
全景视频基于块的视口自适应传输方案综述
2024-03-21 02:25李俊杰望育梅李志军
计算机应用 2024年2期
李俊杰,望育梅,李志军,刘 雨
(北京邮电大学 人工智能学院,北京 100876)
0 引言
随着相关领域技术和硬件设施的发展,全景视频,或称360°视频及虚拟现实(Virtual Reality,VR)视频也快速发展。“元宇宙”时代的到来使全景视频与工业生产、日常生活的联系越来越紧密。全景视频以沉浸式、交互式的体验备受人们关注[1]。虚拟现实与物联网、人工智能、大数据等技术的融合催生了更多的产业与应用,促进了VR 生态的蓬勃发展。据研究报告数据,VR 产业规模预计将以每年15%的增速增长[2],VR 产业总产值在2029 年预计达到2 273.4 亿美元[3]。
全景视频的高质量传输给现有的网络传输系统带来了一定挑战[4]。
其一是全景视频传输时所需的高带宽。与传统视频相比,全景视频是3D 球体视频,允许用户自由选择观看的视角[5],任意地探索视频中呈现的内容。全景视频包含更多的信息量,同分辨率下全景视频的数据量是传统视频的4~6倍[6]。除此之外,用户观看全景视频需要佩戴头戴式显示器(Head Mounted Display,HMD),由于人眼距离屏幕更近,对视频分辨率大小更加敏感。一般来说,为了保证用户的体验感,全景视频的分辨率一般要求在4K 及以上[7],传输所需带宽将会随之上涨至400 Mbps[8]。现有网络传输系统中,只有少部分可以满足该传输要求[9]。
其二是全景视频传输需要低时延。为避免观看者产生眩晕感,头动时延(Motion To Photon,MTP),即从用户头部开始移动到相应画面渲染、呈现给用户的时延,应尽量控制在20 ms 以内[10]。
综上所述,全景视频数据量大、对时延敏感的特性[11]给现有的网络传输带来了很大的挑战。如何在资源有限、时变的网络条件下传输全景视频,保障用户体验质量(Quality of Experience,QoE),已成为当前全景视频领域的研究热点。
由于人眼特性和HMD 的固定视野范围,用户无法看到全部的视频区域,只有大概20%能被看到[12],这部分区域即通常所称的视口区域(Field of Viewport,FoV)。鉴于以上特性,理论上来说,只需要传输FoV 范围内的视频内容就可以满足用户的观看需求,从而大幅减少带宽消耗[13]。基于此,学者们提出了基于tile 的视口自适应传输(Tile-based Adaptive Streaming)[14],对视口区域和非视口区域做出智能决策,从而减少带宽的消耗。在该传输系统中,主要包含两个重要的模块:一是视口预测模块,负责根据用户当前视口信息,预测下一时刻的视口位置;二是码率分配,基于视口预测的结果与可用的网络资源生成码率分配方案,对视口与非视口区域进行差异化传输。在基于tile 的视口自适应传输系统中,只需要传输视口区域内的tile 便可以满足用户的观看需求。实际上,视口预测模型难以准确预测用户未来的视口位置,一旦预测错误,通常会造成视口区域内对应的画面质量降低,进而影响用户的体验质量[15]。除此之外,码率分配算法需要在资源有限的时变网络中生成最优的码率分配策略,优化用户的体验质量[16]。因此,在自适应传输系统中,视口预测与码率分配算法的性能一定程度上决定系统性能的好坏。
本文基于当前全景视频的主流的传输方案,即基于tile的视口自适应传输方案,重点讲述该系统中视口预测和码率分配两个重点模块。从不同的视角,归纳总结该领域的研究现状与发展。
1 全景视频传输框架
在全景视频应用中,为了保障用户的沉浸式体验,需要传输高分辨率的视频,并且传输时延要控制在20 ms 内。全景视频的上述特性给现有的网络传输带来了较大的挑战,亟须优化全景视频传输系统。
1.1 全景视频传输原理
动态图像专家组(Moving Picture Experts Group,MPEG)在2015 年发起了面向全景视频封装格式的标准化制定工作,由此产生了第一版全景视频标准,即全向媒体格式(Omnidirectional MediA Format,OMAF)。OMAF 标准中阐明,全景视频从采集到播放主要包括全景视频采集、拼接、映射、编码、传输、解码、渲染和播放等[17]。全景视频传输框架如图1 所示。
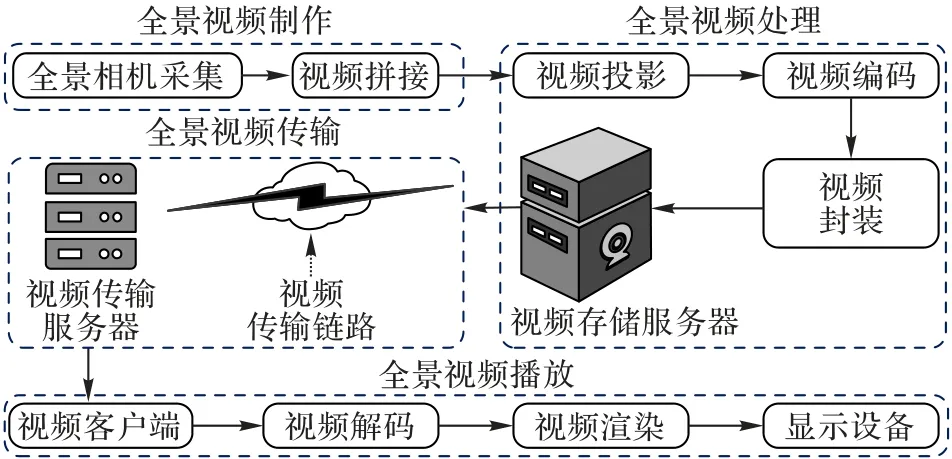
图1 全景视频传输框架Fig.1 Transmission framework of panoramic video
目前全景视频的采集通常由多个普通摄像机按照一定规律摆放,同步对实景进行拍摄。视频采集后,并不能直接得到所需的球体视频,而是从不同方位不同视角拍摄的视频集合。要得到球体视频,需通过视频拼接技术,将多方位摄像机采集的视频拼接得到全景视频。伴随着硬件设施的发展,全景视频采集技术日渐成熟,目前已有全景视频专用摄像机,可以提供视频采集和拼接的一体化服务,极大地方便了全景视频的制作。
