
基于改进分层注意网络和TextCNN联合建模的暴力犯罪分级算法
2024-03-21 02:25张家伟高冠东宋胜尊
计算机应用 2024年2期
张家伟,高冠东,肖 珂,宋胜尊
(1.河北农业大学 信息科学与技术学院,河北 保定 071000;2.中央司法警官学院 数据科学与智能矫正技术研究中心,河北 保定 071000;3.中央司法警官学院 信息管理系,河北 保定 071000;4.河北省农业大数据重点实验室(河北农业大学),河北 保定 071000;5.中央司法警官学院 监狱学学院,河北 保定 071000)
0 引言
暴力犯罪严重影响社会安全稳定,运用犯罪心理学内容进行暴力犯罪服刑人员矫治的关键性认知任务在于分级、治疗和解释[1]。分级作为首位尤为重要,划分是否科学合理将直接影响服刑人员处遇的效用价值;同时也能为监管部门合理制定矫正教育方案、评估再犯罪风险提供科学依据,从而促进社会治安的持续稳定。
目前,服刑人员的分级策略主要基于犯罪类型和风险等级。犯罪类型是对服刑人员行为的简化分类,忽视了行为的复杂性和异质性,不能将服刑人员细分为有意义的心理和行为类别。基于风险等级的评估主要通过VRS(Verbal Rating Scale)、OGRS(Offender Group Reconviction Score)和VRAG(Violence Risk Appraisal Guide)等量表,将服刑人员划分为低、中、高再犯罪风险等级,有助于管理监管资源的分配,但无法反映服刑人员犯罪的原因,难以对症矫治[2],因此还应从服刑人员的气质[3]、性格等方面的特征着手,深层次剖析服刑人员的心理和行为内容,分析其犯罪原因,实现多元化分级,以达到对症矫治的目的。
在心理学中,气质是指心理活动中表现出的强度、灵活性和指向性等方面的稳定心理特征,因此将服刑人员分为胆汁质、多血质、粘液质、抑郁质4 种类型[4]。胆汁质服刑人员常因冲动易怒而犯罪,倾向于单独作案;多血质服刑人员常因探索欲望而犯罪,倾向于团伙作案;粘液质服刑人员常因缺乏自我主张而犯罪,倾向于渐进式犯罪;抑郁质服刑人员常因自卑、无助而犯罪,倾向于自杀式犯罪[5]。4 种气质类型服刑人员的心理和行为表现特征各不相同,但都具有冷漠、自私和缺乏同情心等共性,因此通过犯罪行为描述文本信息实现归因分类分级具有较大难度。
传统的犯罪分析工具大多在服刑人员处于理性状态时使用量表对他们进行评估,易受到主观因素干扰,影响了评估结果的准确度[6]。而犯罪事实是服刑人员受到外界刺激,处于非理性状态的外在表现。通过对犯罪事实的分析可以推断出极端情况下服刑人员的归因类型,结合服刑人员基本情况等信息可以进一步提高归因分类的准确性,对服刑人员进行针对性的教育和改造。近年来,人工智能技术的应用,为新一代的犯罪评估工具的发展提供了契机[7]。
因此,可将文本分类方法引入犯罪心理学领域,通过挖掘分析暴力犯罪服刑人员的犯罪事实和服刑人员基本情况,以端到端的方式对他们的气质类型进行分类决策。目前文本分类模型可分为传统机器学习模型和深度学习模型两大类[8]。深度学习具有自动执行特征学习捕获判别信息等优势,已广泛用于各个领域[9-12],并在法律判决预测[13-14]、司法案例智能推荐和暴力倾向分级[15]等司法实践领域任务上取得了不小的进展。其中,TextCNN(Text Convolutional Neural Network)[16]为深度学习中常用的模型之一,由于采用了卷积滤波器,具有突出的局部特征捕捉能力。循环神经网络(Recurrent Neural Network,RNN)[17-18]因为能捕获长程依赖性而被认为是有效的顺序文本数据处理架构。