
基于改进ADASVM的不平衡财务困境动态预测模型
2024-03-16 13:39李乃文
统计与决策 2024年4期
李乃文,李 慧
(辽宁工程技术大学工商管理学院,辽宁 葫芦岛 125100)
0 引言
财务困境预测(Financial Distress Prediction,FDP)是财务分析和企业风险管理领域的重要研究方向。2008年全球金融危机爆发之后,很多公司都受到了冲击,陷入了财务困境。因此,FDP 模型作为防范财务风险的有效工具,受到众多学者的关注[1]。
FDP 问题的本质是统计学中的二分类问题,解决该问题的方法包括数理统计理论与人工智能模型两大类[1]。数理统计理论在FDP 问题常用的模型包括判别分析模型(DA)[2]、逻辑回归模型(LRA)[3]、因子分析模型(FA)[4]等。其优势在于参数较少、结构简单且能提供概率估计。但当变量的正态性、独立性等假设条件不能得到满足时,模型的有效性会受到极大限制[5]。而人工智能模型不要求任何概率分布假设就能够处理非线性系统问题,为财务困境预测领域提供了新的研究思路,已成为该领域的热点研究方向。近年来,诸多人工智能模型广泛应用于FDP 问题。包括决策树模型(DT)[6]、神经网络(ANN)[7]、遗传算法(GA)[8]、粗糙集(RST)[9]、支持向量机(SVM)[10]和最近邻方法(KNN)[11]、模糊方法(FCM)[12]等。其中,支持向量机(SVM)在样本数相对较小的情况下,也能产生良好的泛化性能,且对非线性和非平稳数据的拟合表现良好,通常被认为是最有效的财务困境预测基础算法。近年来,在单一模型的基础上,越来越多的研究转向FDP 模型的集成方法[13]。其中,Bagging 和Boosting 作为两种最为流行集成算法,被广泛应用于FDP 模型的构建[10]。
以往国内外学者对财务困境预测的研究已经取得了丰富的成果,但仍存在许多不足。其中有两个问题亟待解决:第一,以往的大多数研究都是基于静态数据的静态模型,忽略了财务数据流随时间推移而引发的概念漂移问题;第二,虽然有少数学者研究了财务困境中的概念漂移现象,但大多数研究采用的是经过处理的平衡数据集。事实上,财务困境公司占上市公司中的比重很小,数据呈现严重的不平衡特征,以前的基于静态和类别平衡的财务困境预测模型无法与真实情况相吻合,难以对企业财务状况作出准确判断以达到预测预警的效果。
基于上述两个问题在财务困境预测研究中的迫切需要,本文提出了一种新的面向不平衡数据的动态FDP 模型,即MS-ADASVM-ITW 模型。该模型引入了带有信息保持期的时间权重函数并对ADASVM模型进行改进[14],建立了模型的动态更新机制,解决了财务困境动态变化引起的概念漂移问题;同时提出了一种混合采样方法,与ADASVM 模型耦合,以解决数据不平衡问题。通过对1081 家沪深股市上市公司的财务数据进行实证分析,验证本文提出的模型的有效性和稳定性。
