
面向深度学习应用的组件式开发框架的设计实现
2024-03-21 02:25魏宏原
计算机应用 2024年2期
刘 祥,华 蓓,林 飞,魏宏原
(中国科学技术大学 计算机科学与技术学院,合肥 230027)
0 引言
近年来,深度学习算法在图像识别[1]、目标检测[2]、目标追踪[3]等领域正逐渐取代传统算法[4]。随着深度神经网络(Deep Neural Network,DNN)模型和通用数据处理过程的日趋多样化,以及各种加速硬件的不断涌现,深度学习应用的软件开发难度在不断增大。一个深度学习应用的开发通常需要整合来自多个开源项目的代码,并针对底层硬件平台进行运行效率优化,开发工作量大、周期长,而且图形处理器(Graphics Processing Unit,GPU)资源利用率通常不高。GPU是深度学习的主要算力来源,但目前GPU 运行模型推理任务的资源利用率很低。例如,实时车牌识别应用中分别将YOLO(You Only Look Once)用于车辆检测、RetinaNet 用于车牌检测、LPRNet 用于车牌识别这3 个神经网络模型,在3 840×2 160 分辨率、30 FPS(Frames Per Second)帧率的视频流输入下,使用单块NVIDIA RTX2080Ti 依次推理模型时,GPU 的平均利用率仅为30.7%。
为了让开发者从繁重的代码开发、移植和调优中解脱出来,近些年出现了一些针对特定平台的组件式深度学习应用开发框架,如MediaPipe[5]、OpenVINO[6]等。MediaPipe 是Google 面向感知应用开发的流水线构建套件,允许用户通过网页前端或配置文件组合组件库的算子,构造输入和输出管道快速设计应用原型。用户可以自定义算子加入MediaPipe库,在移动端或桌面端部署应用。OpenVINO 是Intel 开发的一款面向计算机视觉应用的开发和部署工具,除支持深度学习模型部署外,还包含图片处理工具包OpenCV 和视频处理工具包Media,用于图像和视频解码和推理前后的处理等,在Intel x86 中央处理器(Central Processing Unit,CPU)上的推理速度达到了行业领先。然而,MediaPipe 在设计之初主要面向移动端,仅提供有限数量的TensorFlow 或TensorFlow Lite类的模型,无法为PyTorch 模型和桌面端GPU 提供支持。OpenVino 面向的异构加速设备主要是Intel 的核心显卡或集成显卡,并不支持目前服务器节点中广泛使用的NVIDIA GPU。
针对现有深度学习应用开发框架存在的问题,本文设计和实现了一个针对通用GPU 服务器,兼具灵活性、易用性和高效率的组件式深度学习应用开发框架。一方面,对深度学习应用中常见的通用处理过程提取和管理,降低开发者的查找和移植成本,提高代码的可复用性;另一方面,将神经网络的推理过程融入组件式开发方案,允许用户指定吞吐量和延迟的平衡策略,保证应用运行的高效性。本文使用真实交通视频进行的车牌检测识别实验结果表明,单块GPU 卡(NVIDIA RTX 2080Ti)在吞吐优先的场景下最多可以支持7路视频输入,GPU 利用率(执行YOLO、RetinaNet 和LPRNet 推理任务)达到82%;在延迟优先的场景下平均单帧端到端延迟0.73 s,延迟标准差0.57 s,可以满足实时处理的要求。本文使用框架重新开发了MediaPipe 上的典型应用(单人姿态估计和多人姿态估计)并进行实验对比。在拥有2 个CPU(40个CPU 核)以及4 个GPU(NVIDIA RTX 2080Ti)的服务器上,单人姿态估计在延迟优先模式下处理帧率提高了0.64 倍,吞吐优先模式下处理帧率提高了12.11 倍;多人姿态估计应用处理帧率分别提高了31.61倍和107.70倍。
1 框架的设计准则及主要设计问题
1.1 框架的设计目标
框架的设计目标如下。
1)易用性:组件丰富,且便于扩展组件库和移植新组件,保证应用程序编程接口(Application Programming Interface,API)的简洁。
2)高效性:利用框架开发的深度学习应用资源利用高效,并能根据平台资源作横向扩展。
3)灵活性:包括应用开发的灵活性(可通过改变组件或组件参数实现新的应用),以及应用部署的灵活性(可提供不同场景的部署方案,并根据应用偏好平衡吞吐量和延迟)。
1.2 框架的设计准则
框架的设计准则如下:
1)应用是由若干组件通过输入和输出相连构成的有向无环图(Directed Acyclic Graph,DAG),一个组件可以有0个、1 个或多个输入,也可以有0 个、1 个或多个输出。
2)有清晰的组件管理规范,以及完整的组件开发和移植规范。
3)面向开发者提供开发过程中需要用到的调试工具、运行日志、校验工具以及可视化工具。
4)提供C++编程API,以及可选的配置文件开发方式。
5)支持Python 类型的组件,支持高效的C++数据类型和Python 数据类型之间的转换,以保证Python 类深度学习项目的移植性。
6)使用C++作为主要开发语言,减少对第三方库的依赖,保证框架的低开销。
7)针对模型数多于GPU 卡的情况[7],保证单个GPU 上能高效运行多个深度学习模型。
