
改进萤火虫群算法协同差分隐私的干扰轨迹发布
2024-03-21 02:25倪志伟朱旭辉
计算机应用 2024年2期
彭 鹏,倪志伟,朱旭辉,陈 千
(1.合肥工业大学 管理学院,合肥 230009;2.北方民族大学 商学院,银川 750021;3.过程优化与智能决策教育部重点实验室(合肥工业大学),合肥 230009)
0 引言
随着互联网、全球定位系统(Global Positioning System,GPS)和智能设备的广泛应用,用户通过提交位置及需求等信息,可以获得基于位置的服务(Location-Based Services,LBS)[1]。在LBS 不断发展下,众包应用也逐渐发展和拓展,产生了大量的空间众包应用[2],如导航软件、美团外卖APP、滴滴快车APP 等。用户不间断上传位置数据,软件及服务器获取大量数据,这些序列化的时间、位置数据即轨迹数据[3]。发布及分析轨迹数据对市政规划、交通管理和应急预案等优化配置具有重要价值。轨迹数据包含用户隐私的个人信息,根据某一用户轨迹的起点、终点和经常停留的位置等信息可能得到用户的家庭住址、单位住址和兴趣爱好。文献[4]中记录了15 个基于位置的应用都出现了泄露位置信息的情况,所以轨迹数据发布亟须可靠的保护机制。
轨迹数据保护机制的研究,除了考虑轨迹的数据安全外,还需考虑以下3 方面问题:
1)轨迹可用性的综合评价。现有文献通常用距离误差衡量轨迹可用性[3],平均距离误差越小,轨迹可用性越高。如图1 所示,真实轨迹共生产两条干扰轨迹,虽然轨迹2 和真实轨迹的平均距离小于轨迹1 和真实轨迹的平均距离,但轨迹2 与真实轨迹的相似性更低。相似性也会影响轨迹的可用性。此外,干扰轨迹2 与原始轨迹反复交叉,这会让攻击者采用滤波等手段过滤异常,增加数据泄露的风险[5]。
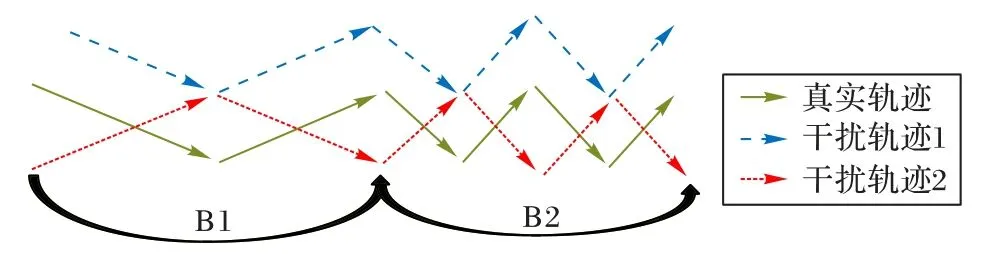
图1 不同的干扰轨迹Fig.1 Different interference tracks
2)轨迹的复杂度。假设时间戳B1 和B2 为同等时间,但轨迹复杂程度明显不同。在实际应用中,轨迹通常被作为一个位置与时间对应的有序离散数据集[3],因此根据轨迹复杂度,适当增减离散点,提取更多的特征点[6],有利于描绘更准确的轨迹。
3)生成兼顾距离误差及相似性的干扰轨迹的方法。在加噪发布干扰轨迹时,干扰轨迹由各干扰点连接生成,任何一个干扰点的有效性都会影响干扰轨迹的可用性。假设某条轨迹离散为M个时刻的点,某个位置点泛化和加噪后得到N个位置不同的点,则共有NM种组合[7]。如何得到可用性较高的干扰轨迹,属于NP-Hard 问题。
基于以上问题,本文针对历史轨迹数据发布问题,采用中心化差分隐私,建立k-匿名融合差分隐私的加密模型。通过提取显著特征点,构建加权距离评估目标,引入改进的萤火虫群优化(Improved Glowworm Swarm Optimization,IGSO)算法,实现轨迹数据先约简后泛化,再进行差分隐私加噪的基于IGSO算法寻优求解的干扰轨迹发布保护(Trajectory Protection of Simplification and Differential privacy of the track data based on IGSO,IGSO-SDTP)机制。本文的主要工作如下:
1)构建新的轨迹可用性评估指标——加权距离。加权距离同时考虑两条轨迹的相似度和距离误差,进一步提升生成的干扰轨迹的可用性和安全性。
