
实体类别增强的汽车领域嵌套命名实体识别
2024-03-21 02:25黄子麒胡建鹏
计算机应用 2024年2期
黄子麒,胡建鹏
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引言
汽车产业作为智能制造规划中的重要产业,受到工业界智能制造研究的广泛关注,自然语言处理和深度学习技术为其中知识挖掘提供了重要支撑。汽车产业汇聚了工业产品全生命周期设计研发、供应链、生产制造和维修运维等各个环节的数据,具有产业链复杂、业务逻辑多等特点,同时具备工业领域的数据多源、知识表征异构等特征,能作为工业典型数据进行分析,设计适用于汽车领域的通用命名实体识别(Named Entity Recognition,NER)模型是工业数字化转型中的一大挑战。
NER 是信息抽取的任务之一,旨在识别代表某类实体的文本跨度,并给定预先定义的类别,通用领域常用于识别人名、地名和组织名等,是自然语言处理技术关系抽取[1]、问答系统[2]和信息检索[3]等下游应用的关键支撑。现有的研究大多针对通用领域数据,同时在农业[4]、电网[5]等垂直领域也已取得较好的进展。以上领域数据标注歧义少,实体通常结构扁平且构成规则简单,因此实体识别效果较好。而汽车领域复杂的业务场景对实体识别提出了新的要求,实体组成结构复杂、实体标签不一致和样本不平衡等问题使得汽车领域实体抽取结果不理想。整车与零部件产品的从属关系、汽车装配中电气系统和动力系统的上下级关系引入了复杂的语义关系,带来了嵌套实体识别问题。汽车领域NER 的研究近年集中在基于序列的方法[6-7],并未针对嵌套实体识别进行模型设计,挖掘上下文丰富语义信息和解决嵌套实体识别问题对于汽车领域NER 意义重大。
本文围绕汽车故障诊断与维修文本实体抽取数据,提出一种基于跨度的实体类别增强实体抽取模型来完成汽车领域的嵌套命名实体识别任务。本文的主要贡献有:1)设计了领域数据的特征融合方法;2)提出了基于注意力机制的实体类别增强方法,提升了在领域数据嵌套实体和长实体命名实体识别的效果;3)通过多个角度的实验验证了本文模型在汽车领域实体识别的优势。
1 相关工作
在NER 中应用的技术主要有4 种:基于规则的方法、无监督学习方法、基于特征的监督学习方法和基于深度学习的方法[8],随着BERT(Bidirectional Encoder Representation from Transformers)[9]的提出,近年来基于预训练模型的深度学习方法在许多自然语言处理任务上取得了较先进的性能。基于深度学习的嵌套NER 的常用方法按模型结构主要分为基于超图的方法、基于序列的方法和基于跨度的方法。
基于超图的方法利用超图结构有效保存对象之间的多元关联关系,能较好地解决嵌套命名实体标签网络中一条边包含多节点的问题。Lu 等[10]使用超图建模实体节点跨度,进而抽取嵌套实体;Katiyar 等[11]针对识别嵌套命名实体提出一种基于BILOU 标记方案的超图表示方法,并通过双向长短时记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)网络对超图的边概率进行建模,进一步改进了超图的表示。但在设计超图结构时需要大量人力,不同领域数据结构不一样导致通用领域模型较难设计,同时复杂的结构增加了解码的难度,且超图无法对嵌套实体之间的依赖进行编码,丢失了细粒度信息。
