
基于UPS策略自我训练的半监督语义分割
2024-04-14 02:12李雨杭朱小东杨高明
现代信息科技 2024年2期
李雨杭 朱小东 杨高明

DOI:10.19850/j.cnki.2096-4706.2024.02.001
收稿日期:2023-10-27
基金项目:安徽高校自然科学研究项目(KJ2017A084);安徽省自然科学基金面上项目(1808085MF179)
摘 要:为提高半监督语义分割的效果,文章提出一种损失归一化技术结合UPS策略的半监督语义分割网络SPNS。利用损失归一化技术缓解标准损失函数的自我训练不稳定问题;UPS策略是结合不确定性估计和消极学习的技术,通过计算输出值的不确定性作为另一种阈值,用以挑选可靠的伪标签,最后利用生成的伪标签和标记数据完成半监督语义分割任务。SPNS方法在PASCAL·VOC数据集上相对于只使用标记数据训练有着+2.06的效果提升,与其他方法相比也有一定提升。
关键词:半监督;语义分割;自我训练;UPS;消极学习
中图分类号:TP391 文献标志码:A 文章编号:2096-4706(2024)02-0001-04
Semi-supervised Semantic Segmentation Based on UPS Strategy Self Training
LI Yuhang, ZHU Xiaodong, YANG Gaoming
(School of Computer Science and Engineering, Anhui University of Science and Technology, Huainan 232001, China)
Abstract: To improve the effectiveness of semi-supervised semantic segmentation, this paper proposes a semi-supervised semantic segmentation network SPNS that combines loss normalization technology with UPS strategy. Using loss normalization techniques to alleviate the instability of self training in standard loss functions; the UPS strategy is a technique that combines uncertainty estimation and passive learning, by calculating the incompleteness of the output value as another threshold, reliable pseudo labels are selected, and finally the semi-supervised semantic segmentation task is completed using the generated pseudo labels and labeled data. The SPNS method has +2.06 improvement compared to training with only labeled data on the PASCAL · VOC dataset, and also has some improvement compared to other methods.
Keywords: semi-supervised; semantic segmentation; self training; UPS; negative learning
0 引 言
