
基于ZYNQ平台的卷积神经网络加速器设计与实现
2024-04-13 06:08陈思浩吴黎明彭克锦许志杰
自动化与信息工程 2024年1期
关键词:卷积神经网络
陈思浩 吴黎明 彭克锦 许志杰


本文引用格式:陈思浩,吴黎明,彭克锦,等.基于ZYNQ平台的卷积神经网络加速器设计与实现[J].自动化与信息工程,2024, 45(1):30-34.
CHEN SiHao, WU LiMing, PENG KeJin, et al. Design and implementation of convolutional neural network accelerator based on ZYNQ platform[J]. Automation & Information Engineering, 2024,45(1):30-34.
摘要:针对卷积神经网络模型规模较大,以及嵌入式系统计算资源有限的问题,提出一种基于ZYNQ平台的卷积神经网络加速器设计方案。采用软硬件协同设计的原则,首先,在FPGA端设计图像、参数输入模块;然后,利用FPGA并行计算技术实现卷积层和池化层运算,并通过摄像头采集手写数字图像与LCD显示结果;最后,在嵌入式平台上实现手写数字识别。实验结果表明,卷积层和池化层的运算速度比ARM平台提高了2.68倍。
关键词:卷积神经网络;ZYNQ平台;硬件加速;FPGA
中图分类号:TN912.3 文献标志码:A 文章编号:1674-2605(2024)01-0005-05
DOI:10.3969/j.issn.1674-2605.2024.01.005
Design and Implementation of Convolutional Neural Network Accelerator Based on ZYNQ Platform
CHEN Sihao WU Liming PENG Kejin XU Zhijie
(School of Electromechanical Engineering, Guangdong University of Technology, Guangzhou 510006, China)
Abstract: A convolutional neural network accelerator design scheme based on the ZYNQ platform is proposed to address the issues of large-scale convolutional neural network models and limited computing resources in embedded systems. Adopting the principle of software hardware collaborative design, first, design image and parameter input modules on the FPGA side; Then, using FPGA parallel computing technology to implement convolutional and pooling layer operations, and capturing handwritten digital images and LCD display results through a camera; Finally, implement handwritten digit recognition on an embedded platform. The experimental results show that the computational speed of the convolutional and pooling layers is 2.68 times faster than that of the ARM platform.
Keywords: convolutional neural networks; ZYNQ platform; hardware acceleration; FPGA
0 引言