基于序列的方法采用序列模型输出扁平化的命名实体,条件随机场(Conditional Random Field,CRF)作为一种无向图模型常作为NER 任务的解码模块。例如BERT-BiLSTMCRF[12]模型,近期为处理嵌套实体的问题,序列模型的结构被重新设计。Ju 等[13]提出了一种动态堆叠平面NER 层的Layered-BiLSTM-CRF 模型,由内层到外层逐层识别实体。新的标签策略解决了传统序列标注模型无法识别嵌套实体的问题,但受限于模型本身,序列标注模型无法并行训练,枚举、堆叠所有可能的标签类型导致标签分布稀疏、模型较难训练和解码耗时过长等问题。
基于跨度的方法将实体识别定义为实体跨度分类问题,由于划分跨度包含所有潜在实体,因此可以解码并识别嵌套实体,由于领域实体存在较多长实体,基于跨度的方法识别工业长实体也具备一定优势。近期,基于跨度的方法受到广泛研究,Sohrab 等[14]、Zhong 等[15]提出的PURE(Princeton University Relation Extraction)模型、Eberts 等[16]提出的SpERT(Span-based Entity and Relation Transformer)模型通过在文本中枚举有限长度内的所有跨度,通过分类器得到所有候选跨度的实体类别标签,验证了不同预训练模型、不同级别的跨度表征方法对于实体识别的影响。以上基于跨度的命名实体识别方法主要存在以下问题:1)枚举限定长度的跨度会引入大量低质量跨度,计算成本高,限定跨度长度对长实体识别效果较差;2)简单利用字符向量表征跨度忽略跨度边界信息,无法准确定位实体边界,以上方法均未引入实体类别的先验知识;3)未针对数据集普遍存在的嵌套实体问题进行设计,内部嵌套实体在外部实体中的起始位置会影响跨度表征,影响实体识别准确率。针对以上问题,本文提出基于跨度与实体类别增强的嵌套命名实体识别方法。
2 方法概要
针对通用模型在领域数据中存在的嵌套实体识别和长实体识别效果不佳的问题,本文提出融合语法信息、实体类别特征增强(Entity Category Enhanced NER,ECE-NER)模型,融入领域知识对汽车领域文本进行NER。方法概要如图1 所示。核心模块主要分为:
1)数据预处理和标注。主要清洗收集的汽车领域数据,定义实体类型,制定嵌套实体标注规则完成数据标注。
2)模型。主要包括:
a)特征融合编码层。利用BERT 预训练模型以及构造好的词性特征、偏旁特征进行特征融合编码。
b)尾词识别器。利用多层感知机(Multi-Layer Perceptron,MLP)得到句子尾词概率,从而得到实体尾词索引集合。
c)前向边界识别器。由实体类别特征构造和跨度生成与识别两部分组成。其中实体类别特征构造利用先验实体标签知识以及义原分析构造特征,基于自注意力机制得到融合实体类别特征的尾词向量表征;跨度生成与识别基于候选尾词生成候选跨度,跨度经过双仿射编码得到特定尾词的首词概率,从而确定特定尾词和实体类型的实体跨度。
本文模型将实体识别任务拆解成两个优化目标,分别是实体尾词损失和前向边界识别损失。
3 核心模块和关键算法
3.1 数据预处理及标注
汽车领域目前尚未有较高质量的公开数据集,汽车故障诊断与维修是我国汽车产业中重要部分。随着信息技术和业务规模不断发展,企业累积了海量的业务数据,同时业务数据复杂,可用于工业领域知识抽取的研究。本文从大型汽车企业收集到实际生产过程中记录的汽车故障诊断文本语料数据,共3 547 段汽车生产线故障诊断的文字描述,每段文字包含了问题描述、操作步骤和解决方案等丰富的场景信息。为了保障语料质量,消除句子中与该领域实体识别无关的文本,针对语料进行预处理操作,删除了标号、空格等无用的文本内容,同时规范化文本,补充了记录时省略的部件名称等信息。预处理后的原始数据未标注,没有定义实体类型,不能直接用于模型训练。为了使实体类别以及模型适用于汽车领域其他文本,本文结合专家经验定义实体,有6 类实体:设备单元、设备功能、检修动作、检修工具、失效模式和设备属性,具体实例与实体数量如表1 所示。