此外,Yang等[19]提出了一种名为HAN(Hierarchy Attention Network)的模型,通过句子和文档两个层次提取特征,提高文本语义信息的获取能力。Baek 等[20]利用TextCNN 构建了一种预测暴力倾向评分和犯罪类型的模型,旨在推动智能警务技术的发展,但在提取上下文语义特征方面存在一定不足。Sadiq等[21]针对网络暴力欺凌问题,对攻击性行为进行智能分级,通过手动设计特征构建多层感知机,并采用CNN-LSTM(Convolutional Neural Network-Long Short-Term Memory)和CNN-BiLSTM(Convolutional Neural Network-Bi-directional Long Short-Term Memory)进行自动检测,但由于缺乏关键性语义的提取,它们的性能无法得到充分发挥。
以上研究表明,采用新的模型结构和方法能更好地捕获语义特征,是实现准确的暴力倾向分级的关键,因此,本文利用自然语言处理(Natural Language Processing,NLP)分析服刑人员的气质信息进行处理决策,并提出一种基于改进HAN 与TextCNN 两通道联合建模的暴力犯罪分级模型——犯罪语义卷积分层注意网络(Criminal semantic Convolutional Hierarchical Attention Network,CCHA-Net)。所提网络分别分析犯罪事实和服刑人员基本情况的语义,自动提取犯罪文本特征,并将服刑人员分为4 种类型:胆汁质、多血质、粘液质和抑郁质。首先,采用Focal Loss 同时替代两通道中的Cross-Entropy 函数提升小样本类别的分类准确率;其次,在两通道输入层中,同时引入位置编码以更好地对位置信息建模;改进HAN 通道,为使编码出的向量具备更明显的类别特征,采用最大池化扩展了显著向量;最后,输出层都采用全局平均池化(Global Average Pooling,GAP)替代全连接方法,从而规避过拟合。
1 研究方法
1.1 本文算法框架及流程
本文首先收集中国裁判文书网上关于暴力犯罪类型案件的判决书组成基础数据集;其次,由本课题组的多位犯罪心理学专家进行联合评估标注工作;随后,将数据集划分为犯罪事实与服刑人员基本情况两部分,分别通过Jieba 分词器进行分词操作,并从犯罪事实文本中抽取具有关键性表征的字、词、短语等构成基于暴力犯罪气质类型的关键词词典,将它作为犯罪事实部分Jieba 分词器的用户预定义词典;最后,将两部分分词之后的结果通过CCHA-Net 模型进行联合建模,以端到端的方式自动提取特征,并将暴力犯罪服刑人员划分为胆汁质、多血质、粘液质、抑郁质4 种气质类型,监管部门可根据气质类型间的差异个性化制定矫治方案,以实现对症矫治的目的。图1 描述了本文算法总体技术路线。
1.2 CCHA-Net暴力犯罪分级模型
为解决传统模型在暴力犯罪文本分类中语义特征提取不足和缺乏对不同信息维度的融合分析问题,本文提出一种基于改进HAN 与TextCNN 两通道联合建模的暴力犯罪分级模型CCHA-Net。首先,利用HAN 通道提取非结构化文本信息特征;其次,通过TextCNN 通道提取结构化及半结构化信息文本特征;最后,通过两通道融合的方式充分利用不同信息维度的特点,实现更全面的特征提取。这种模型设计能有效克服传统模型在暴力犯罪分类任务中的缺陷,从而达到提升模型分类准确性的效果。CCHA-Net 框架流程如图2 所示,其中两通道的输入层和输出层模块相同,但特征提取层模块存在差异。
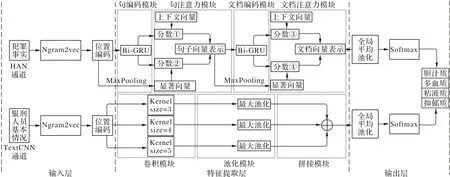
图2 CCHA-Net整体流程Fig.2 CCHA-Net overall process
