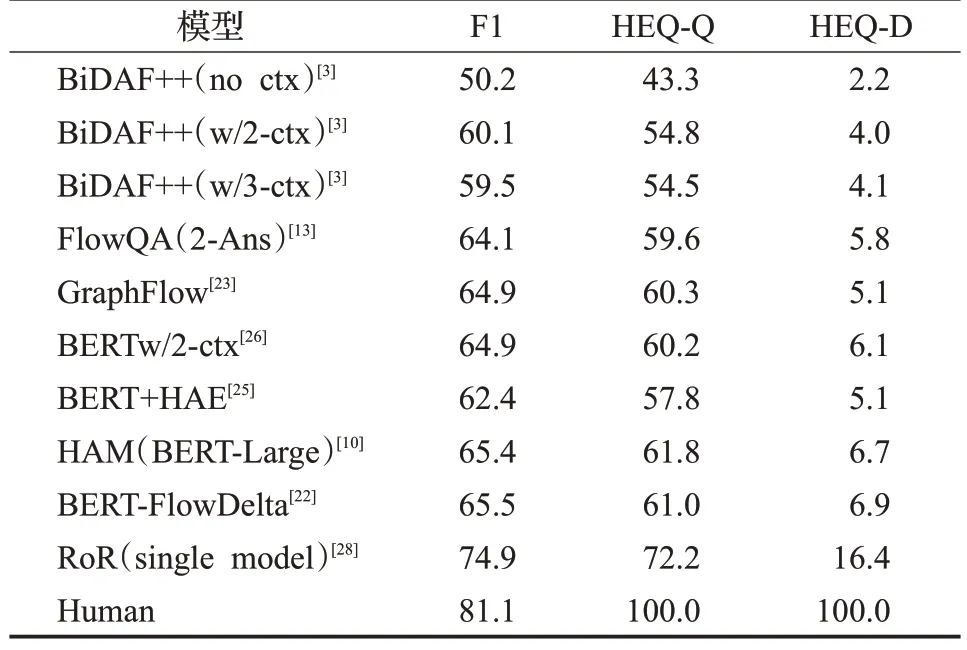
表2 模型在QuAC数据集上F1值和HEQ得分Table 2 F1 values and HEQ scores of model on QuAC dataset 单位:%
表3展示了各模型的优缺点,从表中可以看出目前的大部分模型都使用了自注意力机制或者是它的变体来进行推理。随着BERT的出现,将其运用到文章段落和历史会话的嵌入表示,使得模型从历史会话中抽取与问题相关的能力在逐步提升。但是以上大多数模型的答案生成方式都是从文章中抽取预测答案,很少是自己生成预测答案,这使得会话转换的流畅度降低。

表3 会话式机器阅读理解模型比较Table 3 Comparison of conversational machine reading comprehension models
4 知识图谱推理问答
知识图谱是由实体以及实体间关系组成,用三元组形式表示两者间的关系。知识图谱推理是知识图谱构建中重要的组成部分,它根据现有事实,推断出实体间隐含的关系或缺失的事实,可应用于推理问答,来缓解现有的CMC模型推理能力较差的问题。
4.1 知识图谱架构
知识图谱可划分为数据层和模式层。在数据层,以事实为单位将数据存储在图数据库中。以“实体-关系或属性-实体”三元组来表示两个实体间的关系,实体可以是具体的人名、地名等,也可以是时间、大小等属性值;关系是两个实体间的语义关系。模式层在数据层之上,是知识图谱的核心,提炼过的知识存储在模式层,更适用于知识图谱推理。数据层到模式层的转化过程如图2所示。

图2 知识图谱数据层到模式层的转化过程Fig.2 Transformation process from knowledge graph data layer to pattern layer
知识图谱的构建方式分为自顶向下与自底向上。自顶向下是先定义好本体与数据模式,再将实体加入到知识库;自底向上是从数据中提取实体,将置信度较高的加入到知识库,再构建顶层的本体模式[29]。目前,大多采用自底向上的方式构建,Google 的Knowledge Vault[30]最典型。
4.2 知识图谱的关键技术
知识图谱中包含知识的抽取、表示、融合和推理四大技术,接下来对这四个技术进行简要介绍。
4.2.1 知识抽取
知识抽取通过知识抽取技术,从半结构化或者非结构化的数据中抽取可用的知识,抽取要素为实体、关系以及属性,在此基础上形成高质量的事实表达,为模式层的构建奠定基础。
4.2.2 知识表示
基于三元组的知识表示形式广泛使用,但是该形式数据稀疏,使得计算效率低。数据表示是机器学习算法成功的关键,因为不同的解释性变异因素可以隐藏在不同的制图表达中。以深度学习为代表的编码技术将实体的语义表示为低维实值向量,然后计算实体、关系及其两者间的关联,构建知识库[31-33]。
4.2.3 知识融合
知识融合是高层次的知识组织[34],在同一框架规范下,将不同知识源的知识进行异构数据的整合,形成知识库。知识融合的方式主要有知识对齐、知识加工和知识更新。