2)提取显著位置点并简化轨迹点集。轨迹数据集中并不是每个轨迹点都具有相同的影响,因此本文提取特征点,减少非特征点数,简化轨迹点集,从而提高生成干扰轨迹的准确性和效率。
3)通过k-匿名泛化结合差分隐私的加噪方式生成满足差分隐私的位置点数据集,通过改进离散萤火虫群优化算法,以加权距离为目标函数,计算生成可用性高且安全的干扰轨迹。
4)在Geolife 数据集上通过实验验证IGSO-SDTP 方法在生成干扰轨迹中的有效性,并对参数进行相关实验。
1 相关工作
1.1 干扰轨迹发布
轨迹隐私保护和发布研究根据应用场景不同主要分为历史轨迹[3,8-9]和实时轨迹的发布[10-11]。实时轨迹数据发布一般用于各类基于位置服务的软件;历史轨迹数据发布一般用于市政、公司的数据挖掘和分析,对调整行业未来规划、资源优化配置具有重要意义。文献[3]中利用Hilbert 曲线提取轨迹分布特征,并结合个性化隐私需求,对历史轨迹生成发布轨迹数据;文献[8]中通过离散化轨迹生成多粒度系统,并构建前缀树和采用权重进行发布,提高历史轨迹数据可用性;文献[9]中提出多层次前缀树,用不同层次网络结构呈现具有不同速度特性的轨迹,提高历史轨迹可用性。实时轨迹数据隐私保护通常使用马尔可夫链、本地化差分隐私等技术。文献[10]中用马尔可夫链表示位置时序关系,提出基于凸包的差分隐私机制,保护了当前实时位置的隐私;文献[11]中基于本地差分隐私,基于真实位置生成攻击者推测的最有可能存在的位置集合,并重新定义敏感度可对轨迹发布进行实时保护。轨迹隐私保护和发布研究根据数据源类别,分为单源数据轨迹发布和多源数据轨迹发布:单源数据轨迹发布主要使用中心化差分隐私[3]和k-匿名[12];多源数据轨迹发布因为有多个数据来源,通常使用本地化差分隐私[11]在每个数据差分隐私保护后,再统一发给第三方发布,防止第三方攻击。
1.2 k-匿名和差分隐私
针对LBS 中的位置和轨迹隐私信息,吴云乘等[13]提出了不同隐私保护方法,最常用的是泛化和扰乱:泛化指将某个敏感位置替换成一个区域或者多个位置,最常用的是k-匿名;扰乱指通过添加噪声将真实位置生成假的位置进行替换,差分隐私是近年来广泛使用的扰乱方法。
k-匿名将真实信息替换成包含k个用户的空间信息,用户的真实信息与其他k-1 个用户不可区分[12]。文献[14-15]中分别通过轨迹分割、位置点扰动的方式模糊化轨迹中的用户真实特征,满足k-匿名。面对前景知识攻击、组合攻击等具备背景知识的攻击者时,k-匿名模型会失去保护作用,差分隐私[7]能够很好地解决上述问题。
差分隐私一般分为中心化差分隐私[3,16]和本地化差分隐私[17]:中心化差分隐私基于存在可信的第三方服务器存储敏感数据,经差分隐私加噪后,功能服务器获取并使用加噪数据集;本地化差分隐私指用户实时上传加噪的位置点数据,用户和服务器间传输的加噪轨迹数据实时交互。差分隐私由Dwork 等[18]提出,具有严格的数学定义和证明,主要过程是对原始查询结果添加随机噪声,攻击者即使掌握一定背景知识,也无法识别添加或删除一条记录带来的影响,从而很难推导出某条真实信息。许多学者结合差分隐私研究了不同场景下轨迹数据的隐私保护方法。文献[16]中通过时间泛化和空间分割的采样模型,使用隐私保护对轨迹数据进行双重扰动,从而保证发布轨迹数据的精度;文献[17]中对连续数值型数据进行划分变换和分段,根据分段转化为二元分类数据并进行差分隐私加噪。