8)保证应用设计逻辑和框架解耦,应用执行的高效性由框架保证,框架中的繁琐算法以及高性能保证的实现对开发者透明;
9)保证在大多数高负载情况下对CPU 逻辑核和GPU 的高利用率。
其中:准则1)为基本的组件式设计原则,准则2)~5)等细分小点旨在减轻用户开发过程中的心智负担,准则6)~9)旨在保证开发的应用能高效利用平台资源,实现高吞吐或低延迟。
1.3 主要技术问题及解决方案
在满足设计原则的基础上,在框架设计实现中需要重点解决以下问题。
1.3.1 组件的划分问题
基于组件库构建软件的最大特点之一是层次化程度高。层次化建模的基础是系统的可分解性,即系统可分解为若干相互作用的子系统,子系统本身又可以进一步分解。对每个子系统建立模型,就形成了层次化、模块化的系统模型[8]。
划分组件的目的是想通过以下3 点提高应用开发效率:1)增加组件的可重用性,继承以往项目中的开发成果;2)降低组件之间的耦合程度,每个组件后期可以单独修改和调试;
3)增强功能的内聚性和软件的可配置性和可移植性,使组件具有灵活的结构和清晰的接口。
组件库的开发在Linux 下GUN C 语言编译器(GNU C Compiler,GCC)环境完成,按照功能分类分级构造组件库的软件层次体系。如图1 所示,将组件库划分为功能层和实现层两个层次,其中功能层又按照其包含关系进行二级分类。

图1 组件库的分层组织Fig.1 Hierarchical organization of component library
模型推理是深度学习应用的最重要组成部分,通常按执行流程分为前处理、推理和后处理三个过程。模型推理是一个相对复杂的任务,包含CPU 处理过程(消耗CPU 资源)、GPU 处理过程(消耗GPU 资源)以及主存和显存之间的数据传输过程(消耗外围组件快速互联(Peripheral Component Interconnect express,PCIe)带宽)。GPU 作为一种批量计算设备还会涉及任务组批和分批处理,因此在对模型推理过程进行拆分时,采用更细粒度的拆分方案:不仅将前处理、后处理、分批和组批功能放置到组件库中,还抽象出了两个传输组 件(简 称 trans 组 件):transferToDeviceMemory 和transferToHostMemory,可以在主存和显存之间传递张量(Tensor)或者批量张量(Batch_Tensor)。
如图2 所示,一个YOLO 模型的推理过程被拆分为包含CPU 处理任务、GPU 处理任务和数据传输任务的7 个阶段。这种拆分方式便于将推理任务的瓶颈转移到GPU 上,从而实现较高的GPU 利用率。

图2 YOLO模型推理过程的组件拆分Fig.2 Component splitting of YOLO model inference process
较细粒度的组件拆分会增加任务间通信次数,需要高效设计底层数据结构和数据通信方式。在进行数据结构设计时需要考虑以下几点因素:
1)良好的数据结构可操纵性,以便节省操作数据时的时间复杂度;
2)较少的存储空间占用,尽量减少冗余的存储开销;
3)统一的管理方案,方便扩展新的数据类型;
4)安全性,在意外情况发生时能根据持久化的信息进行重建。
框架在存储高效性方面借助C++的预编译指令(pack)和共用联合体(union),数据结构的元信息控制在20 个字节以内:若数据本身较小,例如矩形(Rect)数据和字符串(String)数据,数据体直接相连描述数据基本信息的元数据;若数据本身较大,例如矩形(Mat)数据和张量(Tensor)数据,则将真实的数据体单独存放,元数据只存储一些基本信息和真实数据体的指针,方便数据的统一管理和扩展。
元数据和数据体的分离也可以带来某些细分操作的高效性,例如某些方法可能只需要访问元数据,而另一些方法可能只需要拷贝数据体。在安全性方面,本框架开放了保存日志的选项,如果开启数据日志,则会以文件形式记录数据流。用户借助Google 的Tracing 组件能对数据的处理时间线做可视化展示,方便进行意外中断分析以及应用快照重建。
组件间通信时仅传递数据的首地址(在64 位系统中占用8 个字节)。实际测量表明,两个组件之间的数据通信时间(从发出数据到接收到数据)可以控制在20 μs 以内。
1.3.2 GPU共享问题
模型推理主要在GPU 上执行,由于通用服务器中GPU数一般远小于模型数,多个模型推理任务需共用1 个GPU。NVIDIA 从Kepler 架构开始提供Hyper-Q[9]硬件特性,结合多进程服务(Multi-Process Service,MPS)可允许多个进程同时加载任务到一个GPU 上,并共享同一个统一的计算设备架构上下文(Compute Unified Device Architecture Context,CUDA Context)。然而文献[10-14]研究发现,在GPU 上同时执行多个任务会在任务间产生干扰,导致任务计算速度减慢,大多数情况下甚至比串行执行还慢。在数据中心联合调度训练任务和推理任务的PipeSwitch[15]采用在GPU 上一次执行一个任务的方式保证计算速度,同时通过有效的显存管理、提前绑定计算逻辑、主备worker、模型分块以及边加载模型边计算等方法减少从训练任务切换到推理任务的时间。但PipeSwitch 的任务切换方式存在以下不足:
1)边加载模型边计算的方式不能完全隐藏模型载入时间,且模型分块策略仅针对卷积神经网络设计,不能用于Transformer 模型[16];
2)经过组批后模型的输入数据往往很大,例如YOLO 模型的单次输入可达100 MB 以上,但PipeSwitch 并未试图隐藏数据传入传出GPU 的时间;
3)主备worker 方式可重叠旧任务的结束处理和新任务的初始化过程,对于模型训练任务效果很好,但对于模型推理任务过于笨重。
总之,目前尚缺少一个通用、简洁、高效的多模型推理任务共享GPU 的方案。本文框架主要从应用层面解决GPU 共享问题,提高GPU 利用率,主要通过以下两个策略实现:
1)增加数据批量,在吞吐量要求较高的场景下,输入较大的批量进行推理;
2)任务打包,将多个模型推理任务打包到一个GPU 上,在满足数据依赖和资源依赖的情况下串行执行。
其中,策略1)要提高单模型推理时的GPU 利用率,策略2)要使GPU 的空闲时间尽可能短,从而使GPU 利用率长时间保持在较高水平。以上策略在应用时会带来一些问题:
1)批量处理会带来较高的数据输入、输出时间;
2)对于实时应用而言,串行执行模型推理的切换时间不可忽略,包括模型换入/换出时间、模型启动/结束时间、计算缓存的换入/换出时间等。
本文框架通过两个trans 组件分离数据传输任务和推理任务,并在功能放置阶段将它们分开放置,实现GPU 计算和数据传输的重叠,从而隐藏数据传输时间;进一步地,将预先加载模型权重文件、提前绑定模型计算逻辑、统一管理显存等策略集成到框架实现和组件开发规范中,以减少任务切换开销。
1.3.3 流水线部署问题
在采用流水线部署的应用中,输入数据以一定的速率进入流水线,理想情形是每个阶段的处理速度一致,且刚好最大限度利用了系统资源;然而真实情形通常如图3 所示,流水线各阶段的处理速度并不一致,有些阶段的处理速度甚至低于数据到达速率,成为系统瓶颈。一旦形成瓶颈,处理负载就会堆积,导致端到端延迟不断增大。

图3 流水线瓶颈示意图Fig.3 Schematic diagram of pipeline bottleneck
消除流水线瓶颈的方法是给瓶颈阶段分配更多的资源。但流水线各阶段的处理速度与各自阶段的任务类型、平台资源、输入数据量等都有关系,难以精确刻画。幸运的是,大多数深度学习应用的输入数据来自通信频率固定的传感器,它的数据速率相对固定,例如智慧交通、智慧校园等场景下的应用[17-18]通常以固定帧率的视频作为输入数据。为此,框架对应用进行一段时间的评测,根据评测结果指导流水线分配各阶段资源,具体分为任务评测和以任务实例为单位的资源分配两个步骤。
任务评测包括测量任务对单项数据的平均处理时间Ti,以及在不同批量(batch_size)下相对于batch_size=1 时的加速比(仅针对GPU 上的任务)。图4 为根据评测结果绘制的YOLO(yolo_v5m)、RetinaNet 和LPRNet 这3 个模型在不同的batch_size下,推理一张图片的平均时间相对于batch_size=1时图片推理时间的加速比。
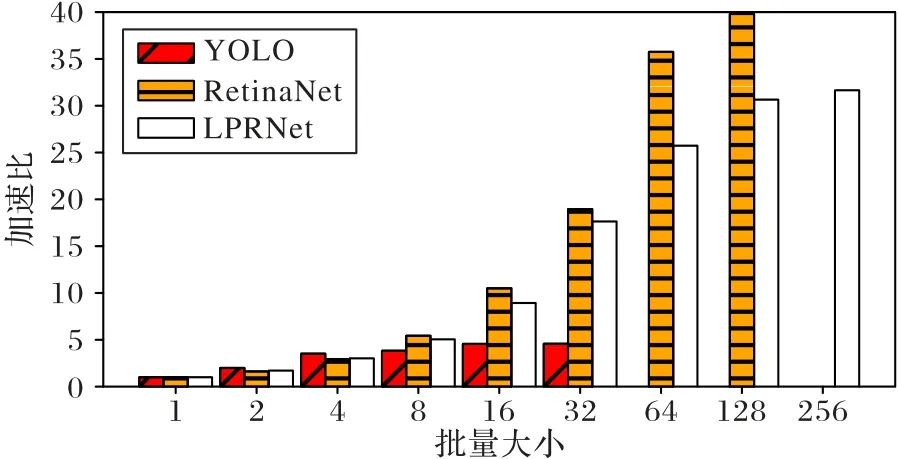
图4 不同批量大小推理加速比对比Fig.4 Comparison of inference speedup ratios under different batch_sizes
本文框架采用以任务实例为单位的资源分配方法。当一个处理过程不能在时间T内完成对数据项的处理时,增加该处理过程的运行实例数,通过任务并行提高该阶段的处理能力。具体地,对于CPU 消耗型任务fi,若评测时得到它的单项数据处理时间为Ti,则为它分配的实例数由式(1)计算:
GPU 消耗型任务需要先确定批量大小,批量大小的选择本质上是在GPU 吞吐量和应用延迟之间进行权衡。框架将选择权交给用户,引入参数scale∊[0,1]表示用户对吞吐量或延迟的偏好。对于GPU 消耗型任务fi,其batch_size由式(2)计算:
当scale取0 时,batch_size为1,对应延迟优先的情况;当scale取1 时,batch_size最大,对应吞吐优先的情况;当scale取其他值时,表示对吞吐量和延迟的综合考虑。在评测阶段提前测量推理过程fi在某个batch_size下的用时Ti,根据式(3)确定分配的实例数量:
由于PCIe 传输过程和GPU 推理过程关联,因此为PCIe传输任务分配的实例数与为对应的GPU 推理任务分配的实例数相等。
1.3.4 CPU利用率问题
以实例为单位的资源分配只考虑到消除流水线瓶颈,带来的问题是CPU 核使用数较多,CPU 利用率很低。本文框架通过对任务实例进行组合放置解决CPU 利用率过低的问题。在对任务实例进行组合放置时,需要遵循以下3 条原则。首先,由于放入同一组合的任务实例将被串行执行,因此需要并行执行的任务实例必须放入不同的组合中(互斥原则),为此以下两类任务实例必须放入不同的组合:①同一任务的不同实例;②模型推理任务及其对应的数据传输任务。其次,为使得CUDA Context 占用最少的显存,GPU 上的进程数应尽可能少,为此放置在同一个GPU 上的推理任务所关联的PCIe 任务应放入同一个组合中。最后,在满足互斥原则的基础上,最终得到的组合数越少越好(最小化原则)。
