
基于孪生网络和Transformer的红外弱小目标跟踪方法
2024-03-21 02:25崔晨辉蔺素珍李大威禄晓飞
计算机应用 2024年2期
崔晨辉,蔺素珍*,李大威,禄晓飞,武 杰
(1.中北大学 计算机科学与技术学院,太原 030051;2.中北大学 电气与控制工程学院,太原 030051;3.酒泉卫星发射中心,甘肃 酒泉 735000)
0 引言
红外弱小目标跟踪作为精确制导和远距离飞行器目标监控等系统的关键技术之一,也是计算机视觉研究中的经典难题。在上述应用中,目标通常距离红外传感器较远,获取的图像不仅分辨率较低、目标所占像素较少(通常在2×2~9×9),而且目标轮廓模糊,导致很难有效提取目标特征,更难精确跟踪目标[1];如果再遭遇目标周围相似物干扰、传感器抖动和目标明暗变化等,甚至会导致跟踪完全失败。因此,亟需探索复杂场景下的红外弱小目标稳健跟踪方法。
现有红外弱小目标跟踪方法可分为基于模型驱动的数学建模方法(下称模型驱动法)和基于数据驱动的深度学习方法(下称数据驱动法)两大类[2]。模型驱动法通常在首帧标定的目标位置裁剪图像区域,并训练得到相关滤波器之后,再用该滤波器与当前帧图像区域运算获得响应图,响应图中的最大位置即为目标新位置,然后据此更新相关滤波器进行下一轮次,以此类推。该类方法的关键是降低背景杂波对跟踪器的影响[3-4]、增强目标区域[5]。为提高跟踪速度,通常需要利用周期性循环移位训练滤波器,会不可避免地引入边界效应,降低目标模型的质量。为了改进目标模型,多数研究通常采用尺度估计和多特征提取等手段[6],虽然能提升精度但增加了方法的复杂度,以至于在实时性方面离探测系统的要求越来越远。总体地,模型驱动法近期进展较慢。
与模型驱动法不同,数据驱动法近几年得到了长足的发展。数据驱动法多是通过神经网络提取目标特征,并产生响应图定位目标位置,它的跟踪效果较好且泛化能力强。其中,基于孪生网络的目标跟踪方法由于出色的跟踪精度和速度得到广泛应用[7]。它将目标跟踪问题视为一个相似性匹配的任务,通过共享参数的神经网络提取视频序列中首帧和后续帧图像的特征图,在后续帧的特征图上寻找与首帧特征图最为相似的位置,作为最终的跟踪结果。对于红外弱小目标在跟踪过程中易受到背景杂波和遮挡等影响,Att-Siam(convolutional channel Attention Siamese network)[8]方法基于SiamFC(Fully-Convolutional Siamese network)[9]方法进行改进,融合卷积通道注意力机制、堆叠通道注意力机制和空间注意力机制,实现对红外弱小目标有效且稳定的跟踪。张文波等[10]提出一种改进的全卷积孪生网络,使用深度特征响应图的平均峰值相关能量和最大峰值判断目标跟踪状态,在目标受到背景杂波干扰时,利用深度特征响应值联合局部对比度判别的方式定位目标,当目标发生遮挡时,使用卡尔曼滤波器预测目标位置,所提方法可适应复杂多变的红外环境。为解决红外弱小目标快速运动和丢失重现问题,Chen等[11]提出一种基于时空注意力的孪生网络方法,它的特点是在局部区域跟踪过程中添加空间和时间注意力机制消除背景干扰,更好感知红外弱小目标,当目标快速运动跑出局部区域时,设计三阶段全局重检测机制在全局视角下重新定位目标,最后通过状态感知切换策略,自适应融合局部跟踪和全局重检测,可对弱小目标进行鲁棒跟踪。尽管这些研究通过添加不同的模块应对了红外弱小目标跟踪中的一些挑战,使跟踪结果精确性得到很大提升;但总的来看,基于孪生网络的方法在计算响应图的过程中常采用卷积互相关操作,将模板特征图作为卷积核,搜索特征图作为输入,由此得到最相似位置,该操作易受周围相似物的干扰,陷入局部最优,跟踪结果偏移到相似物上,丢失真实目标[12]。