k-匿名的实质是增加干扰位置,差分隐私是对现有数据进行不规则的扰动,两者并不冲突,有机结合会加强隐私保护的作用。如文献[19]中设计了一种Laplace 机制和k-匿名相结合的轨迹保护算法,对用户真实位置进行多轮加噪生成匿名组,用匿名组获取LBS 服务,增强了轨迹隐私保护效果。文献[20]中结合k-匿名和本地差分隐私,对k-匿名集中的候选位置进行扰动,在保证性能的同时降低了攻击者获取用户信息的概率。与本文方法相比,文献[19-20]都结合差分隐私和k-匿名进行加密,但文献[19]中用多轮加噪生成的匿名组获取LBS 服务,消耗隐私预算较大,且任务分配效用较低;文献[20]中的方法虽用于位置加密,但使用本地差分隐私,加密方法不同,且如果不对数据预处理,直接应用于空间众包任务分配,会显著增加位置的噪声,最终降低任务分配的效用。
1.3 萤火虫群优化算法
近年来,萤火虫群优化(Glowworm Swarm Optimization,GSO)算法[21]被广泛应用于解决调度、旅行商问题等组合问题。GSO 算法是受萤火虫群体之间智能协作启发的算法,相较于粒子群算法、蚁群算法等,具有运算较快、有较强寻优能力的优点,但算法收敛速度和全局寻优能力有待进一步提升。通过初始化、变步长、离散化和改变移动策略等方式[22-24]可进一步优化算法性能,推广应用范围。
2 理论知识
2.1 轨迹可用性评估
一条轨迹是位置与对应时间的有序数据集列表,通常表示为T=(l1,t1) →(l2,t2) →… →(ln,tn)。其中:位置li表示离散点,用经纬度表示;ti是位置li对应的时刻。本文将误差距离以及轨迹相似性两个方面都作为轨迹可用性的评估。
假设某真实轨迹T某时刻t的真实位置为lt,发布轨迹T'对应时刻位置为rt,轨迹共有n个点,距离误差(Distance Error,DE)为距离均方根总和[3],如式(1)所示:
Frechet 距离离散化的计算方式[25]如式(2)所示,常用于衡量两条轨迹的相似性,距离越小表示轨迹越相似,距离越大表示越不相似。
其中:T、T'表示两条轨迹;d(T(i(t)),T'(j(t)))表示两个采样点在时刻t的欧氏距离;infi,j,t∈[0,1]表示曲线i和曲线j之间距离最大值的下界值。每次采样时,t离散地遍历[0,1],得到最大距离max{d(T(i(t)),T'(j(t)))},即Frechet 距离。
2.2 k-匿名
定义1k-匿名。原始数据集T,泛化后的数据集T'。若T中的任意数据li在T'对应的数据中均有不少于k个近似的数据,则称T满足k-匿名[13]。
2.3 差分隐私
差分隐私具体如定义2[20],主要性质包括全局敏感度[26]、序列组合性[26]、并行组合性[27]、Laplace 噪声机制[28]和指数噪声机制[28]等。本文将相关的部分性质介绍如下。
定义2ε-差分隐私(ε-DP)。给定相邻数据集T和T'及一个算法A。若算法A 在T和T'的任意输出O满足式(4),则算法A 满足差分隐私。
其中:参数εt表示t时刻的差分隐私预算,εt越大,噪声越小,隐私保护程度越小;反之则隐私保护程度越大。
定义3全局敏感度。对查询函数f:T→Td,Δf=则称Δf为函数f的全局敏感度。全局敏感度与数据集T无关,只与查询函数f有关。
定义4并行组合性。将一个数据集T分成n个互不相交的集合{T1,T2,…,Tn},每个集合依次对应随机算法,任意Ai均符合εi-DP,则{A1,A2,…,An}在T上的并列序列组合满足(maxεi)-DP。
Laplace 噪声机制是差分隐私的噪声机制之一,向返回的结果加入符合拉普拉斯函数分布的随机噪声。Laplace 函数为式(5):
在差分隐私中,通常令μ=0,b=Δf/ε,此时Laplace 函数记为式(6):