尽管传统视频的编码方案已有丰富的研究基础,但针对全景视频的编码方案仍未完全成熟。为了编码全景视频,目前主流解决方案是将全景视频映射到二维平面上、再对它使用传统视频编码的方案,这一映射过程称为视频映射。在OMAF 标准中,指定支持两种投影格式,即等矩形映射(EquiRectangular Projection,ERP)[18]和立方体映射(Cubic Mapping Projection,CMP)[19]。除此之外,高通提出的金字塔棱台映射(Truncated Square Pyramid projection,TSP)[20]也是常用的映射方法。各映射格式示例如图2 所示。ERP 由地图映射发展而来,是目前主流的全景视频映射方法。ERP 在球体的纬度上,按照赤道的采样频率对视频内容进行采样,然后生成宽高比为2∶1 的平面图像[21]。ERP 简单、直观,但在两极处像素采样密度大于赤道,两极处画面扭曲较大。CMP 是另外一种常见的映射方法。该方法在球体视频外部构造一个外接立方体,然后从球体中心向外投射光线,从而缓解了两极处的扭曲。CMP 压缩效率比ERP 更高[22],但是在正方体的边缘和拐角处,会产生更大程度的扭曲;同时,CMP 映射得到的视频画面不连续,进而会影响图像处理的效果。TSP 将全景视频投影到截断金字塔的6 个平面上,然后拼接画面。相较于ERP 映射格式,TSP 画面失真小,同时一定程度上解决了CMP 画面不连续的问题,更利于视频编码与图像处理。

图2 常用映射格式示例Fig.2 Examples of common projection formats
视频映射后,即可对全景视频进行编码处理。目前流行的编码方案是高效视频编码(High Efficiency Video Coding,H.265/HEVC)[23],而较早的高级视频编码(Advanced Video Coding,H.264/AVC)[24]也仍被广泛使用。此外,2020 最新发表的多功能视频编码(Versatile Video Coding,H.266/VVC)[25]在原有编码方案的基础上,作了更多扩展,可以更好地支持全景视频传输。
1.2 全景视频传输方案
传统流媒体视频一般通过DASH(Dynamic Adaptive Streaming over HTTP)[26]协议进行传输,该协议是当前最流行的视频流传输协议之一。DASH 根据网络带宽自适应地调节待传输视频序列的码率,从而保证用户在网络波动时也能享受到流畅的观看体验。DASH 使用媒体描述文件MPD(Media Presentation Description)描述服务器端存储的视频属性和分片信息[27]。其中,自适应码率(Adaptive Bit Rate,ABR)是DASH 协议中重要组成部分,通过对网络吞吐量及播放器缓存器状态的评估,作出传输下一视频块的码率等级的决策。
如何保障用户流畅、沉浸式的观看体验是全景视频无线传输目前的最大挑战。目前,全景视频的传输主要分为全景传输与视口自适应传输。
全景传输是将全部全景视频区域以等质量的形式无差别地传输给用户。显然,这种方案简单、直接,可以保留全部的视频信息;但由于FoV 仅占完整视频的20%左右,全景传输方案不仅会造成明显的带宽资源浪费,而且容易导致高时延[28]。因此,学者们根据用户视觉特性,提出根据用户的FoV 动态调整传输区域,将更多的带宽资源用于提升FoV 内的视频质量。简单来说,即FoV 内的视频区域进行高质量传输,而FoV 外的则对应较低质量传输或甚至不传输。
基于tile 的视口自适应传输方案是视口自适应传输方案的一种,也是当前主流的视口自适应传输方案。如图3 所示,该方案将DASH 与tile[29]思想相结合,将视频区域分割为若干个矩形区域,进一步提升了带宽的利用率。对任一全景视频,首先在时域范围内被分为若干个等长的时间块,通常称之为chunk 或segment。每个chunk 在空间域上被分为若干个等大小的矩形块,即tile。每个tile 都以多种分辨率、不同质量等级的版本存储在服务器中。客户端首先通过视口预测算法判断FoV,自适应码率分配算法则根据当前的网络带宽、FoV 等信息做出传输方案智能决策,从而大幅减少带宽的消耗,并提升用户的体验质量。
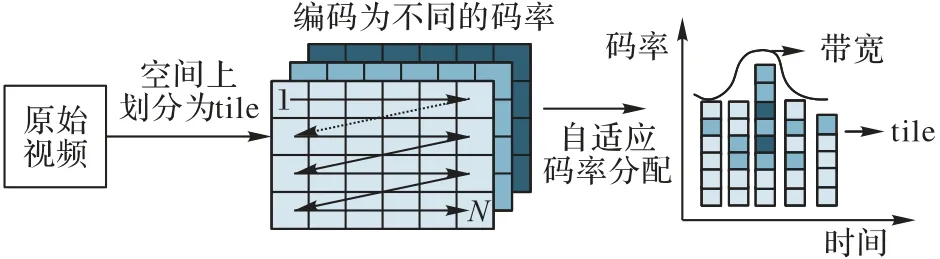
图3 基于tile的视口自适应传输方案Fig.3 Tile-based viewport adaptive streaming
基于tile 的视口自适应传输方案通过视口预测机制,可以有效减少带宽的浪费。在同等网络状况下,将更多的带宽用于提高FoV 内的视频质量,维持用户的沉浸式体验;然而,若用户当前视口与预测视口不符,会出现黑屏或视频质量降低等问题。即使在精准预测用户视口的情形下,同样需要高效率的自适应码率分配算法,以适应不同的终端设备与网络条件。综上所述,视口预测可以适应用户的头部移动,自适应的码率分配算法则能够适应网络状况的变化。在视口自适应方案中,视口预测算法和自适应码率分配算法与传输系统性能好坏关系密切[28],而用户质量评估则是系统性能好坏的关键评估指标。
2 用户质量评估
用户体验质量是客户对服务体验的满意度或烦恼度的度量,反映了视频传输系统下用户体验感受,常被用于评估传输系统的性能。在波动的网络状况下,传输全景视频容易发生卡顿、画面质量频繁切换等现象,进而影响用户的体验质量。在全景视频传输系统中了解如何评估用户的体验质量,成为设计全景视频自适应传输方案的首要问题。
MPEG 标准化协会将QoE 评估主要分为主观评估和客观评估两种。主观评估指由用户对体验质量从多个层次、分等级评分,能直接反映用户对视频质量的感知,但易受用户主观意愿的影响;客观评估基于数学模型选择合适的指标衡量视频质量,可以自动计算,无需过多的人为干预。
