
基于异构图表示的中医电子病历分类方法
2024-03-21 02:25王楷天程春雷
计算机应用 2024年2期
王楷天,叶 青,2*,程春雷,2
(1.江西中医药大学 计算机学院,南昌 330004;2.江西省中医人工智能重点研究室(江西中医药大学),南昌 330004)
0 引言
电子病历是医疗资源的一种,随着医疗水平不断提高,它的重要性愈发明显。在数字医疗高速发展时代,电子病历在医疗信息化中占据重要地位。2022 年11 月25 日,国家中医药管理局发布《“十四五”中医药信息化发展规划》,并提出将加强中医药数据资源治理作为主要任务之一。医学领域的数据资源中,最重要的就是电子病历数据。依靠数字化方式,电子病历不仅帮助医生高效有序地记录和存储患者的临床诊疗信息,还为医院提供足够的信息载体以归纳总结患者数据,从而提高医院诊疗水平。目前,中医(Traditional Chinese Medicine,TCM)领域已经广泛推广使用电子病历,旨在促进中医药信息化、智能化的发展,并提高临床服务水平和医疗质量。
由于西医诊疗阶段的数字化程度较高,同时仪器设备较先进,因此西医的电子病历结构完整、内容丰富,在医疗领域已成为研究者的重要关注点,并且西医基于电子病历的辅助决策模型已经得到广泛的发展和应用,如围手术期智能临床辅助决策系统[1]、慢性疾病个性化辅助决策[2]和多元数据融合的临床辅助决策系统[3]等。但是西医的临床决策系统基于患者身体状况的理化数据支持,无法直接应用于中医。
在TCM 领域,Yang 等[4]提出的中医证候诊断决策系统基于中医知识图谱预测患者证候,但由于中医证候复杂多样,该研究没有涉及从证候到患者疾病的过程;Ruan 等[5]的SaGCN(Semantic-aware Graph Convolutional Network)模型通过大规模非结构化的中文病历数据构建训练预料,挖掘从症到药的关系,但并未深入研究症与病的联系;张玉洁等[6]以糖尿病为例,设计了一种辅助诊疗系统实现对糖尿病的病情量化评估、病症类型判别等功能。虽然该系统对单一疾病的功能已经较为全面,但是只针对了糖尿病一种病情,并未拓展延伸。上述工作是利用中医电子病历的先进研究成果,为中医提供了优秀的辅助诊疗工具,但由于中医电子病历数据难以利用,大部分研究都未完全利用病历的特征数据,在患者疾病的辅助决策方面缺少更进一步的研究。中医临床决策阶段也需要电子病历这种宝贵医疗资源的支持,优秀的辅助决策手段不仅让中医诊疗有直观的数据支持,更能提高中医的可信力,并且有研究表明,在推广辅助决策系统后,病历的质量显著提高,急诊中医生的诊疗速度也得到了提高[7]。
由于中医电子病历刚刚起步,它的数据结构差异较大、诊疗术语不规范、症状描述复杂多样等特点导致难以利用。因此,对中医电子病历的研究充满了挑战。如果能够利用好中医电子病历数据,实现对患者疾病的诊断推荐或预测,将不仅会提升中医临床诊疗质量,还可以推进中医诊疗数字化进程。在中医电子病历刚刚起步的当下,它的研究对于推动中医信息化的发展有着重要意义。
本文的主要工作如下:
1)使用 LERT(Linguistically-motivated bidirectional Encoder Representation from Transformer)[8]词嵌入方式获取句向量以表达病历整体文本语义特征,将句向量作为节点的特征向量保存在异构图中弥补异构图结构对病历整体语义信息的忽视,并通过回传的方法在训练过程对该特征向量也进行同步更新。
