
深度学习在多核缓存预取中的应用研究综述
2024-03-05 04:58张建勋乔欣雨林炳辉
计算机应用研究 2024年2期
张建勋 乔欣雨 林炳辉

收稿日期:2023-05-24;修回日期:2023-07-19 基金项目:中国高校产学研自然基金资助项目(2021FNA04016)
作者简介:张建勋(1978—),男,河北保定人,副教授,硕导,博士,CCF会员,主要研究方向为混合存储优化(Zhangjx@tute.edu.cn);乔欣雨(1997—),女,江苏南京人,硕士研究生,主要研究方向为软件工程;林炳辉(1998—),男,福建泉州人,硕士研究生,主要研究方向为软件工程.
摘 要:当前人工智能技术应用于系统结构领域的研究前景广阔,特别是将深度学习应用于多核架构的数据预取研究已经成为国内外的研究热点。针对基于深度学习的缓存预取任务进行了研究,形式化地定义了深度学习缓存预取模型。在介绍当前常见的多核缓存架构和预取技术的基础上,全面分析了现有基于深度学习的典型缓存预取器的设计思路。深度学习神经网络在多核缓存预取领域的应用主要采用了深度神经网络、循环神经网络、长短期记忆网络和注意力机制等机器学习方法,综合对比分析现有基于深度学习的数据预取神经网络模型后发现,基于深度学习的多核缓存预取技术在计算成本、模型优化和实用性等方面还存在着局限性,未来在自适应预取模型以及神经网络预取模型的实用性方面还有很大的研究探索空间和发展前景。
关键词:深度学习;数据预取;多核架构;缓存优化;神经网络;研究综述
中图分类号:TP333;TP181 文献标志码:A
文章编号:1001-3695(2024)02-003-0341-07
doi:10.19734/j.issn.1001-3695.2023.05.0231
Review of deep learning-based multi-core cache prefetching research
Zhang Jianxun,Qiao Xinyu,Lin Binghui
(School of Information Technology Engineering,Tianjin University of Technology and Education,Tianjin 300222,China)
Abstract:The current research on the application of artificial intelligence techniques to the field of system architecture is promising,especially the research on applying deep learning to data prefetching in multicore architectures has become a research hotspot at home and abroad.This work studied the cache prefetching task based on deep learning and defined the deep learning cache prefetch model formally.Based on the introduction of current common multi-core cache architectures and prefetching techniques,this paper comprehensively analyzed the design ideas of existing typical cache prefetchers based on deep learning.The application of deep learning neural network in the field of multicore cache prefetching mainly adopts machine learning methods such as deep neural network,recurrent neural network,long and short-term memory network and attention mechanism.A comprehensive comparative analysis of existing deep learning-based data prefetching hierarchical neural models reveals that deep learning-based multicore cache prefetching techniques still have certain computational cost,model optimization,and practicality.In the future,there is still much room for research exploration and development prospect in adaptive prefetching models and the practicality of neural network prefetching models.
Key words:deep learning;data prefetching;multi-core architecture;cache optimization;neural network;research review