尽管本文将处理功能划分成3 种资源类型,事实上所有功能都需要消耗CPU 时间,因为PCIe 传输和GPU 上的操作都需要CPU 调度控制。特别是,GPU 任务会占用与GPU 时间等长的CPU 时间,因此,需按照以下顺序进行组合放置:①由于GPU 资源是瓶颈,应优先放置GPU 任务;②按照互斥原则放置与GPU 任务绑定的PCIe 任务;③按照互斥原则和最小化原则放置剩余的CPU 任务。
以上问题可以规约为一个分步装箱问题。共有GPU 和CPU 两种箱子,每个GPU 箱子代表一个GPU,每个CPU 箱子代表一个CPU 核。每个GPU 箱子必须唯一绑定一个CPU 箱子。GPU 箱子中只能放入GPU 任务,CPU 箱子按照可以放入的任务类型又分为CG、CT 和CC 三种箱子。CG 箱子允许放入GPU 任务和CPU 任务,CT 箱子允许放入PCIe 任务和CPU任务,CC 箱子只能放入CPU 任务,CG 和CT 箱子数相同。箱子的容量是数据流中数据项到达的时间间隔T,物品是任务实例f,物品的体积是任务实例的单项数据处理时间。
装箱问题是组合优化问题中常见的NP Hard 问题,框架采用First Fit 贪心算法进行近似求解,即按照顺序每次选择剩余容量最大的箱子进行放置。
2 框架的设计与实现
如图5 所示,框架设置了3 个层次:核心层、组件层和应用层。
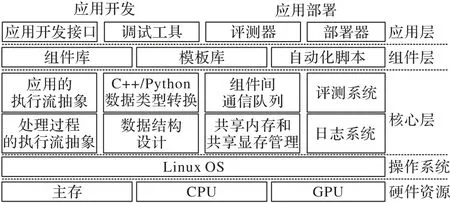
图5 本文框架的三层架构Fig.5 Three-layer architecture of proposed framework
核心层提供应用和处理过程的执行流抽象、高效的底层数据结构和C++/Python 数据类型转换、共享内存和共享显存管理、低开销的组件间通信、评测系统和日志系统;组件层提供丰富的组件库、模板库以及用于构建组件的自动化脚本;应用层提供应用开发接口和调试工具用于应用开发、评测器和部署器用于应用部署。
2.1 核心层的设计实现
核心层由Function、Executor、App、Data、Queue、Memory和Profile 这7 个模块组成。其中:Function 类提供处理过程对应代码体的静态抽象,它的子类PythonFunction 类提供C++/Python 数据类型转换;Executor 类提供处理过程的执行流抽象,同时负责管理运行时日志;App 类提供应用的执行流抽象;Data 类提供高效的底层数据结构;Queue 类提供低开销的组件间通信;Memory 模块提供共享内存和共享显存管理;Profile 类提供应用和处理过程的评测。7 个模块相互协作,为组件层和应用层提供高效服务。
2.1.1 Function类
Function 类对应组件或任务体。Function 是所有组件的基类,向下派生出PythonFunction 和GpuFucntion 两个类。PythonFunction 类中提供convertToPython 和convertToCpp 方法,提供常用C++和Python 类型的高效转换。
Function 类是所有执行任务的代码对应的静态结构。一个执行过程开发为Function(组件)需要实现以下5 个函数。
1)void star(t):任务的初始化函数,在Function 初始化时被调用一次。
2)bool waitForResource():等待资源函数,在任务的process 方法被调用前执行,采用非阻塞式结构,不满足依赖时返回false。
3)void process(&data_inputs,&data_outputs):处理函数,输入参数为输入数据集合和输出数据集合的引用。
4)bool releaseResource():释放资源函数,在process 方法执行后调用,释放资源。
5)void finish():结束函数,在Function 完全执行完后调用。
Function 采用数据驱动的方式执行,当被当前Executor(CPU 核)调度时,仅当输入数据依赖被满足(指定batch_size的数据全部到达)时,它的process 函数才会被调用执行。
2.1.2 Executor类
Executor 类对应执行器,所有的应用逻辑、任务实例都要借助Executor 来执行。一个Executor 向上承载每个任务的执行逻辑,向下绑定平台的硬件资源。每个Executor 类对应一个任务实例集合,同时绑定一个CPU 逻辑核,是连接硬件逻辑和软件逻辑的核心中介。
Executor 类的主要功能如下:
1)管理任务实例的执行,提供非阻塞式、非抢占式的轮询任务调度方案;
2)提供共享内存和共享显存的操作接口,供组件层调用;
3)管理任务逻辑在执行器的额外工作,包括环境初始化,向共享内存管理器和共享显存管理器下发命令,以及在运行期间采集信息和记录日志等。