2)使用 BW25 与点间互信息(Pointwise Mutual Information,PMI)算法构造文本异构图的边,能够有效缓解中医电子病历数据难以利用的问题,克服传统分词方法对中医术语错误拆分造成的不良影响,成功捕获并存储数据中隐含的结构特征。
3)验证了TCM-GCN(TCM-Graph Convolutional Network)模型在中医电子病历数据上的特征识别效果与分类能力,并通过消融实验证明了异构图各部分在特征提取上的有效性。
1 相关工作
应用中医电子病历数据进行临床辅助决策本质上属于一种文本分类任务。目前,浅层机器学习分类算法有朴素贝叶斯、K 近邻算法、支持向量机(Support Vector Machine,SVM)、决策树算法等。中医电子病历中,病历数据由于结构差异大、实体不连续的特点,用浅层机器学习算法效果较差,且在许多领域已经被深度学习与基于神经网络的分类算法超过[9]。
在深度学习类的文本分类模型中,TextCNN(Text Convolutional Neural Network)[10]因为网络结构简单、占用内存小、运算快、准确率高的优点成为热门的神经网络,在短文本分类领域有出色的表现,但可解释性不强;BERT(Bidirectional Encoder Representations for Transformers)[11]的注意力(Attention)机制和静态mask 方法由于在文本分类领域有极佳的性能,也被广泛使用。Kipf 等[12]提出了图卷积网络(Graph Convolution Network,GCN)模型用于数据集的分类任务,GCN 是一种能够直接作用于图并且利用它的结构信息的卷积神经网络。Yao 等[13]在GCN 的基础上提出了TextGCN(Text Graph Convolutional Network)用于文本分类工作,TextGCN 使用将document 通过word 进行表达的思想构图;但TextGCN 的构图过程只利用了结构特征,未能很好地利用文本的语义特征。Lin 等[14]提出了BertGCN,结合预训练模型BERT 与图注意力网络(Graph ATtention network,GAT)用于文本分类,采用预测插值、记忆存储和小学习率等技术,在通用数据集上取得了显著的效果提升。
上述深度学习模型虽然在通用数据集上有着出色的表现,但因为中医电子病历结构的特殊性,深度学习模型捕捉中医电子病历的有效特征的效果较差。有不少研究者开始针对中医医案信息难以利用的问题展开研究,李明浩等[15]基于长短期记忆-条件随机场(Long Short-Term Memory -Conditional Random Field,LSTM-CRF)网络提出了症状术语识别方法,通过添加基于症状的字符级别的特征,该特征作为字嵌入的扩展为模型进行中医术语识别提供更具体有效的信息。杜琳等[16]提出BERT+Bi-LSTM+Attention 融合模型用于病历文本抽取与分类的工作,该模型使用BERT 转化分词后的中医文本到词向量的方式捕捉有效特征,再将词向量拼接为句向量,最终句向量通过Bi-LSTM 与注意力层完成分类任务。