1 模型构建及其改进
1.1 ADASVM-TW模型
Sun 等(2019)[11]提出的ADASVM-TW 模型以ADASVM模型为基础,引入时间权重函数用以解决概念漂移问题。其基本思想是数据批次的重要性随时间单调增加。具体时间权重函数如式(1)所示。其中,t表示数据批次号,当前数据批次号为0,从新到旧,数据批次号依次增加;n为数据集批次的总数;λ的取值范围为[0,0.99]。
ADASVM-TW 模型改进了集成训练分类器迭代过程中的样本加权机制,改进的样本权重函数如式(2)至式(5)所示。
其中,U代表ADASVM-TW算法中的迭代总次数,m表示样本总数。和分别表示第u+1 次和第u次迭代的第i个样本的权重。用于控制样本权重值改变方向,分类正确的赋值为1,分类错误的赋值为-1,以此降低正确分类样本的权重,增加错误分类样本的权重。此外,αu为由u基分类器的错误率eu确定的权重因子,它也是Adaboost集合的u基分类器的投票权重。
ADASVM的权重更新机制是基于误分率的,而时间加权的引入则是在误分率的基础上加入了时间限制。它可以更加重视样本的错误分类和更新分类,从而提高模型对动态数据流的适应能力,解决了财务困境中概念漂移的问题。
1.2 MS-ADASVM-ITW模型
本文提出的MS-ADASVM-ITW 模型在ADASVM-TW的基础上引入了带有信息保持期的时间权重函数,使得时间权重的衰减呈梯度指数衰减,以适应概念漂移的真实变化情况。同时在模型中内嵌混合采样方法,以降低数据集的不平衡性。其中混合采样方法并非直接对原始数据集进行采样,而是在ADASVM 迭代过程中动态更新样本。接下来对该模型的两个重要改进进行详细描述,并构建了模型的整体框架。
1.2.1 基于信息保持期的时序赋权方法
在财务困境中实际的概念漂移并非是连续的[15],虽然总体递减,但递减的过程是阶段性的,这一阶段被称为信息保持期,在这一期间,数据中蕴含的信息保持不变。由此,本文引入了基于信息保持期的时间权重函数式(6)、非线性指数遗忘函数来刻画信息的衰减程度,其中T'表示信息保持期时间的长短。该函数能更好地描述财务困境预测中数据随时间的阶段性衰减特征。尽管信息整体呈非线性下降趋势,但在一定时期内的影响不会有明显的改变。
当然,还可以定义其他类型的权重函数(如对数、指数等)。例如logistic 函数也常被作为权重函数引入,与上文常规的时间权重函数类似,时间权重的取值范围为(0,1),衰减系数的取值范围为[0,0.99]。图1为Sun等(2019)[11]提出的时间权重函数、logistic时间权重函数和带有信息保持期的时间权重函数的样本加权机制。经过比较发现,在新的时间加权函数中增加了信息保持期的概念,相当于在原有的权重函数中增加了一个信息基本保持不变的时间窗,从而使其衰减呈指数梯度衰减,更接近于现实,利用渐进遗忘可以提高对漂移概念的预测精度。