定理1对任意函数f:T→Td,若随机算法A 的输出结果满足式(7),则称算法A 满足ε-DP。
Lap(Δf/ε)是添加的Laplace 噪声,噪声与全局敏感度成正比,与ε成反比。
2.4 显著点判断
结合文献[6]中道路拐角显著性的判断方法,对轨迹所有离散点,结合式(8)判断如下:
假设某位置点li的前一点和后一点构成的基线Lb,a长度为Len(b,a),位置点li到Lb,a垂直距离为h(如果垂足不在基线Lb,a内,则以Len(li,a)和Len(li,b)中较小者为准)。设置阈值g(c常数),若g>gc,则称该位置点显著,简化轨迹数据集时应予以保留;否则可以忽略。
2.5 萤火虫群优化算法
萤火虫群优化算法步骤依次是荧光素更新、选择移动方向、位置更新和决策域更新等阶段[21],具体步骤如下:
其中:li(t)是荧光素值;ρ是萤火素挥发系数;γ、J(xi(t))分别指增强系数和第t次迭代的目标函数值;Ni(t)是萤火虫xi在第t次迭代时比它更亮的萤火虫集合;ρij(t)指当前萤火虫xi移向更亮萤火虫xj的概率;s是步长,β为感知半径系数;nt为邻域萤火虫数量阈值;rs为邻域感知半径,(t)表示第i只萤火虫t时刻的动态决策范围。
3 方案设计
3.1 主要符号
本文符号主要包含两部分:第一部分包含轨迹数据、k-匿名、差分隐私加噪、提取显著点和数据评估等轨迹数据处理各环节的符号;第二部分包含萤火虫群优化算法及IGSO 算法运行的相关参数符号。主要参数及含义介绍见表1,算法相关参数见2.5 节和3.2 节。

表1 轨迹加噪的主要符号及含义Tab.1 Main symbols and meanings for adding noise to trajectory
3.2 IGSO-SDTP整体思路
IGSO-SDTP 具体过程如图2,分为IGSO 和SDTP 两部分,通过算法目标函数和萤火虫荧光素关联。目标函数考虑了误差距离和轨迹相似性两个方面的影响因素。
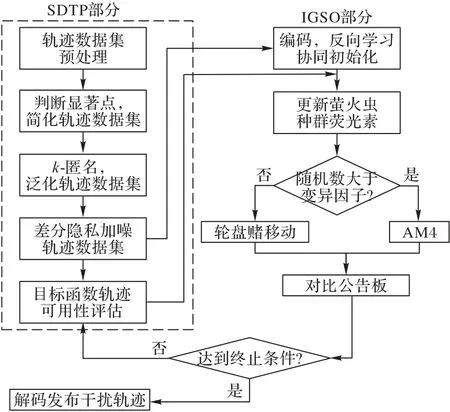
图2 IGSO-SDTP方法框架Fig.2 Framework of IGSO-SDTP method
1)IGSO-SDTP 方法步骤。
在轨迹数据的处理过程中,首先对轨迹数据集进行预处理。预处理方法是将经纬度位置坐标转化成直角坐标系坐标,再通过映射,转化到指定的数字区间。然后,运用式(8)判断轨迹数据集中的显著点和非显著点,进一步简化轨迹数据集;在k-匿名泛化时,按照式(3)要求,将简化后轨迹数据集生成具体k个近似数据的等价数据集,再利用差分隐私进行加噪;以轨迹可用性评估指标为目标函数,利用IGSO 算法从加噪后的数据集中寻找位置点的最优组合;最后,进行解码,发布寻找到的较优干扰轨迹。
2)IGSO 算法的目标函数。
目标函数构建如式(14)所示,通过构建加权线性函数将多目标问题转为单目标问题再求解。
其中:式(15)表示目标函数的约束条件;sei表示萤火虫选择的各个离散位置点的编号组合,每个点均是从1~k泛化数据集中对应时刻任意选中的一点;SEi表示对一条轨迹通过k-匿名泛化和差分隐私加噪后的数据集,通过萤火虫群优化算法对数据集n个离散点选择的编号集合;r1、r2为误差距离和轨迹相似度的权重系数,体现重要程度。其他相关公式和符号含义详见第2 章和第4 章。
3.3 改进萤火虫群优化算法
萤火虫群优化算法主要用于连续解空间问题,对于组合应用问题,要在初始解和移动策略方面进行离散化处理[29]。
1)编码和解码。
