
基于事件驱动深度强化学习的建筑热舒适控制
2024-03-05 19:47李竹傅启明丁正凯刘璐张颖陈建平
计算机应用研究 2024年2期
李竹 傅启明 丁正凯 刘璐 张颖 陈建平
收稿日期:2023-06-14;修回日期:2023-08-21 基金項目:国家重点研发计划资助项目(2020YFC2006602);国家自然科学基金资助项目(62102278,62172324,61876217,61876121);江苏省高等学校自然科学研究项目(21KJA520005);江苏省重点研发计划资助项目(BE2020026);江苏省自然科学基金资助项目(BK20190942);江苏省研究生教育教学改革项目
作者简介:李竹(1997—),女,江苏南京人,硕士研究生,主要研究方向为建筑智能化、强化学习;傅启明(1985—),男(通信作者),江苏淮安人,副教授,硕导,博士,主要研究方向为强化学习、模式识别、建筑节能(fqm_1@126.com);丁正凯(1996—),男,江苏盐城人,硕士,主要研究方向为建筑智能化、强化学习;刘璐(1998—),女,江苏泰州人,硕士研究生,主要研究方向为建筑智能化、强化学习;张颖(1998—),女,江苏镇江人,硕士研究生,主要研究方向为建筑智能化、强化学习;陈建平(1963—),男,江苏南京人,教授,俄罗斯工程院外籍院士,硕导,主要研究方向为建筑节能、智能信息处理.
摘 要:住宅暖通空调系统通常耗用大量能源,同时也极大地影响居住者的热舒适性。目前,强化学习广泛应用于优化暖通空调系统,然而这一方法需要投入大量时间和数据资源。为了解决该问题,提出了一个新的基于事件驱动的马尔可夫决策过程(event-driven Markov decision process,ED-MDP)框架,并在此基础上,提出了基于事件驱动的深度确定性策略梯度(event-driven deep deterministic policy gradient,ED-DDPG)方法,通过事件触发优化控制,结合强化学习算法求解最优控制策略。实验结果显示,与基准方法相比,ED-DDPG在提升学习速度和减少决策频率方面表现出色,并在节能和维持热舒适方面取得了显著成果。经过实验验证,该方法在优化住宅暖通空调控制方面展现出强大的鲁棒性和适应性。
关键词:强化学习; 事件驱动; 暖通空调; 住宅建筑; 热舒适
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)02-031-0527-06
doi:10.19734/j.issn.1001-3695.2023.06.0273
Event-driven reinforcement learning thermal comfort controlfor residential buildings
Li Zhu1a,1b, Fu Qiming1a,1b, Ding Zhengkai1a,1b, Liu Lu1a,1b, Zhang Ying1a,1b, Chen Jianping1b,1c,2
(1. a.School of Electronic & Information Engineering, b.Jiangsu Provincial Key Laboratory of Intelligent Energy Saving in Buildings, c.College of Architecture & Urban Planning, Suzhou University of Science & Technology, Suzhou Jiangsu 215009, China; 2.Chongqing Industrial Big Data Innovation Center Co.,Ltd., Chongqing 400707, China)
Abstract:Residential HVAC systems typically constitute a substantial portion of energy consumption and exert a significant influence on occupants thermal comfort. At present, reinforcement learning is widely employed to optimize HVAC systems; however, this approach necessitates a substantial investment of time and data resources. To address this issue, this paper proposed a novel framework based on an event-driven Markov decision process(ED-MDP) and further introduce an event-driven deep deterministic policy gradient(ED-DDPG) method. This approach amalgamated reinforcement learning algorithms to deduce optimal control policies through event-triggered optimization. The experimental results demonstrate that ED-DDPG excels in enhancing learning speed and reducing decision frequency compared to the benchmark method. Furthermore, it attains notable accomplishments in energy conservation and sustaining thermal comfort. Following comprehensive testing and validation, the method showcases robustness and adaptability in optimizing residential HVAC control.