从目前已有的中医医案数据研究来看,中医电子病历数据集难以利用主要有两方面原因:
1)诊疗术语不规范。中医对于症状描述缺少统一的度量方法,诊断阶段也缺少精密仪器的支持,数据质量参差不齐。
2)电子病历表述具有多样性。中医电子病历的记述有着结构差异大、关键词多、语义不可分割、实体不连续等特点,普通的数据分析方法效果不佳。
面对中医数据集问题,先前的工作大都是将病历进行拆分,从病历分词后的字向量与词向量出发,以更好地发掘病历中的隐藏信息。但是这种方式通常忽略了病历本身的整体语义,并且过于依靠预处理阶段分词的准确率,而中医病历又由于其自身特点,分词方式需与一般文本不同,所以词向量与句向量的特征提取方式也较难发挥应有的作用。
基于上述讨论,本文提出一种基于异构图表示的中医电子病历文本分类模型TCM-GCN,用于中医辅助决策任务。TCM-GCN 将病历的关键词与病历一同构建异构图,在异构图中建立“关键词-关键词”“病历-关键词”边以提取中医病历中隐含的语义特征。通过该方法,模型能够更好地在中医电子病历中提取语义特征,实现中医电子病历分类,改善电子病历数据自身问题对数据分析工作的影响。
2 模型设计
2.1 模型架构
TCM-GCN 模型结构如图1 所示,主要分为4 个部分:数据预处理、LERT 特征传递、异构图构建和模型输出。
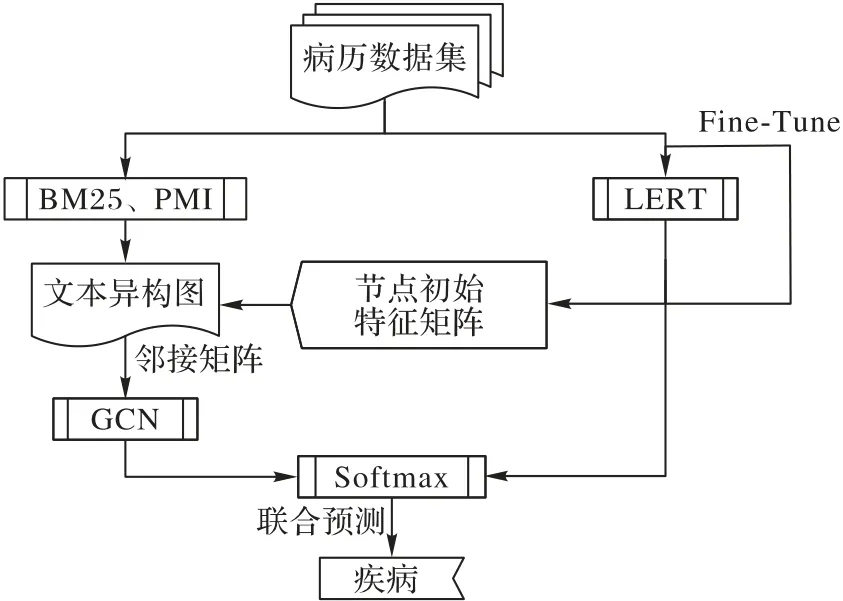
图1 TCM-GCN模型的结构Fig.1 Structure of TCM-GCN model
1)数据预处理。中医电子病历数据作为原始数据集,提取病历中的性别、四诊与主诉信息并进行数据清洗、分词等预处理操作,患者所患疾病为每一条病历的标签。
2)LERT 特征传递。针对图结构数据会忽略病历语义特征的问题,使用LERT 对病历进行处理,LERT 是哈尔滨工业大学与科大讯飞一同研发的多任务预训练模型,实验表明相较于BERT 等预训练模型,LERT 在多个数据集上有着更优异的性能。LERT 利用读取的中医电子病历数据进行微调(Fine-tune)操作,能提高预训练模型在中医电子病历领域的适应度。TCM-GCN 把病历输入微调后LERT 的Token Embedding 层,转换成记录病历特征的[CLS]向量,将[CLS]向量保存至文本异构图作为初始特征向量使用,该向量存放于异构图的节点,保存了病历整体的语义特征。
3)异构图构建。为了改善中医电子病历结构复杂多样、实体不连续等问题对特征提取的影响,预处理后的数据集使用改进的BM25、PMI 等方法,构建病历信息为数据的文本异构图。该异构图将关键词与病历一同作为节点,将病历拆分成关键词以加强病历的结构特征表达,改善了模型对病历特征进行聚合与抽取的效果。
4)模型输出。最后在分类输出层中,利用GCN 层与LERT 层得到的句子表示输入至全连接层,将二者以一定权值相加,通过Softmax 函数生成每个类别的概率值,并根据概率的最大值分类文本的类别。应用交叉熵作为模型训练的损失函数,在每一个Epoch 结束后,不仅进行Adam 优化,还会使用LERT 重新对病历数据Token Embedding,更新异构图中病历节点的[CLS]特征,该特征会随模型训练进行更新以更加契合数据。
