
基于生成式对抗网络的联邦学习激励机制
2024-03-21 02:25余孙婕熊诗雨史红周
计算机应用 2024年2期
余孙婕,曾 辉,熊诗雨,史红周
(1.移动计算与新型终端北京市重点实验室(中国科学院计算技术研究所),北京 100190;2.中国科学院大学 计算机科学与技术学院,北京 100190)
0 引言
在新一代人工智能技术的催化下,数据作为重要的生产要素发挥着越来越重要的作用[1]。“数据二十条”提出数据资源持有权、数据加工使用权和数据产品经营权“三权分置”的数据产权制度框架,在安全方面对数据共享提出新的要求[2]。2016 年,Google 为应对数据共享与隐私安全之间日益激化的矛盾,首次提出了数据安全共享的新思路,即联邦学习[3]。数据保留在本地物理域中,参与节点使用自身数据分别训练本地模型,并共同建立联合模型。数据所有者的数据资源持有权和数据加工使用权均不受侵害,依托数据产品经营权的转让委托获取收益,缓冲了数据共享与隐私安全之间的矛盾,为打通“数据孤岛”提供新范式,也为数据驱动型产业带来了新的解决方案。联邦学习概念一经提出,便得到了众多关注,目前已在多个领域得到应用,如智慧医疗[4]、智慧城市[5]、金融[6]和智能工业[7]等;但联邦学习仍面临着众多挑战。联邦学习系统通常假设所有参与节点会诚实且积极地参与联邦学习,但由于不同的参与节点往往拥有不同数据量、不同数据质量的数据,不同参与节点对于最终全局模型的贡献度不同,因此在公平激励环境中,拥有高数据量和高数据质量的参与节点的参与积极性较低,假设难以成立。特别地,在非独立同分布数据场景中,参与节点的贡献度更难衡量。在本地模型训练的过程中存在算力、带宽等多种资源的消耗。如果缺乏公平合理的激励机制,参与节点,特别是拥有高质量数据的参与节点参与联邦学习任务的积极性难以保证,将严重影响联邦学习效果和系统稳定性。
Zhan 等[8]提出联邦学习中的激励机制设计的两个重要目标:一是评估参与节点贡献,二是设计合理的回报吸引更多的参与节点。第一个目标从中央节点出发,目的是通过提供最低的回报获得更高的学习性能;第二个目标从参与节点出发,目的是获得一个公平、有回报且安全可信的联邦学习环境。联邦学习系统通常对于隐私安全有较高的要求,深度学习常规模型性能指标,如精度、召回率、F1-Score 等,由于测试数据集的缺失难以评估,因此中央节点难以准确构建每个参与节点的贡献模型。
现有对参与节点贡献模型的研究可以按数据源的不同分为以下三类:节点行为驱动、模型驱动和数据驱动。
节点行为驱动型贡献度评估方法使用参与节点历史行为、参与节点对自身数据集的评估等数据计算参与节点在联邦学习任务中的贡献度,以基于博弈论的拍卖理论[9]、Stackelberg 博弈[10]、深度强化学习[11]等方法为代表。Zeng等[9]在联邦学习场景下提出了多维激励框架FMore,该框架使用博弈论为参与节点推导最优策略,并使用预期效用理论为中心节点评估参与节点贡献度,以此作为选择最优的参与节点依据训练模型。基于博弈论的贡献度评估方法通常要求参与节点诚实提交自身参数,包括数据量、数据质量和带宽等,但在实际场景中,为了获取高额佣金,参与节点可能谎报自身参数。深度强化学习需要部署深度强化学习智能体以确定最优策略,深度强化学习智能体的训练过程依赖于环境的大量交互信息,存在巨大的计算开销,而联邦学习常应用于边缘计算,难以承受深度强化学习带来的计算成本。
