
融合片段对比学习的弱监督动作定位方法
2024-03-21 02:25党伟超高改梅刘春霞
计算机应用 2024年2期
党伟超,张 磊,高改梅,刘春霞
(太原科技大学 计算机科学与技术学院,太原 030024)
0 引言
时序动作定位是视频理解中重要的基本领域之一,旨在识别视频中的动作实例,并在未修剪视频中定位每个动作的时间边界。时序动作定位可以看作由两个子任务组成,一个子任务预测动作的起止时序区间,另一个子任务预测动作的类别。现实世界中的大多数视频通常未被剪辑,且时间较长,视频可能没有动作,也可能包含多个动作。传统的时序动作定位需要注释视频中的每个动作实例类型和时间区间,导致收集样本数据成本昂贵、消耗时间长,以及动作样本易错标或漏标。这些问题表明使用更少注释信息的重要性,因此,只需要视频级别标签的弱监督时序动作定位[1-3]逐渐成为动作定位研究的重点。
现有的一些弱监督时序动作定位方法[4-5]利用注意力机制分离前景背景,构建视频级特征,应用分类器获取分类激活序列(Class Activation Sequence,CAS)[6],对CAS 阈值化处理得到定位结果。在视频中除动作帧与背景帧外,还存在语义模糊的上下文帧,这些上下文帧与动作帧相似,导致在定位过程中难以被准确分类。此外,这些方法大多处理单个片段,片段间的联系未得到充分利用,导致出现在动作时间边界处的上下文帧也易被错误划分为动作实例。
随着深度学习的技术发展,无监督学习[7-8]近年来备受关注,已被验证具有特征提取的适应性和丰富性。在弱监督时序动作定位研究中,由于缺乏帧级别的注释,可以利用无监督学习提取特征的适应性和丰富性的优势,借助无监督学习间接获取帧级特征,帮助模型提高性能。文献[9]中使用自编码器生成数据,使之在整体或高级语义上与训练数据相近,这类方法称为生成式学习。对比式学习只将样本分为正负样本两类,正样本之间应该相似,而正样本与负样本应该不相似。通过学习同类样本的共同特征,区分非同类样本的不同以构建对比学习模型。因此,可以利用对比学习范式解决弱监督动作定位中上下文混淆的问题。
为了将出现在动作时间边界处的上下文帧准确分类,本文提出一种融合片段对比学习的弱监督动作定位方法。该方法主要由多分支注意力机制与片段挖掘算法[10]组成,其中,片段挖掘算法根据CAS 确定动作边界处的模糊片段。首先,通过特征提取进行特征嵌入表示;其次,使用3 个注意力分支分别测量每个视频帧是动作实例、上下文以及背景的可能性,根据获得的注意力值得到关于3 个类别对应的类激活序列;随后,对动作实例类激活序列采用片段挖掘算法,挖掘模糊片段与显著片段;最后,应用片段对比学习范式识别这些模糊片段,引导模型定位准确的时间边界。
1 相关工作
完全监督的时序动作定位通过提供帧级别的注释定位和分类未修剪视频中的动作实例。现有方法大致分为两类:一类是两阶段方法[11-14],另一类是一阶段方法[15]。第一类方法首先生成动作建议,然后在动作发生的时间边界上分类;而第二类方法则从原始数据中直接预测帧级别的动作类别与时间边界,然后处理获得的数据后完成最终定位。但这些方法在生成建议阶段与分类阶段都需要精确的动作实例注释,需要耗费大量的人力资源,导致效率低,因此无法在现实中广泛应用。