隨着人工智能技术的迅速发展,卷积神经网络(convolutional neural network, CNN)作为一种深度学习模型,广泛应用于图像识别[1]、目标检测[2]和语音处理[3]等领域。然而,传统的嵌入式系统无法满足CNN的复杂性和大规模计算的需求。图形处理器(graphics processing unit, GPU)虽然可以加速CNN,但其存在体积大、功耗高等问题。为此,研究人员将硬件加速
器应用于CNN的计算中,以提高其计算性能和能效。因此,在保证性能的前提下,体积更小、功耗更低的硬件平台成为CNN加速领域的热门发展方向[4-7]。
基于现场可编程门阵列(field-programmable gate array, FPGA)的加速平台因具有可编程性强、并行计算能力强等特点,成为研究热点[8-10]。但直接在FPGA上实现CNN计算是一项复杂的任务,需考虑诸多因素,如外设控制、内存带宽、开发难度和开发周期等。
为此,本文提出一种基于ZYNQ平台的卷积神经网络加速器设计方案,在FPGA端设计加速器模块,通过摄像头采集手写数字图像与LCD显示结果,实现手写数字的识别。该方案根据软硬件协同设计的原则,利用ZYNQ平台上FPGA的并行计算能力和ARM的通用计算能力,对CNN模型中的卷积层和池化层进行IP核设计,提升了手写数字的识别速度。
1 系统设计
1.1 系统组成
硬件系统主要由OV5640摄像头、FPGA、ARM、LCD显示屏和DDR存储器等组成,如图1所示。
ZYNQ平台是硬件系统的核心部分,它集成了FPGA和ARM,通过双片BRAM(Block RAM)与AXI总线实现PS与PL之间的通信,进而实现嵌入式开发[11-13]。这种组成方式允许开发人员在单个芯片上同时运行硬件计算和嵌入式软件,具有较强的灵活性,可满足不同应用场景对计算资源和实时性的需求。
硬件系统运行流程如下:
1) 在ARM端对OV5640摄像头进行配置,通过OV5640摄像头采集手写数字图像;
2) 手写数字图像传入FPGA端的OV5640图像采集IP核,并将8位图像数据拼接为24位图像数据;
3) FPGA端的图像预处理IP核对24位图像数据进行灰度和二值化处理;
4) FPGA端的卷积与池化IP核提取手写数字图像特征后,通过AXI总线将池化后的数据传入ARM,进行全连接运算与结果分类;
5) 分类结果显示在LCD上。
1.2 CNN结构
CNN利用了局部连接和参数重用的特性,其每层都单独使用一组卷积核,有助于从局部相关数据中提取有用的特征[14-17]。CNN主要包括输入层、卷积层、池化层、全连接层等,结构如图2所示。
考虑到嵌入式芯片的计算资源有限,为充分发挥FPGA端和ARM端的性能,本文对经典的CNN结构进行改进,在尽量精简结构的同时,保留了CNN的卷积层。改进后的CNN结构包含1个卷积层、1个池化层和2个全连接层,以实现手写数字的识别。输出层有10个节点,每个节点对应1个手写数字,因此改进后的CNN结构没有使用SoftMax函数。如果需要部署更复杂的CNN,只需在加速器模块中导入新的权重参数,并复用卷积层和池化层IP核即可。
2 加速器模块设计
加速器模块主要由图像输入模块、参数输入模块、卷积运算模块和池化运算模块组成,结构框图如图3所示。
在FPGA上部署神经网络一般采用硬件描述语言(hardware description language, HDL)和高层次综合(high-level synthesis, HLS)工具两种方法。虽然传统的HDL编程耗时比HLS长,但它可以精确定义每个时序硬件电路的行为和功能,能更好地利用FPGA资源。因此,本文采用HDL设计加速器模块。
2.1 图像输入模块
图像输入模块主要由降采样部分和数据存储单元组成。考虑到采集的手写数字图像需清晰地显示在800×600像素的LCD上,在输入卷积运算模块前,需对其进行降采样操作。
根据卷积层的输入大小,先对采集的手写数字图像进行倍数放大,卷积层输入图像的大小为28×28像素,将手写数字图像先放大4倍,即图像大小为112×112像素;再进行降采样操作,即每隔4个点取1个点,如图4所示。
数据存储单元采用BRAM来实现。本文设计一个28 bit的BRAM来存储手写数字图像数据。降采样后的手写数字图像数据以列优先的顺序写入BRAM,每次写入1个像素点的数据,即1 bit。
读端口和写端口通过不同的使能信号控制。读端口的使能信号一直为高电平,可连续从BRAM中读取卷积窗口大小的数据。读取数据时,一次性读取一行数据的前5个数据,每次读取后,数据指针向后移动1位,这样可确保连续读取5×5的数据,满足卷积计算的需求,如图5所示。