Key words:reinforcement learning; event-driven; HVAC; residential buildings; thermal comfort
0 引言
随着全球气候变化日益加剧,降低建筑能耗和提高热舒适显得尤为重要。据国际能源署报告称,住宅建筑占建筑能耗的最大份额,仅2020年消耗了全球能耗的35%[1]。而在建筑系统中,暖通空调系统的能耗最高,占比超过50%[2]。因此,降低暖通空调系统能耗已成为优化建筑控制的研究重点之一。然而,在追求建筑节能的同时,不能以牺牲热舒适为代价。尤其是在疫情期间,人们在室内停留时间更长[3],因此,研究人员和相关从业者越来越关注如何在保持住宅建筑热舒适性的前提下最大限度地减少能耗。
目前,大多数暖通空调系统采用RBC(rule-based control)、PID(proportional integral derivative)[4]、拉格拉朗日松弛法[5]和MPC(model predictive control)[6]等方法。然而,RBC在实际应用中存在一些限制,其控制精度有限,难以适应复杂的实际环境;PID控制器依赖于固定的参数,当环境变化时可能无法提供最佳的性能;尽管MPC控制效果可能更好,但是在实践中构建一个简化的且足够准确的建筑模型并不容易。室内环境受到多种因素影响,如建筑结构、建筑布局、建筑内部热量和室外环境等。当模型无法准确描述建筑热动力学,并存在较大偏差时,控制性能可能会偏离预期[7]。
强化学习为暖通空调系统的控制带来了新的机遇[8]。Mozer[9]最早将强化学习应用于住宅建筑;随后,Chen等人[10]提出了一种Q学习方法,旨在最大限度地减少能耗和热不适。但是对于具有大的状态和动作空间的问题,简单强化学习方法可能不实用。为了应对这一挑战,深度Q网络(deep Q-network,DQN)方法由于其简单性和高数据效率而成为暖通空调控制的常见选择[11]。然而,DQN需要对动作空间进行离散化,而足够精细的离散化会成倍地增加动作的数量,使得控制额外参数变得越来越难。为了处理连续的动作空间,Fu等人[12]提出了基于深度确定性策略梯度(deep deterministic policy gradients,DDPG)方法,避免了动作空间的离散化。尽管强化学习在暖通空调系统中展现了巨大的潜力,但是传统的强化学习方法在固定的时间步上进行学习,而暖通空调系统的控制涉及连续的时间步,这导致了一些问题。首先,由于连续时间步之间具有相似性,强化学习方法可能会导致数据冗余和低效利用。因为在连续时间步之间,环境可能保持相似的状态,但传统方法仍然需要进行策略更新和数据收集,造成了资源的浪费。其次,时间间隔的选择对控制性能有重要影响。较长的时间间隔会降低控制的精度,可能会错过重要的状态变化和事件。而较短的时间间隔会导致过多的动作调整,增加了计算负担,并且可能会引起过度频繁的策略更新,降低了控制的稳定性和效率。此外,暖通空调系统的控制问题通常涉及高维状态空间,这进一步增加了传统强化学习方法的复杂性。高維状态空间意味着智能体需要处理大量的状态信息,导致计算资源和时间的增加。这使得传统方法在实际应用中可能面临着计算效率和学习性能的折中。因此,在有限资源情况下,如何提升学习速度和节省资源,以保证节能和热舒适是必要的,这也是促使开展本文研究的直接原因。
事件驱动的思想在暖通空调领域一直备受关注。与传统的周期性控制方法不同,它仅在事件发生时触发控制行为。Wang等人[13]提出了一种基于事件驱动和机器学习的方法以提高运行效率,该方法优于传统的固定时间序列方法。为了进一步简化计算过程,Jia等人[14]为暖通空调控制问题建立了局部和全局事件,并通过实验证明了其良好的性能。然而在实际问题中,通常不存在任何封闭形式的函数来准确量化所选择的事件与事件驱动类控制策略性能之间的关系。因此,事件的构建具有较高的复杂性,并且对先验知识有较高的依赖性。此外,事件驱动的方法可能只关注短期调整,而未充分考虑暖通空调系统的长期性能。
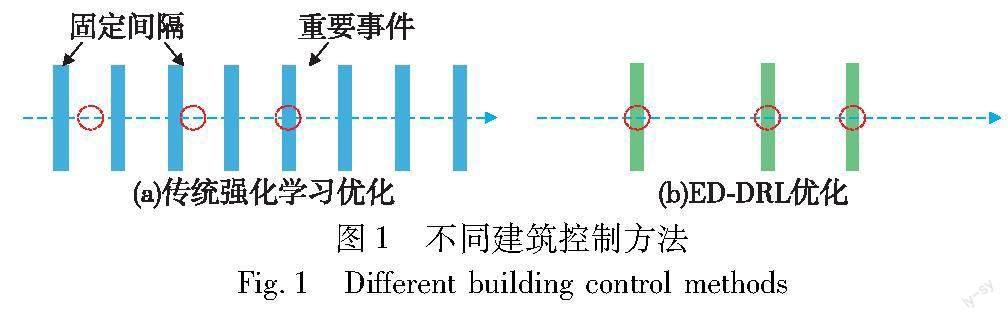
综合以上分析,本文针对传统强化学习在复杂环境中学习效率低以及频繁操作等问题,提出了一种基于事件驱动的深度强化学习(event-driven deep reinforcement learning,ED-DRL)方法。如图1所示,该方法基于“间歇性”概念,在重要事件发生后才作出决策,提高了数据的利用率。此外,ED-DRL 通过学习动态非线性特征(室内温度),可以捕捉和利用一些不经常出现的状态。最后,ED-DRL 还可以结合先验知识,在事件定义期间分配变量权重,从而可以灵活地适应看不见的环境[15]。本文通过实验证实了所提方法在优化暖通空调控制上的有效性,有望成为改进传统强化学习控制方法的一种有力手段。