模型驱动型贡献度评估方法使用模型参数、梯度等数据计算参与节点在联邦学习任务中的贡献度,以模型余弦相似度[12]等方法为代表。Xu 等[12]提出了一个公平且稳定的联邦学习框架RFFL(Robust and Fair Federated Learning),该框架使用参与节点本地模型与联合模型的余弦相似度确定参与节点的声誉值,通过声誉值迭代计算参与者的贡献,并向参与节点提供与它的贡献相称的奖励。但是,模型驱动型贡献度评估方法假设与联合模型具有相似模型参数的模型提供了更多的贡献。首先,深度神经网络的模型参数易受扰动,基于模型参数的模型相似度评估难以确保准确性;其次,在非独立同分布数据场景下,参与节点持有不同数据分布的数据,它的模型参数的分布也不一致,仅依赖模型相似性难以评估该场景下参与节点的贡献度。
数据驱动型贡献度评估方法使用真实数据计算参与节点在联邦学习任务中的贡献度,以Shapley 值[13]等方法为代表,Shapley 值通过边际收益衡量每个参与节点的贡献。Wang 等[13]针对横向联邦学习,每次删除某一参与节点提供的本地模型并重新训练模型,计算新模型与原模型之间的差异作为该参与节点的贡献度;针对纵向联邦学习,考虑到每一个参与节点都拥有一部分特征空间,使用Shapley 值计算分组特征的重要性,以衡量每个参与方的贡献度。但是,数据驱动型贡献度评估方法依赖高质量、大数据量的测试集数据,而在联邦学习场景下,中心节点通常不具备该条件,同时,出于联邦学习对数据隐私的保护,中心节点难以大量采样来自各参与节点的数据。
本文首先提出一种基于生成式对抗网络(Generative Adversarial Network,GAN)的联邦学习激励机制,采用GAN在保证数据隐私安全的同时生成大量高质量测试数据,该过程透明、可审计,为参与联邦学习任务的节点提供公平的贡献度评估方法。其次,采用两阶段Stackelberg 博弈对激励机制建模分析。最后,分析并验证了所提方法的安全性和可行性。
1 准备工作
1.1 联邦学习
联邦学习通过多个参与节点合作的方式提供分布式机器学习解决方案,允许原始数据保存于用户本地,仅将模型上传至中央节点,以构建全局模型。随着用户日益对隐私的重视和法律法规对隐私数据使用的限制,联邦学习在避免隐私问题、减少服务端数据存储开销的同时,极大地提高了数据的利用率,对于智能边缘服务,如智能医疗等场景,具有极高的吸引力。集中式联邦学习框架流程如图1 所示。具体流程共分为5 个环节,分别为:1)中心节点初始化联合模型,并调度指定参与节点参与联邦学习任务;2)参与节点下载联合模型;3)参与节点利用本地数据训练本地模型;4)参与节点上传本地模型;5)中心节点使用聚合器根据指定聚合算法对本地模型聚合,得到联合模型。
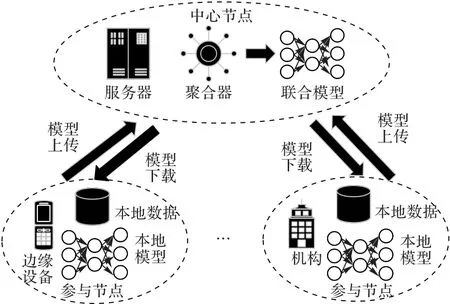
图1 集中式联邦学习框架流程Fig.1 Process of centralized federated learning framework
联邦学习的总体目标定义为最小化联合模型的损失函数,即:
1.2 生成式对抗网络
Goodfellow 等[14]基于零和博弈和对抗训练,为解决生成建模问题提出了GAN。GAN 在视觉[15]和图像[16]领域表现出卓越的性能,目前被广泛应用于自然语言处理[17]等任务。GAN 由1 个生成器(Generator,G)和1 个判别器(Discriminator,D)构成:生成器以学习真实数据分布为目标,输入随机噪声z,输出生成图片g(z);判别器以正确识别是否真实数据为目标,输入服从真实数据分布的采样数据x,输出是真实数据的概率D(x)。生成器G 和判别器D 共同训练达到纳什均衡。GAN 目标函数可以描述为如下:
在给定生成器G 的情况下,目标函数L(D,G)在
处取到最小值,即为判别器最优解,其中pdata(x)为真实数据分布,pg(x)为生成器数据分布。