Executor 根据它绑定的任务实例集合,在初始化阶段决定是否需要进行Python 环境或GPU 运行环境的初始化。在GPU 运行环境初始化阶段会进行Torch 的初始化,并根据App 提供的信息引导显存空间的申请,以及控制显存空间句柄的发送和接收。
2.1.3 App类
App 类对应应用,所有应用都需要借助App 执行。一个App 向上承载指定的应用逻辑和部署逻辑,向下管理若干个Executor,是从应用逻辑到硬件执行逻辑所要经历的第一关。
App 类的主要功能如下:
1)在App 运行前检查上下游组件的输出输入数据类型是否匹配;
2)管理Executor 的生命周期,在应用开始执行时统筹所有Executor 的初始化,并启动所有Executor 执行;
3)为Executor 提供一些全局信息,例如哪些Executor 被绑定到同一个GPU 上,或者该Executor 在某个GPU 上的序号。
App 通常在主进程中建立,与每个Executor(对应子进程)都有两个传递命令的管道(分别用于接收命令和发送命令),并负责管理Executor 的生命周期。
2.1.4 Data类
Data 类对应不同任务间传输的数据,所有任务的输入输出都以Data 类的对象作为媒介。Data 下维护9 个子类型,分别为存储图片的Mat、存储字符串的String、存储矩形坐标的Rect、存储网格信息的Mesh、在主存中存储单个张量的Tensor 和存储多个张量的Batch_Tensor、在显存中存储单个张量的Gpu_Tensor、存储多个张量的Batch_Gpu_Tensor 以及仅用于数据初始化的Unknown 类型。
Data 数据类型还包含3 个id,分别为用于标识应用的app_id、标识流的flow_id 和标识请求的request_id。一些Data类型中只包含数据的元信息(String、Rect、Gpu_Tensor 和Batch_Gpu_Tensor),另有一些Data 类型(Mat、Mesh、Tensor 和Batch_Tensor)会额外申请数据体空间,用于存放相对较大的连续数据,元信息中附加存放数据体首地址。Data 类提供面向指定内存地址的构造方案,方便开发者在共享内存中创建Data 类型。事实上,由于不同Executor 执行流在不同的子进程中,所有的Data 类型都是在共享内存中被创建和使用。
Data 类可以扩展子类型,扩展时需要指定新的type 标识和3 个id 属性,其余部分的存储结构可以按照1.3.1 节的原则自行设计。
2.1.5 Queue类
Queue 使用C++泛型实现多生产者多消费者队列,提供阻塞和非阻塞发送和接收API。底层基于共享内存的环形队列实现,通过atomic 库模拟自旋锁的方式实现进程间互斥。框架使用Queue 传递Data 类型的指针,实现组件之间的消息传递。
2.1.6 Memory模块
Memory 模块首先封装了一个基本的共享内存池类SharedMemoryPool,该类可以提供共享内存中相同大小数据单元的连续存储。在共享内存池类的基础上,Memory 模块构造了共享内存管理器smm,smm 包含了9 个固定的共享内存池(维持基本的框架功能)和1 个用于自定义的共享内存池容器。9 个固定内存池为Data、Mat4K、Mat1080P、Mat720P、Mat540P、Tensor10M、Tensor1M、Tensor100K 和Tensor10K 内存池,分别用于存储不同类型或不同大小的数据,内存池的容量大小可以根据配置文件自行指定。一个自定义的共享内存池容器可以根据需求使用smm 自行创建和删除共享内存池。
Memory 模块还包含一个共享显存管理器类gpu_smm,gpu_smm 接管整个GPU 显存,将整个显存划分为数据存储区、模型区和计算区。数据存储区用于缓存输入输出数据,模型区用于存储模型权重,计算区用于模型推理时存储中间数据。数据存储区划分成多个数据存储单元(block),每次数据传输时申请一个block,传输完后释放。框架会在PyTorch 插件(针对PyTorch 的Cache 层编写的插件,提供申请/释放显存空间、申请/释放显存块等API)的基础上提供操纵显存的C++API,供App 类和Executor 类在操作显存中使用。相关的Python API 跟随PyTorch 插件编译至PyTorch 库,供深度学习推理组件和trans 组件调用。
2.1.7 Profile类
Profile 类主要评测应用和处理过程,汇总和处理每个Executor 运行过程产生的时间戳信息,产生应用运行日志并统计应用运行时的资源消耗,为应用层部署器的决策提供底层信息参考。
2.2 组件层的设计实现
组件库目前共实现了Image、Model、Tool 这3 类共36 个基础组件,涵盖实时视频流的推拉,图像的变形、裁剪、仿射变换和标记,5 个常用深度学习模型的前处理、后处理和推理过程,2 个主存和显存之间传输的trans 过程,与批处理相关的组批、分批过程,与流控相关的多流聚合和多流分离过程,为开发新组件也提供了丰富的模板和范例。