2.1 主观质量评估
用户体验质量是一个主观的概念,受到人主观因素、系统因素和视频内容等的影响。全景视频中涉及人与内容的交互,主观评估可以更准确地反映用户的体验感好坏。
目前,全景视频主观质量评估方法大都在传统视频评估方法的基础上进行研究。国际电信联盟(International Telecommunication Union,ITU)提出使用绝对等级评分(Absolute Category Rating,ACR)和失真等级评分(Degradation Category Rating,DCR)评估QoE。平均意见评分(Mean Opinion Score,MOS)是最常用的ACR 评分方法之一。该方法将视频内容呈现给大量的体验用户,然后要求用户按1~5 的分值评分,分值越高表示用户的体验感越佳。该方法不需要参考原始视频,直接评价处理后的视频。差分平均意见评分(Differential Mean Opinion Score,DMOS)是DCR的常用评估指标,常被用于评估失真视频和原始视频质量之间的差异,比较适合评估压缩方案对画面质量的影响或者不同算法之间的直接性能比较。
2.2 客观质量评估
传统2D 视频中常用的客观评估指标同样可用于全景视频。常用的客观指标包括峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、结构相似度指数(Structural SIMilarity index,SSIM)[30]等。尽管一些传统的客观评估指标仍能适用,但由于全景视频中独特的画面畸变、压缩伪影等使传统的评估指标难以满足全景视频场景下的评估需求。例如,由于人眼对画面质量的感知存在差异,PSNR 难以和用户的感知质量保持一致。鉴于此,学者们基于传统的视频评估指标,结合全景视频的视觉特性,提出了许多全景视频专用的评估指标。
在JVET(Joint Video Experts Team)会议[31]中,采纳了WS-PSNR(Weighted-to-Spherically-uniform PSNR)[32]、S-PSNR(Spherical-PSNR)[32]和CPP-PSNR(Craster’s Parabolic Projection-PSNR)[33]作为全景视频质量的评价标准。与PSNR 不同,WS-PSNR 对全景视频的不同区域的像素点分配不同的权重值。WS-PSNR 直接在二维平面上计算,而S-PSNR 在球上均匀采样若干个点,然后将它们重新投影到参考和扭曲的全景图像[34]上,再计算PSNR。相比WS-PSNR,S-PSNR 直接在球域上计算,计算复杂度更高,且采样点所占比例较低。CPP-PSNR 专用于克拉斯特抛物线投影,将全景视频用该投影格式后得到二维视频,再计算所得图像的PSNR。同样地,为了适应球体视频,基于SSIM 提出的WS-SSIM(Weighted-to-Spherically-uniform SSIM)[35]和S-SSIM(Spherical-SSIM)[36]使用类似WS-PSNR 的权重函数,弥补全景视频的画面失真,更能真实反映全景视频用户的感知质量。
截至目前,尽管学者们已提出多种QoE(Quality of Experience)评估指标,但在实际应用中,这些指标仍难以精准反映用户的观看体验。特别是在全景视频领域,由于影响用户体验质量的因素极为多样且复杂[37],加上不同用户的偏好差异,主观与客观评估指标之间的不一致性成为一个显著的挑战。这一现象不仅揭示了现有评估方法的局限性,也强调了开发更为精准和个性化评估工具的迫切需求。未来的研究需致力于探索综合考虑个体差异和多元化体验要素的新型评估机制,以更真实地反映和提升用户的全景视频体验。
3 视口预测
3.1 视口预测概述
视口预测是自适应传输方案中的关键技术。由于全景视频的时延敏感特性,为了避免用户头部随意移动时FoV 出现黑块或者视频质量急剧降低[38],必须提前预测FoV,并把相应的视频区域预存于播放缓存,从而保证用户始终能够流畅地观看视频。
一般来说,视口预测主要可以分为与内容无关和与内容相关的预测方法[39],如表1 所示。与内容无关的视口预测方法只依赖用户先前的视口位置信息预测未来时刻的位置,一般基于HMD 内传感器采集到的一段时间内的历史轨迹信息预测用户未来时刻的视口位置,因而常被称为基于历史轨迹的预测方法。根据是否采用单用户轨迹预测,基于轨迹的预测方法又可进一步分为基于单用户轨迹和基于多用户轨迹预测。与内容相关的预测方法通常基于视频的显著性进行视口预测。显著性预测通过智能算法模拟人的视觉系统特点,预测人类的视觉凝视点和眼动,提取图像中人类感兴趣的区域(Region of Interest,RoI)。除此之外,学者们还提出同时基于视频内容与历史轨迹的视口预测方法,该方法与用户的历史轨迹和视频内容相关,视频内容可以进一步分为基于目标追踪和基于显著性,两者分别使用视频内物体的运动轨迹和图像显著性代替视频内容。

表1 视口预测算法概述Tab.1 Overview of viewport prediction algorithms
3.2 视口预测研究现状