近年來,随着深度神经网络的发展,深度学习为系统结构研究领域中的硬件预测问题提供了新的研究方向和机会,例如分支预测和缓存替换等。然而,深度学习能否用于数据预取的研究是一个值得深入思考的问题。当前,深度学习解决数据预取问题主要面临着两个挑战。
挑战一是在数据预取模型中,输入通常是计算机程序访问内存的指令地址,输出则是对应指令地址所需的数据,由于数据预取中需要根据当前指令地址预测未来可能需要访问的数据地址,所以其输入和输出空间通常非常庞大。例如对于一个具有64位地址空间的地址相关预取来说,其输入和输出若是单个的地址值,输入和输出的个数则会达到千万级别,这是现有用于图像分类或语音识别的深度学习模型所不能处理的,因此深度学习用于数据预取存在着类别爆炸问题。挑战二是数据预取属于实时行为,一方面,深度学习的训练时间受限,基于深度学习的预取器没有明显的类别标签用于指导神经网络学习,无法事先通过获取具体的标签来训练模型,例如对于一个内存访问地址m,数据预取器可以学习预测m后续的任何地址,没有明确哪个地址标签可以指导深度学习模型的训练,因此深度学习用于数据预取还存在类别标记问题。
为解决这些问题,已提出多种技术方案,如Hashemi等人[1]将预取作为一个分类问题,并使用LSTM[2]作为预取模型,但该方案只关注了增量或步长相关性,并不能将其涵盖为解决所有相关性问题,且由于模型空间大小有限,只能在空间区域内学习delta增量。
由于现有的神经网络模型受到上述两个问题的困扰,其研究目标均是搭建一种能够学习增量和地址相关性的神经网络模型,然后利用数据预取的独有特性,建立一种新的神经网络结构来解决这两个问题。本文对常见的基于深度学习的多核缓存预取神经网络模型进行了对比分析与研究,对深度学习用于缓存预取的问题进行了梳理,并指出了未来的发展方向。
1 多核缓存架构及其预取技术
本章主要描述了多核缓存的架构,介绍了多核缓存的预取技术,重点建立了基于深度学习的缓存预取模型。
1.1 多核缓存架构
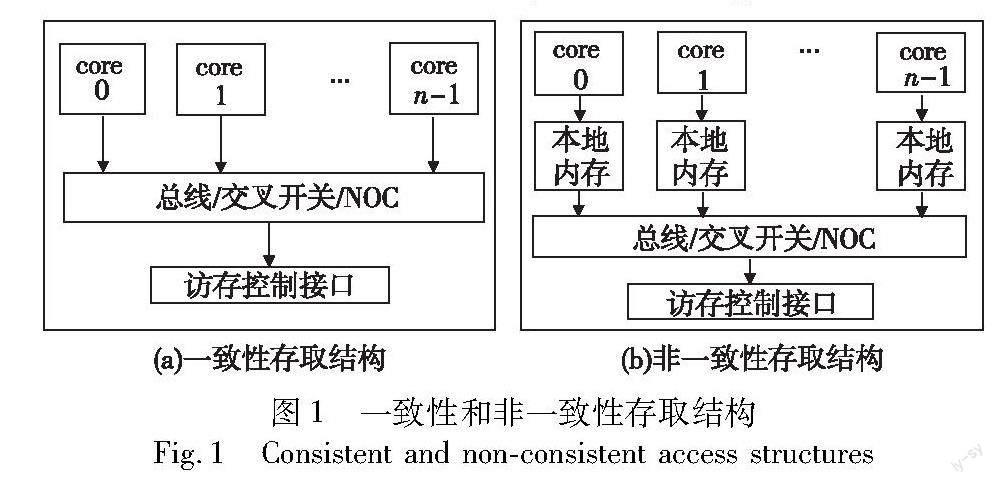
現代的多核处理器主要采用共享存储结构,传统的存储结构可分为一致性内存访问结构(uniform memory access,UMA)和非一致性内存访问结构(non uniform memory access,NUMA)。一致性存取结构是指所有的物理存储器被均匀的共享,每个处理器访问内存的时间是一致的。非一致性存取结构是指每个处理核有本地存储和远端存储,其存储访问时间不同,访问本地存储的速度远远高于访问远端存储的速度,如图1[3]所示。
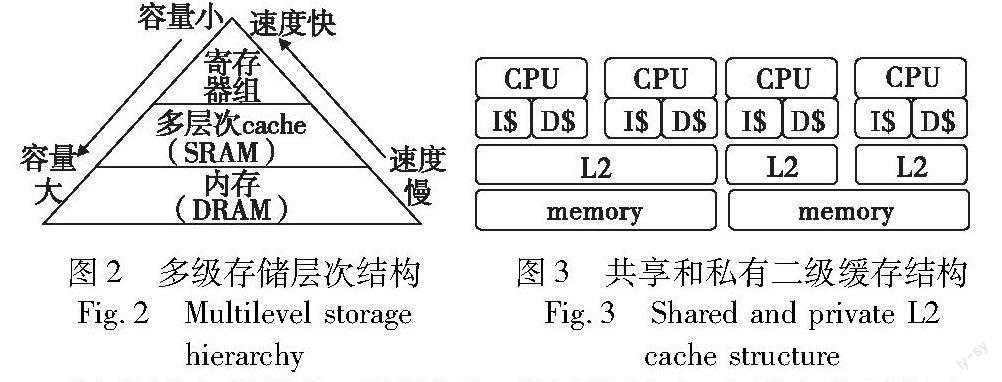
通常,处理器存储架构一般采用多级存储层次结构,如图2[4]所示。通常多核系统中都会加入两级以上的缓存,用于平衡处理器速度和底层存储速度之间的差异。片上多核缓存的存储架构主要有私有缓存、共享缓存和混合缓存三种结构。私有缓存通常是一级或者二级缓存,其结构和检索过程相对较简单,访问延时比较小,同时由于其隔离性,各个核之间的影响比较小;但对于每个核来说,可用的缓存资源也就相对比较少,所以缓存的命中率较低。共享缓存通常为二级或者三级缓存,共享缓存允许一个核访问全部共享的缓存,可用缓存资源比较多,所以其命中率较高;但这种结构需要所有的核都可以任意访问所有共享缓存的数据,结构相对复杂,从共享缓存中读写数据也会造成较大的访问时延。混合缓存结合了共享和私有缓存的存储架构,在混合缓存中,处理器会拥有自己的私有缓存,同时也与其他处理器共享一部分缓存空间,这样可以减少缓存之间的竞争,提高命中率和性能表现[5]。通常一级缓存为各个处理核私有,并且分为指令缓存和数据缓存,其容量较小,访问速度是整个层次化缓存存储结构中最快的一层。二级缓存一般容量较大,访问速度比一级缓存慢,但其可以保留更多数据。二级缓存的组织方式一般有私有和共享两种,如图3[5]所示,在这两种多核缓存结构中,私有缓存只由一个核所使用,各个核之间只能通过共享的内存或者专用的核间通信通道相联系;而共享缓存可以被多个核共享使用,缓存中所有的数据都可以被共享的多个核访问和使用。三级缓存一般为共享缓存,即为多个核所共享,其容量相比于二级缓存更大,访问速度较慢[6]。
随着缓存规模的不断增大,其平均访存时延也变得很大,因此提高共享缓存的命中率,减少远端的内存数据请求访问,在一定程度上能够提高多核处理器的性能,这也是多核缓存数据预取技术的根本目的。
1.2 多核缓存预取技术
数据预取主要是为了屏蔽缓存缺失而导致的数据访问延迟,从而弥补处理器和内存之间的性能差距。通过硬件或软件的支持,数据预取使数据在被请求之前能够更加接近处理器。近年来提出了多项多核缓存预取技术,通过利用多核架构来减少数据访问延迟。但是,多线程和多核处理器架构的出现为设计有效的预取策略带来了新的机遇和挑战。挑战之一就是多个计算内核在共享内存带宽的同时,竞相获取常规数据和预取数据。对于单核处理器而言,主存只接受来自一个内核的预取请求;而在多核处理器中,不仅需要处理常规的数据访问请求,还要处理来自多个内核的预取请求,因此大量请求会给主存带来更大的压力[7]。挑战之二就是缓存一致性问题。多核处理器访问主存,主存由多核共享,因此在内存层次结构的某个级别上必须解决对内存的冲突访问。现有多核处理器中的缓存一致性通常通过基于目录的方法或侦听缓存访问来解决。
Byna等人[8]针对多核处理器的预取机制进行了分类,主要针对硬件预取、软件预取、预测和基于预执行的预取策略等方面进行了全面的概括与研究。数据预取技术主要涉及五个基本问题,即预取什么数据、何时预取数据、从哪里预取数据、预取目标是什么以及如何启动预取。在错误的时间预取错误的数据或正确的数据不仅没有帮助,反而会损害整体性能[9]。