1 基础知识
强化学习是一种机器学习方法,它通过智能体与环境的交互学习如何作出决策以获得最大的奖赏。强化学习通常使用马尔可夫决策过程(Markov decision process,MDP)建模智能体与环境的交互过程,其具体表述为一个五元组:Γ(S,A,P,R,γ),其中S是有限状态集,表示系统可能处于的所有状态的集合;A是有限动作集,表示智能体可以采取的所有动作的集合;P是状态转移概率函数,表示状态st下采取动作at后进入下一个状态st+1的概率,即p(st+1|st,at),其中t表示时间步;R是奖赏函数,表示在状态st下采取动作得到的即时奖赏,即R(st,at,st+1);γ是折扣因子。
如图2所示,智能体在每个时间步t观察到环境的状态st,根据当前策略π选择一个动作at,同时获取到一个即时奖赏rt+1。环境会根据当前状态和动作向智能体返回一个新状态st+1和下一时刻的即时奖赏rt+2,这个过程一直持续到终止状态。在每个时间步t,智能体根据当前状态和历史经验来更新策略和价值函数,使回报的期望最大化。其中,回报被定义为折扣奖赏的总和[16],如式(1)所示。
G(t)=∑TK=tγk-tr(t)(1)
价值函数用于评估在给定策略下状态或动作的价值,可以分为状态价值函数和状态动作价值函数。前者表示给定状态st下的期望累积奖赏,如式(2)所示。
Vπ(s)=Euclid Math TwoEApπ[G(t)|S(t)=st](2)
为了进一步考虑动作空间对目标奖赏的影响,在策略π下,目标奖赏可以用状态动作价值Q函数表示:
Qπ(s,a)=Eπ[G(t)|S(t)=s,A(t)=a](3)
然而,传统的强化学习算法是基于时间序列的,智能体需要与环境不断交互以收集数据并更新策略。这种交互方式可能需要更多的计算资源和更复杂的模型,以处理大量的状态和动作,这在实际应用中可能受到一定的限制。因此,为了应对这些问题,需要引入更加高效和灵活的方法,以提高算法的性能和效果,并降低对计算资源的需求。
2 ED-DRL方法
为了应对强化学习方法在连续的学习过程中需要大量的交互数据和计算资源的问题,本文提出一种ED-DRL方法,该方法由三部分组成。首先,针对传统强化学习的低效率问题,设计了一种新型的ED-MDP模型。通过事件驱动的思想,不再每个时间步都与环境交互,而是根据事件的发生来选择合适的决策时机,避免了不必要的交互和计算资源的浪费。其次,为了进一步优化控制,根据先验知识选择重要的状态变化作为事件,并设置合理的触发条件。这样,智能体可以针对重要事件进行更加精细的策略更新。通过先验知识的指导,智能体能判断关键事件,以更加高效地学习和适应环境的变化。最后,基于DDPG算法提出了一种结合事件驱动的ED-DDPG算法。ED-DDPG能够更好地利用事件信息,在连续动作加速学习过程并提高学习效果。智能体在学习策略时,能够根据事件的触发条件有选择地更新策略,从而进一步提高学习效率和性能。
2.1 ED-MDP框架设计
本文以多区域住宅建筑为基础,讨论了优化暖通空调系统的能耗和热舒适度控制问题。为了建立框架,采用了离散的时间表示,每个时间步為半小时,用t=0,1,2,…表示。然而,传统的强化学习方法在周期性和离散性学习过程中可能是低效的,尤其是在学习环境稳定的情况下。为了解决这个问题,本文采用了事件驱动方法来确定是否更新智能体的策略。因此,传统的MDP模型可以被重新定义为一个具有事件驱动的六元组:Ι(S,A,P,R,γ,e)。其中,e代表事件。当触发函数大于阈值时,智能体被触发并执行策略,同时发生状态转移,转移函数为p(st+1|st,a,e)[17]。具体来说,将多区域住宅建筑视为环境,ED-DRL视为智能体。此外,系统的状态、动作、奖赏的设计如下:
a)状态。状态由环境所决定。对于智能体来说,拥有全面的状态信息可以帮助其学习到更优的策略。然而,状态空间过大会导致探索变得困难,因此需要定义适量的变量以表示环境信息。在本文中,考虑了室内环境状态(每个房间人员占用率和室内温度)、室外环境状态(室外温度)、影响能耗状态(电价和舒适温度上限)。即
S(t)=[Occz(t),Tz,in(t),Tout(t),λretail(t),Thigh(t)]
其中:Occz(t)表示房间内是否有人,z表示房间号。值得注意的是,舒适温度上限Thigh(t)会根据人员占用率的变化而进行调整。当房间没人时,为了节省能耗,可以扩大舒适温度范围;而当有人时,为了保证热舒适,就恢复正常阈值。