語义分割,即从集合中分配标签图片的每个像素类别,是计算机视觉任务中最具挑战性的任务之一。现有的基于卷积神经网络的全监督分割方法[1]很大程度上得益于带标注数据集规模的快速增长,但数据集规模快速增长的同时也给数据标注带来了极大的压力。以语义分割任务为例,如果在语义分割公开数据集PASCAL VOC2012[2]上标注一张图像的像素级标签需要4分钟时间,则标注PASCAL VOC 2012上整个扩展训练集(10 528张图像)的时间会长达一个月,同时获取这些数据的成本急剧上升。
监督学习的替代方法是无监督学习,即利用大量的未标记数据,但是无监督学习的方法缺乏类的概念,只是试图识别一致的区域或区域的边界。半监督学习介于有监督和无监督之间,即给出的数据一部分是标记数据。半监督学习用来识别一些特定的隐藏结构,在某些情况下,未标签数据x的p(x)可以支持分类带有y标签的p ( y | x)。为了解决数据难获得或标注时间过长的问题,一些半监督的方法成为新的选择[3-10]。
一致性正则化方法的本质就是使用数据增强策略。目前对图像常见的数据增强方法除了为图像添加高斯噪声扰动、图像色彩抖动、随机尺度裁剪等基本方法外,还有CutMix[9]、GAN等方法。一致性正则法在目前的半监督学习领域占据主导地位,但是这类技术的惊艳表现是建立在大量的先导工作的基础上的,对于特定数据集的分类任务,往往需要事先花很长的时间去搜索最合适的数据增强策略,如果缺乏十分有效的数据增强策略,就会导致缺乏泛化能力。
还有一种典型的方法是为没有标注释的像素分配伪标签(Pseudo-Labe)。具体来说,给定一张未标记的图像,现有的[3,4,6,7]借用在标记数据上训练的模型的预测,并使用逐像素预测作为“ground-truth”,进而提升监督模型。自我训练[7]也可以叫作自我学习,也是使用这种方法。自我训练主要以经过有标签数据训练出来的模型有极大可能性是正确的为前提。用标签数据训练一个教师模型,再使用教师模型生成的伪标签和有标签数据训练最终的模型。但是这种打伪标签法存在一个问题:即无论样本被贴上的伪标签正确与否,这些标签都需要有很高的置信度。如果大量的无标签样本被贴上错误的标签并用作训练,将导致训练集中存在大量的噪声样本,从而严重影响模型的性能。SPNS方法使用UPS策略的自我训练和语义分割网络结合,能够在一定程度上降低伪标签的错误率。
1 本文方法介绍
1.1 方法概述
给定一个标记集 和一个更大的未标记数据集 ,本文的目标是通过大量未标记的数据和较小的标记数据来完成半监督语义分割任务。使用自我训练的打伪标签方法时,常常因为贴上错误的标签造成噪声样本,而迭代过程会大量增加噪声样本数量;同时使用标准损失函数的自我训练在迭代过程中,加入伪标签训练学生模型时可能会出现训练崩溃、无法收敛的情况。
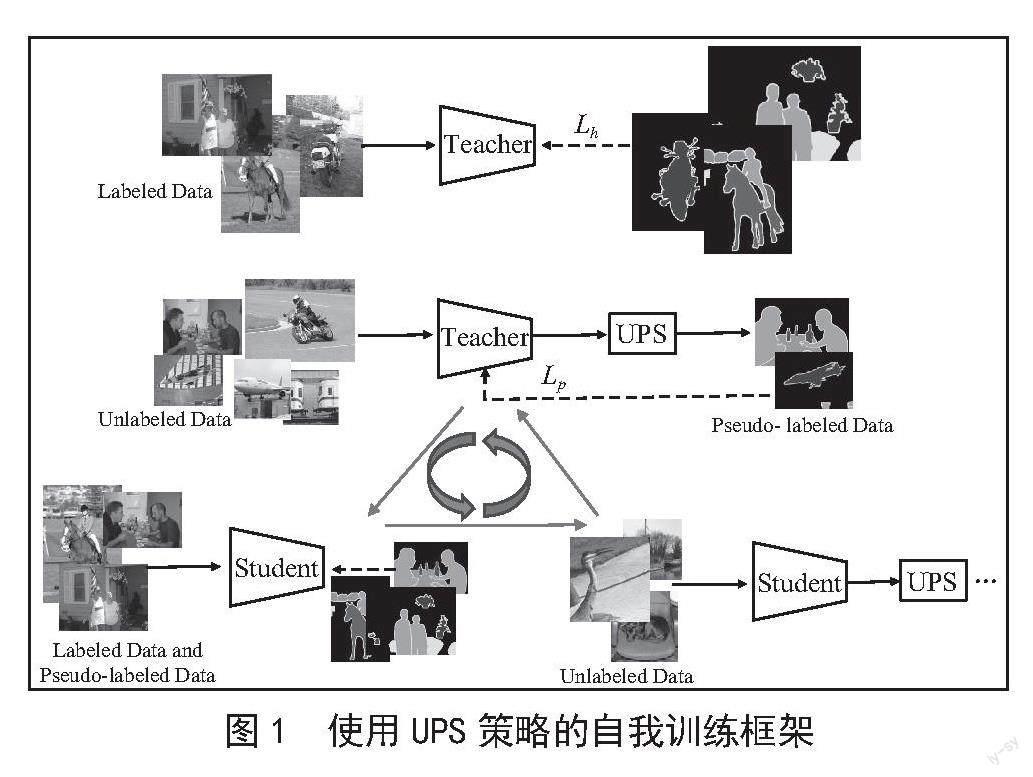
结合兼顾Positive & Negative Pseudo Label的打伪标签法和UPS的自我训练框架,并结合不确定性估计(Uncertainty estimation)和消极学习(Negative learning),减少贴错标签情况的同时,挑选出可靠的伪标签。图1给出了使用UPS策略自我训练的模型图。它遵循自我训练框架,具有两个框架相同的模型,分别命名为教师和学生。1)在标记数据上训练教师模型。2)教师模型在未标记的数据上生成伪标签,并使用UPS策略挑选伪标签。3)使用打上伪标签的数据和有标注数据一起训练模型(重新随机初始化),然后跳至步骤2)继续执行,直到循环迭代到最大迭代次数。
使用标准损失函数的自我训练可能是不稳定的,为解决这个问题,本文使用一种损失归一化技术α[7]:
(1)
其中Lh,Lp,, 分别为真实标签损失、伪标签损失和各自损失的滑动平均值。
1.2 兼顾Positive & Negative Pseudo Label的打伪标签法