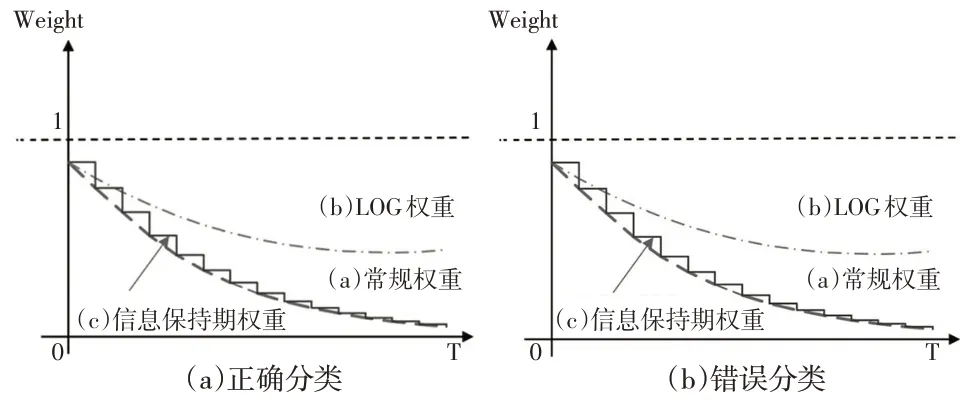
图1 样本权重
1.2.2 混合采样方法
尽管不断有新的欠采样和过采样方法被提出,但仍然存在相应的缺点。为了弥补两者的缺点,同时面向财务困境的实际问题,本文基于ADASVM 提出了一种混合采样方法,在每次迭代提升过程中融合过采样与欠采样技术,使得参与训练样本的少数类与多数类达到平衡。
将采样技术与集成技术相结合,对不平衡数据集进行处理,既保证了数据集在数据层面的平衡,又通过对集成学习算法的改进,提高了分类效果的可靠性。首先,删除部分多数类,去除多数类中的异常值和边缘样本,减少多数类中的难分样本。其次,某些类别难以分类的样本所携带的类别信息不足以充分代表少数类别,采用过采样方法,合成少数类样本,增加少数类样本的信息量。再次,将合成的样本集添加到总体采样的数据集中,通过弱分类器进一步训练,并重复该过程以获得最终分类器。最后,提高分类器的分类精度,既保证了少数类别的识别精度,又不降低多数类别的识别精度。
1.2.3 模型框架与算法
本文提出的MS-ADASVM-ITW模型,在ADASVM-TW的基础上引入了带有信息保持期的时间权重函数,使得时间权重的衰减呈梯度指数衰减,以适应概念漂移的真实变化情况,同时在模型中内嵌混合采样方法,以降低数据集的不平衡。其中混合采样方法并非直接对原始数据集进行采样,而是在ADASVM 迭代过程中动态更新样本。先使用欠采样方法消除训练集中的多数类样本,在分类器的每一轮迭代中,使用上述样本数据集形成弱分类器,再将合成样本集添加到经欠样本后的数据集中,以训练弱分类器。在样本权重更新过程中,引入带有信息保持期的时间权重函数更新样本权重。重复该过程得到最终分类器。详细算法步骤如算法1所示,算法流程图如下页图2所示。
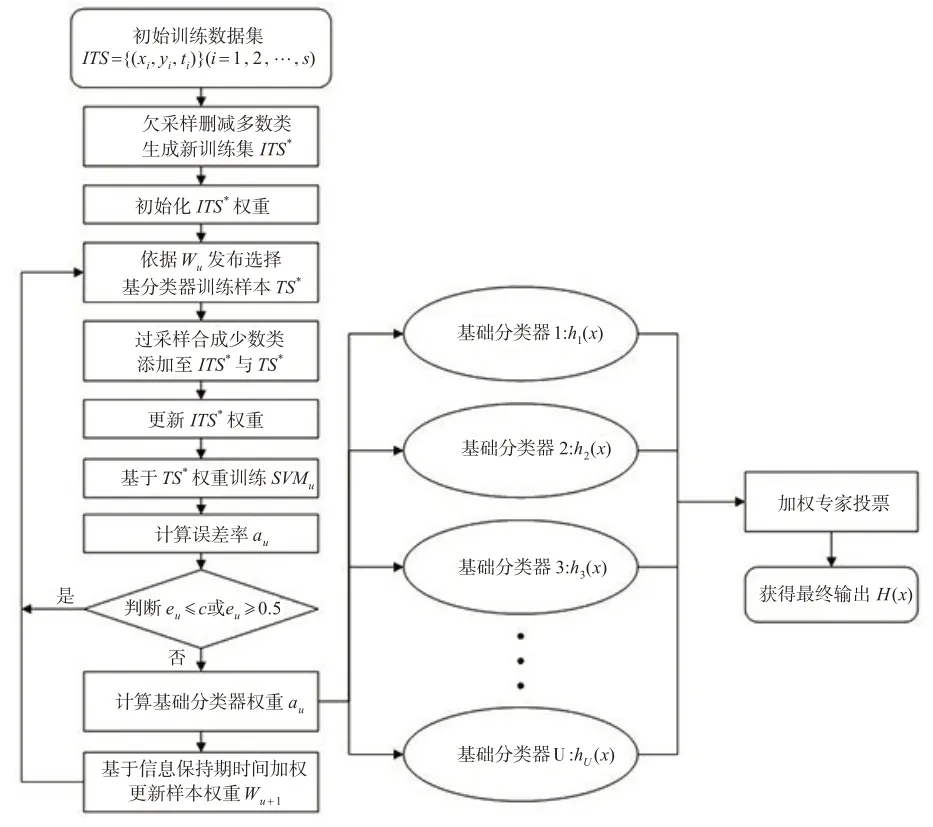
图2 MS-ADASVM-ITW算法流程图
算法1:MS-ADASVM-ITW算法。
输入:带有时间标签的类不平衡训练集ITS={(xi,yi,ti)}(i=1,2,…,S),其中yi∊{-1,1}。
初始化:
(1)基于欠采样方法对ITS训练集多数类样本进行删减,得到新的训练集ITS*,样本数为N。
(2)初始化ITS*权重,W1=(w1,1,w1,2,…,w1,N)={1/N,1/N,…,1/N}。
(3)设定错误率阈值。
Foru=1,2,…,U:
(1)从ITS*中依据分布选择基础分类器的训练集TS*。