写入数据时,通过行计数器控制写使能信号,每采集1个像素点,就向BRAM写入1位数据。当BRAM存储完整图像的一行数据后,再切换至下一行。
读写两个端口使用不同的地址进行控制,不仅能避免读写冲突,还能够高效地实时读取BRAM中卷积窗口大小的数据,为后续的卷积运算提供数据支持。
2.2 参数输入模块
参数输入模块使用6个ROM来存储卷积层中每个卷积核5×5窗口内不同位置的参数值和偏置值,其存储方式与图像输入模块存储图像数据相似。
2.3 卷积运算模块
卷积运算模块作为实现神经网络前向传播的核心模块,利用一维卷积来计算图像与每个卷积核对应的响应值。其中,每个卷积核对应一個卷积窗口的权重参数。卷积运算模块中包含多个乘累加器,如图6所示。
控制单元根据行计数和卷积核索引来控制乘累加器的操作。每个乘累加器负责一个卷积核与图像数据矩阵的乘加计算。首先,乘累加器从BRAM和ROM中同步读取1个图像数据矩阵和相应的卷积核参数;然后,依次将对应的图像数据与卷积核参数相乘;最后,将结果相加。一个完整的卷积计算需要连续读取5行的图像数据与一个卷积核的5×5参数,共进行25次乘加运算。为提高计算效率,每个乘累加器将25次乘加运算并行化为5次流水线操作,充分利用每个时钟周期的计算资源,提升了卷积层的计算吞吐量。
2.4 池化运算模块
池化运算模块采用2×2的池化窗口对每个2×2块数据进行最大值池化。池化运算模块主要包括比较器和FIFO两部分,计算过程如图7所示。
比较器接收来自卷积运算模块的2×2块数据,每次比较该块内第一组的两点数据,输出最大值,存入FIFO中。当第二组2×2块数据进入比较器时,将该块内的值与FIFO保存的最大值进行比较,更新最大值。每处理完一组2×2块数据后,输出的最大值即为该组数据池化的结果。
为获得池化结果的正确顺序,需控制比较器和FIFO的读写时序。比较器每完成一次2×2块数据的最大值计算后,将结果立即写入FIFO,同时FIFO读端口被使能输出结果。读写两端口在不同的时钟边沿分别工作,保证数据的有序输出。最后,通过串联多个2×2块数据的最大值计算,实现整个输入特征图的最大池化。
池化后的低维特征图作为ARM后端程序的输入,经过VDMA传输到ARM,提供给全连接层进行 计算。
3 实验分析与结果
本实验采用领航者ZYNQ开发板,其主芯片ZYNQ采用XC7Z020CLG400-2,ARM端采用频率为666 MHz的双核Cortex-A9处理器,FPGA端的时钟频率为200 MHz,开发环境为Vivado2020和Vitis2020。ZYNQ开发板带有摄像头模块接口和RGB LCD接口。考虑到适合手写数字识别的应用场景,开发了摄像头和LCD等模块来模拟真实识别场景。上板验证效果如图8所示。
在开发工具Vivado2020中,生成器件的资源使用情况报告如表1所示。
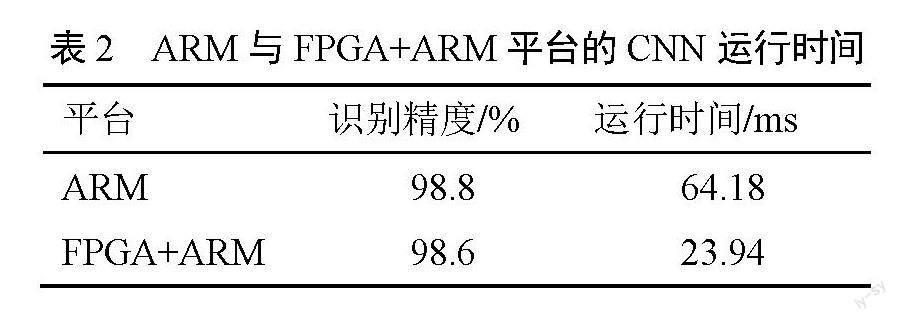
通过多次实验分析加速器模块的仿真時序图,计算卷积与池化运行所需的时间,在Vitis中通过时间获取函数得到全连接层的运算时间,即可得到FPGA加速后的CNN运行总时间,并将其与仅在ARM端运行的CNN进行对比,结果如表2所示。
由表2可知,相较于仅在ARM端运行的CNN, FPGA加速后的CNN在识别精度损失较小的情况下,网络运行时间减少了2.68倍。
4 结论
本文基于ZYNQ平台提出了一种卷积神经网络加速器设计方案。在FPGA端设计了图像数据与参数数据存储模块,实现高效的存储与读取,为卷积计算提供数据支持。采用并行设计的思路实现卷积和最大池化的运算,在保证识别精确度的同时,卷积层和池化层的运行速度提高了2.68倍。与其他神经网络的加速方案相比,该加速方案具有功耗低、体积小、容易部署、通用性强等特点,具有一定的实际应用意义。
参考文献
[1] NARAYAN A, MUTHALAGU R. Image character recognition using convolutional neural networks[C]//2021 Seventh Interna-tional conference on Bio Signals, Images, and Instrumentation (ICBSII). IEEE, 2021:1-5.