GAN 结构如图2 所示。

图2 GAN结构Fig.2 Structure of GAN
现有的针对基于GAN 的联邦学习样本生成策略[18-19]通常采用分布式部署GAN 的方法实现,但分布式部署的GAN生成器难以避免地暴露本地数据样本的真实分布,难以保障参与节点的数据隐私安全。
2 方案设计
2.1 融合训练模型的生成式对抗网络
本文基于GAN 实现融合训练模型的生成式对抗网络(GAN with Trained model,GANT)。联合模型通过真实数据训练得到,将联合模型作为影响判别器的一个重要因素,可以缓解由于采样特征数据的数据量不足带来的生成器难收敛和精度不足的问题。与GAN 算法的训练机制类似,GANT算法的训练机制同样分为两个部分:固定生成器G 优化判别器D 和固定判别器D 优化生成器G。
1)固定生成器G 优化判别器D。
对于任意输入x,联合模型对该输入为伪造样本的评估值为:
其中:Ce为数据标签的独热编码集合,c为数据标签的独热编码,M(x)为联合模型M输入数据x产生的输出。Y(x)的值越接近0,表示x越有可能为真实样本;Y(x)的值越大,表示x越有可能为伪造样本。
判别器D 的训练数据将采样自真实数据分布pdata(x)的数据x标注为1 -αY(x),其中,α∈[0,1]为联合模型对真实样本的影响因子;采样自生成器生成数据分布pg(x)的数据g(z)标注为μ-βY(g(z)),其中,β∈[0,1]为联合模型对伪造样本的影响因子,μ∈[0,1]表示伪造样本的上界。
由于Y(⋅)是稠密的,GANT 采用均方误差评估判别器D的损失,它的目标函数表示为:
将(D,G)映射在连续空间上,即
对YD-1(x) 做一阶项近似,令y=D(x),因此有YD-1(D(x)) =YD-1(y) =ay+b,a、b为一阶项和常数项对应系 数,令对于任意非零实数∈[0,1],有
判别器D 的最优值不仅与pdata(x)和pg(x)的比值相关,而且与联合模型相关。当a=0,b=0,μ=0 时,即将来源于生成器生成数据分布pg(x) 的数据标记为与GAN 模型一致。
2)固定判别器D 优化生成器G。
生成器G 的目标是尽可能阻止判别器D 区分来自真实数据分布的数据和来自生成器生成的数据,因此,它的目标函数为最大化判别器D 损失函数,即
因此,GANT 结构如图3 所示,GANT 目标函数可以描述为:
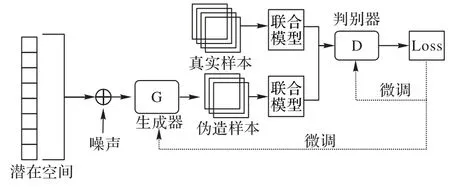
图3 GANT结构Fig.3 Structure of GANT
2.2 基于生成式对抗网络的联邦学习贡献度评估算法
本文基于融合训练模型的GAN 实现联邦学习的贡献度评估算法。本文算法利用GANT 的生成器G 生成大量仿真特征样本g(z),使用联合模型过滤高质量特征样本,过滤条件如下:
其中:Mk表示参与节点k的本地模型,acc(Mk,)表示Mk使用数据集的精度,Fk,i表示参与节点k本地数据集中数据标签为第i类数据标签的数据所占百分比,n表示参与节点k本地数据集中所拥有的数据标签关于总标签的百分比。
基于GAN 的联邦学习贡献度评估算法伪代码如下所示。
算法1 基于GAN 的联邦学习贡献度评估算法。
2.3 基于两阶段Stackelberg博弈的联邦学习激励机制
本文基于两阶段Stackelberg 博弈实现联邦学习激励机制。为了更好地描述激励模式,首先划分参与联邦学习任务的实体,将参与联邦学习任务的实体分为参与节点和请求节点两类:1)参与节点,拥有相关数据集,并参与联邦学习任务的实体;2)请求节点,发布联邦学习任务的实体。