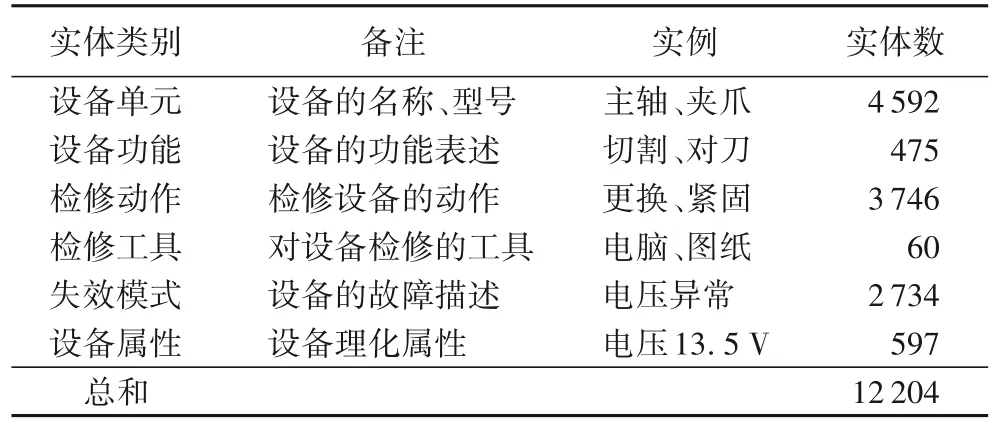
表1 汽车故障文本实体定义Tab.1 Text entity definition of automobile fault
根据命名实体中是否包含其他实体,将命名实体分为简单结构实体和嵌套命名实体:简单结构实体指内部不包含其他实体,例如“电机”表示一个部件单元实体;嵌套命名实体指一个实体内部嵌套一个或多个命名实体,在汽车领域通常由于设备单元的层级关系、失效模式带有性能描述及设备、属性描述等引入嵌套实体,其中问题描述、解决方案等实际场景描述存在大量嵌套实体,例如“伺服电机控制回路”中“伺服电机”作为设备单元,“伺服电机控制回路”也是一个设备单元,“气体压力降至告警值”为失效模式,“气体压力”为性能表征。
参考文献[17]并结合汽车故障诊断语料的数据获取场景,制定如下标注规则以及标注细节:
1)标注的专有名词是具体的、特定的,而不是抽象的、泛指的,并且标注的实体需要符合实际应用场景,例如“线”“液体”“检查”“装置”“机器”等不视为标注的实体概念。
2)汽车领域复合专有名词的嵌套标注:部件单元实体中常存在上下级关系,检修过程中需要尽可能详细描述部件单元的层级关系,需要标注嵌套实体。例如部件单元实体“节气门位置传感器”中“位置传感器”是“气节门”的组成部件,因此“气节门”也需要标注成部件单元。
3)标注的粒度和实体完整性:a)嵌套层数最多3 层;b)含有字母、数字等特殊字符的实体应与其他设备、单位共同标注,例如“电动机C80A”整体标注为“设备单元”且不再拆分成嵌套实体“电动机”标注;c)同一句子出现别名和简称时,只要在句子中标出完整实体,例如句子“检查主刀控制开关损坏,更换开关后正常”中,只需标注“主刀控制开关”为部件单元实体,其中的“开关”不需标注。
4)部分嵌套实体标注会出现共用描述的现象,例如实体“开关和夹爪故障”中,“夹爪故障”失效模式实体不单独标注,标注其中最长的“开关和夹爪故障”作为本句中的真实实体标签,实体“清理和紧固夹爪”中,“清理和紧固”作为检修动作,“清理”和“紧固”不单独做标注。
3.2 特征融合编码
命名实体识别任务基于跨度的方法[15]通常选取词语的起始和终止位置的字符分布式表示BERT 词向量作为下游跨度分类任务的输入,在嵌套命名实体中,多级嵌套实体的子实体存在共用终止位置词向量的现象,例如“空调压缩机”和“压缩机”的终止位置特征向量均为“机”这个词的特征编码,训练时会造成实体边界的混淆,加入分词特征可以指示出该类实体的边界信息。领域实体同时还存在典型的偏旁特征,例如“线”“阀”“轮”等字常出现在部件单元实体中,具备“纟”“门”“车”等部首;同时该类部首通常出现在部件单元实体的词尾,将偏旁部首融入字词编码可使得模型更专注于学习领域常见的组合词语边界。本文加入分词特征以及部首特征以提示模型学习更多的实体边界信息,同时学习嵌套实体的词法组合信息,例如典型的词缀等信息。
本节主要介绍预训练模型编码、词性特征编码和偏旁部首编码,通过拼接操作得到融合上下文特征和实体边界信息的字符表征向量。
3.2.1 预训练模型编码
预训练模型构建的字符分布式表示具备丰富的语义特征[18],被广泛用作下游任务的模型输入。传统word2vec[19]、GloVe(Global Vectors for word representation)[20]等预训练模型为词语的静态分布式表示,未考虑词语的相对位置信息,BERT 模型[9]利用Transformer 的编码器结构,通过注意力机制捕获每个字符对上下文的全局依赖,学习文本级别的语义信息,近期在多项任务中取得最好的效果,BERT-wwm 模型[21]基于BERT 进行改进,采用全词掩蔽的任务,使模型通过覆盖整个词学习更强的语义表示能力,本文选用BERTwwm 模型作为句子的编码(后文用BERT 指代BERT-wwm)。