[2] YAN X, SHUAI C, ZHENG H. A Yolov3-based multi-target detection system for complex scenes[C]//2021 2nd International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT). IEEE, 2021:327-332.
[3] HSU Y, LEE Y, BAI M R. Learning-based personal speech enhancement for teleconferencing by exploiting spatial-spectral features[C]//ICASSP 2022-2022 IEEE International Confe-rence on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022:8787-8791.
[4] USHIROYAMA A, WATANABE M, WATANABE N, et al. Convolutional neural network implementations using Vitis AI [C]//2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC). IEEE, 2022: 0365-0371.
[5] ADIONO T, SUTISNA N. FPGA based hardware accelerator design for convolution process in convolutional neural network [C]//2021 International Conference on Electrical Engineering and Informatics (ICEEI). IEEE, 2021:1-5.
[6] XIONG Z M. A survey of FPGA based on graph convolutional neural network accelerator[C]//2020 International Conference on Computer Engineering and Intelligent Control (ICCEIC). IEEE, 2020:92-96.
[7] LI L, CHEN X, GAO W. Implementation of convolutional neural network accelerator based on ZYNQ[C]//2022 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA). IEEE, 2022:158-165.
[8] PISHARODY J N, PRANAV K B, RANJITHA M, et al. FPGA implementation and acceleration of convolutional neural net-works[C]//2021 6th International Conference for Convergence in Technology (I2CT). IEEE, 2021:1-4.
[9] 江瑜,朱铁柱,蒋青松,等.基于FPGA的卷积神经网络硬件加速器设计[J].电子器件,2023,46(4):973-977.
[10] 黄沛昱,赵强,李煜龙.基于FPGA的卷积神经网络硬件加速器设计[J].计算机应用与软件,2023,40(3):38-44.
[11] 冯光顺,应三丛.ZYNQ的卷积神经网络硬件加速通用平台设计[J].单片机与嵌入式系统应用,2019,19(3):3-6;9.
[12] 刘晛,吴瑞琦,高尚尚,等.基于ZYNQ的通用型卷积神经网络设计与实现[J].电子器件,2023,46(1):121-125.
[13] 缪丹丹,张鹏,张鑫宇,等.基于ZYNQ平台的通用卷积加速器设计[J].国外电子测量技术,2022,41(11):72-77.
[14] 季长清,高志勇,秦静,等.基于卷积神经网络的图像分类算法综述[J].计算机应用,2022,42(4):1044-1049.
[15] 谭亚红,史耀.完备变分模态分解和多传感器卷积神经网络的轴承故障诊断方法[J].机床与液压,2022,50(14):182-188.
[16] 刘斌,龙健宁,程方毅,等.基于卷积神经网络的物流货物图像分类研究[J].机电工程技术,2021,50(12):79-82;175.
[17] 许富景,陈长颖,杜少成.基于改进CNN的压缩感知自然图像重建方法[J].中国测试,2022,48(9):7-16.
作者简介:
陈思浩,男,1998年生,在读研究生,主要研究方向:智能测控。E-mail: edwardchenx@foxmail.com
吴黎明,男,1962年生,硕士,教授,主要研究方向:智能测控。E-mail: jkyjs@gdut.edu.cn
彭克锦,男,1999年生,在读研究生,主要研究方向:智能测控。E-mail: 1334152998@qq.com
许志杰,男,1999年生,在读研究生,主要研究方向:智能测控。E-mail: 1422411797@qq.com
猜你喜欢
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年10期)2016-06-16
