
利用提示调优融合多种信息的低资源事件抽取方法
2024-03-05 07:11苏杭胡亚豪潘志松
计算机应用研究 2024年2期
苏杭 胡亚豪 潘志松

收稿日期:2023-06-29;修回日期:2023-08-22 基金项目:国家自然科学基金资助项目
作者简介:苏杭(1992—),男,山东菏泽人,硕士研究生,主要研究方向为自然语言处理;胡亚豪(1995—),男,江苏苏州人,博士研究生,主要研究方向为自然语言处理;潘志松(1973—),男(通信作者),江苏南京人,教授,博导,博士,主要研究方向为模式识别(panzhisong@aeu.edu.cn).
摘 要:针对现有流水线式事件抽取方法依靠大量训练数据、在低资源情况下难以快速迁移运用等问题,利用提示调优技术,提出适用于低资源场景下的流水线式事件抽取方法(low-resource event extraction method using the multi-information fusion with prompt tuning,IFPT)。该方法通过构造语义映射和提示模板充分利用事件类型描述、实体类型等多种信息,能够高效使用有限训练数据,流水线式地完成事件检测和论元抽取。实验结果表明,在低资源情况下,IFPT方法论元抽取性能超过了所有基准模型,采取流水线方式能够达到与SOTA模型相媲美的性能。
关键词:事件抽取;低资源;提示调优;预训练语言模型;论元抽取
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)02-009-0381-07
doi:10.19734/j.issn.1001-3695.2023.06.0274
Low-resource event extraction method using multi-information
fusion with prompt tuning
Su Hang,Hu Yahao,Pan Zhisong
(College of Command & Control Engineering,Army Engineering University of PLA,Nanjing 210007,China)
Abstract:Existing pipeline-based methods rely on a large amount of training data while not being able to use external information effectively,making it difficult to transfer and apply quickly in low-resource situations.This paper used prompt-tuning to fuse multiple information and proposed a low-resource event extraction method using the multi-information fusion with prompt tuning(IFPT).By constructing semantic verbalizers and prompt templates,this method was able to complete event detection and argument extraction with pipeline-based paradigm,making full use of various information such as event type description and entity type.Experimental results show that IFPT outperforms all baseline models in argument extraction and achieves comparable performance to the SOTA model in event extraction with pipeline-based paradigm.
Key words:event extraction(EE);low-resource;prompt tuning;pretrained language model;argument extraction
0 引言