本文构建的数据集分为犯罪事实和服刑人员基本情况两部分,且分别属于两种不同的信息维度。在刑事案件中,这两个维度的重要性不同。其中,按照服刑人员档案记录数据项中的犯罪事实部分提取了中国裁判文书网有关暴力犯罪类型案件的判决书中的案件事实部分,反映了犯罪行为的具体情况,包括时间、地点、手段和对象等非结构化数据信息。这些信息可以对服刑人员进行更加精准的分类和判定,本文采用HAN 通道对犯罪事实部分进行语义建模。而服刑人员基本情况部分则提取了判决书中的首部和判决结果部分,由服刑人员的年龄、出生日期、文化程度、职业、面貌、婚否、籍贯、罪名、刑期、前科次数、主从犯、团伙犯和累惯犯等多个短语组成。这些信息属于结构化及半结构化数据范畴,可用于对案件的背景和动机进行更深入的分析和理解。其中年龄、出生日期、刑期和前科次数属于结构化数据,可直接提取数值特征,其余属于半结构化数据,需要预处理后才能提取特征。本文采用TextCNN 通道对服刑人员基本情况部分进行语义建模。
本文采用两通道进行网络设计,优势在于可以充分利用不同信息维度的特点和差异,更好地提取和分类特征。此外,采用两通道设计还有利于模型的解释和可解释性,可以更清晰地展示不同信息维度的贡献和作用。综上所述,采用两通道进行网络设计是基于犯罪案件信息特点和分类需求的合理选择,有助于提高分类准确性和解释性。
两通道输入层分别解决了文本向量化、位置信息建模两个问题。首先,为解决犯罪文本存在的高维稀疏性问题,采用Ngram2vec 方法对文本进行向量化处理工作;其次,同时在两通道中引入了位置编码,以增强词语之间位置信息的表达能力。
HAN 通道特征提取层分为句编码、句注意力模块、文档编码、文档注意力4 个模块。首先,在句编码模块,为获取句子的序列信息,采用双向门控循环单元(Bi-directional Gated Recurrent Unit,Bi-GRU)对句子中的词进行了建模表示;其次,在句注意力模块,除了使用上下文向量外,本文提出了一种显著向量,采用最大池化方法提取了词向量每个维度上的最大值;最后,使用两个向量共同打分,从而使句子编码的类别特征更明显。文档编码和文档注意力模块与句编码和句注意力模块类似。
TextCNN 通道特征提取层分为卷积、池化和拼接3 个模块。首先,为提取局部短语特征,本文设计了3 个高度为3、4、5 的卷积核,进行卷积操作,每种尺寸的卷积核有128 个;其次,为抽取主要特征同时减少参数量,采用最大池化方法抽取了每个特征图中的最大值;最后,将池化后的结果进行拼接,得到服刑人员基本情况的特征表示。
两通道输出层分别解决分类输出和联合建模两个问题。首先,同时在两通道中采用全局平均池化替代全连接方法进行分类输出,以解决过拟合问题;其次,通过Softmax 分类器,获得了各自的分类概率;最后,为实现联合建模,采用软投票机制融合两通道的分类概率,得到了最终的分类结果。
此外,为提升小样本类别的关注度,本文在两通道中同时采用Focal Loss 替代了Cross-Entropy 函数。
1.3 基于位置编码的两通道输入层
一个句子中词语的先后顺序不同,含义也会有所差异。随着文本长度的增加,模型无法充分利用到词向量之间的位置信息。为解决此类问题,本文提出在两通道输入层中同时引入了Vaswani 等[22]提出的位置编码。假设输入序列的长度为L,每个单词的向量表示维度为dmodel。对于每个位置pos和每个维度i,计算一个位置编码,如式(1)、(2)所示:
其中:pos是当前位置;i为当前维度;dmodel指向量维度。是一个假设条件,用于确定不同维度之间的周期性,确保位置编码不会重复和重叠。将位置编码按元素加到对应位置的词向量中,得到新的向量表示便带有了位置信息。
1.4 基于显著向量的HAN通道特征提取层