考虑到Transformer 模型可建模全局的上下文信息[13],面对卷积神经网络(Convolutional Neural Network,CNN)中感受野映射到图像中较为局限的问题,利用Transformer 模型特有的多头注意力机制,可有效获取全局信息,并且多头机制可将编码向量映射至多个空间,增强模型的表达能力。本文受到TransT(Transformer Tracking)[12]目标跟踪方法的启发,利用Transformer 中的自注意力机制和交叉注意力机制的优势,对模板帧和搜索帧特征图进行全局建模,可避免跟踪过程中卷积互相关操作陷入局部最优问题。
本文主要工作内容如下:
1)提出一种针对红外弱小目标的跟踪方法,利用孪生网络和Transformer 跟踪红外弱小目标。在特征提取中采用深度特征和灰度方向梯度直方图(Histogram of Oriented Gradient,HOG)特征,使模板帧和搜索帧特征信息更加丰富;利用Transformer 替换原有的卷积互相关操作,建立全局依赖,获得更准确的响应图。
2)提出一个响应图上采样模块,将Transformer 输出的互相关响应图扩大至搜索帧尺寸大小,最后通过边界框预测网络模块输出跟踪结果。
3)在修改后的地空背景下红外图像弱小飞机目标检测跟踪数据集(Dataset for IR Small Targets,DIRST)上进行实验,对比目标检测、通用目标跟踪方法,本文方法达到最高的89.7%的精确率和90.2%的成功率。
1 SiamCAR目标跟踪方法
基于孪生网络的目标跟踪方法将跟踪问题转换为目标匹配问题,计算模板特征图和搜索特征图之间的相似度图,但相似度图只包含有限的空间信息。因此,常在搜索特征图上设定多个尺度以确定目标发生的尺度变换,过程非常耗时。为解决该问题,SiamCAR(Siamese fully Convolutional classification And Regression)跟踪方法[14]将目标跟踪任务分解为两个问题:一是像素级别的分类问题,二是该像素上目标边界框的回归问题,这种端到端无锚网络的结构可避免提取多特征搜索特征图的耗时操作,也可大幅降低采用锚框机制设定超参数的数量,使跟踪方法更加简洁有效。SiamCAR网络的结构如图1 所示。
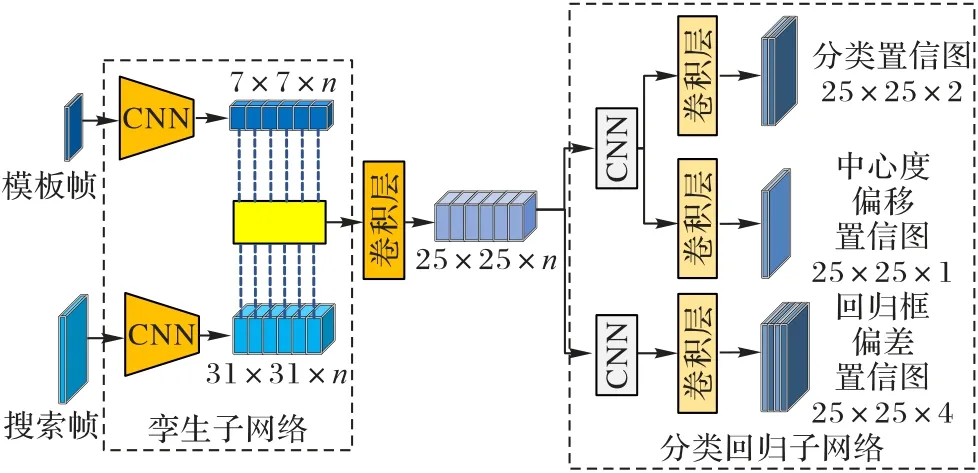
图1 SiamCAR网络的结构Fig.1 Structure of SiamCAR network
SiamCAR 跟踪方法分为孪生子网络和分类回归子网络两个部分。孪生子网络包含特征提取和深度互相关操作。在特征提取过程中模板帧图像和搜索帧图像通过共享参数的ResNet-50 网络获得深度特征图,为充分利用深度网络中浅层细节信息和深层语义信息,特征图将ResNet-50 网络中最后3 个残差块的特征进行通道维度的串联,如式(1)所示:
式中:F3、F4、F5表示ResNet-50 网络最后的3 个残差块,S表示搜索帧图像,φ(S)表示提取的搜索特征图。对于模板帧图像Z也采用相同的操作。
互相关操作中,改进卷积互相关,采用逐通道的相关操作生成多通道的响应图,更好地利用浅层特征和深层特征,易于定位和鉴别干扰。响应图R的计算公式如式(2)所示:
式中★表示深度互相关操作。
响应图R中每个像素都可映射回搜索帧图像区域,分类回归子网络直接对R中每个像素进行分类和回归的预测。包含3 个部分:目标分类得分网络、中心度偏移得分网络和回归框偏差网络。分类得分网络输出是一个二维矩阵代表搜索帧图像相应位置前背景概率,使用交叉熵损失函数进行训练;中心度偏移得分网络输出一个一维矩阵,代表目标中心位置与搜索图像每个像素点位置的距离,以提高网络对相似物目标的辨别能力,使用二分类交叉熵损失函数进行训练;回归框偏差网络输出是一个四维矩阵表示像素点对应搜索图像相应位置距离目标边界框四边的距离,使用交并比(Intersection Over Union,IOU)损失函数进行训练。以上3 个矩阵的下标w×h×c中,w和h代表响应图R的宽和高,c表示矩阵的通道数。最终的损失函数如式(3)所示:
式中:λ1设置为1,λ2设置为2,Lcls表示分类得分网络损失函数,Lcen表示中心度偏移得分网络损失函数,Lreg表示回归框偏差网络损失函数。
虽然,SiamCAR 目标跟踪方法使用深度互相关和输出中心度偏移得分网络的方式在一定程度上抑制真实目标周围的相似物目标,但对于红外弱小目标并不适用,因为红外弱小目标和周围相似物灰度值都呈现高斯分布,且无轮廓和纹理特征,采用简单的卷积操作并不能很好地辨别。因此,本文在SiamCAR 目标跟踪方法上进行修改,使SiamCAR 跟踪方法更适合红外弱小目标跟踪场景,提升跟踪方法的鲁棒性。
2 本文方法
本章首先阐述本文方法的整体结构,之后详细介绍方法中多特征提取级联模块、特征互相关模块、响应图上采样模块、模板帧实时更新模块,以及本文方法的测试过程。
2.1 整体结构
本文提出的红外弱小目标跟踪方法的整体网络结构如图2 所示,由多特征提取级联模块、特征互相关模块、响应图上采样模块、边界框预测网络模块和模板帧实时更新模块组成。
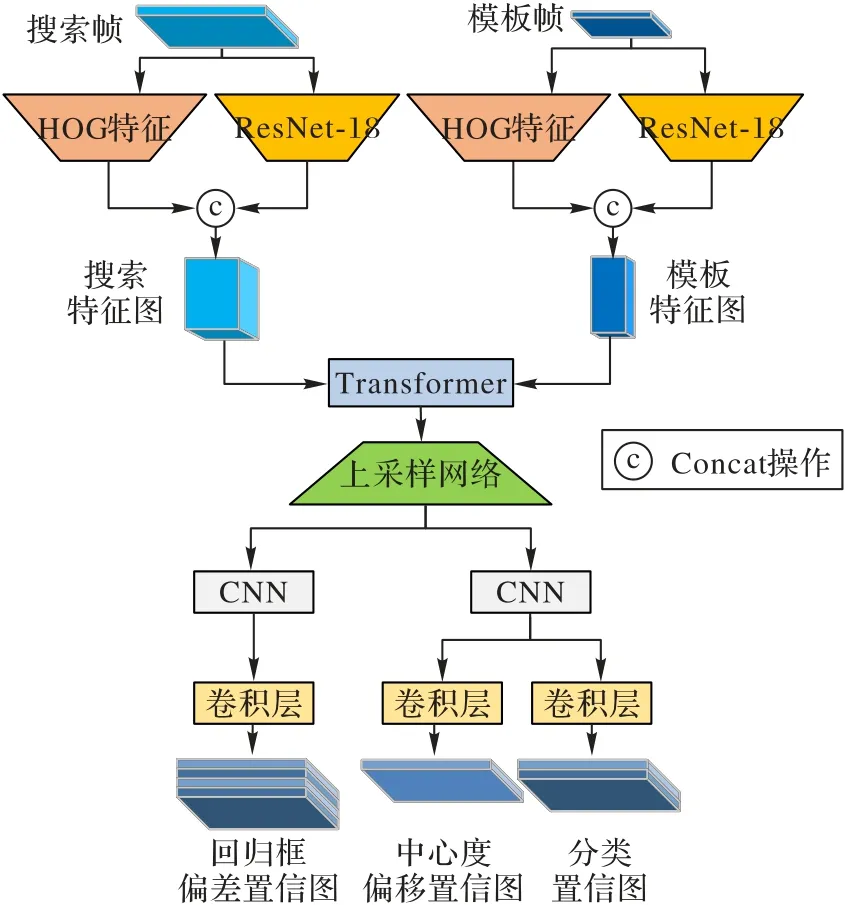
图2 本文方法的整体结构Fig.2 Overall structure of proposed algorithm
输入是红外图像序列,模板帧实时更新模块会以跟踪的前一帧图像按目标中心位置为原点进行裁剪,获得模板帧Z;当前帧图像以上一帧目标中心为原点裁剪,获得搜索帧S;之后,模板、搜索帧图像通过多特征提取级联模块获得级联特征图(由ResNet-18 提取的深度特征与HOG 特征串联产生);再通过特征互相关模块,利用Transformer 的自注意力和交叉注意力机制对两种特征进行相似性计算,产生互相关响应图;之后通过响应图上采样模块,将互相关响应图扩充至搜索帧图像大小;通过边界框预测网络模块(采用SiamCAR中分类回归子网络),获得目标在搜索帧区域的分类(Classification,Cls)、中心度偏移(Centrality offset,Cen)、边界框偏差(Regression box bias,Reg)置信度图,最终通过对3种置信度图的计算获得待跟踪目标的边界框(x1,y1,x2,y2)。
2.2 多特征提取级联模块
红外弱小目标虽然所占像素较少,分辨率低,边缘轮廓模糊,但目标常呈高斯分布,对红外弱小目标插值放大,可提取出有效的特征图。本文利用孪生网络结构进行特征提取,由两个分支组成:一是以模板帧Z为输入的模板分支,二是以搜索帧S为输入的搜索分支。在传统的跟踪方法中,仅使用神经网络提取的深度特征进行互相关计算,跟踪准确性并不高,在深度特征的基础上添加其他的图像特征可使模板分支和搜索分支输出的特征图信息更加丰富,有利于跟踪准确性的提高。
因此本文将两个分支一起通过共享参数的ResNet-18 网络[15]和HOG 特征提取器,再进行维度层面的拼接,获得最终的模板特征图和搜索特征图。特征提取器的结构如图3 所示(输入以模板区域为例)。

图3 多特征提取级联模块网络结构Fig.3 Network structure of multi-feature extraction cascading module
在跟踪过程中,目标模板帧和搜索帧经放大裁剪变换为127×127×3 的z和255×255×3 的s,通过ResNet-18 网络f后得到15×15×512 的f(z)和31×31×512 的f(s)特征图。
对于红外图像,目标前景和背景之间灰度值的差异是一个重要信息,提取目标与周围背景的梯度分布信息可有效区别干扰物的影响。其中HOG 特征能表征图像边缘信息和梯度分布情况,在深度特征基础上添加该特征会使目标信息更加丰富。目标模板帧和搜索帧通过HOG 特征提取后,获得15×15×8 的h(z)和31×31×8 的h(s)大小的HOG 特征图。将HOG 特征图与深度特征图进行拼接,得到15×15×520 的f′(z)和31×31×520 的f′(s)的级联特征图:
通过级联后的特征信息更加丰富,使后续定位和回归操作更加精确。
2.3 特征互相关模块
为解决传统孪生网络跟踪方法易陷入局部最优问题,增强本文方法对目标与干扰物的判别能力,使用Transformer 模块[16]代替卷积相似性计算。Transformer 模块采用多头注意力机制,可关注全局信息,在搜索特征图上自适应地寻找与模板特征图最相关的区域,获得更加精准的响应图,特征互相关模块网络结构如图4 所示。
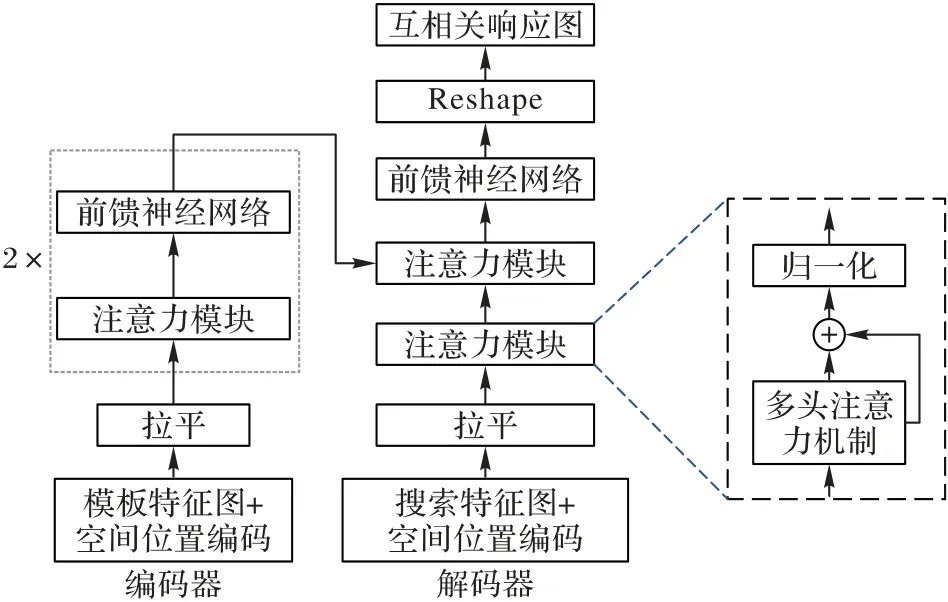
图4 特征互相关模块网络结构Fig.4 Network structure of feature cross-correlation module
在编码器阶段,由两个编码器层组成。由于Transformer需要将每个维度的特征图进行拉平操作,无法判断输入特征向量的位置信息,因此,为引入位置信息,要将模板特征图每个像素的相对位置关系加入模板特征图,最后进行拉平操作,作为第一个编码器层的输入,公式可表示为:
其中:f′(z)是多特征提取级联模块模板特征输出级联特征图,P(f′(z))是级联特征图的空间位置编码,flatten(·)表示拉平操作,f″(z)是经拉平和添加空间位置编码的特征向量。
编码器层由注意力模块和前馈神经网络构成,它的注意力模块通过多头注意力机制、相加和归一化操作,目的是增强模板特征图中最有用的信息,提高解码器性能,多头注意力机制(MultiHead)公式可表示为:
然后通过前馈神经网络(FeedForward Neural network,FFN),输出第一层编码器的编码特征。其中,前馈神经网络由两个全连接层、一个ReLU 激活函数层、一个Dropout 层和一个归一化层组成,具体公式表示如下:
在解码器阶段,由两个解码器层组成,在搜索特征图f′(s)进行空间位置编码和拉平操作后,输入到第一个解码器层中,增强搜索特征图信息,获得。然后与编码器输出的编码特征一同输入到第二个解码器层,采用交叉注意力的方式,主要区别是使编码特征与解码特征在全局层面进行相似性计算,获得第二个解码器层的输出。最终通过一个前馈神经网络和尺寸变换操作,获得相较于卷积互相关操作更精确的互相关响应图X。
2.4 响应图上采样模块
由于红外弱小目标所占像素少、信噪比低,进行多特征提取级联和互相关操作后,响应图每个像素映射回搜索图像的区域通常会大于目标所在区域,引入更多的背景噪声,在测试阶段,会影响目标位置的确定,导致跟踪失败。为使响应图更加精确定位目标所在位置,降低背景对跟踪结果影响,便于之后边界框预测网络模块中分类和回归操作。本文在跟踪方法上添加响应图上采样模块,依据U-Net 网络[17]进行修改,将31×31×5 20 大小的响应图X转变为255×255×1 大小的响应图X′,响应图上采样模块的网络结构如图5 所示。
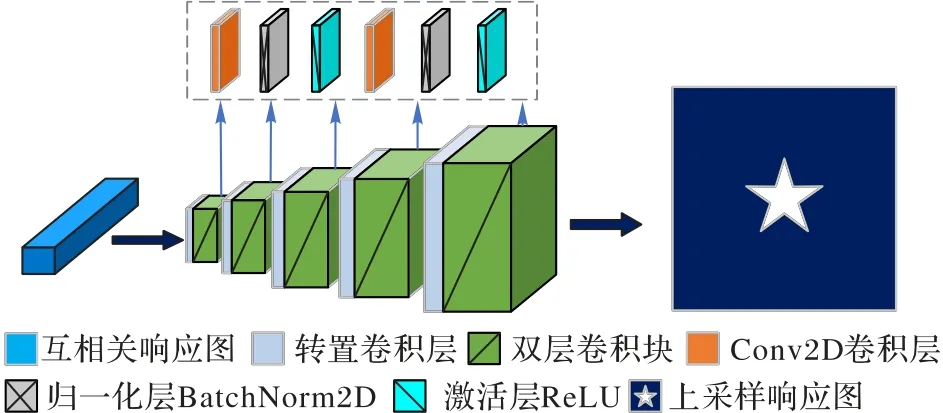
图5 响应图上采样模块的网络结构Fig.5 Network structure of upsampling module of response map
图5 中,响应图上采样模块由一个转置卷积层和一个双层卷积块重复5 次串联获得。其中,5 个双层卷积块的结构相同,都由Conv2D 卷积层、BatchNorm2D 归一化层、ReLU 激活函数层重复2 次获得。转置卷积层的作用是将响应图X的尺寸放大、维度缩小为原来的一半,降低响应图的感受野,提高目标定位的精确性;双层卷积块的作用是进一步缩小响应图的维数,最终使多维度的特征信息整合于一个维度,提高网络表达能力,同时降低网络参数量,减少过拟合的风险。
2.5 模板帧实时更新模块