综上所述,TCM-GCN 模型使用预处理后的中医电子病历数据,运用LERT-BM25-PMI 方法构造将病历与关键词作为节点的能够反映病历间特征关系的异构文本图,LERT 层与GCN 层联合对病历进行分类。
2.2 病历文本异构图
GCN 通过图中节点间的关系作为每一个节点的特征表示,节点间关系的权重反映节点间不同的关系。以病历为数据构建异构图不仅可以建立病历和病历之间的联系,也可以获取到每一个病历中的非连续共现信息,丰富文本的特征。
中医病历中包含了中医对患者的脉诊、舌诊、望诊、查体和对患者状态的详细观察所获得的数据。即使电子病历已经按照检查内容分类,但病历信息还是具有关键词多、语义不可分割等特点,难以利用大部分深度学习模型。为了解决该问题,TCM-GCN 将病历中的关键词与病历一同作为图的节点,通过在病历节点与关键词节点、关键词节点与关键词节点构建边的方式,尽可能地利用病历与关键词的包含关系完整表示病历间的特征信息。比如两个病历是否同时含有该关键词,该关键词与其他关键词的同时出现频率等都会被异构图作为特征关系保存。
异构图由病历与关键词两个节点组成。对筛选后的病历信息运用改进的BM25 算法,评估该关键词对病历的重要程度。BM25 是词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)的优化版本,是信息索引领域用来计算query 与文档相似度得分的经典算法,标准的BM25算法计算的每个词和d的相关性加权和Score(Q,d),如式(1)所示:
其中:Q表示一条query;qi表示query 中的单词;d表示整个文档;wi表示词qi的权重,R(qi,d)表示词与文档的相关性。
中医电子病历数据中,由于只要出现在病历中的词语都不可忽视,词频反而不是很重要。而主诉是患者对自身病情的描述,难以避免对一些症状出现反复诉说导致TF 值偏大。所以传统的TF-IDF 算法在中医电子病历这类文档长度不一,且高频词语特别多的情况效果较差。BM25 算法在TF-IDF 算法上增添了一个常量k,用于限制TF 值的增长极限,使TF 值对打分值的影响存在上限。BM25 考虑到文本长度和平均文本长度对相关性的影响,加入了超参数调节文本长度因素在打分中所占权重。
逆文档频率如式(2)所示:
其中:N代表语料库中文本的总数;而N(x)代表语料库中包含词x的文本总数。IDF 值越高,表示该词语出现的文档数越少。
其中:fi为词qi在文本d中出现的频率,由于病历文本长短没有规律,故本文采用频数代替频率;qfi为词qi在语料库Q中出现的频数,通常取qfi=1;k1、k2、b都为可调节的超参数,通常取k2=0;ld为文本d的长度;lavg为所有文档的平均长度。词与文档相关性的计算如式(4)所示:
在本实验中,使用该算法的目的是获取关键词与病历间的关系,所以只需考虑病历d中的词qi在该条病历d中的打分。故可将公式简化为:
取最常见的k1=1.2,b=0.75,代入式(5),Score(qi,d)的结果即为关键词qi在病历d中的打分,将该打分作为“病历-关键词”边的权重加入异构图。
因为病历都是中医临床诊断中凝练的关键信息,所以本实验将病历中分词得到的所有词语都视为关键词作为图的节点,不进行筛选。比如“舌质/偏/暗青/苔/淡黄/稍/厚”,则会 将“舌质”“偏”“暗青”“苔”“淡黄”“稍”“厚”加入图的节点,相同词语不会重复添加。