事件抽取(EE)是信息提取領域中重要且具有挑战性的课题。ACE 国际评测会议将事件定义为“发生在某个特定时间点或时间段、某个特定地域范围内,由一个或者多个角色参与的一个或多个动作组成的事情或者状态的改变”[1]。事件抽取任务旨在将非结构化文本中的某类事件信息如时间、地点、参与者等转换为结构化形式,辅助人们整编运用各类信息,便于检索事件信息并分析人们的行为,在信息检索、智能推荐、智能问答、知识图谱构建等领域广泛应用。事件抽取工作包括识别事件触发词、事件类型、事件论元、论元角色等[2]。事件抽取主要包括事件检测(event detection)和论元抽取(argument extraction)两个任务[3]。其中,事件检测是识别出句子中包含的触发词并对其所属的事件类型进行分类,具体可细分为触发词识别(trigger identification)和触发词分类(trigger classification);论元抽取是识别特定事件类型下的论元并确定其角色,该任务是一个基于单词对的多分类任务,用于确定句子中触发词和实体之间的角色关系,具体可细分为论元识别(argument identification)和论元角色分类(argument role classification)。根据不同子任务的处理流程,事件抽取可分为基于流水线(pipeline-based)和基于联合的方式(joint-based)。基于流水线的方式将复杂的事件结构分解为多个独立的子任务,分别训练不同模型,比较常见的是首先进行事件检测而后进行事件论元抽取;联合方法构建了触发词识别和论元识别的联合学习模型,触发词和论元可以相互促进以提升模型表现。虽然一些实验结果表明联合的模型效果要好于流水线的模型,但Zhong等人[4]在研究实体关系抽取任务中发现,基于联合的方法需要独立学习每种类型,在不同的事件类型之间不能共享信息,不利于标记数据较少情况下的事件抽取,联合抽取的方式并不一定比流水线的方式表现好;此外,同一个句子中可能包含多类事件,并且事件论元存在重叠现象,联合抽取的方式在低资源情况下较难发现触发词与论元之间的潜在关系。流水线的方式虽然存在传播误差,但是结构简单,便于建模和迁移应用,通过合理设计模型结构可以减少传播误差影响[5],取得比流水线模型更好的表现。
目前,基于深度学习的事件抽取逐渐成为研究主流,已是比较成熟的研究分类。但深度学习模型需要大量有标注数据进行模型训练,获取高质量标注样本成本较高,因此如何高效利用少量带注释的训练数据得到较为理想的事件抽取模型仍然是一个挑战。随着技术的不断发展,GPT[6]、T5[7]等大规模预训练语言模型逐渐应用到小样本(few-shot)或者低资源(low-resource)場景下,但其模型参数量巨大,在硬件资源和标注数据相对有限的领域,通过微调(fine tuning)方式难以快速迁移应用。提示学习(prompt learning)在不显著改变预训练语言模型结构和参数的情况下,通过向输入中增加提示信息,充分利用模型的预训练成果能够在低资源场景下取得较好表现,该特性越来越受到研究人员重视[8]。近年来,研究者提出通过外部知识图谱扩展标签映射的方法KPT[9],在关系抽取、文本分类等任务场景中取得较大的性能提升,并在小样本情况下取得较好表现。文献[10]通过构造提示模板利用事件类型信息辅助进行论元分类,提高了数据利用率,在低资源情况下较以往模型性能得到提升。以上研究结果表明,通过合理构造提示能够有效利用外部信息,提升预训练模型对领域、任务的感知,进一步提升预训练语言模型在小样本和零样本情况下的性能表现。本文借鉴文献[10,11]的思想,提出了一种利用提示调优融合多种信息的低资源事件抽取方法,通过人工构造语义映射和提示模板融合运用多种外部知识,以流水线方式完成事件检测和论元抽取任务,在低资源情况下取得了较好表现。本文的主要贡献有:a)利用提示调优技术,提出语义映射(semantical verbalizer)和提示模板(prompt template)的构造方法,能够利用实体、论元角色描述等多种外部信息;b)基于该方法提出了两阶段事件抽取模型IFPT,首先利用事件类型描述信息、事件关键词等信息构造语义映射完成事件检测,而后利用实体信息构造提示模板、利用论元角色信息构造语义映射完成论元抽取。在ACE 2005数据集上进行了大量实验,该模型在低资源情况下能够取得较好表现。
1 相关工作
1.1 事件抽取
随着深度学习技术的不断发展运用,循环神经网络(RNN)[12]、图神经网络(GNN)[13]、预训练语言模型(PLM)[14]等不断推广应用到事件抽取领域中,通过在大量人工标注样本上进行训练,模型能够学习到原始数据更加深层的特征,端对端地完成事件抽取任务,避免了复杂的特征工程和传播误差,简化了任务流程[15]。近年来,研究人员提出了基于注意力机制的Transformer架构[16],该架构能够使模型关注到更加重要、更加深层的信息,一定程度上缓解了长依赖问题。利用该架构,研究者提出了BERT[14]、GPT、BART[17]等预训练语言模型。通过在大量语料上进行预训练,预训练语言模型中蕴涵着更加丰富的上下文知识,使用训练数据进行微调就能迁移应用到下游不同NLP任务中。Lin等人[18]提出端到端的信息抽取框架OneIE,该模型利用BERT模型,在解码阶段加入全局特征捕捉实体之间和子任务之间的联系,该框架没有使用任何特定语言的语法特征,所以很容易运用到新的语言环境中。葛君伟等人[19]提出基于上下文融合的文档级事件抽取方法,融合利用段落序列特征、上下文交互信息来解决文档中中文事件元素分散问题。