本文从资源配置和激励机制角度对参与节点和请求节点构建效用模型,如下所示:
1)参与节点效用模型。
假设参与节点k单位时间最大CPU 周期数为,参与模型训练任务花费的单位时间CPU 周期数为qk(qk≤)。模型训练总共e轮,参与节点k拥有Dk个batch 块数据,每个batch块花费的CPU 周期数为dk。参与节点k参与模型训练任务需要的总CPU 周期数为μk=edkDk,花费的时间开销为Tk=,其中,Tk'为总时间开销的上限。
为了鼓励参与节点积极参与联邦学习任务,请求节点将为参与节点提供奖励。假设参与节点k参与模型训练任务单位时间奖励为pk,参与节点k参与联邦学习获得的奖励为Rk=Tkpk。
根据能耗模型[20]计算得到参与节点k的计算开销为,其中ρk与参与节点的硬件架构相关。参与节点的总体开销为其中ξ>0 表示计算开销折算的成本因子。参与节点的效用模型表示如下:
2)请求节点效用模型。
其次,根据实体效用模型可知,参与节点k根据请求节点的奖励提供计算能力和隐私数据完成联邦学习任务,即参与节点k单位时间奖励pk决定单位时间CPU 周期数为qk,因此本文将参与节点与请求节点之间的交互表述为两阶段Stackelberg 博弈。其中,阶段一请求节点基于预算和消耗的总CPU 周期数μk,通过最大化自身效用为每个参与节点设置单位时间奖励pk;阶段二参与节点在收到单位时间奖励pk后通过优化自身效用确定相应的计算能力qk。具体分析如下:
1)阶段二:优化参与节点效用。
基于对参与节点的效用模型和两阶段Stackelberg 博弈问题表述,参与节点k的目标函数表示如下:
2)阶段一:优化请求节点效用。
基于对请求节点的效用模型和两阶段Stackelberg 博弈问题表述,代入参与节点k的最优策略请求节点的目标函数表示如下:
其中:约束条件1 表示请求节点对任意参与节点的收益非负;约束条件2 中表示对参与节点k的奖励预算,由请求节点的总预算R和贡献度评估算法共同决定;约束条件3 表示单位时间奖励非负。令即请求函数的目标函数表示如下:
最后,总结基于两阶段Stackelberg 博弈的联邦学习激励机制伪算法如算法2 所示。
算法2 激励机制算法。
对他人和自己文章的再书写不应当只是简单的抄写。要使书法创作高质圆满,对文章阅读、认识乃至再创作,尤其对文章时空情绪的体认和把握是非常关键的。当然,书者要有高超的书技和过硬的基本功是前提。在这个前提下,书法行为所达到的高质就取决于上述那个关键了。对文章时空情绪的体认程度和再创造、再感染程度越高,就越能提升书法行为的秩序化程度,从而提升作品质量。
3 安全性分析
本文将从数据采集、数据生成、节点标记、数据存储和过程审计5 个方面分析激励机制安全性。
1)数据采集。本文激励机制需采集少量真实数据,该数据量大小约为真实数据集的千分之一,难以据此还原参与节点的数据特征和数据分布。同时,参与节点可采用接受-拒绝采样[21]或差分隐私[22]的方式为采样数据提供安全隐私保障。
2)数据生成。本文激励机制数据生成过程使用GANT算法,采用GAN 与联合模型相结合的方法实现。与针对联邦学习的GAN 攻击[23]不同,该过程仅使用最终训练完成的联合模型,并不涉及训练过程中对本地模型的恶意引导和对参与节点数据分布的恶意猜测。
3)节点标记。本文激励机制通过对参与节点的贡献分析,可以标记低数据质量节点,用于在未来联合训练过程中筛选和识别,提升联邦学习过程的安全性和稳定性。
4)数据存储。参与节点的数据除极少数采样数据外,均不出本地物理域,仅通过模型的形式共享,数据的隐私安全得到充分保障。