框架提供groupByRequestId 和SplitByFlowId 两个与流控相关的组件,用于多流应用中面向相同类型数据的多流聚合和其后的多流分离,在聚合和分离的过程中主要使用了Data中携带的flow_id 信息。由于多流应用中多数处理过程与流无关,即对于处理任务,只是增加了输入数据流的密度,因此可以在单流输入数据负载较小时,通过扩展应用服务范围对输入数据源进行横向扩展,实现对批量计算硬件的充分利用。
2.3 应用层的设计实现
应用层提供丰富的组件、简洁的应用开发和部署API,以及相关开发、调试和部署工具。API 主要分为以下几类:①构建应用DAG 的连接类API(connect、connectOneByOne、connectOneToMany、connectManyToOne、connectOneFanMany、connectManyCollectOne);②扩展多实例的expand;③用于打印App 信息的help。
图6 中,f 表示处理过程(function),q 表示队列(queue)。图6 列举了6 种不同连接关系的API,在满足多样化开发需求的基础上,力求简洁规范易用,减少开发者的心智负担。在框架的examples 文件夹下实现了6 个经典应用,涵盖了所有API 的使用,为开发者开发应用提供范例和参考。

图6 应用开发API示意图Fig.6 Schematic diagram of application development API
3 应用实例
本章通过一个车牌号识别应用的开发和部署实例说明框架在应用开发和部署过程中的简洁性、易用性和灵活性表现。
3.1 应用描述
车牌检测识别应用以交通路口的高清摄像头视频流作为输入数据,提取进入检测区域的所有车辆的车牌号,绘制在图片的右上角。图7 为该应用的一个效果,可用于车辆追踪和车流密度检测等。

图7 车牌号识别应用效果Fig.7 Rendering of license plate number recognition
3.2 应用开发
实现3.1 节应用需要车辆检测、车牌位置检测、车牌号识别等功能。经过调研,最终用YOLO(yolo_v5m)模型作车辆检测、RetinaNet模型作车牌位置检测和端到端的LPRNet模型作车牌图片到车牌号码字符的转换。在以上3 个模型的基础上,再结合一些常规的图片处理过程,就能够构造出一个实时车牌号检测应用。图8为该应用构建的处理任务DAG。
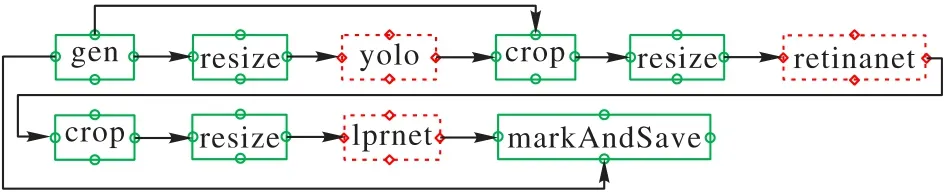
图8 构成车牌号检测应用的DAGFig.8 DAG of license plate number recognition application
根据处理流程的DAG 及性能要求在组件库中选取组件。在实际开发时,可以根据组件的输入参数作检测效果和检测速度的权衡。图9 为使用CPU 进行推理的低速版本,图10 为在GPU 上进行批量推理的高速版本,批量推理时的批处理大小可以通过参数指定。

图9 CPU推理版本的关键代码Fig.9 Key code for inference version on CPU

图10 GPU推理版本的关键代码Fig.10 Key code for inference version on GPU
框架还提供了使用MarkDown 文档构建应用的方式。图11 展示了CPU 推理版本的MarkDown 文档输入。
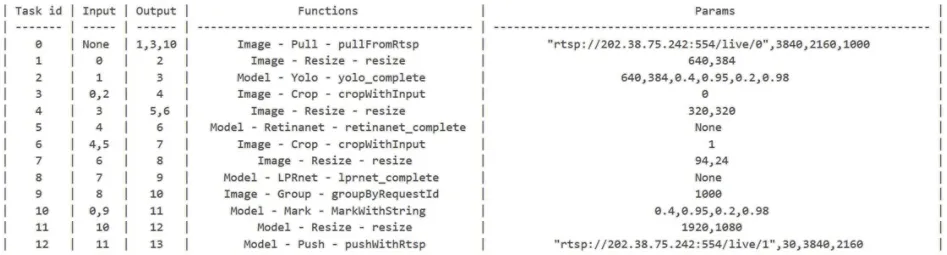
图11 使用MarkDown方式开发应用Fig.11 Application development using MarkDown
得益于丰富的层次化组件设计和多种构造函数重载,通过调整各处理过程的输入参数可进行例如检测范围的改变、标识位置和颜色的更新、输出视频流的分辨率大小调整等。如图12 所示,改变一些组件和参数,就能得到一个车辆统计应用。
框架提供标准化的流程和丰富的模板范例用于新组件的开发和移植。例如,移植一个YOLO 模型至组件库遵循以下流程:
1)下载ultralytics/yolov5 项目至本地,并下载模型权重文件(本例使用yolo_v5m.pt)至本地文件夹;
2)在根目录文件夹中新建yolo.py 文件,提取preprocess和postprocess 过程接口,封装于yolo 类;
3)运行框架提供的create_Python_GPU_Function.py 文件,在命令行参数中指定yolo 项目的根目录、yolo.py 文件路径和yolo_v5m.pt 权重文件路径;
4)框架根据模板生成yolo_preprocess.h/.cpp、yolo_inference.h/.cpp、yolo_postprocess.h/.cpp 和新的yolo.py文件,并编译入基础组件库。
3.3 应用部署
在定义了应用的处理逻辑后,需要进行应用的部署。本框架提供3 种部署方案:纯手动部署、半自动部署和全自动部署。不同部署方案适用的场景不同,对应着对开发者不同的开放自由度。
3.3.1 纯手动部署
框架提供expand API 用于扩展某个阶段或多个连续阶段的实例数,提供cpus_map 和gpus_map 两个参数指示任务实例所放置的CPU 核或GPU。使用此种方式部署车牌识别应用的关键代码如图13 所示。