在本文方法跟踪过程中,模板帧除目标区域外还添加部分周围背景区域,使搜索帧定位目标更加准确。但在实际跟踪过程中,红外序列中背景相对比较复杂、目标背景常发生改变,如图6 所示,从左到右表示红外弱小目标运动过程中目标所在局部区域的变化情况,可从图6 中明显看出红外弱小目标周围背景发生较大的变化。因此,仅利用红外序列第一帧目标区域作为模板帧并不准确。

图6 同一场景下不同帧的模板帧图像Fig.6 Template frame images of different frames in same scene
本文方法在测试过程中添加模板帧实时更新模块,在跟踪当前帧时,利用上一帧定位的目标和周围背景区域作为新的模板帧,具体公式如下所示:
其中:S′表示上一帧红外图像,Recut 表示以上一帧预测的目标中心位置为原点向四周进行扩充和尺度变化的操作,扩充长度为1.5 倍预测边界框对角线的长度,Z′∈R127×127×3表示新的模板帧图像。
之后,将Z′通过多特征提取级联模块后,更新模板特征图,可使边界框预测网络模块的输出结果更具鲁棒性。
2.6 测试过程
本文方法的最终目的是预测当前帧图像红外弱小目标的边界框,以确定目标位置和大小。采用SiamCAR 方法[14]中的边界框预测网络模块,对于响应图X′通过边界框预测网络模块输出分类得分图Scls、中心度偏移得分图Scen和边界框偏差得分图(St,Sb,Sl,Sr)。在实际红外弱小目标运动过程中,相邻帧目标运动距离较小且尺度大小不会发生剧烈变化。因此,本文在预测当前帧目标中心位置上添加余弦窗惩罚,预测边界框上进行平滑处理。余弦窗惩罚可表示为:
式中:λcos大小设置为0.65,Hcos表示255×255 大小的余弦窗,P表示新产生的响应图。添加余弦窗惩罚可抑制较大距离的位移,减弱在搜索区域范围内距离真实目标较远相似干扰物的影响。
边界框平滑可用公式表示为:
式中:λbbox大小设置为0.8,S*i,j表示P中分数最高像素点位置(i,j)与预测边界框上下左右四边的距离,Sli,j+Sri,j可获得预测边界框的宽,Sti,j+Sbi,j获得预测边界框的高,Wpre和Hpre代表上一帧目标边界框的宽和高,W和H表示最终预测边界框的宽和高。通过边界框平滑可使相邻帧间边界框不会发生剧烈变化,更加稳定框选真实目标。
本文方法在测试过程中添加余弦窗惩罚和边界框平滑处理,可使目标定位和回归更加准确,提升方法稳健性。
3 实验与结果分析
实验环境 实验使用版本号为1.9.1 的Pytorch 开源深度学习框架,训练及测试使用NVIDIA RTX 3090 图形图像工作站。
3.1 训练集和测试集
本文方法训练集选用可见光场景下小目标数据集(Large-scale Tiny Object Tracking dataset,LaTOT)[18]中的训练集,包含269 个视频序列,共104 726 帧标注图像。在训练过程中,通过灰度化、平移、缩放、模糊、镜像翻转等操作,增加方法鲁棒性。
方法测试集主要选用修改后的DIRST 数据集[19],在原有目标位置上覆盖灰度值呈高斯分布的目标,大小在5×5 至7×7,并采用外接矩形框作为Label,包含16 个视频序列,共13 655 帧图像。
由于本文方法在灰度化的可见光数据集LaTOT 上训练,为充分验证本文方法的鲁棒性,采用交叉对比的方法,在灰度化后的LaTOT 测试集中多个图像序列进行新的测试,其中包含16 个图像序列,共8 544 帧图像。
3.2 训练过程
训练时使用随机梯度下降法(Stochastic Gradient Descent,SGD)对网络优化,批尺寸batchsize 设置为32,动量momentum 为0.9,训练周期epoch 为50,学习率在整个周期内从0.01 下降到0.000 5 呈指数形式递减。
3.3 评价指标
为验证本文方法的有效性,采用精确率Pre和成功率Suc定量评估跟踪器的目标跟踪结果。