异构图的方法在面对中医电子病历实体不连续的特点有着独特的解决办法,通常在中医中,比如“脉弦”必须视为一个整体,但在普通的分词方法中,通常会将“脉”与“弦”分离开来,视为两个词语。而异构图会对拆开的“脉”“弦”两个关键词构建边,关键词节点之间使用PMI 法计算“关键词-关键词”边的权重。该方法考虑到了关键词之间的全局共现性,即如果“脉”与“弦”总是在一条病历中同时出现,那么它们的边的值就会很高,特征关系更加明显。PMI 算法的使用增强了中医电子病历数据结构特征表达,成功改善了由其数据特点引发的数据难以利用的困境。
PMI 法公式如下:
其中:p(word1word2)是两个词语同时出现在一句话的概率,本文将其视为两个词语同时出现在一个病历中的概率;p(word1)是词语在语料库中出现的概率(出现次数/文档总词数)。PMI 越大,两个词之间的联系越紧密,一般取0 为阈值:当PMI>0,可以认为两个词语是相关的;当PMI=0,两个词语是独立的;当PMI<0,两个词语不相关,互斥。取PMI>0 的两个词语建立边,边的权重为PMI 的值。
如图2 所示,异构图的边由通过BM25 算法获得的“关键词-病历”边和用PMI 算法筛选得到的“关键词-关键词”边组成,由于是无向图,故将异构图转换为稀疏轴对称矩阵保存。
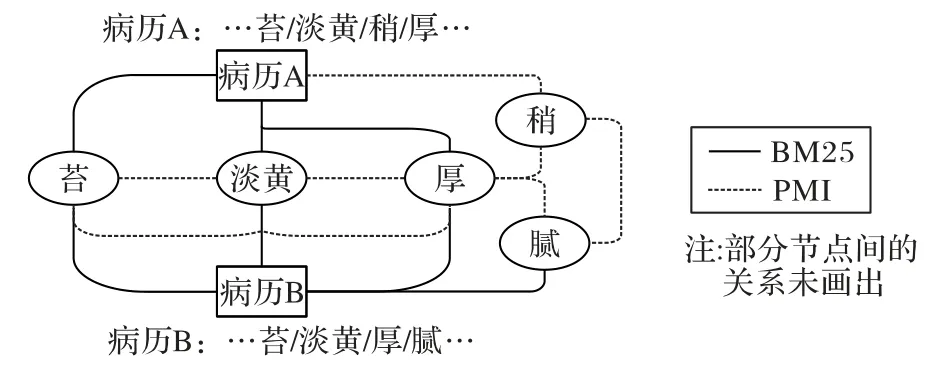
图2 中医电子病历异构图示例Fig.2 Heterogeneous graph example of TCM electronic medical records
2.3 TCM-GCN
TCM-GCN 的LERT 层由微调好的LERT 预训练模型构成,如图3 所示,将预处理后的数据集输入,通过Token Embedding 层获取每一条病历纬度为C的特征向量[CLS],数据初始节点特征矩阵为单位矩阵其中n(doc) 为病历数,n(word)为全部病历中的关键词数,将[CLS]与X融合得到XL以供GCN 层使用。
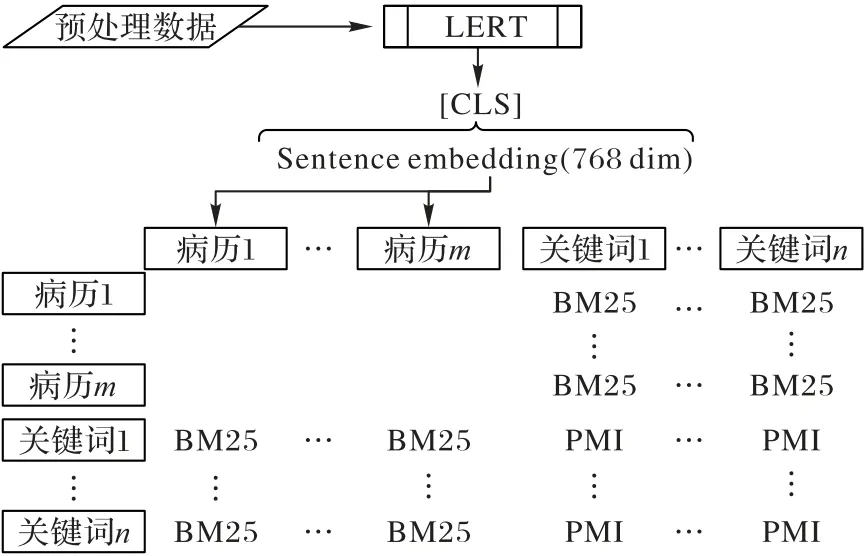
图3 LERT句嵌入传递到异构图Fig.3 LERT sentence embedding transferring to heterogeneous graph
LERT 的输出矩阵通过Softmax 层得到LERT 层的输出ZLERT:
GCN 层中,设定中医电子病历的病历图G={V,E},V是节点,E是边。LERT 传递过来的特征矩阵XL的纬度为N×C,N为病历节点与关键词节点总数,C为LERT 中[CLS]的纬度,一般为768,节点间的特征关系用一个N×N的邻接矩阵A存储,在图G上使用卷积操作的公式为:
为了缓解网络非常深时可能导致的梯度爆炸和消失问题,采用Wu 等[17]的renormalization trick 方法,该方法对邻接矩阵A进行归一化操作(式(11)),将特征值的绝对值范围缩小,约束网络参数,避免梯度爆炸。
本文的下游任务属于节点分类的一种,GCN 的输出结果需要使用Softmax 层以完成节点分类任务,且TCM-GCN 只有1 层隐藏层,由此可得模型中GCN 部分的传播公式为:
其中:W(0)∈RC×H是输入层到隐藏层的权重矩阵,C为LERT传递的特征纬度,H为隐藏层特征数。W(1)∈RH×L是隐藏层到输出层的权重矩阵,L为数据标签数。