在文本分类任务中,传统的将文档中的句子作为长序列进行处理的方法无法捕捉文档中的层次结构信息,导致信息的丢失。为了解决这个问题,HAN 模型[19]应运而生,该模型通过学习文本的语义层次结构进行文本分类,由句子和文档两个级别的注意力机制组成,能形成每个句子和文档级别的加权平均表示,进而为文本分类任务提供更准确的表示。
为深化具有明显的类别特征权重,提升分类准确度,本文在HAN 模型基础上提出一种显著向量,采用最大池化方法提取句子和文档的向量以表示矩阵中每个维度上最重要的信息;同时利用上下文向量与显著向量共同评价的方式使模型能够聚焦到最具判别性的语义特征。
1.4.1 句编码模块
在句编码模块中,为了获取句子的长距离序列信息,采用RNN[17-18]将句子中的词语按顺序输入进行建模表示。由于RNN 的隐藏层变量会出现梯度消失和爆炸的问题,因此本文采用RNN 的变体,即Bi-GRU 解决此类问题。
假设对于数据集中犯罪事实部分的某一篇文档S=[S1,S2,…,SL],Si代表该文档中的第i(i∈[1,L])个句子。对于该文档中的某一个句子Si=[xi1,xi2,…,xiT],xit代表第i个句子中第(tt∈[1,T])个单词的向量表示。首先,使用Bi-GRU汇总两个方向的信息获得单词的注解,如式(3)、(4)所示:
1.4.2 句注意力模块
并非所有的词都对句子意思的表达有同样的重要性,因此,在句注意力模块采用注意力机制评价每个单词权重,再通过单词及其得分形成句子的向量表示。
特别地,在句注意力模块,为使模型更好地聚焦到最具判别性的语义信息,本文除了使用上下文向量Ug外,还创新性地为每个句子构建了其独有的显著向量Us。设每个单词的词向量为xit=[xit1,xit2,…,xitW],W为词向量的维度,每个维度都表示一个属性信息。本文在计算每个句子独有的显著向量Uis时,对句子中全部T个单词的w个维度,提取每个维度的最大值,然后将它们进行连接作为句子独有的显著向量Uis,使得具有明显类别特征的语义信息更加突出,如式(6)、(7)所示:
其中:Uis为句子Si独有的显著向量;uij为Uis的第j维;xitj是句子Si中的第t个词向量的第j维的值。同时设置一个上下文向量Ug以表示“哪些单词对犯罪分析更为关键”,此向量取随机初始值,并在训练过程中不断迭代学习。
之后,首先通过一个单层的多层感知机(MultiLayer Perceptron,MLP)将词的注解hit送入,得到,如式(8)所示:
其中:Ws表示可训练权重;bs为偏置项。然后对于句子中的所有单词,分别计算它和两个向量的相似度并归一化,得到针对两种向量的注意力得分,如式(9)、(10)所示:
其中:αit、βit分别为单词注解hit对于Ug和Uis两个向量的归一化分数,如图2 中分数①和分数②所示。最后,将两个分数求和作为最终的注意力得分,根据所有单词和注意分数得到最终的句子向量表示Si,如式(11)所示:
通过上下文向量和显著向量共同评价的方式,既能得到文档中每个句子对应的向量表示,又能提升犯罪文本中具有明显判别含义的特征权重,达到模型分类准确率提升的效果。
文档编码及注意力模块与句编码及注意力模块类似。在得到句子的向量表示Si之后,首先,通过文档编码模块同样输入Bi-GRU,得到句子的注解;其次,通过文档注意力模块计算句子注解对于上下文向量Ud和本文提出的显著向量UL的得分,如图2 中分数③和分数④所示;最后将两个分数求和,以得到最终的包含了全部句子信息的文档向量d。
1.5 TextCNN通道特征提取层
服刑人员基本情况是由许多独立且不相关的短语组成,鉴于TextCNN[16]通过卷积操作,在捕获局部短语特征方面表现出色,因此本文采用TextCNN 通道,分为卷积、池化和拼接3 个模块,对服刑人员基本情况文本进行特征提取。