b)动作。动作可以定义为暖通空调中的控制变量。本文将暖通空调的温度设定点定义为动作,即A(t)=[Spz(t)]。
c)对于平衡能耗和热舒适的多目标问题,本文将权重因子α作为调节参数,如式(4)所示。
R(t)=α∑tRcomfort(t′)-∑tt′=t-1λretail(t′)EHVAC(t′)(4)
其中:λretail(t′)表示零售价格,EHVAC(t′)表示能耗,Rcomfort(t′)表示温度在舒适范围内的奖赏。给定舒适范围TH(t)∈[Tlow,Thigh(t)],当执行动作偏离阈值时,会增加负奖赏。具体定义如式(5)所示。
Rcomfort(t′)=0.5 if Tlow<Tin(t′)<Thigh(t′)
Thigh(t′)-Tin(t′)if Tin(t′)>Thigh(t′)
Tin(t′)-Tlowif Tin(t′)<Tlow(5)
传统强化学习学习过程中,智能体观察环境状态、执行动作,环境给予回报,周期性地完成每一个学习步,而ED-DRL框架如图3所示,状态与奖赏仍然是周期性的,但是动作转换成了非周期性的。值得注意的是,非周期性的动作不是指不执行动作,而是不进行策略更新及策略搜索,直接沿用上一动作。
2.2 触发规则设计
传统的强化学习方法通常采用周期性的策略更新,这种方式在某些情况下是有效的强化学习,但是从学习效率的角度看,周期性的方式并不总是合适的。如果暖通空调系统在没有受到外部干扰或受到干扰较小时,一般能够按照预期的要求平稳运行。这种情况下,周期性的策略更新可以认为是资源的浪费。事件驱动方法正是为了缓解周期性采样的缺点而提出的[18]。预先设置了一些事件,并根据触发条件来决定是否需要进行策略搜索。如图4所示,假设暖通空调系统环境较为稳定,则触发条件不满足,智能体无须进行策略搜索,继续执行当前的动作;否则,需要更新策略。
在ED-MDP模型中,事件驱动的关键在于触发规则的设计。当智能体观测结束后,可以根据上一刻观测和当前观测的变化率判断是否需要触发事件。例如,当室内温度超过某个阈值时,可以触发事件,系统会自动调整温度以保持舒适。通过预先设计事件,系统可以更轻易地捕捉影响响应环境变化的先验因素,从而提高学习效率。
本文设计了状态转换事件与组合事件两种事件类型。如果需要可以很容易地将其他类型的事件添加到ED-MDP框架中。
a)状态转换事件。某些状态的变化对系统的运行有很大的影响。考虑到零售价格λretail(t)对能耗的直接影响,将λretail(t)的变化列为事件1[19]。假设当前零售价格为λretail(t)与上一时刻λretail(t′)不同时,则触发事件1。事件1定义如式(6)所示。
epz[[λretail(t′),λretail(t)]|λretail(t′),λretail(t)∈[λlow,λhigh]](6)
其中:λretail(t)与λretail(t′)都在价格范围[λlow,λhigh]内,λlow表示最低零售价格,λhigh表示最高零售价格。
同样地,事件2定义如式(7)所示。
eoz[[Occ(t′),Occ(t)]|Occ(t′),Occ(t)∈[-1,1]](7)
其中:Occ(t)与Occ(t′)在[-1,1]内,-1表示室内没人,1表示室内有人。
b)组合事件。当不同状态同时变化时,可以定义为组合事件[20]。考虑热舒适是优化的目标之一,且舒适度范围根据人员的变化而变化,则将TH(t′)与Occz(t′)的组合列为事件3。事件3定义如式(8)所示。
eTHz[[THoz(t′),THoz(t)]|Occz(t′)∈[-1,1],
THoz(t′)∈[Tlow,Tχ(t′)]](8)
其中:设置了一个舒适度范围THoz(t)∈[Tlow,Tχ(t′)],不同于TH(t),Tχ(t′)≤Thigh(t′),当即将要超出阈值时触发事件3,能更好地控制温度保持在舒适的范围内。
2.3 ED-DDPG算法设计
为了解决上述的ED-MDP问题,基于通用的DDPG算法,本文提出了一种ED-DDPG算法。在温度控制问题中,温度被视为一个连续的物理量,因此需要使用连续动作来提供更精细的控制操作。DQN算法则主要用于处理离散动作空间,可能无法提供足够的灵活性和精确度。相比之下,DDPG作为一种代表性的DRL方法,能够有效解决连续性控制问题,通过深度神经网络生成Q值或动作概率,并输出连续的动作。