给定模型的输入为句子的字符序列C={c1,c2,…,cn},其中ci表示字符序列C中的第i个字符,n是句子的字符序列长度。对句子的字符序列进行编码得到第i个字符对应的词向量表征,其中b为BERT 词向量隐藏层维数,如式(1)所示:
3.2.2 词性与偏旁特征编码
特征融合编码层采用如下方式得到字符序列表征:对于词性编码,首先利用LTP(Language Technology Platform)[22]分词工具对原始句子分词,对分词结果构建词性标签,每个字符的词性标签由词性和“BI”组成,即词性+“B/I”,其中该词的起始位置用“B”标识,起始位置以外位置用“I”标识,例如“机械臂”三字的词性标签分别为“n-B”“n-I”“n-I”,对所有词性标签设置随机种子生成词性的向量表示,句子中第i个字符的词性标签向量表征通过查找词性向量表而获得,p为单个词性标签的向量表征维数。
对于部首特征,先查找所有字符对应的部首,对所有部首标签设置随机种子生成部首的向量表示,句子中第i个字符的部首标签向量表征通过查找部首向量表而获得,r为单个部首标签的向量表征维数。
3.2.3 融合编码
为捕获部首标签以及词性标签之间的依赖关系,对BERT 词向量、偏旁部首特征向量和词性特征向量这3 种特征向量进行拼接操作,并使用双向长短期记忆(Bi-directional Long-Short Term Memory,Bi-LSTM)网络对拼接后的特征向量进行编码,其中“[;]”表示在最后一维进行拼接,最后拼接得到第i个字符向量表征hi,以上过程如式(2)~(4)所示:
其中:embed 表示通过查表得到相应的特征向量,由特征融合得到句子序列中每个字符的表征hi。
3.3 尾词识别
经统计分析,汽车领域部件单元实体在语料中出现频率高,且大量部件单元实体可由特定的词缀衍生,例如词缀“灯、管、泵、盒、阀、表、轴、门、机、膜、器、杆、炉、仪、罐、板、缸、刀、闸、柜、垫、柜”等,实体尾词的识别对后续完整实体的边界跨度识别有重要意义,本节介绍对领域实体尾词进行识别的尾词识别器结构。
对3.2 节得到的特征编码集合H,尾部识别器的输入集合由如下公式得到:
对应字符的尾词概率计算如式(6)所示:
式中:k为预设参数,表示距第i个字符的跨度距离;hi-k:i+k表示以第i个字符为中心各选前后k个距离为字符边界的所有字符表征集合;CNN 表示卷积运算,运算算子为最大池化,[;]为向量拼接操作,MLP 层数参照文献[15]中的设定,由两层线性层和GELU(Gaussian Error Linear Unit)激活函数构建,Sigmoid 为归一化函数,用于将字符为尾词的概率归一化为0 到1,最后概率大于设定阈值α时纳入候选尾词集合中,其中m为尾词概率大于阈值的尾词数量为候选尾词在句中索引为i时的向量表征,即对应的尾词表征。
尾词识别器的损失函数为二元交叉熵损失(Binary Cross Entropy Loss,BCELoss)函数,如式(7)所示:
3.4 前向边界识别
前向边界识别模块首先对预定义的实体类别进行特征构建;再基于尾词识别模块得到的候选尾词集合构建融合自注意力机制的尾词表征并生成前向边界,得到跨度候选集合;最后利用双仿射编码器得到特定实体标签下的跨度分数,确定特定跨度的实体类别。
3.4.1 实体类别特征构建