最终分类结果为LERT 与GCN 的联合预测:
其中:λ为模型GCN 部分在联合预测中所占的权重,Z为最终输出分类矩阵。
3 实验与结果分析
3.1 数据集预处理与评价指标
本文实验使用江西中医药大学-岐黄国医书院脱敏后的中医电子病历数据作为原始实验数据集,该数据集包含了2014—2021 年江西中医药大学岐黄国医书院中医接诊患者病历信息。
提取中医电子病历信息中每一条病历的性别、望诊、舌诊、脉诊、查体、主诉,中医诊断信息,出于对数据有效性与样本容量考虑,筛选提取后的病历信息,去除中医临床诊断阶段较重要的主诉信息缺失的病历。
对性别、望诊、脉诊、舌诊、查体、主诉、症候信息去标点符号、去缺失值和分词处理。本文使用哈尔滨工业大学研发的LTP(Language Technology Platform)[18]作为分词工具,并为LTP 词库添加中医语料,提高对中医术语的识别率与分词准确率。
以表1 中“舌诊:舌质偏暗青,苔淡黄稍厚”为例,预处理后的结果为“舌质/偏/暗青/苔/淡黄/稍/厚”。

表1 中医电子病历示例Tab.1 Example of TCM electronic medical records
对数据集数据预处理筛选过后最终得到5 500 条病历,其中包含感冒、失眠、湿疹、痹症、哮喘、便秘、头痛、痤疮、月经不调、鼻鼽和虚劳11 种疾病,每种疾病有500 条病历。随机打乱后按照8∶1∶1 的比例分为训练集、验证集、测试集,最终获得4 400 条训练集数据,550 条验证集数据,550 条测试集数据用于实验。
3.2 评价指标
数据经过随机打乱后,实验为样本不平衡的多分类实验,故采取加权平均(weight-averaging)后的精确率P(Precision)、召回率R(Recall)、F1 作为评价指标,n为标签种类的数目。表2 为混淆矩阵,其中TP、TN、FP、FN将用于评价指标的计算。

表2 混淆矩阵Tab.2 Confusion matrix
准确率、召回率、单标签的F1 值公式如下:
数据加权平均F1 值WF1为:
为了更直观地体现模型效果,展示模型在不同阈值时的性能,加入了受试者工作特征(Receiver Operating Characteristic,ROC)曲线与曲线下面积(Area Under Curve,AUC),AUC 值越大,准确率越高。ROC 曲线是二分类模型经典的评价指标,多分类中可以通过one-rest 方法计算真阳率(True Positive Rate,TPR)与假阳率(False Positive Rate,FPR),本文使用加权平均后的TPR 与FPR 作为ROC 曲线的坐标。
TPR 等于召回率(式(14)),FPR 计算公式为:
为了标准化各模型分类效果,本实验采用数据加权后的精确率、召回率、F1、AUC 与ROC 曲线作为指标衡量模型的性能。
3.3 参数设置
LERT 的Fine-tune 与TCM-GCN 训练时超参数设置如表3所示。

表3 超参数设置Tab.3 Super parameter setting
LERT 预训练模型选择适合中文文本分类的Chinese-LERT-base 版本,训练优化器选择自适应矩估计(Adaptive moment estimation,Adam),学习率衰减选用余弦退火(Cosine Annealing)[19]算法,通过余弦函数降低学习率,可以防止训练时梯度下降算法可能陷入局部最小值的问题,此时可以通过余弦函数周期性的特点改变学习率,“跳出”局部最小值的困境。