弱监督时序动作定位相较于完全监督学习,仅需要视频级别的动作类别标签,极大地降低了标注成本,更适用于视频监控、异常检测等现实场景。现有的弱监督时序动作定位方法可以分为自上而下的方法和自下而上的方法两类。自上而下的方法[16-17]首先学习一个视频级别分类器,然后选择分类激活序列较高的视频帧作为动作的位置。Min 等[18]将弱监督动作定位任务定义为动作识别问题,通过引入动作背景分离注意力分支构建视频级特征,然后使用分类器分类视频。与自上而下的方法不同,自下而上的方法[4,6,19]直接从原始数据中预测时间注意力权重,为每一帧产生一个注意力值,并设置阈值以区分帧,将注意力值高的视频帧当作动作帧,注意力值低的视频帧作为背景帧,引导模型更专注于更可能包含动作部分的片段。Shi 等[9]提出条件变分自编码器对基于帧级注意力的未知帧概率进行建模,再观察上下文所表现的差异,学习一个概率模型,从而对给定注意力的每一帧的可能性进行建模,最后实现动作与背景的分离。
对比学习[20]是一种利用数据本身作为监督信息学习样本数据的特征表达的自监督学习方式,通过在输入样本间进行比较以学习表示。可以在“相似”输入的正对和“不同”输入的负对之间比较,从而学习样本数据的一般特征。各领域学者提出各种改进模型:如MoCo(Momentum Contrast for unsupervised visual representation Learning)[21]系 列、SimCLR(Simple framework for Contrastive Learning of visual Representations)[22]系列等,这些模型效果已经超越了有监督模型。对比学习的目标是将样本不同的、增强过的正样本们在嵌入空间中尽可能拉近,再将不同类的样本间尽可能拉远。在计算机视觉领域中,对比学习可以被认为是通过样本之间的比较来进行学习,首先使用数据内部模式学习一个嵌入空间,在这个嵌入空间中聚集相关的信号,而不关联的信号则通过噪声对比估计(Noise Contrastive Estimation,NCE)[23]区分。文献[8]中通过局部聚合方法拉近相似数据,拉远相差较大的数据,提出聚类和实例判别对比学习相结合的思路。在弱监督时序动作定位任务中,片段之间也存在联系,但大部分方法忽略了这一点,导致一些片段被错误归类,DGAM(Discriminative and Generative Attention Modeling)[9]将上下文混淆的问题视为单个片段的作弊问题,基于此,本文利用片段间的联系构建了融合片段对比学习的弱监督动作定位模型以提高定位准确率。在动作定位任务中,发生在动作边界处的上下文帧与动作帧不易区分,因此将这些不易区分的片段称为模糊片段,辨别力强的动作帧称为显著片段,将构造的正负样本在特征空间中进行片段对比学习以帮助网络正确识别模糊片段。片段对比学习的原理如图1 所示。本文方法融合注意力机制和片段对比学习,利用注意力机制优化类激活序列,使用片段对比学习引导模型找出模糊片段,更准确定位动作时间边界。
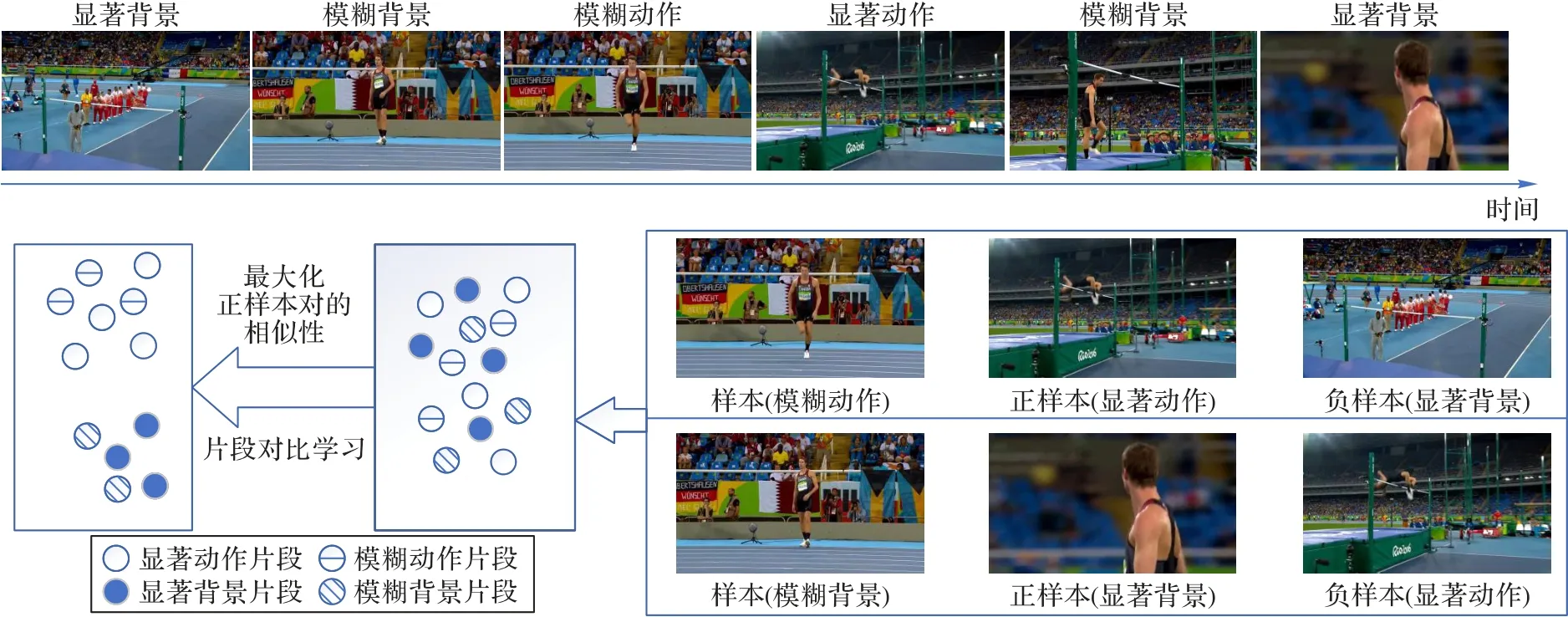
图1 片段对比学习的原理Fig.1 Principle of snippet contrastive learning
2 动作定位模型