假设一条轨迹共有5 个位置点,每个点k-匿名泛化和差分隐私加噪后都分别产生4 个点。假设萤火虫每个维度与位置点依次对应,每个维度上的数字表示选择该位置点4 个点中的第几号点。xi={2,3,4,2,1}表示该干扰轨迹的第1个位置点选择的是泛化加噪后数据集对应位置上的第2 号点,第2 个位置点选择的3 号点,依此类推进行编码和解码。
2)反向学习协同初始化。
反向学习是根据反向数生成反向解的优化方法[30]。设R上d维离散点xd=[m,n],d1∈{1,2,…,d},则x在d1维的反向数定义为:
反向学习协同初始化是指在初始化种群基础上,利用反向学习获得另一组种群。根据对应目标函数,将两组种群的目标函数降序。在每组目标函数中分别选择较好一半的解空间对应的子种群,协同混合生成一组质量较好的初始化种群。
3)距离计算。
因为解空间是离散编码,故不能用原有步长计算方式。萤火虫i和萤火虫j在d维上的距离及总距离用海明距离计算,d∈[1,m],如式(17)~(18):
4)移动策略。
在随机概率(rand)小于等于变异因子p时,萤火虫i利用轮盘赌方式寻优。假设萤火虫j在第g维上优于萤火虫i,则参照式(11)的概率被该值替代。为了增加萤火虫的移动,当随机概率大于变异因子p时,引入前期工作中自适应的4 种移动策略(Four Adaptive Mobile strategies,AM4)[7],可避免算法过早过快陷入局部最优,加强算法在多维空间的寻优能力。具体移动策略见式(19):
3.4 算法伪代码描述
算法1 主要是对轨迹数据集的处理,核心是3 个步骤,先约简再泛化后加噪,详见图2 的SDTP 部分;算法2 主要是在处理后的数据集中根据目标函数寻找符合要求的干扰轨迹,详见图2 的IGSO 部分。
算法1 轨迹约简的隐私保护算法。
输入 原始轨迹数据T;
3.5 算法的时间复杂度
设种群规模为m,某条轨迹位置点n个,匿名泛化加噪后每个位置点生成k个点,每只萤火虫(n维)代表一组位置点自由组合,最大迭代数为tmax。
初始化萤火虫种群时间复杂度为O(m),计算一条轨迹组合的时间复杂度为O(nk),故每次迭代总时间复杂度为O(mnk);计算萤火虫个体间距离的时间复杂度为O(n);每次迭代中计算萤火虫个体移动的时间复杂度为O(n2);每次迭代中计算萤火虫种群位置更新的时间复杂度为O(mn2);因此IGSO 算法的计算时间复杂度为O(mn2tmax)(一般n>k)。
3.6 隐私保护分析
定理2在KT数据集加噪得到KT'过程中,IGSO-SDTP符合ε-差分隐私。
由于IGSO-SDTP 作用在KT'数据集上,T'是所有时间序列上对应位置的泛化数据集上的任意一点,所以T'是KT'的子集,符合差分隐私保护。此外,每一位置点是先进行k-匿名泛化,再进行整体差分隐私加噪处理,所以有更好的安全性。
4 实验与结果分析
4.1 数据和实验说明
实验环境为:Intel i5-10400F 2.9 GHz,16 GB 内存,Windows 10 操作系统,算法在Matlab 2016 运行,轨迹绘图使用OziExplorer 软件。本文采用Geolife 数据集[31]进行实验,该数据集收集了182 个用户从2007 至2012 年的17 621 个轨迹数据,包含时间为序的位置点集的经纬度信息。