在卷积模块中,输入矩阵的第i个到第i+h-1 个窗口内的词向量矩阵xi:i+h-1通过卷积操作提取到的特征oi如式(12)所示:
其中:f(·)是非线性激活函数,W1为权值矩阵,b1是偏置项。卷积操作应用于一个完整的服刑人员基本情况文本的词向量{x1:h,x2:h+1,…,xn-h+1:n}会得到一个特征图o,如式(13)所示:
在池化模块中,最大池化方法用于提取每个特征图中的最大值,具体运算如式(14)所示:
其中Fmax表示池化后的结果。在拼接模块中,需要将词向量分别经过高度为3、4、5 的卷积核进行卷积,再进行池化后输出的特征向量Fmax3、Fmax4、Fmax5按顺序进行拼接,从而得到服刑人员基本情况的特征表示向量Ffinal_max,具体过程如式(15)所示:
1.6 基于全局平均池化和软投票的两通道输出层
1.6.1 基于全局平均池的犯罪气质分类方法
经典HAN 与TextCNN 模型输出层中使用全连接方法进行分类输出,虽然应用广泛,但也有一些缺点:首先,参数量巨大,降低了训练速度;其次,非常容易出现过拟合。为了解决这两个问题,本文同时在两通道输出层中采用全局平均池化替代了全连接方法,分别得到两通道的分类输出结果F1和F2。全局平均池化方法计算不需要设置大量参数,计算量大幅减小,在避免出现全连接方法两个主要缺点的同时,可以达到全连接方法相同甚至更高的分类效果。
1.6.2 基于软投票的犯罪语义联合建模方法
为实现对犯罪事实与服刑人员基本情况的语义表示进行联合建模,本文采用软投票机制进行特征融合。首先将两个通道得到的分类输出结果Fn分别应用于Softmax 分类器,从而得到两个通道的预测概率;然后,对这两个概率求算术平均,得到了最终的类别预测概率p,用于暴力犯罪气质的分类,如式(16)所示:
其中:n表示模型通道数2,Wi为可训练权重,bi为偏置项。
1.7 基于Focal Loss的小样本类别关注度提升方法
为降低样本数不均衡问题带来的影响,本文在两通道中同时采用Lin 等[23]提出的Focal Loss 替代了Cross-Entropy 函数。Focal Loss 主要针对每一种类别数重新赋予不同的权重,易分辨的类别赋予较少的权重,较难分辨的类别赋予较高的权重,从而达到提升关注度的效果。Focal Loss 计算流程如式(17)、(18)所示:
其中:αi表示权重因子,Ci表示每个类的计数。在Cross-Entropy 中,通过参数γ≥0 的Focal Loss 添加调制因子(1 -pi)γ:若γ=0,则Focal Loss 效果与Cross-Entropy 相同;若γ增加,那么α便会减小。为了控制每个类别的损失权重,有效地利用了参数β和σ。
2 实验与结果分析
2.1 数据来源及处理
2.1.1 数据集的获取与标记
首先,本文以中国裁判文书网为语料源,收集并选取了2015 年3 月26 日至2021 年8 月9 日暴力犯罪类型案件的判决书,得到4 665 条数据作为基础数据集;其次,由本课题组的多位犯罪心理学家进行联合评估标注工作;最后,得到胆汁质2 232 条,多血质1 963 条,粘液质465 条,抑郁质5 条。
2.1.2 基于暴力犯罪气质类型的关键词词典构建
通过查看分词器的效果,发现一些具有代表性的心理特征词不能被很好地划分,因此,本课题组的多位犯罪心理学专家从各类服刑人员的犯罪事实中选取了具有关键性表征的字、词和短语等,构建了4种暴力犯罪气质类型的关键词词典。
2.1.3 数据预处理
数据预处理部分分别解决了分词、删除停用词两个问题。首先,Jieba 分词器可以有效识别犯罪文本中的一些实体信息,分词效果较好。因此,本文采用Jieba 分别对犯罪事实和服刑人员基本情况两部分进行分词操作;此外,为避免分词过程中关键性语义特征的流失,将基于暴力犯罪气质类型的关键词词典作为犯罪事实部分Jieba 分词器的用户预定义词典;其次,本文通过加载哈尔滨工业大学停用词表,删除了一些不相关的词、标点符号等内容,以减少训练过程中的噪声。