在领域命名实体抽取任务中,待抽取实体的标签定义通常符合应用场景的需要,具有丰富的专家经验知识,因此根据已定义的实体类型进行语义挖掘可以提供模型先验知识,同时实体类别对模型训练的有效性在Li等[23]的工作中得以证明。
先对每一个实体类别构造相应的实体类别特征,特征的组成由实体类别中的关键词以及与该实体类别的同义概念组成。实体类别的关键词与同义概念由领域专业词典以及OpenHowNet[24]提供API 获得,具体特征向量的构建方法如下所述:“设备单元”实体的关键词为“设备”,由专业词典以及义原概念检索再经过人工选择得到同义概念“器具”“装备”“器械”“器材”等,最后将关键词和同义概念进行词向量拼接得到拼接向量其中词向量由Chinese-BERTwwm 得到,type 表示实体类别标签,若实体类别数为e,则构造e个实体类别特征构造表征,|type∗|表示实体标签类型的字符数,ttjype表示特定实体类型下特征构造器中的第j个字符向量,经过双向长短时记忆网络编码,得到实体类别特征构造器的原始输入:
最后利用自注意力机制计算注意力权重,得到句子中特定实体类别特征构造器的自注意力表征具体计算如下所示:
3.4.2 跨度生成与识别
跨度生成与识别基于标签信息和尾词表征作先验知识,查找特定范围内的实体首词是否能够和尾词组成特定实体类型的实体,其中查找范围由超参数max_span_size指定,相应得到尾词的跨度种子集合如式(10)所示:
实体第j个跨度的首字表征由尾词表征计算公式得到,基于自注意力机制的尾词表征由式(11)得到:
首词评分含义为在特定实体标签以及尾词下,该首词能和尾词组成特定实体类别的实体跨度的概率,利用ReLU(Rectified Linear Unit)激活函数处理评分,使模型训练时更快收敛,最后利用softmax 函数得到特定实体类别和尾词下该跨度的标签概率,计算如式(13)所示:
训练过程中,如式(14)所示通过最小化负对数似然概率来训练模型。
其中S表示枚举的跨度集合。前向边界识别器损失函数采用交叉熵损失函数,如式(16)所示。
3.4.3 优化目标
模型优化目标为尾词损失和前向边界损失两部分构成,如式(15)所示:
其中:γ为超参数,用于控制尾词损失和跨度损失的占比,设置为0.5表示两者损失占相同权重。
预测时首词分数ye(si)大于0.5 时作为预测结果,与尾词组成特定实体类型的实体跨度,如式(16)所示:
其中α为超参数分数阈值,达到分数时进行跨度输出,默认值为0.5。
4 实验与结果分析
4.1 实验数据及设置
本文选择汽车工业故障模式抽取评测公开数据集CCL2022(The 21st China National Conference on Computational Linguistics)、人工构建的具有嵌套实体的某企业汽车生产线故障数据集(Fault Data of Automobile Production Line,FDoAPL)、具有嵌套实体的中文医学文本命名实体识别数据集 CHIP2020(China conference on Health Information Processing)作为实验对象。汽车评测数据来源于CCL2022汽车工业故障模式抽取评测,数据定义了部件单元、性能表征、故障状态三类实体,共3 000 条数据。某企业汽车生产线故障数据集FDoAPL 为搜集到的实际场景记录的汽车生产故障诊断数据,将段落内容分割成句子作为训练语料,共6类实体,3 179 条数据。为了增加领域公开嵌套实体数据集,引入中文医学文本命名实体识别数据集CHIP2020,它来源于CHIP2020 中文医学文本命名实体识别评测一数据集,数据定义了bod、dis、sym、mic、pro、ite、dep、dru、equ 共9 类实体,共20 000 条数据。以上数据集划分成训练集、开发集和测试集的比例均为8∶1∶1,划分句子结果如表2 所示。