在Geolife 抽取了6 条轨迹数据Geo1~Geo6 作为研究案例的具体数据。它们的轨迹形态、复杂程度和位置点数均不相同,6 条轨迹形态差异较大,图3 是Geo1~Geo6 轨迹数据集生成的轨迹图。其中:Geo1、Geo2、Geo4 轨迹整体运动方向是由西向东;Geo3 是由西南向东北;Geo5 是先由北向南,再由西向东;Geo6 是先由西向东,再由北向南。Geo1、Geo2 弯曲较多,轨迹曲线较复杂;Geo4~Geo6 适中;Geo3 大部分轨迹呈直线,复杂程度最简单。
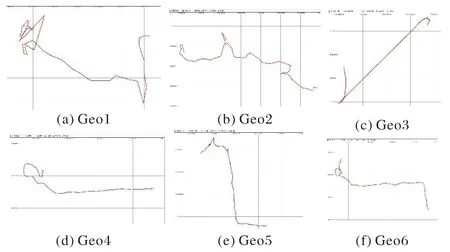
图3 Geo1~Geo6的轨迹形态Fig.3 Trajectories of Geo1~Geo6
因此,在利用显著点约简和设置判断显著点的阈值时,Geo3 采用阈值0.05,其他轨迹均使用阈值0.1,相关数据见表2。
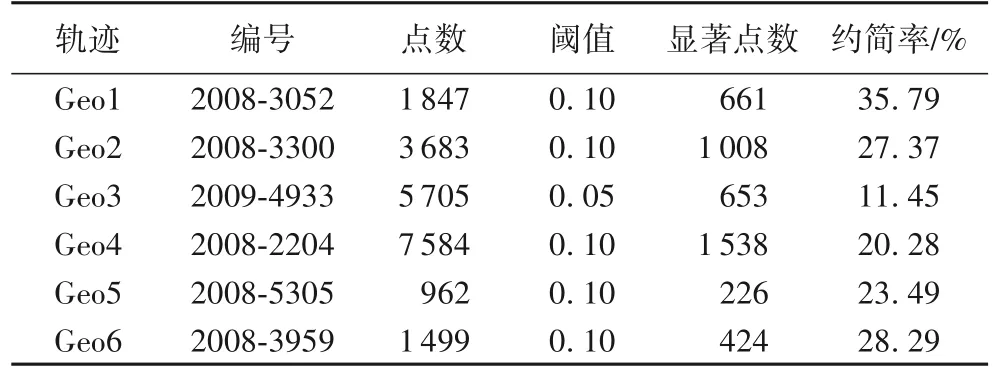
表2 轨迹数据的约简Tab.2 Reduction of track data
本文共对比了5 种轨迹进行差分隐私加噪发布的方法,具体如下:
1)RD(Differential privacy for Raw trajectory data):将原始轨迹直接进行差分隐私加噪并进行轨迹发布。
2)LIC(Linear Index Clustering algorithm)[3]:利用Hilbert曲线提取轨迹分布特征并利用位置代表元对原始轨迹进行加噪的发布方法。
3)DPKTS(Differential Privacy based on K-means shape Similarity)[5]:基于相对熵和K-means 聚类并引入Frechet 距离利用原始轨迹考虑轨迹相似性的轨迹加噪发布。
4)SDTP:显著点约简后的轨迹的加噪发布。
5)IGSO-SDTP:本文提出的使用IGSO 算法协同SDTP 方法的加噪轨迹发布。
SDTP 和IGSO-SDTP 是本文提出的两种轨迹发布方法,选择LIC 和DPKTS 作为对比方法,是因为这两种方法性能好且适用于本文的应用场景。为了避免实验结果的偶然性,案例分析及实验均取20 次实验的平均值。
IGSO-SDTP 中的参数包含IGSO 算法参数和隐私保护的参数。IGSO 算法的参数取值参照文献[24,29]中的取值经验,默认的取值为p=0.3,n=20,nt=rs=8,ρ=0.4,γ=0.6,β=0.08,r1=0.5,r2=0.5;隐私保护的参数包含k-匿名的k、距离kd、隐私预算ε,根据参数实验分析,参数默认取值为k=10,kd=0.01,ε=0.06。LIC 涉及参数Hilbert 曲线阶数h,聚簇数量k1。DPKTS 参数包括簇头数k2,隐私模型参数σ。根据文献[3,8],h=12,kl=50,k2=5,σ=0.06。
4.2 案例分析
5 种方法在发布6 条轨迹数据的距离误差见表3。SDTP的距离误差整体小于RD,说明SDTP 利用显著点简化轨迹后,删除了部分冗余轨迹位置信息,提升了轨迹位置点的有效性;LIC 的距离误差与SDTP 相当,说明利用Hilbert 曲线提取轨迹分布特征生成位置的代表元的过程,与显著点简化的作用近似;DPKTS 在Geo2、Geo3 轨迹上小于RD,在其他轨迹上大于RD,说明在生成形状相似的干扰轨迹时,可能会加大距离误差;IGSO-SDTP 整体小于SDTP,在5 种方法中的距离误差最小,说明通过IGSO 算法进一步组合寻优,可以在SDTP 基础上降低发布干扰轨迹的距离误差,进一步提高干扰轨迹的可用性。
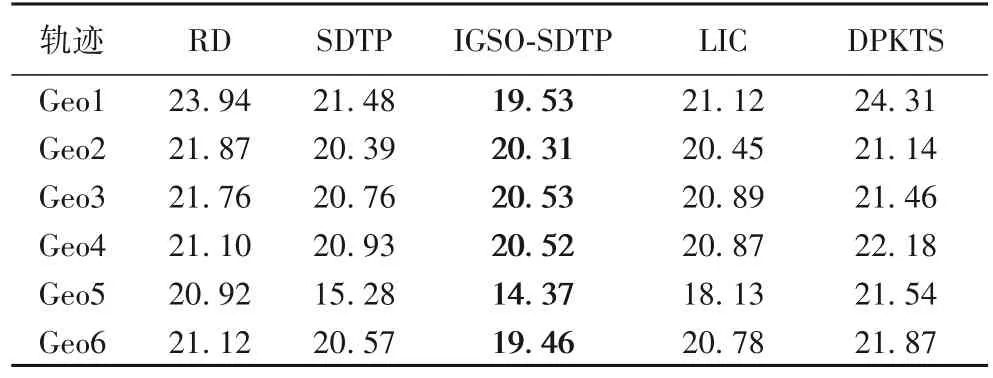
表3 不同方法的距离误差Tab.3 Distance errors of different methods