a)预取什么数据。预测即将要预取的数据是预取最重要的要求,根据预取数据的实现位置和各种技术预测预取数据进行分类,可分为:(a)硬件控制策略,预取在硬件中实现,各种方法支持硬件控制的预取,预取的所有组件都在处理器内实现,不需要任何用户干扰;(b)软件控制策略,开发人员或编译器能够控制将预取指令插入程序的操作,软件控制的预取可以使用编译器控制的预处理指令或在源代码中插入预取函数调用,或者基于二进制执行后分析插入的预取指令[10];(c)混合硬件/软件控制策略,该控制策略在具有多线程支持的处理器上的使用越来越常见,在这些处理器上需要硬件的支持来运行专门用于预取数据的帮助线程,需要软件支持来与实际计算线程同步[11~15]。
b)何时预取数据。发出预取指令的时间对预取的总体性能有很大影响。预取数据应在发生原始缓存缺失之前到达其目标。及时预取的效率取决于下一次缓存缺失发生的时间和预测未来访问的开销与预取数据的开销之和。如果总开销超过下一次高速缓存缺失的时间,则调整预取距离可以避免延迟预取。
c)从哪里预取数据。内存层次结构包含多个级别,包括缓存、主内存、辅助存储和第三级存储。数据预取可以在不同级别的存储器层次结构中实现。在多核处理器中,存储层次结构包含每个内核专用的本地缓存和多个内核共享的缓存。
d)预取目标是什么。预取目标越接近CPU,性能上的优势就越大。单独的预取缓存可以是处理器内核专用的,也可以由多个内核共享。预取数据的最佳目标是私有缓存,但由于私有缓存的容量小,缓存污染无可避免。所以在多核处理器中,预取目标各不相同,每个内核都可以将数据预取到其私有缓存或其专用预取缓存。
e)如何启动预取。预取指令可以由需要数据的处理器或提供这种服务的处理器发出。第一种方法称为客户端预取,处理器在执行程序时,根据程序执行的特点或者历史访问模式等进行主动预取。第二种称为服务器预取,是指处理器在访问内存时,根据内存地址的连续性和访问模式等,主动推送可能需要的数据到缓存中。
1.3 基于深度学习的缓存预取模型
基于深度学习的缓存预取是指在需要访问某个数据时,经过深度神经网络预测提前将数据从存储介质中预先加载到缓存中,以加快数据访问速度,对数据进行缓存预取也可以看做是一种语义关系抽取的过程[16]。具体地说,通过相关算法从数据中抽取出语义对之间的潜在关系,并将这些信息预先加载到缓存中,在需要分析数据时通过直接从缓存中获取已经抽取好的语义关系三元组〈e1,r,e2〉[17],就无须再次访问数据,从而大大提高了处理效率和速度。
对于语义关系r的抽取过程,可以看做是基于深度学习的缓存预取的输入向量表示,向量主要由上下文状态向量与地址向量两部分组成。对于上下文状态向量可以描述为Sen=[w1,w2,…,wn],其中wn表示第n个上下文状态。对于每个上下文状态wn,根据初始化结果可以得到其相应的上下文状态向量W=[v1,v2,…,vm],这样可以得到一个上下文状态向量矩阵,如式(1)所示。
Sen=v11v12…v1m
v21v22…v2m
vn1vn2…vnmn×m(1)
根据语义关系抽取的特点,可以根据上下文之间的距离来提取地址向量。其中wi与wj为两个上下文状态,则对于第k个上下文状态wk,其地址可以表示为
Pos=[Pos1,Pos2]=[|Poswk-Poswi|,|Poswk-Poswj|](2)
将n个上下文状态与式(2)融合地址特征,则得到如式(3)所示的特征向量。
Sen=v11v12…v1mpos111pos112…pos11kpos211pos212…pos21k
v21v22…v2mpos121pos122…pos12kpos221pos221…pos22k
vn1vn2…vnmpos1n1pos1n2…pos1nkpos2n1pos2n2…pos2nkn×(m+2k)(3)
其中:m为上下文状态向量特征的长度;k为上下文状态的地址向量的特征长度。通过以上方法可以得到相应的基于深度学习的缓存预取的输入向量。在确定深度神经网络输入特征向量的基础上,不同的基于深度学习的预取器设计采用不同的神经网络结构和不同的注意力机制,详见第2章。
1.4 缓存预取评测指标
在缓存预取中,常用的评估指标有覆盖率、准确率和及时性三个。覆盖率是指预取算法预测到的数据占总访问数据量的比例;准确率是指预取算法预测正确的數据占预测数据总量的比例;及时性是指预取算法预测并加载数据的速度。本文以三个评估指标为基准,对比分析多种基于深度学习的缓存数据预取算法,从而衡量不同预取器设计算法的优劣。
2 基于深度学习的多核缓存预取技术
基于深度学习的缓存预取策略是一种利用深度学习模型来预测未来的访问模式,并根据预测结果进行缓存优化和预取操作的方法,以此提高缓存命中率,降低延迟,提升存储系统的性能和效率。目前,根据神经网络的模型划分,基于深度学习的缓存预取策略主要包括以下几类。
2.1 考虑程序语义的神经网络缓存预取
由于传统的缓存预取方法主要基于数据的局部性原理,但基于神经网络的数据预取通常更加复杂,不仅取决于数据的物理地址,还受到神经网络的结构和语义特征的影响。通过神经网络的语义信息能够根据神经网络计算的结构和操作类型,预测内存访问模式,并将可能需要的数据提前加载到缓存中,以减少数据访问延迟和提高计算效率。
数据预取中,考虑程序中的上下文语义信息的主要目的在于发现内存访问之间存在的某种关系或模式,其逻辑假设是重复出现的语义关系很有可能会有相似的控制流和时空数据访问流。因此,通过跟踪主存访问之间的上下文信息可以用于区分语义局部性[13]。
语义局部性的概念最初由Peled等人[18]于2015年提出,是数据局部性的一种高级抽象,主要针对当前的非规则访存行为利用程序数据结构或遍历算法固有的语义特征来标识内存访问之间的关系,并提出一个基于强化学习的框架来学习程序的上下文语义信息用以指导数据预取。