(2)基于过采样方法对TS*中的少数类样本进行过采样,合成m个少数类样本,记为Bu,将Bu加入ITS*与TS*中,ITS*训练集样本数量为Nt。
(3)更新ITS*的样本权重,更新后的权重为。
(4)基于TS*训练一个SVM 基础分类器SVMu,也可表示为hu(x)。
(5)计算SVMu在训练样本TS*的误差率eu。
(6)判断,若eu≤c或者eu≥0.5,则删除结果返回到(1),u不变,否则到下一步。
(7)计算SVMu分类器的权重系数αu=0.5*ln[(1-eu)/eu]。
End
1.2.4 模型评价指标
为评价预测效果,本文选择Precision、Recall、G值和F值4个评价指标。对于二分类问题,根据模型预测的结果与真实类别的对比,可组合划分为4 种结果:TP(真阳性)、FP(假阳性)、TN(真阴性)、FN(假阴性)。这4项结果可以派生出相关的几个评价指标。其中,Precision用于评价预测为正类的实例的可信度,Recall用于评价有多大比例的正类实例被正确预测,对于不平衡分类问题,仅使用总体精度来评估分类器的性能是不够的,因此,本文选取G值与F值对分类性能进行评价。G值可以很好地评估模型对正类与负类样本的总体分类性能。只有在准确率和召回率都较高时,F值才会较高,可以很好地反映少数类的分类性能。
在本文中,财务困境表示为正类,财务正常表示为负类。具体的公式如下:
2 实证分析
2.1 实验设计
本文的数据来源于国泰安CSMAR数据库,以1081家沪深股市的上市公司作为研究对象,以年为基本时间单位,时间跨度为2008—2020 年。选取1081 家上市公司的财务数据作为样本。国内学者倾向于将财务困境样本定义为被进行ST 处理的公司,本文也采用了该定义。FDP的动态预测是一个增量学习的过程,选取2014 年为基准年,利用2008—2014 年的数据构建基础训练集,考虑到“ST”的评价是由过去连续两个会计年度的审计结果确定的,因此以样本T-2 年(2008—2012 年)的财务数据构建特征变量,以样本第T 年(2014 年)的财务数据构建标签。然后以2015—2020 年的数据构建测试集,随着时间基准推移,不断更新训练集数据以构建动态模型,并不断评价模型的预测效果,动态预测流程详见图3。
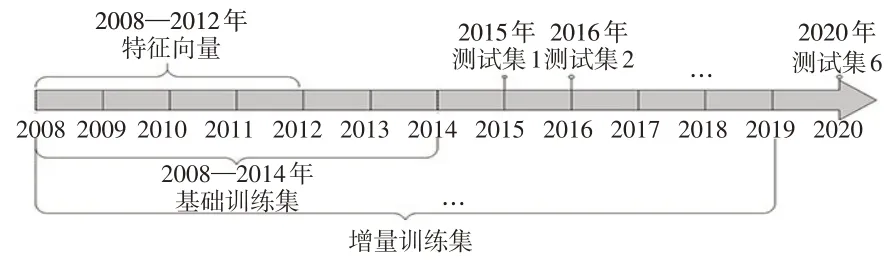
图3 动态预测示意图
本文共设计了两个对比实验,在第一个实验中,将本文提出的MS-ADASVM-ITW模型与ADASVM经典模型以及Sun 等(2019)[11]提出的ADASVM-TW 改进模型进行对比,通过6次移动预测验证模型对处理不平衡财务数据动态预测的有效性与泛化能力。在第二个实验中,对模型的混合采样方式做进一步探索,通过对比不同的过/欠采样组合,选取适合财务困境动态预测的采样方法。本文利用Python编程实现了各类统计学计算、数据处理与模型建模以进行仿真实验。