5 种方法在发布6 条轨迹数据的Frechet 距离见表4。SDTP 的Frechet 距离误差整体小于RD,这说明SDTP 利用显著点简化轨迹后,保留了轨迹的显著特征,提升了发布的干扰轨迹的有效性;LIC 的SDTP 距离小于RD 但大于SDTP,说明减小距离误差在一定程度内有利于提升轨迹的相似性;DPKTS 在Geo2、Geo3、Geo4、Geo6 轨迹上小于SDTP,在Geo1、Geo5 轨迹上大于SDTP 但小于RD,说明使用相对熵和K-means 聚类对提升干扰轨迹的相似性的效果较好;IGSOSDTP 在5 种方法中得到的Frechet 距离最小,说明IGSO 算法在SDTP 基础上组合寻优,可提升发布干扰轨迹的相似性,进一步提高干扰轨迹的可用性。
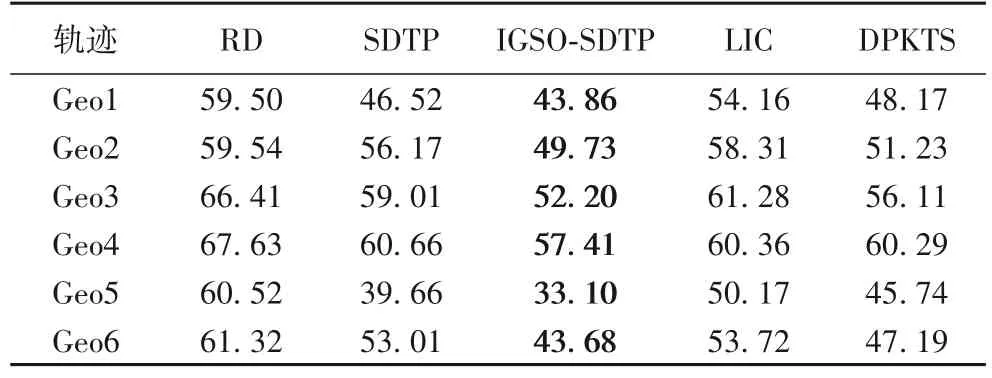
表4 不同方法的Frechet距离Tab.4 Frechet distances of different methods
5 种方法在发布6 条轨迹数据的加权距离见表5。SDTP整体小于RD,说明SDTP 利用显著点简化轨迹后,删除了部分冗余轨迹位置信息,提升了轨迹加噪发布的有效性;LIC在Geo4 计算得到的加权距离比DPKTS 大,在其他5 个数据集上计算得到的加权距离比DPKTS 小,说明DPKTS 在加权距离指标上的整体效果好于LIC。IGSO-SDTP 在不同数据集上计算得到的加权距离均最小,相较于RD、SDTP、LIC、DPKTS 分别降低了21.94%、9.15%、14.25%、10.55%。
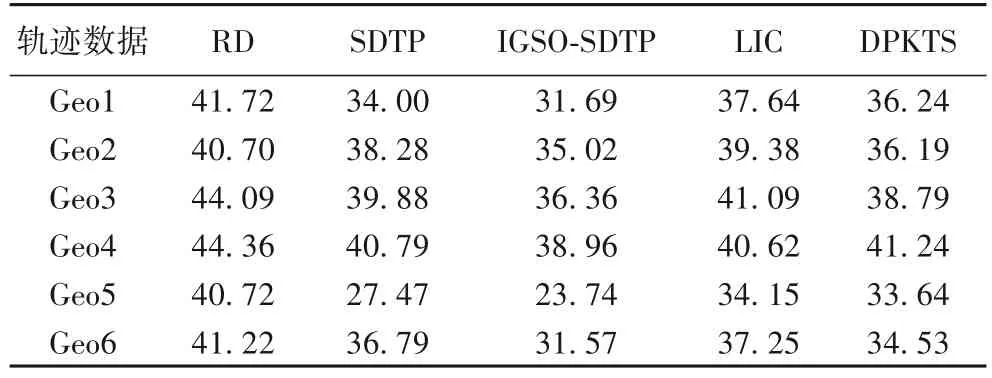
表5 不同方法的加权距离Tab.5 Weighted distances of different methods
4.3 数据集实验
采用Geolife 数据集进行实验,计算5 种方法在不同隐私预算下轨迹加噪发布的误差。表6 是5 种方法基于Geolife 数据集20 次实验计算出的平均加权距离指标。
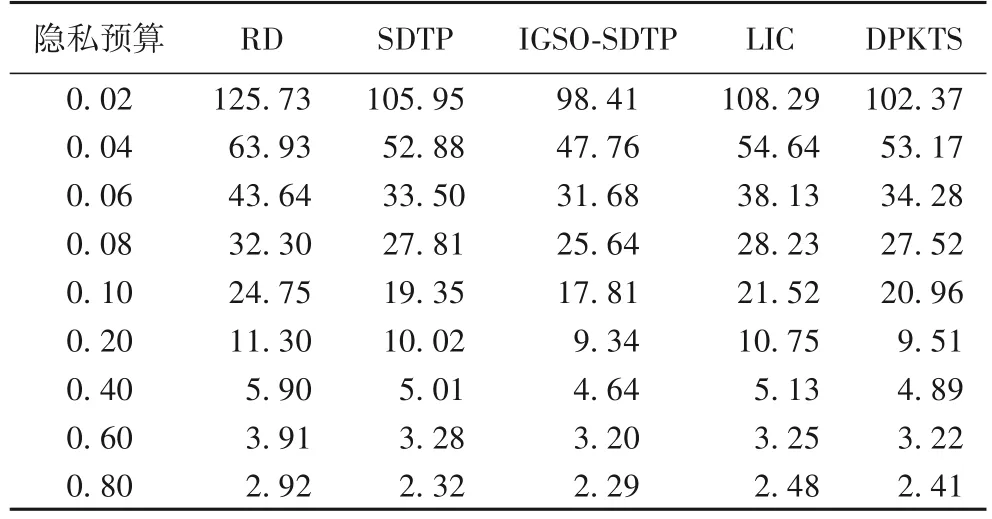
表6 不同隐私预算下的平均加权距离Tab.6 Average weighted distances under different privacy budgets
SDTP 平均加权距离整体依然小于RD,说明SDTP 利用显著点简化轨迹提升轨迹加噪发布始终是有效的;虽然在案例分析时DPKTS 基于Geo4 子数据集的计算结果比LIC 略大,但整体上DPKTS 在Geolife 数据集得到的平均加权距离比LIC 都小,说明DPKTS 利用轨迹相似性原理,不仅可以提升轨迹相似性,同时可以减小轨迹误差,总体效用好于LIC;SDTP 计算的结果在ε为0.02、0.08、0.2、0.4 时介于LIC 和DPKTS 之间,在ε为0.04、0.06、0.1、0.8 时小于LIC 和DPKTS,在ε为0.6 时,大于LIC 和DPKTS,说明SDTP 方法的稳定性较差;IGSO-SDTP 在任何隐私预算下计算的平均加权距离始终小于其他算法,说明该方法能泛化加噪并选择出较好质量的干扰轨迹,且发布的稳定性较好。