实体对齐是从顶层创建一个大规模的知识库,形成统一高质量的知识,解决异构数据中实体冲突等问题。知识加工包括本体构建与质量评估。本体是同一领域内不同主体之间交流的基础[35],冗余程度小[36]。Probase是目前为止可信程度最高的知识库[37]。基于LDIF 框架[38],采用人工标注的方式对1 000 个句子中的实体关系三元组标注[39],使用逻辑回归模型计算结果的置信度[31]。知识更新包括模式层与数据层的更新。模式层更新即本体中元素的更新[40],需人工干预[41];数据层更新即实体元素的更新,以自动的方式完成。
4.2.4 知识推理
知识推理即在已有知识的基础上推断出隐藏知识,扩展知识库。由于实体、属性以及实体间关系较为复杂,推断过程中难以列出所有的关联规则,复杂的规则需人工推理。挖掘推理规则,依赖于实体及其关系间的联系。
4.3 知识图谱推理问答方法分析
目前已有的知识图谱问答推理(knowledge graph question answering,KGQA)方法分为三类:基于逻辑的方法、基于图嵌入的方法以及基于深度学习的方法。
4.3.1 基于逻辑的方法
基于逻辑的推理方法即在专家规定的规则[42]或既定的逻辑规则[43]基础上进行显式推理,可解释性强。大多基于逻辑的推理方法[44]是有着特定的领域,语法和图谱结构的不匹配会降低推理的性能。为解决此问题,有学者提出查询图方法。
Yih 等人[45]提出查询图定义,查询图与知识库的子图相类似,可直接转变为逻辑形式。早期的知识库基础上,该方法能够精简搜索空间,简化语义匹配问题。Luo等人[46]遵循STAGG(staged query graph generation)的查询图生成方法,便于获取复杂问题中,各种语义之间的关系。Sorokin 等人[47]与Maheshwari 等人[48]也是改进编码方法,前者使用门控图神经网络(gated graph neural networks,GGNN),改进了多个实体以及实体间关系的向量表示问题,很好地解决了复杂语义的问题;后者提出基于自我注意的槽位匹配模型,在图的固有结构基础上,改进了由大问答数据集向小数据集的改进,一定程度上解决了数据集的缺失问题。
以上查询图的方法存在噪声和表达能力有限的问题,因此,部分学者对此进行改进。Hu等人[49]提出了一种基于状态转换的方法,将复杂的自然语言问题转换为语义查询图,该查询图用于匹配底层知识图以找到问题的答案,利用四种基本操作展开、折叠、连接和合并来生成查询图。Ding 等人[50]提出了一种基于频繁查询子结构的查询生成方法,它有助于对现有查询结构进行排序或构建新的查询结构,在复杂问题上效果更加显著。由于观察到在查询图中早期加入约束可以更有效地修剪搜索空间,Lan 等人[51]提出了一种改进的阶段查询图生成方法,该方法具有更灵活的生成查询图的方式,可以同时处理具有约束性的问题和具有多跳关系的问题。Chen等人[52]提出了一种新的形式化查询构建方法,该方法由两个阶段组成。第一阶段预测问题的查询结构,并利用该结构约束候选查询的生成,提出了一种新的图生成框架来处理结构预测任务,并设计了一个编码器-解码器模型来预测每个生成步骤中预定操作的参数;第二阶段按照前面的方法对候选查询进行排序。