精确率根据预测目标位置中心点与真值目标中心位置之间的欧氏距离在规定阈值范围内的帧数百分比值得出,这里阈值设置为8 像素,中心位置距离计算公式表示为:
式中:(x,y)表示跟踪器预测边界框的中心点坐标,(xg,yg)表示真值边界框的中心点坐标。
成功率根据预测边界框和真值边界框之间的重叠率(Overlap Score,OS)大于规定阈值的帧数的百分比值得出,由于红外弱小目标尺度较小,计算交并比时阈值设置得不同,成功率变化较大,为使结果尽可能精确,阈值设置为0.1,重叠率计算公式为:
式中:A表示预测的边界框位置,Ag表示真值边界框位置。
3.4 对比实验
3.4.1 DIRST数据集定性对比实验及分析
为评估本文方法对红外弱小目标跟踪具有更好的性能,本文选用5 种对比方法包括:1)红外弱小目标检测方法AGPC(Attention Guided Pyramid Context network)[20]和DNANet(Dense Nested Attention Network)[21];2)通用跟踪方法KeepTrack[22]和TransT[12];3)基准跟踪方法SiamCAR[14]。采用红外弱小目标检测方法的原因是可在整幅图片范围内分割出最有可能是红外弱小目标的区域,与之对比可评估本文方法对红外弱小目标的敏感程度,是否适用于红外弱小目标跟踪场景。
图7 可视化展示了不同跟踪方法在修改后的DIRST 测试数据集上的跟踪结果,不同颜色的边界框代表不同的跟踪方法。从图7 可以看出,data8 序列目标周围存在多个相似干扰物,在跟踪过程中,如203 帧,所有对比方法会丢失真实目标,偏移到相似物上,但到295 帧后,如374 帧,KeepTrack 方法会再次捕捉到真实目标,这得益于该方法会对所有潜在目标保持跟踪,建立多条跟踪轨迹,当真实目标置信度高时可重新跟踪。data22 序列目标穿越空地时,发生红外传感器抖动,且周围存在白色亮点,所有对比方法丢失真实目标,本文方法依然稳健跟踪真实目标,在目标进入森林区域,与背景对比度明显,AGPC 和DNANet 全局检测的方法会再次跟踪到真实目标,其他对比方法始终跟踪在相似干扰物上。data4 序列真实目标与相似物目标会交会再分离,分离过程在262 帧时TransT 和KeepTrack 方法会发生尺度估计的误差,框选两个目标,其他方法均稳健跟踪。data17 序列当目标周围出现相似物时,如378 帧,KeepTrack 方法会认为干扰物是真实目标,并偏移到干扰物上,但后续会再次跟踪到真实目标,当目标与背景灰度值差异较低时,如378 和499 帧,DNANet 未检测到真实目标。data10 序列,目标与背景灰度值差异较大,周围无相似干扰物,所有方法均稳健跟踪。总体而言,本文方法对存在相似物干扰和复杂背景情况具有鲁棒的跟踪结果。

图7 不同跟踪方法结果在修改后DIRST测试数据集上的可视化展示Fig.7 Visualization of results of different tracking methods on modified DIRST test dataset
3.4.2 DIRST数据集定量对比实验及分析
选择2.3 节中介绍的评价指标对比本文方法和对比方法的性能,结果如表1 所示。

表1 DIRST数据集上不同方法的定量评估结果 单位:%Tab.1 Quantitative evaluation results of different methods on DIRST dataset unit:%
从表1 中可以看出,相较于其他方法,本文方法成功率分别提高了5.9、14.2、26.5、7.7 和11.6 个百分点。这主要得益于本文方法在测试阶段,对边界框的预测添加了平滑处理,体现在回归框偏差置信图生成边界框后,与上一帧边界框以百分比的形式相加,可使边界框的尺度变换更加平缓,适用于尺度变化较小的红外弱小目标跟踪场景。精确率分别提高了1.8、14.6、22.7、7.4 和11.8 个百分点。这得益于本文提出的多特征提取级联模块、特征互相关模块、上采样模块及模板帧实时更新模块的共同作用,可有效降低目标周围干扰物的影响,使跟踪方法始终保持在真实目标上。总体表明本文方法与两种红外弱小目标检测方法、三种跟踪方法相比跟踪结果更加准确。