然而,通过遍历上下文的属性和程序状态,无法区分属性和状态是否有用。为此,Peled等人[19]又将所提出的语义局部性概念应用于深度学习,提出了一个基于程序上下文的神经网络预取器,通过提高语义相关的准确性来识别多种内存访问模式,将机器和程序状态元素作为输入,输入到神经网络工作中来学习程序的算法属性,神经网络在运行时被训练,以此来预测基于相关上下文地址关联到未来内存访问模式。
在前期工作的基础上, Peled等人[20]于2019年使用全连接的前馈神经网络用于数据预取,将数据预取作为回归问题来训练神经网络,提出一种基于上下文语义信息的神经网络(NN)预取设计模型,将程序和机器上下文信息与内存访问模式通过不同关联策略[21~23]相关联,使用在线训练来识别代码所表现出的独特访问模式并进行动态调整,以此来动态适应不同的内存访问模式。
Peled等人所提出的预取神经网络模型展示了通过预测数据并将其预取到缓存中来提高系统性能具有较大的潜力,且该模型可以应用于任何内存访问模式,而不限于特定的应用程序或工作负载。然而,该模型在程序的数据结构发生变化时,其NN预取器需要重建网络权值来反映这个变化,而每个权值又表示多个并行的元素,这个改变过程会打破现有的预测并需要较长时间来恢复。同时,该神经网络模型是在假设能耗和芯片面积能够进一步优化的基础上开展,现有的实现能效耗费仍然很高,需要进一步的研究来探索其可扩展性及其对系统成本和复杂性的影响。
同时,基于语义局部性的概念,Ganfure等人[24]提出了一种新型的受深度神经网络启发的上下文感知预取方法Deep Prefetcher,将访问模式预测作为一个分类问题,通过使用分布式表示法捕获块访问模式的上下文信息,并利用深度学习模型进行上下文感知数据预取。Deep Prefetcher通过两个连续的读取请求之间的差异生成一个新的学习特征作为输入,通过模型将特征信息转换为一个新的富含上下文信息的嵌入式表示,通过深度学习算法捕捉训练数据中额外的语义信息,以此减少了训练数据中的变异程度,降低学习的复杂性,最后输出最有可能的逻辑块地址序列。然而该模型是根据逻辑块地址访问模式序列中得到的学习特征进行训练的,无法根据具体提出请求的应用程序获取数据,因此,未来将深入研究应用深度强化学习进行预取,考虑能够捕获高层次的应用环境以提高预取性能是改进的举措之一。
Bera等人[25]设计了一种通过进程和内存子系统交互来自主学习预取的框架Pythia,将数据预取表述为一个概率预测问题,并将其输出视为一个概率分布,通过强化学习(RL)[26]对多程序特征和系统级反馈信息进行预取。对于每一个新的请求,Pythia都会提取一组程序特征信息,使用该特征状态信息,根据其先验经验进行预取操作。对于每个预取操作,Pythia都会收到一个数字奖励,该奖励用于增强程序上下文信息和预取决策之间的相关性,以便生成高准确度、高及时性的系统感知的预取请求。同时该框架还能够将任何类型的系统级反馈信息纳入其决策中,然而该框架是基于硬件实现的预取框架,会导致芯片面积增加,功耗增加等问题,且该框架所使用的深度强化学习算法需要大量的计算资源和时间,对于多核缓存预取的应用来说存在一定的限制,因此可扩展性和实用性还需要进一步探索和改进。
2.2 基于循环神经网络的缓存预取
为了应对神经网络中复杂的数据访问模式,可以利用神经网络的语义信息来预测内存访问模式,从而实现更智能的缓存预取,因此基于循环神经网络(recurrent neural network,RNN)[27]的缓存预取方法被提出。循环神经网络具有输入信号、输出信号和权重,但内部有几个隐藏层,这些隐藏层不仅受到当前输入的影响,而且周期性连接以记住以前的输入信息。图4[28]是RNN的一个单元。为了计算出隐藏状态的当前时间t,使用前一个时间t-1的隐藏状态ht-1和输入xt计算出的ht值被发送到输出层,成为再次计算ht+1的输入值。
循环神经网络是用于学习时间序列数据的强大工具,其用于缓存预取主要是利用RNN直接学习和预测主存的访问模式,通过跟踪主存访问之间的上下文信息来发现内存访问之间存在的某种关系或模式,这些上下文信息可以包括神经网络的输入数据、中间计算结果以及控制流信息等,将缓存预取问题转换为一个序列预测问题。通過分析这些上下文信息,可以在训练阶段建立一个循环神经网络模型,使用该模型进行内存访问模式的预测,并将可能需要的数据提前加载到缓存中。
在预测阶段,循环神经网络模型可以根据当前的上下文信息预测下一个内存访问的位置和数据需求。然后,根据这些预测结果,提前将可能需要的数据加载到缓存中,以供后续的计算使用。通过这种方式,循环神经网络的缓存预取方法能够更好地适应神经网络的复杂性和多样化的数据访问模式,提高计算效率并降低数据访问延迟。这种方法对于处理复杂的神经网络任务和大规模数据集具有重要意义,可以提高计算效率并加速神经网络的训练和推断过程。
Zhang等人[29]提出一种基于RNN的偏移预取器(RAOP)框架,主要应用RNN来增强传统的偏移预取器,不仅在请求发生时产生预取,还能够预测地址用于数据预取。该框架由基于RNN的预测器和增强偏移预取模块两部分组成。通过利用RNN预测的接入作为时间参考,预测器在虚拟地址(VA)空间[30]中采用压缩LSTM结构进行建模,对于每个应用程序都训练一个预测器模型,在物理地址(PA)空间上进行预取,并将最近可能访问的缓存行预取到LLC中,针对LLC缓存实现了一个最佳偏移(best-offset,BO)预取器[31]。RAOP通过对当前地址和RNN预测地址执行偏移预取来提高预取性能。
由于RNN对于长序列处理问题存在梯度消失和爆炸问题,所以使用LSTM[32]作为预取预测器的主要结构,通过内存访问trace的偏移量来训练LSTM模型,并试图预测给定的前一个偏移序列的后续偏移量。将偏移预测问题看做是一个分类问题,通过将词汇表编码为二进制来压缩输出和输入维度,实现压缩模型的压缩。