多区域暖通空调系统的完整控制框架如图5所示。就网络结构来说,ED-DDPG运用了Actor和Critic两种类型的网络。同时还延续DQN使用固定目标网络的思想,每种网络都包含目标网络和估计网络。传统policy gradient方法采用随机策略,每一次获取动作需要对当前最优策略的分布进行采样,而ED-DDPG采取确定性策略,Actor网络的输入是当前状态,输出的是一个确定性的动作。Critic网络用来拟合状态动作价值函数,它的输入由当前状态和Actor网络生成的动作组成,输出是当前状态动作对Q值。这个Q值将被进一步用于更新Actor网络的参数。
ED-DDPG算法具体解释如下:
首先,随机初始化Actor网络和Critic网络,两个网络的参数分别用θμ和θQ表示,同时也初始化它们的目标网络[21],如式(9)和(10)所示。
Actor:PolicyNetonline:μθ(s|θμ)target:μθ′(s|θμ′)(9)
Critic:QNetonline:Qθ(s|θQ)target:Qθ′(s|θQ′)(10)
对于每次迭代,需初始化状态,然后判断是否触发事件。如果不触发事件,则继续执行这个动作;如果触发事件,则根据当前Actor网络选择控制动作,即温度设定点,同时将噪声添加到所选择的动作以促进对算法的探索。接下来,以t为控制间隔,执行所选动作,并观察得到的奖赏和下一个状态,将状态转移序列{S(t),Spz(t),R(t),S(t+1)}存放在经验缓存池中,用于进一步训练。当收集到足够数量的状态转移序列时,随机选择一小批状态转移序列来更新Actor网络和Critic网络的参数,更新目标y(i)(t)如式(11)所示。
y(i)(t)=R(i)(t)+γQ′(S(i)(t+1),μ′(S(i)(t+1)|θμ′)|θQ′)(11)
其中:i表示當前序列号。Critic网络的损失函数被定义为目标Q值和当前Q值之间的均方误差,如式(12)所示。
L(θQ)=1M∑t[y(i)(t)-Q(S(i)(t),μ(S(i)(t)|θμ|θQ)]2(12)
设置学习率为ηQ,利用最小化损失函数更新参数θQ,如式(13)所示。
θQ=θQ-ηQθμL(θQ)(13)
Actor网络根据确定性策略梯度进行更新参数θμ,如式(14)和(15)所示。
θμJ(θ)=1M∑t[aQ(S(i)(t),μ(S(i)(t)|θμ)|θQ) θμμ(S(i)(t)|θμ)](14)
θμ=θμ-ημJ(15)
同时, 为避免计算网络梯度时的振荡和发散问题,按照软更新(soft update)方式更新两个目标网络参数,可以保证参数波动较小且易于收敛, 如式(16)所示。
θQ′←τθQ+(1-τ)θQ′
θμ′←τθμ+(1-τ)θμ′(16)
3 实验分析
3.1 仿真设置
本文使用了一个有五个房间的三人住宅模型[22],其中卧室(房间1和2)和客厅(房间3)为训练和测试暖通空调的功能房间。而厕所和厨房只在特定情况下占用,因此不在考虑之列。住宅的占用率根据一周中的时间而变化。图6展示了人员活动规律,人员根据工作日和周末产生了不同的行动轨迹。
天气数据来自气象局[23],如图7所示,横轴表示训练或测试的时间步,纵轴表示相应的室外温度。因为研究的重点是制冷,所以选择较为炎热的7月和8月的天气数据。其中7月用于训练,8月用于测试。此外,还创建了一个模拟电价序列,其中λlow=0.5,λhigh=1.5, 电价每四小时在高低值之间交替。另外,本文定义有人时Tlow=24,Thigh(t)=26,没人时Tlow=24,Thigh(t)=28。
3.2 网络参数设置
实验实现方法基于Python以及PyTorch框架,表1列出了ED-DDPG中使用的参数。在Actor网络的输出层,使用的激活函数是tanh,确保输出值在[-1,1]。表2给出了DQN中使用的参数,动作空间从23~28 ℃,以0.5℃为步长离散化,从而导致每个房间11个可能的动作,3个房间暖通空调总共1 331个动作组合。
3.3 参数影响分析
为了深入研究ED-DDPG算法在不同情况下对模型参数的敏感性,进行了详细的实验分析,重点关注神经网络参数、奖赏权重参数和事件触发阈值。通过观察这些参数对ED-DDPG算法学习性能的影响,选择最合适的参数组合,以实现最优的算法性能。