为了减小上下文与单片段作弊问题带来的影响,本文构建了一种融合片段对比学习的弱监督动作定位模型。本文模型的总体框架如图2 所示。
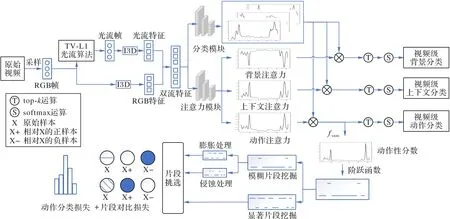
图2 本文模型的总体框架Fig.2 Overall framework of proposed model
2.1 特征提取与嵌入
对于给定的未修剪视频V,以每秒25 帧的采样率采样为RGB 帧,然后使用TV-L1 算法[24]将RGB 帧转换为光流数据,最后将RGB 数据与光流数据分割为具有连续16 帧的非重叠片段。将这些片段放入Kinetics 数据集[25]预训练的I3D(Inflated 3D ConvNet)网络[26]提取特征,然后将得到的RGB特征Frgb(t) ∈RD与光流特征Fflow(t) ∈RD连接在一起形成片段特征F(t)=[Frgb(t),Fflow(t)]∈R2D,然后堆叠所有片段特征,形成特征F∈RT×2D,其中T为视频片段数。
特征F是经过预训练的I3D 网络提取得到,为了将它映射至任务特定的特征空间中,需要引入特征嵌入模块。嵌入模块由一组卷积层和非线性激活函数ReLU(Rectified Linear Unit)组成,特征嵌入模块如下表示:
其中:θembed为嵌入层可训练的参数。
2.2 动作分类激活建模
为了定位视频中动作实例的时间边界,将得到的特征X首先通过一个动作分类分支得到一个初始的类激活序列,即CAS(t),将它视为动作实例的初始指标。动作分类分支将特征X从初始空间映射至动作类别空间,输出是关于每个动作类别随时间变化的分数。记作Φ∈RT×(C+1)。分类激活分支表示如下:
其中:θcas为分类激活分支中可训练的参数,MLP()为多层感知机。
2.3 多分支注意力建模
为使网络准确分离上下文帧与动作帧,本文设计了一个具有三条分支的注意力模块分别为动作帧、上下文帧以及背景帧进行建模,使用Softmax 函数对输出结果进行归一化处理。注意力模块使用一个卷积层与Softmax 函数测量每个视频帧是动作实例、上下文以及背景的可能性,它的输出为:其 中attins(t)、attcon(t)和attbak(t)分别表示片段s(t)是动作实例、动作上下文和背景的可能性。三分支动作注意力模块表示如下:
其中θatt为多分支注意力模块中可训练的参数。
基于分类激活序列和三分支注意力值,构建关于动作实例、动作上下文和背景的类激活序列,即CASins(t)、CAScon(t)和CASbak(t),分别表示如下:
CASins(t) 是关于动作实例的类激活序列,相较于CAS(t),CASins(t)在CAS(t)的基础上增加注意力机制,得到的CASins(t)可以更关注动作帧。而CAScon(t)更关注于动作上下文帧,CASbak(t)更关注于背景帧。
2.4 模糊片段与显著片段的选取
在弱监督时序动作定位任务中,引入注意力机制可促使网络更关注动作帧,并在一定程度上提高类激活序列的准确性,但由于网络始终处理单个片段,导致片段间的语义信息无法得到充分利用。为此,本文使用片段挖掘算法选取模糊片段与显著片段,利用对比学习范式最大化正样本对之间的相似性,从而捕获更完整的动作信息,缓解模糊片段的误分类问题。
2.4.1 模糊片段的挖掘