传统的伪标签方法,通常设定一个阈值,当模型预测样本属于某类的概率超过阈值时,给样本贴上相应的伪标签并用于训练;或者,直接选取模型预测的最大概率所在的类作为伪标签,其公式如下:
(2)
其中 为样本x(i)关于第c类的伪标签, 为模型输出的第c类的概率,γ为阈值。若伪标签的值域为{0,1},则该标签指示了样本属于或不属于第c类即传统C分类问题中的one-hot label形式,即可转换为由该类标签组成的1×c维的标签:(i) = [,… ,… ]c。令 指示样本x(i)的伪标签是否被用作训练模型,g(i) = [,…,?{0,1}c,用卡阈值的方法生成Positive Pseudo Label(伪标签指示样本属于某类),当然也可以用类似的方法生成Negative Pseudo Label(伪标签指示样本不属于某类)其计算公式为:
(3)
其中,τp和τn分别为Positive、Negative Pseudo Label的选取阈值(τp≥τn),这样就得到了Negative Pseudo Labe。对于单标签分类任务来说,仿照只有Positive Pseudo Label时的交叉熵损失,可得到Negative Pseudo Labe的损失函数:
(4)
其中s(i)为样本的伪标签数目, = 为模型的原始输出概率;进一步融合Positive、Negative Pseudo Label的损失函数即可用于多分类任务:
(5)
1.3 UPS(基于不确定性的伪标签选择法)
为了减少训练中存在的噪声样本,校正网络模型的输出。计算输出值的不确定出值的不确定性[9]作为另一种置信度,和Softmax层输出的概率联合挑选可靠的伪标签样本。
使用网络模型预测的不确定性用作模型输出的校正,需要分析网络校正与模型对个体样本输出不确定性的关系。ECE(Expected Calibration Error)是一种衡量网络校正的常用指标:
(6)
数据集D被等分成L份,Il为第l份中的样本。每份的校正偏差的均值,即可得到ECE的值。在参照MC dropout计算出网络的不确定性之后。即可得出:打上标签时模型的不确定性越低,网络校正的误差越小,也就是说可以计算模型对每个样本输出的不确定性,来判断该样本的伪标签是否可靠。由此可仿照式(3)得到:
(7)
其中u(p)为预测结果p的不确定性估计值,kp、kn为不确定性的阈值。
1.4 SPNS方法
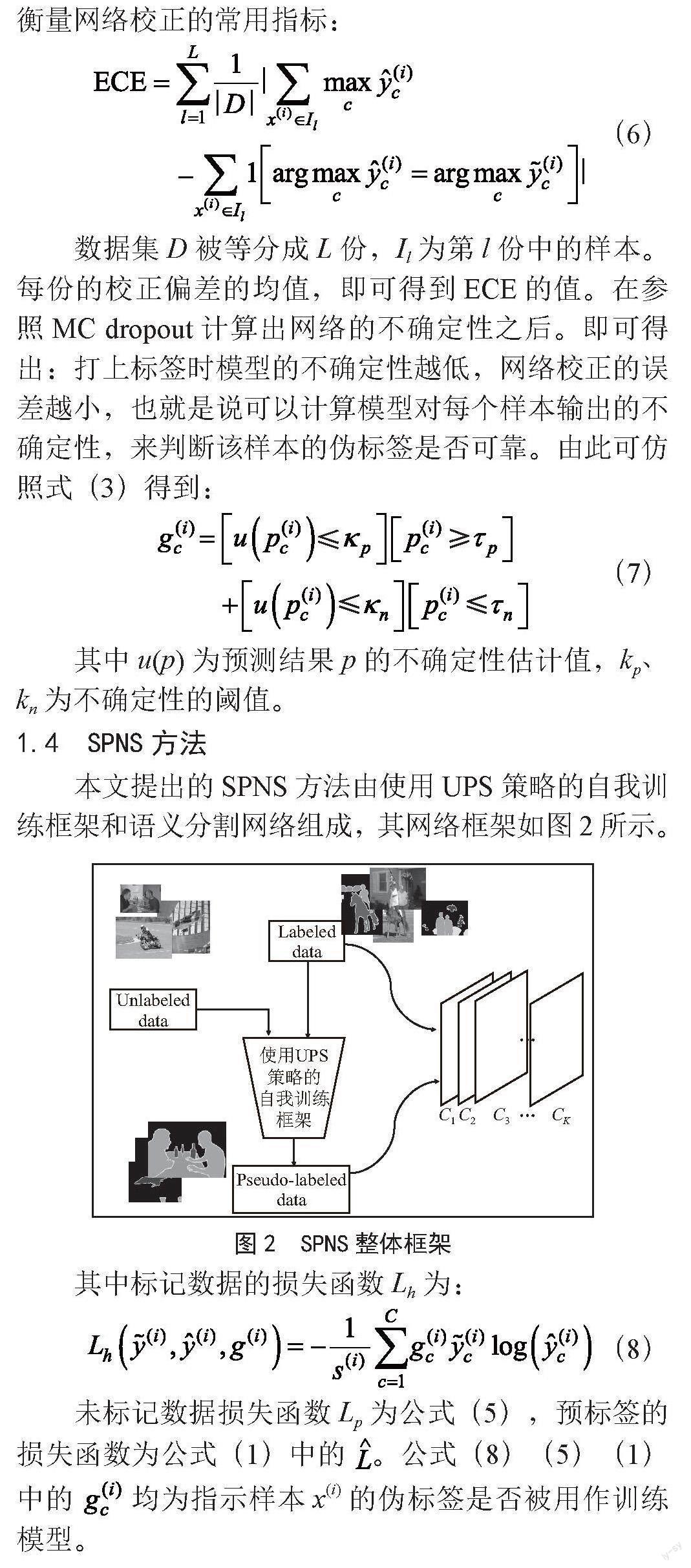
本文提出的SPNS方法由使用UPS策略的自我训练框架和语义分割网络组成,其网络框架如图2所示。
图2 SPNS整体框架
其中标记数据的损失函数Lh为:
(8)
未标记数据损失函数Lp为公式(5),预标签的损失函数为公式(1)中的 。公式(8)(5)(1)中的 均为指示样本x(i)的伪标签是否被用作训练模型。
2 实验设置与对比分析
2.1 实验设置
PASCAL VOC 2012数据集具有20个对象的语义类别和1个背景类别,非常适合完成语义分割任务。其训练集和验证集分别包括1 464和1 449张图像。使用SBD作为具有9 118个额外训练图像的增强集。由于SBD数据集是粗注释,所以PseudoSeg[6]仅将标准的1 464张图像作为整个标记集,在经典集(1 464个候选标记图像)和扩展集(10 582个候选标记图像)上评估本文的方法。Cityscapes 是一個专为理解城市场景设计而设计的数据集,由2 975张带有精细标注掩码的训练图像和500张验证图像组成。对于每个数据集,我们将1/2、1/4、1/8、1/16分区协议下SPNS与其他方法进行比较。