由于用户的视口位置在时间上具有一定的相关性,因此视口预测问题常被建模为时间序列预测问题。一些传统的时间预测方法被广泛应用于该场景,包括线性回归、概率统计和机器学习等。现有的一些视口预测方法基于头部运动历史轨迹,使用较简单的模型预测未来的视口位置。例如平均值(Average)[40]、线性回归(Linear Regression,LR)[41]和加权线性回归(Weighted Linear Regression)[42]。文献[43]中基于1 300 多个数据集测试,比较了线性回归(Linear Regression,LR)、岭回归(Ridge Regression,RR)和支持向量回归(Support Vector Regression,SVR)在不同预测时间长度的准确率,发现:当预测间隔在1 s 内,LR 能取得最佳效果;当预测间隔大于1 s,RR 可以提高预测算法的鲁棒性。学者们还提出基于用户头部的多项移动数据,对用户未来视口进行预测,例如:文献[44]中提出基于用户观看时候的位置信息、头部转动速度以及加速度,建立一个频率驱动(Frequency-Driven)预测模型;类似地,文献[45]中将用户的头部移动数据综合建模成一个向量,包括了用户头动速度与加速度;文献[46]中通过用户的角速度与角加速度预测用户的未来视口位置。
然而,这些模型结构通常比较简单,难以很好地挖掘用户的复杂行为。当用户头部快速移动时,准确率通常难以保持较高水平。随着深度学习与强化学习理论的成熟与发展,学者们提出应用深度学习的方法,解决视口预测准确率低的难题。一些研究结果表明,卷积神经网络(Convolutional Neural Network,CNN)[47]和循环神经网络(Recurrent Neural Network,RNN)[48]在视口数据集上的测试取得了较好效果,证明深度学习网络模型用于视口预测可行。Bao 等[49]提出使用长短期记忆(Long Short-Term Memory,LSTM)网络模型提高预测算法在长期预测的准确率。Xu 等[50]建立了用于头部运动预测的深度强化学习模型,根据头部的运动提取FoV,并在长期预测取得了90%以上的准确率。Lee 等[51]在LSTM 中引入了注意力模块,使用LSTM 和门控递归单元(Gated Recurrent Unit,GRU)更精准地预测全景视频中的用户头部位置。
同时一些学者提出视口预测算法的误差分布服从一定的规律,可以将用户的头部运动视为概率事件,构建一个概率模型描述视口预测误差的分布,用特定的分布拟合视口预测的误差,从而减小算法预测的错误概率。Xie 等[52]指出LR的误差分布近似于高斯分布,并分别对描述用户头部的3 个角度(roll,yaw,pitch)的预测误差建立高斯分布模型。Zou等[53]发现使用LSTM 预测视口时,误差分布更接近拉普拉斯分布。Jiang 等[54]提出视口预测误差分布更接近t Location-Scale 分布。在视口预测中,预测误差可以建模为系统噪声。Kalman 滤波器基于隐马尔可夫的经典模型[55],常用于预测含噪声的系统的状态,因此Kalman 滤波器也常被用于预测用户的头动轨迹[56]。尽管如此,现有的误差分布函数大多都是静态的,无法适应视频播放时预测准确率的变化,误差在时域内不断累积,导致视口预测算法在长期预测时可靠性降低。也就是说,只考虑单用户的历史轨迹信息,在短期预测虽然可以取得较高的准确率,但是预测间隔一旦增长,预测方法的可靠性难以保障。
除了考虑单个用户的历史轨迹,一些研究者发现不同用户观看同一视频时常常表现出相似的观看模式,探索跨用户行为的相似性可以弥补视口预测结果与实际值不匹配的缺陷。文献[57]中同时使用了LR 与K近邻(K-Nearest Neighbor,KNN)算法,既考虑了用户的历史位置信息,又考虑用户之间行为相关性对初步预测结果进行修正,使用KNN聚类进一步提高预测算法的准确率。文献[58]中考虑用户观看模式的相似性,对tile 的观看概率进行统计分析,并将高频次出现的tile 与FoV 预测结果取并集,从而一定程度上提高视口预测算法的准确率。文献[59]中通过识别用户轨迹,利用用户之间观看行为的相似性提高传统线性回归方法的准确率。文献[60]中分别对描述用户头部位置的3 个角度建模,并使用聚类算法将相似的轨迹分为不同的子类,分别计算每个子类的轨迹函数。文献[61]中使用了一种基于密度的DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类算法,先将用户分类,再通过支持向量机(Support Vector Machine,SVM)预测用户的类别,以预测不同类别对应的观看轨迹。
除了基于历史轨迹的与视频内容无关的视口预测方法,另一类是内容相关的视口预测方法,通常基于视频内容的显著性特征进行预测[62]。全景视频显著图示例如图4 所示(颜色越深代表显著性越高)。一般来说,视频显著性的高低反映了用户感兴趣的程度,视频内容的显著性越强,相应被观看的概率就越高,因此显著性高的区域内的tile 对应高的传输码率。在传统视频中,卷积神经网络常被用于显著性检测。对于全景视频中的显著性预测,一些文献[63-65]中直接将传统视频的显著性检测模型应用至全景视频,但是传统视频的显著性检测模型通常并不适用于全景视频。由于全景视频在经过ERP 后,画面会产生不同程度的扭曲,这种来自空间变化的扭曲失真使传统CNN 的权重共享无效,导致显著性检测效果变差。
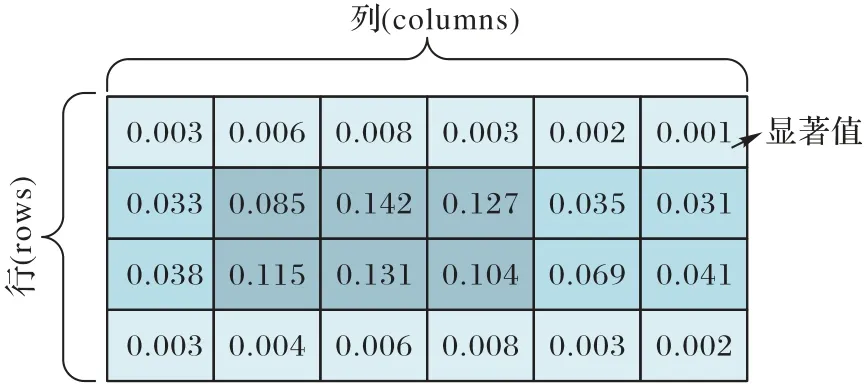