图4 是IGSO-SDTP 方法相较于其他方法在不同隐私预算下的性能提升程度。可以看出,IGSO-SDTP 方法相较于RD 方法提升最多,相较于DPKTS 提升最小。在ε<0.1 时,IGSO-SDTP 较其他4 种方法整体提升的程度较优,随着ε的逐渐增大,IGSO-SDTP 较其他4 种方法整体提升的幅度较小,说明IGSO-SDTP 在ε较小时,发布的干扰轨迹质量较高。IGSO-SDTP 相较于SDTP 发布干扰轨迹的性能有所提升,是因为基于k-匿名协同差分隐私的升维以及IGSO 算法的降维结合,进一步提升了发布干扰轨迹在距离误差和Frechet 距离两个方面的性能,降低了加权距离。

图4 不同方法的性能比较Fig.4 Performance comparison of different methods
4.4 参数分析
对影响IGSO-SDTP 性能的主要参数实验,保持其他参数不变,实验某一参数取不同值时IGSO-SDTP 在Geo1 数据集上计算得到的加权距离,并取20 次实验的平均值。
关于k-匿名的半径r参数分析如表7,整体变化是随r的增大,平均加权距离先减小后增大,当r取0.01 时,平均加权距离最小。
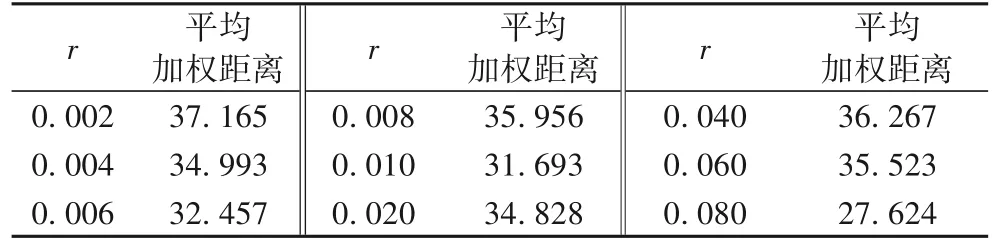
表7 半径r的取值分析Tab.7 Analysis of radius r
关于k-匿名的泛化数量k参数分析如图5,平均加权距离整体随k增大不断减小,直到k取10 后趋于稳定,因为k越大,泛化生成的位置点更均衡,加噪后得到的数据集更能寻找发布出兼顾距离误差和相似性的干扰轨迹,即加权距离较小,当k增大一定程度后,加权距离趋于稳定。

图5 参数k的分析Fig.5 Analysis of parameter k
关于变异因子p的参数分析如图6,整体变化是随p的增大,平均加权距离先减小后增大,当p取0.3 时,平均加权距离最小。
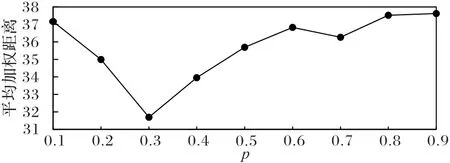
图6 参数p的分析Fig.6 Analysis of parameter p
关于显著点阈值g的参数分析如图7,虽然约简率随阈值增大持续下降,但平均加权距离先减小后增大,因为轨迹数据中的一些位置点是冗余信息,但约简率过大时,可能过滤了部分关键信息,会影响发布干扰轨迹的可用性,所以g要取适中的值0.1。
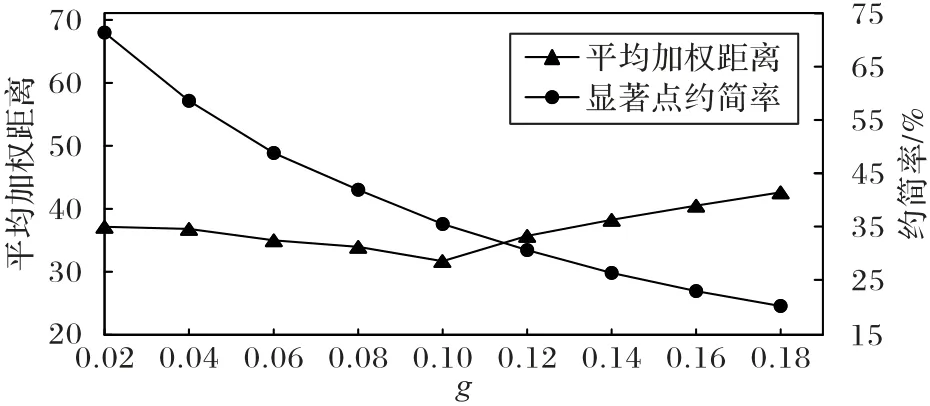
图7 参数g的分析Fig.7 Analysis of parameter g
隐私预算ε见图4,当ε取0.06 或0.1,IGSO-SDTP 方法相较于其他方法提升较大,且绝对差距在ε取0.06 较大,所以ε取0.06。
5 结语
针对历史轨迹数据加噪发布干扰轨迹的问题,本文通过显著点的判断,先对轨迹数据集进行了约简,并结合k-匿名和差分隐私对约简后的数据集泛化和加噪;通过改进萤火虫群优化算法,基于加权距离评价指标,寻找到的干扰轨迹既考虑到了距离误差,又兼顾到了轨迹的相似性,因此安全性和可用性都更好。理论分析和实验结果验证,本文方法在确保轨迹隐私的前提下,提高了干扰轨迹可用性。
猜你喜欢
包装工程(2023年24期)2023-12-27
新世纪智能(数学备考)(2021年5期)2021-07-28
海洋信息技术与应用(2021年1期)2021-06-11
小天使·一年级语数英综合(2018年7期)2018-09-12
小天使·一年级语数英综合(2017年6期)2017-06-07
为了孩子(孕0~3岁)(2016年1期)2016-01-16
小天使·一年级语数英综合(2015年8期)2015-07-06
河南科技(2015年7期)2015-03-11
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