Hamilton等人[53]为解决不完整图谱上的复杂逻辑推理,提出图查询嵌入框架(graph query embedding,GQE)。模型如图3,其中q=V?∃V:Win (TuringAward,V)∩Citizen(Canada,V)∩Graduate(V,[V?]),首先,GQE 将查询语句表示为图,如图3中的(1),再将图放到低维向量中,如图中的(2)所示;其次,从节点开始,迭代地应用映射算子P与合取算子I,生成相对应查询的嵌入q,最后根据q预测答案。其中P是将头实体表示通过关系类型连接得到新的嵌入表示,而I是计算两个集合嵌入的交集,流程如图3(a)所示。但该模型只能应用于合取问题。

图3 基于逻辑推理的方法框架Fig.3 Method framework based on logical reasoning
表4是基于逻辑的方法优缺点比较,基于逻辑的方法适用于带有否定的问题,但是该方面的研究还很薄弱,利用逻辑规则来解决问答中否定词的问题是一大研究方向。利用这种方法推理问答,有着既定的逻辑规则作为基础,可解释性强。
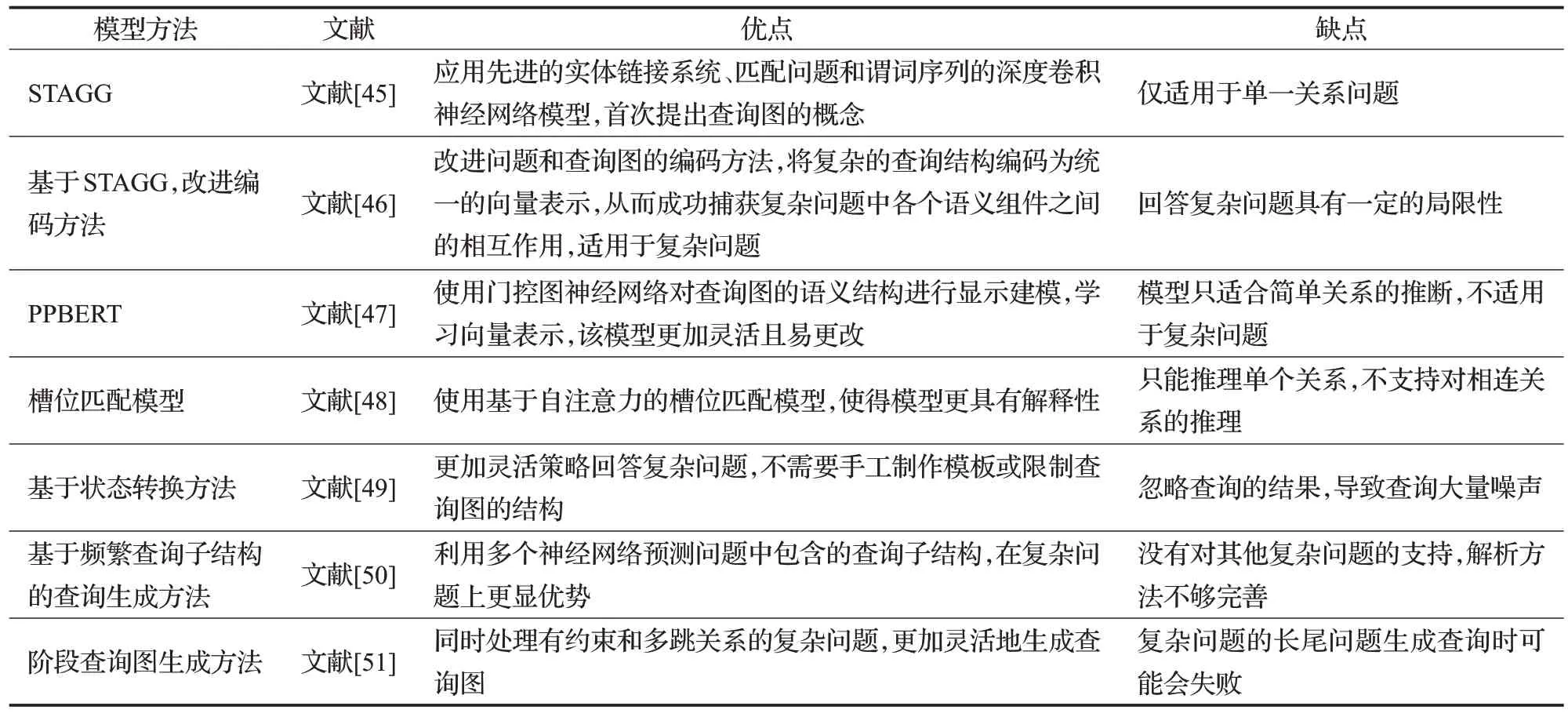
表4 基于逻辑的方法模型比较Table 4 Comparison of logistic-based method models
4.3.2 基于图嵌入的方法
基于嵌入表示方法中典型的模型是Bordes 等人[54]提出的TransE[55]模型(https://github.com/thunlp/Open-KE),该模型易训练,含参数少,并能够扩展到大的数据库。后续,人们又提出TransE的衍生变体ComplEx[56](https://github.com/thunlp/OpenKE),用于解决实际问题。基于图嵌入方法流程图如图4所示。
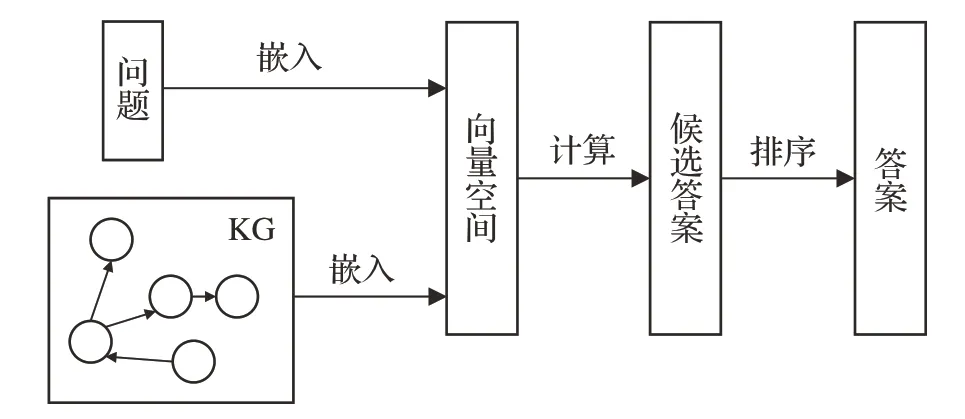
图4 图嵌入方法流程图Fig.4 Flowchart of embedding method
Wang等人[57]提出了一种基于RDF图嵌入的框架来解决连续向量空间方面的SPARQL 空答案问题。首先通过专门为SPARQL 查询设计的实体上下文保留平移嵌入模型将RDF(resource description framework)图投影到连续向量空间中。然后,给定一个返回空集的SPARQL 查询,将其划分为几个部分,并通过利用RDF嵌入和转换机制计算近似答案。他们还为返回的答案生成替代查询,有助于用户识别他们的期望并最终优化原始查询。所提出的框架可以显著提高近似答案的质量,并加快替代查询的生成速度。在知识图谱上回答自然语言问题的一个有希望的途径是将自然语言问题转换为图结构查询。