RAOP通过使用循环神经网络自适应地学习并预测未来的数据访问模式,相比于传统的预取算法,能够更准确地预测未来数据的访问顺序,提高缓存的命中率;通过偏移信息考虑不同数据之间的相关性,以更好地利用缓存空间,并通过调整循环神经网络的参数来适应不同的数据访问模式,因此还具有较强的通用性和自适应性。
然而,RAOP框架一定程度上对训练模型的大小進行了压缩,仍然需要大量的计算资源和时间来训练RNN,增加了实现的难度和成本,即使RAOP对预取深度的数量增加通常会导致更高的覆盖率,但仅增加深度并不总是能提高整体系统性能[33]。另一方面,如果仅考虑RAOP框架预测能力,其预取的准确率很高,但是在预取的覆盖率、缓存命中率以及预取的有用性指标方面普遍较低,在预取性能提升方面与下一块预取性能提升不明显。此外,现有RAOP框架的预测基于单线程的数据访问模式,未考虑多核平台多个应用混合访存模式的复杂性。
Guan等人[34]针对长期大范围预测的需求,于2021年提出了一种将上下文无关语法(CFG)[35]和在线标记集成到RNN学习和推理中作为输入的预取方法,通过Sequitur分层压缩算法[36]将重复的子序列数据压缩为CFG,并根据压缩序列作为输入,调用RNN模型进行预测,通过对序列进行连续有效的压缩从而细化RNN模型。该研究是第一个已知的将序列压缩集成到RNN学习和推理中的方法,既扩大了预测范围,也减少了推理延迟,并通过设计高效回滚和考虑准确性的部分压缩技术来解决模型复杂性问题。然而循环神经网络和上下文无关语法都是相对复杂的概念和技术,将它们结合在一起可能导致更加复杂的模型和算法,增加了实现和理解的难度,特别是在处理长期依赖关系时可能使训练变得更加困难,需要更多的计算资源和更复杂的优化策略,同时也会增加模型的开销成本。
2.3 基于长短期记忆网络和注意力机制的缓存预取
在缓存预取中,深度神经网络和循环神经网络在捕捉长期上下文依赖关系中有所限制,尤其是对于长度可变的输入序列,如自然语言文本或时间序列数据,由于每个样本的长度不同,模型需要进行动态调整来适应不同的上下文大小,所以会导致缓存预取策略无法有效地利用缓存空间。为了应对神经网络中复杂的数据访问模式,可以利用神经网络的语义信息来预测内存访问模式,从而实现更智能的缓存预取。其中,长短期记忆(long short-term memory,LSTM)网络[37]和注意力机制[38](attention mechanism)是两个常用的技术手段。
长短期记忆是为了解决RNN的输入变长时,当前隐藏层失去先前输入信息的记忆这一缺点而提出的方法。为了解决这个问题,通过添加一个叫做单元状态的值来删除不必要的记忆,并选择要记住的内容。图5[28]是一个LSTM单元。LSTM由三个门来获取隐藏状态和单元状态值。第一个遗忘门(ft)是删除记忆的大门,第二个输入门(it,gt)是记住当前信息的大门,最后,输出门(ot)是计算当前时间点隐藏状态的门。单元状态ct可以通过将两个值相乘(it,gt)计算每个元素的输入门,并将输入门所选择的存储器添加到遗忘门的结果中,隐藏状态ht可以由单元状态ct和输出门(ot)相乘得到[28]。
然而LSTM的递归结构很难被并行化,而且推理延迟会随着输入时间步长而线性增加[39],因此注意力机制是一种允许模型自动选择相关信息的机制,它可以根据输入的特征权重动态地调整不同位置的注意力,可有效缓解该问题。在缓存预取中,注意力机制可以根据神经网络的结构和计算过程中的语义关系,自适应地选择需要预取的数据。
基于长短期记忆网络和注意力机制的缓存预取使用长短期记忆网络模型来建立访问序列的特征表示,并使用注意力机制来加强相关性分析,以提高预取精度和缓存效率。
Hashemi等人[1]首次将预取看做为一个分类问题,并使用LSTM建立了一个预取器,但这个基于LSTM的预取器无法对不规则数据进行预取,主要受限于模型空间大小,所以该预取器只能在空间区域内学习delta增量。此外,该模型训练是离线进行的,没有在实际的预取环境中实现,因此,其评价指标没有考虑预取的及时性和准确性,而仅仅是考虑到了预取的正确性。
基于机器学习的预取器设计无法投入实际应用,其根本原因在于模型的尺寸太大从而导致较高的存储开销和延迟。同时,模型的在线训练也是一个难题。针对这些问题, Srivastava等人[40]提出一种压缩LSTM的技术来改变预测模型的尺寸,同样将内存访问地址的预测问题看做是分类问题,将LSTM的输出层用二进制编码,将单一标签分类问题转换为多标签分类( log n)问题,从而实现与传统LSTM相比,其压缩因子能够达到O(nlog n)级别,并降低了预取的覆盖率。
为解决类爆炸问题,Zhan等人[41]提出一个神经分层序列预取模型(neural hierarchical sequence,NHS)。为使模型能够学习数百万个地址之间的地址相关性,该模型使用分层神经结构,将地址预测分解为页面预测[42]和偏移预测[43]两个子问题。尽管一个应用程序能够有数千万个唯一地址,但唯一页面的总数只有几万或几十万个,且唯一偏移量的数量固定为64。这种分解会导致页内偏移的折叠问题,即那些不同页面的地址但具有相同页内偏移的折叠在一起,不同访存地址将共享相同的偏移嵌入,这会限制神经网络的学习能力,从而导致较差的性能。为解决该问题,该方案使用了一个新的基于注意力的嵌入层,使页面预测为偏移预测提供上下文,这个上下文信息能够使共享嵌入层区分不同的数据访问地址,而无须知道每个数据地址的唯一表示。
然而由于NHS无法获得训练用的基本真实值标签,为解决标记问题,该研究组提出了一种基于概率分布框架的数据预取神经模型Voyager[44],在NHS的基础上构建一个多标签训练方案,达到探索新的定位形式的目的。该方案的核心是使模型能够从多个可能的标签中学习并选择出最可预测的标签,这样就不必预取全局地址流中的下一个地址,而不是仅仅提供单一的真实值标签[45]。同时该模型将数据预取表述为一个概率预测问题,并将其输出视为一个概率分布,机器学习的模型能够为概率分布建模提供灵活的研究框架[46~49]。