网络结构本文采用具有EfficientNet-B7和EfficientNet-L2主干模型的NAS-FPN[1]模型架构。SPNS采用的NAS-FPN模型使用7次重复的深度可分离卷积,P3到P7使用特征金字塔,并将所有特征级别上采样到P2,然后通过求和操作将特征合并。在特征合并后应用3层3×3卷积层再附加1×1的卷积层,以进行21类的预测。EfficientNet-B7的学习率设置为0.08,Efficient-L2d的学习率为0.2,batch size为256,权重衰减为1×10-5。所有模型都使用余弦学习率衰减计划进行训练,并使用同步批量标准化。对于自我训练EfficientNet-B7 batch size为512,EfficientNet-L2为256。其他超参数遵循监督训练中的超参数。此外,使用0.5的硬分数阈值来生成分割掩码。并将分数较小的像素设置为忽略标签。最后,我们应用具有(0.5、0.75、1、1.25、1.5、1.75)尺度的多尺度推理增强来计算伪标记的分割掩码。
评价指标采用MIoU(Mean of Intersection Over Union )作为度量评估这些裁剪的图像。
在不同分区协议下经典PASCAL VOC 2012 验证集上与其他先进方法进行比较。被标记的图像从VOC训练集中选择,该训练集包含1 464个样本。分数表示百分比用于训练的标记数据,然后是实际的图像数量。来自SBD的所有图像都被视为未标记数据。“OnlySup”代表不使用任何未标记数据训练。
2.2 与现有方法的比较
将提出的SPNS方法和最近的半监督语义分割方法MT[4]、CutMix[5]、MixMatch[10]、GAN进行比较。所有方法都配备相同的网络架构(EfficientNet-B7、EfficientNet-L2作为主干)。经典的PASCAL VOC 2012数据集与扩展的PASCAL数据集仅在训练集存在差异,验证集是相同的1 449张图像。如表1所示,在1/16、1/8、1/4、1/2分区协议下,本文方法与OnlySup相比表现分别提高了17.01%、13.33%、5.03%、3.07%;与PseudoSeg相比,分别提高了5.77%、1.65%、1.62%、2.33%。
表2是本文所提SPNS方法与其他方法在不同协议下PASCAL扩展集上的比较,所有标记图像都是从PASCAL扩展集中选择的。OnlySup代表不使用任何未标记数据情况下进行监督训练。
在PASCAL扩展集上,SPNS方法均优于其他的方法,如表2,与基线模型OnlySup(仅使用监督数据训练)相比,在1/16、1/8、1/4、1/2分区协议实现了4.68%、2.66%、2.16%、2.47%的改进;特别是在1/16和1/8分区协议下,SPNS方法的表现优于MixMatch 2.4%和1.8%。
表3是SPNS方法与其他方法在不同协议下Cityscapes数据集上的比较,OnlySup代表不使用任何未标记数据情况下进行监督训练。
表3是在Cityscapes数据集上的比较结果。SPNS方法在1/16、1/8、1/4、1/2分区协议优于基线模型7.29%、8.06%、3.61%、3.23%;特别是优于MixMatch的方法2.4%、1.8%、0.68%、1.03%。
3 结 论
本文设计了一种损失归一化技术结合UPS策略的半监督语义分割网络:SPNS。利用兼顾Negative Learning技术的自我训练生成伪标签,同时使用一种归一化技术解决训练过程中学生模型崩溃的问题,再使用结合不确定性估计和UPS策略,计算输出值的不确定性作为另外一种置信度阈值,和softmax输出概率一起挑选可靠伪标签,减少噪声样本,以解决大量噪声样本的问题,以提高半监督语义分割的效果。与全监督方法相比,SPNS的方法训练耗时较多,这是半监督学习任务的常见缺点,由于极度缺乏标签,半监督学习框架通常需要付出时间代价才能获得更高的准确性。
参考文献:
[1] GHIASI G,LIN T Y,LE QV. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:7029-7038.