在翻译过程中,一个至关重要的过程是将自然语言问题的实体、关系短语映射到基础知识图谱的顶点、边缘,这些顶点、边缘可用于构建目标图结构化查询。然而,由于语言的灵活性和自然语言的模糊性,映射过程具有挑战性,一直是知识图谱问答模型的瓶颈。对于此,Wang等人[58]提出了一个名为KemQA的新框架,它基于关系短语词典和知识图嵌入技术的最新进展,以解决映射问题并构建自然语言问题的图结构查询。对于理想知识库既不完整又过度指定,Sun 等人[59]提出查询嵌入(embedding query language,EmQL)系统,它在不需要泛化或松弛的答案上可能与演绎推理不一致,Sun等人就用一种新的量化宽松方法解决了这个问题,这种方法更忠实于演绎推理,并表明这在对不完整理想知识库的复杂查询上有更好的性能。
为了更方便利用知识图谱中的知识,有人提出通过对问句和候选答案训练,预测最终的结果。Huang 等人[56]针对语言的模糊性问题,提出知识嵌入问答框架(knowledge embedding based question answering,KEQA),即将每个实体表示为低维向量,保留图谱中的关系信息。Saxena 等人[60]针对多跳推理问题以及图谱信息缺失问题,提出EmbedKGQA 模型,EmbedKGQA适用于稀疏的图谱。该模型还放宽了从预先指定的邻域中选择答案的要求,这是以前的多跳知识图谱推理方法强制执行的次优约束。首先,该模型利用ComplEx[61]方法将图谱嵌入至复数空间,捕获特征信息;其次,使用RoBERTa 模型[62]对问句编码,再替换为向量,使用打分函数以及损失函数训练数据;最后,对候选答案打分,选择分数高的作为答案。
表5是基于图嵌入的方法优缺点比较,基于图嵌入的方法着力于解决图谱不完整和语言的模糊性问题,稳定性强。但此方法推理能力弱,可解释性差,同时会影响答案预测的准确率。
表5 基于图嵌入的方法模型比较Table 5 Comparison of method models based on graph embedding
4.3.3 基于深度学习的方法
基于神经网络的方法是通过循环神经网络获取路径信息[63];能够利用强化学习通过策略的代理顺序获取推理路径,获取答案;能够利用图神经网络获得邻域信息以及图谱结构信息,预测缺失信息。
基于图神经网络的知识图谱推理问答方法是一种利用图神经网络技术进行知识图谱推理和问答的方法。通过将图神经网络与知识图谱相结合,可以实现对复杂的知识推理和问答任务的处理。
Zhang等人[64]提出了一种新颖而统一的深度学习架构,以及一种端到端变分学习算法,该算法可以处理问题中的噪声,同时学习多跳推理。他们还推导了一系列新的基准数据集,包括多跳推理问题、神经翻译模型释义问题和人声问题,解决了自然语句中语义模糊的问题。Sun 等人[65]研究了一个更实际的设置,即知识库和实体链接文本组合的问答,这适用于大型文本语料库中可用的不完整知识库。基于图表示学习的最新进展,他们提出了一个新的模型GRAFT-Net,用于从包含文本和知识库实体和关系的特定问题子图中提取答案。