图4 全景视频显著图示例Fig.4 Example of panoramic video saliency map
为了使传统视频显著性检测的研究成果可以应用至全景视频,学者们提出了多种方法,例如通过线性加权将传统视频的显著图转化为全景图像的显著图[66],或者通过迁移学习使传统图像显著性检测模型能够适应全景图像的显著性检测[67]。文献[68]中使用浅层网络进行显著性检测,并使用迁移学习的方法生成深度网络。文献[69]中使用三维卷积神经网络(3-Dimensional CNN)提取视频的时空特征,包括显著性图、移动图等,并与基于历史视口的预测方法相比,在预测准确率上表现更佳。为了消除画面扭曲造成的影响,一种方法是将全景视频转换为多个透视图[70-72],并在每个透视图上使用传统CNN 进行处理;但是,这种方法并不能消除失真,而只是将影响降到最低。例如文献[72]中提出了一种用于全景视频的显著性预测网络,以CMP 格式的视频帧和光流作为输入,再通过解码器和双向卷积LSTM 对这些特征进行显著性预测;但因为CMP 映射格式画面不连续,可能影响显著性预测性能。除此之外,文献[73-75]中采用另一种方法策略,通过改变卷积方法抵消失真的影响。例如文献[74]中提出了一个新的框架SphereNet,根据球面图像表示的几何形状调整卷积滤波器的采样网格位置,并将滤波器包裹在球体周围,以避免图像失真带来的影响。
除此之外,还可以将用户的历史轨迹与全景视频的内容相结合进行视口预测。文献[76-78]中认为用户的观看区域主要受视频内运动的物体的影响,应结合目标追踪算法进行视口预测。文献[76]中通过YOLOv3(You Look Only Once v3)算法识别视频内物体的运动轨迹,并使用差分整合移动平均自回归模型(Auto-Regressive Integrated Moving Average,ARIMA)时间序列预测的方法初步预测用户的未来视口位置,然后使用被动攻击回归算法,修正预测结果。文献[79]中同时基于用户的历史轨迹和图像显著性图,使用LSTM 预测用户视口,采用预训练的VGG-16 网络提取视频视觉特征,与位置信息级联经Flatten 层处理后输入双层LSTM 网络。文献[80]中基于用户先前视口位置与视频内容预测未来视口位置,使用LSTM 初步处理,然后与空间显著特征级联拼接,联合输入到Inception-ResNet-V2 的网络。文献[81]中提出了基于深度卷积网络的显著性模型PanoSalNet 提取显著特征,然后将位置信息映射成掩码,输入到双层LSTM 网络中。文献[82]中采取了上述类似的方法,在文献[81]方法基础上增加了一个修正模块,补偿预测值与实际值的差异。然而,在大量的数据集上测试后发现,现有的同时基于视频内容与历史轨迹的预测方法在测试时,性能都低于较新的仅基于历史视口的预测方法[39]。所以,一些学者在最新的一些研究进展中另辟蹊径,结合两种预测模型,并将两种模型的预测结果整合得到最终的预测结果。文献[38]中提出的视口预测方法中,基于历史视口得到第一次视口预测结果,将它记为固定视口;然后基于Spherical Walk 方法[83](将用户的头部运动视为在球体上行走,并基于从一点到另一点的球体运动来预测未来视口位置)得到第二次视口预测结果,即为扩展视口;最后对两次预测结果取并集,得到最终的预测视口区域。综上所述,学者们提出了多种方法提高视口预测算法的准确率。基于已有的研究成果,现有的基于单用户的视口预测方法在短期预测可以维持较高的准确率。随着预测间隔变长,预测的准确率将会大幅度降低。基于内容显著性特征与跨用户行为的相似性可以一定程度上克服该缺陷。从相应的技术手段看,越来越多的深度学习模型用于内容显著性估计与视口预测。相较于简单的回归模型,基于深度学习的视口预测算法在长期预测场景下表现更佳。
4 码率分配
4.1 码率分配算法概述
视口自适应传输方案基于人们的视口位置进行选择性传输,为视口内区域提供高质量传输,其余部分以低质量传输[84]。自适应码率(Adaptive Bit Rate,ABR)算法(或称码率分配算法)基于视口位置信息,进行智能决策。码率分配算法通过选择合适的码率版本,为终端用户提供最佳的用户体验质量。为了保障流畅的播放体验,除了依赖于准确的视口预测,在时变网络环境中如何高效地进行码率分配对保障用户的体验质量也至关重要。现有的全景视频自适应码率分配算法大多借鉴了传统视频的ABR 算法,并考虑全景视频的特性,对传统的ABR 算法进行了改进。
总体来说,现有的自适应码率算法可以分为4 类:基于吞吐量(Throughput-based)、基于缓存区容量控制(Bufferbased)、混合控制(Hybrid)和基于学习(Learning-based)。Throughput-based 与Buffer-based 分别通过考虑网络可用带宽和缓存区的容量生成码率分配方案;Hybrid 一般综合考虑带宽、缓存区容量和时延等多方面因素,构造自适应码率模型;Learning-based 强调从系统环境中学习,基于历史的播放器状态找到最合适的码率分配策略。全景视频传输中自适应码率分配算法的基本逻辑如图5 所示,码率分配算法主要包括资源估计模块和自适应逻辑模块。资源估计模块负责收集网络状况或者缓存区的容量信息。自适应逻辑则根据当前的网络状况或者缓存的容量向视频服务器请求合适的码率,将请求的视频版本预存在视频播放缓存区中,供用户观看设备渲染及播放,以优化用户的体验质量。