在图8中,横轴表示回合数,纵轴表示该方法获得的平均奖赏。图8(a)展示了不同折扣因子下ED-DDPG的收敛速度。折扣因子决定了智能体对未来奖励的重视程度。观察图8(a)可以发现,当折扣因子为0.9时,算法收敛得最快,同时在50回合后获得了最高的奖赏。但是,当折扣因子为0.99时,算法可能会过度探索,无法及时响应当前的奖赏信号,因此50回合后的奖赏明显下降。图8(b)展示了不同批量下ED-DDPG的收敛速度,批量指每次输入神经网络的样本数量。可以看到,当批量为128时,奖赏明显高于其他参数,因为较大的批量可以减少数据读取和内存访问的次数。图8(c)展示了不同学习率下ED-DDPG的收敛速度。当学习率为0.001时,该算法可以收敛到最佳性能。但是,当学习率过大(0.01)或过小(0.000 1)时,算法无法收敛到最佳性能。图8(d)展示了不同衰减率下ED-DDPG的收敛速度,衰减率用于控制学习率的变化速度。当衰减率为0.005时,算法收敛得最快。然而,当衰减率过大(0.05)或过小(0.000 5)时,收敛速度和奖赏大小都不如0.005。
奖赏权重参数在很大程度上影响能耗和热舒适性之间的权衡。为了更好地平衡这两个因素,在其他参数保持相同的情况下,本文对参数α进行了研究,范围为0.1~1。在图9中,横轴表示采用不同权重设置时的热舒适违反情况,纵轴表示相应的能耗。这里热舒适违反指所有时间步中超出热舒适区域的比率。当α=0.9时,产生的能耗最高,约为15.82;当α=0.6时,热舒适违反最高,约为9.834%;而当α=1时,能耗约为15.04,热舒适违反约为2.845%,奖赏权重对于能耗和热舒适性的平衡达到了最佳状态。
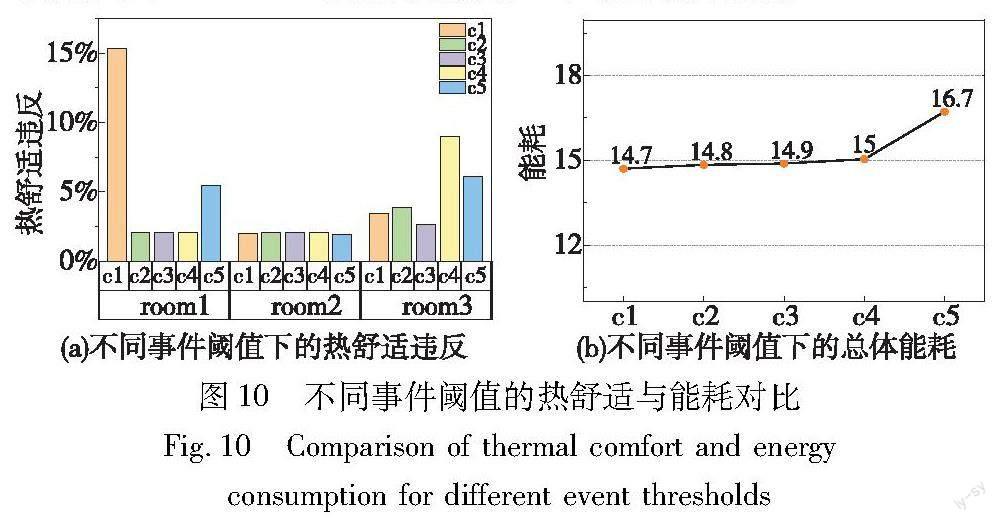
在触发规则设计中,本文定义了三个事件。事件1和2是相对简单的触发条件,分别根据价格和房间占用率的变化来触发。而在事件3中,智能体根据三个房间的占用率与热舒适阈值的变化来触发。具体来说,当有人出现在房间内时,智能体会根据相应房间的热舒适阈值来判断是否触发事件。不同的触发阈值选择会导致不同的热舒适效果。为了选择合适的触发阈值,进行了五组实验,并在表3中列出了不同情况下的设置。
在图10(a)(b)中,横轴对应了五个例子,纵轴分别表示相应的热舒适违反和能耗。从图10中可以观察到,无论是在热舒适性还是节能方面,c3都保持在较高水平。这可能是因为触发阈值恰好等于热舒适阈值,智能体能够更好地判断环境的舒适程度。从c4和c5的结果可以看出,如果触发阈值范围较小,可能会导致频繁的变动,使智能体无法学习到关键的信息,从而无法有效地平衡热舒适性和能耗,尤其是在c5中,能耗最高。而c1和c2的结果显示,即使room1或room3与c3的设置相同,也不能很好地权衡两个目标。尤其是在c1中,room1的热舒适违反最高。总体而言,如果选择了合理的参数配置,就可以保证ED-DDPG逐渐收敛至一个较好的性能。
3.4 实验结果分析
3.4.1 收敛性分析
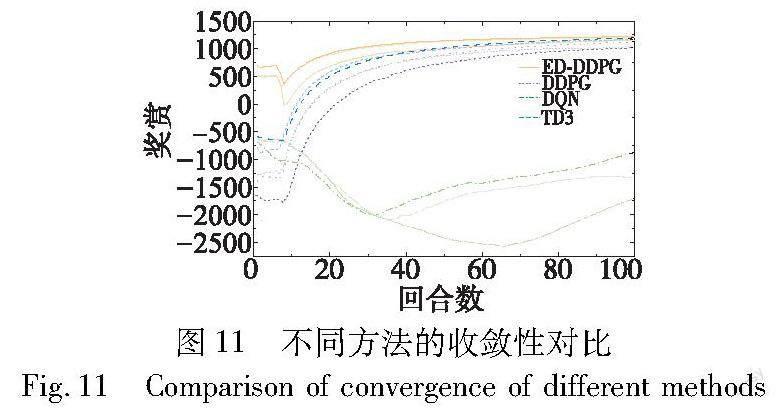
本文对比了实现暖通空調优化控制的不同方法,包括ED-DDPG、DDPG、DQN和TD3(twin delayed deep deterministic policy gradient)。DQN、DDPG和TD3都是深度强化学习算法,针对不同类型的问题和动作空间进行了设计和改进,在建筑领域受到广泛关注,特别是DDPG在该领域更为流行。DQN适用于解决离散动作空间问题,通过Q值函数输出每个动作的Q值,并使用贪婪策略选择动作。而DDPG和TD3适用于连续动作空间问题,通过策略函数输出连续动作。TD3是在DDPG的基础上引入了双Q网络和目标策略延迟更新等改进,以提高训练稳定性和性能。尽管TD3在某些场景下可能表现更优,但是相对于TD3,DDPG算法更容易实现和调整,并且在多个领域已经证明了其有效性。因此,本文选择采用DDPG作为主要的深度强化学习算法,并且大部分实验都以DDPG作为比较基准。
图11展示了这些方法的收敛性,每种方法训练了三次,用相同颜色但不同线条表示。通过图11可以观察到,ED-DDPG在大约40回合时就趋于收敛,比其他方法收敛速度更快。这是因为ED-DDPG利用了事件驱动的优化控制,智能体在重要事件发生时选择更新策略,避免了在连续时间步上进行不必要的策略更新和数据收集,从而加快了学习过程。 此外,虽然TD3与DDPG在后期趋近于ED-DDPG,ED-DDPG相对于其他方法获得了相对更高的平均奖赏。因为ED-DDPG能够灵活地适应不同的环境和情况,并在重要事件发生时选择最佳的策略更新时机。这使得ED-DDPG能够更好地学习到环境的动态变化,并根据事件判断哪些因素能耗和热舒适性的影响最为关键,证明了ED-DDPG在优化暖通空调控制上达到了更好的性能。
3.4.2 热舒适与能耗分析