3.4.3 LaTOT测试集定性对比实验及分析
为充分验证本文方法的鲁棒性,在LaTOT 测试集中多个图像序列进行新的测试,其中包含3 种对比方法:两种通用跟踪方法KeepTrack[22]和TransT[12]、一种基准跟踪方法SiamCAR[14]。图8 可视化展示了不同跟踪方法在LaTOT 测试数据集上的跟踪结果。

图8 不同跟踪方法结果在LaTOT测试数据集上的可视化展示Fig.8 Visualization of results of different tracking methods on LaTOT test dataset
从图8(a)中可以看出,真实目标移动较慢、周围相似物距离较远的情况下,四种跟踪方法均可稳健跟踪到真实目标;图8(b)中,虽然真实目标出现较大距离的位移,但背景较为干净,没有干扰物的影响,四种跟踪方法始终可以跟踪到真实目标;图8(c)中,第110 帧图像目标从干扰物附近穿过,TransT 和SiamCAR 跟踪方法跟踪偏移到周围物体上,而本文方法和KeepTrack 预测边界框保持在真实目标上,到第293 帧图像,真实目标运动到第7 帧图像目标位置附近,TransT 方法再次跟踪到目标,而KeepTrack 和SiamCAR 跟踪错误,这主要因为基于Transformer 网络的相似性计算更加精确,降低了相似物的干扰,当真实目标再次出现时,会重新跟踪到真实目标;图8(d)中,第103 帧图像目标周围出现相似干扰物,SiamCAR 预测边界框包围真实目标和虚假相似目标,出现尺度估计错误,这主要因为采用深度互相关操作对于相似物的干扰判别性并不强,而较小尺寸的响应图会将相似干扰物和真实目标混淆,导致预测边界框过大,而其他算法都可稳健跟踪,第147 帧图像本文方法跟踪到真实目标尾部区域,原因在于本文方法跟踪过程中尺度估计过小,模板帧实时更新模块将小尺寸的模板帧输入到网络中提取特征进行相似性操作,导致之后的跟踪过程始终保持在目标尾部,但其他方法均跟踪失败。
3.4.4 LaTOT测试集定量对比实验及分析
对比本文方法和三种对比方法在LaTOT 测试集上的性能,结果如表2 所示。

表2 LaTOT测试集上不同方法的定量评估结果 单位:%Tab.2 Quantitative evaluation results of different methods on LaTOT test set unit:%
从表2 中可以看出,相较于其他对比方法,本文方法成功率分别提高了0.7、2.8、2.0 个百分点,精确率分别提高了1.7、2.9、6.7 个百分点。这主要得益于本文方法多个模块的共同作用,此外,在测试阶段添加的余弦窗惩罚和边界框平滑操作也会提高本文方法的跟踪成功率和精确率。
3.5 消融实验分析
为验证本方法中多特征提取级联模块、特征互相关模块、响应图上采样模块和模板帧实时更新模块的有效性,在DIRST 数据集上进行消融实验分析,结果如表3 所示。其中,Base 表示修改过的SiamCAR 跟踪方法,由于本文方法在多特征提取级联模块中深度特征仅使用ResNet-18 最后一个残差块的特征图,为保证消融实验的统一性,修改SiamCAR 中利用多个残差块输出特征图进行深度互相关操作,改为只采用最后一个残差块输出特征图进行深度互相关操作。此外,表3 中①代表Base 方法,②代表在Base 方法中依次添加本文中的一个独立模块,③、④代表以排列组合的方式在Base 方法中添加本文两个和三个模块,⑤代表Base 方法添加本文所有模块,即本文方法。