5)过程审计。本文提出的激励机制过程可审计,任意参与节点获取中央节点训练时使用的随机种子均可复现贡献度评估过程;同时,参与节点可采用区块链技术提供对联邦学习激励过程每一环节的监督和审计,为联邦学习提供更加充分的安全保障。
4 实验与结果分析
4.1 正确性分析
假设各参与节点的数据大小相同,对此,本文设置μk=10。对于参与节点和请求节点,共有4 种策略组合,分别是:参与节点和请求节点均选择最优策略;参与节点选择最优策略,请求节点选择随机策略;参与节点选择随机策略,请求节点选择最优策略;参与节点和请求节点均选择随机策略。分别仿真参与节点总效用和请求节点效用随参与节点数的变化如图4 所示。
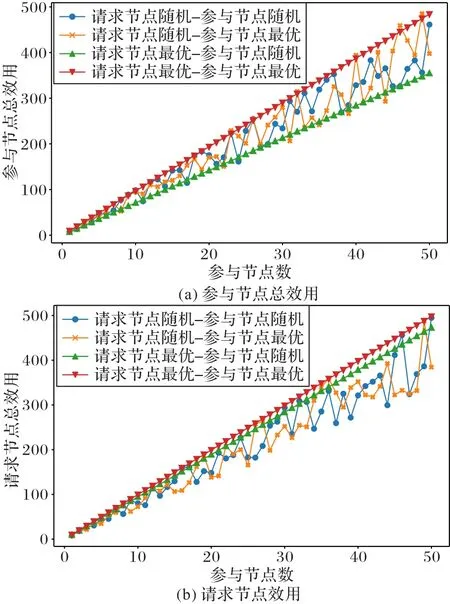
图4 参与节点总效用和请求节点总效用随参与节点数变化Fig.4 Total utility of participant nodes and total utility of requesting nodes varying with number of participant nodes
从图4 结果可以看出,当参与节点和请求节点均选择最优策略时,可以获得比其他策略更高的效用。
为了验证总CPU 周期数对于请求节点和参与节点效用、对单位时间奖励和单位时间CPU 周期数的影响,设置参与节点总数为50,测试在μk=(1,4]时,请求节点和参与节点的效用变化如图5 所示,单位时间奖励和单位时间CPU 周期数变化如图6 所示。

图5 参与节点和请求节点效用随总CPU周期数变化Fig.5 Utilities of participant nodes and requesting nodes varying with total number of CPU cycles
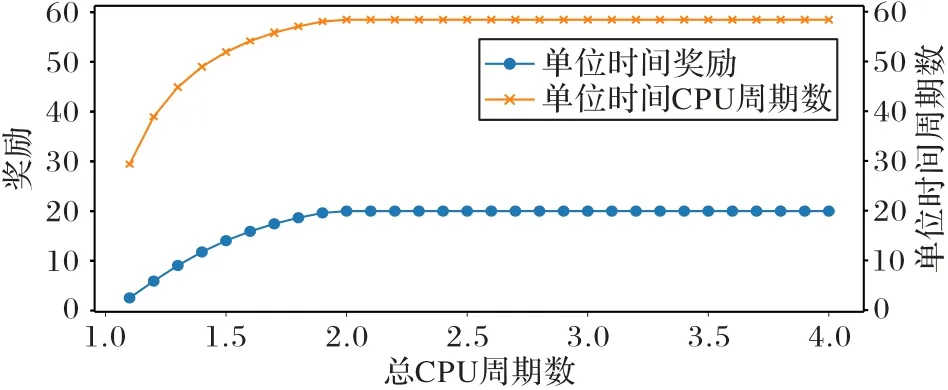
图6 单位时间奖励和单位时间CPU周期数随总CPU周期数变化Fig.6 Reward per unit time and CPU cycles per unit time varying with total number of CPU cycles
随着训练的总CPU 周期数增加,可以刺激参与节点提供更强的计算能力,降低时间成本,提高模型的性能,提高请求节点的效用;但是,由于参与节点的计算成本随着训练的总CPU 周期数增加而上升,隐私参与节点的收入并没有随着总CPU 周期数的增加出现明显增长。
单位时间奖励和单位时间CPU 周期数均随着总CPU 周期数的增加而增加,这是因为如果总CPU 周期数增加,就需要更多的奖励激励参与节点投入更多的计算资源到训练过程。
为了研究单位时间奖励pk对于单位时间CPU 周期数qk的影响,以探究请求节点的决策是如何影响参与节点的决策,设置μk=10,并且令pk∈[0.2,10.0],仿真结果如图7所示。
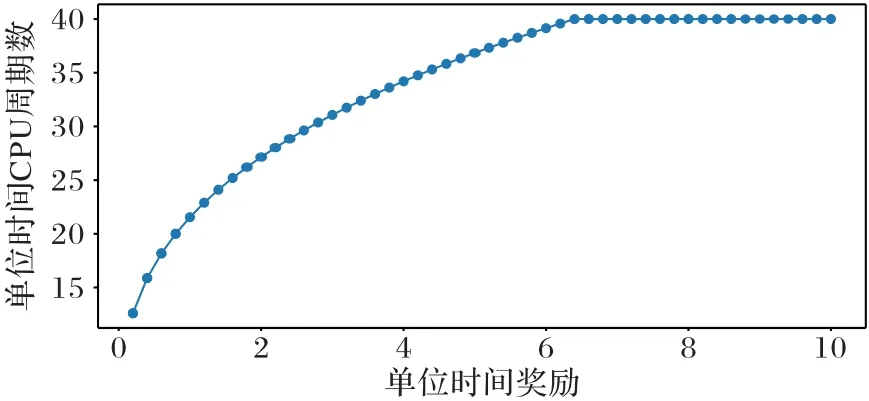
图7 单位时间CPU周期数随单位时间奖励变化Fig.7 CPU cycles per unit time varying with reward per unit time
从图7 可以看出,由于更多的单位时间训练奖励会激励参与节点将更多的计算资源用于模型训练,因此,单位时间CPU 周期数与单位时间奖励呈正相关的趋势。
综上所述,实验验证了激励机制的正确性。
4.2 算法性能