与现有技术相比,该神经网络模型的准确性和覆盖率都有所提高,且现有预取器的工作负载性能很差,该模型能够很好地弥补这一缺陷。然而,该神经网络模型的实用性却不高,随着神经网络技术的进步,该模型在计算成本上也还有改进的空间。
对于可以为每个触发器预取多个块的预取器而言,一次预取的预测块地址的顺序不算重要,对于Voyager产生的延迟问题就会被忽略,为此Zhang等人[50]提出使用细粒度地址分段[51],将地址进行分割来处理模型的输入,通过基于注意力的网络来学习输入分段地址和偏移之间的映射关系,在训练中人为地引入估计的延迟,然后进行距离预取,进一步抵消模型推断的延迟。但该研究并未说明引入估计的延迟数据来源,通过人为引入延迟数据并不具有普遍性,同时该模型并未考虑计算成本,因此该模型还具有改进的空间。
2.4 深度学习用于多核缓存预取的对比分析
深度学习在多核缓存预取策略上的成效主要体现在提高了高速缓存的命中率和降低了访问延迟,从而提升了深度学习应用的性能和效率。然而这些预取技术都有着一定的针对性,针对缓存的具体问题采用了各种可能的策略进行优化处理,现将几种基于深度学习的缓存预取策略进行对比分析,如表1和2所示。
根据表2能够看出,未来深度学习用于缓存预取方面还具有许多可探讨性的空间,通过深度学习方法能够预测未来访问,从而提高缓存命中率和性能,且由于深度学习能够自动学习访问序列中的复杂特征和相关性,无须人为设定规则或参数,可以适应不同类型和场景下的访问模式,具有较强的泛化能力和鲁棒性。同时,深度学习可以动态调整缓存大小和预取粒度,以适应变化的工作负载。
然而,深度学习在缓存预取上也存在一些局限性,由于深度学习的模型需要大量的训练数据和计算资源,就可能会导致训练时间过长或者内存不足等问题;且深度学习需要根据不同的应用场景调整模型参数和结构,可能存在过拟合或者欠拟合等风险。同时,深度学习的模型还存在模型过时或者不适应新环境等挑战,因此需要考虑模型更新和迁移等问题。
3 基于深度学习的多核缓存预取技术分析与展望
通过上述经典工作的分析和比较,可以看出深度学习已经在缓存预取技术上的研究取得了一定成果,但依然存在着一定的问题,具体来说有以下几点:
a)计算成本。基于深度学习的缓存预取技术训练模型仍然比较耗时,其训练时间与训练集和计算环境规模紧密相关。因此在进一步降低计算成本方面仍有研究意义。
b)优化模型。现有模型预测的准确率和覆盖率虽然有所改进,但其优化空间还很大。通过优化模型能够进一步提升预测的准确率以及缓存的命中率。
c)实用性。现有的基于神经网络的预取模型的研究虽然在覆盖率和准确率上有所提高,但其预测能力会受限于训练模型的样本量,所以其实用性并不高。
基于深度学习的多核缓存预取研究具有很大的发展前景,未来在基于深度学习的缓存预取技术的研究有以下方向值得探索和实践。
a)在线自适应预取模型。由于运行程序的多样性,大量应用的访存行为不一致,单一的预取策略并不能同时很好地满足各种应用的需求。较为复杂的策略虽然能保证精度,但会引入较高的额外开销。而简单的预取策略在不规律访问情况下的精度过低,导致效率不足。因此,需要研究自适应的预取策略,根据当前运行的程序状态,动态选择合适的预取策略,从而进一步提高程序性能。对于实时、高效的在线自适应预取模型,第一,必须降低预测模型的时间和空间复杂度。虽然Voyager模型具有较高的预测准确率,降低了模型大小,但很难实现在线自适应。第二,提高对预取时机的预测准确率,而这方面的研究很少。
b)基于启发的实用神经网络预取模型。利用从Voyager和后续深度学习研究中获得的启发来构建一种基于神经网络的实用预取模型。例如:对于缓存替换,感知器可以代替LSTM以提高技术水平;对于数据预取方面的任务也更具有挑战性,同时潜在的性能也很大,通过地址预取提供改进增量预取的文本,或通过数据地址历史记录为硬件预取策略的功能选择提供信息。
c)时空数据预取的深度交互。时间局部性和空间局部性的简单混合不利于数据预取的设计,需要研究时空预取两个维度的深度交互来设计数据预取策略。根据地址相关性,长的历史数据访问地址空间对于预测不规则访问是一个很好的特征选择,同时,在神经网络设计中,多个定位器设计方法能够为一些难以预测的数据提供解决方案,因此,未来针对非则数据预取方面,考虑时空局部性的深度交互原理对于促进神经网络预取模型的实用性方面具有重要意义。
4 结束语
随着多核技术的迅速发展,数据的并发处理和大数据操作已成为主流,为了处理更加复杂的程序行为和规模愈发庞大的数据量,缓存系统的效率也正面临着严峻的挑战。如何在复杂的多核环境中基于深度学习来更高效地使用预取技术,从而提高系统响应速度和数据命中率,目前还处于刚刚起步阶段,也无法满足当前多核環境提高缓存效率的需要。可以预见,随着技术的不断进步,深度学习和预取技术的创新与发展能够更加保证处理器的高性能工作,同时也为多核技术的进一步成熟发展提供强有力支持。
当前深度学习应用于多核架构的数据预取研究已经成为国内外的研究热点。本文通过梳理当前常见的多核缓存架构和预取技术,对基于深度学习的预取的主流技术进行了分类分析,比较了不同神经网络预取技术之间的优劣,以期对未来基于深度学习的多核缓存预取技术研究提供借鉴参考。
参考文献:
[1]Hashemi M,Swersky K,Smith J,et al.Learning memory access patterns[C]//Proc of International Conference on Machine Learning.2018:1919-1928.