视频中大部分的动作片段和背景片段远离时间边界,噪声干扰较小,可信度较高,但出现在时间边界处的片段,处于动作与背景之间的过渡区域,噪声干扰大,容易导致模型检测错误。因此在得到CASins(t)后,时间边界处仍存在许多错误检测的片段,本文在仅使用注意力分支得到的CASins(t)的基础上应用片段挖掘算法得到模糊片段。最后根据捕获到的片段的时间索引划分为模糊动作片段与模糊背景片段。具体如下:
得到CASins(t)后,在类别维度上按动作类聚合,然后使用Sigmoid 函数得到一个与类无关的动作性分数An∈RT,再对An阈值化处理得到
其中:ε(⋅)为海维赛德阶跃函数,θb为阈值,当An>θb时为1,否则为0。

图3 模糊片段挖掘算法Fig.3 Hard snippet mining algorithm
2.4.2 显著片段的挖掘
为了构造正负样本对,还需捕获显著片段以学习片段间的特征信息,根据得到的动作性分数An,对它按照降序分别选取前keasy个与后keasy个片段作为显著动作片段与显著背景片段具体如下:
2.5 损失函数及优化
对于已挖掘的模糊片段和显著片段,设计了片段对比损失函数以学习片段的特征信息;此外,对于分类损失,分别计算视频相应的3 个CAS损失;最后增加了注意力引导损失,它用于约束CASins与动作注意力保持一致。总损失函数表示如下:
其中:Lcls为分类损失,Lgui为注意力引导损失,Ls为片段对比损失,λ1与λ2为平衡总损失的两个超参数。下面分别定义各个损失函数。
2.5.1 分类损失
分类损失由3 个分支的类激活序列损失构成,首先定义动作分支的类激活序列损失,即。
为了测量视频中动作分支的类激活序列的损失,首先取每个动作类别的所有视频片段,按降序取前kins个动作分支的分类分数,再将其平均,得到视频V对应第c类动作分支的视频级分类分数,即(V):
然后再对得到的视频级分类分数应用Softmax 函数得到视频级动作概率。
为了分离动作帧、背景帧以及上下文帧,将得到的CASins应用上述机制得到视频级动作概率分布,将CAScon与CASbak分别应用上述机制可得。
为了得到视频中关于动作注意力类激活序列CASins的损失,将预测的视频级动作概率分布和真实视频动作概率分布应用交叉熵损失函数分类视频中不同的动作,关于CASins的分类损失表示如下:
首先设置动作分支的视频级标签为yins=[y(c)=1,y(C+1)=0]表示视频V中包含第c个动作类是视频V中第c个类的视频级标签。因为上下文帧与动作类别相关,又与静态背景帧类似,所以设置上下文分支的视频级标签为ycon=[y(c)=1,y(C+1)=1],而CASbak更关注背景帧,因此设置背景分支的视频级标签为ybak=[y(c)=0,y(C+1)=1]表示视频V中不包含第c个动作类。同理可以得到关于CAScon和CASbak的分类损失,即根据得到的可构建出分类损失Lcls。
2.5.2 注意力引导损失
由于只构建了视频级分类损失,并未在片段级优化动作分类的结果,因此引入注意力引导损失,使分类激活序列和动作注意力趋于一致,使用attins在片段级水平上引导CASins,抑制上下文帧与背景帧。
其中:pins(t)是对CASins应用Softmax 函数后得到的预测片段级动作概率分布则表示片段s(t)不包含动作实例的可能性,attins(t)是片段s(t)处的动作注意力值,通过最小化Lgui可以引导网络在片段级优化类激活序列。