Li等人[20]提出了一种基于生成模型BART的 BART-Gen,该模型使用流水线的方式,能够进行文档级事件论元提取。大部分基于深度学习的方法均依赖大量的有标注的高质量训练样本,比如广泛使用的事件抽取数据集ACE 2005语料库,它需要语言学专家进行两轮注释,高昂的标注成本使得这些模型难以快速扩展到新的领域和新的事件类型,在训练数据相对有限的低资源情况下难以推广运用。因此,如何提升模型在训练数据较少情况下的性能逐渐成为研究热点[8]。Li等人[21]针对以往全监督的方法泛化性能较弱、无法利用标签中丰富的语义信息等问题,将事件抽取转换为一系列问答(QA)问题,从而引入历史信息来捕获不同论元角色之间的依赖关系,提高了模型在少样本上的泛化能力。Liu等人[22]将事件抽取定义为机器阅读理解问题,提出了一种无监督的问题生成方法以提升训练数据的利用率,可用于零样本学习的场景。Yang等人[23]提出了两阶段事件抽取模型PLMEE,针对事件抽取任务中训练数据不足的问题,提出了通过编辑原型(prototypes)来自动生成标注数据进行模型性能优化的方法。
1.2 提示调优
提示调优的核心是将给定的下游任务转换成与预训练语言的训练任务一致的形式,能够适应很少或没有标记数据的新场景[20]。提示主要有填空式提示(cloze prompt)[24]和前缀式提示(prefix prompt)[25]两种运用方式。填空式提示首先将提示模板(template)中需要预测的内容使用“[MASK]”替代,将下游分类任务转变为与预训练阶段一致的填空任务,而后利用标签映射器(verbalizer)将生成的内容转换成相应的类别标签;前缀式提示构造连续的语句拼接在输入前,引导模型从左到右地完成自回归任务。提示从其形态上可进一步划分为离散提示和连续提示,其中离散提示也称为“硬提示”,主要使用人类可以理解的自然语言的词语组成;连续提示是把原本离散词转变为连续表示,运用到模型的嵌入空间中,使得提示参数能够独立于预训练语言模型的参数,也称为“软提示”。在事件抽取领域,使用提示可以将实体信息、逻辑关系等先验知识注入到模型中,使模型能够在训练样本较少的情况下也能取得比较好的性能。Hu等人[9]利用外部知识库来扩展分类任务的标签词映射(verbalizer),形成具有知识的映射(knowledgable verbalizer),在小样本场景下取得了较好表现。Hsu等人[26]提出DEGREE模型,该模型利用生成式架构,通过构造提示模板融入外部知识完成事件抽取任务,通过设计恰当的提示,引导模型捕获实体之间的关系,能够更加全面地利用先验知识,减少模型训练所需要的样本数量,实现低资源情况下的信息抽取。但DEGREE方法在推理阶段需要枚举所有的事件类型,从大量生成结果中遴选匹配的结果,复杂度较高。Ma等人[10]扩展了基于QA的模型来处理事件论元抽取任务,该方法针对特定事件类型,构造包含相应论元角色的提示模板,通过编解码器捕获事件论元之间的隐含关系,利用解码阶段的输出构造选择器,抽取最有可能是论元的文本片段,虽然提升了性能表现,但该方法仅能针对特定事件类型抽取事件元素,无法实现事件类型和触发词抽取。陈诺等人[27]提出一种基于模板提示学习的事件抽取方法,通过自动构造模板引出预训练语言模型知识,完成中文句子级事件联合抽取模型,但该方法依赖大量的训练数据。由于所有的事件论元均是句子中的实体提及,Dai等人[11]认为可利用句子中已有的实体信息辅助进行论元分类,提出一种用于事件元素抽取的双向迭代的提示调优方法BIP,该方法将EAE任务转换成完形填空任务,将外部的实体信息融入到提示模板中,利用论元角色标签的语义知识构造标签词映射,该模型融合运用了实体信息、分类标签语义信息、论元之间的相互关系信息,提高了数据利用率,在低资源情况下较以往模型性能得到提升,但该模型仅能完成EAE任务,依赖于事件类型和事件触发词。
本文提出IFPT方法,通过构造语义映射和提示模板融合实体、论元角色描述等多种外部信息,在低资源情况下分阶段完成事件抽取任务。与文献[11]不同,本文借鉴文献[10],使用编解码器模型,能够完成事件检测和论元抽取两种任务,且利用了事件类型描述信息;与文献[23]等不同,本文仅利用已有数据,无须额外生成数據;相较于文献[26],本文能够利用更加丰富的外部信息,能够在使用较小预训练语言模型的情况下取得更好表现。
2 IFPT方法
本文IFPT方法使用统一的模型架构建模事件检测和论元抽取两阶段任务:a)将事件触发词抽取转换成词分类任务,通过构造事件类别的语义映射判断输入中每个词是否为某事件的触发词,完成触发词识别和事件类别判定;b)基于模型的生成能力,利用实体信息构造提示模板,构造论元角色的语义映射来判断论元角色。
2.1 总体架构
2.1.1 语义映射(semantical verbalizer)