2.2 实验条件和环境
2.2.1 实验环境和超参数设置
本文使用的实验平台为Ubuntu 18,硬件为Intel i7-9700处理器,32 GB 内存,RTX 2080 GPU 处理器。编码采用Python 3.7.11 版本,深度学习库为PyTorch 1.9.1,机器学习库为Sklearn 1.0.2。为了使模型取得更好的效果,本文通过大量实验选取了最优的超参数设置,如表1 所示。

表1 超参数设置Tab.1 Hyperparameter setting
2.2.2 数据集划分
为验证实验结果,按6∶2∶2 随机划分了4 665 条数据,数据之间没有交叉,数据集划分如表2 所示。模型总共训练了50 个epoch。每100 个batch 后,对验证集数据进行测试,以保存最好的模型。然后用在测试集上,得到最终结果。
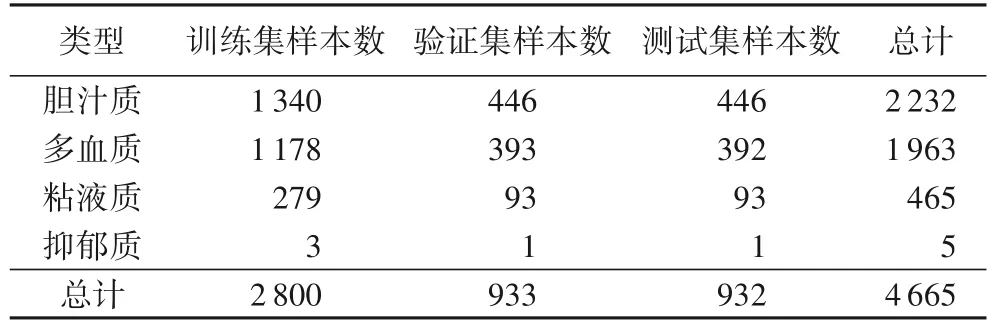
表2 数据集划分Tab.2 Dataset division
2.2.3 评价指标
为统计本文所提模型CCHA-Net 与其他相关基线模型的显著差异,本文使用了准确率(Acc)、精确率(P)、召回率(R)、F1 分数对模型进行了综合评价。同时考虑到数据集存在样本数不均衡问题,还引用了曲线下面积(Area Under Curve,AUC)值。由于本文是多分类问题,所以采用宏平均和微平均两种方式对精确率(Macro_P,Micro_P)、召回率(Macro_R,Micro_R)、F1 分数(Macro_F1,Micro_F1)、AUC 值(Macro_AUC,Micro_AUC)进行计算。
2.3 实验结果与分析
2.3.1 消融实验结果与分析
为深入分析两通道单独建模改进内容与联合建模对暴力犯罪气质分类能力的影响,本文设计了消融实验进行分析比较,结果如表3 所示。

表3 消融实验测试结果 单位:%Tab.3 Test results of ablation experiments unit:%
由表3 可知,在HAN 通道对犯罪事实进行语义建模,将Focal Loss 替代Cross-Entropy 后,Macro_P 与Macro_F1 分别提升了2.96 和2.56 个百分点。这是由于Focal Loss 类似于一个奖惩机制,对大样本类别权重进行惩罚,同时对小类别权重进行奖励,使模型在训练过程中能更多地关注小类别,从而提升分类效果。
在输入层引入位置编码后,Acc 与Macro_AUC 分别提升了1.08 和5.71 个百分点。这是由于词语的先后顺序对犯罪文本的含义理解有偏差,而位置编码能够通过引入位置向量而提高模型对于位置信息的感知能力,以解决此类问题。
在特征提取层句及文档注意力模块构建显著向量后,Acc 与Macro_P 分别提升了3.97 和4.08 个百分点。这是由于显著向量的构建,与上下文向量共同对句子中的单词、文档中的句子进行打分,从而使句子及文档编码的类别特征更加明显,模型能够更好地关注到犯罪文本中最具差异性的信息。
在输出层将全局平均池化替代全连接方法后,Acc 与Macro_P 分别提升了0.53 和0.87 个百分点。这是由于全局平均池化方法对全连接方法参数量大和易过拟合缺点进行了避免。
在TextCNN 通道对服刑人员基本情况进行了语义建模,各项改进也得到了相应的指标提升。最终,将两通道进行联合建模后,模型达到了最佳效果,其中Micro_F1、Macro_AUC和Micro_AUC 分别达到了99.57%、99.45%和99.89%。验证了本文提出的CCHA-Net 模型在暴力犯罪气质分类方面具备较好的应用价值。