本文分析第2.2 节提出的基于GAN 的联邦学习贡献度评估算法性能,联邦学习参与节点的数据量越大、数据质量越高,对联邦学习过程的贡献度越高。本文使用CIFAR10 数据集[24]进行实验,CIFAR10 共有60 000 张32×32 的彩色图像,分为10 类,其中训练集为50 000 张图片,测试集为10 000张图片。本文共设置60 个参与节点,并从60 个参与节点中分别随机采样5 条数据,总计300 条采样数据,本地训练5轮,联合训练20 轮,相关参数设置为μ=0.5,α=1,β=1。本文面向图像生成任务,使用基于深度卷积GAN 实现本文算法;同时,由于联邦学习常应用于边缘计算,任务相对简单,且对计算复杂度要求高,因此本文仅使用4 层卷积构成的轻量GAN 结构。本文算法涉及的GAN 结构如图8 所示。

图8 GAN结构Fig.8 Structure of GAN
下面介绍测试基于GAN 的联邦学习贡献度评估算法在不同数据量、不同数据质量、不同数据分布场景下的贡献度评估准确度结果,并选择使用节点行为驱动型的文献[22]、使用模型驱动型贡献度评估方法的文献[12]和文献[25]、使用数据驱动型贡献度评估方法的文献[13]和文献[26]进行对比。其中:文献[22]方案依据参与节点的本地数据量和损失计算贡献度,要求参与节点诚实地提交本地数据集大小和损失;文献[12]方案依据参与节点的模型相似度计算贡献度;文献[25]方案依据参与节点梯度欧氏距离的L2 范数计算贡献度;文献[13]方案依据参与节点模型的Shapley 值计算贡献度;文献[26]方案依据参与节点中选拔出的委员会节点的数据集计算参与节点的贡献度,由于涉及委员会节点评估其他参与节点贡献度,不诚实的委员会节点将带来安全隐患。
贡献度评估准确度以不同分组参与节点的贡献度平均值和标准差作为指标,计算过程如下:1)对参与节点的贡献度作min-max 归一化后乘系数100;2)分别计算每个组别下参与节点贡献度的平均值的标准差。不同分组之间的贡献度平均值差异越大,标准差越小,说明不同分组参与节点之间的差异越大,区分和筛选越容易。
1)数据量。
本文将60 个参与节点分为3 组:第一组参与节点A1 分配5 000 条数据,第二组参与节点A2 分配500 条数据,第三组参与节点A3 分配50 条数据。不同数据量组别之间的贡献度平均值差异越大,标准差越小,说明对不同数据量的参与节点贡献度评估准确度越高。
使用本文方案与文献[12-13,22,25-26]方案评估的不同数据量参与节点的贡献度统计值比较如表1 所示。

表1 几种方案在不同数据量参与节点时的贡献度统计值Tab.1 Comparison of contribution statistics under several scenarios of participate nodes with different data volumes
从表1 可以看出,文献[22]方案对大数据量(A1)参与节点的贡献度评估效果较优,但对小数据(A2)和极小数据量(A3)参与节点的贡献度评估效果较差;文献[12]方案对极小数据量(A3)参与节点的贡献度评估效果较优,但对大数据量(A1)和小数据(A2)参与节点的贡献度评估效果较差;文献[25]方案难以评估不同数据量参与节点贡献度;文献[13]方案评估各个参与节点集合的贡献度方差较大,平均值区分不明显,精度较低;文献[26]方案对不同数据量参与节点的贡献度评估在平均值区分度和标准差方面表现最优。本文方案在平均值区分度和标准差方面表现次优,仅逊色于文献[26]方案,对不同数量的参与节点贡献度评估基本与参与节点的数据量大小一致。
2)数据质量。
本文将60 个参与节点分为3 组:第一组参与节点B1 分配1 000 条数据:第二组参与节点B2 分配1 000 条添加30%随机噪声的数据,第三组参与节点B3 分配1 000 条添加50%随机噪声的数据。不同数据质量组别之间的贡献度平均值差异越大,标准差越小,说明对不同数据质量的参与节点贡献度评估准确度越高。