2.5.3 片段对比损失
应用片段挖掘算法挖掘模糊片段和显著片段后,将片段对应的嵌入特征应用对比学习,即引入片段对比损失Ls细化模糊片段的特征,并获得更丰富的特征信息。模糊片段分为模糊动作片段和模糊背景片段,因此构造两组对比对,即模糊动作片段HA 的细化与模糊背景片段HB 的细化,HA 细化的目的是通过在特征空间中促使模糊动作片段与显著动作片段转化模糊动作片段的特征,HB 的细化同理。
其中:K表示负例数表示第i个负例片段,τ为温度系数,通过最大化同一类别(动作或背景)的显著片段和模糊片段之间的相互信息,这有助于细化特征表示,从而缓解单个片段作弊的问题。
2.6 输出结果
对于给定的输入视频,将得到的CASins(t)、CAScon(t)和CASbak(t)分别采用top-k运算得到三分支的视频级分类预测。再对动作注意力类激活序列CASins进行阈值处理后再进行定位操作,输出结果为,应用文献[6]中提出的外-内-对比函数获得每个动作实例的置信度得分最后生成动作建议并且使用非极大值抑制删除重复的建议。其中置信度分数的定义如下:
其中:v表示第c个动作类在第t个片段处的类激活分数;α是用于组合CASins与attins的超参数为定位到动作实例的时间边界为膨胀对比区域表示对应的动作类别。
3 实验与结果分析
3.1 数据集
本文在两个流行的动作定位数据集THUMOS14[27]与ActivityNet1.3[28]上进行实验,且使用了视频级标签训练网络。
THUMOS14 数据集包含20 个动作类别,验证集包含200个未修剪的视频,测试集包含213 个未修剪的视频。视频的长度变化较大,从长度几秒到超过1 h 不等。每个视频可能包含多个动作实例,有超过70%的帧为上下文帧或背景帧。选取验证集视频用于模型训练,测试集视频用于测试模型性能。
ActivityNet1.3 数据集相较于THUMOS14 数据集,规模更为庞大,涵盖了与人类在日常生活中最相关的活动,视频数量多、类别丰富,包含200 种不同类别的动作,其中有10 024 个未修剪的视频用于模型的训练,4 296 个未修剪的视频用于模型的性能测试。约有36%的帧为上下文帧或背景帧。大部分视频时长在5~10 min,50%的视频的分辨率在1 280×720,大部分视频是30 FPS,类别主要分为个人护理、饮食、家庭活动、关怀和帮助、工作、社交娱乐、运动锻炼7 大类。
3.2 评价指标
实验遵循了标准的评估方案,记录了在不同交并比(Intersection over Union,IoU)阈值下的平均精度均值(mean Average Precision,mAP),在THUMOS14 数据集上,阈值为[0.1:0.1:0.7],在ActivityNet1.3 数据集上的阈值为[0.5:0.05:0.95]。在两数据集上评估都是使用ActivityNet 提供的基准代码进行的。
3.3 实验细节
实验环境 融合片段对比学习的弱监督动作定位方法是在PyTorch 环境、单个NVIDIA GeForce RTX 2080Ti GPU 上样本训练。