3.4 对比实验
为了验证TCM-GCN 的有效性,将TCM-GCN 与LSTM[20]、Text-GCN[13]、LERT[8]、Text-CNN[10]、Text-RNN[21]、FastText[22]在预处理后的岐黄中医数据集上进行对比,不同模型实验中所用训练集、验证集与测试集均相同。
TCM-GCN 与其他经典文本分类模型的对比结果如表4所示,最优结果加粗表示,TCM-GCN 的加权平均准确率为78.46%,加权平均召回率为78.18%,加权平均F1 为78.07%,均优于其他6 种基线模型,与次优的LERT 相比,TCM-GCN 加权平均后的准确率、召回率、F1 值分别提升了2.24%、2.38%、2.32%。证明了在异构图中,将病历和关键词一同作为节点,并通过连接“病历-关键词”和“关键词-关键词”的边来构建图结构的构图方式发挥重要作用。这种构图方式解决了传统分词方法造成的研究难题,即使分词将中医术语错误拆分,也可以通过异构图成功地抽取到病历中该术语信息,并且针对电子病历数据长文本且语义不可分割的特点,异构图中采用LERT 转化的句向量作为节点的特征向量的语义信息传递方式,成功使异构图同时保存病历语义信息与结构信息,提高了模型分类性能。
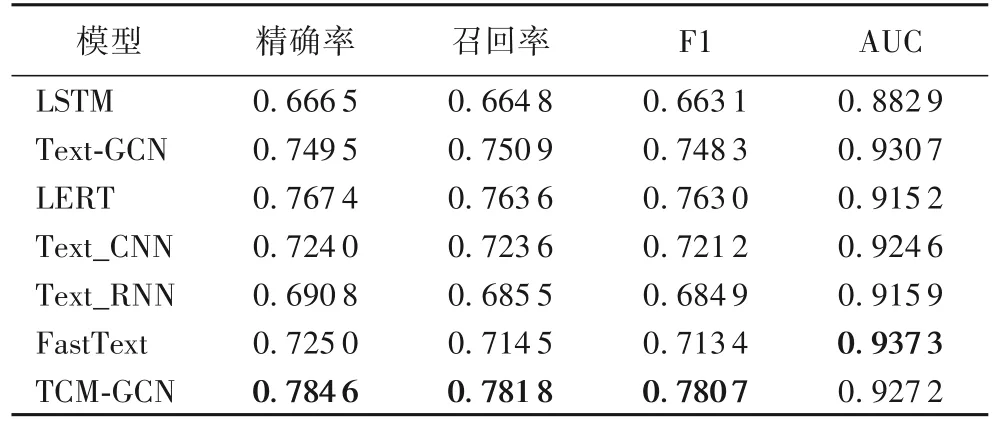
表4 不同模型的结果对比Tab.4 Result comparison of different models
ROC 曲线如图4 所示,在较为靠近起点的区域TCM-GCN一直领先于其他模型,但是在后半部分被FastText、TextGCN等模型超过。虽然TCM-GCN 的ROC 曲线不是一直领先,但是可以看出,它的曲线是靠近左上角,这也说明了最佳临界点领先其他模型,灵敏度和特异度之和最大。TCM-GCN 的AUC 为0.927 2,略低于TextGCN 的0.930 7 与FastText 模型的0.937 3。由图4 可知,是因为后半段曲线走势偏低。考虑到TCM-GCN 为医生辅助诊断的实际应用,在ROC 曲线前半段的优势即在假阳性率低的情况下真阳率最高,仍然表明TCM-GCN 在实际应用中优于其他模型。
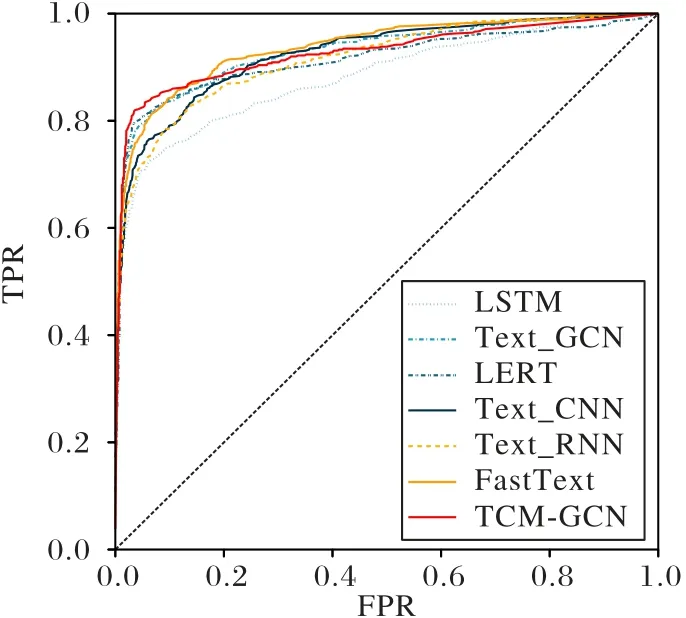
图4 不同模型的ROC曲线Fig.4 ROC curves of different models
综上所述,通过对比实验分析,说明了本文算法的有效性,有效缓解了中医电子病历数据难以利用的问题。
3.5 消融实验
为了进一步体现TCM-GCN 算法与LERT-BW25-PMI 联合构图方法的有效性,设计5 个分组进行消融实验。实验1去除掉BM25 算法计算关键词与病历的相关性的部分,替换为简单的one-hot 方法构图,若病历包含该关键词,该“病历-关键词”边的值就为1;实验2 删除了PMI 方法构造的“关键词-关键词”边;实验3 则删除LERT 将embedding 后的句向量回传给异构图的步骤;实验4 为对照实验,将BM25 算法置换为TF-IDF 算法进行实验,验证BM25 算法在中医电子病历数据集的优势;实验5 为TCM-GCN 原模型。全部实验组除了上述提及的操作外,其他模型参数与训练过程均未作变动,消融实验结果如表5 所示。