图13 纯手动部署关键代码Fig.13 Key code for pure manual deployment application
纯手动部署方案提供了直接面向硬件进行资源分配和功能放置的底层接口,是半自动部署和全自动部署方案的基础,给部署人员提供了最高的自由度。
3.3.2 半自动部署
半自动部署是指部署人员可以结合框架提供的工具进行自动化的评测,评测器根据平台硬件环境和运行环境给出流水线各阶段的实例分配数及功能放置方案,部署人员可以直接使用此方案或在此方案的基础上进行调整。图14 为评测器统计的各阶段消耗的CPU 时间。

图14 各阶段耗时统计Fig.14 Time consumption statistics of each stage
半自动化部署要求部署人员对软件执行情况和服务器硬件资源有基本认知和了解,可用于专业人员的定制化部署。
3.3.3 全自动部署
全自动部署直接调用部署器的deploy 函数,部署器调用评测器,根据评测结果和自动化算法进行资源分配和实例放置,其函数原型为:
void deployer::deploy(float scale);
此种部署方式借助1.3.3 节和1.3.4 节中提及的资源分配和实例放置方式,只需指定scale值就能将部署方案编译进应用的可执行文件中,不需要部署人员额外干预,是应用开发者的一键式部署方案。
3.4 扩展到多路输入(多流)
上述应用可以通过使用 groupByRequestId 和splitByFlowId 组件改变应用的DAG 逻辑,将应用扩展到多路输入。图15 展示了一个四路视频输入的实时车牌号检测应用的处理流程DAG。
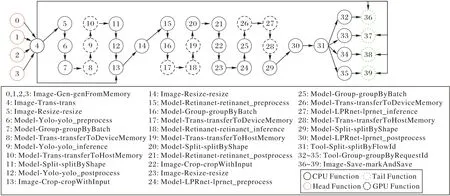
图15 四路视频输入的车牌号检测应用DAGFig.15 DAG of license plate number recognition application with four-way video input
4 实验验证
4.1 实验环境
实验在一台AMAX Super Server X11DPG-QT 上运行,包括2 片Intel Xeon Gold6230 CPU(每个CPU 包含20 个逻 辑核)、4 块NVIDIA GeForce RTX 2080Ti GPU、376 GB 内存和PCI-E 3.0 X16。操作系统为Ubuntu16.04,编程语言为gcc-6.5.0,Python3.8.0,采用深度学习框架PyTorch1.7.0,软件库OpenCV4.5.4。
4.2 吞吐量和延迟
4.2.1 实验目的
实验旨在验证框架在深度学习应用开发时的有效性。首先,通过一段时间的运行,验证应用运行时的稳定性(不会产生数据项堆积);其次,通过对CPU 利用率和GPU 利用率等指标的测量验证框架对平台资源的利用效果。最后,通过观察scale值对资源利用率以及应用延迟的影响,验证scale值对应用吞吐/硬件延迟偏好的调节效果。
4.2.2 应用描述
本实验选用3.1 节中的车牌识别应用进行框架开发有效性的验证。车牌号识别应用使用支持多流的GPU 推理版本,采用全自动部署方式,scale值设置为0、0.5 和1。应用的输入为四路分辨率为4K(3 840×2 160)、帧率为30 fps 的视频流,采用实时流传输协议(Real Time Streaming Protocol,RTSP)格式从流服务器拉取;输出为四路1080P(1 920×1 080)、帧率为30 fps 的视频流,实时推流到流媒体服务器。数据源来自手机拍摄的交通路口视频(https://gitee.com/blazarx/ traffic_video_dataset)。
4.2.3 实验结果
在应用运行过程中统计所支持的最大路数、资源使用量、资源利用率、平均单帧延迟和延迟标准差,实验结果如表1 所示。
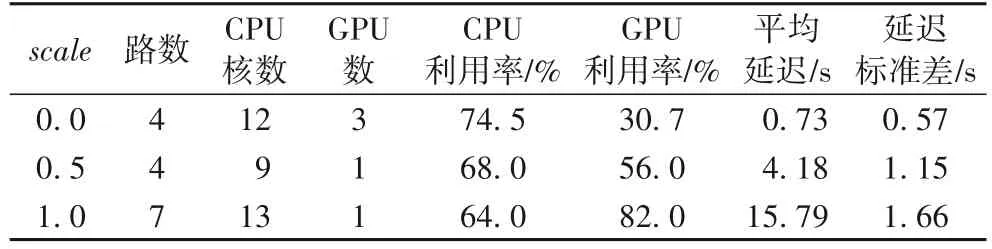
表1 不同scale下的吞吐量和延迟Tab.1 Throughput and latency under different scale
在吞吐优先模式(scale=1)下,单块GPU 卡最多可支持七路视频;在延迟优先模式(scale=0)下,可得到0.73 s 的应用延迟,能够满足此应用的实时性要求;在吞吐和延迟的均衡模式(scale=0.5)下,单块GPU 卡最多支持四路视频,得到1.15 s 的应用延迟,是吞吐量和延迟综合考虑的结果。CPU单核利用率在三种模式下平均为68.8%,GPU 利用率在吞吐优先模式下可达到82%。
实验结果表明,车牌识别应用能在快捷开发和全自动部署模式下正确平稳运行,能根据用户意愿在不增加开发负担的前提下,对硬件的使用作横向扩展(CPU 核和GPU),在吞吐优先模式下能获得较高的GPU 利用率,在延迟优先模式下能获得较低的应用延迟,并且在三种模式下都能得到较高的CPU 利用率。
4.3 与MediaPipe的开发和性能对比测试
4.3.1 实验目的