为了进一步验证ED-DDPG方法的优越性,本文不仅与强化学习方法进行了对比,还选择了RBC方法作为对照。在RBC方法中,制定了一组规则,即在有人时将温度设定为24℃,在无人时将温度设定为28℃。表4对比了ED-DDPG与其他基准方法在能耗和热舒适性方面的效果。可以观察到,在所有方法中,虽然TD3和RBC在热舒适性方面表現较好,但是ED-DDPG方法在实现最低能耗的同时,保持了较高的热舒适性。具体来说,相比于TD3方法,ED-DDPG的能耗略低约0.3单位,而与RBC方法相比,其能耗较低约0.8单位。从热舒适与能耗平衡的角度来看,ED-DDPG是最优的选择。此外,图12展示了7月31日三个房间的室内温度在不同方法下的对比,横轴表示一天中的时间,纵轴表示各房间的室内温度。相比于DDPG,可以看出ED-DDPG更为平缓,只有环境突然变化时才会波动。这是因为ED-DDPG方法无须固定时间步内更新策略,而是根据事件自主调整时间间隔,所以不仅不会错过重要的环境变化,而且还提高了学习的稳定性。尽管ED-DDPG、TD3和RBC方法都能够在三个房间中良好地维持热舒适性,然而从节能效果的角度来看,ED-DDPG方法更为优越。
传统强化学习方法在每个时间步都需要与环境进行交互,以收集数据并进行策略更新,这导致学习过程变得低效。而ED-DDPG方法在重要事件发生后才作出决策,通过减少决策频率,避免了在连续时间步上频繁进行策略更新,从而节省了计算资源并延长设备的使用寿命。表5列出了ED-DDPG与DDPG方法在决策数量上的对比。可以清楚地看到,ED-DDPG在三个房间中的决策数量明显少于DDPG。
3.4.3 测试
为了验证ED-DDPG方法的鲁棒性和扩展性,基于之前训练数据,又进行了测试实验。根据表6可以看出,ED-DDPG方法在维持热舒适与能耗之间达到了最佳平衡。尽管RBC方法在热舒适方面违反最低,但却导致了较高的能耗。另一方面,虽然其他强化学习方法的能耗略低于ED-DDPG,但却存在很高的热舒适违反率,这意味着它们在实际应用中可能无法满足用户对热舒适的需求。相比之下,ED-DDPG在能耗和热舒适平衡方面表现更为出色,是未来更具实践潜力的选择。此外,从表7可以看出,ED-DDPG的决策率较DDPG明显降低,意味着通过减少决策次数能够节省计算资源的消耗。因此,可以得出结论,ED-DDPG在节省计算资源消耗、能耗与热舒适方面都具有明显的优越性。
4 结束语
本文将事件驱动引入经典的MDP框架,提出一种新的结合事件驱动的ED-MDP框架,以应对环境中规律性的变化。通过定义和识别不同的事件,智能体无须每个时间步都进行策略更新,提高了资源利用率。在此基础上,提出一种新的ED-DDPG方法,并用于优化暖通空调的控制。实验结果表明,相比于DDPG、DQN和RBC方法,ED-DDPG能够更好地平衡能耗和热舒适之间的关系,在减少决策率的同时提升了学习速度,证明了ED-DDPG方法在暖通空调优化控制方面的优越性。在未来的研究中,值得探索一种更为有效的事件驱动和数据驱动的交互模式,使这两种优化方式从相互独立变为相互合作。通过这种方式可以持续优化事件触发的准确性,并提高数据处理和分析的效率,为解决优化问题提供创新的解决方案。
参考文献:
[1]Hamilton I, Rapf O, Kockat D J, et al. Global status report for buil-dings and construction[R]. Nairobi, Kenya: United Nations Environmental Programme, 2020.
[2]Li Wenqiang, Gong Guangcai, Fan Houhua, et al. A clustering-based approach for“cross-scale”load prediction on building level in HVAC systems[J]. Applied Energy, 2021,282: 116223.[3]Qi Hongchao, Xiao Shuang, Shi Runye, et al. COVID-19 transmission in Mainland China is associated with temperature and humidity: a time-series analysis[J]. Science of the Total Environment, 2020,728: 138778.
[4]Wemhoff A P. Calibration of HVAC equipment PID coefficients for energy conservation[J]. Energy and Buildings, 2012,45: 60-66.