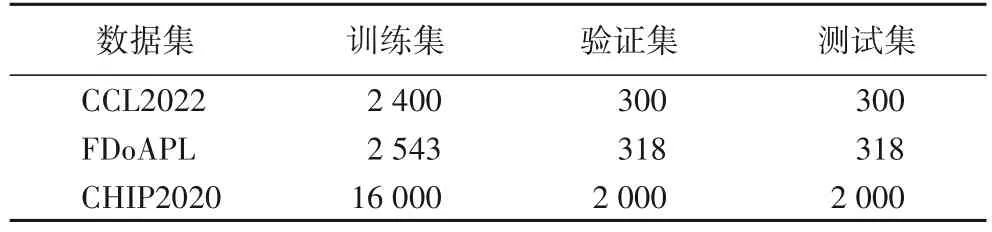
表2 数据集句子划分Tab.2 Dataset sentence division
4.2 实验环境与参数设置
本文实验使用显卡型号为NVIDIA 3080Ti,编程语言为Python3.8,深度学习框架为Pytorch1.10.2。各数据集使用的预训练模型为Chinese-BERT-wwm-ext,隐藏层维数为768,特征编码部分词性标注来自第三方工具LTP,词性嵌入和偏旁部首嵌入通过随机初始化获得,维数均为50。模型主要参数如表3 所示,可根据句子长度调整从而降低枚举跨度数,tail threshold 为尾词识别器的阈值。
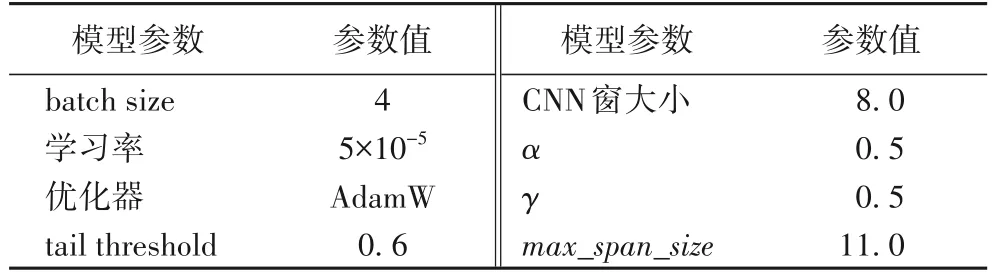
表3 本文模型参数Tab.3 Parameters of proposed model
本文采用实体识别的准确率(Precision,P)、召回率(Recall,R)和两者的调和平均值F1 值作为评价指标来评估模型的性能,当实体类别和实体边界均正确时认定该实体识别正确。准确率、召回率和F1 值计算公式分别为:
其中:TP为正确预测出的实体数,FP为预测的实体是非正确实体的数,FN为未预测出的实际标注实体数。
所对比的基线模型有序列标注模型BERT-BiLSTMCRF、基于跨度的PURE、SpERT 模型,其中PURE、SpERT 采用原始代码默认参数,其中batch size 为4,BERT-BiLSTMCRF 模型参数学习率为3×10-6,batch size 为28,隐藏层维度为256,warmup 为0.1,使用BERT-BiLSTM-CRF 模型时去除嵌套实体进行实验。将本文模型分别在数据集CCL2022、FDoAPL 上实验,并与基线模型进行比较,以验证本文模型在汽车领域实体识别中的有效性。
4.3 实验结果分析
4.3.1 整体结果
如表4 所示,本节通过复现模型的方法得到汽车领域数据集在相应模型的验证集结果。
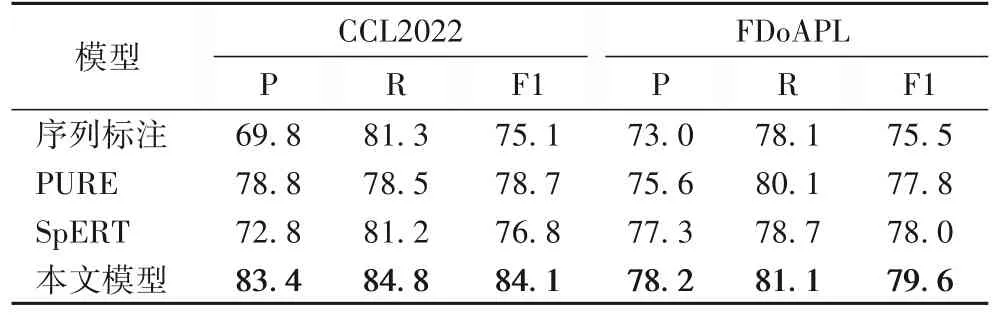
表4 汽车领域实体识别结果 单位:%Tab.4 Entity recognition results for automotive domain unit:%
本文模型在两个数据集结果都优于序列标注基线模型、基于跨度的实体抽取模型,在CCL2022、FDoAPL 数据集中,F1 值相较序列标注、PURE、SpERT 模型分别提高了9.0、5.4、7.3 个百分点和4.1、1.8、1.6 个百分点,R 分别较基线模型序列标注模型、PURE 模型和SpERT 模型分别提升3.5、6.3、3.6个百分点和3.0、1.0、2.4 个百分点。序列标注BERTBiLSTM-CRF 模型R 与其他模型相比,差异较小,P 较低的原因为难以识别完整长实体的序列标签。SpERT模型通过改进字符编码表示,利用池化窗丰富了字符的上下文语义表征,在R 上相较于其他模型有一定提升。本文模型在SpERT 编码基础上增加了词性和偏旁特征,同时利用实体类别标签特征作为引导,达到了更高的R和F1值。
4.3.2 嵌套实体识别结果分析
为验证模型在嵌套实体识别效果,在CHIP2020 数据集进行对比实验,统计FDoAPL、CHIP2020 数据集嵌套实体所占比例如表5 所示。
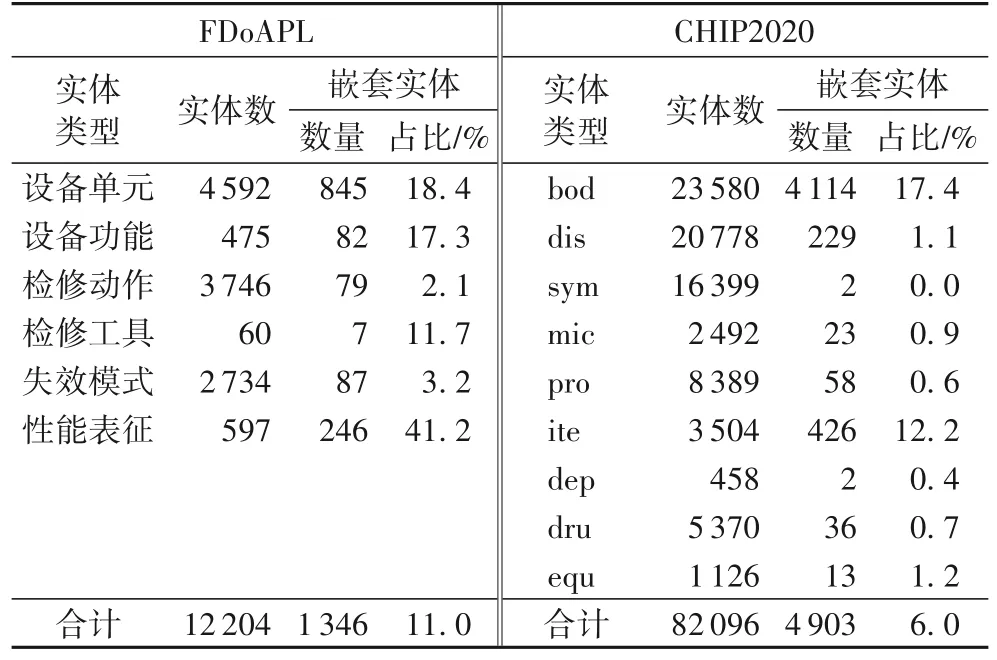
表5 嵌套实体比例统计Tab.5 Proportion statistics of nested entities