2.2 指标筛选
基于上市公司财务报表,采用定性选择与定量相关分析相结合的方法对财务指标进行选取。首先,充分借鉴国内外研究成果,从偿债能力、发展能力、股东获利能力、盈利能力、营运能力、现金流量能力6个方面,选取了45个财务指标作为备选原始财务指标,如表2所示。

表2 备选原始财务指标
并不是所有财务指标都对财务困境预测模型的构建具有现实意义,因此需要对备选财务指标进行降维处理。筛选前必须对数据进行预处理,包括补全缺失值和删除异常值。本文采用序列平均法来填补缺失的数据。由于每个企业的发展都有所不同,一些公司的财务数据表现出极端现象,这种极端现象的财务数据的存在可能会影响模型的训练,因此本文采用三倍标准差法检测并排除了极值。
为了比较“ST”和非“ST”公司组间财务指标是否具有显著性差异,要对财务指标进行显著性检验。本文利用Kolmogorov-Smirnov 方法对财务数据指标进行了正态性检验。判断正态分布的标准是P 值是否超过0.05。经检验,除了营运资金比率(X4)、资产负债率(X5)、每股营业收入(X19)、销售毛利率(X23)、固定资产净利润率(X28)、净资产收益率(X29)、应付账款周转率(X33)、固定资产周转率(X37)、营业收入现金比率(X42)和每股营业活动现金净流(X43),其余指标都不服从正态分布。对于符合正态分布的指标采用Student-t 参数检验方法,不符合正态分布的指标采用Mann-Whitney U 非参数检验方法。
Mann-Whiney U非参数检验的结果(略)表明,备选原始财务指标中共12 个指标在不同公司间具有显著性差异,予以保留,其余指标对财务困境状态的敏感度较低,应当从研究范围中删去。t 检验结果显示,在显著性水平为5%时X5和X29存在明显差异。根据以上显著性检验筛选出的指标能够较好地区分财务困境公司与正常公司,使得预测结果更具客观性,可以进行下一步分析。
为避免出现多重共线性问题,本文采用容差系数(TOL)和方差膨胀系数(VIF)进行多重共线性检验,剔除容许度(TOL)小于0.1 或方差膨胀因子(VIF)大于10 的指标,最终保留9个对财务困境预测具有明显统计学意义的指标作为模型的输入,包括:流动比率、权益对负债比率、每股收益、每股净资产、每股未分配利润、资产报酬率、净资产收益率、流动资产周转率和总资产周转率。
2.3 结果分析