本实验旨在通过与MediaPipe(针对移动端需求设计且被广泛使用的深度学习应用构建框架)在开发成本和运行效率上的对比,验证框架针对CPU-GPU 异构服务器进行深度学习应用开发时的独特优势。其中,开发成本可用代码行数来衡量,实时视频流应用的运行效率使用运行时能够达到的最大帧率衡量。
4.3.2 框架和应用描述
本文选用MediaPipe 支持的经典应用,基于BlazePose[19]的单人姿态估计以及与YOLO(yolo_v5m)相结合的多人姿态估计。应用在Python 环境下采用MediaPipe 提供的Python API 开发,其中,mediapipe.solutions.pose.Pose 函数参数MODEL_COMPLEXITY=1(中等复杂度模型)。作为对比方案,选取 BlazePose 的 PyTorch 版(https://github.com/WangChyanhassth-2say/BlazePose_torch)的开源项目作为原项目,进行组件开发和移植,其余组件选用组件库中已有方案,选用最细粒度的组件划分方式。
人体姿态估计应用将每帧视频中人体和手部共33 个关键点标识出来并连成骨架,可用于人员数量统计、人体动作捕捉、手势识别等诸多应用。图16 是多人姿态估计应用的其中一个输出帧。

图16 多人姿态估计应用效果Fig.16 Effect of multi-person pose estimation
应用的输入和输出为分辨率为720P(1 280×720)、帧率为23 fps 的视频流。数据源来自网络上真实舞蹈大赛视频(https://www.youtube.com/watch?v=pObHe2A8ID4&ab_channel=TranslationSIT)。
4.3.3 实验结果
实验比较应用的开发成本(代码行数)和执行效率(最高支持的处理帧率),实验结果如表2 所示。

表2 与MediaPipe的开发成本和运行效率比较Tab.2 Comparison with MediaPipe on development cost and operating efficiency
在开发成本方面,使用本框架开发的应用代码行数(C++API)与使用MediaPipe 开发的应用代码行数(Python API)相近。在运行效率方面,单人姿态估计应用在延迟优先模式下,相较于MediaPipe 获得0.64 倍的帧率提升,吞吐优先模式下获得12.11 倍的帧率提升;多人姿态估计应用中分别获得31.61 倍和107.70 倍的帧率提升。
4.4 实验总结
在4.2 节中,通过对车牌号检测应用在不同scale值下的应用延迟、CPU-GPU 资源占用量及资源利用率等指标的评测,验证了框架开发深度学习应用的有效性,展示了框架在各个关键问题,如流水线部署问题、GPU 共享问题和资源利用率问题上的解决表现。4.3 节将框架和MediaPipe 在开发成本和运行性能进行对比,说明了框架在CPU-GPU 异构的服务器平台下应用运行性能优势。综合两个实验结果可得,该框架能够作为CPU-GPU 异构服务器上面向深度学习应用开发部署的有效解决方案。
5 结语
本文针对深度学习应用缺少开发与部署工具的问题,提出一个组件式的深度学习应用开发框架。就框架设计过程中的组件划分问题、GPU 共享问题、流水线部署问题以及由此带来的CPU 利用低效的问题做了详细的考量,并给出了解决方案。在考虑深度学习应用的特点、组件间的通信开销、应用的资源利用方式和应用的部署方式之后,设计并实现了应用开发和部署一体化的三层软件框架。
通过应用开发和部署实例以及性能对比实验表明,本工作基本上实现了框架初始设计时提出的易用性、高效性、灵活性等目标,说明了框架在实际的应用开发和部署场景下的实用性和有效性。框架能根据吞吐和时延偏好作出对硬件方面的自适应扩展,为面向流式数据的深度学习应用提供了有效的开发部署方案。
本文框架尚存在许多不足,还有很多进一步的工作可以完成,现结合需求以及技术的发展趋势,总结3 点如下:
1)框架目前仅对视频流应用提供支持,无法完成其他模态的应用开发。应用开发和框架完善是一个互相迭代的过程。在之后的工作中,可以对更多类型的应用进行考量,进一步增加框架组件库的丰富度。
2)当前深度学习领域前端框架和后端平台类型十分丰富。本文框架目前只对PyTorch 类型的前端框架和CPU、GPU 等部署后端提供支持。后续可以面向更多硬件的存储特点及编程范式进行分析、考量和设计,对更多种类的硬件平台提供支持。
3)当前面向特定硬件的深度学习部署加速工具在不断发展进程之中。为了得到在相应硬件上更高的模型推理效率,框架需要面向主流推理引擎做兼容性设计。
猜你喜欢
能源工程(2022年2期)2022-05-23
成都信息工程大学学报(2021年5期)2021-12-30
今日农业(2021年7期)2021-07-28
重型机械(2020年2期)2020-07-24
非公有制企业党建(2020年5期)2020-06-16
装备制造技术(2019年12期)2019-12-25
太空探索(2016年9期)2016-07-12
太阳能(2015年11期)2015-04-10
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