使用本文方案与文献[12-13,22,25-26]方案评估的不同数据质量参与节点的贡献度统计值比较如表2 所示。
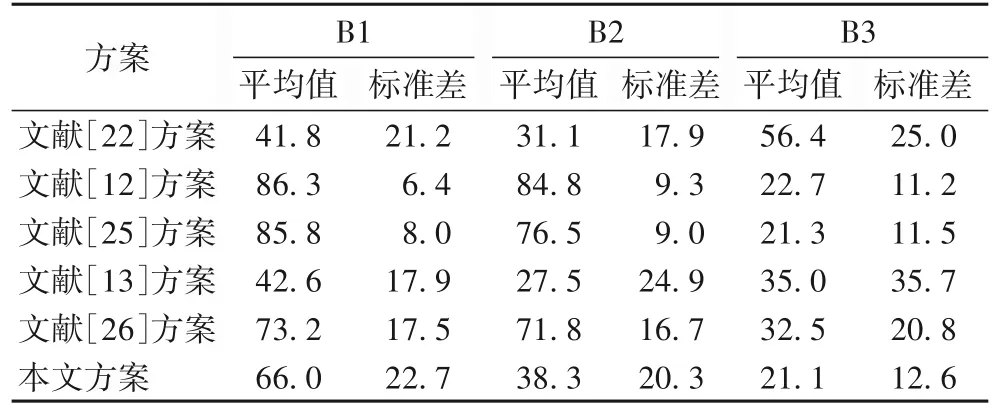
表2 几种方案在不同数据质量参与节点时的贡献度统计值Tab.2 Comparison of contribution statistics under several scenarios of participate nodes with different data qualities
从表2 可以看出,文献[13,22]方案难以评估不同数据质量参与节点贡献度;文献[12,25-26]方案对有极大噪声数据质量(B3)参与节点的贡献度评估效果较优,但对无噪声数据量(B1)和有少量噪声数据(B2)参与节点的贡献度评估效果较差;本文方案在平均值区分度方面表现最优,标准差方面表现较优,对拥有不同数据质量的参与节点贡献度评估基本与参与节点的数据质量一致。
3)数据分布。
本文将60 个参与节点分为3 组:第一组参与节点C1 分配1 000 条独立同分布数据,第二组参与节点C2 分配1 000 条仅有50%数据标签的数据,第三组参与节点C3 分配1 000 条仅有20%数据标签的数据。由于数据量相近,数据质量相近,不同数据分布组别之间的贡献度平均值差异越小,标准差越小,说明对不同数据分布的参与节点贡献度评估准确度越高。
使用本文算法与文献[12-13,22,25-26]方案评估的不同数据分布参与节点的贡献度统计值比较如表3 所示。

表3 几种方案在不同数据分布参与节点时的贡献度统计值Tab.3 Comparison of contribution statistics under several scenarios of participate nodes with different data distributions
从表3 可以看出,文献[22,25]方案对于不同数据分布的参与节点贡献度评估效果较差,对于拥有相似数据质量和数据量的参与节点,其贡献度评估结果应相近;文献[12,26]方案难以评估不同数据分布参与节点贡献度,拥有独立同分布数据的参与节点贡献量(C1)显著优于拥有非独立同分布数据的参与节点(C3);文献[13]方案能够评估不同数据分布的参与节点贡献度,但是,具有独立同分布特征(C1)由于其分布面广、非独立同分布程度较深(C3)的数据由于单一类别拥有的数据量更多,应获得更高的贡献度评估,文献[13]方案的评估结果与直观不符;本文方案能评估不同数据分布的参与节点贡献度,且评估效果与直观相符,即具有独立同分布特征(C1)和非独立同分布程度较深(C3)的数据应获得更高的贡献度评估,对拥有不同数据分布的参与节点贡献度评估基本与参与节点的数据标签分布一致。
4.3 算法分析
下面将从采样数据量、参与节点数据标签分布和GANT算法3 个方面分析基于生成式对抗网络的联邦学习贡献度评估算法。
1)采样数据量。
为了测试采集数据量对贡献度评估的影响,本文以不同数据量的参与节点的贡献度评估实验为例,测试采集数据分别120 条和600 条时对不同数据量的参与节点贡献度的影响。使用本文算法在不同样本量下评估的贡献度统计值比较如表4 所示。

表4 不同样本量下参与节点贡献度统计值Tab.4 Comparison of contribution statistics of participant nodes with different sample volumes