借鉴BIP模型[11]中虚拟词(virtual word)的构建方法,将每个事件类型、论元角色类别分别用一个虚拟词表示,使用已有的外部信息对其进行描述。本文借鉴文献[26],将触发词词性、同义词(本文使用三个)、事件类型描述信息进行拼接并尽可能地组成符合逻辑的词组来对该虚拟词进行描述。由于触发词大部分为动词,触发词词性部分使用“verb”,虚拟词构造样例如表1所示。而后利用描述信息对其表示进行初始化,其表示将随模型训练不断调优。最后使用虚拟词表示构造语义映射向量,将解码器的隐层输出映射为所属事件类别或论元角色。
比如,对于数据集中事件类型“transport”,首先构造虚拟词〈transport〉;而后使用“verb,travel,go,move from one place to another”描述〈transport〉;最后使用BART的嵌入层获得提示中每个词的表示,并使用所有词表示的均值初始化虚拟词表示。对于非事件触发词使用虚拟词〈none〉,表示该词不是任何事件的触发词,并使用“not event trigger”对其进行描述。虚拟词描述的组成结构如图1所示。
2.1.2 提示模板(prompt template)
设计提示模板主要用于融合实体信息、实体类型信息等外部知识,将分类任务转换成完形填空任务,利用模型的生成能力完成下游的论元角色分类任务。考虑到预训练模型以人类正常的自然语言为预训练语料,所以使用尽量符合正常语序的自然语言来构造提示模板。效仿文献[11],需要模型预测的论元角色部分使用“[MASK]”进行填充。本文中事件类型描述均来自于文献[26]。例如针对“In trucks and on foot they came to the town of Safwan.”,构造如图2所示提示模板:“movement which occurs when a weapon or vehicle is moved from one place to another.The vehicle trucks is[MASK],The geogra-phical or political entity Safwan is[MASK] .”。图2中斜体部分是事件类型描述,标注黑框部分为句子中的实体,标注下画线的部分是实体对应的实体类型,不同的“实体类型+实体”使用逗号分隔。为使模型充分学习句子中的语义,本文利用BART模型的抗扰特性[21],通过打乱“实体类型+实体”组的前后顺序来构造多个提示(当“实体类型+实体”组的个数大于3个时,随机打乱3次),如图2中的提示可变为“movement which occurs when a weapon or vehicle is moved from one place to ano-ther.The geographical or political entity Safwan is[MASK],The vehicle trucks is[MASK] .”。通过这种随机打乱的方法提高标注数据的利用率,使模型能够学习到更加丰富的上下文语义,提升模型在低资源情况下的表现。
2.1.3 编解码(encoder-decoder)
本文选择BART模型[17]作为编解码器。BART模型是一种基于注意力机制的编解码模型,编码阶段能够融合输入的上下文信息,解码阶段能够利用编码器的输出和解码器的输入生成相应格式的句子,在多个自然语言理解和生成任务中表现出色,并且具有一定的抗扰能力。这些特性适用于本文提出的统一模型架构。
2.2 事件检测
事件检测阶段的模型架构如图3所示。在模型训练过程中,虚拟词能够学习到同一类事件下不同触发词的上下文表示,最终通过相似性函数将解码器输出映射为相应的事件类型。
第n个事件类别对应的虚拟词vt(n)的描述经过分词形成序列{q(n)1,q(n)2,…,q(n)k},其中vt(0)是〈none〉。虚拟词初始化过程如式(1)所示,其中E是BART中embedding层中的的权重向量。
E(vt(n)) = 1k∑kj=1E(q(n)j)(1)
所有N个事件类型虚拟词的初始化表示HVT=[E(vt(0)),E(vt(1)),…,E(vt(N))]将随着模型微调不断优化,最终得到调优后的虚拟词表示VT。使用多层感知机得到事件类型的映射矩阵QVT,其中多层感知机使用ReLU作为激活函数,如式(2)所示。
QVT =MLPEE(VT)(2)
在编解码器部分,BART预训练语言模型包括encoder和decoder两个部分L=[Lenc,Ldec],模型输入的样本集合为D,输入文本序列X={x1,x2,…,xi}∈D。原始输入序列经过编解码器的自注意力机制计算,可得到其最后的隐层表示HX=[Hx1,Hx2,…,Hxi],计算过程如式(3)(4)所示。
H(enc)X=Lenc(X)(3)
HX=Ldec(X;H(enc)X)(4)
使用余弦相似度函数cosSim计算得到相似性分数向量SVTi,如式(5)所示,其中i表示输入中第i个词。
SVTi=cosSim(Hxi,QVT)(5)