对于这个问题,他们构建了一套基准任务,改变了问题的难度、训练数据的数量和知识库的完整性。由于上述模型的抽取子图的方法是启发式的,会引入不相关的实体,Sun 等人[66]提出了PullNet,这是一个集成框架,用于学习从知识库和语料库检索,以及对这些异构信息进行推理以找到最佳答案。PullNet使用迭代过程构造特定于问题的子图,其中包含与问题相关的信息。在每次迭代中,使用图卷积网络来识别子图节点,这些子图节点应该使用语料库和知识库上的检索操作进行扩展。在子图完成后,使用一个类似的图卷积神经网络从子图中提取答案。这种检索和推理过程允许我们使用大型知识库和语料库回答多跳问题。PullNet 是弱监督的,需要问答对,但不需要黄金推理路径。通过实验,PullNet改进了先前的技术状态,并且在语料库与不完整知识库一起使用的情况下,这些改进通常是显著的。在纯KB设置或纯文本设置中,PullNet 通常也优于以前的系统。Xiong 等人[67]提出了一种新的端到端问答模型,该模型学习从不完整知识库和一组检索到的文本片段中聚合答案证据。在假设结构化知识库更容易查询,获取的知识有助于理解非结构化文本的前提下,模型首先从与问题相关的知识库子图中积累实体知识;然后在潜在空间中对问题进行重新表述,并利用手头积累的实体知识阅读文本。来自知识库和文本的证据最终被汇总以预测答案。
Das 等人[68]提出MINERVA 方法,它解决了更加困难和实际的任务,即回答关系已知但只有一个实体的问题。由于在目的地未知且从一个起始节点出发有多条路径的情况下,随机漫步是不切实际的。Lin 等人[69]针对上述两种问题,提出奖励形成的RL模型,用预训练的单跳嵌入模型来预测未观察事实,降低假阴性监督的作用。但该方法不适用于复杂问题,因此Qiu 等人[70]提出了一种基于强化学习的神经方法,即逐步推理网络。该模型对知识图谱进行有效的路径搜索以获得答案,并利用波束搜索减少候选者的数量。该方法可以加速训练算法的收敛,更好表现模型,如图5 所示。He 等人[71]提出了一种新颖的师生方法,学生网络找到查询的正确答案,教师网络学习中间监督信号,来提高学生网络的推理能力,缓解推理的虚假问题。
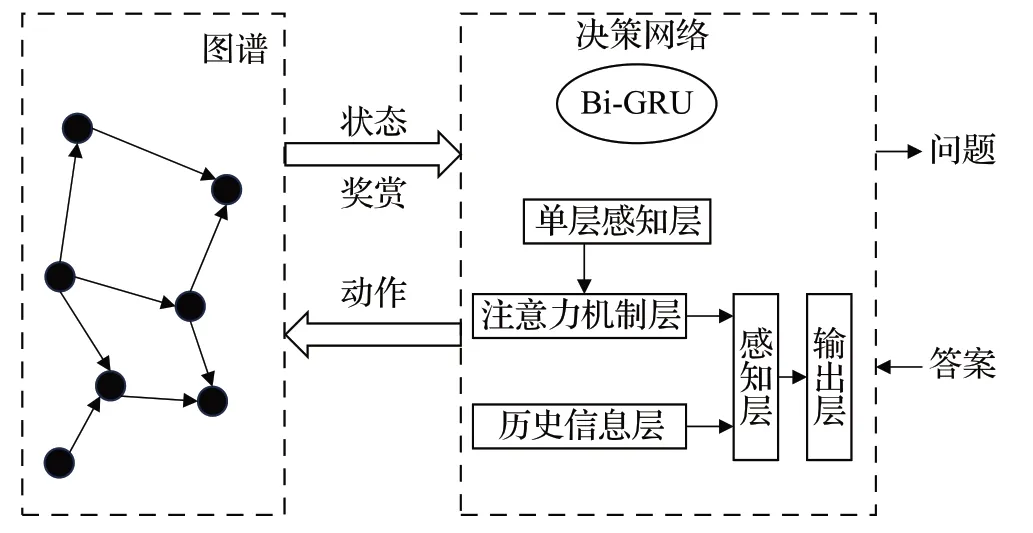
图5 基于强化学习的方法框架Fig.5 Methodological framework based on reinforcement learning
如何充分利用知识图谱上下文理解问句中的隐含实体或关系,以及时间、排序和聚合等复杂约束条件等,一直是理解问题意图的主要挑战。针对此问题,Gao等人[72]提出了一种基于语义块的知识图谱问答语义解析框架,结合了基于规则的准确度和基于深度学习的覆盖度,实现了问题到语义块序列的解析和语义查询图的构造。框架将问题意图使用基于语义块的语义查询图表示,将问题的语义解析建模为语义块序列生成任务,采用编码器-解码器神经网络模型实现问题到语义块序列的解析,然后通过语义块组装形成语义查询图。同时,结合知识图谱中的上下文信息,模型使用图神经网络学习问题的表示,改进隐含实体或关系的语义解析效果。