基于上文构建的评价指标体系,对逐年的预测结果进行评价。表3列出了各模型2015—2020年的测试精度,其中每个结果为计算50次试验的平均值,最后一列为每个模型6 年精度指标的平均值。从Precision指标可以看出,MS-ADASVM-ITW在5个预测年份精度最高,1个预测年份精度居中;ADASVM在4个预测年份精度最低,2个预测年份精度居中,ADASVM-TW在3个预测年份精度居中,1个预测年份精度最高,1个预测年份精度最低,Recall指标也显示了类似的趋势。就Precision和Recall的结果而言,ADASVM 模型整体精度较低,ADASSVM-TW的动态预测效果明显优于ADASVM 静态模型,然而ADASSVM-TW模型稳定性较差,MS-ADASVM-ITW 明显优于其他两个模型。就G值和F值的结果而言,ADASVM 的精度几乎都是最低的,显示其对非均衡数据的处理能力较低,MS-ADASVM-ITW 几乎都是最高的,体现其对非均衡数据特别是少数类的良好预测效果。同时需要注意的是,一般基于不平衡数据的采样方法会在一定程度上牺牲多数类财务正常样本的识别能力,以提高对少数类财务困境样本的识别能力,而本文提出的混合采样方法,迭代更新样本,对多数类财务正常样本仍保持较高的识别能力。
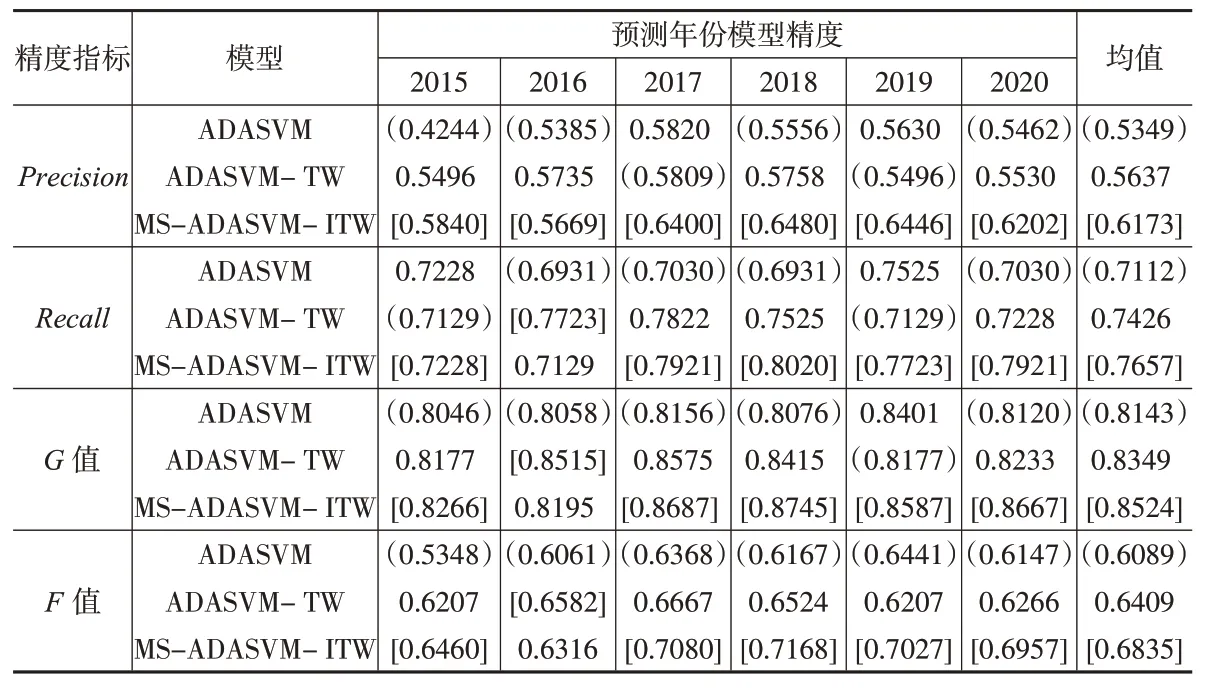
表3 逐年预测结果评价
将三个模型6年的指标均值绘制成柱状图(如下页图4 所示)。总体来看,本文提出的MS-ADASVM-ITW 模型在四个指标上都是最优的,ADASVM 模型的预测效果最差。ADASVM 模型在Precision、Recall、G值三个精度指标上与本文提出的模型相差不大,而在F值上具有较大差异,只有当少数类别的Precision和Recall较大时,少数类别的F值才较大,所以它可以准确地反映少数类别的分类效果,把一个财务困境公司错分类为财务正常公司的成本,远比把财务正常公司错分类为财务困境公司的成本要大得多,本文提出的模型在解决数据不平衡问题上具有较大优势。
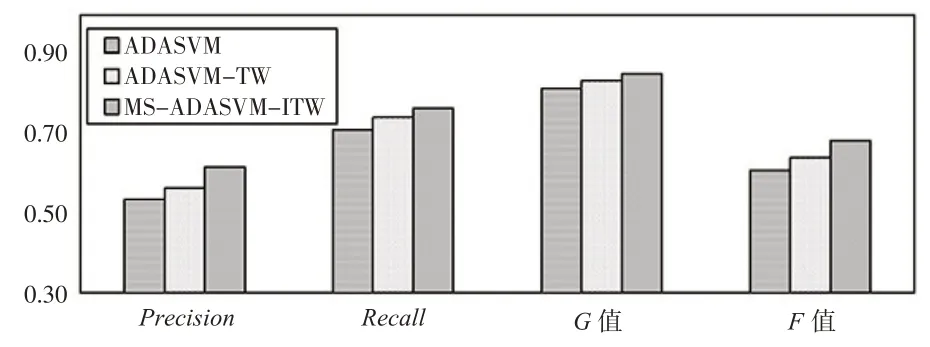
图4 评价指标均值对比
进一步验证不同采样方式组合对改进模型的提升效果。其中欠采样技术包括EasyEnsemble、BalanceCascade、Tomek Link 和ENN 四种方法,过采样技术包括SMOTE、DBSMOTE、Border-line SMOTE 和ADASYN 四种方法,两两组合应用于本文提出的MS-ADASVM-ITW 模型,其中SMOTE+Tomek Link 是上文实验的基础组合。表4 和表5为不同组合G值和F值的均值比较结果。
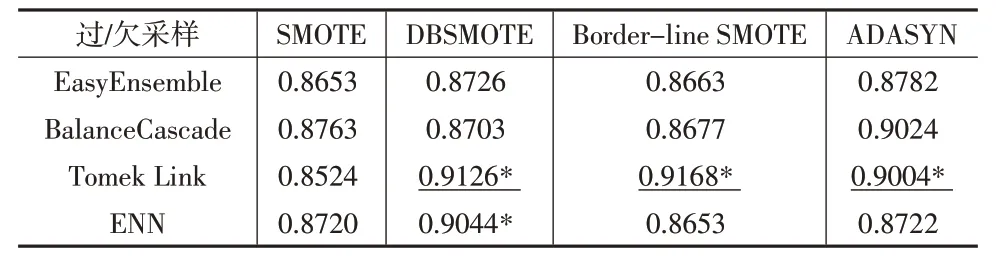
表4 不同采样组合方式的G 均值
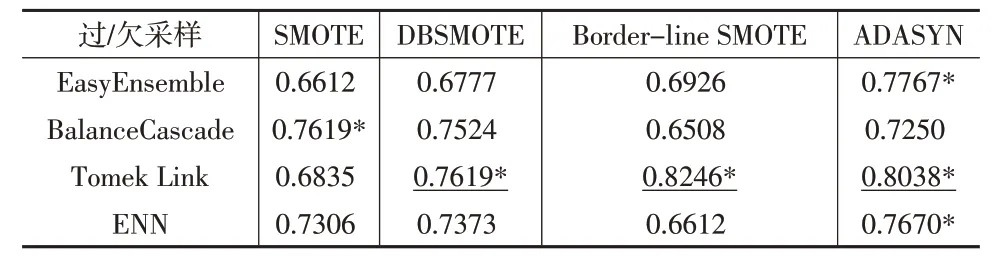
表5 不同采样组合方式的F均值