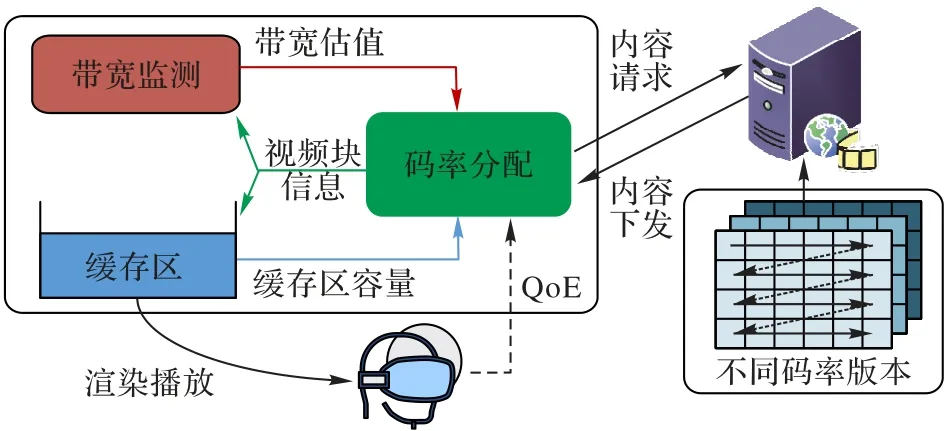
图5 全景视频自适应码率分配算法Fig.5 Adaptive bit rate allocation of panoramic video
4.2 自适应码率算法研究现状
自适应码率分配算法可在时变的网络环境中兼顾画面的质量和视频的流畅播放,同时提供更好的用户体验质量。从自适应码率分配算法被提出以来,业界涌现了许多经典的算 法,包 括Festival[85]、MPC(Model Prediction Control)[86]、BBA0[87]、Elastic[88]、BOLA[89]和Pensieve[90]等,算法概述如表2所示。全景视频传输系统中的自适应码率算法考虑了全景视频的视觉特性和QoE 模型等,在传统视频经典的算法的基础上作出了改进。

表2 码率分配算法概述Tab.2 Overview of bit rate allocation algorithms
在全景视频场景中,最简单、直接的自适应码率分配算法ERP[91]被广泛应用于视频平台(例如YouTube)等。该方法对视频进行ERP 投影后,将视频在空间域划分为若干个tile,在带宽的可用范围内,对每个tile 分配等质量的码率。这种方案简单、直接,但由于非视口区域会占用很多的带宽,造成带宽浪费的同时,还降低了视口区域内的画面质量。许多改进方案在视口区域与非视口区域选择传输不同的码率版本。文献[83]中提出CTF(Center Tile First)的策略,即对位于视口区域中心的tile 优先传输高质量的视频版本。文献[92]中对现有经典的基于tile 传输方案进行综述,统一实验条件下发现,相较于非tile 的传输方案,基于tile 的传输方案在视口区域内的PSNR 更优,且不易受视频块chunk 的时长和缓存区大小等因素的影响。
文献[52]中提出使用QoE 驱动的优化方法,在有限的带宽资源下,为每个tile 分配码率,最大化用户的QoE。为了求解码率分配中QoE 最大化的问题,将码率分配问题建模成其他的数学问题,并使用不同的算法模型解决问题。文献[93]中将码率分配算法转换为整数线性规划问题(Integer Linear Programming,ILP),减少了76%的带宽消耗。文献[94]中提出了QoE 模型,考虑了画面亮度、视觉深度等因素对用户体验质量的影响。同时提出了大小可变的tile 方案,使用模型预测控制(MPC)算法为每一视频块内的tile 分配对应的码率,在达到相同画面质量的情况下,可节省40%左右的带宽资源。文献[43]中综合考虑了多种QoE 的影响因素,包括缓存时间、FoV 内视频质量与相邻视频帧之间质量的切换,并将该问题建模为效用函数,使用MPC 求解效用函数最大时的码率分配策略。效用函数与用户体验质量直接相关,从而进一步优化用户的体验质量,并节省35%的带宽资源。文献[57]中提出码率分配是典型的非确定性多项式完全问题(Non-deterministic Polynomial,NP-Complete Problem),可以将其视为背包问题(Knapsack Problem)求解。类似地,在文献[11]中也将码率分配算法建模为背包问题,并使用贪心算法穷举码率分配方案,极大地提高了传输后的视频画面质量。文献[16]中使用贪心方法不断计算每个tile 的传输花费与性能提升,找到综合效益最优的传输策略,输出最终码率分配结果。文献[95]中利用多用户数据组合成一个整体模型,基于预测的用户视口位置,计算每个tile 的优先级,再通过束搜索的优化方法,根据每个tile 的优先级为它分配对应的码率。为了确定服务器端最佳的编码方案,以最大化客户端观看质量,文献[96]中将QoE 优化问题分为不同带宽下的类优化问题和存储限制下最大化用户感知质量的全局优化问题,并分别采取不同的算法分别求解;该方案不仅计算速度快,且视口区域内画面质量更高。
由于视口预测的误差会对码率分配产生较大的影响,学者们提出了双层(2-tier)的全景视频传输系统。文献[97]中将视频分为基础背景层与增强层,客户端根据对QoE 的提升动态决定选择tile 的码率。利用Lyapunov 优化理论中的漂移加罚(Drift Plus Penalty)方法解决QoE 优化问题,在视口质量、视口质量变化与视频卡顿上有了显著的优化。类似地,文献[98]中将整个全景视频分为基础层和增强层。基础层对所有的视频区域传输一个低质量的视频版本,防止预测误差导致的视口区域黑块现象;增强层则根据视口预测的结果,对FoV 叠加更高质量的视频版本,保障FoV 内的视觉感知质量;且对不同层的码率分配方案可以根据视口预测的准确率进行调整,从而增加了码率分配算法对视口预测的容错率,保障了用户的体验质量。文献[99]中将全景视频划分为两种质量等级:一是原始视频对应的质量等级,二是通过将原始质量减半得到的较低质量的视频。该方案仅考虑视口位置,对视口位置内的tile 分配最高的码率,对视口以外的tile 则分配较低的码率。