由 表3 中 的Macro_AUC 和Micro_AUC 可 知,HAN 和TextCNN 的表现最差,这是因为两者并没有对样本数不均衡、位置信息建模和过拟合等问题进行优化。HAN 到HAN+Focal Loss+位置编码+显著向量+GAP;TextCNN 到TextCNN+Focal Loss+位置编码+GAP 的Macro_AUC 和Micro_AUC 指标呈递增趋势,这说明本文提出的各项改进措施都是有效的。而CCHA-Net 的Macro_AUC 和Micro_AUC 指标则最高,这证明了本文提出的CCHA-Net 模型通过两通道联合建模后,在面对存在样本数量不均衡问题的犯罪文本时,仍然能够具备良好的分类效果。
2.3.2 相关模型对比实验结果与分析
为了与以往的犯罪分析工作进行比较,同时验证本文提出的CCHA-Net 模型的优越能力,本文在同一数据集上与17种相关模型进行了对比实验,包括9 种传统机器学习已有相关基线模型:K最近邻(K-Nearest Neighbor,KNN)[24]、多项式朴素贝叶斯(Multinomial Naive Bayes,MNB)[25]、高斯朴素贝叶斯(Gaussian Naive Bayes,GNB)[26]、伯努利朴素贝叶斯(Bernoulli Naive Bayes,BNB)[27]、决策树(Decision Tree,DT)[28]、随机森林(Random Forest,RF)[29]、支持向量机(Support Vector Machine,SVM)[30]、XGBoost(eXtreme Gradient Boosting)[31]和逻辑回归(Logistic Regression,LR)[32],8 种深度学习已有相关基线模型:长短期记忆(Long Short-Term Memory,LSTM)[33]、双向长短期记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)[34]、门控循环单元(Gated Recurrent Unit,GRU)[35]、Bi-GRU[36]、Att-BiLSTM(Attentionbased Bidirectional Long Short-Term Memory networks)[37]、CLSTM[38]、CNN-BiLSTM[9]、AC-BiLSTM(Attention-based Bidirectional Long Short-Term Memory with Convolution layer)[39]。考虑到这些模型不是多通道模型,在实验过程中,将两类数据按照犯罪事实、服刑人员基本情况的顺序整合在一起输入模型。结果如表4 所示。
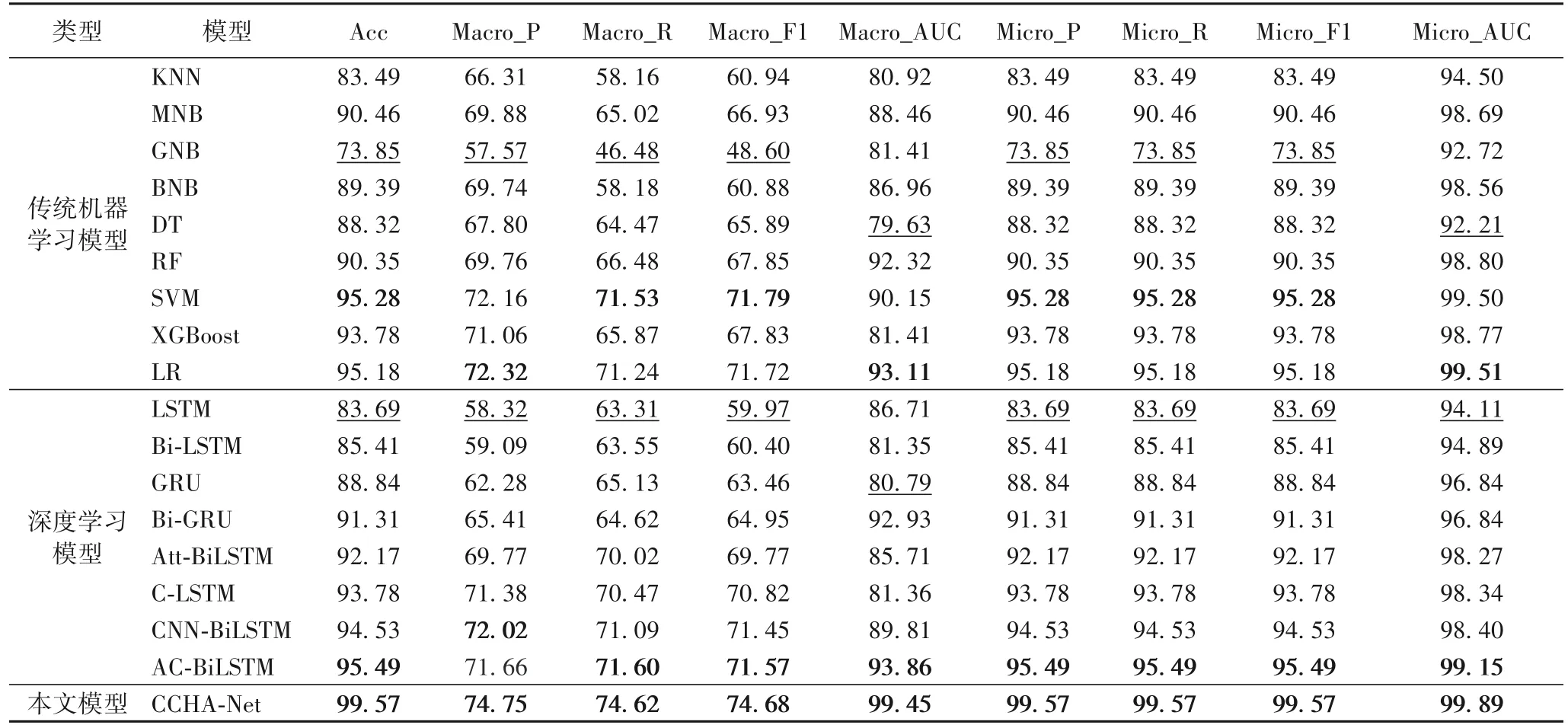
表4 对比实验测试结果 单位:%Tab.4 Test results of comparative experiments unit:%
由表4 可知,在传统机器学习模型中,GNB 表现最差,与CCHA-Net 相比,Acc 与Macro_R 分别低25.72 和28.14 个 百分点。这是由于胆汁质与多血质类型犯罪文本之间存在一定的相关性,GNB 在处理具有相关性的类别时效果不佳。与其中最优 的SVM 相比,CCHA-Net 在Acc 和Macro_AUC 指 标上分别高4.29 和9.30 个百分点,表明CCHA-Net 在处理相关性较强的类别时具有更好的性能。