[2] EVERINGHAM M,G00L L,WILLIAMS C K.L,et al. The Pascal Visual Object Classes (VOC) Challenge [J].International Journal of Computer Vision,2010,88(2):303-338.
[3] RIZVE M N,DUARTE K,RAWAT Y S,et al. In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning [J/OL].arXiv:2101.06329 [cs.LG].[2023-08-28].https://arxiv.org/abs/2101.06329.
[4] TARVAINEN A,VALPOLA H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results [J/OL].arXiv:1703.01780 [cs.NE].[2023-08-28].https://arxiv.org/abs/1703.01780.
[5] YUN S,HAN D,OH S J,et al. Cutmix: Regu- larization strategy to train strong classifiers with localizable features [J/OL].arXiv:1905.04899 [cs.CV].[2023-08-29].https://arxiv.org/abs/1905.04899v1.
[6] ZOU Y L,ZHANG Z Z,ZHANG H,et al. Pseudoseg: Designing Pseudo Labels for Semantic Segmentation [EB/OL].[2023-08-28].https://www.xueshufan.com/publication/3118629228.
[7] SOULY N,SPAMPINATO C,SHAH M. Semi Supervised Semantic Segmentation Using Generative Adversarial Network [C]//2017 IEEE international conference on computer vision.Venice:IEEE,2017:5689-5697.
[8] ZOPH B,GHIASI G,LIN T Y,et al. Rethinking Pre-training and Self-training [J/OL].[2023-08-29].https://arxiv.org/abs/2006.06882v1.
[9] KIM Y,YIM J,YUN J,et al. Nlnl: Negative Learning for Noisy Labels [C]//2019 IEEE/CVF international conference on computer vision.Seoul:IEEE,2019:101-110.
[10] Berthelot D,Carlini N,Goodfellow L,et al. Mixmatch:A holistic approach to semi-supervised learning [C]//NIPS'19: Proceedings of the 33rd International Conference on Neural Information Processing Systems.Vancouver:Curran Associates Inc.,2019:5049–5059.
作者簡介:李雨杭(1998—),男,汉族,安徽蚌埠人,硕士研究生在读,主要研究方向:半监督语义分割;通讯作者:朱小东(1980—),男,汉族,安徽淮南人,讲师,博士,主要研究方向:模式分类、图像分割。