除了2-tier 的系统以外,还尝试根据视口位置,将tile 划分为不同的类别,再根据类别分配码率。文献[38]中根据视口预测结果将tile 分为预测视口(Estimated Viewport)区域、外部(External)区域和背景(Background)区域;再分别计算不同类别tile 的权重因子,根据各tile 的权重分配对应的码率。文献[100]中同样将视频所有的区域分为FoV 的中心区域、边缘区域和外围区域,并考虑缓存区的容量和可用带宽使得视频播放的时空平滑性最佳,即相邻chunk 和相邻tile 的质量切换最小。文献[101]中将视频区域分为视点区域(Viewpoint Region)、边缘区域(Marginal Region)和未观看区域(Not-Viewed Region),划分的不同区域由不同的速率失真模型表示,通过联合考虑速率失真模型和视口预测精度自适应码率分配策略。文献[102]中根据视口位置将不同tile 划分为3 个不同的优先级。在全景视频流传输时,根据优先级为不同的区块分配不同的比特率。为视点所在tile 分配高码率,为水平、垂直两方向上的tile 分配中等码率,为其余4 个顶角方向的tile 分配低码率。除了固定的tile 划分方案,自适应的tile 划分方案可以增加传输系统对视口预测算法的容错率,保障用户的体验质量。文献[103]中采用自适应的tile 分配方案计算每种tile 划分方案对应的惩罚值,最后基于MPC算法求解对应tile 方案下最佳的码率分配策略。文献[104]中采用popularity-aware 的tile 划分方式,即基于多用户的视口信息分布,计算视频区域的观看频次,进而得到观看频次最多的区域,标记为macrotile,再将QoE 优化问题建模为NPhard 问题,求解最佳的码率分配策略。文献[105]基于视频内容与用户观看行为,提出一种自适应的tile 分块方式,将tile 划分为tcurrent、tneighbor与tmerged三类。基于视频画面复杂度与用户观看区域,计算各tneighbor的NGS(Normalized Growing Speed)指标值。其次,选择NGS 最大的tile,将它合并,与固定分块的方式相比,大幅降低了全景视频传输所需的带宽需求。
伴随着基于视频显著性的视口预测方法的发展,衍生出了一类Saliency-driven(显著性驱动)的码率分配算法。文献[106]中指出基于显著性的码率分配算法具有优化用户体验质量的巨大潜力。基于显著性预测结果将整个画面区域分为High-salient、Low-salient 和Non-salient 这3 个不同显著性等级的区域。为了保障高QoE,将决策回报定义为与观看质量以及画面质量切换相关的决策变量,并考虑画面区域的显著性值,用于QoE 加权。在求解QoE 最优化问题时,采用了一种基于元启发式的模拟退火(Simulated Annealing,SA)算法,在大型搜索空间中对QoE 优化问题进行全局优化。类似地,文献[107]中提出了RoSal360 模型,同样基于图像显著性分配码率,并采用类似的数学建模方法;但采用的自适应步长的搜索机制大幅缩短了决策空间的遍历时间,同时还采用了强化学习纠错机制,剔除码率分配效果较差的节点,提高了系统的容错率,增强了鲁棒性。
随着强化学习理论的发展,强化学习模型也被广泛应用于码率分配。强化学习具有可以通过与环境交互进行学习,并计算相应的奖励回报的机制[108]。一般地,决策空间常被定义为对每一个chunk 内的tile 选择一个合适的码率,输入信息包括当前的可用带宽、历史选择码率和缓存区的剩余容量,决策回报定义为相应的QoE 函数[109]。文献[110]中联合考虑了多个QoE 指标提高流媒体传输系统的性能,采用了基于LSTM 的Actor-Critic(AC)模型优化用户体验质量,适应了不同的网络状况。在不同的网络条件下的测试实验结果表明,QoE 提升了20%~30%。
强化学习的方法,决策空间较大,模型训练耗时长。因此学者们提出了很多方法压缩决策空间,使得强化学习理论可以实际应用到自适应码率分配算法。文献[111]中引入了SRL(Sequential Reinforcement Learning),将决策空间从指数级转化至线性型,大幅压缩了决策空间,缩短了模型的训练时间。其次,SRL 不依赖于准确的带宽预测,而是观测过去时刻QoE 的性能,作出码率决策。该方法与其他算法相比,平均用户体验质量提高了12%。文献[112]中提出将自适应码率分配问题转换为非线性离散优化问题,并将码率自适应逻辑建模为马尔可夫决策过程,再基于深度强化学习算法动态学习最优的码率分配方案。与其他全景视频流系统相比,该系统在平均QoE 上实现了至少1.47 dB 的性能增益。以上模型尽管性能有了一定的提升,但是仍然存在一些问题。在自适应流媒体系统中,不同的业务、用户对QoE 模型有不同的需求和偏好,但一些模型的训练一旦完成,QoE 指标的比例关系就基本确定,无法适应各方面、多用户的不同需求。针对以上问题,文献[113]中提出了具有稳定性的双工结构,将码率决策分为fetch 与prefetch 队列,码率分配算法先选择队列然后选择相应的码率版本,从而压缩了算法的决策空间。通过将系统的状态分为SE(State Embedding)和PE(Preference Embedding)适应不同用户的QoE 偏好,并基于DQN(Deep Q-Network)决策码率,在数据集上的测试结果表明,该方案将QoE 提升了近20%。