表6是基于深度学习的方法优缺点比较,通过关系路径推理,可解决多跳问题。但关系路径扩展使得节点数迅速增加,因此关于计算空间减小和增强其预测能力是当前研究的一大挑战。

表6 基于深度学习的方法模型比较Table 6 Comparison of methods and models based on deep learning
表7对知识图谱推理问答方法进行了总结,对于三种方法的特点以及优缺点进行了比较。

表7 知识图谱推理问答方法对比Table 7 Comparison of knowledge graph reasoning question answering methods
5 总结与展望
本文介绍了CMC领域的数据集以及当前的一些模型方法,对模型的性能和优缺点做了简要的分析。然后,介绍了知识图谱的定义、架构以及四大核心技术,并详细介绍了三大类知识图谱推理问答的模型方法。最后,对未来的研究重点进行展望。
会话式机器阅读理解的数据集相较于特定的问答数据集种类更多,更加复杂,但是它也属于问答数据集,因此知识图谱应用于对话式机器阅读理解是可行的。到目前为止,会话式机器阅读理解的模型改进,一直未解决筛选历史问答对的问题。而知识图谱将实体之间的关系都表示出来,便于筛选历史问答对,将提高会话式机器阅读理解的会话推理能力。
目前很多问答平台都引入知识图谱[73],这是一个充满潜力的领域[74],发展趋势包括以下几个方面:
(1)跨文档、跨知识图谱的推理:目前的研究着力于单个知识图谱的推理和问答,未来将会关注多个知识图谱的推理和跨文档推理,使得系统能够整合更广泛的知识并大大提升推理能力。
(2)动态知识图谱构建:传统的知识图谱是静态的,而实际的对话和信息背景是动态,未来将会着力于构建动态的知识图谱,将能够更好地适应动态的对话。
(3)多模态会话理解:会话式机器阅读理解不局限于文本的理解,还可以涉及其他模块,比如语音、视频和图像等。未来将更加关注多模态的信息融合推理,实现更全面的对话交互。
(4)可解释性和可追溯性:会话式机器阅读理解的可解释性和可追溯性是十分重要的。未来的研究将会更加注重推理过程和答案生成的可解释性,并且注重模型对推理路径和知识来源的追溯能力。
未来,会话式机器阅读理解将可以应用于汽车领域,满足顾客对汽车的咨询、性能比较以及售后等要求,使得顾客有更好的购车体验。还可以应用于金融领域,实现网点的精准查询,便于了解到网点的联系电话、网点地址以及营业时间等信息。
猜你喜欢
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
制造技术与机床(2019年6期)2019-06-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中国交通信息化(2016年9期)2016-06-06
领导科学论坛(2016年9期)2016-06-05
图书馆研究(2015年5期)2015-12-07