表3 消融实验结果 单位:%Tab.3 Ablation experimental results unit:%
从表3 中①和②对比可以看出,在Base 上添加其他单独模块后,成功率和精确率都有所提高,但基于Transformer 的特征互相关模块影响最大,成功率提高了15.1 个百分点,精确率提高了12.6 个百分点,说明Transformer 网络中多头注意力机制可有效提高网络的判别性,降低背景及周围干扰物的影响。
从Base+H、Base+U、Base+R 和③对比看出,基于Transformer 的特征互相关模块对跟踪结果的提升最大;从Base+T 和③对比看出,在跟踪较为准确的情况下,利用模板帧实时更新模块对跟踪结果影响最大,由于目标在运动过程中背景不断发生变化,只采用首帧目标区域作为模板帧跟踪结果并不准确,不断更新模板帧图像可提高特征互相关模块输出响应图的准确性,进而提高跟踪成功率和精确率,而当跟踪精度较低时,模板帧实时更新模块对跟踪结果的提升较小。
从Base+H+T、Base+T+U 和④对比看出,模板帧实时更新模块对跟踪结果提升最大,可以推断出,当跟踪结果较好时,采用模板帧实时更新模块会提高跟踪的准确性;从Base+R+U、Base+H+R 和④对比看出,基于Transformer 的特征互相关模块对跟踪结果的提升最大;从Base+H+U 和④对比看出,基于Transformer 的特征互相关模块和模板帧实时更新模块都对跟踪结果有较大的提升;从Base+T+R 和④对比看出,HOG特征和响应图上采样网络都对跟踪结果有一些提升。
从④和⑤对比可以发现,在多特征提取模块中加入HOG 特征后,成功率、精确率分别提高了6.2 和5.8 个百分点,原因是将HOG 特征与深度特征的融合,使模板特征图和搜索特征图获得目标与背景区域更丰富的信息,更好定位到目标。
利用Transformer 代替卷积互相关操作后,成功率和精确率均有所提高,分别为10.9 和11.7 个百分点,证明多头注意力机制可在搜索特征图上寻找与模板特征图最相似的区域,摆脱简单的卷积操作导致陷入局部最优的问题。
响应图上采样模块的加入,使响应图扩大并与搜索区域大小保持一致,可降低小响应图每个像素点感受野过大、引入过多背景信息的不利影响,减小目标定位过程中产生的误差,成功率和精确率分别提升4.0 和4.1 个百分点。
模板帧实时更新模块的加入,成功率、精确率提高了10.1 和10.8 个百分点,说明对复杂背景下的红外弱小目标跟踪很有必要,利用上一帧目标区域提取的特征图代替第一帧目标区域提取的特征图,可使边界框预测网络头网络输出定位更加准确。
4 结语
本文提出一种基于孪生网络和Transformer 的跟踪方法,适用于复杂背景下的红外弱小目标跟踪。输入红外序列后,对模板帧和搜索帧图像进行多特征提取,获得级联特征,之后通过Transformer 的互相关模块和响应图上采样模块,获得上采样响应图,最后通过边界框预测网络输出跟踪结果。在修改后的复杂背景下红外弱小目标数据集DIRST 上评估本方法与其他方法的差异。实验结果表明,本文方法可达到90.2%的成功率和89.7%的精确率,可准确跟踪红外序列中的红外弱小目标。在未来的工作中,考虑将多帧图像输入网络中进行训练和测试,提取具备时间信息的特征图,进一步提高跟踪的成功率和精确率。
猜你喜欢
疯狂英语·新悦读(2023年3期)2023-10-10
环球时报(2022-05-23)2022-05-23
儿童时代·幸福宝宝(2021年11期)2021-12-21
金桥(2021年4期)2021-05-21
电子制作(2019年7期)2019-04-25
证券法律评论(2018年0期)2018-08-31
光学精密工程(2016年3期)2016-11-07
宠物世界·猫迷(2015年7期)2015-05-30
红领巾·萌芽(2015年1期)2015-04-10
外语学刊(2014年6期)2014-04-18