[2]胡新辰.基于LSTM的语义关系分类研究[D].哈尔滨:哈尔滨工业大学,2015.(Hu Xinchen.Research on semantic relation classification based on LSTM[D].Harbin:Harbin Institute of Technology,2015.)
[3]叶红伟.片上网络多级缓存技术研究及系统互联方案实现[D].西安:西安电子科技大学,2017.(Ye Hongwei.Research on multi-level caching technology for on-chip networks and implementation of system interconnection scheme[D].Xian:Xian University of Electronic Science and Technology,2017.)
[4]袁驰坤.面向缓存一致性优化的高性能片上网络[D].成都:电子科技大学,2019.(Yuan Chikun.High-performance on-chip network for cache coherency optimization[D].Chengdu:University of Electronic Science and Technology of China,2019.)
[5]闵庆豪,张为华.多核缓存优化技术研究综述[J].计算机系统应用,2015,24(1):1-8.(Min Qinghao,Zhang Weihua.A review of research on multicore cache optimization techniques[J].Computer System Applications,2015,24(1):1-8.)
[6]刘鹏.三维多核处理器片上缓存功耗管理机制研究[D].南京:南京航空航天大学,2020.(Liu Peng.Research on power management mechanism of on-chip cache for three-dimensional multicore processors[D].Nanjing:Nanjing University of Aeronautics and Astronautics,2020.)
[7]Manegold S,Boncz P A,Kersten M L.Optimizing database architecture for the new bottleneck:memory access[J].The VLDB Journal,2000,9:231-246.
[8]Byna S,Chen Yong,Sun Xianhe.A taxonomy of data prefetching mechanisms[C]//Proc of International Symposium on Parallel Architectures,Algorithms,and Networks.Piscataway,NJ:IEEE Press,2008:19-24.
[9]He Jun,Sun Xianhe,Thakur R.Knowac:I/O prefetch via accumulated knowledge[C]//Proc of IEEE International Conference on Cluster Computing.Piscataway,NJ:IEEE Press,2012:429-437.
[10]Kougkas A,Devarajan H,Sun Xianhe.I/O acceleration via multi-tiered data buffering and prefetching[J].Journal of Computer Science and Technology,2020,35:92-120.
[11]张建勋,古志民.基于交织预取率的帮助线程预取质量调节算法[J].计算机应用研究,2019,36(2):430-434.(Zhang Jianxun,Gu Zhimin.A helper thread prefetch quality adjustment algorithm based on interleaved prefetch rate[J].Application Research of Compu-ters,2019,36(2):430-434.)
[12]张建勋,古志民.帮助线程预取质量的实时在线评价方法[J].计算机应用,2017,37(1):114-119,127.(Zhang Jianxun,Gu Zhimin.A real-time online evaluation method to help thread prefetching quality[J].Computer Applications,2017,37(1):114-119,127.)
[13]Zhang Jianxun,Gu Zhimin,Huang Yan,et al.Helper thread prefetching control framework for chip multi-processor[J].International Journal of Parallel Programming,2015,43:180-202.
[14]張建勋,古志民,胡潇涵,等.面向非规则大数据分析应用的多核帮助线程预取方法[J].通信学报,2014,35(8):137-146.(Zhang Jianxun,Gu Zhimin,Hu Xiaohan,et al.A multi-core helper thread prefetching approach for non-regular big data analysis applications[J].Journal on Communication,2014,35(8):137-146.)
[15]张建勋,古志民.帮助线程预取技术研究综述[J].计算机科学,2013,40(7):19-23,39.(Zhang Jianxun,Gu Zhimin.A review of research on helper thread prefetching techniques[J].Computer Science,2013,40(7):19-23,39.)
[16]陈剑南,杜军平,薛哲,等.基于多重注意力的金融事件大数据精准画像[J].计算机科学与探索,2021,15(7):1237-1244.(Chen Jiannan,Du Junping,Xue Zhe,et al.Accurate portrait of big data of financial events based on multiple attention mechanism[J].Journal of Frontiers of Computer Science and Technology,2021,15(7):1237-1244.)
[17]Zheng Suncong,Wang Feng,Bao Hongyun,et al.Joint extraction of entities and relations based on a novel tagging scheme[C]//Proc of the 55th Annual Meeting of the Association for Computational Linguistics.2017:1227-1236.
[18]Peled L,Mannor S,Weiser U,et al.Semantic locality and context-based prefetching using reinforcement learning[C]//Proc of the 42nd Annual International Symposium on Computer Architecture.2015:285-297.
[19]Peled L,Weiser U,Etsion Y.A neural network memory prefetcher using semantic locality[EB/OL].(2018).https://arxiv.org/abs/1804.00478.
[20]Peled L,Weiser U,Etsion Y.A neural network prefetcher for arbitrary memory access patterns[J].ACM Trans on Architecture and Code Optimization(TACO),2019,16(4):1-27.
[21]Khan T A,Sriraman A,Devietti J,et al.I-spy:context-driven conditional instruction prefetching with coalescing[C]//Proc of the 53rd Annual IEEE/ACM International Symposium on Microarchitecture.2020:146-159.
[22]Schneider S O,Schlather M.A new approach to treatment assignment for one and multiple treatment groups[R/OL].(2017).http://deas.repec.org/p/got/gotcrc/228.html.
[23]黨思航.目标识别中的增量学习方法研究[D].成都:电子科技大学,2021.(Dang Sihang.Research on incremental learning methods in target recognition[D].Chengdu:University of Electronic Science and Technology of China,2021.)
[24]Ganfure G O,Wu Chunfeng,Chang Yuanhao,et al.Deep Prefetcher:a deep learning framework for data prefetching in flash storage devices[J].IEEE Trans on Computer-Aided Design of Integrated Circuits and Systems,2020,39(11):3311-3322.
[25]Bera R,Kanellopoulos K,Nori A,et al.Pythia:a customizable hardware prefetching framework using online reinforcement learning[C]//Proc of the 54th Annual IEEE/ACM International Symposium on Microarchitecture.2021:1121-1137.
[26]刘全,翟建伟,章宗长,等.深度强化学习综述[J].计算机学报,2018,41(1):1-27.(Liu Quan,Zhai Jianwei,Zhang Zongchang,et al.A review of deep reinforcement learning[J].Journal of Compu-ter Science,2018,41(1):1-27.)