特征提取 在特征提取部分,首先使用预训练的I3D 网络提取特征,使用TV-L1 光流算法从RGB 帧中提取光流特征,将每个视频分为连续16 帧的非重叠片段,得到1 024 维的RGB 特征与光流特征。
THUMOS14 数据集上的实验 在THUMOS14 数据集上,将每批数据量大小设置为16,使用Adam[37]优化器,学习率为0.000 1,权重衰减为0.000 5,将视频片段长度设置为T=750,以及top-k运算中对应三分支的k的大小,动作分支中kins=T//sins,上下文分支中kcon=T//scon,背景分支中kbak=T//sbak。其中sins为8,scon与sbak为3,λ1为0.002,λ2为0.01,α为0;reasy为5,rhard为20;θb为0.5,m与M分别为3和6;τ为0.07。对于生成的动作建议,将阈值设为0.15~0.25,步幅为0.05。在IoU 为0.5 时执行非极大值抑制。在THUMOS14数据集上不同弱监督动作定位模型的检测结果如表1 所示。观察表1 可知,所提方法在IoU 阈值为0.1~0.6 时均取得了最佳性能。与之前的最佳方法DGCNN(Dynamic Graph modeling for weakly-supervised temporal action localization Convolutional Neural Network)相比,在IoU 为0.5 时,mAP 提高了1.1 个百分点,这表明所提方法在包含动作较多且长度不断变化的视频数据上,能表现出良好的性能。
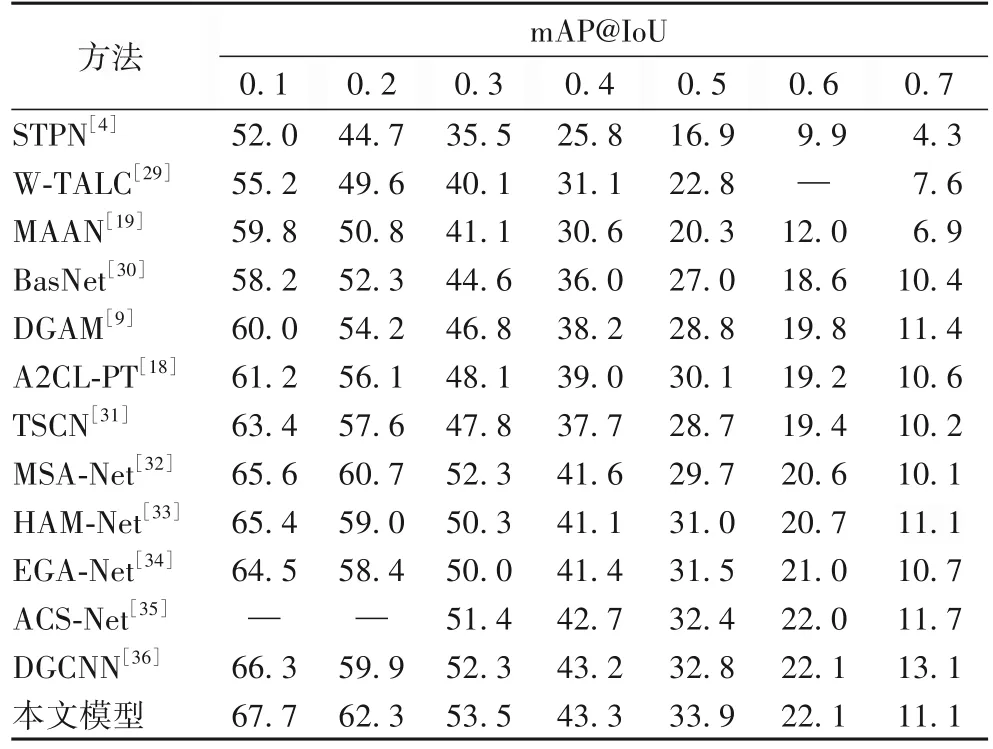
表1 不同弱监督动作定位方法在THUMOS14数据集上的检测结果 单位:%Tab.1 Detection results of different weakly-supervised action localization methods on THUMOS14 dataset unit:%
ActivityNet1.3 数据集上的实验 在ActivityNet1.3 数据集上,将每批数据量大小设置为64,使用Adam 优化器,学习率为0.000 05,权重衰减为0.001,由于大多视频时长相较于THUMOS14 中的视频时长要短很多,因此将视频片段长度设置为T=75,对于top-k运算中对应三分支的k的大小,动作分支中sins为2,上下文分支中scon为10,背景分支中sbak为10;λ1为0.005,λ2为0.01,α为0.5;reasy为10,rhard为8;θb为0.5,m与M分别为3 和6;对于生成的动作建议,将阈值设为0.01~0.02,步幅为0.005。τ为0.07。在IoU 为0.9 时执行非极大值抑制。在ActivityNet1.3 数据集上不同弱监督动作定位模型的检测结果如表2 所示。观察表2 中可知,所提方法在各个不同的IoU 阈值下均取得了最佳性能。与DGCNN 相比,在IoU 为0.5时,mAP 提高了2.9个百分点。

表2 不同模型在ActivityNet1.3数据集上的检测结果 单位:%Tab.2 Detection results of different models on ActivityNet1.3 dataset unit:%