FDoAPL 中设备单元和性能表征包含嵌套实体总数82%的嵌套实体,CHIP2020 中bod 和ite 嵌套实体占总嵌套实体数的92.6%,对该类嵌套实体的识别准确率对于整体嵌套实体识别效果有重要影响。
模型对于嵌套实体识别结果如表6 所示,分析可见,PURE、SpERT 模型对于嵌套实体识别能力较差,在FDoAPL数据集中F1 值分别为35.6%、40.6%,在嵌套实体数多的CHIP2020 数据集中分别为19.1%、31.5%,训练集中过多长实体标签使得模型更注重识别完整长实体,同时由于数据中实体类别分布不均引入的长尾问题,使模型更注重学习识别某类长实体,而对其中嵌入的短实体识别不准确,对长实体中的嵌套实体边界识别不准。传统的基于跨度的方法基于跨度的首字符和尾字符构造跨度表征再进行分类,未注重学习短嵌套实体的边界信息,本文模型加入词性和偏旁特征,引入各类实体的边界信息,同时CNN 操作更好地聚合字符的邻域特征,对每个实体类别都构建特征构造器,解决了数据分布不均导致模型侧重学习训练样本多的实体特征的问题,在两数据集中嵌套实体F1 值相较PURE 和SpERT 模型分别提高了13.3、8.3 个百分点和21.7、9.3 个百分点。

表6 嵌套实体识别结果 单位:%Tab.6 Nested entity recognition results unit:%
4.3.3 不同实体长度实体识别结果分析
将实体长度分为三组分析F1 分数,结果如表7 所示,长度L为实体字符数。PURE 模型、SpERT 模型以及本文模型对于短实体识别效果差异不大,当实体长度L大于10 时,PURE 模型、SpERT 模型两者F1 值均出现明显下降,尤其是PURE 模型,在3 个数据集中分别仅有30.4%、30.8%、17.6%的F1 值。PURE 模型超参数最大跨度长度设置过大会导致模型训练计算量大幅增加,设置过小导致长实体识别F1 值明显下降。结果显示本文模型在3 个数据集中长实体识别效果比PURE 模型和SpERT 模型均有超过5 个百分点的提高。
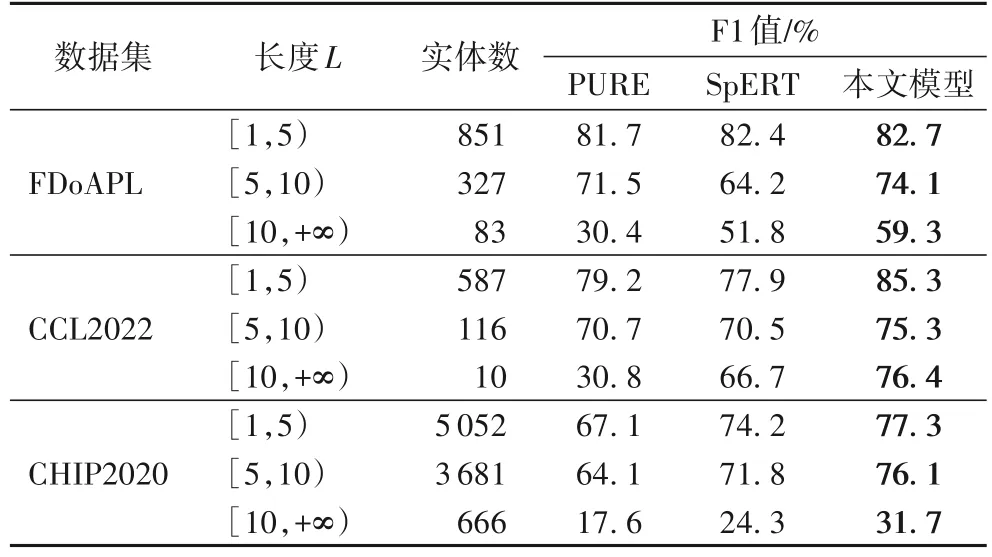
表7 3个数据集中不同模型不同实体长度的F1值对比Tab.7 Comparison of F1 values for different models with different entity lengths in 3 datasets
4.3.4 超参数对模型的影响
1)候选跨度长度。
max_span_size指已知尾词和实体类型,识别跨度首词构造种子跨度所允许的最大候选跨度长度。在本次任务所给定的数据集中所统计的最大跨度长度为17,即得到最大跨度长度的候选首词对模型进行训练与预测。在实验中,随着最大跨度长度的增加,实体的召回率有明显提高,部分较长的实体被正确预测,但整体F1 值略微降低,实验对比结果如图2 所示。分析结果下降的原因为:长度较大的实体为长尾实体,训练不充分使得长尾实体的预测准确率不高,并且对长跨度负例实体的训练引入噪声信息,对整体准确度带来了影响;同时过短的跨度长度使较多长实体正例无法训练,导致F1 值降低。当最大跨度选为11 时得到最高F1 值。

图2 FDoAPL数据集候选跨度变化结果Fig.2 Results of candidate span change for FDoAPL dataset
2)尾词阈值设置。
对于尾词识别器识别实体尾词的分数阈值决定最终候选跨度的数:过多的候选尾词引入会导致最终识别出较多的实体跨度,增加最终实体分类器的识别压力,增加了推理时间;过少的候选尾词会筛除真实的尾词,进而导致误差的传播以及无法识别正确的候选实体,因此选取合适的尾词阈值分数极为重要。分析尾词分数阈值对于最后结果的影响如图3 所示。阈值越高,R 会有所降低,因为候选尾词数减少,P 先提高后降低,在阈值为0.6 时取到最高F1 值。