从表4和表5的实验结果可以看出,本文不同的采样组合方式对模型性能的提升效果各异。G均值较优的组合方式包括DBSMOTE+Tomek Link 组合、Border-line SMOTE+Tomek Link组合、ADASYN+Tomek Link组合、DBSMOTE+ENN 组合和ADASYN+BalanceCascade 组合;F均值较优的组合方式包括SMOTE+ BalanceCascade 组合、DBSMOTE+Tomek Link组合、Border-line SMOTE+Tomek Link组合、ADASYN+EasyEnsemble组合、ADASYN+Tomek Link组合、ADASYN+ENN组合;两个评价指标均高的组合方式包括DBSMOTE+ Tomek Link 组合、Border-line SMOTE+Tomek Link组合和ADASYN+Tomek Link组合,这三种组合方式的欠采样技术都包含Tomek Link 方法,可见Tomek Link欠采样方法对模型性能提升具有较大影响。同时三种组合方式中,Border-line SMOTE+Tomek Link 的组合相对最优,其G均值为0.9168,F均值为0.8246,相比上文实验中的基础组合SMOTE+Tomek Link,G均值提高了7.6%,F均值提高了20.6%,为财务困境预测不平衡数据的建模提供了较优的解决方案。
3 结束语
本文考虑到FDP 中数据不平衡和概念漂移同时存在的问题,以ADASVM模型为基础,提出了一种新的动态集成模型MS-ADASVM- ITW。以我国沪深股市1081 家上市公司作为研究对象,通过实验对比,结果表明,本文提出的模型具有较高的精度。基于信息保持期的时间权重函数动态更新模型,解决了财务困境中的概念漂移问题,使企业财务困境建模从静态向动态更新。同时针对不同混合采样组合方式进行对比,得到Border-line SMOTE+Tomek Link为最优组合方式。这表明,分类不均衡导致少数类型的财务困境样本缺少足够的财务信息,使得财务困境预测模型对少数类型的财务困境样本的判正率较低,而采用混合采样的方法可以有效地平衡财务困境和非财务困境的样本,提高了模型的预测效果。
猜你喜欢
当代陕西(2020年17期)2020-10-28
文苑(2020年12期)2020-04-13
人大建设(2018年5期)2018-08-16
电子测试(2018年1期)2018-04-18
电信科学(2017年6期)2017-07-01
环境保护与循环经济(2017年8期)2017-03-22
中国卫生(2016年5期)2016-11-12
环境科技(2016年3期)2016-11-08
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