通过softmax函数将相似性得分转变为第i个词作为不同事件类别触发词的概率分布向量pEEi,如式(6)所示。
pEEi=softmax(SVTi)(6)
模型推理阶段,利用模型输出的概率分布向量即可判定输入词xi为事件类别n的触发词,如式(7)所示。
n=argmax(pEEi)(7)
2.3 论元抽取
论元抽取阶段主要是根据已知的事件类型对句子中每个词所属的事件论元角色进行分类。由于在不同事件类型中可能包含相同的论元角色,如在ACE 2005数据集中,事件类型“extradite”和“transport”均有论元角色“destination”。为充分利用训练样本,避免上述问题带来的影响,本文对不同事件类型下的相同论元角色进行统一建模,再根据相应的事件类型进行匹配。该阶段模型架构如图4所示。
首先构造论元角色虚拟词,使用论元描述信息对虚拟词进行描述。采用与事件检测阶段相同的初始化方式得到虚拟词初始化表示HVA=[E(va(0)),E(va(1)),…,E(va(L))],其中L是论元角色类型的个数,va(0)为非论元角色虚拟词〈none〉。模型微调后的虚拟词表示VA,通过多层感知机得到论元角色类型映射矩阵QVA。将构造完毕后的提示Pt输入到BART模型的解码器部分,其对应的原始文本作为编码器的输入,提示和原始文本将在编解码器注意力机制的作用下相互作用,可得到面向上下文的提示表示Hpt,如式(8)所示
Hpt=Ldec(Pt;H(enc)X)(8)
解码器在提示模板某个“[MASK]”位置m的输出可表示为H(m)pt,利用余弦相似度函数计算其与论元角色虚拟词的相似性分数SVAm,进而可以得到其属于不同论元角色的概率分布向量pEAEm,如式(9)(10)所示。在模型推理阶段,利用模型输出的概率分布向量即可判定“[MASK]”位置对应的论元角色l,如式(11)所示,从而确定实体所属的论元角色。
SVAm=cosSim(H(m)pt,QVA)(9)
pEAEm=softmax(SVAm)(10)
l=argmax(pEAEm)(11)
2.4 損失函数
由于训练样本中真正带有类别标签的词占极少数,属于难分类样本,若直接采用交叉熵损失函数,模型预测无类别标签的词产生的损失将在模型训练中占据主导地位,将会影响模型的训练效果。为缓解上述问题,增强模型对带有类别标签词的预测能力,本文使用Focal损失函数[28],如式(12)所示。
lossFL=-(1-pt)γ log (pt)(12)
其中:pt表示某个词真实类型的预测概率。
该损失函数增加了动态调节因子γ,使模型能够更加聚焦难分类的有类别标签的样本,本文中γ=2。事件检测阶段的损失LEE如式(13)(14)所示,其中ni表示第i个词对应的真实触发词类别。同理可计算得到论元抽取阶段的损失函数。
LEEi(X)=-(1-pEEi(ni))γ log (pEEi(ni))(13)
LEE=∑X∈D∑iLEEi(X)(14)
3 数据与实验
3.1 实验数据及评估指标
3.1.1 数据集
实验使用的数据集为ACE 2005数据集,采取与文献[26]相同的预处理方法,形成实验数据集ACE05-E。该数据集中包含33种事件类型和22种事件论元角色。采取与文献[26]实验中相同的数据切分方法构建低资源情况下的训练集,使用原有的验证集和测试集验证不同大小训练集对模型的影响。
3.1.2 评估指标
为便于实验结果对比,本文采用与文献[26]相同的评估指标,使用F1值衡量模型表现。事件检测任务中,Tri-I 表示识别出的触发词与真实标注完全一致,Tri-C 表示在识别出触发词并准确区分事件触发词所属的事件类型;论元抽取任务中,Arg-I 表示识别出的事件论元与真实标注完全一致,Arg-C 表示准确识别并正确区分事件论元角色。
3.2 实验环境及参数设置
本文挑选在验证集上表现最好的模型,然后在测试集上进行测试。考虑到特殊领域资源受限的情况,本文所有实验均在NVIDIA Tesla T4 16 GB GPU上进行,使用BART-base[17]预训练语言模型以适应计算资源受限的应用环境。BART-base的encoder和decoder各为6层,隐藏层向量维度(hidden_size)为768维度。模型训练使用AdamW[29]优化器,其他参数设置如表2所示。
3.3 对比模型
本文选取近几年使用预训练语言模型的事件抽取方法作为对比基线。
3.3.1 事件论元抽取模型
此类模型在给定事件类型和事件触发词情况下能够完成特定事件类型下的论元抽取任务。
a)PAIE[10]。该方法通过构造提示的方式将论元抽取转变为抽取任务,利用BART产生特定角色的片段选择器,从原句中识别论元并完成角色分类。
b)BIP[11]。该模型利用实体信息人工构建提示将论元抽取任务转变为填空任务,使用BERT在低资源情况下较好地完成论元抽取任务并超过了其他模型。
3.3.2 联合抽取模型
此类模型可以采用联合(joint)或流水线(pipeline)的方式完成事件检测和论元抽取任务。