[5]Xu Zhanbo, Liu Shuo, Hu Guoqiang, et al. Optimal coordination of air conditioning system and personal fans for building energy efficiency improvement[J]. Energy and Buildings, 2017,141: 308-320.
[6]Eini R, Abdelwahed S. A neural network-based model predictive control approach for buildings comfort management[C]//Proc of IEEE International Smart Cities Conference. Piscataway, NJ: IEEE Press, 2020.
[7]Fu Qiming, Chen Xiyao, Ma Shuai, et al. Optimal control method of HVAC based on multi-agent deep reinforcement learning[J]. Energy and Buildings, 2022, 270: 112284.
[8]Fu Qiming, Han Zhicong, Chen Jianping, et al. Applications of reinforcement learning for building energy efficiency control: a review[J]. Journal of Building Engineering, 2022,50: 104165.
[9]Mozer M C. The neural network house: an environment that adapts to its inhabitants[C]//Proc of AAAI Spring Symposium. Palo Alto,CA: AAAI Press, 1998.
[10]Chen Yujiao, Norford L K, Samuelson H W, et al. Optimal control of HVAC and window systems for natural ventilation through reinforcement learning[J]. Energy and Buildings, 2018,169: 195-205.
[11]李可, 傅啟明, 陈建平, 等. 基于分类 DQN 的建筑能耗预测[J]. 计算机系统应用, 2022,31(10): 156-165. (Li Ke, Fu Qiming, Chen Jianping, et al. Building energy consumption prediction based on classification DQN[J]. Computer Systems Applications, 2022, 31(10): 156-165.)
[12]Fu Qiming, Liu Lu, Zhao Lifan, et al. Predictive control of power demand peak regulation based on deep reinforcement learning[J]. Journal of Building Engineering, 2023,75: 106992.
[13]Wang Junqi,Liu Rundong,Zhang Linfeng,et al. Triggering optimal control of air conditioning systems by event-driven mechanism: comparing direct and indirect approaches[J].Energies,2019,12(20):3863.
[14]Jia Qingshan, Wu Junjie, Wu Zijian, et al. Event-based HVAC control-a complexity-based approach[J]. IEEE Trans on Automation Science and Engineering, 2018,15(4): 1909-1919.
[15]Ran Yongyi, Zhou Xin, Hu Han, et al. Optimizing data center energy efficiency via event-driven deep reinforcement learning[J]. IEEE Trans on Services Computing, 2022,16(2): 1296-1309.
[16]Sutton R S, Barto A G. Reinforcement learning: an introduction[M]. Cambridge,MA: MIT Press, 2018.
[17]张文旭, 马磊, 王晓东. 基于事件驱动的多智能体强化学习研究[J]. 智能系统学报, 2017,12(1): 82-87. (Zhang Wenxu, Ma Lei, Wang Xiaodong. Reinforcement learning for event-triggered multi-agent systems[J]. CAAI Trans on Intelligent Systems, 2017,12(1): 82-87.)
[18]徐鹏, 谢广明, 文家燕, 等. 事件驱动的强化学习多智能体编队控制[J]. 智能系统学报, 2019,14(1): 93-98. (Xu Peng, Xie Guangming, Wen Jiayan, et al. Event-driven reinforcement learning for multi-intelligent body formation control[J]. Journal of Intelligent Systems, 2019,14(1): 93-98.)
[19]Xu Zhanbo, Hu Guoqiang, Spanos C J, et al. PMV-based event-triggered mechanism for building energy management under uncertainties[J]. Energy and Buildings, 2017,152: 73-85.
[20]Wu Zijian, Jia Qingshan, Guan Xiaohong. Optimal control of multiroom HVAC system: an event-based approach[J]. IEEE Trans on Control Systems Technology, 2015,24(2):662-669.
[21]李永福, 周发涛, 黄龙旺, 等. 基于深度强化学习的网联车辆队列纵向控制[J/OL]. 控制与决策.(2023-03-20).https://doi.org/10.13195/j.kzyjc.2022.2094. (Li Yongfu, Zhou Fatao, Huang Longwang, et al. Deep reinforcement learning-based longitudinal control of networked vehicle queues[J/OL]. Control and Decision(2023-03-20).https://doi.org/10.13195/j.kzyjc.2022.2094.)
[22]Deng Jie, Yao Runming, Yu Wei, et al. Effectiveness of the thermal mass of external walls on residential buildings for part-time part-space heating and cooling using the state-space method[J]. Energy and Buildings, 2019, 190: 155-171.
[23]China Meteorological Bureau, Tsinghua University. China standard weather data for analyzing building thermal conditions[S]. Beijing: China Architecture and Building Press, 2005.
猜你喜欢
建筑建材装饰(2016年12期)2017-01-19
建筑建材装饰(2016年11期)2016-12-29
建筑建材装饰(2016年11期)2016-12-29
科学与财富(2016年28期)2016-10-14
科技视界(2016年24期)2016-10-11
科技视界(2016年20期)2016-09-29
企业导报(2016年13期)2016-07-19
科技视界(2015年26期)2015-09-11