表1、2 分别展现了在 THUMOS14 数据集和ActivityNet1.3 数据集上不同弱监督动作定位模型的检测结果,对比的网络模型涵盖了近五年内弱监督动作定位任务的主流方法。其中STPN(Sparse Temporal Pooling Network)、A2CL-PT(Adversarial and Angular Center Loss with a Pair of Triplets)为使用前景-背景分离注意机制构建视频级特征的主流算法。而另一类主流算法W-TALC(Weakly-supervised Temporal Activity Localization and Classification)、MAAN(Marginalized Average Attentional Network)等将时序动作定位表述为多示例学习任务,通过分类器获取时序类激活序列,进而描述动作在时间上的概率分布。此外,为充分说明所提方法的对比效果,与近两年内的主流算法MSA-Net(Multi-Scale structure-Aware Network)、HAM-Net(Hybrid Attention Mechanism)、EGA-Net(Entropy Guided Attention Network)、DGCNN 对比,并与BasNe(tBackground suppression Network)、TSCN(Two-Stream Consensus Network)、ACS-Net(Action-Context Separation Network)、TSM(Temporal Structure Mining)、BMUE(Background Modeling via Uncertainty Estimation)等主流算法对比,实验结果表明,所提方法相比目前主流方法有着良好的效果提升。
3.4 损失函数平衡因子
本文参数设置参考主流的弱监督动作定位算法[9-10],并利用网格搜索法做大量实验调试确定。由于对比损失函数的平衡因子λ2对实验结果影响较大,因此在表3 中给出THUMOS14 数据集中不同的对比损失系数λ2的实验结果,选取交并比为0.5 作为评价指标,参数λ2用于式(13)中平衡对比损失与分类损失和注意力引导损失。实验结果表明,当λ2=0.01 时,网络性能最佳,mAP@0.5 达到了33.9%。此外,平衡因子λ2在0.01~0.1 的变化范围内定位精度保持稳定,说明所提方法具有一定的鲁棒性。
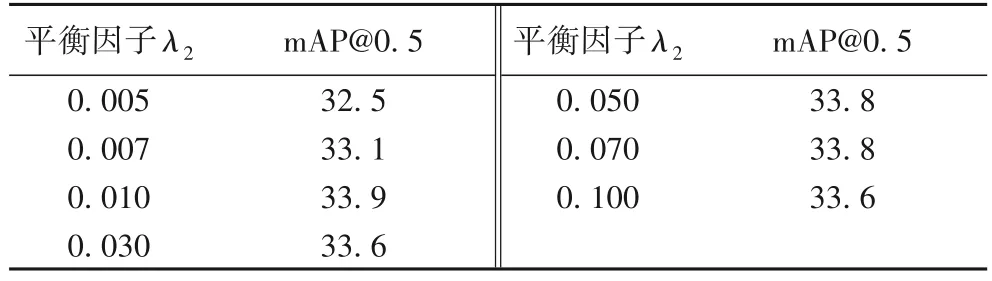
表3 不同平衡因子在THUMOS14数据集上的性能比较Tab.3 Performance comparison of different balance factors on THUMOS 14 dataset
3.5 消融实验
在实验过程中进行了多个消融研究,如表4 中基线所示,THUMOS14 数据集是用于评估弱监督时序动作定位任务的最常见数据集,它的视频长度变化较大,且每个视频可能包含多个动作实例,超过70%的帧为上下文帧或背景帧,相较于ActivityNet1.3 数据集背景干扰较多,消融实验可以更直观地体现不同因素对检测结果的影响,因此所有实验均在THUMOS14 数据集上进行。
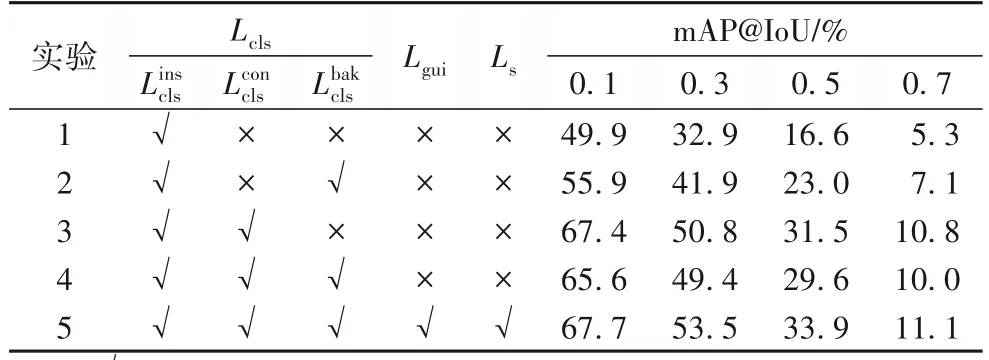