a)OneIE[18]。该模型利用BERT进行编码,能同时完成关系抽取和事件抽取任务,是当前表现最好的模型。本文仅使用该模型作为低资源情况下的对比模型。
b)BERT_QA[30]。该模型将事件抽取转变为QA任务,通过设置问题使用基于BERT的QA模型生成事件触发词、论元以及论元角色。
c)DEGREE[26]。该方法通过构造特定格式的提示来融合额外的信息,使用BART模型按照特定格式生成事件触发词和事件论元,本文使用其流水线模式下的实验结果进行对比。
3.4 实验结果与分析
虽然本文主要研究低资源情况下的事件抽取,但为了验证提出方法的有效性,本文首先在正常数据量情况下进行实验,而后在低资源情况下进行实验。此外,为检验该方法在事件抽取任务上的综合性能,本文区分事件检测、论元抽取以及流水线执行两类任务三种情况分别进行了实验。对比模型的实验结果来源于文献[10,11,26]。由于部分方法未给出独立进行事件检测或论元抽取的实验结果,本文仅与提供实验结果的方法进行了对比。实验结果中加粗表示最优结果,下画线为次优结果,“※”为本文对其模型复现的结果。
3.4.1 正常数据量情况下实验结果分析
a)事件检测。实验结果如表3所示。从表3可以看出,虽然本文方法较问答式模型BERT_QA表现欠佳,但模型结构简单,超越使用BART-base的DEGREE模型,能够与使用BART-large的该模型达到相媲美的效果,表明构造语义映射的方法能够有效识别和分类事件触发词。
b)论元抽取。实验结果如表4所示。从实验结果可以看出,本文IFPT方法取得了最优结果。相较于其他使用BART-base的模型,通过“语义映射+提示模板”的方法能够利用外部信息,较好地引导模型完成下游任务,相较于同样利用实体信息的BIP模型性能得到进一步提升。
c)流水线方式。实验结果如表5所示。从表5可以看出,虽然IFPT在事件检测方面性能有所下降,但在论元抽取方面性能有所提升,使得其在流水线模式下仍然能够取得较好的整体表现。原因在于IFPT方法虽然在事件检测阶段准确率偏低,但召回率较高,在论元抽取阶段,IFPT模型仅使用句子的事件类型而不依赖触发词,相较于DEGREE模型,能够一定程度地缓解误差传播;对输入中原本没有的事件类型,无法抽取相应的事件论元,一定程度上起到了过滤作用,保持了较好性能。
3.4.2 低资源情况下结果分析
本文使用ACE05-E数据集中5%、10%、20%、30%、50%的训练样本构造低资源训练数据集,进一步验证模型在低资源情况下的性能表现。为体现IFPT方法在低资源事件抽取任务上的优越性,此部分对比模型实验结果均为公布的最优实验结果。
a)事件检测。实验结果如表6所示。从表6可以看出,本文IFPT方法虽然较使用BART-large的DEGREE方法存在一定差距,但较其他对比模型在极低数据量的情况下(5%、10%的训练数据)具有显著优势。
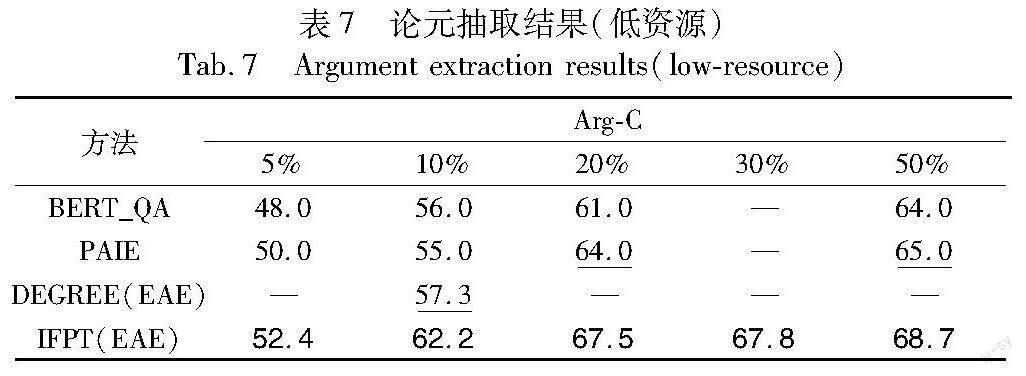
b)论元抽取。实验结果如表7所示,其中“—”表示文献未提供相应训练数据量情况下的实验结果。从表7可以看出,本文IFPT方法能够在低资源情况下较好完成论元抽取任务,有效融合利用实体、事件描述等外部信息,尤其是在极低数据量的情况下(5%、10%的训练数据),表现超过了其他基准模型。
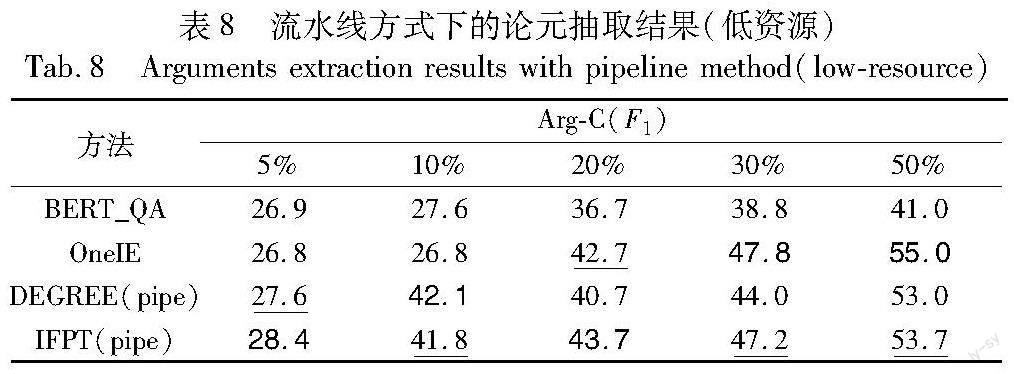
c)流水线方式。采用流水线方式执行两阶段任务的实验结果如表8所示,仅列出论元抽取结果进行对比。实验结果表明在较少数据量的情况下,IFPT方法仍然能够取得较好的表现,说明IFPT方法能够有效融合利用外部知识以提升模型性能。此外,较DEGREE(pipe)表现更好,说明IFPT方法能够有效地缓解传播误差造成的影响。
3.4.3 消融实验
本节分别针对事件检测和论元抽取任务进行了消融实验,进一步验证提出方法融合外部知识的能力。其中,random init是指语义映射中虚拟词的表示进行随机初始化情况下的实验结果。所有消融实验与原实验采用相同的参数设置,论元抽取阶段的消融实验均采取相同的打乱顺序策略。
表9中:w/o verb指去掉事件类型虚拟词描述中的“verb”;w/o synonyms指去掉事件类型虚拟词描述中的同义词信息;w/o event type desc指去掉事件类型虚拟描述中的事件类型描述信息。
从表9可以看出,在不添加任何外部信息仅对虚拟词进行随机初始化的情况下,模型在极低数据量的情况性能下降明显,随着数据量的增多,模型性能逐步提升,但与其他加入额外信息的方式相比仍然存在一定差距。说明随着训练数据逐渐增多,模型能够不断优化虚拟詞的表示,使之更符合当前下游任务。在极低训练数据量的情况下,去除同义词组对模型性能影响较大。随着数据量提升,缺少事件类型描述信息(w/o event type desc)的模型性能提升较慢,本文认为该类信息能够提升模型判断的准确度,仅有词性和同义词的情况下虽然能够识别触发词,但难以确定触发词所属事件类型,导致模型表现欠佳。