从表4 可以看出,当采集数据量为120 时,虽然仍然能区分不同数据量的参与节点,但同样数据量的参与节点之间的平均值差距减小,同时在实验过程中发现部分类的测试数据量小于10 的情况,测试数据量的不均衡将直接导致贡献度评估准确度的下降;当采集数据量为600 条时,不同数据量的参与节点的贡献度评估的平均值和标准差均与采集数据量为300 时相差不大,但采集数据量的增大意味着参与节点需要承担更多的隐私泄露风险。
2)参与节点数据标签分布。
为了测试参与节点数据标签分布的影响,本文以不同数据分布的参与节点的贡献度评估实验为例,测试有无参与节点数据标签分布对不同数据分布的参与节点贡献度的影响。使用本文算法在有无参与节点数据标签分布下评估的贡献度统计值比较如表5 所示。
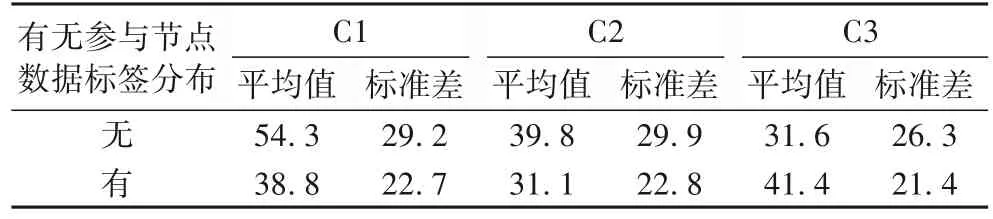
表5 有无参与节点数据标签分布下参与节点贡献度统计值Tab.5 Comparison of contribution statistics of participant nodes with or without data label distribution
从表5 可以看出,当不引入参与节点数据标签分布时,对于不同数据分布的参与节点贡献评估精度出现显著降低,一方面标准差增大,另一方面无法评估出非独立同分布数据标签节点的贡献度。
3)GANT 算法。
为了测试GANT 算法对贡献度评估的影响,本文以不同数据质量的参与节点的贡献度评估实验为例,测试不使用样本生成算法、使用GAN 算法和使用GANT 算法对不同数据量的参与节点贡献度的影响。使用本文方案在不同样本生成算法下评估的贡献度统计值比较如表6 所示。

表6 不同样本生成下参与节点贡献度统计值Tab.6 Comparison of node contribution statistics under different sample generation algorithms
从表6 可以看出,当删除样本生成算法后,由于采样样本中很可能存在噪声较大的数据样本,从而导致算法难以区分数据质量较高的参与节点(B1)和含有一定噪声数据的参与节点(B2);当将样本生成算法替换为传统GAN 算法后,由于生成样本的质量不高,且未经联合模型筛选,因此平均值的区分度明显不如GANT,且在低质量参与节点(B3)和含有一定噪声数据的参与节点(B2)的标准差也显著高于GANT。
5 结语
本文结合GAN、博弈论等技术,提出一个联邦学习激励机制解决方案。该方案提出基于GANT 的贡献度评估算法,实现高精度的样本生成和对不同数据量、不同数据质量和不同数据分布的参与节点联邦学习贡献度评估。该方案实现基于两阶段Stackelberg 博弈的联邦学习激励机制,实现对联邦学习过程公平、合理、有效的激励。为了实现更加安全、可追溯的联邦学习激励机制,下一步将研究在联邦学习激励机制中引入区块链技术,并将本方案涉及的分类模型场景扩展到回归模型场景。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
数码设计(2020年16期)2020-12-08
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
石河子大学学报(哲学社会科学版)(2019年3期)2019-07-27
中国生物医学工程学报(2019年4期)2019-07-16
电子技术与软件工程(2016年8期)2016-07-10
中兴通讯技术(2016年2期)2016-03-24
电力自动化设备(2015年4期)2015-09-28