综上所述,学者们提出了多种码率分配算法,最终目的都是在节省带宽资源的前提下提高用户的体验质量。尽管很多算法提升了用户的体验质量,但是算法复杂度较高,模型训练耗时长;同时,一些算法追求高码率,反而没有综合考虑用户的体验质量的影响因素,或者不同的用户对体验质量有不同的偏好。因此,如何控制算法时间复杂度在可接受的范围,保障用户的体验质量一直是学者们研究的问题。
5 未来发展与展望
全景视频流传输要保障用户良好的体验质量,需要高带宽、低时延。由于FoV 的限制,用户只能看到视频中一部分区域。为了节省带宽并提供流畅、高清晰度的视频,基于tile的视口自适应传输成为当前的主流传输方案。本章针对该传输方案中的几个可能的研究方向进行概述。
5.1 增强QoE评估的完善度
全景视频的QoE 评估是全景视频流系统优化的前提和关键。尽管全景视频的QoE 已经有了很大的进展,但是还缺乏更深入的研究。首先,用于全景视频QoE 评价的视频数据集不够完备,权威的数据集紧缺,而且数据集规模较小。全景视频中用户的体验质量与多方面因素有关,包括用户因素、网络因素和传输因素等。由于需要考虑的因素众多,全景视频的主观评估实验难以设计,从而制约了全景视频数据集的发展。其次,QoE 评估是基于人的感知水平的评价标准。虽然已有很多视频评价指标被提出,但是这些指标对人眼的视觉特性以及全景视频的视频特点考虑不够完备,客观评估指标与用户实际的感受还存在一定的差距。总之,建立充足、完备的视频数据集用以测试,防止QoE 评估出现过拟合风险的同时,应当充分研究人眼的视觉特性,将QoE 评估与用户感知相结合是全景视频QoE 评估的发展方向之一。
5.2 提高视口预测的准确性和鲁棒性
视口预测一直被视为视口自适应传输中关键技术,也是一直以来的研究热点。视口预测的精度直接影响预取视频片段与用户真实观看区域的一致性,决定了用户体验质量的高低。基于历史轨迹的预测方案可以比较精准地预测用户的FoV,但预测间隔增长时,精准度会大幅下降。除此之外,基于视频内容的显著性,预测用户的感兴趣的区域,精度上有了较好的提升,但算法复杂度更高。目前衍生出了许多同时基于历史轨迹与视频内容的预测模型,提高了视口预测算法的鲁棒性;然而,尽管对于视口预测的研究已经较为成熟,但是各学者多基于自建或其他人开源的数据集进行测试。目前还没有较大的数据集统一评估视口预测算法的性能。随着全景视频技术的深入发展,除了3DoF 的视频,还有6DoF 的视频正逐步发展。视口预测算法的发展应该紧跟全景视频业务的发展,普适性强、精度高、鲁棒性好的视口预测模型仍待探索与研究。
5.3 优化码率分配算法的决策和训练过程
传统的自适应码率分配算法包括基于吞吐量估计、基于缓存区容量控制、混合控制方法和基于学习的分配方案。全景视频中码率分配算法的研究已经持续了很长一段时间,但仍有问题亟须解决。首先,自适应码率算法的目标是保障用户的体验质量,码率分配的决策过程,势必要考虑影响用户体验质量的众多因素。其中包含两个挑战:其一,用户体验质量的指标之间是相互冲突的,例如要保障较高的视觉质量,那么卡顿发生的概率就越大;其二,不同用户对于QoE 的偏好有所不同。因此,需要优化自适应码率算法的决策过程,使它能够兼顾多项用户体验指标,或是动态调整码率分配策略使之能够自适应不同的用户偏好。其次,基于Qlearning、Actor-Critic 及其近年衍生出的系列强化学习模型通过过去的播放状态理解环境的变化机制,被尝试用以解决全景视频中的码率分配问题,进一步提升用户体验质量。与此同时,强化学习带来的决策空间庞大、训练耗时等问题不容忽视。这一问题目前还没被较好解决。一些学者尝试将整帧分成若干个较大的区代替细粒度的tile 分区,缩小决策空间,但会使决策的粒度粗化,不利于最优化。另外,强化学习网络的训练也需要通过仿真更新网络模型的参数,如何建立一个跟现实足够接近同时又快速的仿真模型也是一个问题。总之,码率分配算法如何同时以较低算法复杂度,高效完成码率分配,适应不同的网络环境和用户偏好是未来主要的突破方向。
6 结语
全景视频以独特的沉浸式体验广受到工业界与众多用户的青睐,但全景视频传输所需的高带宽、低时延特性阻碍了它的深入普及。为了在带宽受限的网络中提供流畅、高质量的视频观看体验,全景视频自适应传输成为如今的研究热点之一。学者们提出的基于tile 的视口自适应传输方案已成为当前主流的传输方案。本文介绍了当前主流的传输方式,即基于tile 的视口自适应传输方案;分析了该方案的核心技术,包括视口预测和码率分配的研究现状,从不同视角分别进行归纳总结。在此基础上,围绕现有研究方法的不足和挑战,展望了未来全景视频传输的发展趋势。本文从以上方面总结了未来可能的研究方向,旨在为该领域的研究者了解相关研究提供参考,并为深入研究提供思路。
猜你喜欢
家庭影院技术(2020年11期)2020-12-28
铁道通信信号(2020年9期)2020-02-06
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
经济技术协作信息(2018年30期)2018-11-22
计算机应用(2018年7期)2018-08-27
英美文学研究论丛(2018年1期)2018-08-16
家庭影院技术(2017年12期)2017-02-06
特别文摘(2016年21期)2016-12-05
江西理工大学学报(2015年3期)2015-12-22