表4 动作上下文分支消融实验结果Tab.4 Ablation experiment results of action context branch
关于动作上下文注意力分支的有效性,消融实验结果如表4 所示。
从表4 中可以看出,相较于没有动作上下文注意分支的基线方法,动作上下文分支的引入有显著效果,这是由于将动作帧、上下文帧和背景帧划分为一个类别是不合理的,因此在三种不同语义片段中增加注意力机制可以有效提高模型的性能。而实验3 中的结果相较于实验4 更有效,这是由于在没有引入指导损失与片段对比损失的情况下,更准确地区分动作帧、上下文帧和背景帧。
注意力引导损失与片段对比损失的有效性:关于注意力引导损失与片段对比损失的有效性,消融实验结果如表5所示。
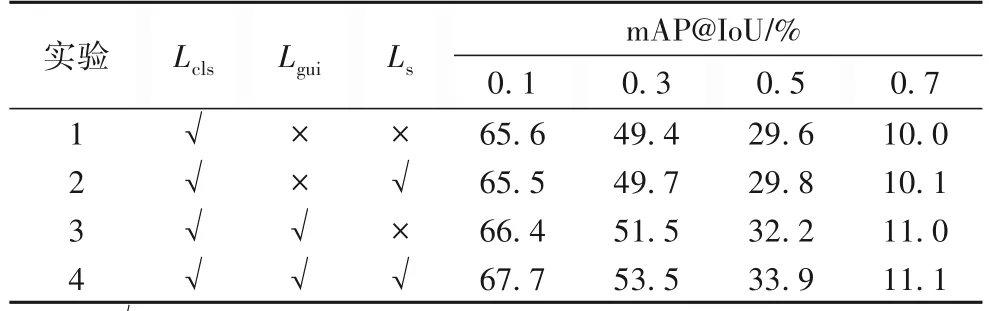
表5 注意力引导损失与片段对比损失消融实验结果Tab.5 Ablation experiment results of attention guided loss and snippet contrast loss
从表5 中可以看出,在有分类损失与片段对比损失的情况下,mAP@0.5 达到了29.8%,在此基础上引入注意力引导损失后,可以达到33.9%。这是由于注意力引导损失可以促使网络在片段级别上最小化CASins与attins的差异,从而提高模型的性能。在有分类损失与注意力引导损失的情况下,mAP@0.5 可以达到32.2%,而在此基础上引入片段对比损失后,mAP@0.5 可以达到33.9%。这是由于片段对比损失引导网络在弱监督动作定位上实现了更好的特征分布,可以更精确地分离模糊片段以及动作片段与背景片段。
综上所述,融合片段对比学习的弱监督动作定位方法可以通过注意力机制帮助网络更关注关键信息,同时通过对比学习的方式将模糊片段进行准确分类以提高模型的性能。
4 结语
融合片段对比学习的弱监督动作定位方法由分类模块、注意力模块和片段对比学习模块组成。其中,分类模块通过神经网络获取CAS;注意力模块分别由动作注意力分支、上下文注意力分支以及背景注意力分支构成,3 个分支分别用于测量每个视频帧为动作实例、上下文和背景的可能性。融合CAS和注意力值获得3 种类激活序列,它们表示每个视频帧分别是动作帧、上下文帧和背景帧的分类激活分数;片段对比学习模块应用片段挖掘算法挑选正负样本对,构建片段对比学习模型提高片段分类精度。本文方法解决了弱监督动作定位中上下文帧容易被错误分类的问题。在两个基准数据集上充分实验,在THUMOS14 数据集上,mAP@0.5 达到了33.9%;在ActivityNet1.3 数据集上,mAP@0.5 达到了40.1%。实验结果验证了融合片段对比学习的弱监督动作定位方法的有效性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
学生天地(2019年28期)2019-08-25
数学物理学报(2018年1期)2018-03-26
数学物理学报(2017年5期)2017-11-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
新课程学习·中(2013年3期)2013-06-14