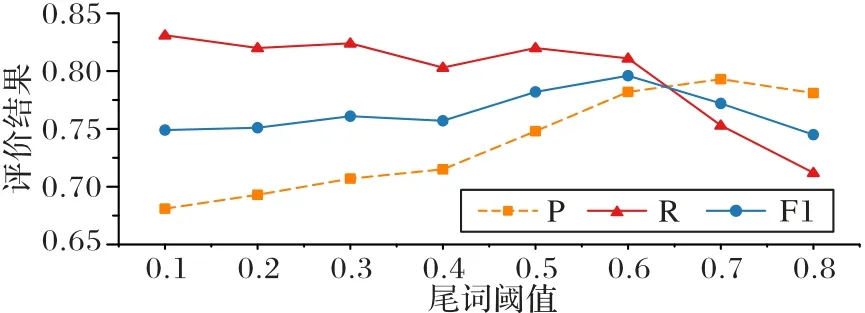
图3 FDoAPL数据集尾词阈值变化结果Fig.3 Results of changes in tail word threshold of FDoAPL dataset
4.3.5 消融实验
为了测试ECE-NER 模型中模块有效性,本文在FDoAPL数据集中做消融实验,分别删除句法特征、实体标签特征构造、字符向量编码CNN 池化操作,得到实验结果如表8 所示。
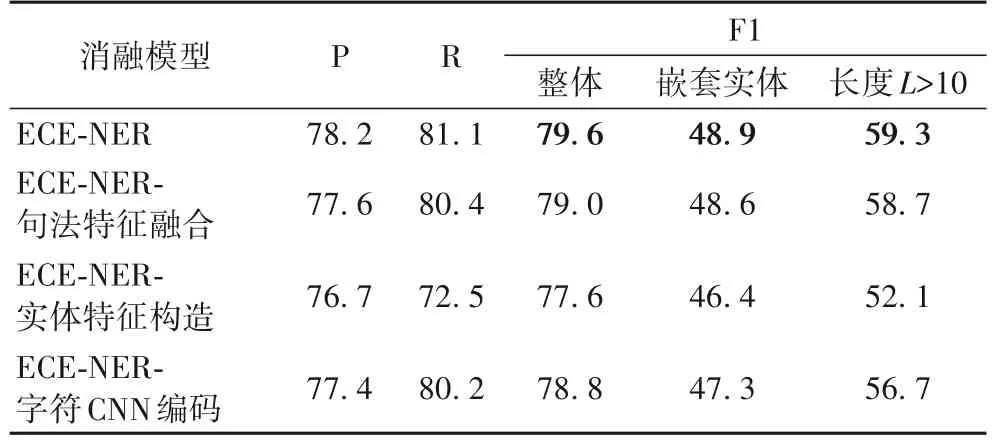
表8 消融实验结果 单位:%Tab.8 Results of ablation experiment unit:%
1)句法特征。在FDoAPL 数据中,词性与偏旁特征可以引入语义以外的句式组合特征与领域特性明显的词缀信息,移除词性特征与偏旁特征后,模型整体F1 值下降了0.6 个百分点,嵌套实体的F1 值下降0.3 个百分点,实体长度大于10的实体F1 值下降0.5 个百分点,验证了引入词性特征与偏旁特征对领域命名实体抽取效果有提升。
2)实体标签特征构造器。为验证引入实体标签先验知识的有效性,消融实验采取的方法为构造与原始实体标签特征向量同维度的|type∗|个随机向量,|type∗|为实体类别数。移除特征构造器后,模型的P、R、F1 值分别下降了1.5、2.6、2 个百分点,嵌套实体的F1 值下降2.5 个百分点,实体长度大于10 的实体F1 值下降7.2 个百分点,引入基于义原的领域实体标签构造器辅助前向边界识别特定实体类型的实体首词,显著提高了领域嵌套实体以及长实体的识别效果。
3)采用CNN 对字符向量进行编码。利用CNN 池化操作对字符向量进行编码可以提取一定范围的邻域信息,能进一步获取文本的语义特征,去除池化窗后模型的F1 值下降了0.8 个百分点,嵌套实体的F1 值下降1.6 个百分点,实体长度大于10 的实体F1 值下降2.6 个百分点,证明了CNN 池化操作聚合邻域信息,提升了字符表征能力,对后续尾词识别器和前向边界识别器识别实体效果有一定提升。
5 结语
针对汽车领域特定文本中存在的嵌套实体识别问题,本文选取了数据量大、应用场景丰富的汽车故障诊断数据作为分析的语料,并结合语料特征针对嵌套实体问题设计了标注规则,最后提出一种基于跨度和实体类别增强的嵌套命名实体识别方法,在汽车故障诊断数据集上取得了较好的效果,并在公开的医疗领域CHIP2020 和CCL2022 评测数据集中进行补充实验,验证了本方法在垂直领域数据集中的可行性,说明了本方法在嵌套实体命名实体识别任务以及长实体识别中的有效性。但由于模型是先识别尾词再识别特定尾词和实体标签的实体首词,从而得到给定实体标签的实体,因此存在误差传播问题。下一步将分析垂直领域数据的语法信息等领域特征,同时进一步改进融合领域特征的跨度表征,融合两任务的共享参数学习,降低误差传播对模型结果带来的影响。
猜你喜欢
建材发展导向(2022年14期)2022-08-19
系统工程学报(2021年4期)2021-12-21
西部交通科技(2021年9期)2021-01-11
中国外汇(2019年18期)2019-11-25
上海建材(2018年4期)2018-11-13
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
计算机工程(2014年6期)2014-02-28
河南科技(2014年24期)2014-02-27