表10给出了独立进行论元抽取任务时的消融实验结果,其中random init指随机初始化论元角色虚拟词;w/o entity type指从提示中去掉实体类型信息;w/o event type desc指从提示追踪去掉事件类型的描述信息。
从表10可以看出,缺少事件类型描述信息使模型性能出现了劣化,原因在于缺少了该信息,模型将无法聚焦于某事件类型进行论元抽取,对论元角色进行区分难度增大。在缺少实体类型信息的情况下,模型性能也出现明显下降,虽然随着训练数据量的提升模型性能逐步提升,但仍超过了随机初始化虚拟词的模型,原因在于论元角色和实体类型有一定的相似性,在低资源情况下,相较于构造虚拟词来加入论元额外信息的方式,直接使用提示模板的方式更加有效。
3.4.4 提示模板對模型表现的影响
为验证不同提示模板对模型表现的影响,本文参照文献[11]的方式构建了软提示模板(soft template)。为进行区分,本文使用的提示模板为硬模板(hard template),两种提示模板构造方式示例如表11所示。其中“[Vi]”是随机初始化的伪标记(pseudo tokens),伪标记的表示将在模型训练中进行优化。本文仅对其在不同训练数据量情况下的Arg-C值进行了对比,实验结果如表12所示。
从实验结果可以看出,在5%和10%的训练数据量情况下,硬模板具有一定的优势,但随着数据量的上升,采用软模板的模型性能逐渐超越采用硬模板的模型。实验结果表明,在低资源情况下,使用接近自然语言的描述方式构造模板能够更有效地利用外部知识,发掘语言模型本身具备的知识;而加入伪标记将增加模型的学习成本,导致低资源情况下难以有效引导模型完成下游任务。随着训练数据量增大,软模板的方法性能得到明显提升,并在正常训练数据量情况下较硬模板效果更好。原因在于软模板中的伪标记较人工选择的正常词汇表示更加灵活,通过大量数据训练优化,能够包含更加丰富的上下文信息[24,31],进而提升模型表现。
3.4.5 案例分析
为了更直观地展示IFPT方法的事件抽取能力,本文提供了ACE2005数据集中的几个简单案例来展示事件触发词和事件论元的抽取情况,结果如表13所示。其中,Raw为训练集中的句子,句子中斜体为训练集句子中标注的实体,G为该句子的“Golden label”,P为模型预测阶段输出的结果,下画线为模型识别出现的错误。案例S1中仅有一个事件触发词,S2中没有事件触发词,S3中有两个不同事件的触发词。
从案例S1中可以看出,IFPT能够识别正确的事件类型触发词,并且根据事件类型识别出其对应的事件元素,正确判断给定实体是否为事件元素。S2抽取结果表明,IFPT方法能够抽取多个事件的触发词和事件论元,且在第一个阶段事件触发词抽取中出现错误的情况下,第二个阶段模型同样能够准确判断句子中的实体是否为相应事件论元,一定程度上避免流水线方法的误差传播问题。S3抽取结果表明,IFPT方法能够解决事件论元重叠的问题。
4 结束语
本文将提示学习的方法应用到事件抽取任务中,采用“虚拟词+提示模板”的方式,有效融合利用事件类型描述、实体提及、实体类型等多种外部信息,并提出了两阶段的事件抽取模型IFPT。该模型采用先事件检测后论元抽取的方法,采用同样的模型架构,以流水线方式实现了低资源情况下的事件抽取。在ACE 2005 数据集上的对比实验和消融实验的结果表明,本文方法在低资源情况下能够有效利用外部信息,论元抽取性能超过了所有基准模型,采取流水线方式能够达到与SOTA模型相媲美的性能。由于实验中对外部信息的组合运用仍需要进行人工修改,数据集中实体标注错误、特殊字符等都会对实验结果产生影响,本文方法仍存在不足和尚可改进的地方。比如,本文在仅利用了易于获得的事件类型描述、实体类别等信息,其他语义信息如实体共指信息的加入可能会带来模型更好的表现,这些都将是意欲改进和深入研究的问题。
参考文献:
[1]Doddington G R,Mitchell A,Przybocki M A,et al.The automatic content extraction(ACE) program-tasks,data,and evaluation[C]//Proc of the 4th International Conference on Language Resources and Evaluation.Paris:European Language Resources Association,2004:837-840.
[2]张聪聪,都云程,张仰森.事件抽取研究综述[J].计算机技术与发展,2023,33(1):7-13.(Zhang Congcong,Du Yuncheng,Zhang Yangsen.A survey of research on event extraction[J].Computer Technology and Development,2023,33(1):7-13.)