在深度学习模型中,LSTM 表现最差,与CCHA-Net 相比,Acc 与Macro_P 分别低15.88 和16.43 个百分点。这是由于LSTM 丢失建模信息过多,如层次结构与后向信息等。与其中最优的AC-BiLSTM 相比,CCHA-Net 在Acc 和Macro_P 指标上分别高4.08 和3.09 个百分点,表明CCHA-Net 具有更好的文本建模能力。
与所有模型相比,CCHA-Net 各项评价指标最佳。Micro_F1,Macro_AUC,Micro_AUC 相较于次优的AC-BiLSTM提高了4.08、5.59 和0.74 个百分点,证明本文提出的CCHANet 模型能够有效胜任暴力犯罪气质分类任务。
2.3.3 CCHA-Net两通道复杂度分析
CCHA-Net 模型的有效性,本文从两通道处理方式的复杂度视角出发,进行了计算量和参数量的测试工作,以评估时间复杂度和空间复杂度。具体测试结果如表5 所示。
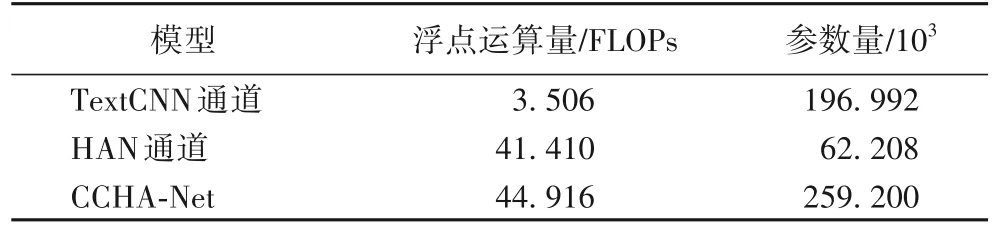
表5 两通道处理方式复杂度评估结果Tab.5 Complexity evaluation results of dual-channel processing method
由表5 可知,本文提出的CCHA-Net 模型采用了两通道联合建模机制,计算量和参数量相当于两个通道的总和。从计算量和参数量的角度来看,CCHA-Net 的复杂度较为合理,具有良好的可扩展性和实用性。
3 结语
本文将文本分类方法引入犯罪心理学领域,提出了一种基于改进HAN 与TextCNN 两通道联合建模的暴力犯罪分级算法CCHA-Net,通过分别剖析犯罪事实与服刑人员基本情况文本,以端到端的方式将服刑人员划分为胆汁质、多血质、粘液质和抑郁质四种气质类型。首先,为提升小样本类别的关注度,采用Focal Loss 同时替代两通道中Cross-Entropy 函数;其次,在两通道输入层中,同时引入了位置编码,优化了模型对词语前后位置信息的感知能力;并改进HAN 通道,为强化具有明显的类别特征权重,采用最大池化构建了显著向量;最后,输出层都采用全局平均池化替代全连接方法,以防止出现过拟合问题。为验证CCHA-Net 的分类准确率,将它与9 种传统机器学习和8 种深度学习已有相关基线模型进行了对比。实验结果表明,CCHA-Net 在9 种主流评价指标下均达到了最优,Micro_F1 为99.57%,Macro_AUC、Micro_AUC分别为99.45%和99.89%,三者相较于次优的AC-BiLSTM 提高了4.08、5.59 和0.74 个百分点。验证了CCHA-Net 能够有效完成暴力犯罪分级任务,同时为后期监管部门制定个性化矫正教育方案奠定基础。
未来的工作将集中在样本数不均衡问题和数据集扩充两个方面。首先,由于数据集中存在样本数不均衡的问题,导致宏平均下的评价指标不是很高,未来将尝试改进损失函数或设计重采样方法,并执行图神经网络解决此类问题。然后,本文将进一步扩充服刑人员样本数据集,包括服刑人员访谈记录、日常康复记录、亲情电话语音和通过各种传感器采集的脉搏、心率、皮电和脑电信号等,通过多模态技术对服刑人员进行综合分级,以实现个性化矫治。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
软件导刊(2022年3期)2022-03-25
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
公民与法治(2020年10期)2020-07-25
电子制作(2019年22期)2020-01-14
社会生活探索(2019年0期)2019-05-21
计算机技术与发展(2019年1期)2019-01-21
疯狂英语·新读写(2018年3期)2018-11-29