[27]Fang Wei,Chen Yupeng,Xue Qiongying.Survey on research of RNN-based spatio-temporal sequence prediction algorithms[J].Journal on Big Data,2021,3(3):97-110.
[28]Choi H,Park S.A survey of machine learning-based system performance optimization techniques[J].Applied Sciences,2021,11(7):3235.
[29]Zhang Pengmiao,Srivastava A,Brooks B,et al.RAOP:recurrent neural network augmented offset prefetcher[C]//Proc of International Symposium on Memory Systems.2020:352-362.
[30]Yu Xiangyao,Hughes C J,Satish N,et al.IMP:indirect memory prefetcher[C]//Proc of the 48th International Symposium on Microarchitecture.2015:178-190.
[31]Michaud P.Best-offset hardware prefetching[C]//Proc of IEEE International Symposium on High Performance Computer Architecture.Piscataway,NJ:IEEE Press,2016:469-480.
[32]Chung J,Gulcehre C,Cho K H,et al.Empirical evaluation of gated recurrent neural networks on sequence modeling[C]//Proc of NIPS Workshop on Deep Learning.2014.
[33]Kim J,Pugsley S H,Gratz P V,et al.Path confidence based lookahead prefetching[C]//Proc of the 49th Annual IEEE/ACM International Symposium on Microarchitecture.2016:1-12.
[34]Guan Hui,Chaudhary U,Xu Yuanchao,et al.Recurrent neural networks meet context-free grammar:two birds with one stone[C]//Proc of IEEE International Conference on Data Mining.2021:1078-1083.
[35]Zhao Guorong,Wang Wenjian.Method for Chinese parsing based on fusion of multiple structural information[J].Journal of Frontiers of Computer Science and Technology,2017,11(7):1114-1121.
[36]Nevill-Manning C G,Witten I H.Identifying hierarchical structure in sequences:a linear-time algorithm[J].Journal of Artificial Intelligence Research,1997,7:67-82.
[37]Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[38]Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[C]//Advances in Neural Information Processing Systems.2017.
[39]Hwang K,Sung W.Single stream parallelization of generalized LSTM-like RNNs on a GPU[C]//Proc of IEEE International Conference on Acoustics,Speech and Signal Processing.2015:1047-1051.
[40]Srivastava A,Lazaris A,Brooks B,et al.Predicting memory accesses:the road to compact ML-driven prefetcher[C]//Proc of International Symposium on Memory Systems.2019:461-470.
[41]Zhan Shi,Jain A,Swersky K,et al.A neural hierarchical sequence model for irregular data prefetching[C]//Proc of ML for Systems Workshop,NeurIPS.2019.
[42]张友志,胡国胜,程玉胜.一种改进的Markov预测模型方法[J].计算机技术与发展,2008,18(12):78-80,83.(Zhang Youzhi,Hu Guosheng,Cheng Yusheng.An improved Markov prediction model approach[J].Computer Technology and Development,2008,18(12):78-80,83.)
[43]陈爱斌,蔡自兴,文志强,等.一种基于预测模型的均值偏移加速算法[J].信息与控制,2010,39(2):234-237.(Chen Aibin,Cai Zixing,Wen Zhiqiang,et al.A mean-shift acceleration algorithm based on prediction model[J].Information and Control,2010,39(2):234-237.)
[44]Zhan Shi,Jain A,Swersky K,et al.A hierarchical neural model of data prefetching[C]//Proc of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems.2021:861-873.
[45]Tsoumakas G,Katakis I.Multi-label classification:an overview[J].International Journal of Data Warehousing and Mining,2007,3(3):1-13.
[46]Bakhshalipour M,Lotfi-Kamran P,Sarbazi-Azad H.Domino temporal data prefetcher[C]//Proc of IEEE International Symposium on High Performance Computer Architecture.2018:131-142.
[47]Wu Hao,Nathella K,Pusdesris J,et al.Temporal prefetching without the off-chip metadata[C]//Proc of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture.2019:996-1008.
[48]Wu Hao,Nathella K,Sunwoo D,et al.Efficient metadata management for irregular data prefetching[C]//Proc of the 46th International Symposium on Computer Architecture.2019:449-461.
[49]Jacobs R A,Jordan M I,Nowlan S J,et al.Adaptive mixtures of local experts[J].Neural Computation,1991,3(1):79-87.
[50]Zhang Pengmiao,Srivastava A,Nori A V,et al.Fine-grained address segmentation for attention-based variable-degree prefetching[C]//Proc of the 19th ACM International Conference on Computing Frontiers.2022:103-112.
[51]石星.基于深度學习的块级缓存预取优化研究[D].武汉:华中科技大学,2019.(Shi Xing.Research on block-level cache prefetching optimization based on deep learning[D].Wuhan:Huazhong University of Science and Technology,2019.)
[52]Qin Zhen,Sun Weixuan,Deng Hui,et al.Cosformer:rethinking softmax in attention[C]//Proc of International Conference on Learning Representations.2022.
[53]蔡曲林,刘普寅.一种新的概率神经网络有监督学习算法[J].模糊系统与数学,2006(6):83-87.(Cai Qulin,Liu Puyin.A new supervised learning algorithm for probabilistic neural networks[J].Fuzzy Systems and Mathematics,2006(6):83-87.)
[54]Chen Youliang,Zhang Xiangjun,Karimian H,et al.A novel framework for prediction of dam deformation based on extreme learning machine and Lévy flight bat algorithm[J].Journal of Hydroinformatics,2021,23(5):935-949.
[55]Nam J,Kim J,Loza M E,et al.Large-scale multi-label text classification—revisiting neural network[C]//Proc of Joint European Confe-rence on Machine Learning and Knowledge Discovery in Databases.2014:437-452.
猜你喜欢
电子制作(2019年19期)2019-11-23
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
知音励志·社科版(2016年9期)2016-11-09
软件导刊(2016年9期)2016-11-07
艺术与设计·理论(2016年10期)2016-11-04
软件工程(2016年8期)2016-10-25
科技视界(2016年21期)2016-10-17
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