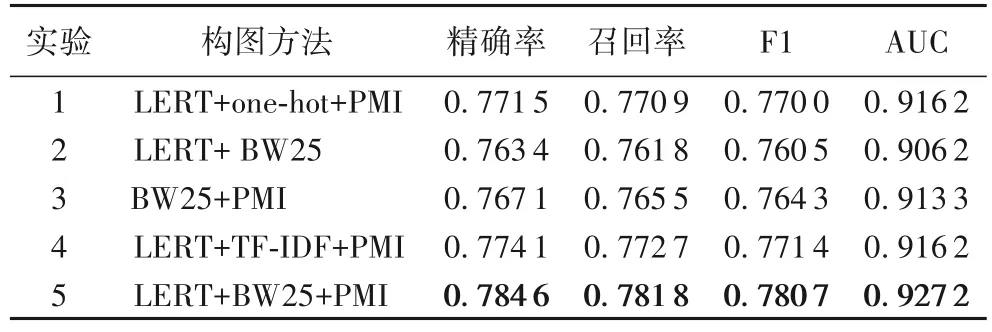
表5 消融实验结果Tab.5 Results of ablation experiments
表5 的消融实验结果显示,TCM-GCN 使用的LERT+BW25+PMI 构图方法在加权平均后的Precision、Recall、F1、AUC 值中均取得了最高值,并且图5 中ROC 曲线领先其余构图方法,证明了该构图方法的合理性与有效性。根据实验组1、2、3、5 的结果对比分析可以得出LERT、BM25、PMI 的构图方法均对模型性能产生积极影响,删除任意方法后模型的各评价指标均下降,分别证实了LERT 传递病历句向量、BM25评估关键词在病历中的重要程度、PMI 评价词之间的共现性3 种方法的有效性。第4 组将BW25 置换为TF-IDF 后的实验中,3 个评价指标也均低于TCM-GCN 原模型,证明异构图构图过程中BW25 算法在通过评估关键词在病历中的重要程度方面上的表现优于TF-IDF,即频数与文本长度是中医电子病历提取特征方法的重要参数。
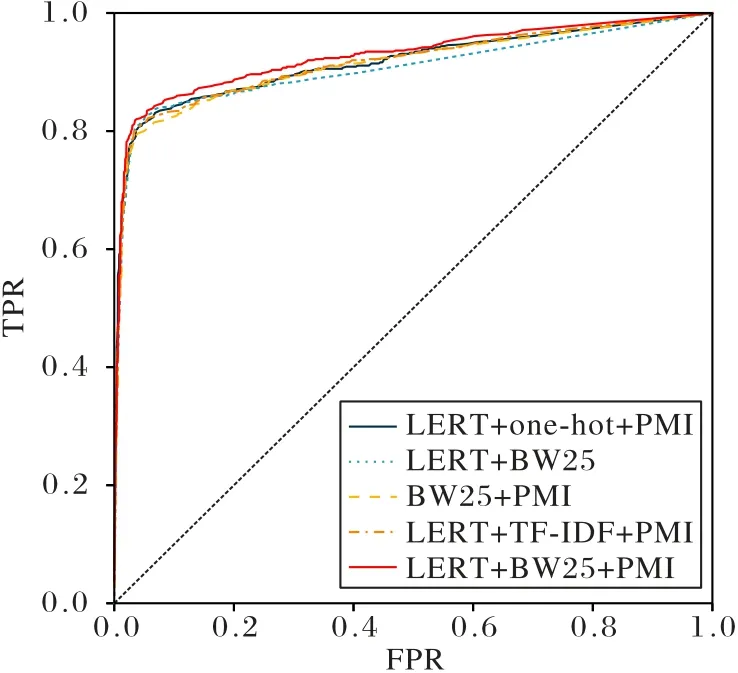
图5 消融实验中不同模型的ROC曲线Fig.5 ROC curves of different models in ablation experiments
3.6 实验总结
实验结果总结如下:
1)LERT 通过病历embedding 得到的768 维的句向量融合到图节点让图的特征更加丰富,该句向量随训练步数进行更新的方式也加强了模型的泛化能力。
2)异构图构图过程中,BM25 算法中对于频数的控制与引入文本长度作为相关性的影响因素,比TF-IDF 更适合中医电子病历数据。PMI 对于词共现的计算,适配中医电子数据前后文关联性较强的数据特征,并且能够弥补分词识别切分中医术语准确率较低所带来的不良影响。
3)LERT-BW25-PMI 所构成的文本异构图中节点-边-节点的特征传递方式有效表达了中医电子病历复杂多样的结构关系,解决了中医电子病历结构复杂多样等数据特点所导致的难以利用问题。
4 结语
本文提出了一种基于异构图表示的中医电子病历分类模型,利用LERT-BW25-PMI 构建的异构图与LERT 和GCN联合预测的方法改善了中医电子病历因为其前后文关联性强、语义不可分割、实体不连续等特点致使数据难以利用的问题。在中医电子病历数据集上的对比实验与消融实验结果验证了TCM-GCN 在中医电子病历文本分类任务上的有效性。在未来工作中,对中医电子病历的研究方向将从多疾病分类中进行,挖掘复合疾病患者的中医电子病历数据中潜在的关系,进而更好地应用到辅助中医诊断的工作上。
猜你喜欢
小学教学研究(2022年5期)2022-04-28
趣味(语文)(2021年9期)2022-01-18
数学小灵通(1-2年级)(2021年4期)2021-06-09
数学小灵通·3-4年级(2020年9期)2020-10-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
中国卫生(2016年10期)2016-11-13