[3]Li Qian,Li Jianxin,Sheng Jiawei,et al.A survey on deep learning event extraction:approaches and applications[J/OL].IEEE Trans on Neural Networks and Learning Systems.(2022-10-21).https://doi.org/10.1109/TNNLS.2022.3213168.
[4]Zhong Zexuan,Chen Danqi.A frustratingly easy approach for entity and relation extraction[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computatio-nal Linguistics,2021:50-61.
[5]Xie Chenhao,Liang Jiaqing,Liu Jingping,et al.Revisiting the negative data of distantly supervised relation extraction[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Proces-sing.Stroudsburg,PA:Association for Computational Linguistics,2021:3572-3581.
[6]Brown T B,Mann B,Ryder N,et al.Language models are few-shot learners[EB/OL].(2020-07-22).https://arxiv.org/pdf/2005.14165.pdf
[7]Raffel C,Shazeer N,Roberts A,et al.Exploring the limits of transfer learning with a unified text-to-text transformer[J].Journal of Machine Learning Research:2020,21(1):5485-5551.
[8]Liu Pengfei,Yuan Weizhe,Fu Jinlan,et al.Pre-train,prompt,and predict:a systematic survey of prompting methods in natural language processing[J].ACM Computing Surveys,2023,55(9):article No.195.
[9]Hu Shengding,Ding Ning,Wang Huadong,et al.Knowledgeable prompt-tuning:incorporating knowledge into prompt verbalizer for text classification[C]//Proc of the 60th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2022:2225-2240.
[10]Ma Yubo,Wang Zehao,Cao Yixin,et al.Prompt for extraction? PAIE:prompting argument interaction for event argument extraction[C]//Proc of the 60th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2022:6759-6774.
[11]Dai Lu,Wang Bang,Xiang Wei,et al.Bi-directional iterative prompt-tuning for event argument extraction[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2022:6251-6263.
[12]Elman J L.Finding structure in time[J].Cognitive Science,1990,14(2):179-211.
[13]Kipf T N,Welling M.Semi-supervised classification with graph convolutional networks[EB/OL].(2017-02-22).https://arXiv.org/pdf/ 1609.02907.pdf.
[14]Devlin J,Chang M W,Lee K,et al.BERT:pre-training of deep bidirectional transformers for language understanding[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2019:4171-4186.
[15]Xiang Wei,Wang Bang.A survey of event extraction from text[J].IEEE Access,2019,7:173111-173137.
[16]Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2017:6000-6010.
[17]Lewis M,Liu Y,Goyal N,et al.BART:denoising sequence-to-sequence pre-training for natural language generation,translation,and comprehension[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2020:7871-7880.
[18]Lin Ying,Ji Heng,Huang Fei,et al.A joint neural model for information extraction with global features[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2020:7999-8009.
[19]葛君偉,乔蒙蒙,方义秋.基于上下文融合的文档级事件抽取方法[J].计算机应用研究,2022,39(1):49-53.(Ge Junwei,Qiao Mengmeng,Fang Yiqiu.Document level event extraction method based on context fusion[J].Application Research of Computers,2022,39(1):49-53.)
[20]Li Sha,Ji Heng,Han Jiawei.Document-level event argument extraction by conditional generation[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2021:894-908.
[21]Li Fayuan,Peng Weihua,Chen Yuguang,et al.Event extraction as multi-turn question answering[C]//Proc of Conference on Empirical Methods in Natural Language Processing:Findings.Stroudsburg,PA:Association for Computational Linguistics,2020:829-838.
[22]Liu Jian,Chen Yubo,Liu Kang,et al.Event extraction as machine reading comprehension[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2020:1641-1651.
[23]Yang Sen,Feng Dawei,Qiao Linbo,et al.Exploring pre-trained language models for event extraction and generation[C]//Proc of the 57th Conference of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2019:5284-5294.
[24]Petroni F,Rocktaschel T,Riedel S,et al.Language models as know-ledge bases?[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Confe-rence on Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2019:2463-2473.
[25]Lisa L X,Liang P.Prefix-tuning:optimizing continuous prompts for generation[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Confe-rence on Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2021:4582-4597.
[26]Hsu I H,Huang Kuanhao,Boschee E,et al.DEGREE:a data-efficient generation-based event extraction model[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2022:1890-1908.
[27]陳诺,李旭晖.一种基于模板提示学习的事件抽取方法[J].数据分析与知识发现,2023,7(6):86-98.(Chen Nuo,Li Xuhui.An event extraction method based on template prompt learning[J].Data Analysis and Knowledge Discovery,2023,7(6):86-98.)
[28]Lin T Y,Goyal P,Girshick R,et al.Focal loss for dense object detection[J].IEEE Trans on Pattern Analysis and Machine Intelli-gence,2020,42(2):318-327.
[29]Loshchilov I,Hutter F.Decoupled weight decay regularization[EB/OL].(2019-01-04) .https://arxiv.org/pdf/1711.05101.pdf.
[30]Du Xinya,Cardie C.Event extraction by answering(almost) natural questions[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2020:671-683.
[31]Qin Guanghui,Eisner J.Learning how to ask:querying LMs with mixtures of soft prompts[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2021:5203-5212.
